目录
一、散点图
特点
通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密度和趋势反映相关性强弱。
应用场景
探索性数据分析、验证变量间关系假设,如身高与体重的关系、温度与销售额的关联。
实现过程
python
import numpy as np
import matplotlib.pyplot as plt
# 设置支持中文的字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "sans-serif"]
# 解决负号显示问题
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据
np.random.seed(42)
x = np.random.randn(100)
y = 2 * x + np.random.randn(100) * 0.5
# 绘制散点图
plt.figure(figsize=(8, 6))
plt.scatter(x, y, color='blue', alpha=0.7, s=30)
plt.title('散点图:展示两变量线性关系')
plt.xlabel('变量X')
plt.ylabel('变量Y')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
# 计算相关系数
correlation = np.corrcoef(x, y)[0, 1]
print(f'皮尔逊相关系数: {correlation:.4f}')结果
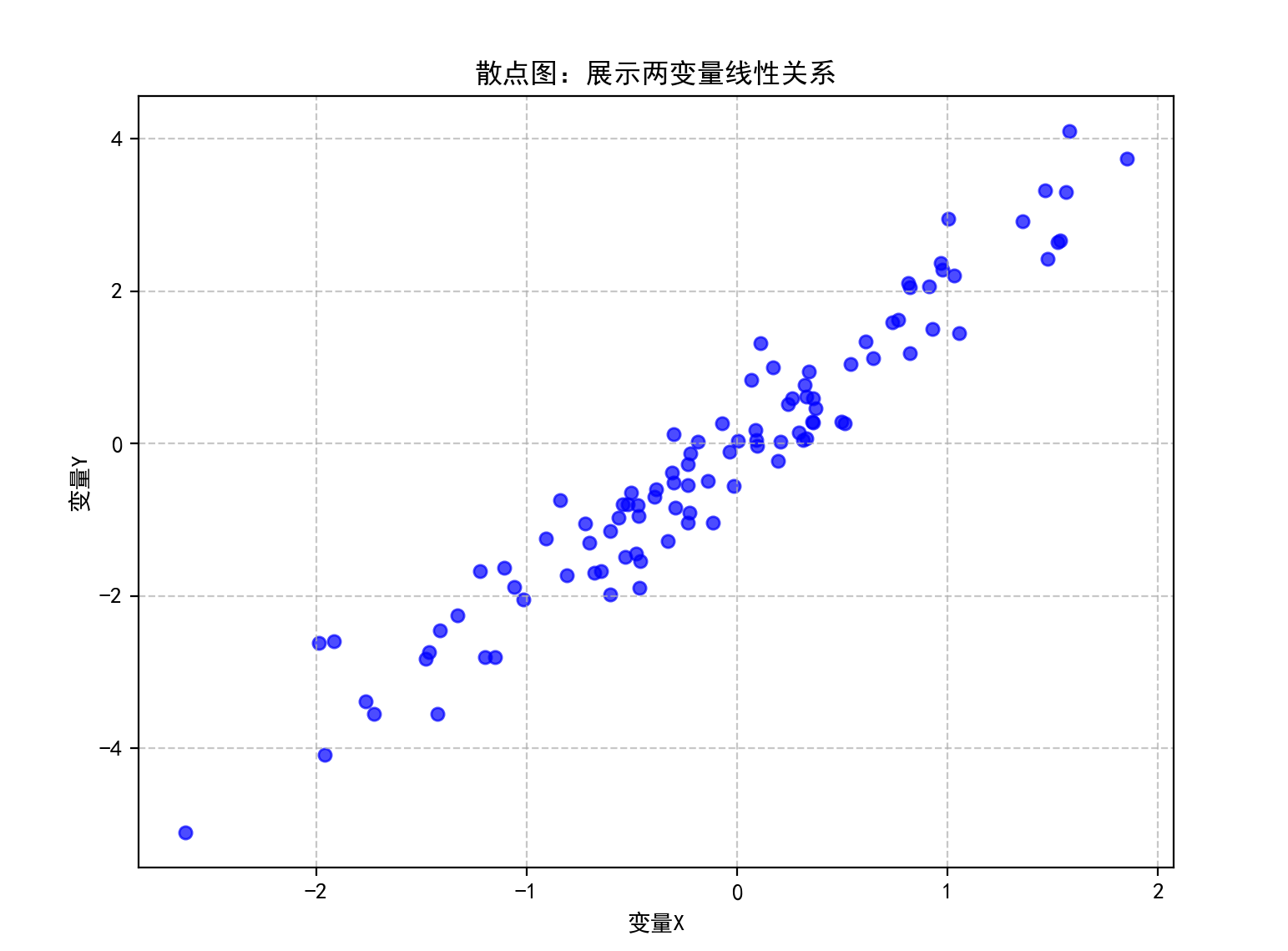
二、气泡图
特点
在散点图基础上增加第三个变量(气泡大小),可展示三维数据关系,气泡颜色还可表示第四维变量。
应用场景
市场分析(如销售额、利润、市场份额)、城市数据可视化(人口、GDP、面积)。
实现过程
python
import plotly.express as px
import pandas as pd
import numpy as np
# 设置随机种子
np.random.seed(42)
# 生成模拟数据
n_countries = 20
countries = [
'中国', '美国', '日本', '德国', '法国', '英国', '意大利', '加拿大',
