
大家好,我是 Ai 学习的老章
前几天介绍了MOE 模型先驱 Mistral 开源的代码 Agent 大模型------mistralai/Devstral-Small-2505
今天一起看看 Mistral 最新开源的推理大模型------Magistral
Magistral 简介
Mistral 公司推出了首个推理模型 Magistral 及自研可扩展强化学习 (RL) 流程。团队采用自下而上的方法,完全基于自有模型和基础设施构建,不依赖现有实现或其他模型的 RL 轨迹。
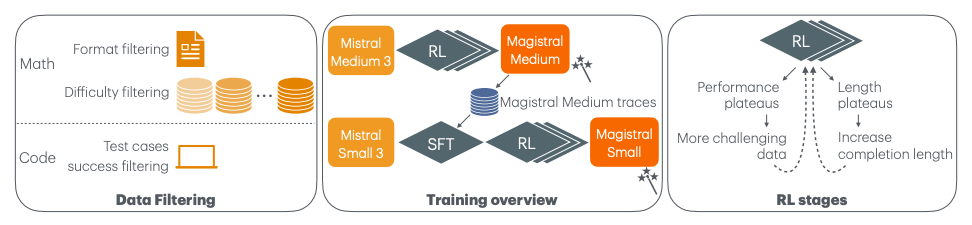
Mistral 的技术栈探索了纯 RL 训练大语言模型的极限,开发出强制模型使用特定推理语言的方法,并证实仅用文本数据的强化学习能保持初始模型大部分能力。这种方法还能维持或提升多模态、指令遵循和函数调用能力。
设计理念是像人类一样缜密思考,同时具备跨专业领域的知识储备、可追踪验证的透明推理流程,以及深度的多语言适应能力。
Magistral 特性
- 与通用模型不同,Magistral 针对多步逻辑进行了微调,提高了可解释性,并以用户语言提供可追溯的思维过程。
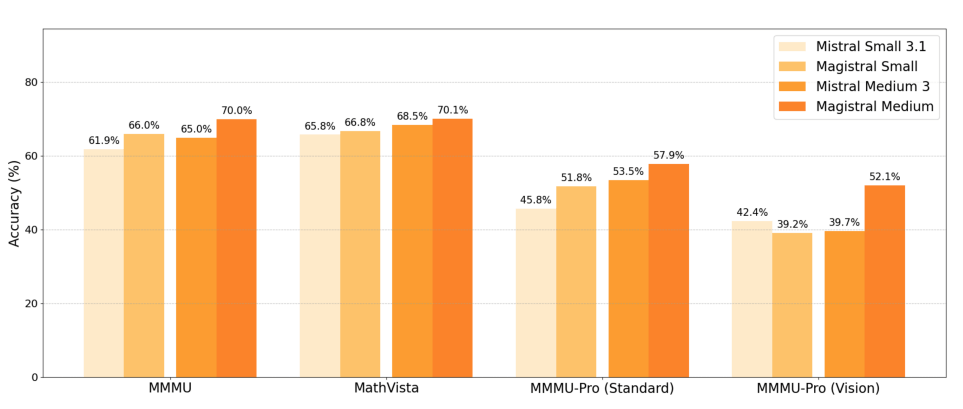
- Magistral 基于 Mistral Small 3.1(2503)构建, 增强了推理能力
- Magistral 提供两种版本:Magistral Small(240 亿参数开源版),Magistral Medium(企业版)
- Magistral Small 融合了来自 Magistral Medium 的冷启动数据
- Magistral Small 参数量 24B, 可本地部署,量化后能适配单张 RTX 4090 显卡或 32GB 内存的 MacBook
- Magistral 上下文窗口 128k , 但超过 40k 后性能可能下降,官方建议将模型最大长度设置为 40k
Magistral 测评数据
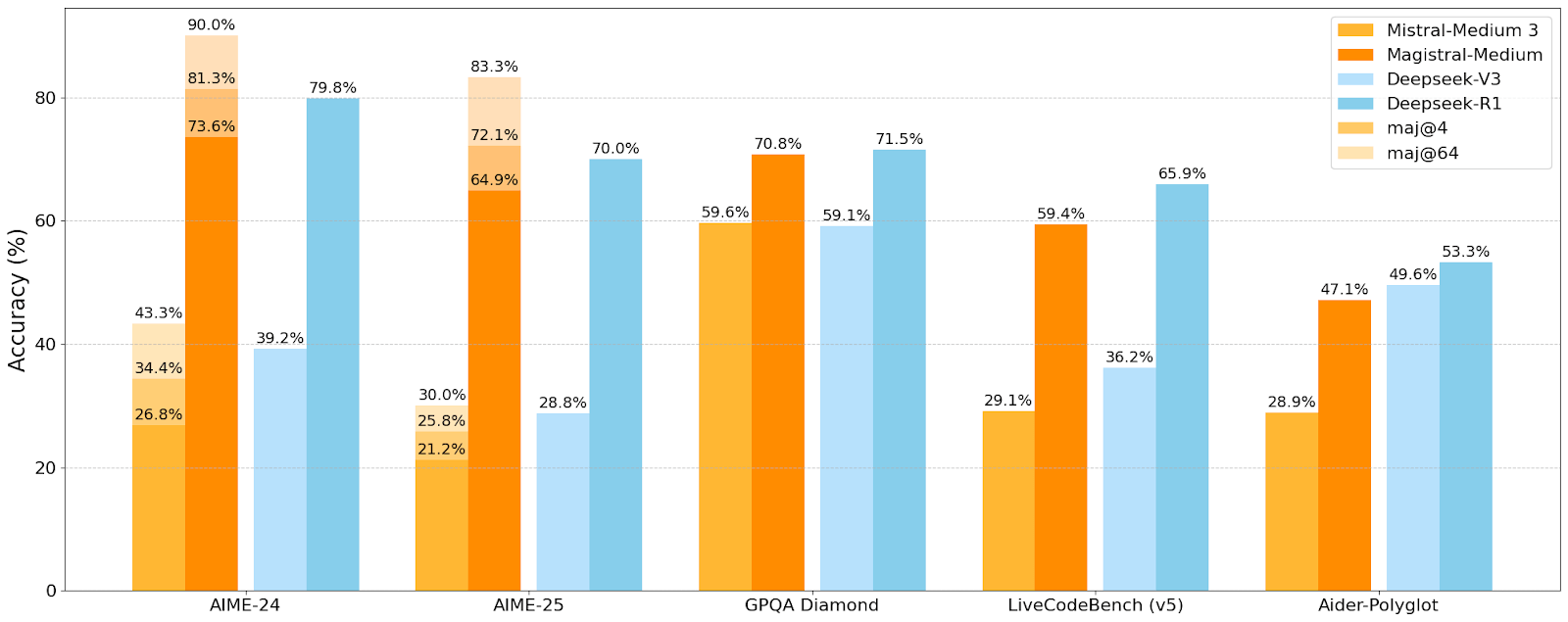
Magistral Medium 只用 24B 参数秒杀 DeepSeek-V3,某些领域 (GPQA Diamond) 可以和 DeepSeek-R1 掰手腕,不过应该是旧版 R1,如果跟 R1-0528 比,那还是差这档次呢
Mistral 也鸡贼,拿去刷榜的是企业版 (Medium),开源版数据就没那么全了
注:GPQA Diamond 是 GPQA 数据集的子集。GPQA 数据集包含 448 道由生物学、物理学和化学领域专家编写的高质量选择题,而 Diamond 子集是其中质量最高的部分,包含 198 条结果,其选取的是两个专家均答对且至少 2/3 非专家答错的问题,这些问题具有很高的难度。
