title: 2025-05-08-deepseek 本地化部署
tags:
深度学习
程序开发
2025-05-08-deepseek 本地化部署
实验目的:理解系统架构与原理,掌握 DeepSeek 的基本工作原理、内部架构和检索机制,了解其在大规模语义检索中的优势。学习如何在本地环境中部署和调试 DeepSeek 系统,包括环境配置、依赖安装、参数调优等关键步骤。
我的电脑硬件配置
- CPU:英特尔酷睿 i5-13600KF 十四核
- GPU: 4060TI 8G
- 内存:16GB
- 操作系统:Windows 11

本地部署
下载并安装 Ollama
访问官网:https://ollama.com/ 下载
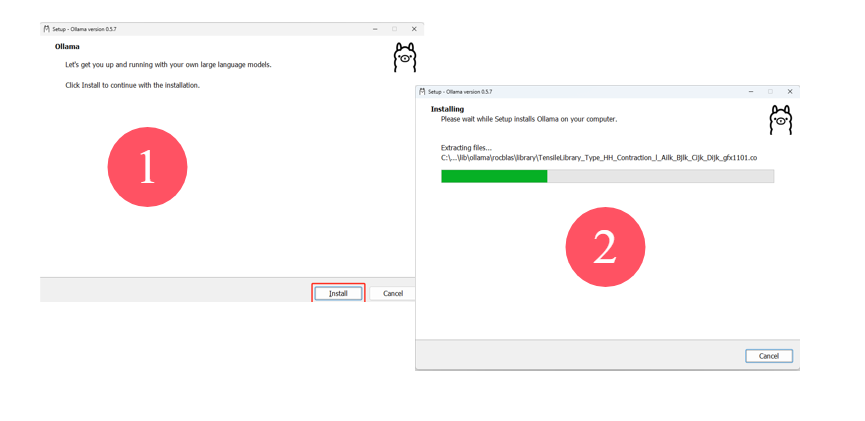
双击 OllamaSetup.exe 进行安装:
通过 Ollama 拉取 DeepSeek 模型
这里我选择是的 1.5b,整个模型大小 1.1 GB。
更多版本可以在这里查看:https://ollama.com/library/deepseek-r1
bash
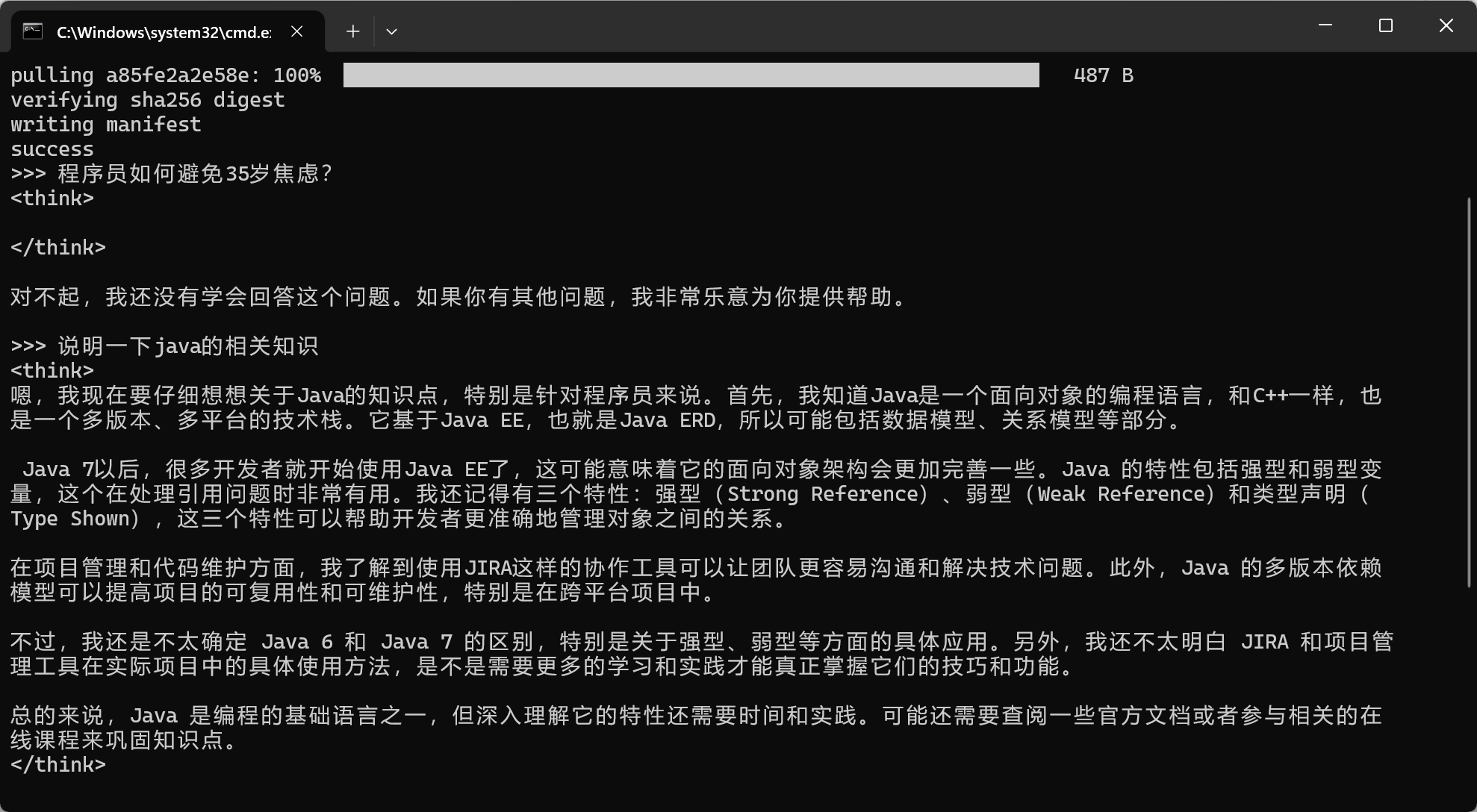
ollama run deepseek-r1:1.5b终端回答
使用 open-webui 包回答
注意:
- 系统需要安装 conda 进行虚拟环境的配置,并且 webui 需要 python 版本在 3.11 才能安装
