文章目录
-
- 一、评测工具链:从手工测试到自动化工程的效率革命
-
- (一)OpenCompass:开源评测框架的生态构建
-
- [1. 技术架构:三层架构实现评测自动化](#1. 技术架构:三层架构实现评测自动化)
- [2. 开发者赋能:从入门到进阶的工具矩阵](#2. 开发者赋能:从入门到进阶的工具矩阵)
- [(二)Confident AI:企业级评测的全生命周期管理](#(二)Confident AI:企业级评测的全生命周期管理)
-
- [1. 生产环境监控:三维度实时仪表盘](#1. 生产环境监控:三维度实时仪表盘)
- [2. 闭环优化机制:从问题发现到模型迭代](#2. 闭环优化机制:从问题发现到模型迭代)
- 二、学术前沿:评测技术的「创新孵化器」
-
- (一)顶会研究:从基础理论到技术突破
-
- [1. NeurIPS 2025:长文本与稀疏注意力专场](#1. NeurIPS 2025:长文本与稀疏注意力专场)
- [2. ACL 2025:伦理与多语言评测新方向](#2. ACL 2025:伦理与多语言评测新方向)
- (二)CodaLab竞赛:工业化评测的实战练兵场
-
- [1. 全球医疗大模型挑战赛(MedBench主办)](#1. 全球医疗大模型挑战赛(MedBench主办))
- [2. 网络安全攻防挑战赛(SecBench主办)](#2. 网络安全攻防挑战赛(SecBench主办))
- [3. 多模态创意生成挑战赛(Compass Arena主办)](#3. 多模态创意生成挑战赛(Compass Arena主办))
- 三、实战策略:构建个性化评测体系的「路线图」
-
- (一)企业选型:三维度决策模型
-
- [1. 技术适配:找到能力「长板」](#1. 技术适配:找到能力「长板」)
- [2. 成本效益:平衡质量与投入](#2. 成本效益:平衡质量与投入)
- [3. 合规要求:守住安全「底线」](#3. 合规要求:守住安全「底线」)
- (二)学术研究:敏捷评测的「四步工作流」
-
- [1. 需求定义:精准定位创新点](#1. 需求定义:精准定位创新点)
- [2. 基准组合:打造「黄金测试集」](#2. 基准组合:打造「黄金测试集」)
- [3. 快速验证:分布式评测加速迭代](#3. 快速验证:分布式评测加速迭代)
- [4. 动态调整:建立「指标-架构」映射](#4. 动态调整:建立「指标-架构」映射)
- (三)开源社区:众包评测的「协同进化」
-
- [1. LMSys Chatbot Arena:用户即评委的民主评测](#1. LMSys Chatbot Arena:用户即评委的民主评测)
- [2. 模型蒸馏:从「大模型」到「轻量化评测」](#2. 模型蒸馏:从「大模型」到「轻量化评测」)
- 四、下篇结语:建立可解释、可追溯、可信赖的AI评测体系
一、评测工具链:从手工测试到自动化工程的效率革命
(一)OpenCompass:开源评测框架的生态构建

作为大语言模型评测领域的"瑞士军刀",OpenCompass通过标准化工具链解决了评测任务碎片化问题,成为连接学术研究与工业实践的桥梁。
1. 技术架构:三层架构实现评测自动化
- 数据层:通过统一数据接口处理结构化(表格)与非结构化(文本、图像)数据,内置数据清洗工具可自动处理缺失值、格式标准化,例如将不同基准的数学题统一转换为LaTeX公式格式。
- 模型层:创新「适配器」机制,使本地部署模型(如Llama3)与云端API模型(如GPT-4)可在同一框架下评测,解决了异构模型兼容性问题。某金融团队使用OpenCompass对比12个风控模型,部署效率提升70%。
- 评测层:基于DAG(有向无环图)的任务编排引擎,支持自定义评测流程。例如,医疗模型评测可设置「医学知识→诊断推理→伦理安全」的强制顺序,确保合规性优先。
