📄 本地 Windows 部署 Logstash 连接本地 Elasticsearch 指南
✅ 目标
- 在本地 Windows 上安装并运行 Logstash
- 配置 Logstash 将数据发送至本地 Elasticsearch
- 测试数据采集与 ES 存储流程
🧰 前提条件
| 软件 | 版本要求 | 安装说明 |
|---|---|---|
| Java | 17+ | Oracle JDK 下载 或 OpenJDK |
| Elasticsearch | 8.x / 7.x | Elasticsearch 下载 |
| Logstash | 与 ES 版本一致 | Logstash 下载 |
💡 确保 Elasticsearch 已成功启动,并监听
http://localhost:9200
📦 步骤一:下载与解压
- 下载 Logstash:
- 访问 Logstash 下载页面
- 选择 ZIP 包(如
logstash-8.x.x.zip)
-
解压到本地路径,例如:
C:\elk\logstash-8.x.x
⚙️ 步骤二:配置 Logstash
1. 创建配置文件
在 C:\elk\logstash-8.x.x\config 目录下新建一个配置文件 logstash-to-es.conf,内容如下:
conf
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{DATA:thread}\] %{LOGLEVEL:level} %{DATA:logger} - %{GREEDYDATA:message}" }
}
}
output {
elasticsearch {
