介绍
Supersonic是腾讯音乐开源的融合了Chat BI和Headless BI的新一代数据分析平台,可以通过自然语言来分析数据。(项目地址在文章末尾)
Headless BI
在传统的BI系统中,数据处理、分析逻辑和用户界面 是紧密耦合在一起的。而Headless BI则采用了"无头"的设计理念,只提供数据处理和分析的核心功能,通过API接口对外提供服务,不包含预定义的用户界面。
Chat BI
在大模型时代,Chat BI的核心主要是通过大模型将自然语言转化为SQL(Text2SQL),以此降低数据分析门槛。
优点
Supersonic使用Headeless BI构建数据模型,更加便于大模型理解我们的数据集,提高了Text2SQL的准确度。
使用效果
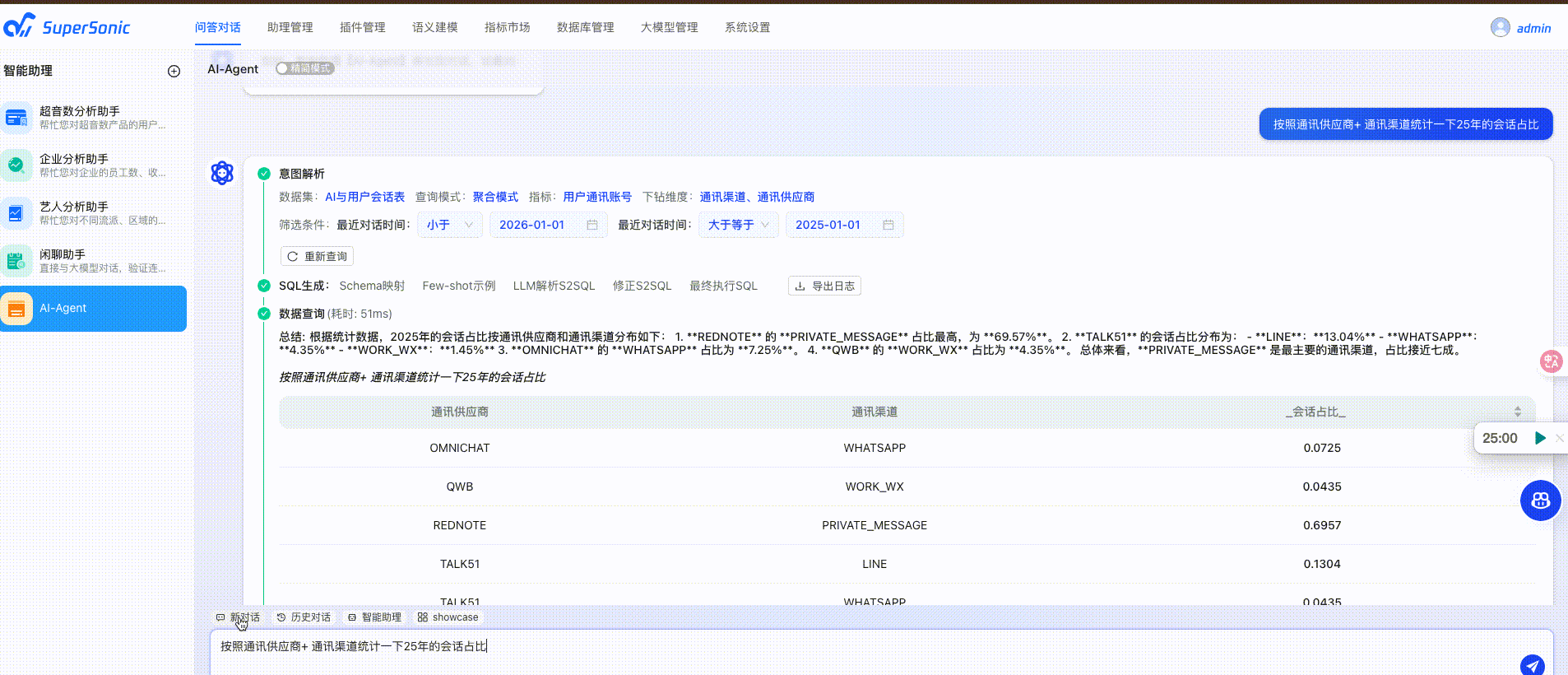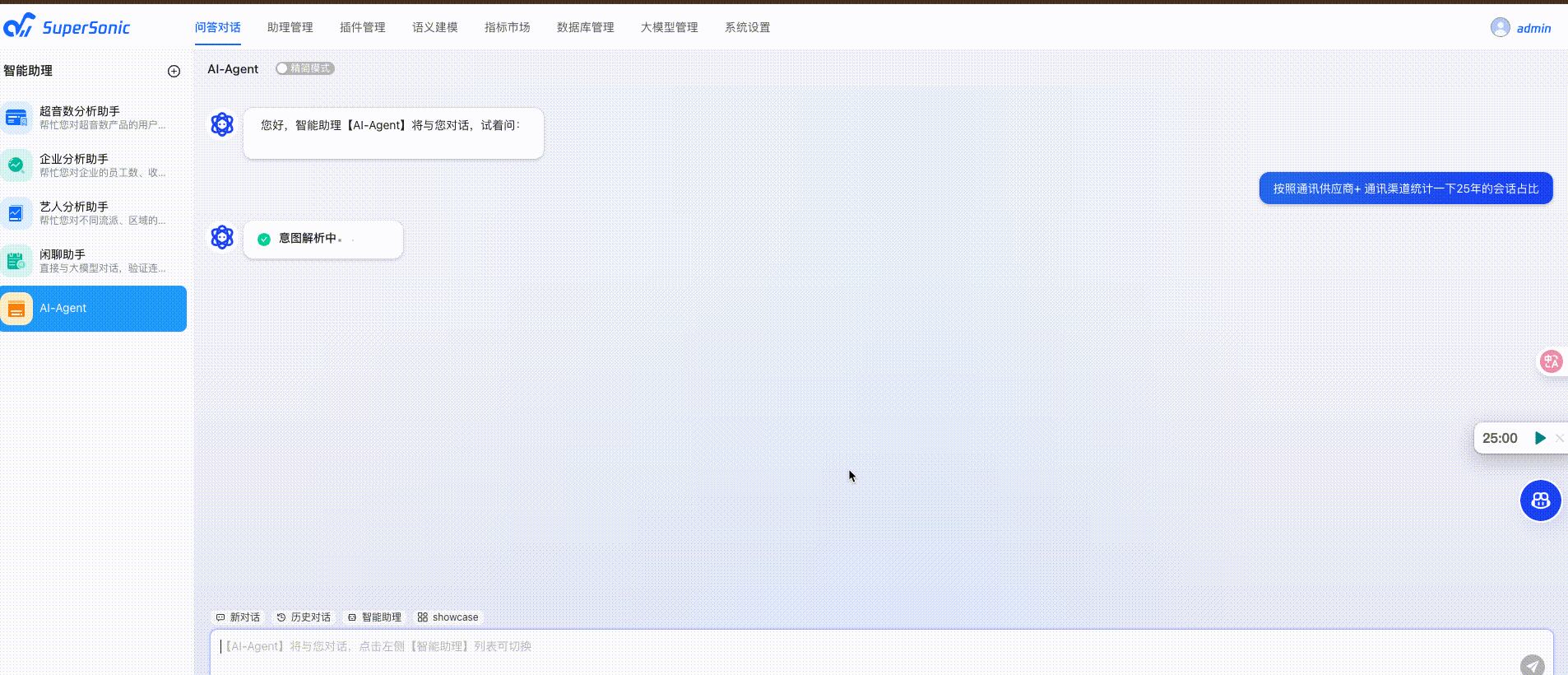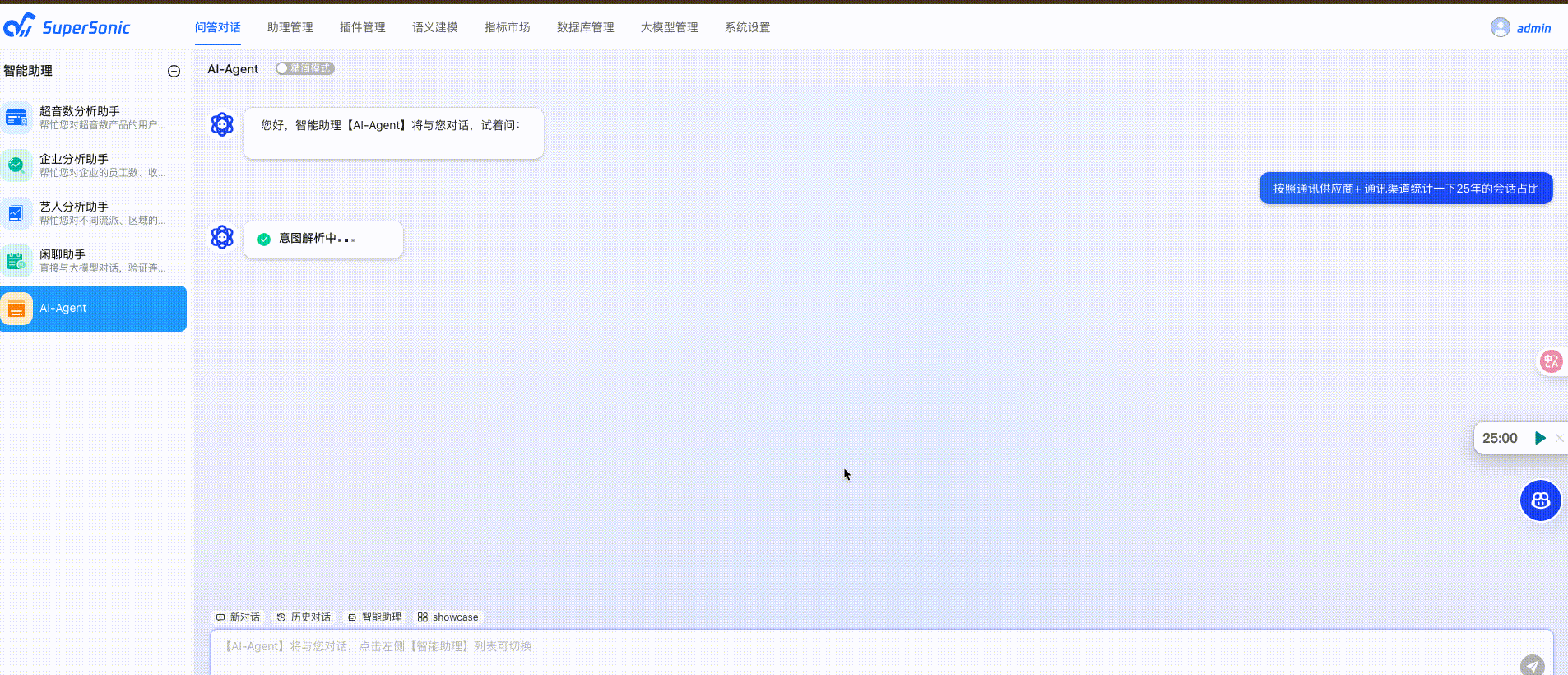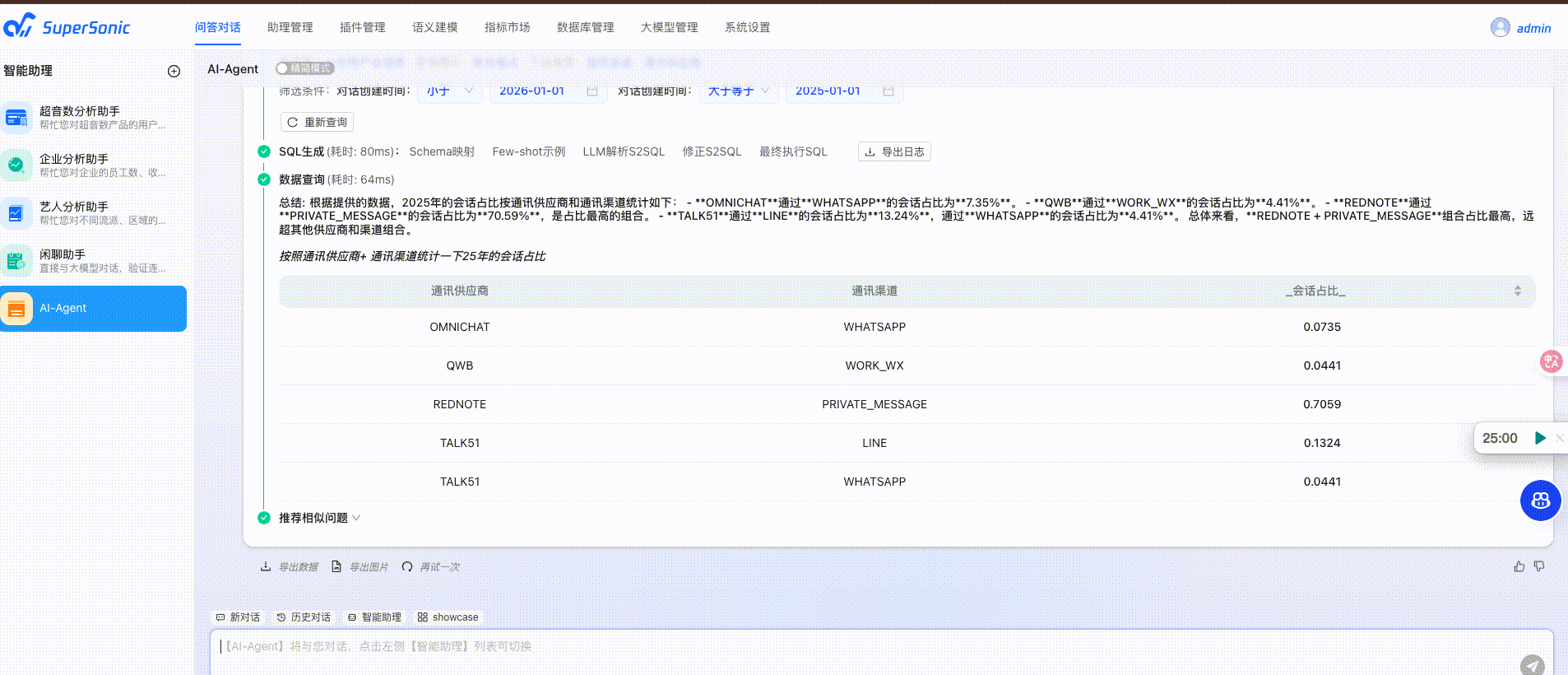
Docker部署
下载docker-compose.yml
shell
wget https://raw.githubusercontent.com/tencentmusic/supersonic/master/docker/docker-compose.yml启动
shell
docker-compose up -d使用
