1. Multi-Query 多查询策略
多查询策略 也被称为 子查询,是一种用于生成子问题的技术,其核心思想是在问答过程中,为了更好地理解和回答主问题,系统会自动生成并提出与主问题相关的子问题,这些子问题通常具有更具体的细节,可以帮助大语言模型更深入地理解主问题,从而进行更加准确的检索并提供正确的答案。
多查询策略 会从多个角度重写用户问题,为每个重写的问题执行检索,然后将检索到的文档列表进行合并后去重,返回唯一文档,该策略的运行流程非常简单,如下: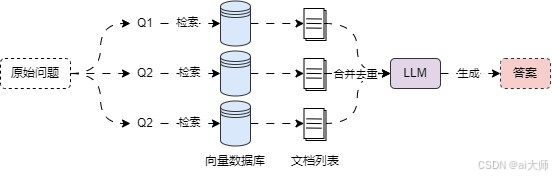
在 LangChain 中,针对 多查询策略 封装了一个检索器 MultiQueryRetriever,该检索器可以通过构造函数亦或者 from_llm 类方法进行实例化,参数如下:
retriever:基础检索器,必填参数。
llm:大语言模型,用于将原始问题转换成多个问题,必填参数。
prompt:转换原始问题为多个问题的提示模板,非必填,已有默认值。
parser_key:解析键,该参数在未来将被抛弃,非必填,已弃用,新版本中保留参数,但没有任何使用的地方。
inclued_original:是否保留原始问题,默认为 False,如果设置为 True,则除了检索新问题,还会检索原始问题。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
例如以weaviate向量数据库作为检索器,使用 多查询策略 优化普通的RAG检索,对应的代码具象化如下:
python
import dotenv
import weaviate
from langchain.retrievers import MultiQueryRetriever
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_weaviate import WeaviateVectorStore
from weaviate.auth import AuthApiKey
dotenv.load_dotenv()
# 1.构建向量数据库与检索器
db = WeaviateVectorStore(
client=weaviate.connect_to_wcs(
cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0"),
),
index_name="DatasetDemo",
text_key="text",
embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)
retriever = db.as_retriever(search_type="mmr")
# 2.创建多查询检索器
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=retriever,
llm=ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0),
)
# 3.执行检索
docs = multi_query_retriever.invoke("关于LLMOps应用配置的文档有哪些")
print(docs)
print(len(docs))输出内容:
python
[Document(metadata={'source': './项目API文档.md', 'start_index': 0.0}, page_content='LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态码共有 6 种,其中只有 success(成功) 代表业务操作成功,其他 5 种状态均代表失败,并且失败时会附加相关的信息:fail(通用失败)、not_found(未找到)、unauthorized(未授权)、forbidden(无权限)和validate_error(数据验证失败)。\n\n接口示例:\n\njson { "code": "success", "data": { "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail" }, "message": "" }'), Document(metadata={'source': './项目API文档.md', 'start_index': 3042.0}, page_content='1.2 [todo]更新应用草稿配置信息\n\n接口说明:更新应用的草稿配置信息,涵盖:模型配置、长记忆模式等,该接口会查找该应用原始的草稿配置并进行更新,如果没有原始草稿配置,则创建一个新配置作为草稿配置。\n\n接口信息:授权+POST:/apps/:app_id/config\n\n接口参数:\n\n请求参数:\n\napp_id -> str:需要修改配置的应用 id。\n\nmodel_config -> json:模型配置信息。