hosts => ["https://localhost:9200"]
index => "springboot-logs-%{+YYYY.MM.dd}"
ssl_enabled => true
ssl_verification_mode => "full"
ssl_certificate_authorities => ["D:/dev/dev2025/EC0601/elasticsearch-9.0.1/config/certs/http_ca.crt"]
# 使用 API Key 认证 id:api_key
api_key => "V6VUSpcBUPesLBBNVAlH:O7l1zeyOwQFfy9w5Af_JTA"
}
stdout {
codec => rubydebug
}
}stdin: 从控制台输入日志elasticsearch: 输出到本地 ES,索引按天分割stdout: 控制台输出处理结果(调试用)
Elasticsearch API Key 权限机制说明
Elasticsearch 的 API key 可以绑定一组权限(privileges),这些权限可以包括:
- 集群权限(Cluster privileges)
- 索引权限(Index privileges)
- 应用程序权限(Application privileges)
API key 的权限不能直接继承用户的角色权限,但可以通过创建带有特定权限的 API key 实现类似效果。
如何给 API key 添加权限
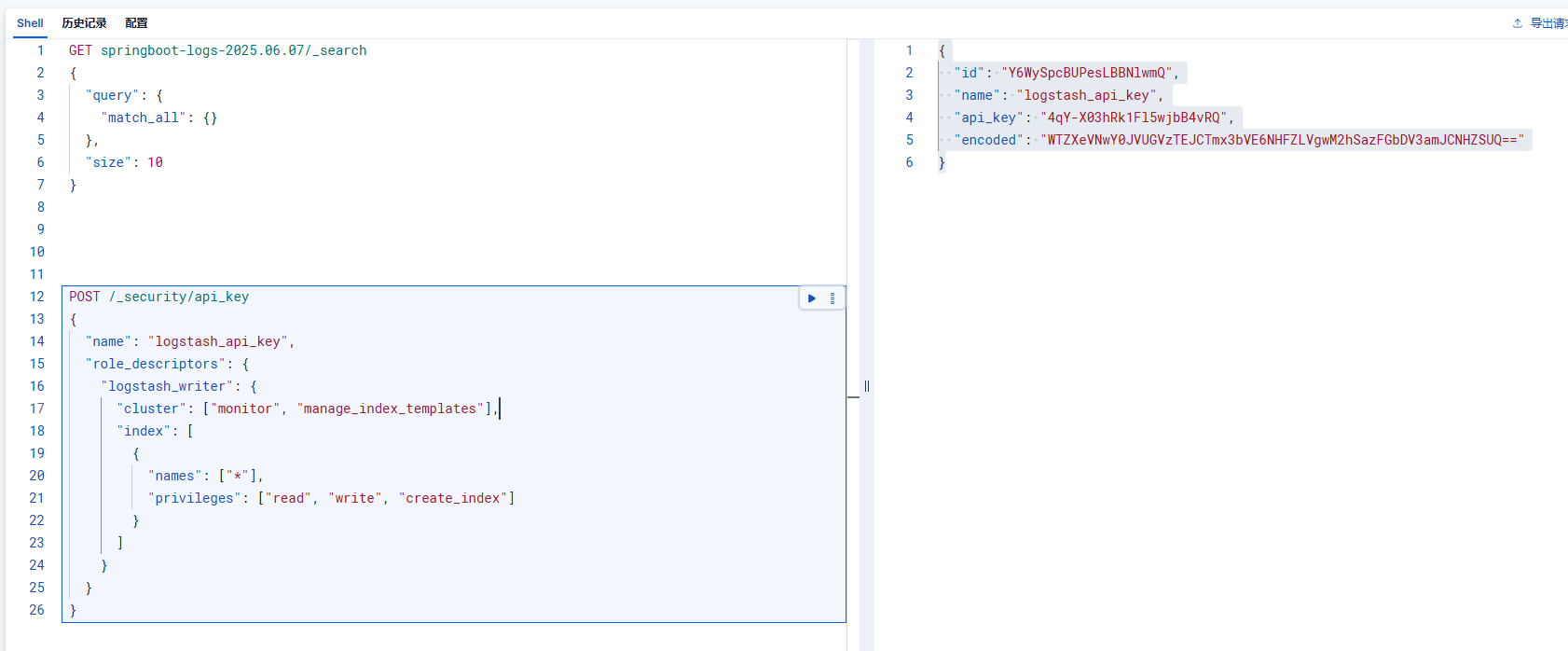
这里通过 REST API 创建带权限的 API Key
你可以使用如下请求来创建一个具有特定权限的 API key:
bash
POST /_security/api_key
{
"name": "logstash_api_key",
"role_descriptors": {
"logstash_writer": {
"cluster": ["monitor", "manage_index_templates"],
"index": [
{
"names": ["*"],
"privileges": ["read", "write", "create_index"]
}
]
}
}
}
🧾 参数说明:
| 字段 | 含义 |
|---|---|
name |
API key 的名称,方便识别 |
role_descriptors |
定义该 API key 所拥有的权限描述符 |
cluster |
集群级别权限,如 monitor, manage_index_templates |
index.names |
索引模式,如 "logs-*" 或 "*" |
index.privileges |
索引级别的权限,如 read, write, create_index |
⚠️ 注意:Elasticsearch 7.10+ 支持
role_descriptors方式创建 API key 权限。
▶️ 步骤三:启动 Logstash
打开命令提示符(CMD),进入 Logstash 根目录并执行:
bash
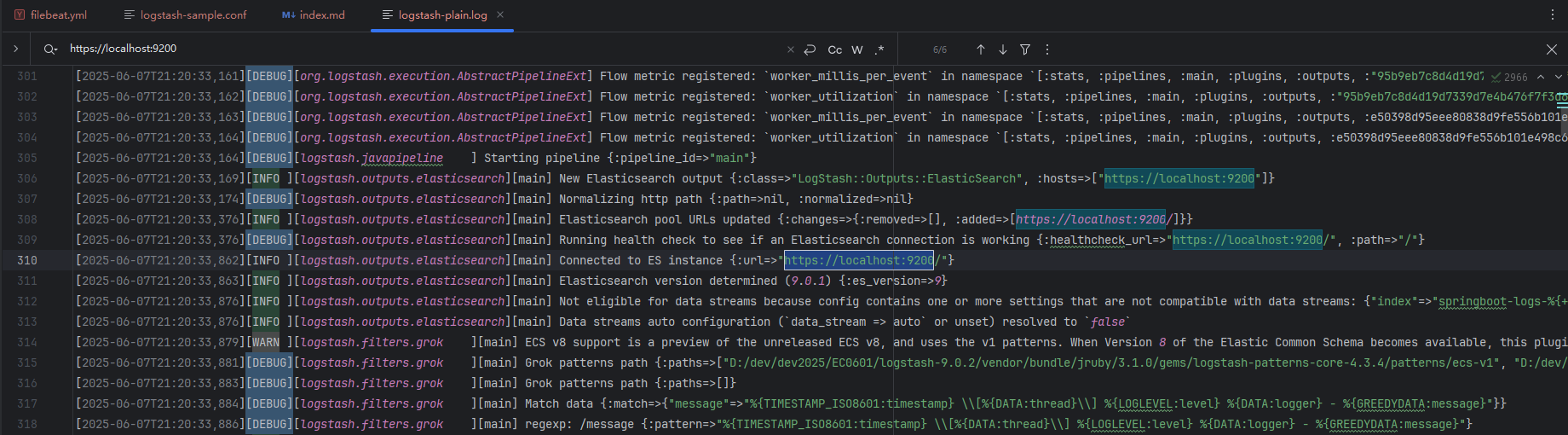
bin/logstash.bat -f config/logstash-sample.conf --log.level debug logstash-9.0.2/logs/logstash-plain.log 注意以下连接es的日志消息,确认output配置是否有问题