在开始使用前我们需要先了解几个核心的概念
概念
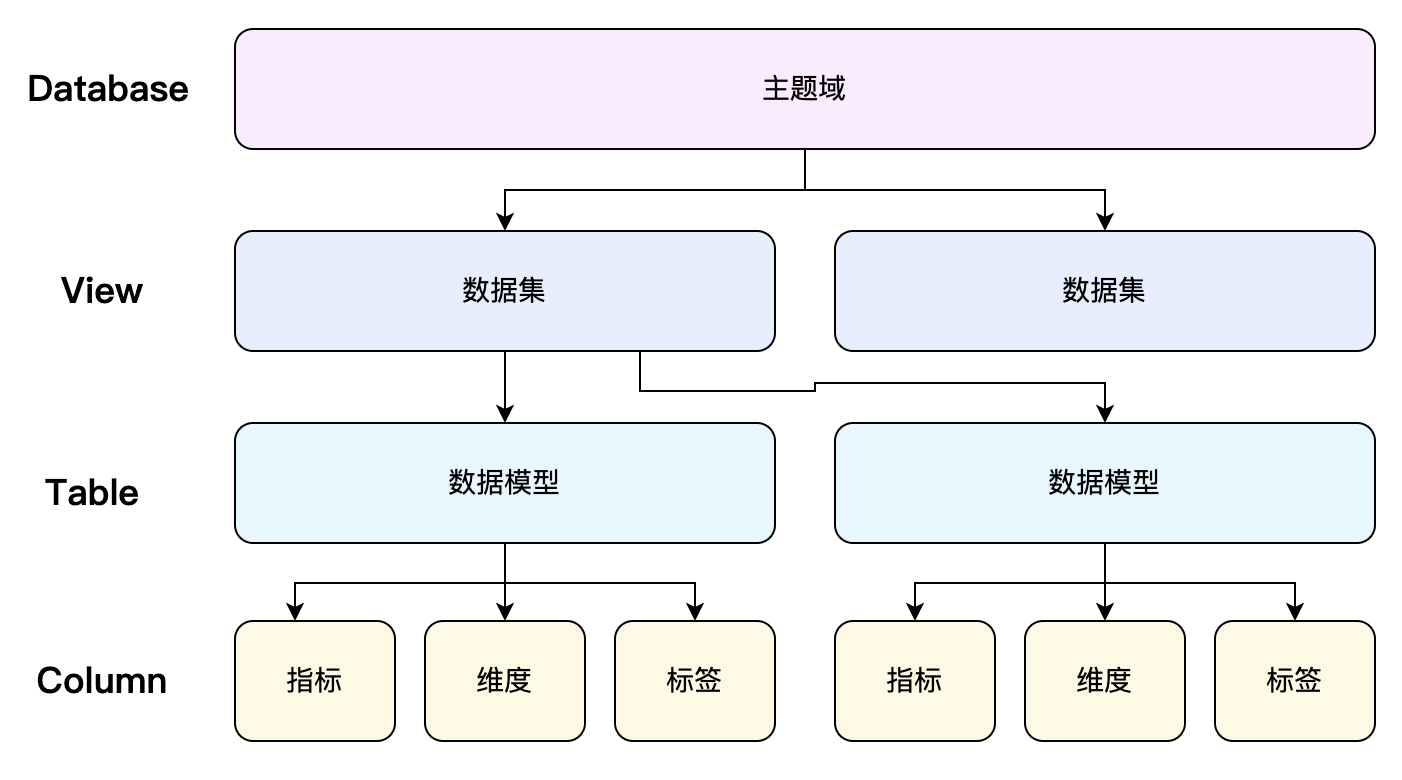
主题域
主题域可以理解为一个分类的概念,用户可以根据自己的业务场景来划分主题域。SuperSonic中的数据模型,数据集,术语等概念都归属于一个主题域。
数据模型
在SuperSonic中, 数据模型是对数据库中数据的一种逻辑层面上的抽象, 它既可以直接指代一张物理表, 也可以由一段SQL逻辑创建而成。 当我们得到一张表物理表或者一段逻辑SQL后,可以将表头字段指定为主键、维度、度量、时间日期或者是普通字段, 当表头字段都被赋予这些特定的语义后, 即形成了一个数据模型。
后边在使用时需要先创建我们的数据模型。
