llamafactory 是一个专注于高效微调和部署大型语言模型(LLMs)的开源框架,尤其针对 Llama 系列模型优化。它提供模块化工具链,支持从数据预处理、参数高效微调(如 LoRA、QLoRA)到模型量化、推理部署的全流程,显著降低计算资源需求。用户可通过简洁的配置实现定制化任务适配,适用于学术研究及工业场景。
笔者在部署应用llama-factory的过程中遇到一些环境及库安装问题,现总结如下,以备不时之需。
目录
服务器硬件说明
在llamafactory 的官方文档的使用说明中,给出了如下简单的安装指令:
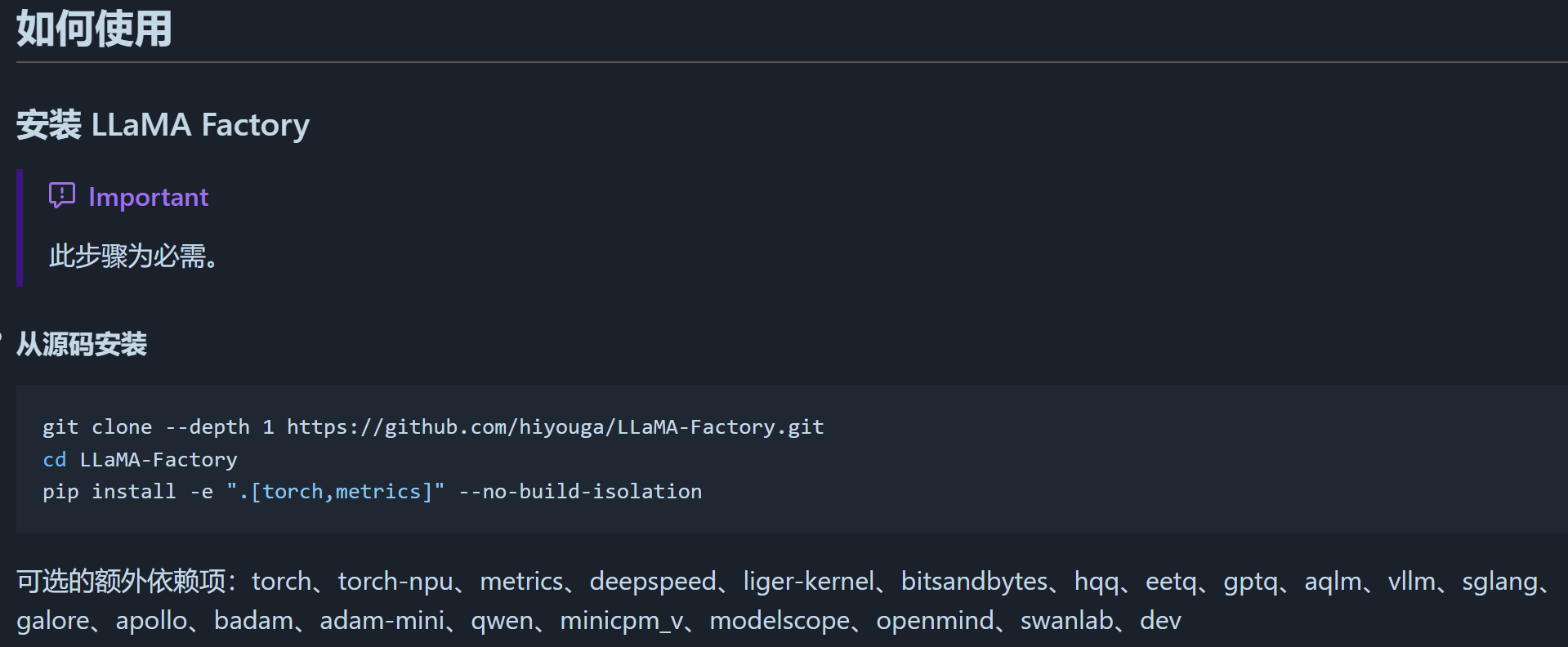