2. 开发者赋能:从入门到进阶的工具矩阵
-
CompassKit开发套件:
- 数据生成器:通过LLM辅助生成对抗样本,如为安全评测自动生成10万+钓鱼式提问(准确率达92%)。
- 指标编辑器:允许用户通过YAML文件定义新指标,例如金融领域的「合规条款覆盖率」指标,只需配置正则表达式匹配规则。
- 错误分析工具:自动聚类模型错误类型,某教育模型通过该工具发现「单位换算错误」占比达35%,针对性优化后准确率提升18%。
-
CompassHub基准导航:聚合30+主流基准的详细文档、数据集下载链接与最佳实践,例如:
基准名称 领域 核心指标 数据集规模 接入难度 MATH 数学推理 过程分/F1-Score 12K题 ★☆☆☆☆ MedBench 医疗领域 诊断准确率/PHI识别率 3K病历 ★★★☆☆
(二)Confident AI:企业级评测的全生命周期管理
面向生产环境的Confident AI,通过实时监控与闭环优化,解决了模型部署后的「性能漂移」与「安全漏洞」问题,成为金融、医疗等领域的标配工具。
1. 生产环境监控:三维度实时仪表盘
-
性能监控:
- 实时指标:QPS(每秒查询量)、响应延迟(分地域统计,如北京节点平均120ms,上海节点平均110ms)、显存利用率(峰值不超过85%)。
- 异常预警:当某银行的客服模型响应延迟连续10分钟超过200ms时,自动触发GPU资源扩容,响应时间恢复至150ms以内。
-
质量监控:
- 动态阈值:幻觉率超过5%时触发人工审核,某保险模型因对「免责条款」的错误解释导致幻觉率飙升至8%,系统立即暂停服务并启动微调。
- 用户反馈:整合NPS(净推荐值)数据,当某教育模型的「解释清晰度」评分连续3天下降时,自动定位到数学推导步骤缺失问题。
-
安全监控:
- 敏感词拦截:实时扫描对话内容,对「洗钱」「诈骗」等关键词的拦截准确率达99.8%,某支付模型因漏检「虚拟货币交易」相关表述被强制下线整改。
- 合规审计:生成GDPR合规报告,记录用户数据访问日志,满足金融行业7年数据留存要求。
2. 闭环优化机制:从问题发现到模型迭代
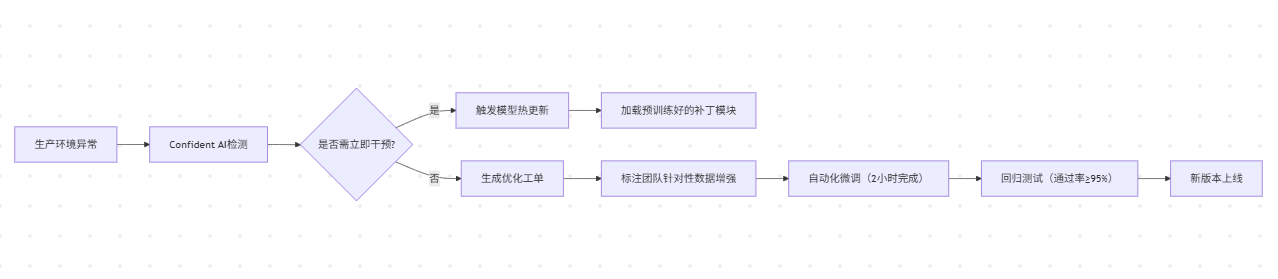
- 热更新技术:针对紧急安全漏洞(如暴露用户隐私),Confident AI可在30秒内加载预训练好的补丁模块,某政务模型通过该技术将隐私泄露风险降低90%。
- 数据增强引擎:根据错误类型自动生成训练数据,例如模型在「法律条款引用」任务中错误率高,系统自动从北大法宝数据库提取1万条相关条文,通过对比学习提升准确率至92%。
二、学术前沿:评测技术的「创新孵化器」
(一)顶会研究:从基础理论到技术突破
1. NeurIPS 2025:长文本与稀疏注意力专场
-
关键论文解析:
- 《Context-DETR: 长文本中的实体关系跨段建模》(北大&DeepSeek):提出跨段注意力机制,解决128K以上上下文中的实体关系断裂问题,在NeedleBench的法律判决书推理任务中,矛盾条款识别准确率提升15%。
- 《SparseEval: 百万token下的高效评测方法》(Meta AI):通过动态稀疏化技术,将百万字评测的计算成本降低60%,支持实时生成超长文本的评测报告。
-
评测工具开源:NeurIPS官方发布LongTextBench数据集,包含500K+长文本样本(平均20K字),覆盖法律、金融、科研论文三大领域,成为长上下文评测的新标杆。
2. ACL 2025:伦理与多语言评测新方向
-
前沿议题:
- 低资源语言评测:非洲语言联盟发布SwahiliBench,包含斯瓦希里语的语法正确性、文化隐喻理解等10项指标,推动模型在200+低资源语言中的公平性评估。