\n\ndialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\n请求示例:\n\njson { "model_config": { "dialog_round": 10 }, "memory_mode": "long_term_memory" }\n\n响应示例:\n\njson { "code": "success", "data": {}, "message": "更新AI应用配置成功" }\n\n1.3 [todo]获取应用调试长记忆'), Document(metadata={'source': './项目API文档.md', 'start_index': 5818.0}, page_content='json { "code": "success", "data": { "list": [ { "id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "conversation_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8", "query": "能详细讲解下LLM是什么吗?", "answer": "LLM 即 Large Language Model,大语言模型,是一种基于深度学习的自然语言处理模型,具有很高的语言理解和生成能力,能够处理各式各样的自然语言任务,例如文本生成、问答、翻译、摘要等。它通过在大量的文本数据上进行训练,学习到语言的模式、结构和语义知识'), Document(metadata={'source': './项目API文档.md', 'start_index': 675.0}, page_content='json { "code": "success", "data": { "list": [ { "app_count": 0, "created_at": 1713105994, "description": "这是专门用来存储LLMOps课程信息的知识库", "document_count": 13, "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/07/96b5e270-c54a-4424-aece-ff8a2b7e4331.png", "id": "c0759ca8-2d35-4480-83a8-1f41f29d1401", "name": "LLMOps课程知识库", "updated_at": 1713106758, "word_count": 8850 } ], "paginator": { "current_page": 1, "page_size": 20, "total_page": 1, "total_record": 2 } }'), Document(metadata={'source': './项目API文档.md', 'start_index': 2324.0}, page_content='json { "code": "success", "data": { "id": "5e7834dc-bbca-4ee5-9591-8f297f5acded", "name": "LLMOps聊天机器人", "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/23/e4422149-4cf7-41b3-ad55-ca8d2caa8f13.png", "description": "这是一个LLMOps的Agent应用", "published_app_config_id": null, "drafted_app_config_id": null, "debug_conversation_id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "published_app_config": null, "drafted_app_config": { "id": "755dc464-67cd-42ef-9c56-b7528b44e7c8"'), Document(metadata={'source': './项目API文档.md', 'start_index': 2042.0}, page_content='dialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\nstatus -> string:应用配置的状态,drafted 代表草稿、published 代表已发布配置。\n\nupdated_at -> int:应用配置的更新时间。\n\ncreated_at -> int:应用配置的创建时间。\n\nupdated_at -> int:应用的更新时间。\n\ncreated_at -> int:应用的创建时间。\n\n响应示例:')]
6亦或者在 LangSmith 平台上也可以观测到整个执行的流程,如下: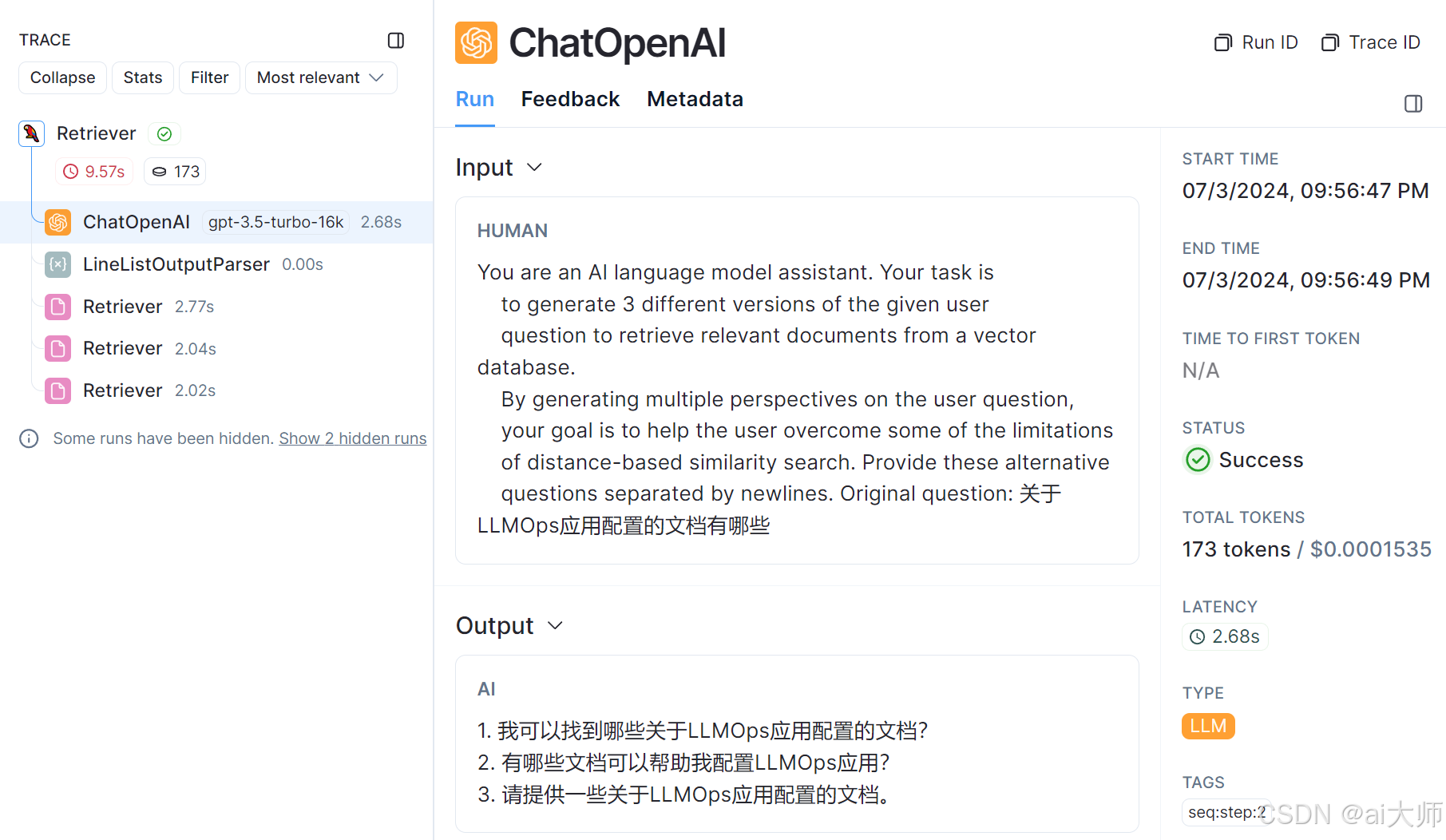
资料推荐