📄 Windows 本地部署 Filebeat 连接 Logstash 操作指南
✅ 一、目标
本指南旨在帮助用户在 本地 Windows 系统 上完成以下操作:
- 安装并配置 Filebeat
- 将 Filebeat 采集的日志发送到 本地运行的 Logstash
- 实现日志采集 → 发送 → 接收的完整流程
🧰 二、环境要求
| 组件 | 版本建议 | 下载地址 |
|---|---|---|
| 操作系统 | Windows 10 / Windows Server(支持 Win7 及以上) | - |
| Logstash | 与 Filebeat 版本一致(如 9.0.2) | Elastic 官网 |
| Filebeat | 与 Logstash 版本一致(如 9.0.2) | Elastic 官网 |
⚠️ 建议使用相同版本的 Elastic Stack 组件以避免兼容性问题。
🔧 三、部署步骤
安装 Filebeat
-
下载适用于 Windows 的 ZIP 包,如:
filebeat-9.0.2-windows-x86_64.zip -
解压到本地目录,如:
D:\filebeat
配置 Filebeat
编辑 D:\filebeat\filebeat.yml 文件,进行如下配置:
📁 设置日志输入路径(inputs)
yaml
filebeat.inputs:
- type: filestream
paths:
- D:/dev/dev2025/EC0601/logs/springboot-ai-rag-demo.log
enabled: true
