事务
事务:在多个操作合在一起视为一个整体。要么就不做、要么就做完。
事务应该满足ACID
- A : 原子性。不可分割。
- C : 一致性。追求的目标,在开始到结束没有发生预定外的情况。
- I : 隔离性。不同的事务是独立的。
- D : 持久性。系统崩溃,数据依然要存在。
AID是为了C。
我们之前一直在使用事务
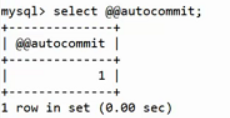
@@autocommit 为1,说明启用了自动提交属性,每个SQL指令都单独看成是一个事务。
在开两个命令窗口对同一个表进行一次操作,不会出现一个进行到一半另一个窗口指令执行的现象,因为每个SQL指令都单独看为一个事务。
让多个SQL指令合成一个事务
begin;/start transaction; 开启事务
写各种指令
commit;事务完成
rollback;事务回滚(放弃该事务前面所作的所有操作)
开启事务后,一定要以事务完成或者事务回滚结束本次事务。用了begin;后面的每单独一条指令不是事务(非原子操作)。
接下来演示事务回滚与事务完成
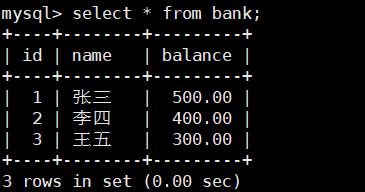
准备一张表:
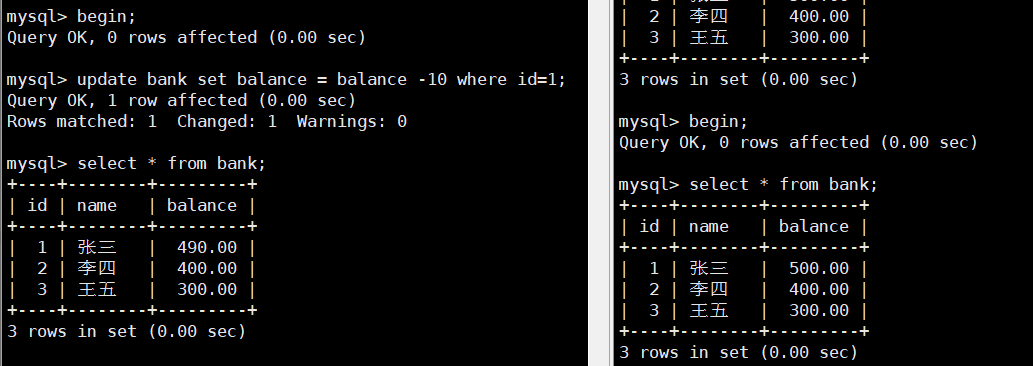
事务回滚
开两个窗口,在左窗口begin;后执行更改数据,右窗口此时查看的是旧数据。
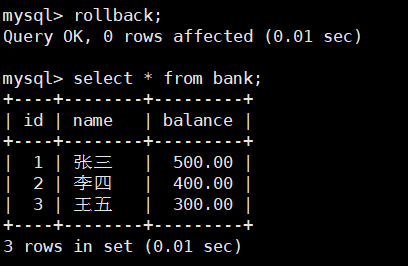
随后左窗口执行rollback;事务回滚到begin;现在数据没有进行更改。
事务完成
同样使用两个窗口
在左窗口执行begin;后,执行数据更改,此时右窗口查看到的依然是旧数据。
左窗口随后执行commit;完成事务,这时候右窗口再进行查看,查看到的为更改完成后的数据。
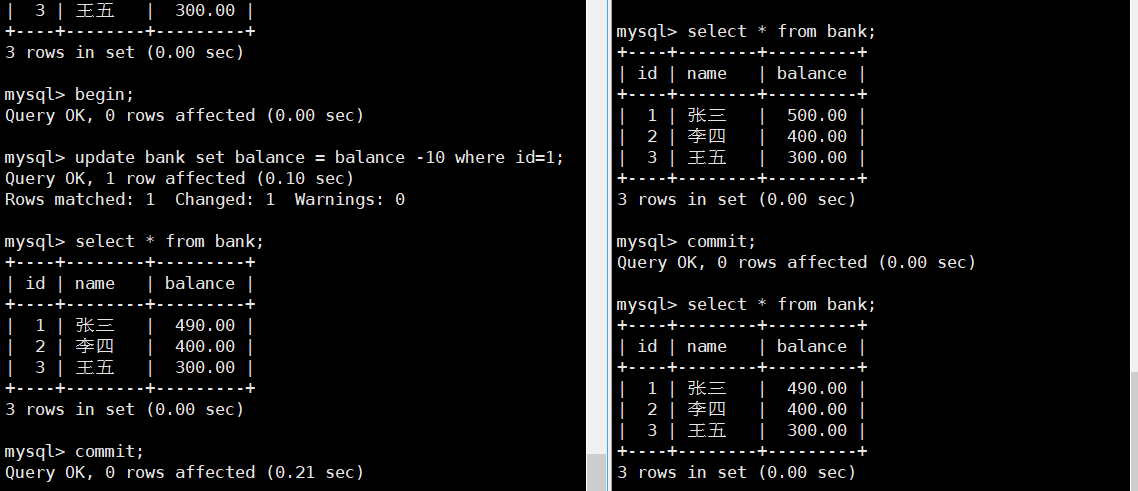
事务的隔离性
不同的事务彼此之间是独立的
多个事务同时执行,有可能会操作同一份数据,会产生竞争条件。若是像进程线程一样采用锁,会导致粒度过大,因为数据库的数据存在磁盘上,对锁的操作时间过长。在数据库领域,访问共享资源(磁盘数据)的时间很长,我们需要对锁机制做更加精细的管理,我们希望尽量让同时运行的时间越长越好。