主键
SuperSonic中的主键概念不完全等同于数据库中的主键。当我们创建多个模型之后,如果需要指定模型间的关联关系,通俗来讲就是Join的方式, 就可以通过指定主键来进行关联。
维度
维度指表格中通常被用来进行分组和过滤的字段。
度量
度量的概念则恰好和维度相反,通常是一些数值型的字段,用来表达客观现象的程度。在SuperSonic中,度量主要用来创建一个具体的指标,没有其它实质性的作用。
指标
指标是相对度量更具具体和实例化的概念,用户可以基于度量,字段或者已有指标来创建指标并对它进行管理。同时,创建出来的指标也可以被问答这样的上层BI产品进行消费。
数据集
数据集是SuperSonic用来对接问答和其它上层BI应用的一个数据结构,在数据集中,可包含来自多个模型的维度指标。 对上层应用来说,底层建模细节是隐藏的,它只需要关注数据集中暴露出来的维度指标即可,也就是说,上层应用可以把一个数据集当作是一个大宽表,可以直接进行指标维度的分析查询。
术语
企业内部通常有自己的私域知识,是否能把私域知识教给大模型对结果准确性有较大的影响。因此,SuperSonic引入了术语的概念,通过配置术语及其描述,就可以把私域知识 传授给大模型。比如SuperSonic给的样例术语:近期指代近10天;核心用户指Tom和Lucy,就能很容易让大模型学习到这个知识。
配置大模型
目前Supersonic支持的大模型有Openai、微软、百炼等。可以在大模型管理中进行配置。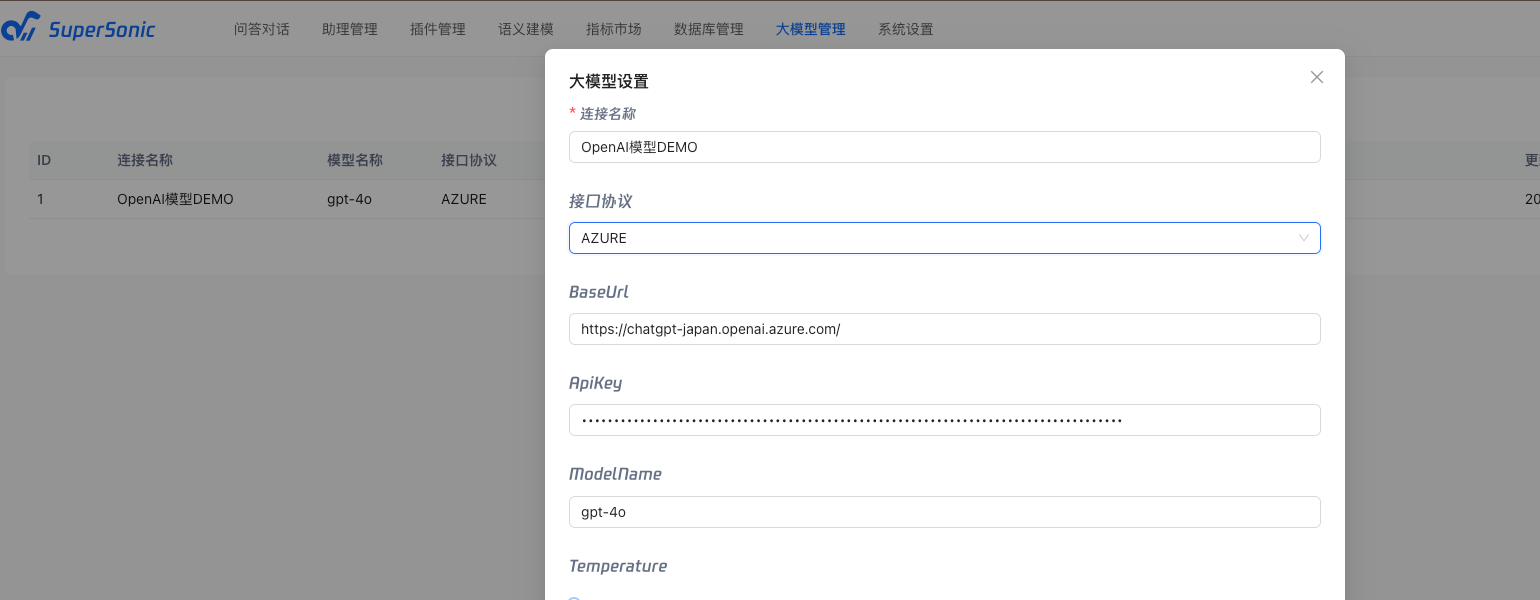
