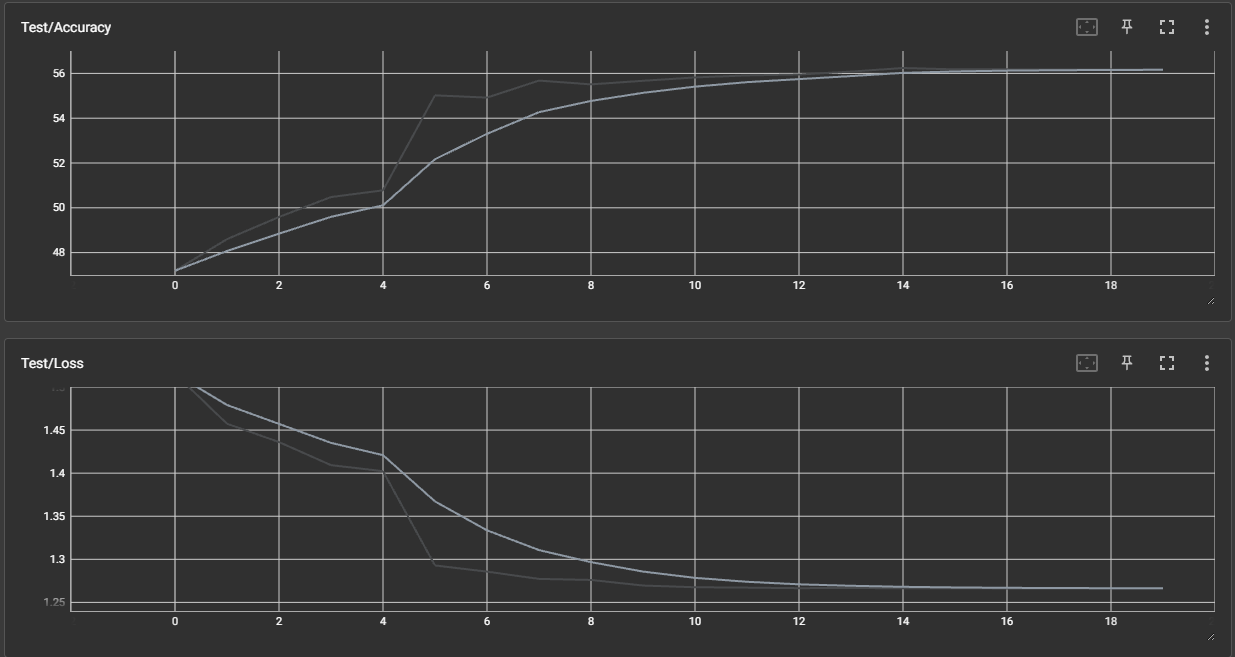
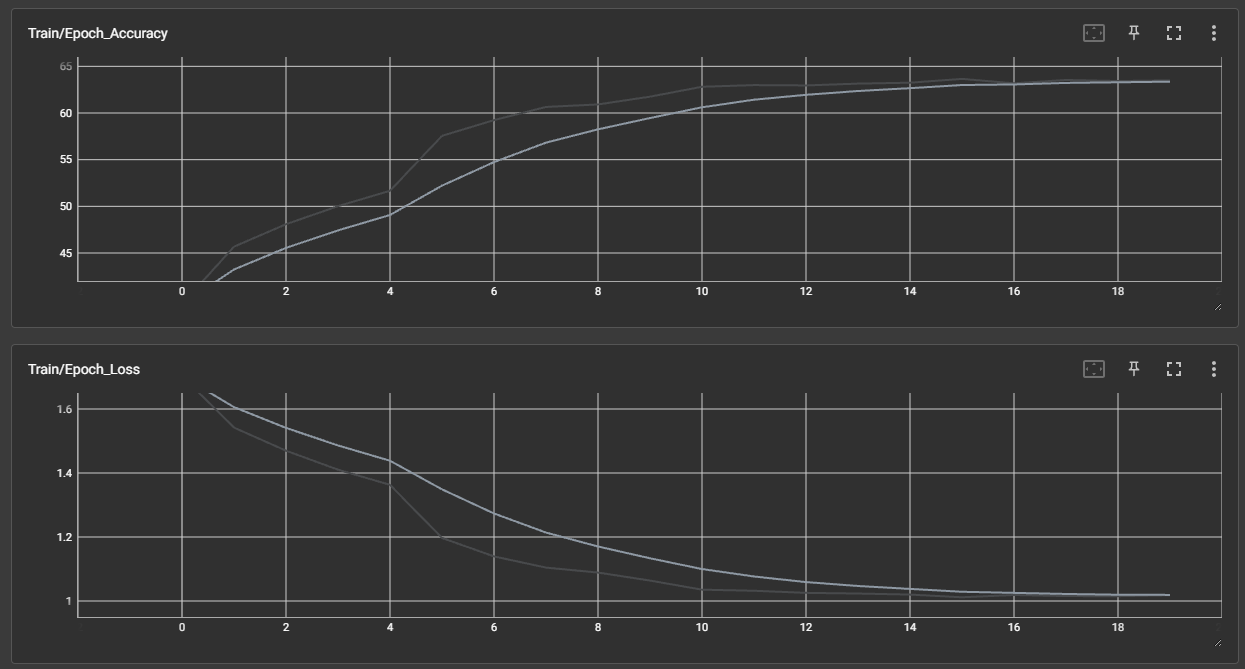
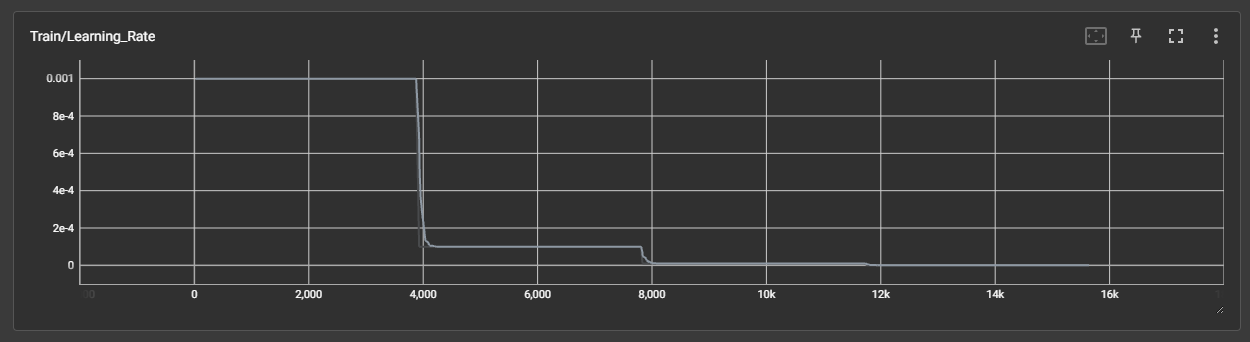
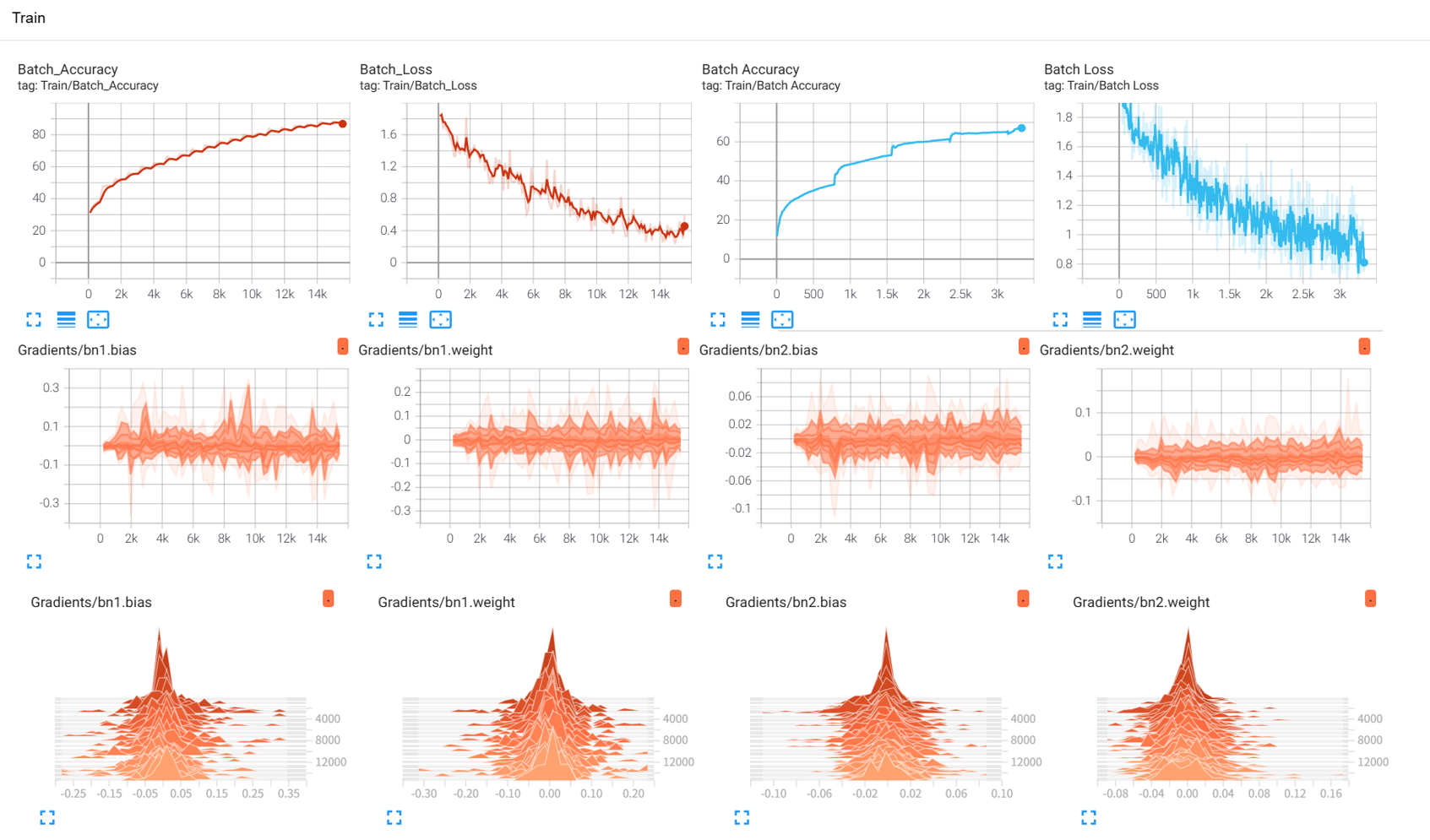
来自超大力王的友情提示:在用tensordoard的时候一定一定要用绝对位置,例如:tensorboard --logdir="D:\代码\archive (1)\runs\cifar10_mlp_experiment_2" 不然读取不了数据
知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
**作业:**对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 4. 定义MLP模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Linear(3072, 512)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.2)
self.layer2 = nn.Linear(512, 256)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.2)
self.layer3 = nn.Linear(256, 10)
def forward(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu1(x)
x = self.dropout1(x)
x = self.layer2(x)
x = self.relu2(x)
x = self.dropout2(x)
x = self.layer3(x)
return x
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 初始化模型
model = MLP()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 创建TensorBoard的SummaryWriter
log_dir = 'runs/cifar10_mlp_experiment'
# 自动生成唯一目录(避免覆盖)
if os.path.exists(log_dir):
i = 1
while os.path.exists(f"{log_dir}_{i}"):
i += 1
log_dir = f"{log_dir}_{i}"
# 创建日志目录并验证
os.makedirs(log_dir, exist_ok=True)
print(f"TensorBoard日志将保存在: {log_dir}")
# 检查目录是否创建成功
if not os.path.exists(log_dir):
raise FileNotFoundError(f"无法创建日志目录: {log_dir}")
writer = SummaryWriter(log_dir)
# 模型保存路径
model_save_dir = 'saved_models'
os.makedirs(model_save_dir, exist_ok=True)
best_model_path = os.path.join(model_save_dir, 'best_model.pth')
final_model_path = os.path.join(model_save_dir, 'final_model.pth')
# 5. 训练模型(优化TensorBoard日志写入)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):
model.train()
best_accuracy = 0.0
global_step = 0
# 可视化模型结构(添加错误处理和调试打印)
try:
