PDF批量删除固定位置图片工具 PDF PicKiller
- [<center>PDF PicKiller Download(https://github.com/Peaceful-World-X/PDF-PicKiller)](#
PDF PicKiller Download) - [🤩 工具介绍](#🤩 工具介绍)
- [🥳 主要功能](#🥳 主要功能)
- [🤪 软件使用](#🤪 软件使用)
- [🤪 参数解释](#🤪 参数解释)
- [🤪 关键代码](#🤪 关键代码)
- [🤩 项目代码](#🤩 项目代码)

PDF PicKiller Download
🤩 工具介绍
PDF PicKiller 是基于Python的PDF批处理工具,默认无感解密,使用命令行界面批量删除固定位置图像、渐变背景图、水印图或字,后续还有可能添加新功能,额...如果软件有用的话~
🥳 主要功能
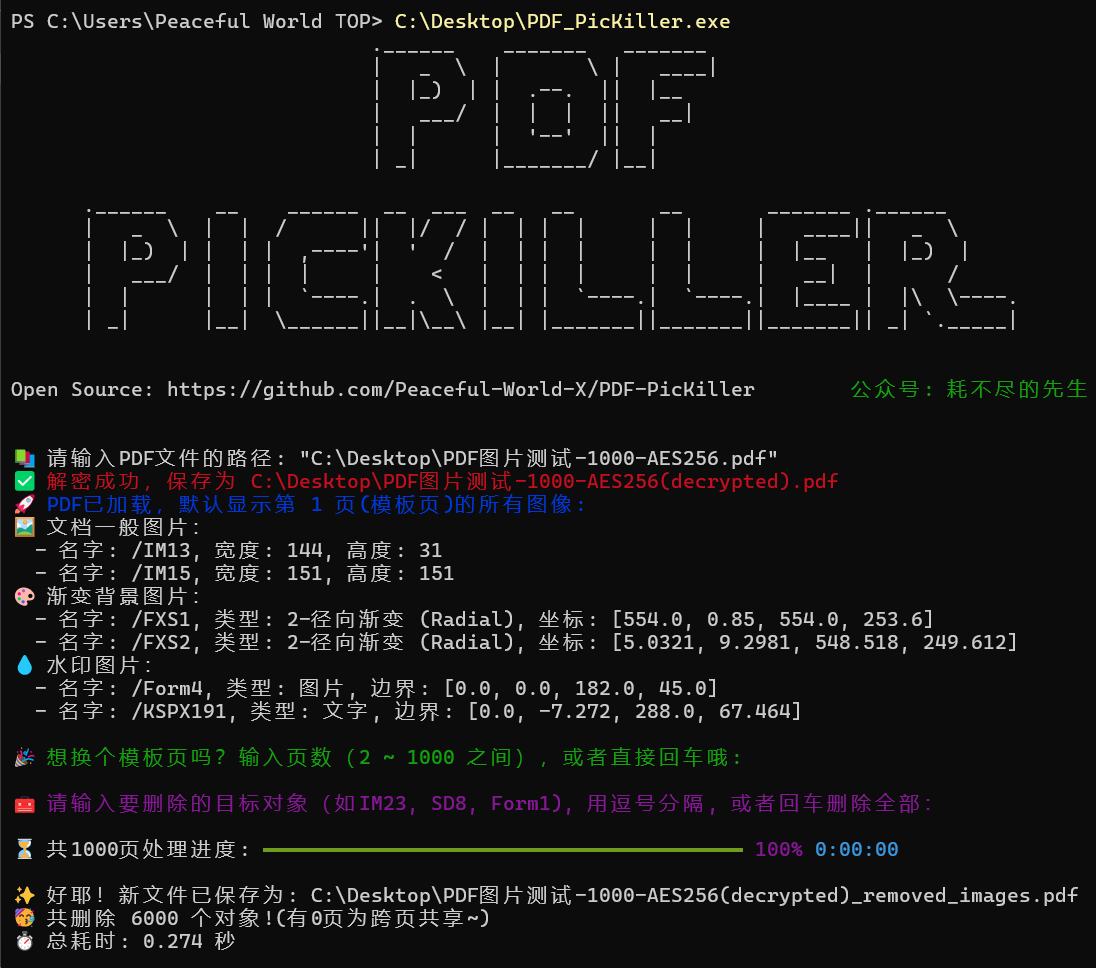
✨ 默认解密:无感处理(破解)加密的 PDF 文件(有打开权限),支持多种加密方式:RC4 128bits, AES 128bits, AES 256bits 等。
✨对象提取:检索模板页(默认第1页),并列出 XObject 图像、Shadings 背景图像和 Form 水印图。
✨批量删除:批量高效的删除列出的图像对象,平均速度为 0.2 秒 处理每 1000 页(每页 5 个删除对象)。
✨交互式命令行:命令行界面,表情样式可爱回复~
🤪 软件使用
- 命令行绿色可执行文件,双击食用~
- 直接拖入PDF文件,或输入文件地址
- 选择模板页(即有要删除图片的页面),默认第一页则回车
- 选择模板页中要删除的对象名,默认删除全部对象则回车
- 已批量删除打开文件路径~
- 随时按下 Ctrl+C 退出软件!