'俄罗斯', '巴西', '印度', '澳大利亚', '西班牙', '墨西哥', '韩国',
'印度尼西亚', '土耳其', '沙特阿拉伯', '瑞士', '荷兰'
]
# 生成随机数据
gdp_per_capita = np.random.randint(1000, 80000, n_countries)
population = np.random.randint(5e6, 1.5e9, n_countries)
life_expectancy = np.random.uniform(60, 85, n_countries)
region = np.random.choice(['亚洲', '欧洲', '北美洲', '南美洲', '非洲', '大洋洲'], n_countries)
# 创建DataFrame
df = pd.DataFrame({
'国家': countries,
'人均GDP': gdp_per_capita,
'人口': population,
'预期寿命': life_expectancy,
'地区': region
})
# 创建气泡图
fig = px.scatter(df, x="人均GDP", y="预期寿命", size="人口", color="地区",
hover_name="国家", log_x=True, size_max=60,
title="世界各国发展指标气泡图",
labels={
"人均GDP": "人均GDP (美元)",
"预期寿命": "预期寿命 (岁)",
"地区": "地理区域"
})
# 更新布局
fig.update_layout(
font=dict(family="SimHei", size=12),
legend_title="地理区域",
height=600,
width=1000
)
# 添加趋势线
fig.add_traces(
px.scatter(df, x="人均GDP", y="预期寿命", trendline="ols").data[1]
)
# 显示图表
fig.show()
# 导出为HTML文件
fig.write_html("bubble_chart.html")结果
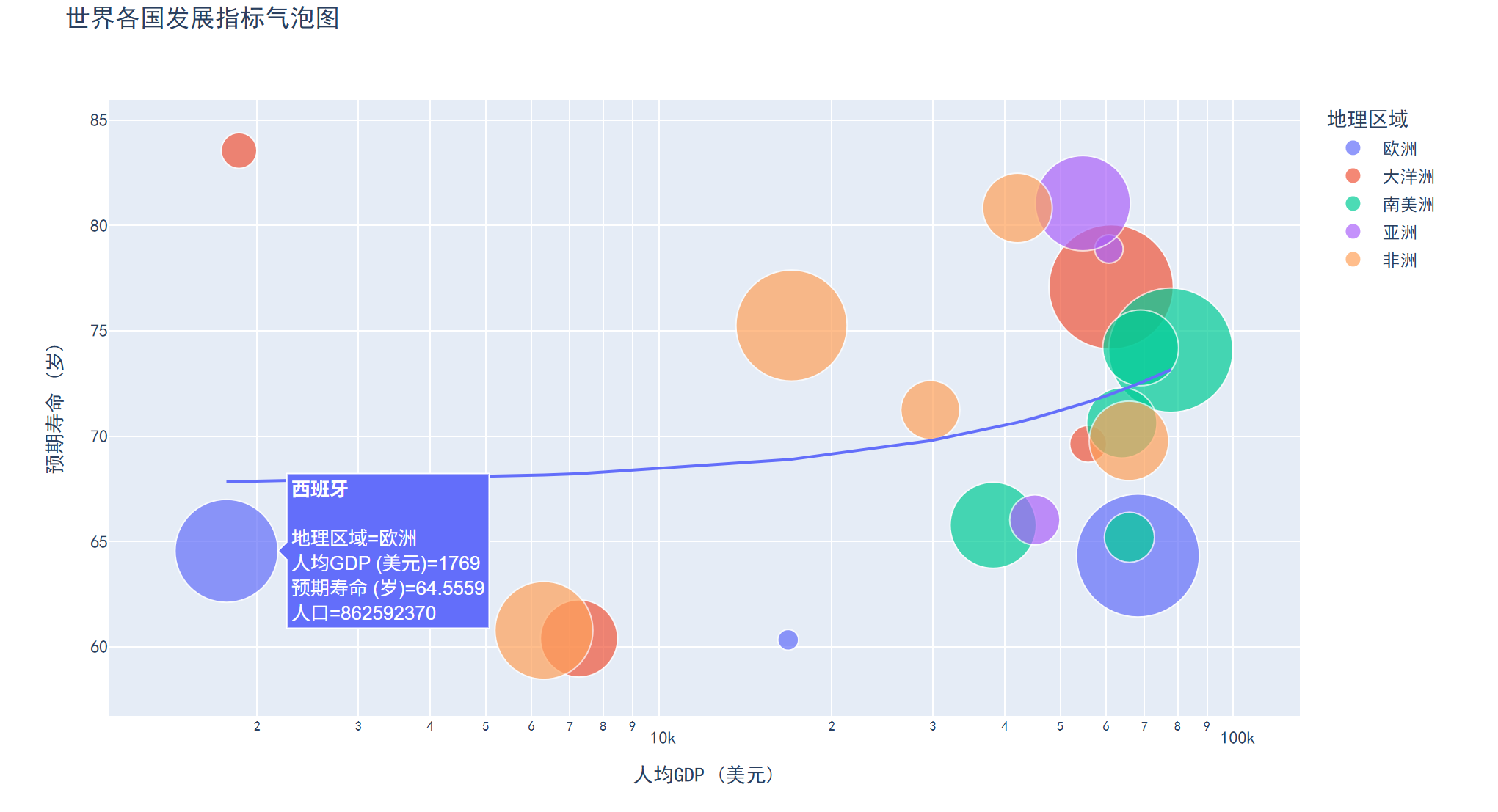
三、相关图
特点
展示多个变量间的相关系数矩阵,通常以数值或图形(如颜色、形状)表示相关强度和方向。
应用场景
