前言
简单地介绍一下负责代码分析的语法分析器的相关内容,接着对描述cbc的解析器所使用的JavaCC这一工具的概要进行说明。
一、语法分析的方法
将对语法分析的一般方法进行说明
1.代码分析中的问题点
代码的分析可不是用普通的方法就可以解决的。例如,考虑一下C语言中的算式。C语言中的8+2-3应该解释为(8+2)-3,但8+23的话就应该解释为8+(2 3)。分析算式时,一定要考虑运算符的优先级(operator precedence),大家是不是想到了用栈实现的逆波兰表达式了哦,哈哈。
C语言中能够填写数字的地方可以用变量或数组、结构体的元素来替代,甚至还可以是函数调用。对于这种多样性,编译器都必须能够处理。
而且,无论是算式、变量还是函数调用,如果出现在注释中,则不需要处理。同样,出现在字符串中也不需要处理。编译器必须考虑到这种因上下文而产生的差异。
如上所述,在分析编程语言的代码时,需要考虑到各种因素,的确非常棘手。
2.代码分析的一般规律
为了处理分析代码时产生的各类问题,人们尝试了各种手段,现在编程语言的代码分析在多数范围内都有一般规律可循。只要遵循一般规律,绝大多数的编程语言都能够顺利分析。
另外,如果将编程语言设计得能够根据一般规律进行代码分析,那么之后的处理就会容易得多。C♭就是这样设计的一种语言。它将C语言中不符合代码分析一般规律的部分进行了改良,尽量简化了代码分析处理。
换言之,C♭语言中所修改的规范也就是利用一般规律难以处理的规范。关于这部分规范的内容,以及原来的规范为什么使用一般规律难以处理,后文将进行适当的说明。
3.词法分析、语法分析、语义分析
接着,我们就来具体了解一下代码分析的一般规律。第1章中提到了代码分析可分为语法分析和语义分析两部分。一般来说,语法分析还可以继续细分为以下2个阶段。
- 词法分析
- 语法分析
首先解释一下词法分析。
词法分析(lexical analyze)就是将代码分割为一个个的单词,也可以称为扫描(scan)。 举个栗子,词法分析就是将x = 1 + 2这样的程序分割为"x"" ="" 1"" +"" 2"这样5个单词。
并且在该过程中,会将空白符和注释这种对程序没有实际意义的部分剔除。正因为预先有了词法分析,语法分析器才可以只处理有意义的单词,进而实现简化处理。
负责词法分析的模块称为词法分析器(lexical analyzer),又称扫描器(scanner)。理想的情况是将词法分析、语法分析、语义分析这3个阶段做成3个独立的模块,这样的代码是最优美的。但实际上,这3个阶段并不能明确地分割开。现有的编程语言中,能将词法分析、语法分析、语义分析清晰地分割开的恐怕也不多。因此,比较实际的做法是以结构简洁为目标,在意识到存在3个阶段的基础上,进行各类尝试和修改。
我们制作的C♭编译器的词法分析为独立的模块,但语义分析的一部分将放在语法分析的模块中来实现。
4.扫描器的动作
接着,让我们更深入地了解一下这部分内容。先从扫描器(即词法分析器)的结构开始,以下面的C♭代码为例。
c
import stdio;
int
main(int argc, char** argv)
{
printf("Hello, World!\n"); /* 打个招呼吧 */
return 0;
}这就是所谓的Hello,World!程序。扫描器将此代码分割为如下的单词:
c
import
stdio
;
int
main
(
int
argc
,
char
*
*
argv
)
{
printf
(
"Hello, World!\n"
)
;
return
0
;
}需要注意的是,这里已经剔除了空白符、换行以及注释。一般情况下,空白符和注释都是在词法分析阶段进行处理的。
5.单词的种类和语义值
扫描器的工作不仅仅是将代码分割成单词,在分割的同时还会推算出单词的种类,并为单词添加语义值。
单词的种类是指该单词在语法上的分类,例如单词"54"的种类是"整数"。语义值(semantic value)表示单词所具有的语义。例如,在C语言中,单词"54"的语义为"数值 54"。单词""string""的语义为"字符串"string""。"printf"和"i"的语义有可能是函数名,也有可能是变量名。