🤪 参数解释
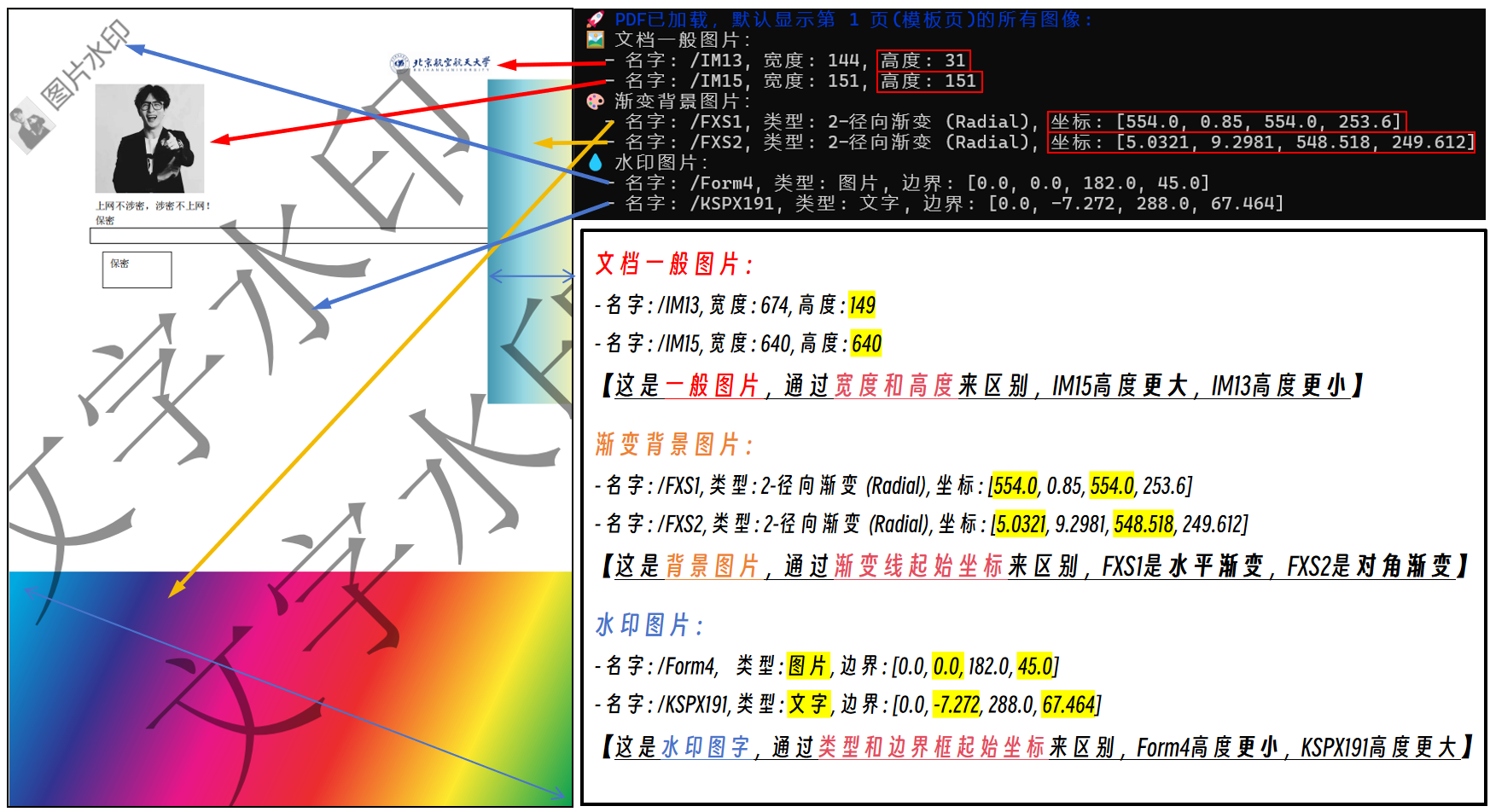
文档一般图片:
- 名字: /IM13, 宽度: 674, 高度: 149
- 名字: /IM15, 宽度: 640, 高度: 640
【这是一般图片,通过宽度和高度来区别,IM15高度更大,IM13高度更小】
渐变背景图片:
- 名字: /FXS1, 类型: 2-径向渐变 (Radial), 坐标: 554.0, 0.85, 554.0, 253.6
- 名字: /FXS2, 类型: 2-径向渐变 (Radial), 坐标: 5.0321, 9.2981, 548.518, 249.612
【这是背景图片,通过渐变线起始坐标来区别,FXS1是水平渐变,FXS2是对角渐变】
水印图片:
- 名字: /Form4, 类型: 图片, 边界: 0.0, 0.0, 182.0, 45.0
- 名字: /KSPX191, 类型: 文字, 边界: 0.0, -7.272, 288.0, 67.464
【这是水印图字,通过类型和边界框起始坐标来区别,Form4高度更小,KSPX191高度更大】
🤪 关键代码
- PDF解密
python
import pikepdf
pdf = pikepdf.open(input_pdf_path)
# 判断是否加密
if not pdf.is_encrypted:
pdf.close()
return input_pdf_path
pdf.close()
# 如果加密,重新用密码打开
pdf = pikepdf.open(input_pdf_path)
output_file = input_pdf_path.replace('.pdf', '(decrypted).pdf')
pdf.save(output_file)
pdf.close()
print(f"\033[31m✅ 解密成功,保存为 {output_file}\033[0m")
return output_file- 识别对象
python
def list_xobjects_and_shadings(page):
result = {
'images': [], # 每个元素是 (name, width, height)
'shadings': [], # 每个元素是 (name, shading_type, coords)
'watermarks': [] # 每个元素是 (name, resources, bbox)
}
try:
resources = page.obj.get('/Resources')
shadings = resources.get('/Shading')
xobjects = resources.get('/XObject')
# 处理XObject图像
if xobjects is None: return result