多变量数据分析、特征选择(如机器学习前筛选相关变量)。
实现过程
python
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据
np.random.seed(42)
data = pd.DataFrame({
'var1': np.random.randn(100),
'var2': 0.8 * np.random.randn(100) + 0.2 * np.random.randn(100),
'var3': -0.5 * np.random.randn(100) + 0.5 * np.random.randn(100),
'var4': np.random.randn(100)
})
# 计算相关系数矩阵
corr_matrix = data.corr()
# 绘制相关图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f',
linewidths=1, cbar_kws={'label': '相关系数'})
plt.title('相关系数矩阵图')
plt.show()结果
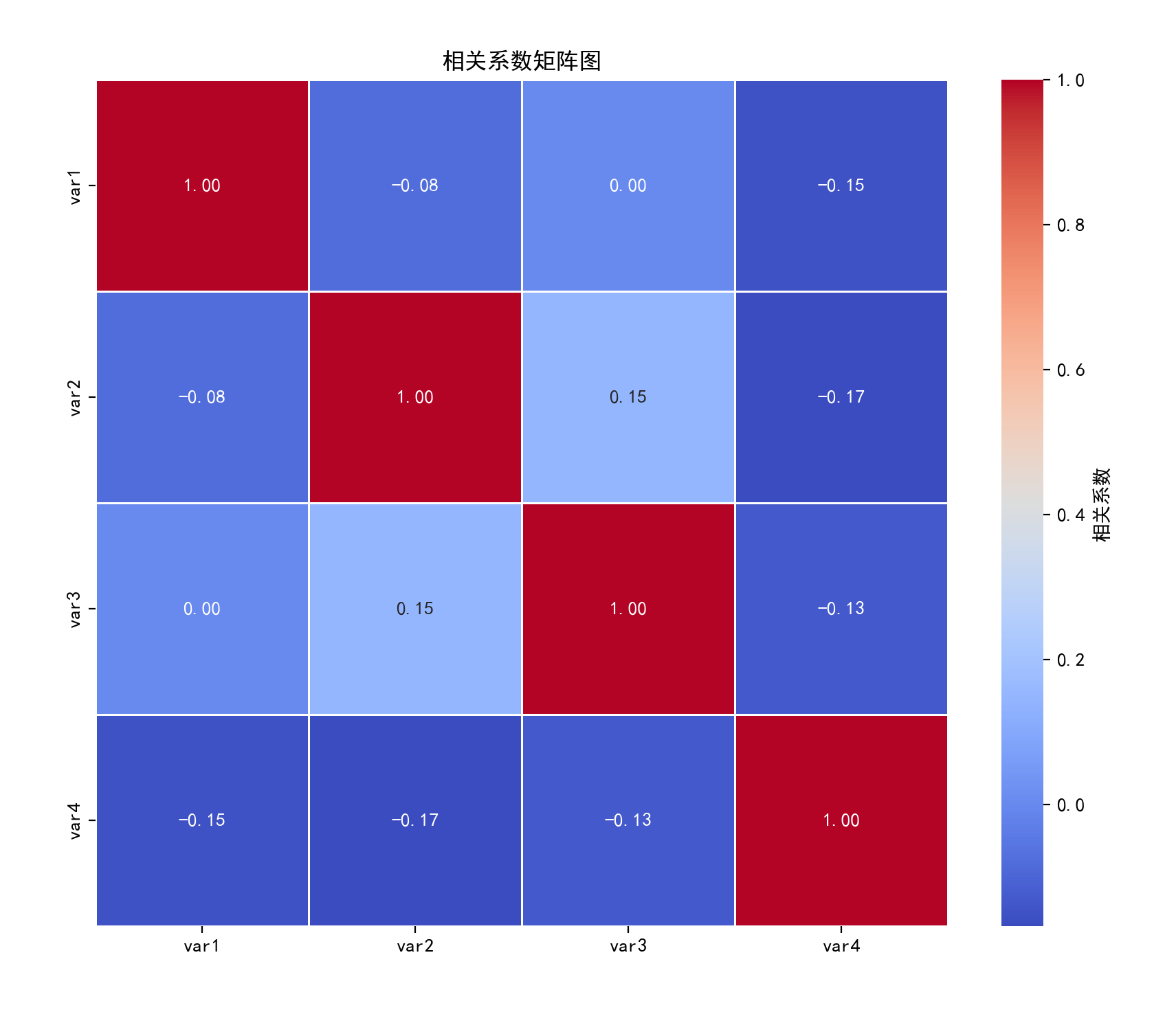
四、热力图
特点
用颜色矩阵展示数据值大小,可直观呈现二维数据的分布模式和热点区域。
应用场景
基因表达数据、时间序列数据(如年度销售热力图)、矩阵数据可视化。
实现过程
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.cluster import hierarchy
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据:月度销售数据
np.random.seed(42)
n_products = 12
n_months = 12
# 创建产品名称和月份名称
products = [f'产品{i+1}' for i in range(n_products)]
months = [f'{i+1}月' for i in range(n_months)]
# 生成基础销售数据(有季节性和产品类别效应)
base_sales = np.random.rand(n_products, n_months) * 1000