首先需要做的是对并发带来的问题,按严重程度进行分级。
并发带来的问题
最严重 --> 最不严重问题:脏写 -> 脏读 -> 不可重复读 -> 幻读
脏写
对于t2来说没有实现隔离性,在任何情况下,脏写都是不可接受的。
解决方案:让第二次write操作会阻塞,直到第一次事务结束。

脏读
整个过程顺利完成了,但是在事务进行中某个过程t2读出的数据不满足一致性。 在一致性要求不高的场景下是可以接受的。
解决问题:只能读到已经提交的旧数据,不能读到最新还未提交的数据。
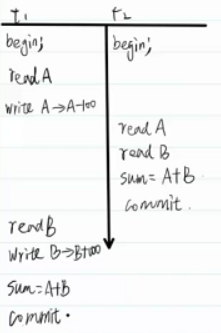
不可重复读
一个事务内部先后两次读取,数据不一致。不会造成严重后果,在t2看起开很奇怪。
解决方案:只要进行读就加锁,不让别人更改。
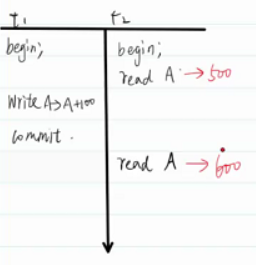
幻读
在一个事务当中连续读取多次数据,第一次读取到的内容在第二次读取中保持不变,但是会读取到其他数据。
隔离级别
为了实现隔离性,我们需要解决并发带来的问题。
- 读未提交(READ UNCOMMITTED)
- 读已提交(READ COMMITTED)
- 可重复读 (REPEATABLE READ)
- 串行化 (SERIALIZABLE)
查看隔离级别(注:每个窗口的隔离级别是不一样的,若要更改,每个窗口都要单独执行更改隔离级别的指令)@@开头的为系统变量。
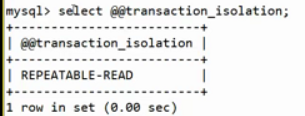
读未提交
更改隔离级别为读未提交
当右一方提交新数据时,其他方对该数据的updata会被阻塞。
解决了脏写问题
没有解决脏读问题

读已提交
更改隔离级别为读已提交
解决了脏读问题,没有解决不可重复读问题

可重复读
这是默认的隔离级别
解决了不可重复读问题,第一次和第二次读到的内容一定是一样的。这是一种比较高的隔离级别。
如果一边insert into ,看上去没有幻读,但是紧接着insert into,触发约束,说明幻读依旧存在。


串行化
等价于mutex