没有指定python cuda等版本。
笔者在Ubuntu22.04 python3.11 cuda11.5 GPU4090的配置下,可以成功安装llamafactory并执行llamafactory-cli webui,正常显示如下界面:
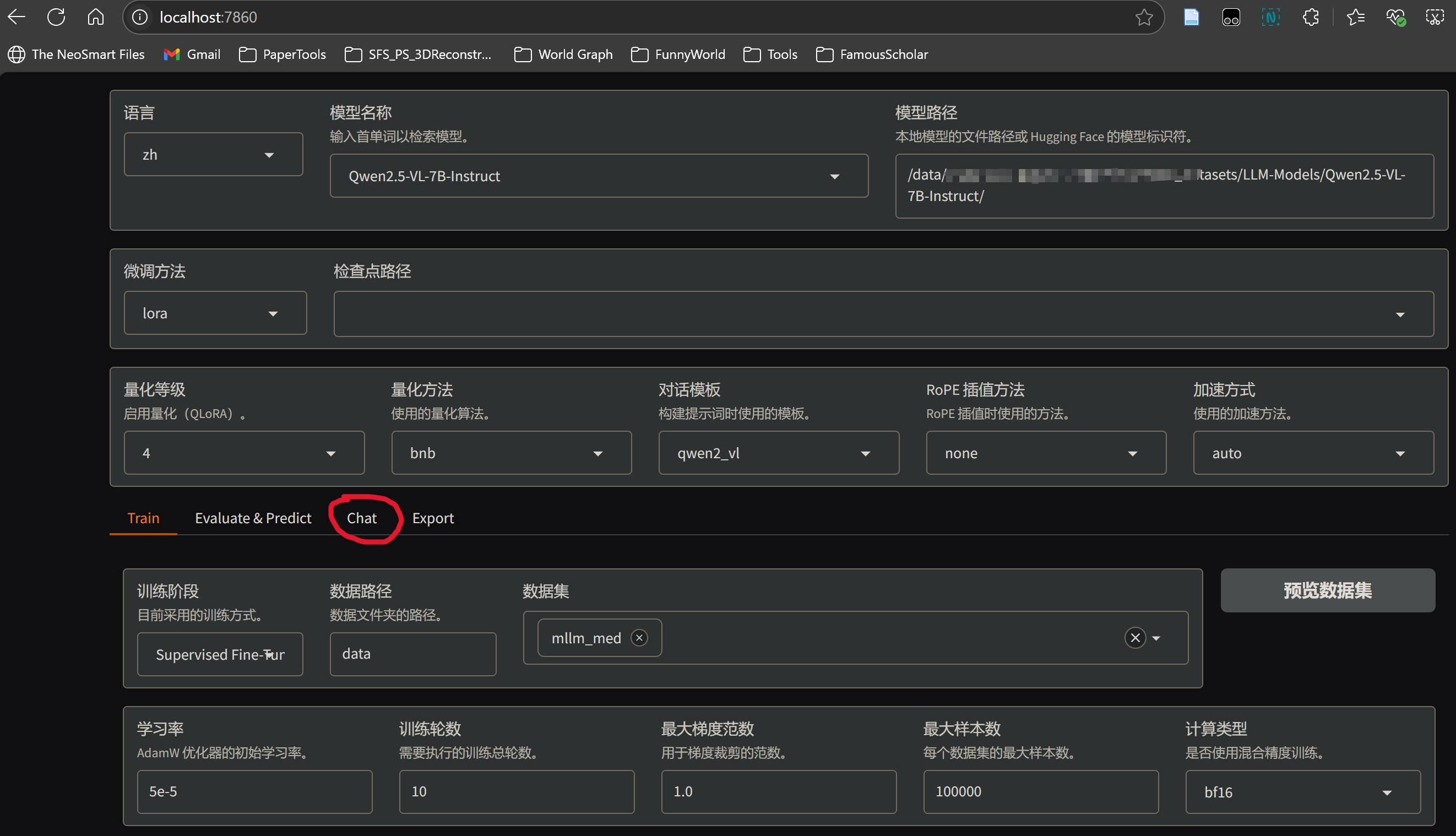
在模型路径填入自己本地下载的模型路径后,点击chat,会出现加载按钮,点击加载就会出现如下ImportError: No package metadata was found for bitsandbytes.