# 添加季节性效应
seasonal_effect = np.sin(np.linspace(0, 2*np.pi, n_months)) * 300
for i in range(n_products):
base_sales[i, :] += seasonal_effect * (0.5 + i/24)
# 添加产品类别效应
category_effect = np.random.rand(n_products) * 500
for i in range(n_products):
base_sales[i, :] += category_effect[i]
# 添加随机噪声
sales_data = base_sales + np.random.randn(n_products, n_months) * 100
# 转换为DataFrame
df = pd.DataFrame(sales_data, index=products, columns=months)
plt.figure(figsize=(12, 10))
sns.heatmap(df, cmap="YlGnBu", annot=True, fmt=".0f",
linewidths=0.5, cbar_kws={"label": "销售额"})
plt.title('月度产品销售额热力图')
plt.tight_layout()
plt.show()结果
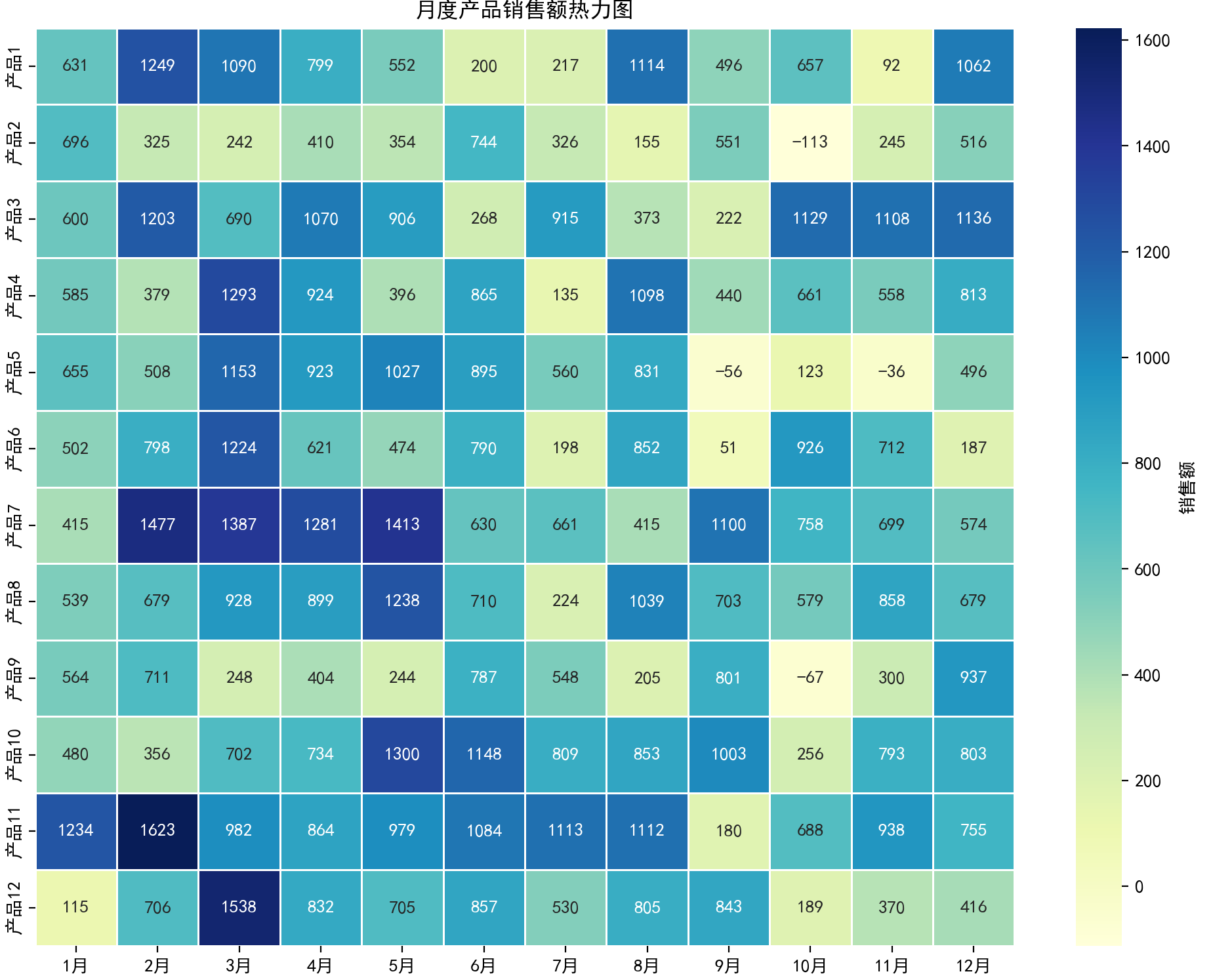
五、二维密度图
特点
通过颜色或等高线展示二维数据的分布密度,比散点图更适合大数据量场景,可识别数据聚类和分布形态。
应用场景
概率密度分析、金融数据分布(如股票收益率)、空间数据热点分析。
实现过程
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
n_samples = 1000
mean = [0, 0]
cov = [[1, 0.7], [0.7, 1]]
x, y = np.random.multivariate_normal(mean, cov, n_samples).T
# 创建DataFrame
df_single = pd.DataFrame({
'X': x,
'Y': y
})
# 绘制二维密度图
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', data=df_single, fill=True, cmap='Blues', alpha=0.7)
