AI Agent 目标设定与异常处理
智能体系统的双翼:目标设定与异常处理深度解析
在构建高效可靠的智能体系统时,目标设定与监控(第11章)和异常处理与恢复(第12章)如同双翼,缺一不可。前者确保智能体行为始终聚焦于核心目标,后者则赋予系统在动态环境中容错前行的韧性。本文将深入剖析这两大模式的逻辑内核,并结合实战代码展示如何打造健壮的智能体应用。

一、目标设定与监控:智能体的"导航系统"
目标设定与监控模式解决了智能体在复杂任务中保持方向性的核心挑战。其本质是通过明确的目标定义 和持续的进度追踪,将智能体从被动响应提升为主动规划的自驱系统。
逻辑框架解析
-
SMART原则落地:
- 具体性:目标需清晰界定,如"生成用户行为分析报告"而非"处理数据"。
- 可衡量性:通过量化指标(如准确率≥95%)评估进展。
- 可达成性:目标需符合智能体能力边界,避免不切实际的期望。
- 相关性:子目标必须对齐终极任务,如报告生成需基于有效数据清洗。
- 时限性:设置截止时间(如10分钟内完成),驱动高效执行。
-
监控机制三层设计:
- 实时追踪:在任务执行中动态收集指标(如API调用成功率)。
- 反馈闭环:通过反思模式(第4章)比较实际输出与预期,生成优化建议。
- 自适应调整:当环境变化时,智能体可重新规划路径(如目标优先级动态切换)。
技术实现:ADK中的目标管理
以下代码展示了如何在Google ADK中实现带监控的目标执行流程。智能体通过状态(State)跟踪进度,并在偏离时自我修正:
python
from google.adk.agents import LlmAgent
from google.adk.sessions import InMemorySessionService
# 初始化智能体,明确目标描述
analyst_agent = LlmAgent(
model="gemini-2.0-flash",
instruction="""你是一名数据分析师,目标是在5分钟内生成用户活跃度报告。
成功标准:报告需包含DAU/MAU计算、环比增长率、关键趋势摘要。
若步骤耗时超时或数据缺失,立即触发异常处理流程。"""
)
# 通过Session State监控进度
session_service = InMemorySessionService()
session = session_service.create_session(app_name="ReportApp", user_id="user1")
session.state["current_step"] = "data_processing"
session.state["deadline"] = "2024-07-20T10:00:00Z"
# 智能体根据状态决策下一步行动
if session.state["current_step"] == "data_processing" and is_overtime(session):
trigger_rollback(session) # 超时则回滚此设计确保了智能体在时间约束下有序推进,避免陷入无限循环。
二、异常处理与恢复:智能体的"安全网"
异常处理模式为智能体提供了应对不确定性的韧性。其核心在于预见故障、优雅降级、快速恢复,使系统在部分失效时仍能维持核心功能。
逻辑分层策略
-
异常检测:
- 工具级异常:API返回错误码(如HTTP 500)或超时。
- 逻辑异常:输出违反约束(如生成无效JSON)。
- 环境异常:外部服务不可用(如数据库连接失败)。
-
处理优先级矩阵:
异常类型 处理策略 示例 临时性故障 指数退避重试(最多3次) 网络抖动导致API超时 持久性故障 切换备用工具或降级处理 主数据库宕机,切到缓存 逻辑错误 记录日志并人工介入 智能体生成矛盾结论 -
恢复机制:
- 状态回滚:还原到最近稳定检查点。
- 流程重启:从故障点重新执行子任务。
- 资源清理:释放临时文件或数据库锁。
实战代码:LangChain中的弹性工具调用
以下示例通过装饰器实现工具调用的自动重试和回退,确保单点故障不影响整体流程:
python
from langchain.tools import tool
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
@tool
def fetch_user_data(user_id: str) -> dict:
"""获取用户数据,失败时自动重试"""
response = requests.get(f"https://api.example.com/users/{user_id}")
response.raise_for_status() # 触发重试条件
return response.json()
# 备用工具:当主工具失败时调用
@tool
def fetch_cached_user_data(user_id: str) -> dict:
"""从缓存获取用户数据(降级方案)"""
return redis_client.get(f"user:{user_id}") or {}
# 工具组配置自动回退
tools = [fetch_user_data.with_fallback(fetch_cached_user_data)]此代码通过重试机制和回退工具,实现了服务的高可用性。
三、协同应用:构建自我修复的智能体系统
将目标监控与异常处理结合,可创建具备"免疫系统"的智能体。以下是一个电商客服智能体的完整场景:
- 目标设定:3分钟内解决用户退货请求(SMART目标)。
- 监控指标:响应延迟<10秒,政策引用准确率100%。
- 异常处理 :
- 若退货政策API宕机,切换至本地缓存版本(工具级恢复)。
- 若生成响应超时,简化答案并建议人工客服(降级处理)。
- 若用户反馈错误,启动反思循环修正知识库(自适应学习)。
通过这种设计,智能体在追求目标的同时,能从容应对突发状况,提升用户体验。
四、总结:迈向工业级智能体架构
目标设定与异常处理共同构成了智能体系统的韧性基础。在实践中,开发者需注意:
- 目标需可观测:通过日志和指标暴露内部状态,便于调试。
- 异常处理需透明:记录故障上下文,加速根因分析。
- 平衡成本与可靠性:过度设计异常处理可能引入复杂度,需根据业务关键性权衡。
随着智能体在金融、医疗等关键领域普及,这两大模式将成为构建可信AI系统的基石。未来,结合预测性监控(如异常检测算法)和自动修复(如K8s式重启机制),智能体将逐步逼近"零停机"的工业级标准。
智能体的"导航系统"与"安全气囊":目标设定监控与异常处理实战
智能体要靠谱干活,既要知道"往哪去",也要能应对"路上的意外"。目标设定与监控是智能体的"导航系统",明确方向并追踪进度;异常处理与恢复则是"安全气囊",在遇到问题时兜底止损。这两大模式联手,让智能体从"被动执行"升级为"稳健自主",本文结合实战逻辑,通俗拆解其核心玩法。
一、目标设定与监控:给智能体装"导航+仪表盘"
核心概念:从"瞎忙活"到"有方向"
目标设定与监控模式,本质是给智能体明确"目的地"和"进度条"------先定义具体可衡量的目标,再通过持续追踪状态、评估结果,确保智能体不跑偏、不低效。不同于单纯的"执行指令",它让智能体从"走一步看一步"变成"盯着目标走",甚至能自主调整路线。
关键要素:目标要"落地",监控要"精准"
- 目标设计:得符合SMART原则(具体、可衡量、可达成、相关、有时限),比如"3天内生成3篇符合品牌风格的营销文案",而非"写几篇文案"。
- 监控维度:既要盯"结果"(是否达成目标),也要盯"过程"(步骤是否合理、资源是否超标),还要盯"环境"(外部条件是否变化)。
- 反馈闭环:监控到偏差后,智能体要能自主纠偏,或触发升级机制(比如通知人类)。
实战解析:代码智能体的"目标闯关"
以"生成符合要求的Python代码"为例,核心流程如下:
- 明确目标:用户设定"代码简洁易懂、功能正确、处理边界情况"三大目标。
- 迭代执行:智能体先生成初稿,再自我评审(对比目标),发现问题后优化。
- 终止条件:要么达成所有目标,要么达到最大迭代次数(避免无限循环)。
核心逻辑代码片段(简化版):
python