所以,为了表示"整数 54", 扫描器会为单词"54"添加"这个单词的语义是数值 54"这样的信息。该信息就是语义值。单词""Hello\n""的种类是字符串,添加的语义值为"H""e""l""l""o""换行符"这6个字符。
另外,也有一些单词本身不存在语义值。例如,对于保留字int来说,"保留字int"这样的种类信息已经完全能够表示语义,不需要额外的语义值。
6.token
在编程语言处理系统中,我们将"一个单词(的字面)"和"它的种类""语义值"统称为token。通过使用token这个词,词法分析器的作用就可以说是解析代码(字符行)并生成token序列。
以刚才列举的Hello,World!程序为例,cbc的扫描器输出的token序列如表:
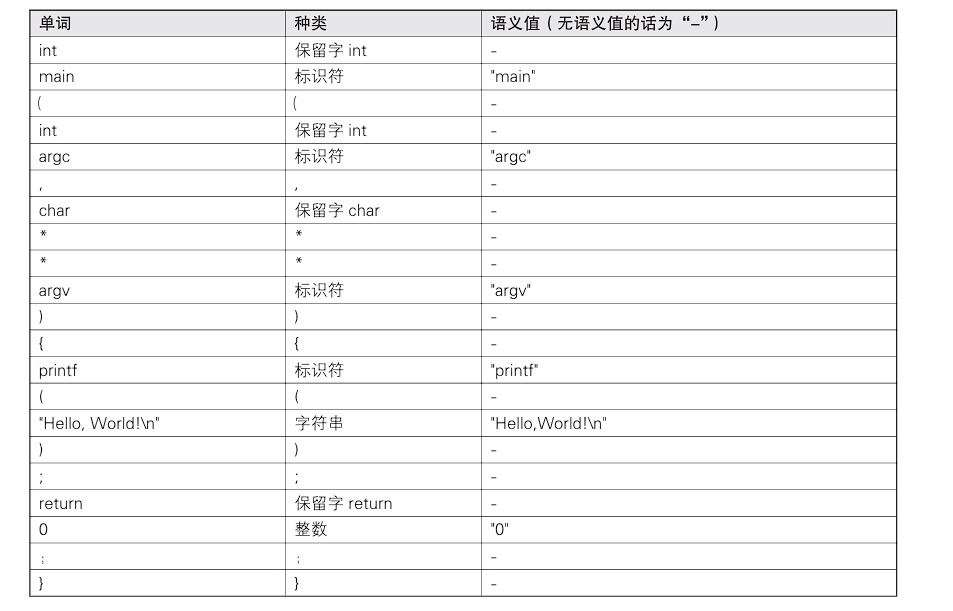
7.抽象语法树和节点
编程语言的编译器中解析器的主要作用是解析由扫描器生成的token序列,并生成代码所对应的树型结构,即语法树。确切地说,也有方法可以不需要生成语法树,但这样的方法仅限于极小型的编译器,我们不讨论。
语法树和语法是完全对应的,所以例如C语言的终结符分号以及表达式两端的括号等都包含在真实的语法树中。但是,保存分号和括号基本没有实际的意义,因此实际上大部分情况下会生成一开始就省略分号、括号等的抽象语法树。也就是说,解析器会跳过语法树,直接生成抽象语法树。
无论语法树还是抽象语法树,都是树形的数据结构,因此和普通的树结构相同,由称为节点(node)的数据结构组合而成。用Java来写的话,一个节点可以用一个节点对象来表示。
二、解析器生成器
我们将了解自动生成解析器的工具。
1.什么是解析器生成器
手动编写扫描器或解析器是一件非常无聊且繁琐的事情,原因在于不得不反复编写同样的代码。而且手动编写扫描器或解析器的话,将很难理解要解析的究竟是一种怎样的语法。
因此,为了使工作量和可读性两方面都有所改善,人们对自动生成扫描器和解析器的方法进行了研究。生成扫描器的程序称为扫描器生成器(scanner generator),生成解析器的程序称为解析器生成器(parser generator)。只需指定需要解析的语法,扫描器生成器和解析器生成器就能生成解析相应语法的代码。
cbc 使用名为JavaCC的工具来生成扫描器和解析器。JavaCC兼具扫描器生成器和解析器生成器的功能,因此能够在一个文件中同时记述扫描器和解析器。
2.解析器生成器的种类
扫描器生成器都大体类似,解析器生成器则有若干个种类。现在具有代表性的解析器生成器可分为LL 解析器生成器和LALR 解析器生成器两类。
这样划分种类的依据是解析器生成器能够处理的语法的广度。 解析器生成器并非能够处理所有语法,有着其自身的局限性。可以说这种局限性越小,能够处理的语法就越广。
一般的解析器生成器的种类如表3.2所示。大家可以结合该表来阅读下面的内容。一般来说,能够处理的语法范围最广的解析器生成器是LR 解析器生成器。但是因为LR 解析器生成器的速度非常缓慢,所以出现了通过稍微缩减可处理的语法范围来提高效率的解析器生成器,那
就是LALR 解析器生成器。而LL 解析器生成器比LALR 解析器生成器的结构更简单、更易于制作,但可处理的语法范围也更小。

LALR解析器生成器能够处理的语法范围比LL要广泛很多,加上现有的编程语言几乎都属于LALR语法,因此解析器生成器长期以来都是以LALR 解析器生成器为主。而最具代表性的LALR 解析器生成器就要数UNIX上的yacc了。
但最近从解析器的易理解性和可操作性来看,LL解析器生成器的势头正在恢复。我们所用的JavaCC 就是面向Java的LL 解析器生成器。
三、JavaCC 的概要
我们用的的C♭编译器使用名为JavaCC的工具来生成解析器。这就对JavaCC进行简单的说明。
1.解析器生成器的选择
JavaCC 是Java 的解析器生成器兼扫描器生成器。为JavaCC描述好语法的规则,JavaCC就能够生成可以解析该语法的扫描器和解析器(的代码)了。