plt.title('二维密度图')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()结果

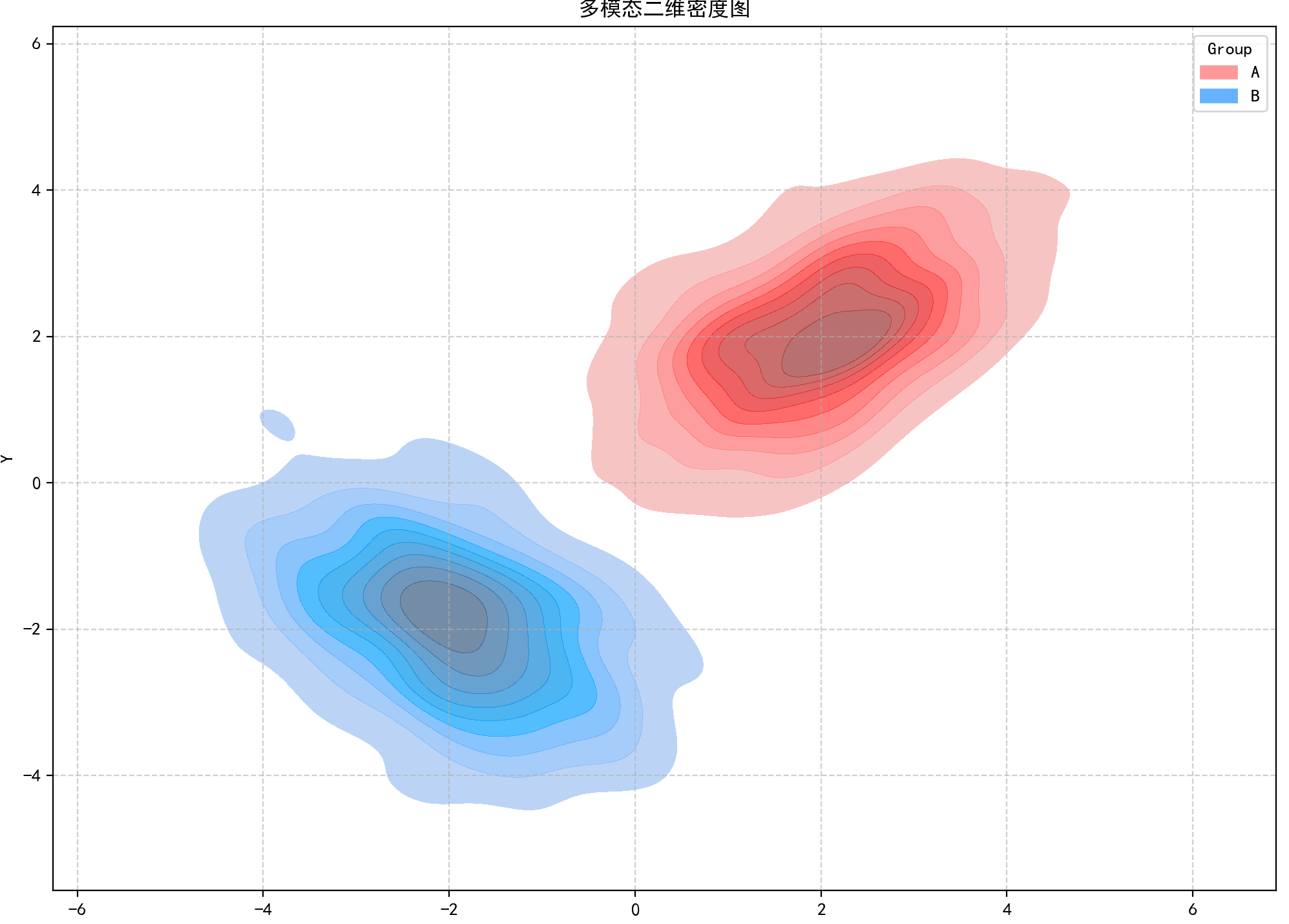
六、多模态二维密度图
特点
捕捉数据中多个密度峰值(模态),反映复杂集群结构,无需预设聚类数。
应用场景
客户分群(消费行为)、金融风险(市场状态分类)、生物信息(细胞亚型)。
实现过程
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 2. 多模态分布
# 创建两个不同的分布
n1 = 800
n2 = 500
# 第一个分布
mean1 = [2, 2]
cov1 = [[1, 0.5], [0.5, 1]]
x1, y1 = np.random.multivariate_normal(mean1, cov1, n1).T
# 第二个分布
mean2 = [-2, -2]
cov2 = [[1, -0.5], [-0.5, 1]]
x2, y2 = np.random.multivariate_normal(mean2, cov2, n2).T
# 合并数据
x_multi = np.concatenate([x1, x2])
y_multi = np.concatenate([y1, y2])
groups = np.concatenate([['A']*n1, ['B']*n2])
# 创建DataFrame
df_multi = pd.DataFrame({
'X': x_multi,
'Y': y_multi,
'Group': groups
})
# 绘制多模态二维密度图
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', hue='Group', data=df_multi,
fill=True, common_norm=False, alpha=0.7,
palette=['#FF9999', '#66B2FF'])
plt.title('多模态二维密度图')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()结果