解决了幻读问题,但是可能导致效率低。做任何读或者写都可能卡住。
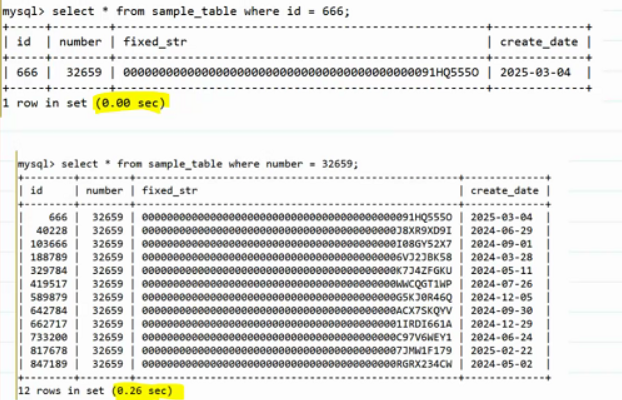
性能
查询条件不一样导致查询时间相差很多倍。
数据在数据库中的存储方式
磁盘IO页大小一般为16KB
可使用select @@innodb_page_size查看
数据在磁盘当中按行存储的,在同一个磁盘页中,数据是有序的,按照主键排序。
特点:
- 数据按行存储
- 多行可以串联成一个链表
- 行是有顺序的,按主键排序的(可以使用二分查找定位,时间复杂度O(logN))
数据存储在多个磁盘页时,需要再分配磁盘页用来存储其他磁盘页的位置。
左侧称为数据IO页,右侧称为索引IO页。
现在数据量进一步增大,一个索引页不够存储,此时需要新的索引页。同时为这一级的索引页再添加索引页。此时的结构称为B+树。
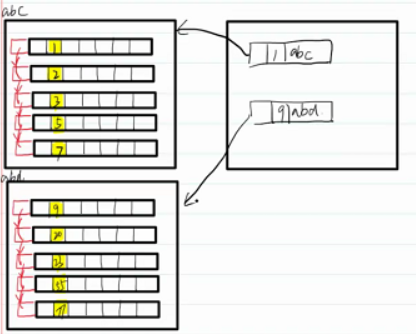
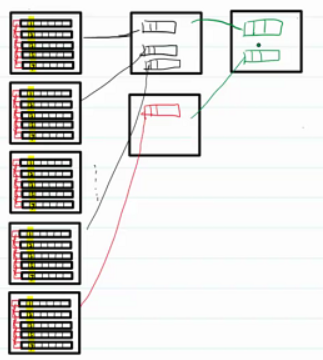
B+树
- 所有的非叶子节点都是索引页,所有的叶子节点都是数据页
- 数据是有序的
- 查询次数(将数据从磁盘加载到内存中的次数)由树的高度决定
主键自带B+树的索引,查找速度很快,因为B+树按照主键排序。按照其他查找,只能通过遍历树来实现,速度很慢。
索引项的大小一般是固定的,一般一个索引页可以放1600个索引项。一个表中的数据最好不要超过两千万,此时树的高度可能增长到四层,导致所有的查询操作变慢。
索引
额外的数据结构,用来做快速查找,可以由以下几种数据结构考虑:
线性表 O(N)
哈希表 O(1)
- 消耗空间大
- 适合做等值查询,不适合做范围查询
排序树 O(logN)
- 二叉排序树 树的高度容易过高
- 多叉排序树 B(B-)树、B+树
LSM tree
- 是一种专门为写入密集型场景优化的分层存储结构,将随机写入转换为顺序写入,显著提升系统写入效率
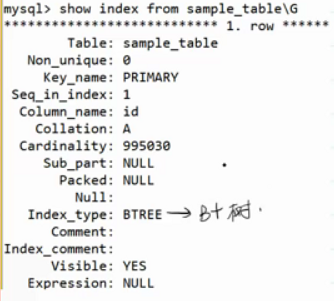
查看当前索引
这里的BTREE实际上是B+树。
新建索引
建立一个索引,number_idx是索引名,(number)是索引的依据