连接数据库
目前支持的数据库有H2、CK、MySQL、PG、 HANADB、STARROCKS、KYUUBI、PRESTO、TRINO
语义建模
创建主题域
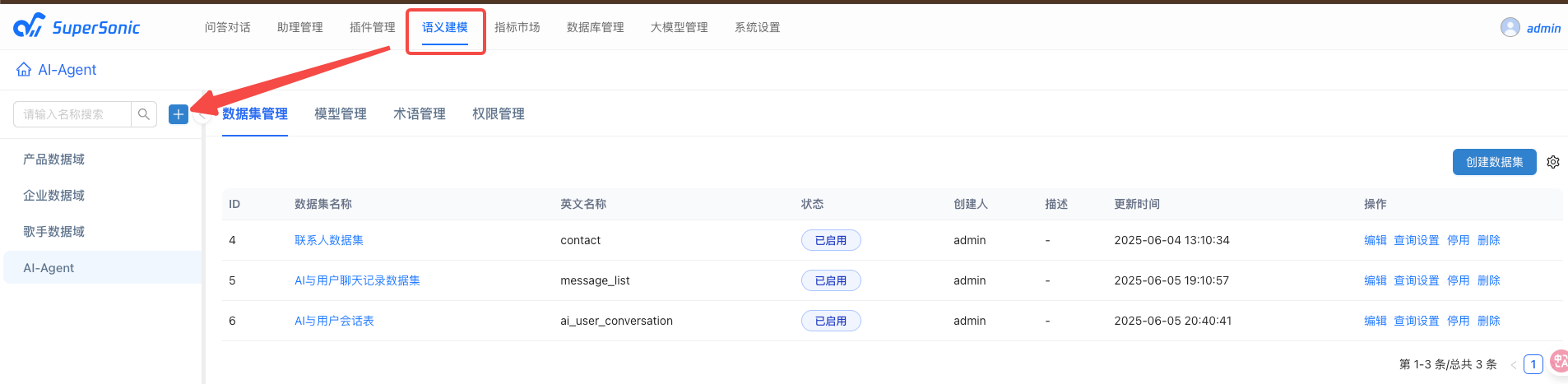 比如我这里建立的AI Agent主题域
比如我这里建立的AI Agent主题域
创建模型
创建模型可以通过SQL创建和快速创建,这里我们使用SQL创建:
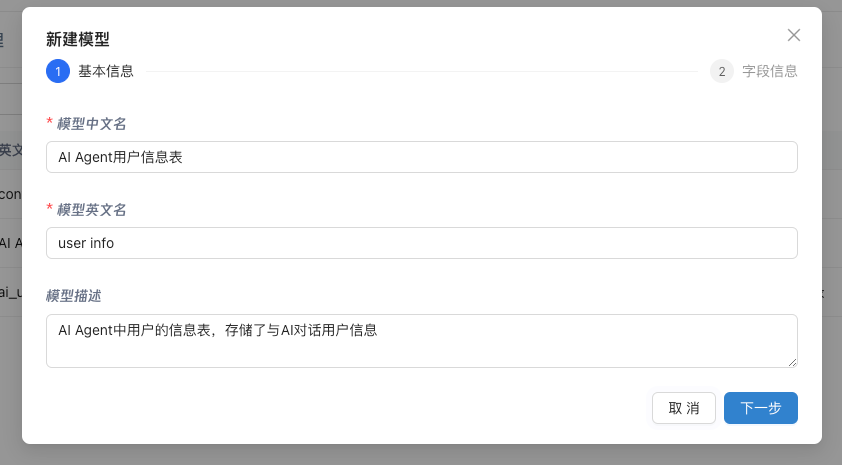 可以自定义这个模型需要的字段
可以自定义这个模型需要的字段
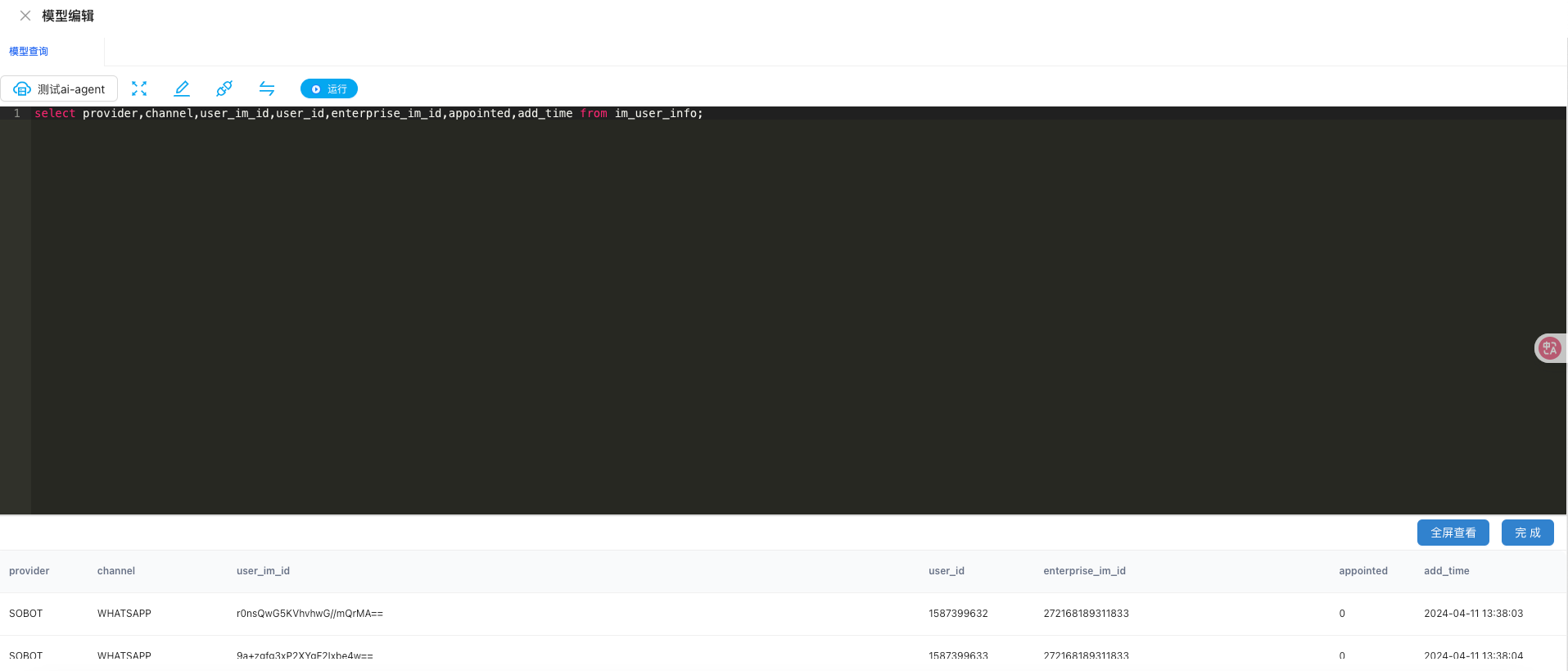