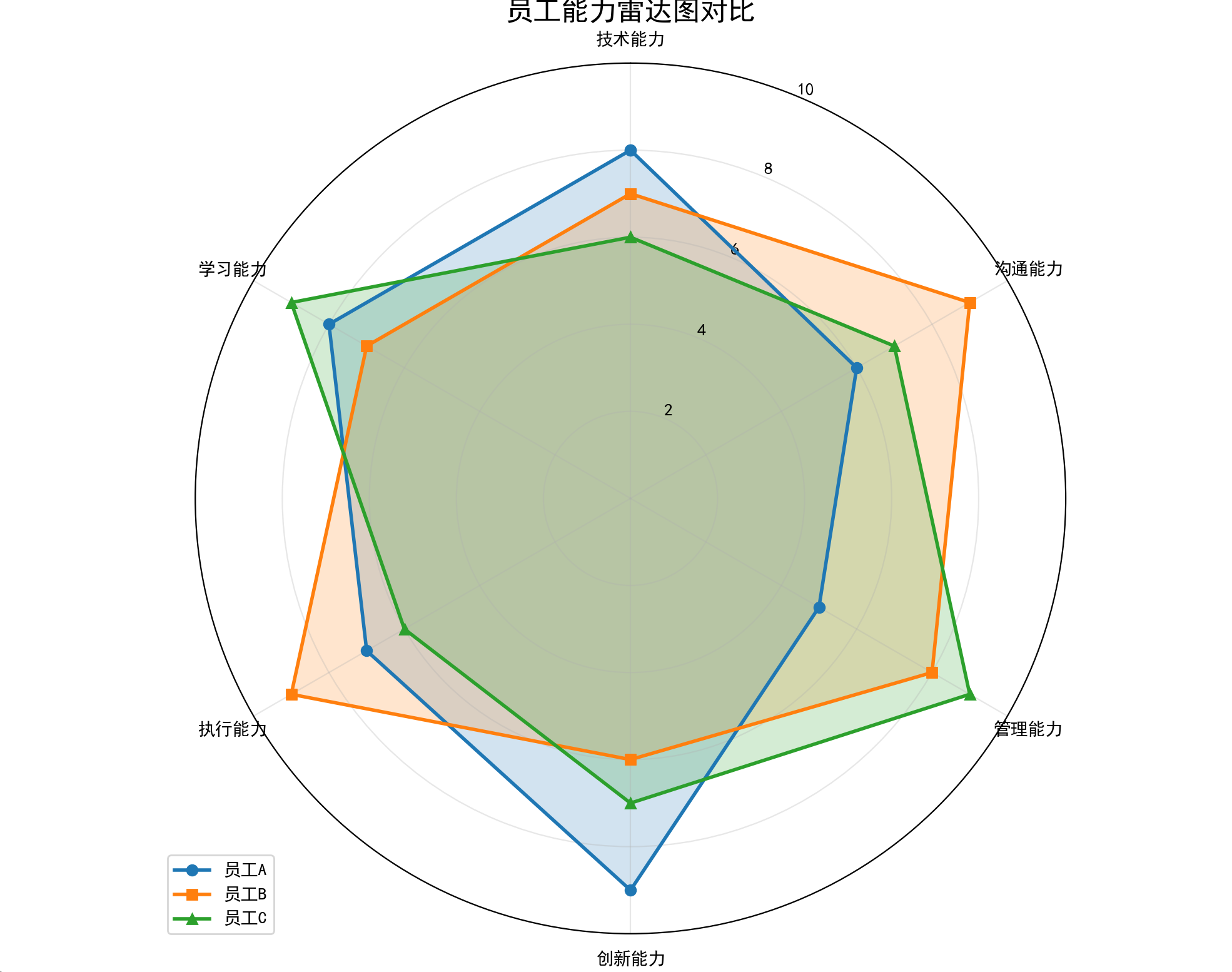
七、雷达图
特点
以原点为中心辐射出多条坐标轴,每个样本用多边形连接各维度值,直观比较多变量综合表现。适合展示样本在多个维度的均衡性或偏科情况。
应用场景
产品多维度评分(如手机的性能、价格、续航、拍照等)。人才评估(如员工的沟通、技术、管理、创新能力)。竞争对手分析(多指标对比)。
实现过程
python
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False
# 定义评估维度
dimensions = ['技术能力', '沟通能力', '管理能力', '创新能力', '执行能力', '学习能力']
n_dims = len(dimensions)
# 生成3名员工的评分数据(1-10分)
employee1 = [8, 6, 5, 9, 7, 8] # 技术和创新突出
employee2 = [7, 9, 8, 6, 9, 7] # 沟通和执行突出
employee3 = [6, 7, 9, 7, 6, 9] # 管理和学习突出
# 准备雷达图数据(闭合多边形)
angles = np.linspace(0, 2*np.pi, n_dims, endpoint=False).tolist()
employee1 += employee1[:1]
employee2 += employee2[:1]
employee3 += employee3[:1]
angles += angles[:1]
# 绘制雷达图
plt.figure(figsize=(10, 10))
ax = plt.subplot(111, polar=True)
# 绘制各维度网格线
ax.set_theta_offset(np.pi/2) # 起始角度设为上方
ax.set_theta_direction(-1) # 顺时针旋转
ax.set_thetagrids(np.degrees(angles[:-1]), dimensions)
ax.set_ylim(0, 10)
ax.grid(True, alpha=0.3)
# 绘制员工评分
ax.plot(angles, employee1, 'o-', linewidth=2, label='员工A')
ax.fill(angles, employee1, alpha=0.2)