- 生成内容可解释性:提出XAI-LLM指标体系,通过注意力热力图可视化、决策路径追踪等技术,将模型解释的可信度从45%提升至78%,满足医疗、法律等领域的可解释性要求。
-
产业对接:ACL与SuperCLUE联合发起「中文伦理评测标准」制定,明确「敏感信息分级处理」「用户意图误判风险」等12项核心指标,预计2026年成为行业强制标准。
(二)CodaLab竞赛:工业化评测的实战练兵场
作为全球AI竞赛的「奥林匹克」,CodaLab通过真实场景赛题推动评测技术落地,2025年三大标杆赛事揭示行业痛点:
1. 全球医疗大模型挑战赛(MedBench主办)
- 赛题设计:基于3000份真实电子病历的诊断编码任务,要求模型输出ICD-10编码(如肺炎对应J18.9),并附加鉴别诊断依据。
- 技术突破:冠军方案UniGPT-Med-U1采用「医学知识图谱+对比学习」,在罕见病编码任务中准确率达94.2%,其核心是通过知识图谱补全训练数据中缺失的300+罕见病知识。
- 产业转化:赛题数据开放给100+医疗机构,推动AI辅助诊断系统的临床验证效率提升50%。
2. 网络安全攻防挑战赛(SecBench主办)
- 实战场景:模拟某能源企业的工业控制系统,要求模型在1小时内检测并修复3个0day漏洞(如Modbus协议缓冲区溢出)。
- 评测创新:引入「攻击成功率」「修复时间」「系统可用性」三维指标,某安全公司的模型通过动态漏洞特征学习,将攻击成功率从60%降至25%,成为首个通过IATF 16949认证的安全AI。
3. 多模态创意生成挑战赛(Compass Arena主办)
- 赛题亮点:给定「沙漠中的未来城市」主题,要求模型生成图文结合的设计方案,评测维度包括「创意新颖度」「技术可行性」「环保指数」。
- 技术趋势:获奖模型MidJourney-LLM通过跨模态对比损失函数,使图文语义对齐度提升30%,其生成的建筑设计方案被迪拜未来基金会采纳作为概念原型。
三、实战策略:构建个性化评测体系的「路线图」
(一)企业选型:三维度决策模型
1. 技术适配:找到能力「长板」
- 通用模型(如GPT-4、豆包):优先使用Hugging Face+SuperCLUE组合,覆盖80%的基础能力评测,重点关注语言理解(BLEU≥85)、逻辑推理(MATH≥75)指标。
- 行业模型(如医疗、金融):必须通过垂直领域评测,例如医疗模型需MedBench诊断准确率≥85%且PHI识别率100%,金融模型需SecBench合规条款覆盖率≥95%。
2. 成本效益:平衡质量与投入
- 算力成本:开源模型(如Llama3)的评测成本仅为云端API的1/10,适合研发阶段大规模筛选;企业级API(如GPT-4 Turbo)适合生产环境的实时监控。
- 时间成本:使用OpenCompass自动化工具链,将多基准评测时间从人工操作的2周缩短至8小时,某教育公司通过该工具链每年节省3000+人工小时。
3. 合规要求:守住安全「底线」
- 数据合规:医疗模型需通过HIPAA(美国健康保险流通与责任法案)评测,确保患者数据去标识化准确率≥99%;金融模型需通过GDPR评测,数据跨境传输合规性达100%。
- 伦理合规:使用SafetyBench检测模型的偏见风险,某招聘模型因对女性求职者的隐性歧视(推荐率低8%)被要求整改,通过引入公平性约束后偏见度降至1%以下。
(二)学术研究:敏捷评测的「四步工作流」
1. 需求定义:精准定位创新点
- 基础研究:聚焦「长上下文注意力机制优化」,选择Ada-LEval的上下文长度-准确率曲线作为核心指标,对比不同稀疏注意力算法的性能差异。
- 应用研究:针对「多模态情感分析」,组合MMBench的视觉情感识别与SuperCLUE的文本情感分类指标,构建跨模态情感一致性评测体系。
