
大家好,今天要和大家分享的项目是MatAnyone ,与上一篇分享的SAM2LONG类似,不过上次的分享没有提到如何在 MAC 上部署,后来有小伙伴私信说希望能出一个 MAC 版本的。那正好看到MatAnyone这个项目顺手就写下来。该项目基于SAM2同样可以一键抠出视频中的主体,快速输出绿幕视频或者是AlphaMask视频。本篇会分享本地手动部署流程以及MatAnyone的使用方法。

以下是手动部署的步骤,也可以直接使用一键包进行部署。
手动部署
克隆代码仓库
python
git clone https://github.com/pq-yang/MatAnyone
cd MatAnyone创建 Conda 虚拟环境
python
conda create -n matanyone python=3.10 -y安装依赖
python
pip install -e .
python
pip3 install -r hugging_face/requirements.txt安装FFmpeg
python
# macOS
brew install ffmpeg
# Windows (通过 Chocolatey)
choco install ffmpeg
# Ubuntu/Debian
sudo apt install ffmpeg安装pytorch
windows
安装 CUDA 12.8 支持的 PyTorch 套件,启用 GPU 加速。
python
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128MAC
python
pip3 install torch torchvision torchaudioMAC部署需要修改下matanyone_wrapper.py第44行
python
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
mask = torch.from_numpy(mask).to("cpu")
frames_np = [frames_np[0]]* n_warmup + frames_np