ax.plot(angles, employee2, 's-', linewidth=2, label='员工B')
ax.fill(angles, employee2, alpha=0.2)
ax.plot(angles, employee3, '^-', linewidth=2, label='员工C')
ax.fill(angles, employee3, alpha=0.2)
# 添加图例和标题
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
plt.title('员工能力雷达图对比', fontsize=16)
plt.tight_layout()
plt.show()结果
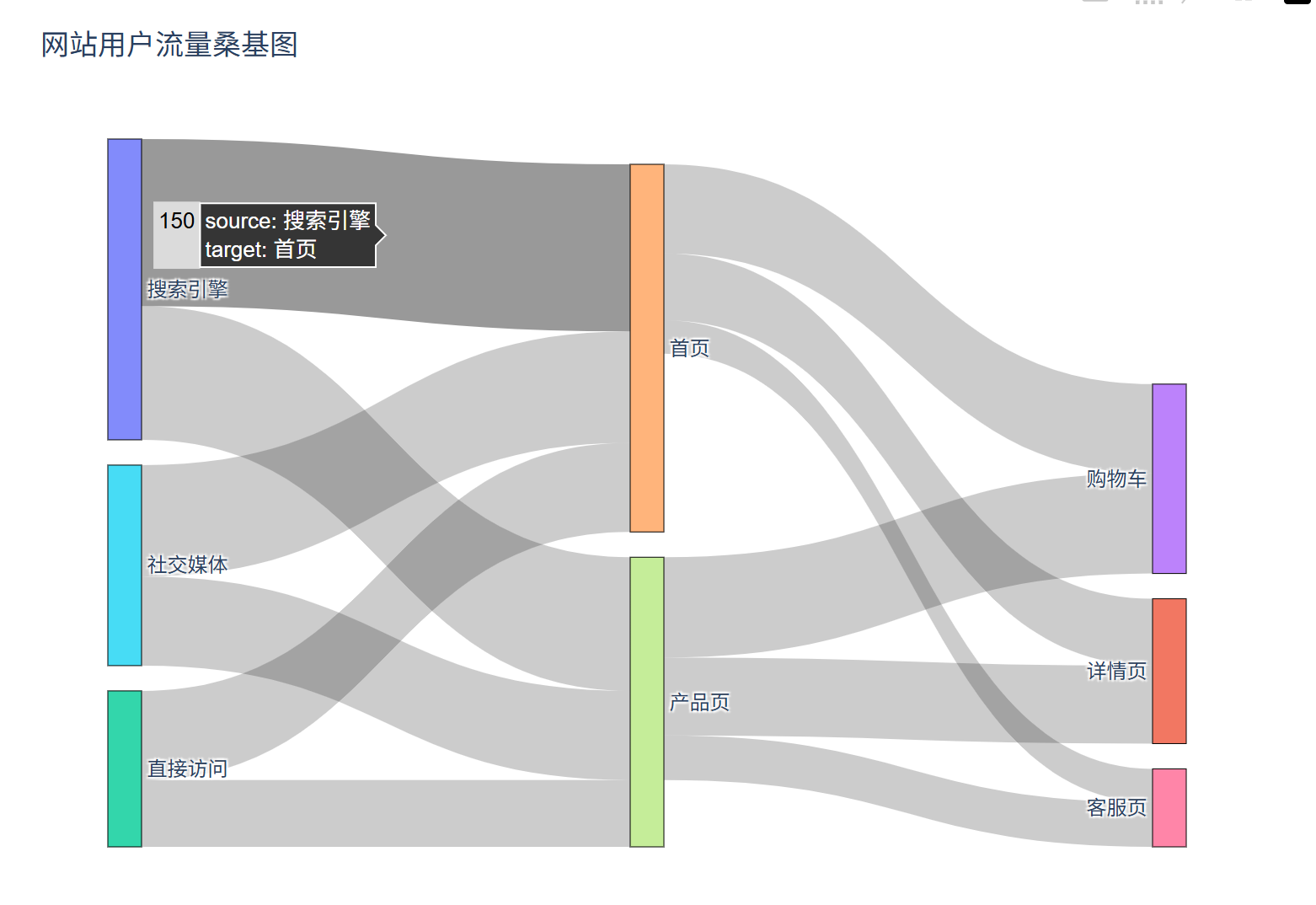
八、桑基图
特点
用带箭头的流线表示数据流向,流线宽度反映流量大小,适合展示物质、能量、资金等的传递路径与分配比例。
应用场景
供应链分析(原材料→加工→成品的价值流动)。网站流量分析(用户从不同渠道到各页面的跳转路径)。
实现过程
python
import plotly.graph_objects as go
import pandas as pd
# 生成用户流量数据(渠道→页面→转化的流向)
source = ['搜索引擎', '社交媒体', '直接访问', '搜索引擎', '社交媒体', '直接访问',
'产品页', '产品页', '产品页', '首页', '首页', '首页']
target = ['首页', '首页', '首页', '产品页', '产品页', '产品页',
'购物车', '详情页', '客服页', '购物车', '详情页', '客服页']
value = [150, 100, 80, 120, 80, 60, 90, 70, 40, 80, 60, 30] # 流量值
# 创建DataFrame
data = pd.DataFrame({
'source': source,
'target': target,
'value': value
})
# 定义节点标签
all_nodes = list(set(source + target))
node_indices = {node: i for i, node in enumerate(all_nodes)}
data['source_idx'] = data['source'].map(node_indices)