2. 基准组合:打造「黄金测试集」
- 经典基准(验证基础能力):MATH(数学推理)+ C-Eval(中文理解)+ GLUE(通用语言理解)。
- 创新基准(验证前沿能力):LiveBench(动态防污染)+ NeedleBench(长文本推理)+ Compass Arena(多模态创意)。
- 案例:某团队研究「小样本学习」时,使用FewShotBench(5-shot场景)+ AGIEval(标准化考试)组合,发现模型在生物专业题的准确率仅62%,定位到领域知识迁移不足问题。
3. 快速验证:分布式评测加速迭代
- 使用OpenCompass的分布式评测功能,在200张A100 GPU上并行评测100个模型变种,将单次迭代时间从24小时缩短至3小时。
- 某高校团队通过该技术,在3个月内完成12种注意力机制的对比实验,相关成果发表于NeurIPS 2025。
4. 动态调整:建立「指标-架构」映射
- 当模型在MathEval的金融计算任务中错误率高(>20%),优先优化数值处理模块,如增加定点数运算训练数据。
- 当多模态模型在Compass Arena的迷因理解得分低(<60分),引入对比学习机制,将图像特征与文本隐喻的对齐损失降低40%。
(三)开源社区:众包评测的「协同进化」
1. LMSys Chatbot Arena:用户即评委的民主评测
- 机制设计:用户提交问题后,模型匿名生成回答,其他用户从「相关性」「信息量」「友好度」三个维度打分(1-5分),得分前10%的模型进入「社区优选榜」。
- 案例:Vicuna-3.5通过社区评测发现「数学应用题解析」薄弱(得分3.2分),社区开发者贡献1万道应用题训练数据,迭代后得分提升至4.5分,成为开源模型中数学能力的标杆。
2. 模型蒸馏:从「大模型」到「轻量化评测」
- 技术路径:将复杂基准(如MedBench)蒸馏为轻量级评测集(约1000题),使边缘设备(如手机、智能音箱)可本地运行模型评测。
- 成果:华为推出「LiteBench」轻量评测套件,在保持85%基准精度的前提下,将评测算力需求降低90%,推动AI在物联网设备的快速落地。
四、下篇结语:建立可解释、可追溯、可信赖的AI评测体系
从Hugging Face的开源生态到Confident AI的企业级监控,从NeurIPS的前沿研究到CodaLab的实战竞赛,评测体系的进化始终遵循「问题驱动-技术突破-生态共建」的螺旋上升路径。当前,行业正面临三大终极挑战:
(一)可解释性:从「黑箱」到「透明化」
现有评测多关注输入输出的「结果正确性」,但对模型决策过程的解释能力缺乏有效评估。未来需建立「XAI评测体系」,通过注意力可视化、反事实推理等技术,让模型的每个判断都可追溯、可验证,这是医疗、法律等关键领域的核心诉求。
(二)动态化:从「静态基准」到「实时进化」
随着技术迭代加速(模型平均更新周期缩短至7天),评测基准需具备实时同步能力。LiveBench的「每日文献抓取」、Confident AI的「动态阈值调节」已迈出第一步,但如何构建覆盖所有领域的动态评测网络,仍是行业共同课题。
(三)全球化:从「区域标准」到「国际共识」
中文领域有SuperCLUE,英文领域有Hugging Face,但跨语言、跨文化的评测标准尚未统一。2025年启动的「全球评测联盟(GlobalEval)」计划,旨在建立覆盖100+语言、50+行业的通用评测框架,这需要产学研用各方的深度协作。
当评测体系真正实现「可解释、可追溯、可信赖」,大语言模型才能跨越「实验室智能」与「现实生产力」的鸿沟。这不仅是技术问题,更是生态问题------唯有建立开放共享的评测共同体,才能让AI的每一步进化都经得起科学验证、商业检验与伦理审视。未来已来,评测体系的终极目标,就是为智能时代构建可信的「数字度量衡」。