frames = []
phas = []
for ti, frame_single in tqdm.tqdm(enumerate(frames_np)):
image = to_tensor(frame_single).to("cpu").float()运行
首次运行会自动下载模型
python
python hugging_face/app.py使用教程
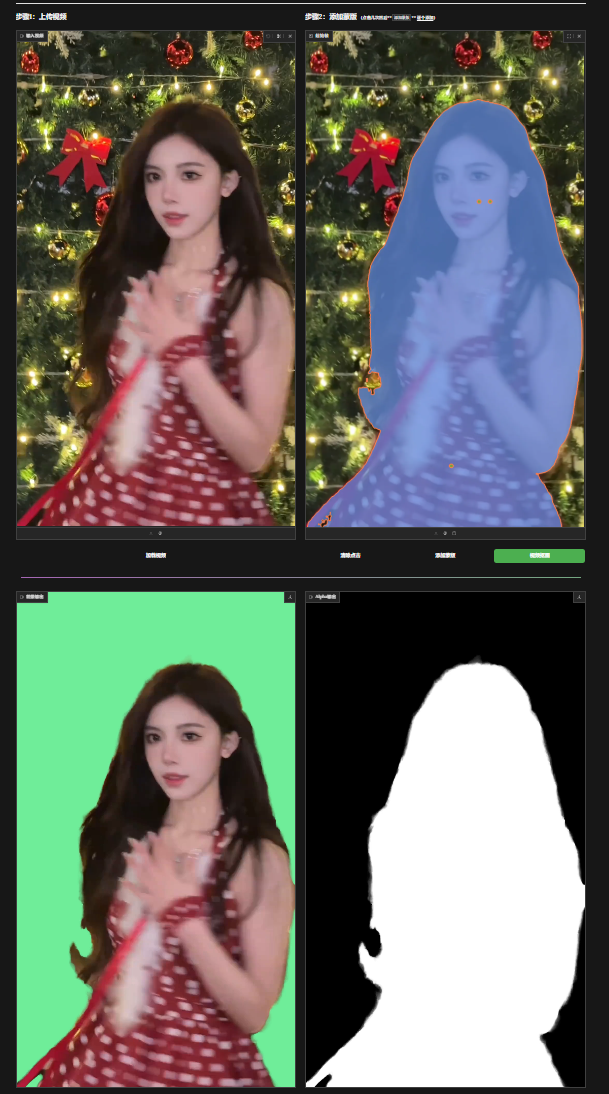
上传需要处理的视频
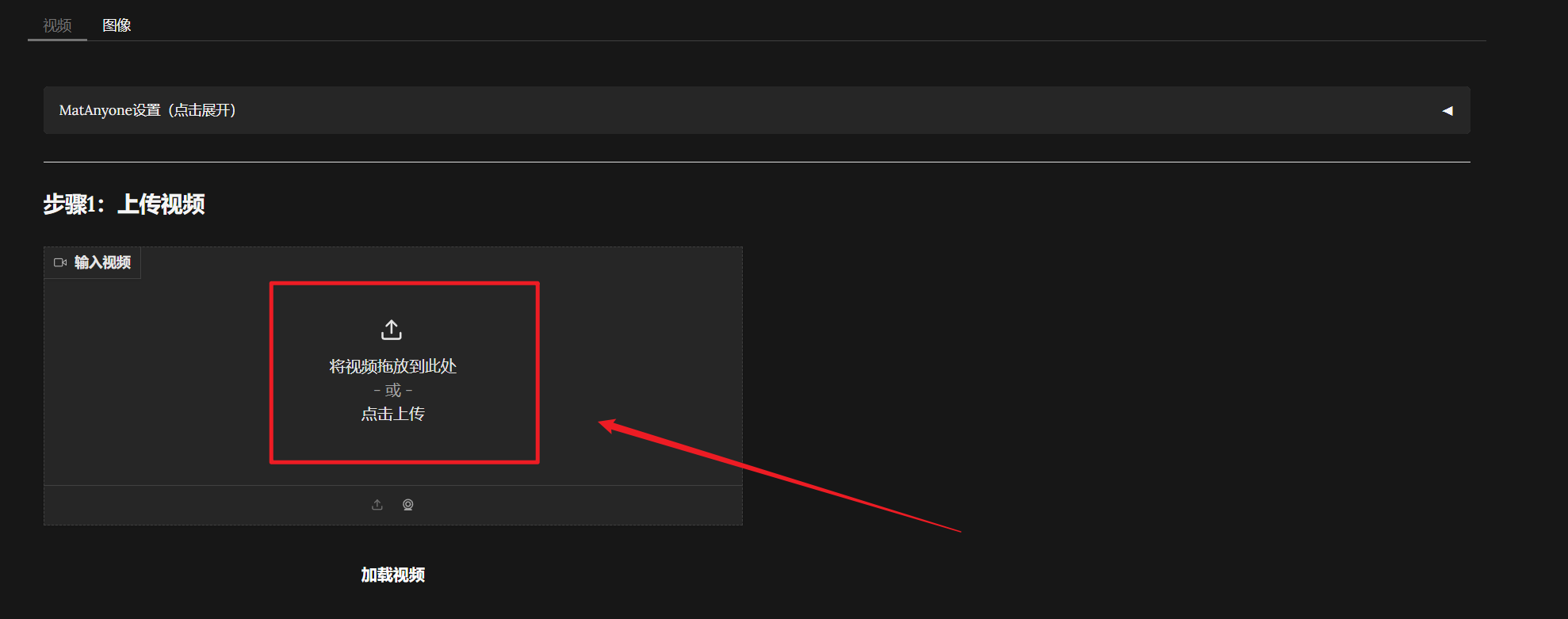
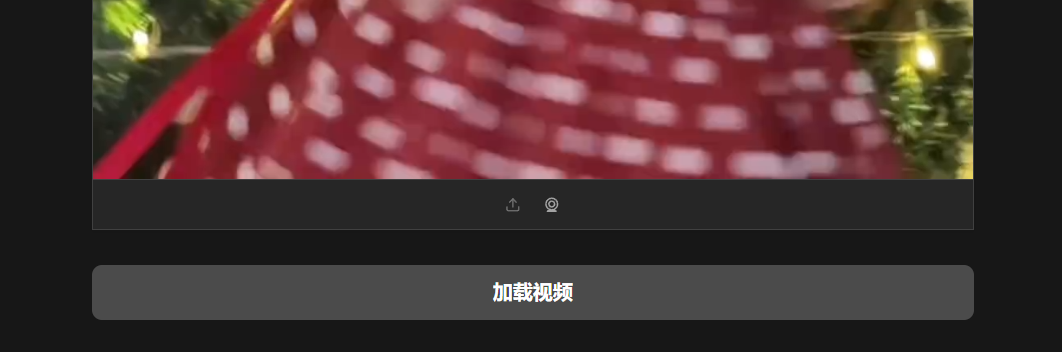
点击加载视频
点击右边的区域可以选择蒙版
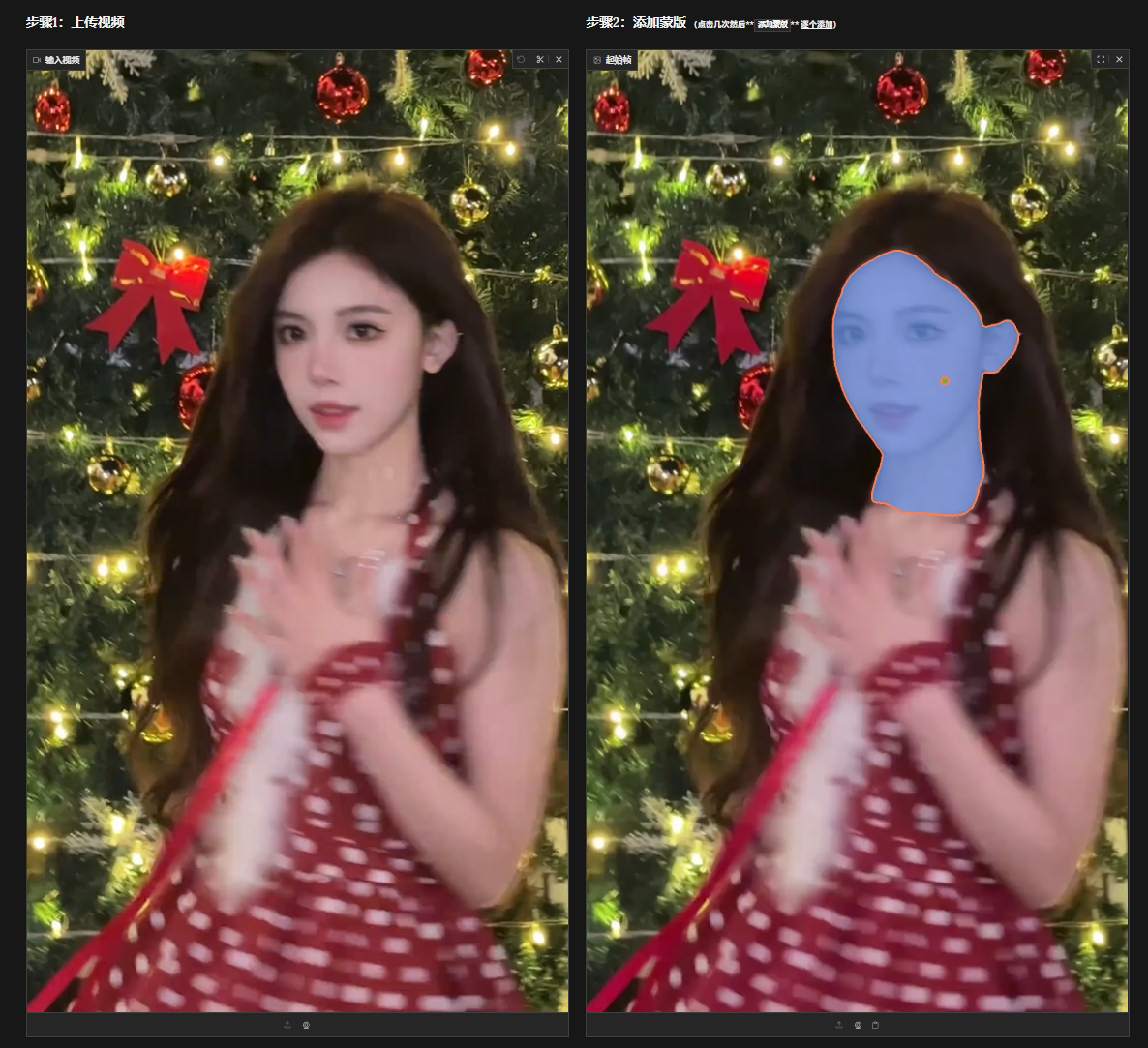
支持多选
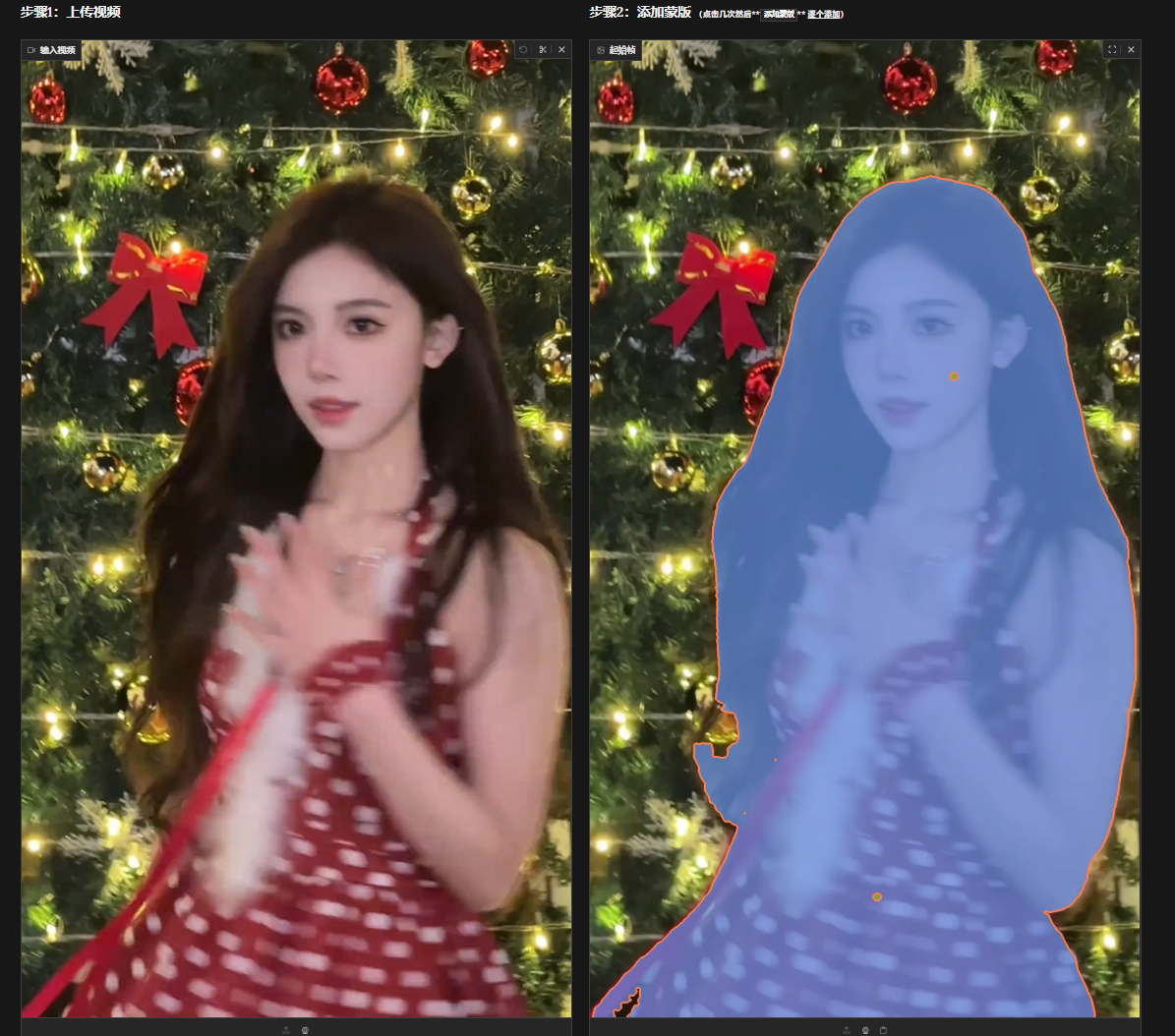
选择完成后点击下方的视频抠图