data['target_idx'] = data['target'].map(node_indices)
# 绘制桑基图
fig = go.Figure(data=[go.Sankey(
node=dict(
pad=15,
thickness=20,
line=dict(color="black", width=0.5),
label=all_nodes
),
link=dict(
source=data['source_idx'],
target=data['target_idx'],
value=data['value']
)
)])
# 更新布局
fig.update_layout(
title_text="网站用户流量桑基图",
width=800,
height=600
)
fig.show()结果
九、总结
| 图表类型 | 特点 | 应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 散点图 | 两点坐标展示变量关系 | 探索两变量关联、异常值检测 | 直观易读,发现线性关系 | 仅支持两变量,大数据量易乱 |
| 气泡图 | 散点 + 大小 / 颜色展示 3-4 维数据 | 市场分析、城市数据可视化 | 多维数据同屏展示,信息密度高 | 维度过多易重叠,布局复杂 |
| 相关图 | 矩阵展示多变量相关系数 | 特征选择、多变量探索 | 全面呈现相关性,数值颜色双标注 | 仅反映线性相关,需结合验证 |
| 热力图 | 颜色矩阵展示二维数据分布 | 基因表达、时间序列、点击数据 | 突出热点区域,适合模式识别 | 数值精度低,颜色映射需谨慎 |
| 二维密度图 | 等高线 / 颜色展示数据分布密度 | 金融数据、空间数据、生物数据 | 识别聚类和密度峰值,适合大数据 | 抽象度高,参数影响结果 |
| 多模态密度图 | 捕捉数据多个密度峰值 | 客户分群、金融风险、细胞亚型 | 自动识别集群,无需预设聚类数 | 计算复杂,对噪声敏感 |
| 雷达图 | 多轴多边形展示多维度均衡性 | 产品对比、能力评估、综合实力分析 | 直观展示优劣维度,适合综合评估 | 维度限≤8,数值比较不精确 |
| 桑基图 | 流线宽度展示数据流向与流量 | 供应链、流量分析、贸易进出口 | 清晰展示流动路径,流量对比直观 | 节点过多易混乱,布局较复杂 |