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images)
print(f"✅ 已记录模型图至TensorBoard")
print(f"成功获取训练数据批次,图像尺寸: {images.shape}") # 调试打印
except Exception as e:
print(f"⚠️ 模型图记录失败: {e}")
return 0.0 # 训练失败时提前返回
# 可视化原始图像样本(添加调试打印)
img_grid = torchvision.utils.make_grid(images[:8].cpu())
writer.add_image('原始训练图像', img_grid, global_step=0)
print(f"✅ 已记录原始图像至TensorBoard")
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 统计准确率和损失
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每批次都记录日志(简化调试)
writer.add_scalar('Train/Batch_Loss', loss.item(), global_step)
writer.add_scalar('Train/Batch_Accuracy', 100. * correct / total, global_step)
writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)
# 每100个批次打印一次信息
if (batch_idx + 1) % 100 == 0:
batch_loss = loss.item()
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
global_step += 1
# 更新学习率
scheduler.step()
# 计算当前epoch的平均训练损失和准确率
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# 记录每个epoch的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
# 限制错误样本数量
max_wrong_samples = 100
wrong_images = []
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集错误样本
wrong_mask = (predicted != target).cpu()
if wrong_mask.sum() > 0 and len(wrong_images) < max_wrong_samples:
num_add = min(max_wrong_samples - len(wrong_images), wrong_mask.sum())
wrong_batch_images = data[wrong_mask][:num_add].cpu()
wrong_batch_labels = target[wrong_mask][:num_add].cpu()
wrong_batch_preds = predicted[wrong_mask][:num_add].cpu()
wrong_images.extend(wrong_batch_images)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录每个epoch的测试指标
writer.add_scalar('Test/Loss', epoch_test_loss, epoch)
writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 保存最佳模型
if epoch_test_acc > best_accuracy:
best_accuracy = epoch_test_acc
torch.save(model.state_dict(), best_model_path)
print(f"✅ 保存最佳模型(准确率: {best_accuracy:.2f}%)")
# 可视化错误预测样本(每个epoch都记录,便于观察)
if len(wrong_images) > 0:
display_count = min(8, len(wrong_images))
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
wrong_text = []
for i in range(display_count):
true_label = classes[wrong_labels[i]]
pred_label = classes[wrong_preds[i]]
wrong_text.append(f'True: {true_label}, Pred: {pred_label}')
writer.add_image('错误预测样本', wrong_img_grid, global_step=epoch)
writer.add_text('错误预测标签', '\n'.join(wrong_text), global_step=epoch)
model.train() # 切回训练模式
# 保存最终模型
torch.save(model.state_dict(), final_model_path)
print(f"模型已保存至 {final_model_path}")
# 刷新并关闭TensorBoard写入器
writer.flush()
writer.close()
return best_accuracy
# Windows环境下的多进程兼容处理
if __name__ == "__main__":
import torch.multiprocessing as mp
mp.set_start_method('spawn') # 关键修改:解决Windows多进程问题
epochs = 20
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir={log_dir}` 启动TensorBoard")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}%")
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 4. 定义MLP模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Linear(3072, 512)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.2)
self.layer2 = nn.Linear(512, 256)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.2)
self.layer3 = nn.Linear(256, 10)
def forward(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu1(x)
x = self.dropout1(x)
x = self.layer2(x)
x = self.relu2(x)
x = self.dropout2(x)
x = self.layer3(x)
return x
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 初始化模型
model = MLP()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 创建TensorBoard的SummaryWriter
log_dir = 'runs/cifar10_mlp_experiment'