fields:
log_type: springboot-app
app_name: springboot-ai-rag-demo
fields_under_root: true
multiline:
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
output.logstash:
hosts: ["localhost:5044"]
#output.elasticsearch:
# hosts: [ "localhost:9200" ]
# username: "elastic"
# password: "elastic"
# 启用 HTTP 状态接口
http.enabled: true
http.port: 5066
logging.level: debug
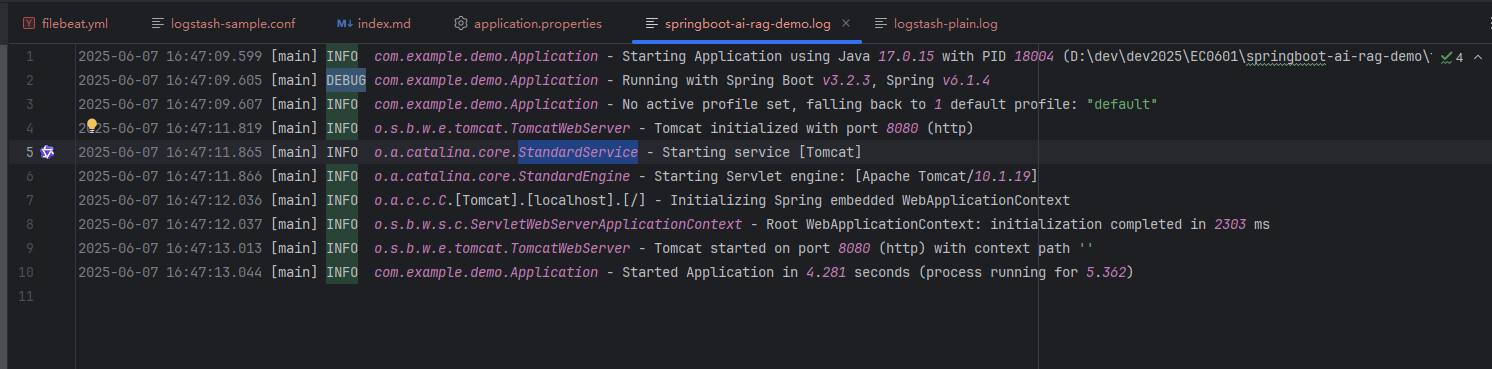
logging.selectors: ["*"]日志内容为spirngboot应用日志:
可以在项目中配置将日志输出到 D:\dev\dev2025\EC0601\logs\springboot-ai-rag-demo.log 文件中。
logging.file.path=D:/dev/dev2025/EC0601/logs
logging.file.name=${logging.file.path}/springboot-ai-rag-demo.log
logging.pattern.file=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
logging.level.root=INFO
