SIMA 2:一个通用型具身智能体,用于虚拟世界 --- SIMA 2: A Generalist Embodied Agent for Virtual Worlds




















任务设定器、智能体、奖励模型


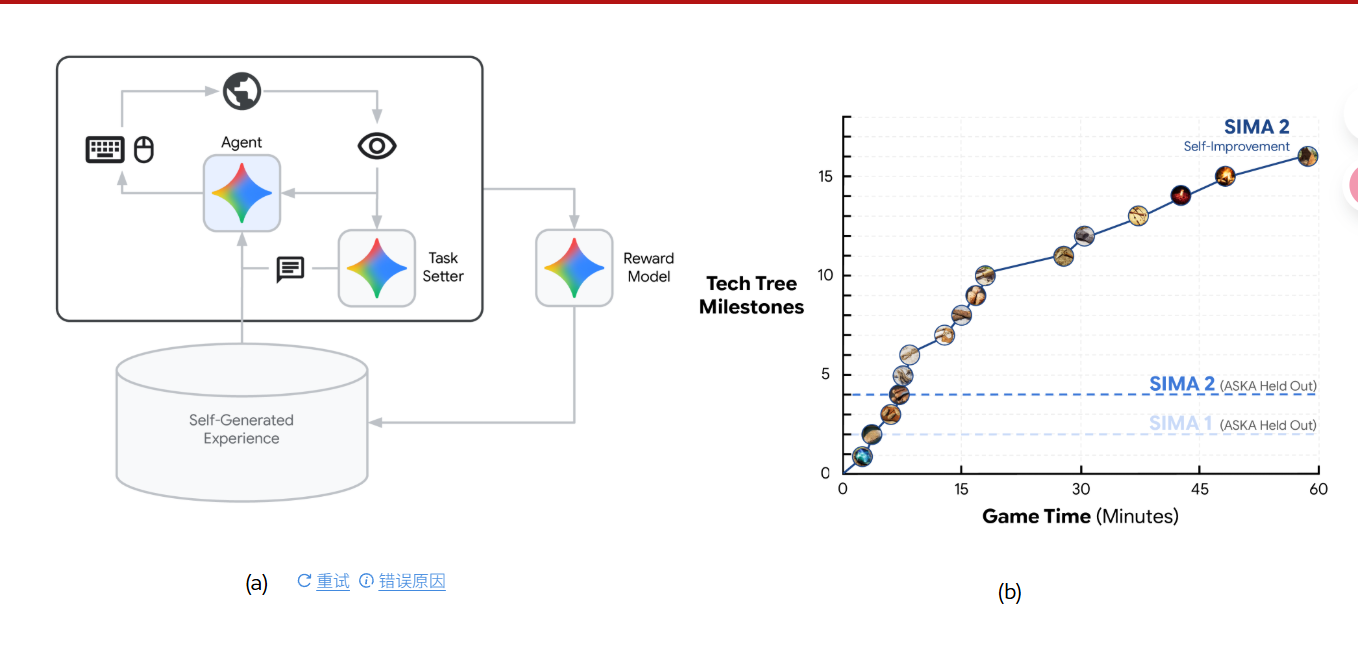

🌱 SIMA 2 是如何"自我改进"的?
✅ 核心机制:闭环自监督学习 + 自我生成任务
SIMA 2 的自我改进不是传统意义上的"在线微调"或"强化学习",而是一种 基于自生成数据的闭环演化过程,其关键在于三个组件之间的协同工作:
🔁 1. Agent(智能体)
- 输入:当前环境视觉(如游戏画面)、历史动作、语言指令等。
- 输出:一系列低级动作(键盘/鼠标),用于与环境交互。
- 模型基础:通常是多模态大模型(如 LLaVA、PaLM-E 等),能理解图像和文本并生成行为。
它的行为由两个部分驱动:
- 外部任务指令(来自 Task Setter)
- 内部推理(如 "我要先找到矿石")
🎯 2. Task Setter(任务设定器)
- 这是一个关键创新点 :它不依赖人类设计的任务,而是自动为 Agent 生成新任务。
- 例如:
- 当 Agent 在游戏中完成采矿后,Task Setter 会生成下一个目标:"建造熔炉"。
- 或者:"探索地图东边区域"、"击败某个怪物"。
它的作用是:
- 保持挑战性:避免重复相同任务导致的学习停滞。
- 引导探索:鼓励 Agent 学习新的技能组合(如采集 → 制作 → 战斗)。
💡 类比:就像一个"AI 教练"不断给你布置新作业,让你逐步掌握复杂技能。
🧠 3. Reward Model(奖励模型)
- 不是人工定义规则,而是从历史经验中学习什么是"好行为"。
- 奖励信号来源于:
- 成功完成任务
- 达成技术树里程碑(如解锁新建筑、获得新道具)
- 提高效率(更快完成任务)
它的作用是:
- 评估 Agent 表现
- 为后续训练提供反馈信号
- 支持策略优化(如 PPO、DQN 等 RL 方法)
🔄 4. Self-Generated Experience(自生成经验)
- 所有 Agent 与环境交互的数据(包括失败尝试)都被存储在这里。
- 这些数据被用来:
- 训练 Reward Model
- 微调 Agent 模型(通过 SFT 或 RL)
- 更新 Task Setter 的任务难度分布
这个数据库是整个系统的"记忆库"和"训练集"。
===============================================================================================================================================
这是一个非常关键的问题:奖励模型(Reward Model)如何具体支持策略优化(如 PPO、DQN 等强化学习算法)?
我们来一步步拆解其机制。
🔁 背景回顾:强化学习中的"奖励"作用
在标准强化学习(RL)框架中:
-
智能体(Agent) 在状态 s 下采取动作 a ,环境返回:
- 下一状态 s'
- 标量奖励 r
-
智能体的目标是最大化累积折扣奖励 (return):
G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \dots
-
策略优化算法(如 PPO、DQN)依赖这个 r 来判断哪些行为"好",哪些"坏"。
❗传统 RL 的问题:奖励函数需要人工设计(例如,"走到终点 +10,撞墙 -1")。这在复杂任务(如 Minecraft、桌面操作)中极难定义。
🧠 奖励模型(Reward Model)如何替代人工奖励?
✅ 核心思想:
用一个可学习的模型 R_\phi(s, a, \text{goal}) 来预测"人类或任务视角下该行为是否好",而不是写死规则。
🛠️ 奖励模型如何支持策略优化?分三步说明
步骤 1️⃣:训练奖励模型(Offline)
数据来源:
- 人类偏好数据(如:轨迹 A 比轨迹 B 更好)
- 成功/失败标签(如:是否达成里程碑)