# 自动生成唯一目录(避免覆盖)
if os.path.exists(log_dir):
i = 1
while os.path.exists(f"{log_dir}_{i}"):
i += 1
log_dir = f"{log_dir}_{i}"
# 创建日志目录并验证
os.makedirs(log_dir, exist_ok=True)
print(f"TensorBoard日志将保存在: {log_dir}")
# 检查目录是否创建成功
if not os.path.exists(log_dir):
raise FileNotFoundError(f"无法创建日志目录: {log_dir}")
writer = SummaryWriter(log_dir)
# 模型保存路径
model_save_dir = 'saved_models'
os.makedirs(model_save_dir, exist_ok=True)
best_model_path = os.path.join(model_save_dir, 'best_model.pth')
final_model_path = os.path.join(model_save_dir, 'final_model.pth')
# 5. 训练模型(优化TensorBoard日志写入)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):
model.train()
best_accuracy = 0.0
global_step = 0
# 可视化模型结构(添加错误处理和调试打印)
try:
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images)
print(f"✅ 已记录模型图至TensorBoard")
print(f"成功获取训练数据批次,图像尺寸: {images.shape}") # 调试打印
except Exception as e:
print(f"⚠️ 模型图记录失败: {e}")
return 0.0 # 训练失败时提前返回
# 可视化原始图像样本(添加调试打印)
img_grid = torchvision.utils.make_grid(images[:8].cpu())
writer.add_image('原始训练图像', img_grid, global_step=0)
print(f"✅ 已记录原始图像至TensorBoard")
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 统计准确率和损失
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每批次都记录日志(简化调试)
writer.add_scalar('Train/Batch_Loss', loss.item(), global_step)
writer.add_scalar('Train/Batch_Accuracy', 100. * correct / total, global_step)
writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)
# 每100个批次打印一次信息
if (batch_idx + 1) % 100 == 0:
batch_loss = loss.item()
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
global_step += 1
# 更新学习率
scheduler.step()
# 计算当前epoch的平均训练损失和准确率
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# 记录每个epoch的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
# 限制错误样本数量
max_wrong_samples = 100