引入索引之后速度变快
新建索引 的叶子节点不存放所有数据,里面只存放新索引和主键,消耗的磁盘空间小。根据新索引找到查找内容的主键,再通过主键在旧索引中查找。
- 聚簇索引:主键是聚簇的,把行的值放入索引结构内部
- 非聚簇索引: 新建的索引,把行的地址或主键放入索引结构内部
mysql只有一个聚簇索引。非聚簇索引要经过两次索引查找擦能找到查询的内容,速度比聚簇索引略慢。

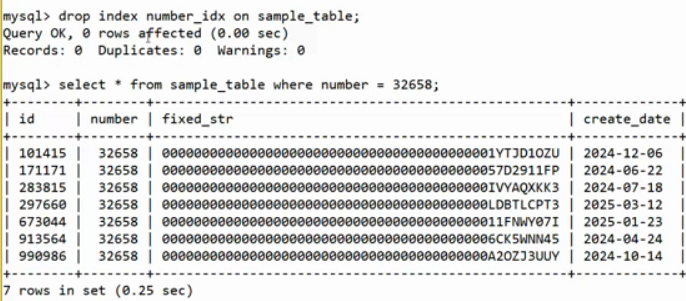
移除索引
移除索引后,查找速度显著变慢
组合索引
索引关注多列。
索引时遵循最左优先原则,如在上例中,先看c3、再看c2、最后看c1。

索引的分类
- 按数据结构分类:哈希/B树/B+树
- 聚簇索引:把行的值放入索引结构内部(主键是聚簇的)
- 非聚簇索引:把行的地址或主键放入索引结构内部
- 单列索引:看一个值
- 组合索引:看多个值,遵循最左优先原则
覆盖索引
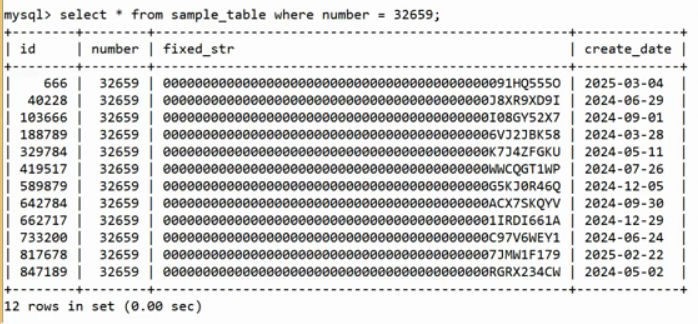
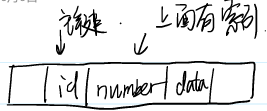
有下图的表,主键为id,number是非聚簇索引
分析下列三种查找效率
- select id,number from ...... where number = 123;
- select data from ...... where number = 123;
- select * from ...... where number = 123;
非聚簇索引中仅存储了行地址、主键以及number值,而第一次查找仅依赖非聚簇索引即可完成,称之为覆盖索引。
三次查找速度对比:
- 第一次操作速度最快
- 第二次、第三次要多做一次回表(到聚簇中去查询)操作
索引的坏处
- 消耗额外的空间
- 查询速度快,但是插入、修改、删除时间变长
- 随着时间的推移,索引的结构会产生碎片,索引是需要维护的
性能考虑
自动增长的整数作为主键比不会重复的随机数做主键要好。因为自动增长的整数,每次会按序进入B+树,即使需要节点合并、分裂操作也在偏向于叶子节点的位置,对B+树更加友好。