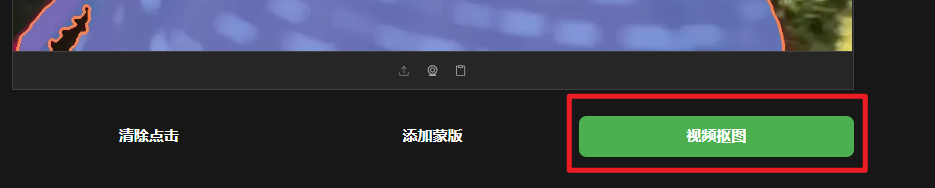
最后输出绿幕视频以及Alpha视频
配置需求
Windows
WindowsN卡需10G显存
如果运行报错,需要安装cuda12.8
https://developer.nvidia.com/cuda-12-8-0-download-archive
支持50系显卡
MAC
MAC Apple Silicon M1/M2/M3/M4 芯片
10G内存以上
关于速度
11秒视频(每秒24帧)
4090完成花费60秒左右。
5090完成花费45秒左右。
MAC M1 MAX完成花费20分钟左右。
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
夸夸夸盘:
https://pan.quark.cn/s/9160ab732d7b
度度度盘:
https://pan.baidu.com/s/1OKOTyzo-PW9Zd3HVK4QK0w?pwd=p7x3
制作不易,如果本文对您有帮助,还请点个免费的赞或关注!感谢您的阅读!