- 自生成经验中标记的"成功事件"(如解锁熔炉、击败 Boss)
训练方式:
- 二元分类 :给定两个轨迹片段,预测哪个更好(类似 InstructGPT 的 RM 训练)
- 回归任务:直接预测一个连续奖励值(如 0~1 分),基于是否完成子目标
输出:一个函数 R_\phi(\text{state}, \text{action}, \text{context}) \rightarrow r \in \mathbb{R}
步骤 2️⃣:在策略训练中使用奖励模型(Online / Offline RL)
现在,每当 Agent 与环境交互(或回放经验),不再使用人工奖励,而是调用奖励模型:
python
编辑
# 伪代码
state, action, next_state = env.step(action)
reward = reward_model(state, action, goal="build_furnace") # ← 关键!
agent.update(state, action, reward, next_state)具体到不同算法:
表格
| 算法 | 如何使用奖励模型 |
|---|---|
| PPO(On-policy) | 在 rollout 时,每一步的 reward 由 RM 提供;用于计算优势函数 A_t 和策略梯度 |
| DQN / SAC(Off-policy) | 在经验回放缓冲区中,存储 (s, a, s'),训练时用 RM 实时打分或预存 r |
| GRPO / ReMax(LLM RL) | 奖励用于对多个推理轨迹排序,加权更新策略(如 DeepSeek R1 的 RLVR) |
💡 奖励模型充当了 "自动评分老师",告诉策略:"你刚才那步操作值得 +0.8 分,因为接近目标了。"
步骤 3️⃣:闭环迭代(Self-Improvement Loop)
- Agent 使用当前 RM 生成新轨迹
- 新轨迹中包含更多样/更难的成功案例
- 用这些新数据 微调奖励模型(让它更准确识别"好行为")
- 更新后的 RM 再用于训练更强的 Agent
- 循环往复 → 协同进化
这就是 SIMA 2、DeepSeek R1 等系统实现"自我改进"的核心机制。
🎯 举个具体例子(Minecraft 场景)
- 任务:建造一把木镐
- 子目标 :
- 砍树 → 获得木头
- 制作工作台
- 用木头合成木镐
奖励模型如何打分?
表格
| 行为 | 奖励模型输出 |
|---|---|
| 随机走动 | r \approx 0.1 |
| 靠近树 | r = 0.3 |
| 成功砍树(获得木头) | r = 0.8 ✅(达成子目标) |
| 打开合成界面但选错物品 | r = 0.2 |
| 成功合成木镐 | r = 1.0 🏆(完成任务) |
→ PPO 算法会放大高奖励轨迹的概率,抑制低奖励行为。
⚠️ 挑战与注意事项
- 奖励黑客(Reward Hacking)
- 如果 RM 只奖励"获得木头",Agent 可能无限砍树而不做镐。
- 解法:RM 需要理解任务上下文 和长期目标(如通过 goal-conditioning)。
- 奖励稀疏性
- 复杂任务中成功很少,RM 早期可能无法提供有效信号。
- 解法:结合课程学习 (从简单任务开始)或内在奖励(好奇心驱动)。
- 分布偏移
- Agent 行为越来越强,超出 RM 训练数据分布。
- 解法:持续用新数据在线微调 RM(active learning)。
✅ 总结:奖励模型如何支持策略优化?
奖励模型将"模糊的成功概念"转化为可微、可量化的标量信号,使通用策略优化算法(PPO/DQN等)能在无显式规则的复杂环境中进行有效学习。
它本质上是:
- 人类意图的代理
- 任务进展的探测器
- 策略更新的指南针
在 SIMA 2、AlphaDev、DeepSeek R1 等前沿系统中,高质量的奖励模型 = 自主进化的引擎。
如果你正在实现类似系统,建议:
- 用 LLM 辅助生成奖励标注(如 "这段轨迹是否完成了'打开设置'?")
- 对 RM 输出做归一化(避免尺度漂移)
- 结合稀疏任务奖励 + 密集过程奖励(multi-stage RM)
需要我画一个数据流图或给出 PyTorch 伪代码吗?