| Model | AIME24 pass@1 | AIME25 pass@1 | GPQA Diamond | Livecodebench (v5) |
|---|---|---|---|---|
| Magistral Medium 模型 | 73.59% | 64.95% | 70.83% | 59.36% |
| Magistral Small 模型 | 70.68% | 62.76% | 68.18% | 55.84% |
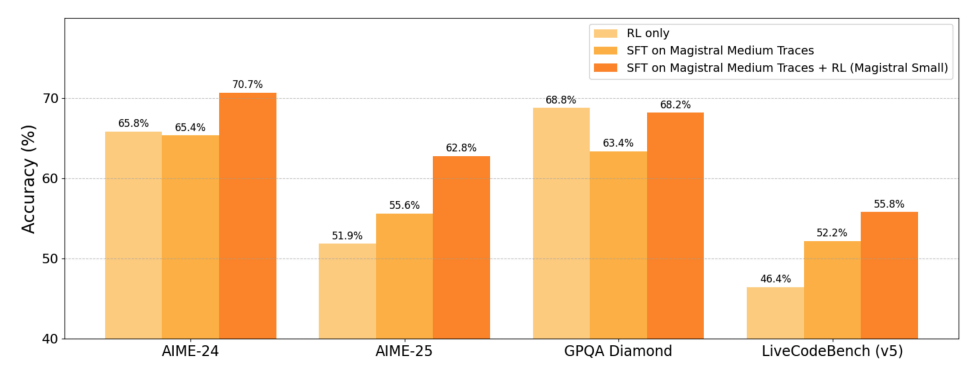
Medium 比 Small 强了 2 个百分点的样子

另:看论文中,Magistral 对中文相对没那么友好,毕竟法国公司。不过拿去写代码应该问题不大,Livecodebench (v5) 上强于 V3 一大截
Magistral Small 部署
截至发文 modelscope.com 尚未更新模型文件,网络不佳的同学可以坐等一下:https://www.modelscope.cn/models/mistralai/
网络畅通就去huggingface:https://huggingface.co/mistralai/Magistral-Small-2506
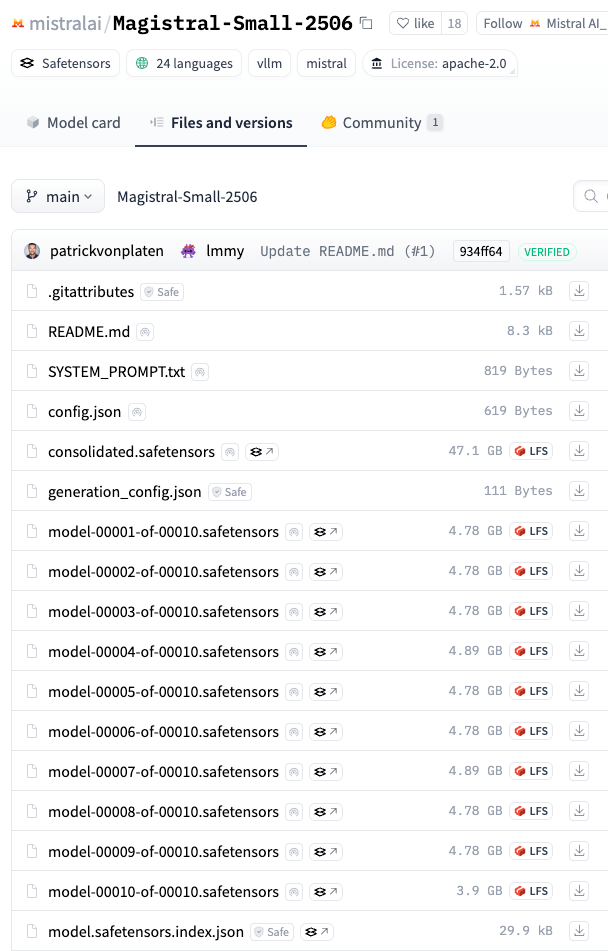
模型文件 50GB,感觉至少需要 4 张 4090 才能启动
启动模型:
BASH
# 需要升级到最新版:
pip install -U vllm --extra-index-url [https://wheels.vllm.ai/0.9.1rc1](https://t.co/kuf2vI0hva "https://wheels.vllm.ai/0.9.1rc1") --torch-backend=auto
vllm serve mistralai/Magistral-Small-2506 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2量化版对显卡的要求至少可以打个对折起步
比如Ollama上量化后模型文件只有14GB
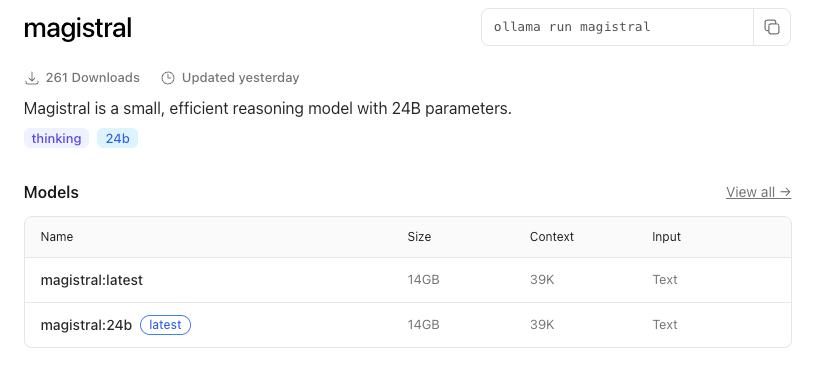
Magistral 量化版汇总:
llama.cpp:https://huggingface.co/mistralai/Magistral-Small-2506_gguflmstudio(llama.cpp, MLX):https://lmstudio.ai/models/mistralai/magistral-smallollama(llama.cpp): https://ollama.com/library/magistralunsloth(llama.cpp): https://huggingface.co/unsloth/Magistral-Small-2506-GGUF