def run_code_agent(use_case, goals, max_iterations=5):
previous_code = ""
for i in range(max_iterations):
# 生成/优化代码
code = generate_code(use_case, previous_code)
# 监控:评估是否符合目标
feedback = evaluate_code(code, goals)
if goals_met(feedback):
break # 目标达成,停止迭代
previous_code = code # 带着反馈优化
return add_comment_header(code)应用场景:哪里需要"盯目标"?
- 项目管理助手:监控里程碑进度,延误时自动预警。
- 个性化学习系统:跟踪学生答题准确率,调整教学内容。
- 交易机器人:监控投资收益与风险,超标时调整策略。
- 自动驾驶:盯紧"安全抵达目的地"目标,实时调整驾驶行为。
二、异常处理与恢复:给智能体装"安全气囊"
核心概念:从"一崩就停"到"自愈前行"
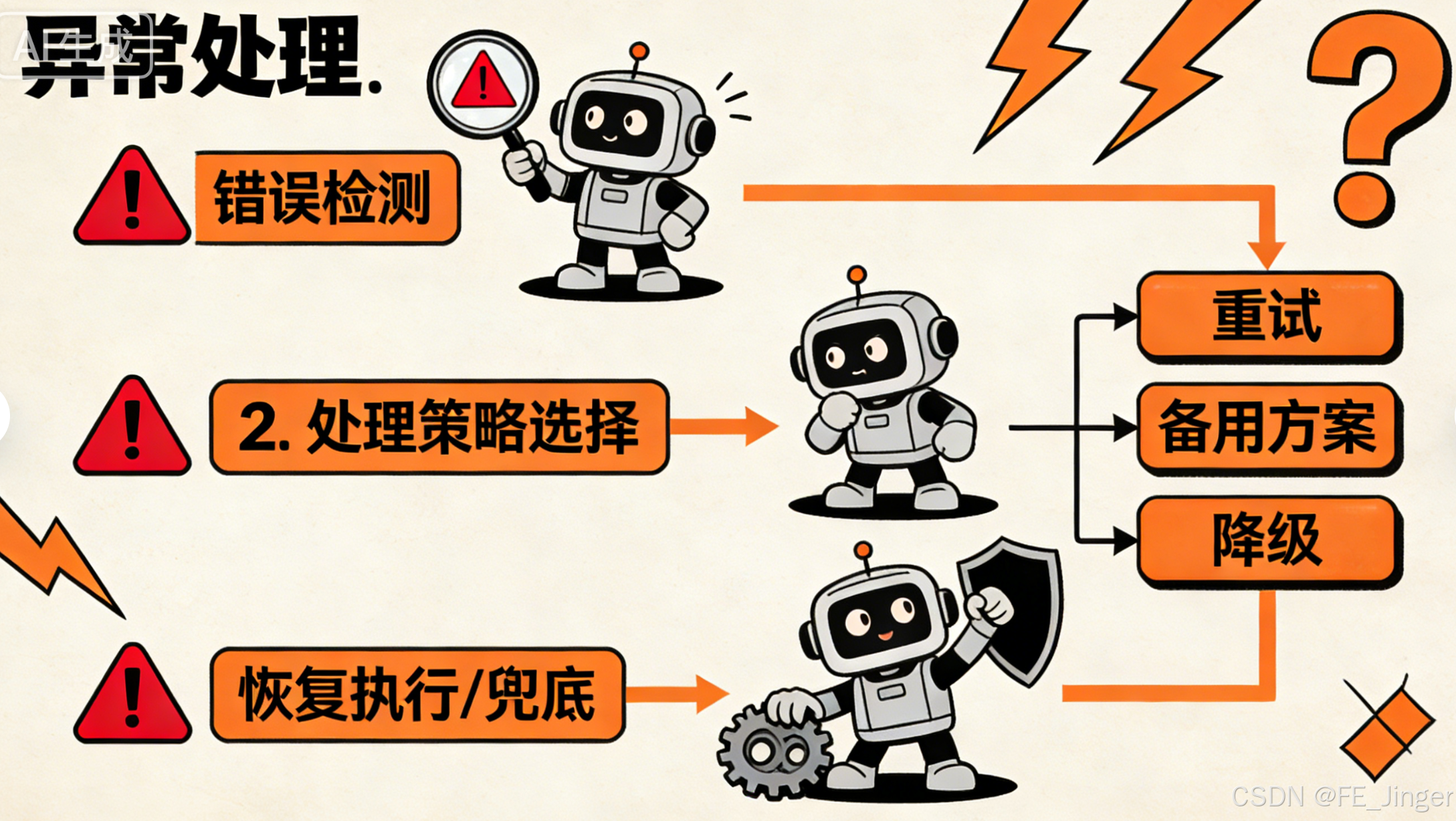
异常处理与恢复模式,是智能体应对"意外状况"的一套标准化流程------提前预判可能出问题的环节(比如工具调用失败、数据格式错误),再定义"发现问题→处理问题→恢复状态"的闭环,避免智能体因一点小故障就"罢工"。
关键机制:三步搞定"意外状况"
- 错误检测:识别异常类型,比如工具返回404(资源不存在)、数据格式不符合要求、网络超时等。
- 错误处理:按场景选策略------临时问题就"重试"(比如网络波动),无法解决就"备用方案"(比如主工具用不了换备用工具),严重问题就"优雅降级"(比如无法获取精准数据,返回近似结果并说明)。
- 恢复流程:要么回滚到上一个稳定状态,要么修正参数后重新执行,必要时通知人类介入。
实战解析:位置查询智能体的"兜底方案"
以"获取用户位置信息"为例,异常处理逻辑如下:
- 主流程:调用"精准位置工具"获取详细地址。
- 异常应对:若工具调用失败(比如用户地址不明确),自动切换到"模糊查询工具",提取城市信息返回大致结果。
- 最终兜底:若仍失败,告知用户并引导补充信息。
核心架构代码片段(简化版):
python
# 主工具:精准位置查询
primary_handler = Agent(
instruction="用get_precise_location工具获取地址",
tools=[get_precise_location]
)
# 备用工具:模糊位置查询
fallback_handler = Agent(
instruction="若主工具失败,提取城市用get_general_area工具",
tools=[get_general_area]
)
# 顺序执行,实现异常兜底
robust_agent = SequentialAgent(sub_agents=[primary_handler, fallback_handler])应用场景:哪里需要"抗风险"?
- 客服机器人:数据库不可用时,自动切换到FAQ回复或转人工。
- 数据处理智能体:遇到损坏文件时,跳过并记录,继续处理其他文件。
- 智能家居:控制设备失败时,重试后通知用户手动操作。
- 网页爬虫:遇到验证码或服务器错误时,暂停后重试或反馈失败。
三、两大模式的协同效应:1+1>2
目标设定监控和异常处理不是孤立的,结合起来才能让智能体更稳健:
- 目标为异常处理定优先级:比如"核心目标相关的异常"(如交易机器人的支付失败)优先处理,"次要目标异常"(如文案排版小问题)可延后。
- 异常处理保障目标达成:遇到问题不直接停摆,而是通过兜底方案推进,确保目标不跑偏。
四、图文建议(便于可视化呈现)
- 图1:目标设定与监控流程图(用户需求→设定SMART目标→执行→监控进度→纠偏/达成)。
- 图2:异常处理三步流程图(错误检测→处理策略选择→恢复执行/兜底)。
- 图3:两大模式协同示意图(目标为导向,异常处理为保障,闭环推进任务)。