wrong_images = []
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集错误样本
wrong_mask = (predicted != target).cpu()
if wrong_mask.sum() > 0 and len(wrong_images) < max_wrong_samples:
num_add = min(max_wrong_samples - len(wrong_images), wrong_mask.sum())
wrong_batch_images = data[wrong_mask][:num_add].cpu()
wrong_batch_labels = target[wrong_mask][:num_add].cpu()
wrong_batch_preds = predicted[wrong_mask][:num_add].cpu()
wrong_images.extend(wrong_batch_images)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录每个epoch的测试指标
writer.add_scalar('Test/Loss', epoch_test_loss, epoch)
writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 保存最佳模型
if epoch_test_acc > best_accuracy:
best_accuracy = epoch_test_acc
torch.save(model.state_dict(), best_model_path)
print(f"✅ 保存最佳模型(准确率: {best_accuracy:.2f}%)")
# 可视化错误预测样本(每个epoch都记录,便于观察)
if len(wrong_images) > 0:
display_count = min(8, len(wrong_images))
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
wrong_text = []
for i in range(display_count):
true_label = classes[wrong_labels[i]]
pred_label = classes[wrong_preds[i]]
wrong_text.append(f'True: {true_label}, Pred: {pred_label}')
writer.add_image('错误预测样本', wrong_img_grid, global_step=epoch)
writer.add_text('错误预测标签', '\n'.join(wrong_text), global_step=epoch)
model.train() # 切回训练模式
# 保存最终模型
torch.save(model.state_dict(), final_model_path)
print(f"模型已保存至 {final_model_path}")
# 刷新并关闭TensorBoard写入器
writer.flush()
writer.close()
return best_accuracy
# Windows环境下的多进程兼容处理
if __name__ == "__main__":
import torch.multiprocessing as mp
mp.set_start_method('spawn') # 关键修改:解决Windows多进程问题
epochs = 20
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir={log_dir}` 启动TensorBoard")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}%")