logging.level.com.example.demo=DEBUG 
启动 Filebeat
powershell
.\filebeat.exe -e🔍 四、验证数据是否到达 Logstash
方法一:查看 Logstash 相关日志, 确认 Filebeat 是否成功连接 Logstash。
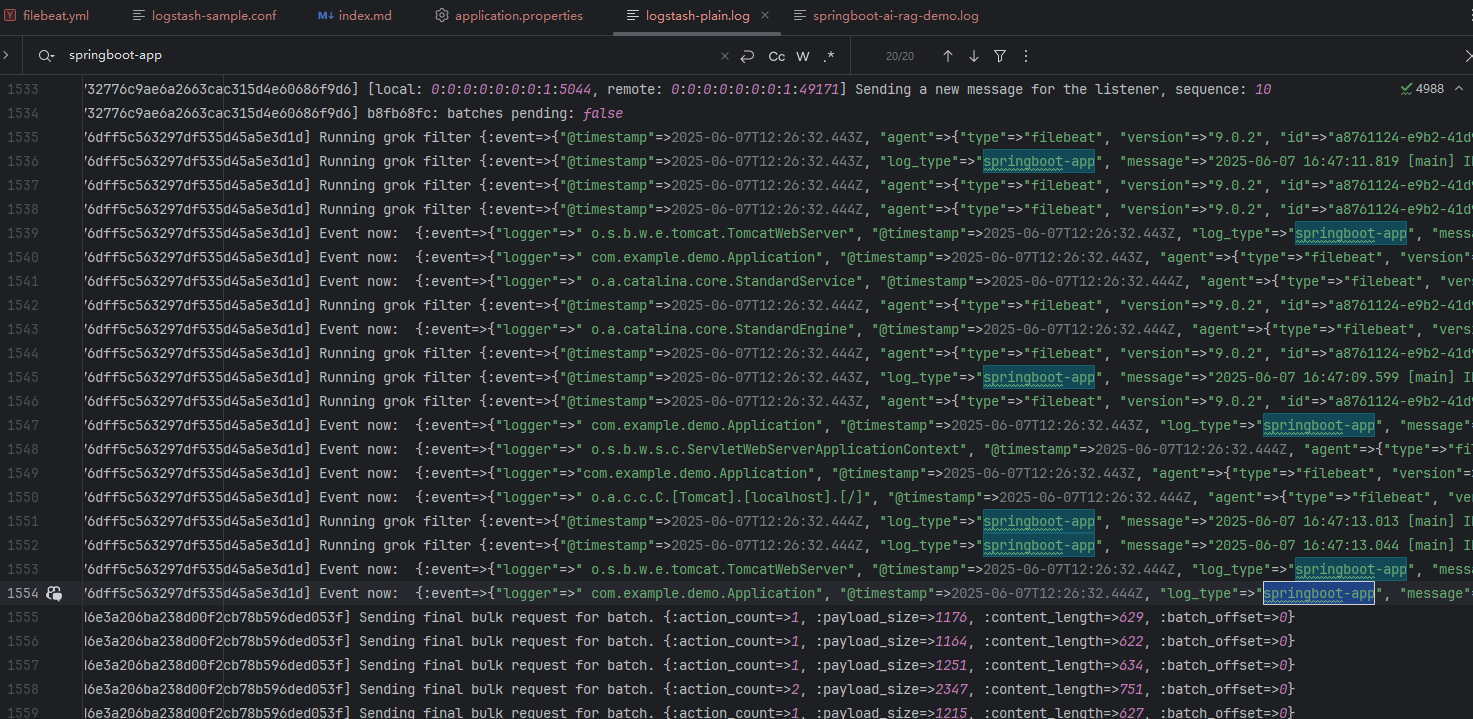
方法二:使用 Kibana 查看索引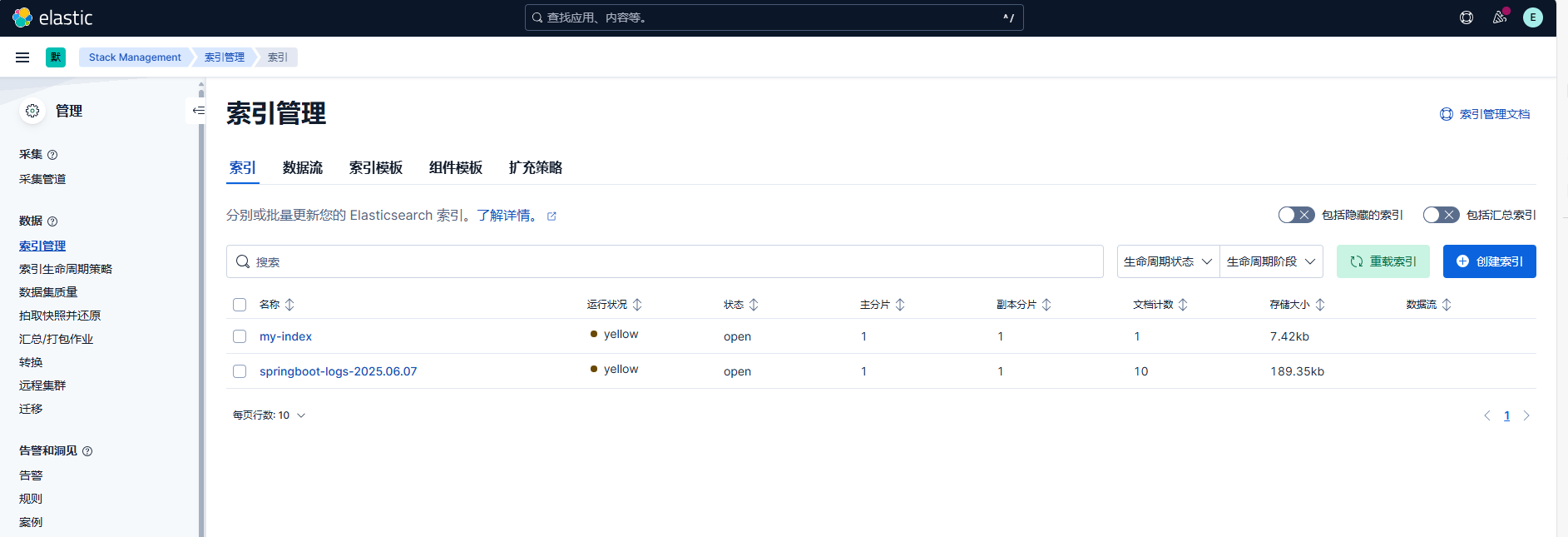
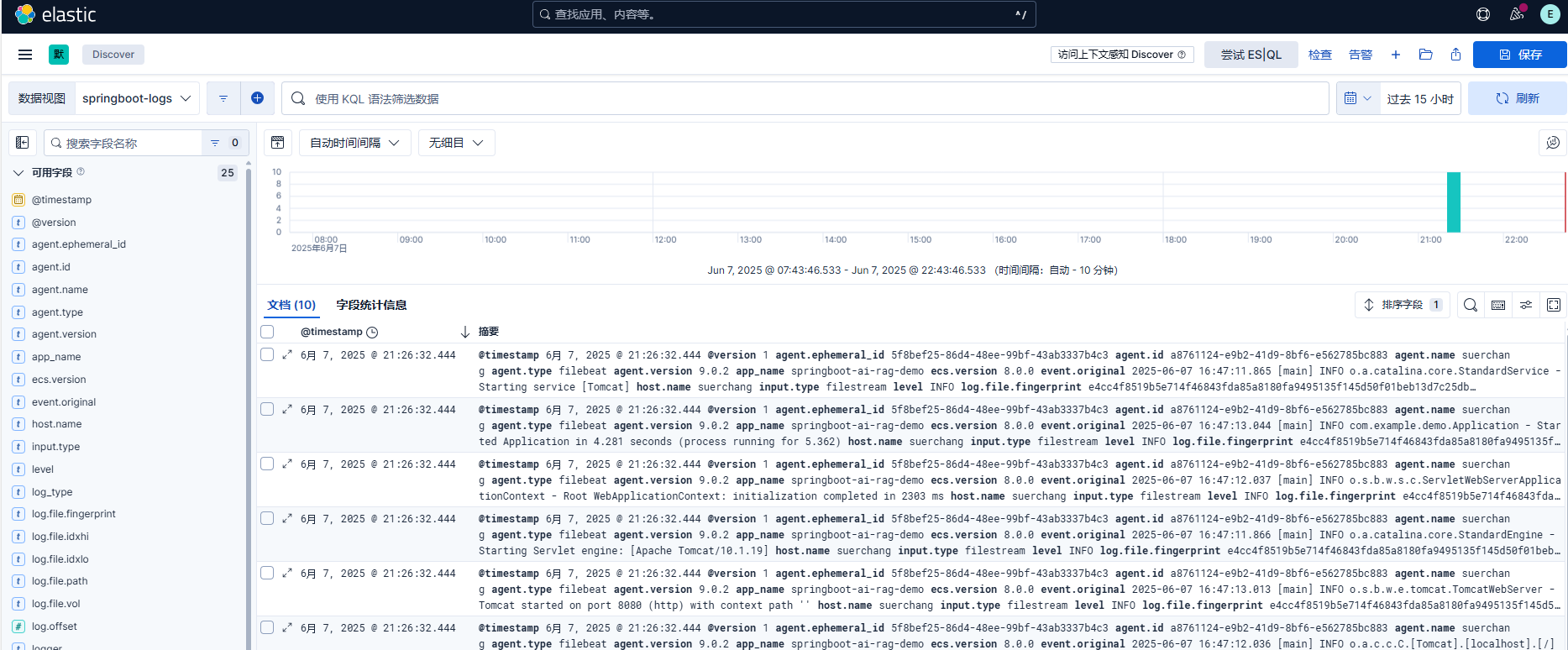
🧪 五、常见问题排查
| 问题现象 | 可能原因 | 解决方法 |
|---|---|---|
| Filebeat 报错无法连接 Logstash | Logstash 未启动或端口未监听 | 确认 Logstash 是否运行,使用 `netstat -ano |
| Filebeat 不采集日志 | 路径错误或权限不足 | 检查 paths 配置;尝试以管理员身份运行 Filebeat |
| Logstash 收不到数据 | 数据格式不匹配 | 检查 Logstash 的 grok 过滤规则是否适配日志格式 |
| Filebeat 卡住不动 | 日志文件过大或编码问题 | 尝试小文件测试;检查日志编码是否为 UTF-8 |
📌 六、总结
后续可以根据需要扩展功能,例如:
- 添加多输入源(如 JSON、CSV)
- 使用 TLS 加密通信
- 输出到远程 Elasticsearch
- 配置 为 Windows 服务自启动
- 把es作为ai-rag服务的向量数据库,使用向量检索等