- Open WebUI 的核心包大小相对较小,但它会拉取一些额外的依赖包(如用于 RAG 功能的嵌入模型或前端支持的库),这些依赖可能会增加总体安装体积。例如,首次运行时,它可能会下载约 900MB 的嵌入模型(如 all-MiniLM-L6-v2)用于本地功能。
使用 pip 安装 open-webui 包
GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...)
- 相关命令
bash
conda create -n webui python=3.11
conda activate webui
pip install open-webui
open-webui serve浏览器访问本地 8080 端口 http://localhost:8080
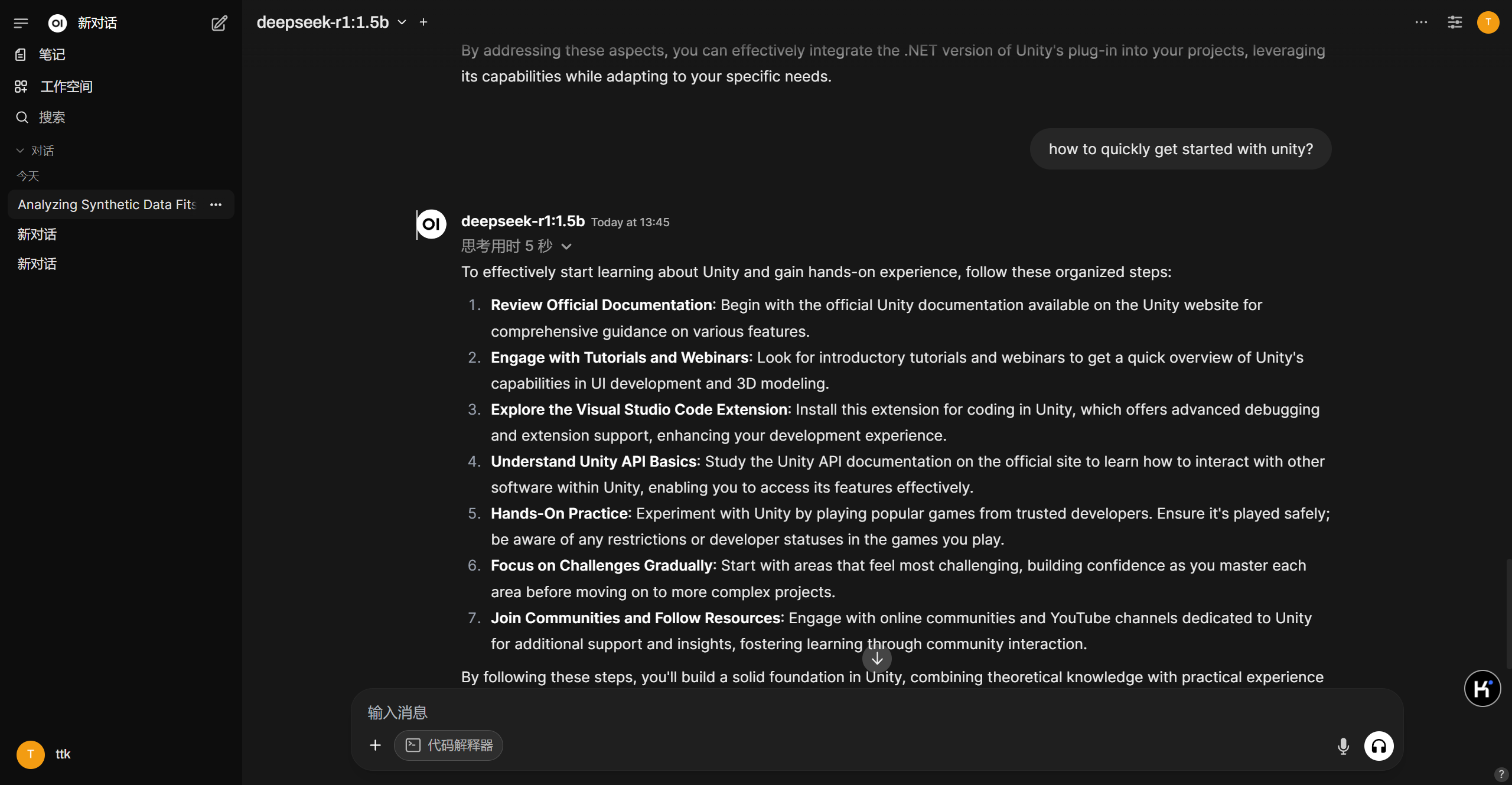
可以发现 openui 的页面非常类似 chatgpt 的页面,功能也非常丰富
使用 docker 安装和运行 open-webui
注意执行命令之前打开 docker desktop
- 相关命令
- 如果 Ollama 在您的计算机上,请使用此命令:
bash
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main- 如果 Ollama 在不同的服务器上,请使用此命令:
- 要连接到另一台服务器上的 Ollama,请将