JavaCC 是LL 解析器生成器,因此比起LR解析器生成器和LALR解析器生成器,它有着可处理语法的范围相对狭窄的缺点。但另一方面,JavaCC生成的解析器有易于理解、易于使用的优势。另外,因为支持了"无限长的token超前扫描",所以可处理语法范围狭窄的问题也得
到了很好的改善,这一点将在后面中介绍。
2.语法描述文件
语法规则通常会用一个扩展名为".jj"的文件来描述,该文件称为语法描述文件。cbc中在名为Parser.jj的文件中描述语法。
一般情况下,语法描述文件的内容多采用如下形式:
c
options {
JavaCC 的选项
}
PARSER_BEGIN( 解析器类名)
package 包名;
import 库名;
public class 解析器类名 {
任意的Java代码
}
PARSER_END( 解析器类名)
扫描器的描述
解析器的描述语法描述文件的开头是描述JavaCC选项的options块,这部分可以省略。
JavaCC和Java一样将解析器的内容定义在单个类中,因此会在PARSER_BEGIN和 PARSER_END之间描述这个类的相关内容。这部分可以描述package声明、import声明以及任意的方法。
在此之后是扫描器的描述和解析器的描述。这部分的内容将在以后详细说明。
3.语法描述文件的例子
如果完全没有例子将很难理解语法描述文件,因此这里举一个非常简单的例子。如代码所示,这是一个只能解析正整数加法运算并进行计算的解析器的语法描述文件。请大家粗略地看一下,只要对内容有大致的了解就行了。
代码如下(示例):
c
options {
STATIC = false;
}
PARSER_BEGIN(Adder)
import java.io.*;
class Adder {
static public void main(String[] args) {
for (String arg : args) {
try {
System.out.println(evaluate(arg));
}
catch (ParseException ex) {
System.err.println(ex.getMessage());
}
}
}
static public long evaluate(String src) throws ParseException {
Reader reader = new StringReader(src);
return new Adder(reader).expr();
}
}
PARSER_END(Adder)
SKIP: { <[" ","\t","\r","\n"]> }
TOKEN: {
<INTEGER: (["0"-"9"])+>
}
long expr():
{
Token x, y;
}
{
x=<INTEGER> "+" y=<INTEGER> <EOF>
{
return Long.parseLong(x.image) + Long.parseLong(y.image);
}
}在一开始的options块中,将STATIC选项设置为false。将该选项设置为true的话,JavaCC 生成的所有成员及方法都将被定义为static。
若将STATIC选项设置为true,那么所生成的解析器将无法在多线程环境下使用,因此该选项应该总是被设置成false。比较麻烦的是,STATIC选项的默认值是true,因此无法省略该选项,必须明确地将其设置为false。
接着,从PARSER_BEGIN(Adder)到PARSER_END(Adder)是解析器类的定义。解析器类中需要定义的成员和方法也写在这里。为了实现即使只有Adder类也能够运行,这里定义了main函数。main函数的内容将稍后讲解。
之后的SKIP和TOKEN部分定义了扫描器。SKIP表示要跳过空格、制表符(tab)和换行符。TOKEN表示扫描整数字符并生成token。
从long expr...开始到最后的部分定义了狭义的解析器。这部分解析token序列并执行某些操作。cbc生成抽象语法树,但Adder类并不生成抽象语法树,而是直接计算表达式的结果。
4.运行JavaCC
要用JavaCC来处理Adder.jj,需使用如下javacc命令:

除了输出上述消息之外,还会生成Adder.java和其他的辅助类。
要编译生成的Adder.java,只需要javac命令即可。输入命令试着进行编译:
如果提示 not found,就执行提示的第一条命令 openjdk 这个

这样就生成了Adder.class文件。
让我们马上试着执行一下。Adder类是从命令行参数获取计算式并进行计算的,因此可以从命令行输入计算式并执行:

可见已经成功了,能很好地进行加法运算了哦。
5.启动JavaCC所生成的解析器
在文章结束前,我们来了解一下main函数的代码。首先,代码清单中再一次给出了main函数的代码。
c
static public void main(String[] args) {
for (String arg : args) {
try {
System.out.println(evaluate(arg));
}
catch (ParseException ex) {
System.err.println(ex.getMessage());
}
}
}该函数将所有命令行参数的字符串作为计算对象的算式,依次用evaluate方法进行计算。例如从命令行输入参数"1 + 3",evaluate方法就会返回4,之后只需用System.out.println方法输出结果即可。
下面所示的是evaluate方法的代码:
c
static public long evaluate(String src) throws ParseException {
Reader reader = new StringReader(src);
return new Adder(reader).expr();
}该方法中生成了Adder类(解析器类)的对象实例,并让Adder对象来计算(解析)参数字符串src。
要运行JavaCC生成的解析器类,需要下面2个步骤。
- 生成解析器类的对象实例
- 用生成的对象调用和需要解析的语句同名的方法
首先说一下第1点。JavaCC 4.0生成的解析器中默认定义有如下4种类型的构造函数。
1.Parser(nputStream s)
2.Parser(InputStream s, String encoding)
3.Parser(Reader r)
4.Parser(××××TokenManager tm)
第1种形式的构造函数是通过传入InputStream对象来构造解析器的。这个构造函数无法设定输入字符串的编码,因此无法处理中文字符等。
而第2种形式的构造函数除了InputStream对象之外,还可以设置输入字符串的编码来生成解析器。如果要使解析器能够解析中文字符串或注释的话,就必须使用第2种或第3种构造函数。但如下所示,如果要处理中文字符串,仅靠改变构造函数是不够的。
第3种形式的构造函数用于解析Reader对象所读入的内容。Adder类中就使用了该形式。
第4种形式是将扫描器作为参数传入。如果是要解析字符串或文件输入的内容,没有必要使用该形式的构造函数。
解析器生成后,用这个实例调用和需要解析的语法(正确地说是标识符)同名的方法。这里调用Adder类实例的expr方法,就会开始解析,解析正常结束后会返回语义值。
6.中文的处理
下面说一下用JavaCC处理带有中文字符的字符串的方法。
要使JavaCC能够正确处理中文,首先需要将语法描述文件的options块的UNICODE_INPUT 选项设置为true,代码如下:
c
options {
STATIC = false;
DEBUG_PARSER = true;
UNICODE_INPUT = true;
JDK_VERSION = "1.5";
}这样就会先将输入的字符串转换成UNICODE后再进行处理。UNICODE_INPUT选项为false 的情况下只能处理ASCII范围内的字符。
另外,使用刚才列举的构造函数的第2种或第3种形式,为输入的字符串设置适当的编码。
使用第3种形式的情况下,在Reader类的构造函数中指定编码。
编码所对应的名称请见下面这个表。这样即使包含中文字符的代码也能够正常处理了。

总结
最近在痴迷《三体》,更新的比较慢,大家见谅噢。