for name, obj_ref in xobjects.items():
try:
obj = obj_ref.get_object()
subtype = obj.get('/Subtype')
if subtype == '/Image':
width = obj.get('/Width', 'Unknown')
height = obj.get('/Height', 'Unknown')
result['images'].append((name, width, height))
elif subtype == '/Form': # 检查是否为水印 (Form)
# 提取水印的资源和边界框
resources = obj.get('/Resources', 'Unknown')
bbox = obj.get('/BBox', 'Unknown')
bbox_list = [float(coord) for coord in bbox] if bbox else None
result['watermarks'].append((name, resources, bbox_list))
except Exception as e_inner:
print(f"⚠️ 哎呀! 无法读取 {name} 对象: {type(e_inner).__name__}: {e_inner}")
continue
# 处理Shading图像
if shadings is None: return result
for name, obj_ref in shadings.items():
try:
obj = obj_ref.get_object()
obj = obj_ref
shading_type = obj.get('/ShadingType', 'Unknown')
coords = obj.get('/Coords', None)
coords_list = [float(coord) for coord in coords] if coords else None
result['shadings'].append((name, shading_type, coords_list))
except Exception as e_inner:
print(f"⚠️ 哎呀! 无法读取 Shading {name}: {type(e_inner).__name__}: {e_inner}")
continue
except Exception as e:
print(f"⚠️ 糟糕! 列出XObject时出错: {type(e).__name__}: {e}")
return result🤩 项目代码
https://github.com/Peaceful-World-X/PDF-PicKiller
✨欢迎反馈BUG,后续会视情况添加新功能!
(代码是晚上为了处理一个PDF文件临时写的,有问题非常欢迎反馈~)