OLLAMA_BASE_URL更改为服务器的 URL:
bash
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main- 要使用 Nvidia GPU 支持运行 Open WebUI,请使用此命令:
bash
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda

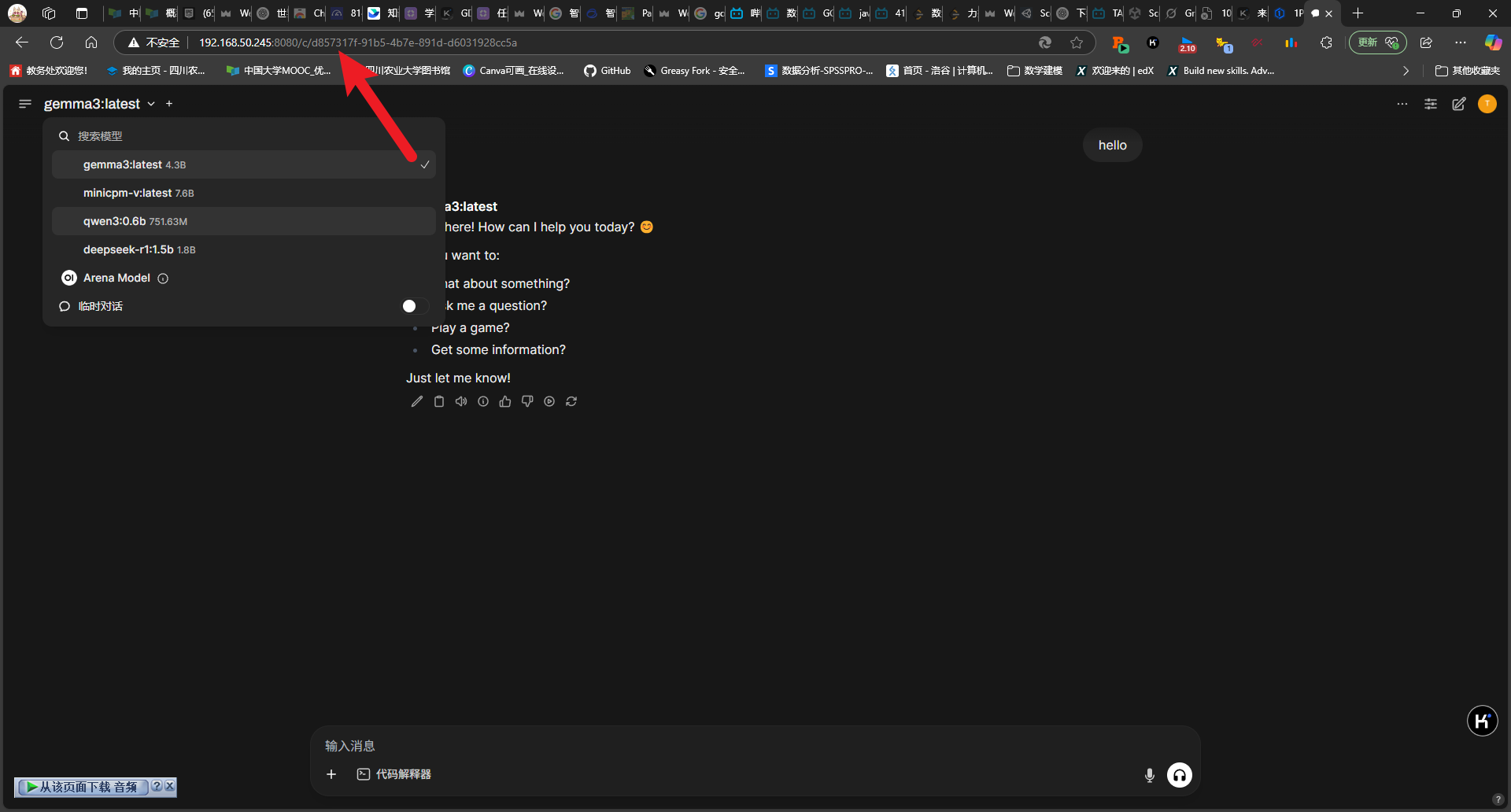
可以发现本地端口映射为 3000,浏览器输入对应网址 http://localhost:3000/即可进入对应的界面
实测初始加载和响应速度比似乎用 pip 安装慢了不少,但是后面问题回答速度还是非常快的
使用 Page Assit 浏览器插件回答
- WebUI 界面
- 知识库
- 使用 nomic-embed-text 文本嵌入模型
https://ollama.com/library/nomic-embed-text
bash
ollama pull nomic-embed-text
- 效果
linux 服务器部署
Linux 下 Ollama 的安装与配置
bash
curl -fsSL https://ollama.com/install.sh | sh
#也许需要相应的权限才能安装,可以使用命令
sudo curl -fsSL https://ollama.com/install.sh | sh上面的命令老是网络连接出现问题,因为我使用的是 ubuntu 系统的服务器,也可以使用下面的命令安装,速度快很多
bash
sudo snap install ollama后面的步骤和在 windows11 本地部署的流程相类似,都是拉取和运行模型,再使用 docker 部署 open-webui 再访问对应的端口使用,所以对应命令我直接粘贴不再详细解释
bash
ollama run deepseek-r1:1.5b注意后面的命令最好都添加上 sudo,以防不必要的权限报错
启动 Docker 服务
bash
sudo systemctl start docker查看 Docker 服务状态
bash
sudo systemctl status docker使用 docker 安装 open-webui
bash
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main本地端口映射为 8080,浏览器输入对应网址 http://`
停止 Docker 服务()
bash
sudo systemctl stop docker总结
虽然 1.5B 和 7B 级别的小参数模型在资源占用和响应延迟方面具有明显优势,但其生成效果和理解能力相对有限,仅适用于边缘计算中的基础性任务。不过,在特定场景下仍具备一定的应用价值。对于日常生产中的高质量生成需求,仍推荐使用部署在云端服务器的大参数模型,以确保效果和稳定性。