Magistral 使用
官方有该模型的最佳参数:
top_p: 0.95temperature: 0.7max_tokens: 40960
我在论文中还看到了史上最简洁的系统提示词
markdown
A user will ask you to solve a task. You should first draft your thinking process (inner
monologue) until you have derived the final answer. Afterwards, write a self-contained
summary of your thoughts (i.e. your summary should be succinct but contain all the critical
steps you needed to reach the conclusion). You should use Markdown and Latex to format
your response. Write both your thoughts and summary in the same language as the task
posed by the user.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual
and as long as you want until you are confident to generate a correct answer.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final
answer to the user.
Problem:
{problem}虽然简介,但是也包括了一个系统提示词的所有结构:
- 双阶段思考 :
- 第一阶段:要求模型在
Thought Process标签内进行详细的思考过程(内部独白) - 第二阶段:在标签外提供简洁但完整的总结和最终答案
- 第一阶段:要求模型在
- 思考可见化 :
- 这种设计让用户能够看到模型的"思考过程",增加透明度
- 类似于"思考链"(Chain-of-Thought) 提示技术,但更加结构化
- 格式要求 :
- 要求使用 Markdown 和 LaTeX 进行格式化,适合数学和科学问题的展示
- 强调结构化输出,使回答更加清晰易读
- 语言适应 :
- 要求模型使用与用户提问相同的语言回答,增强用户体验
- 问题占位符:{problem}是一个占位符,将被实际问题替换
最后就是官方建议的聊天模板:
markdown
<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts (i.e. your summary should be succinct but contain all the critical steps you needed to reach the conclusion). You should use Markdown to format your response. Write both your thoughts and summary in the same language as the task posed by the user. NEVER use \boxed{} in your response.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and as long as you want until you are confident to generate a correct answer.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user. Don't mention that this is a summary.
Problem:
[/SYSTEM_PROMPT][INST]user_message[/INST]<think>
reasoning_traces
</think>
assistant_response</s>[INST]user_message[/INST]其他资源
试用:https://chat.mistral.ai/chat
论文:https://mistral.ai/static/research/magistral.pdf
API:http://console.mistral.ai/
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)
图解机器学习 - 中文版(72 张 PNG)
ChatGPT、大模型系列研究报告(50 个 PDF)
108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础
116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数
史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等