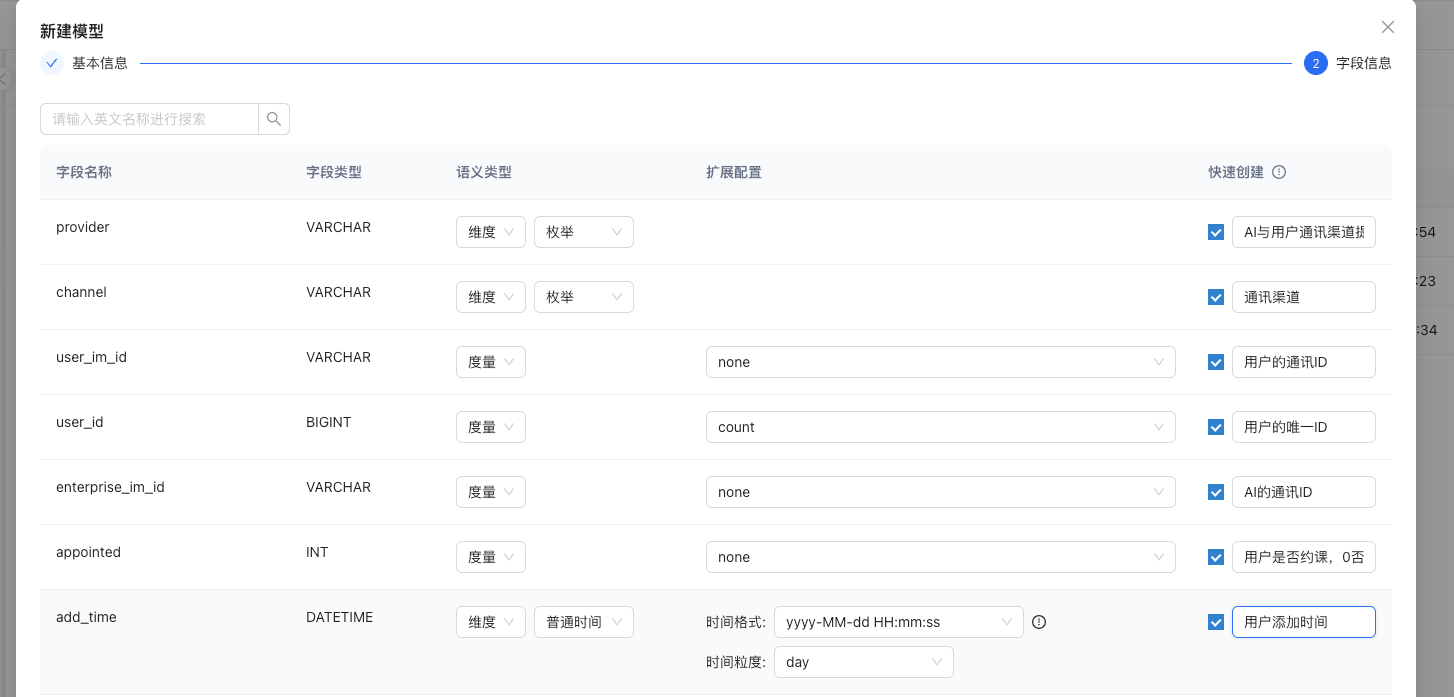
选择模型字段的各个语义
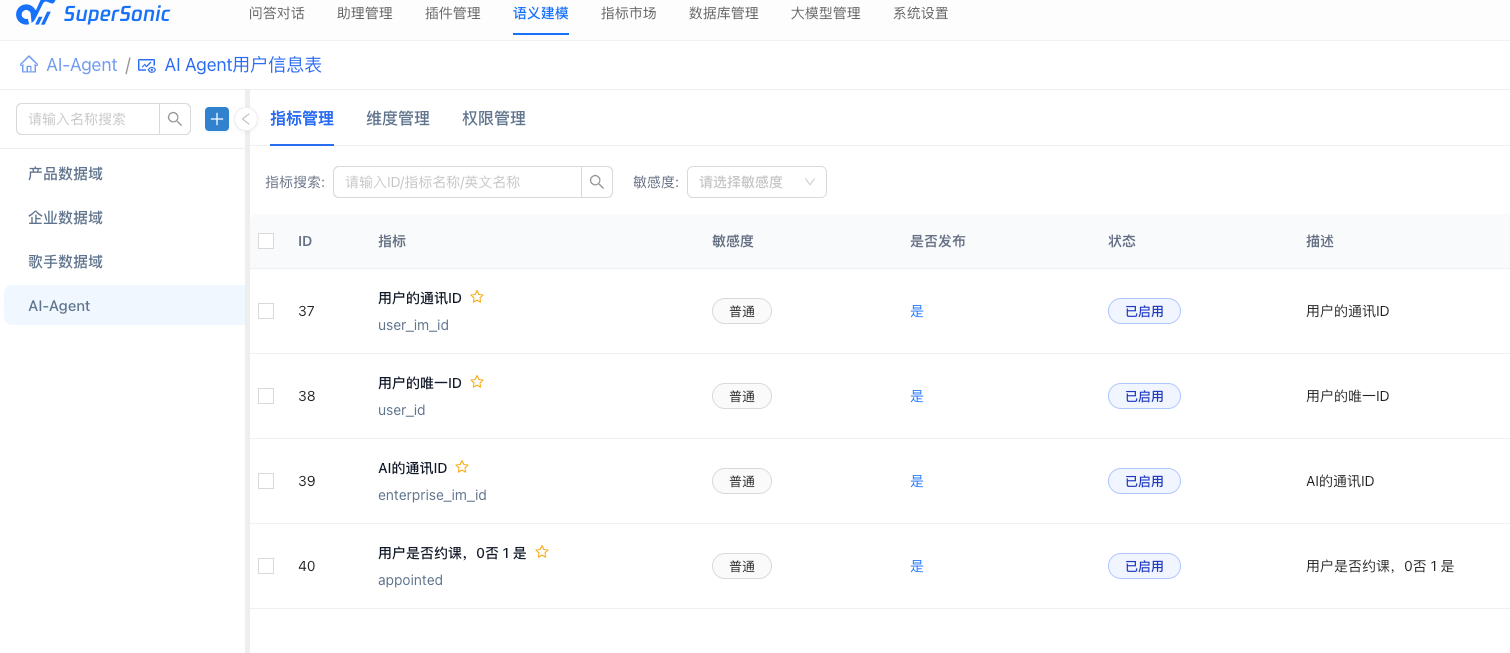
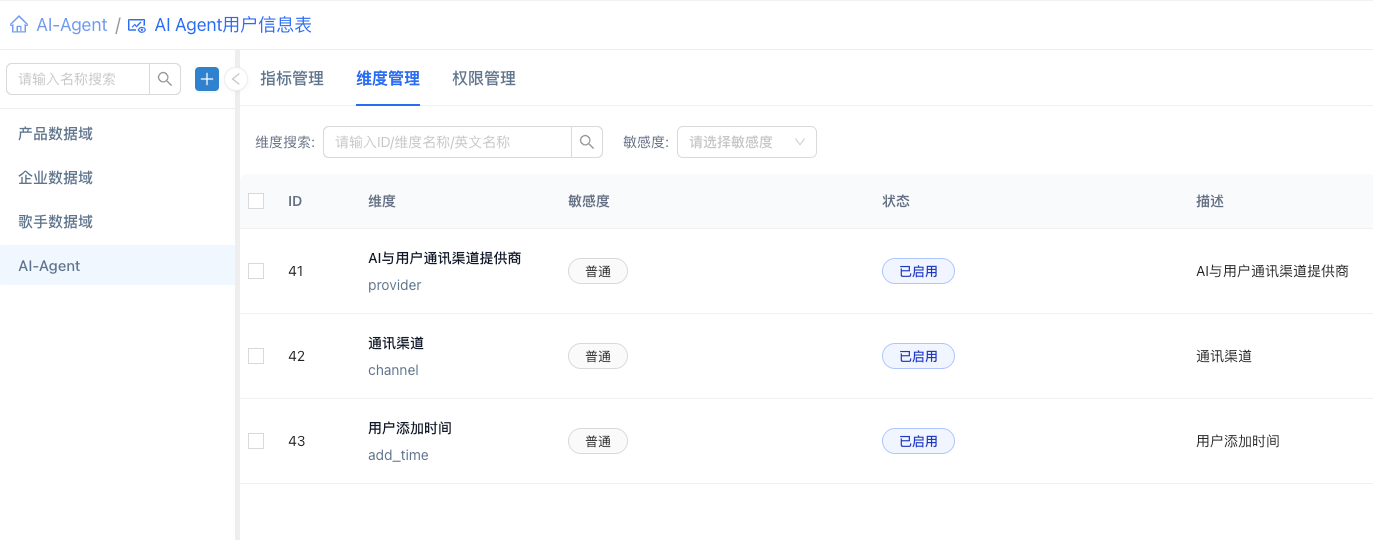
保存之后Supersonic会自动创建指标和维度:
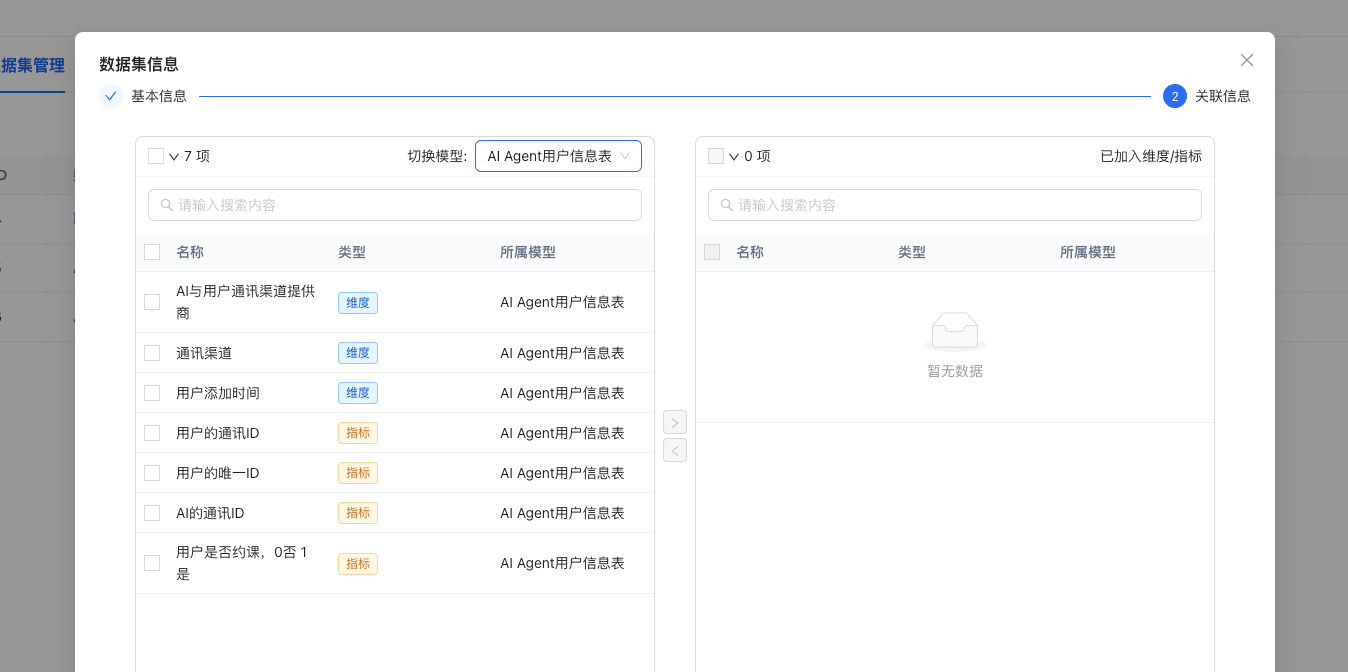
创建数据集
将刚刚创建的模型与数据集进行关联
创建AI助理
助理的配置主要分为四个部分
基本信息配置
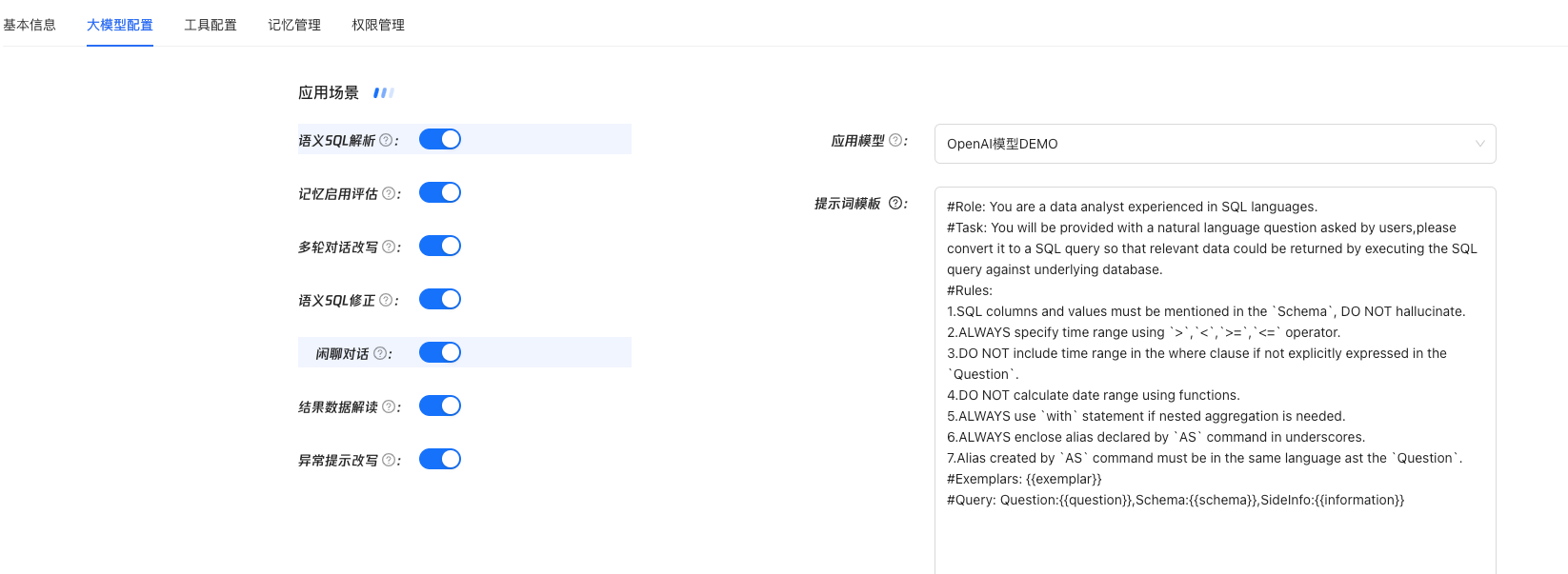
大模型应用配置
这里根据自己的实际需求去配置就可以
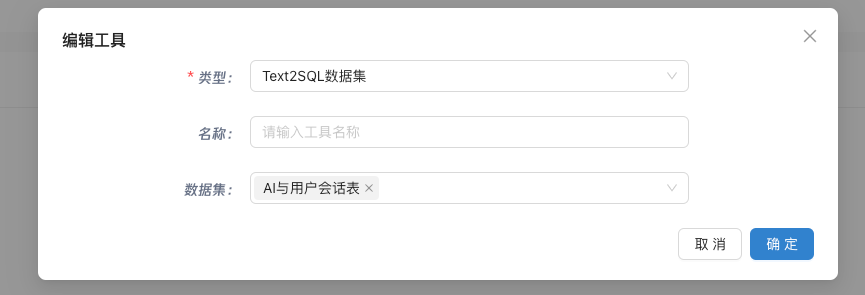
工具配置
需要选择Text2SQL工具,并选择可以使用的的数据集
记忆管理
当开启大模型的"记忆启用评估"后会自动开启记忆
问答对话
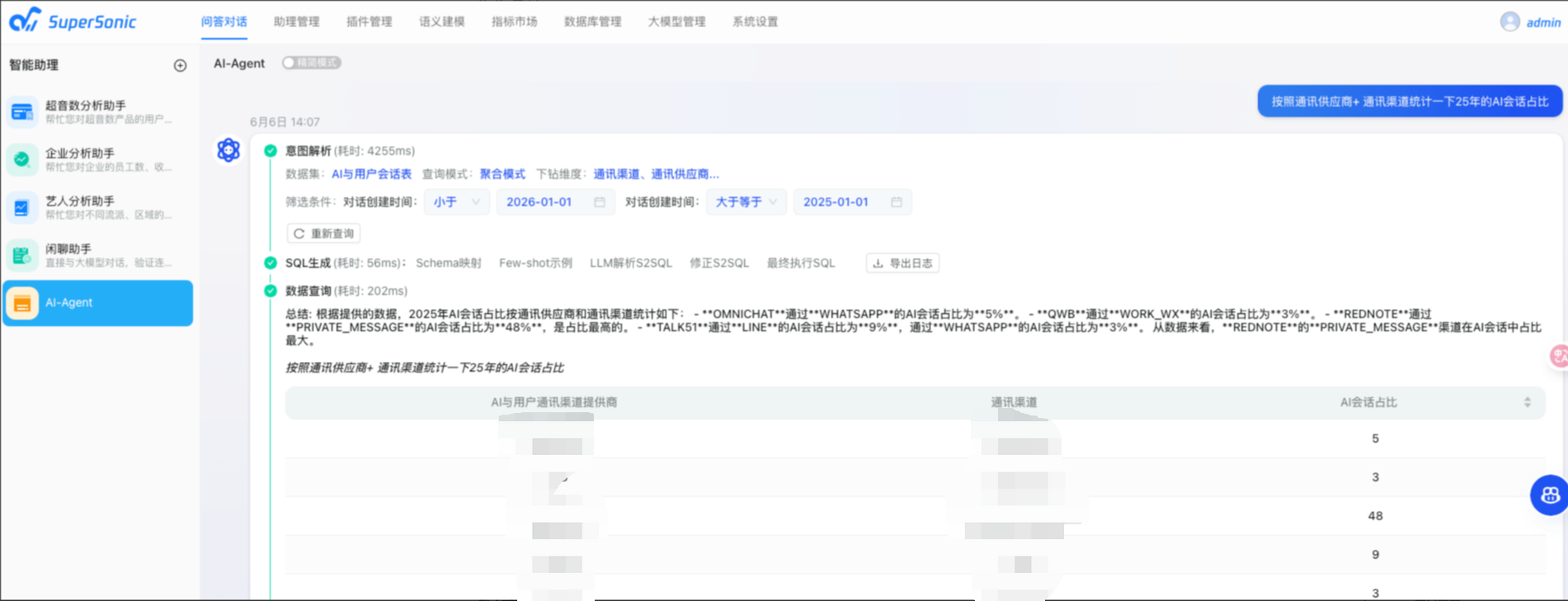
以上配置完毕后就可以在问答对话中和小助理对话了,SuperSonic会自动识别我们的意图,转换为SQL,将数据以可视化的方式呈现出来。
现有问题
- 目前查询的准确性受限于语义模型中的字段定义
- 需要查询描述 与语义模型的字段定义需要相似则准确度比较高,否则效果比较差
- 对于使用人员和建模人员来说会有一定的要求,需要统一话术