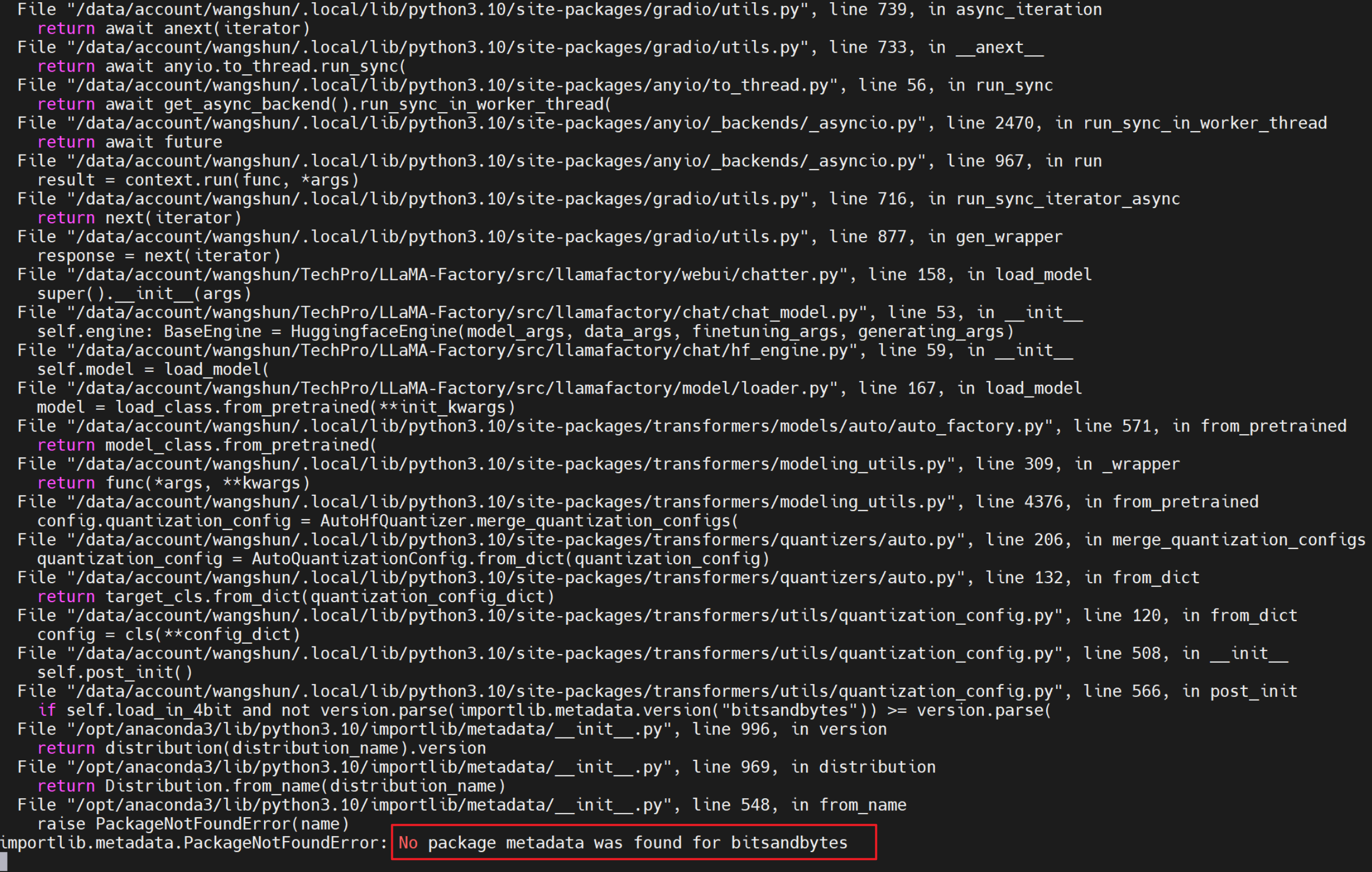
执行pip install bitsandbytes以及安装不同版本的,均无法解决。但单独加载bitsandbytes是正常的。

利用Gemini进行排查,分析如下:

基于上述分析,接着执行nvcc -V,发现cuda版本为11.5。Gemini给出的建议如下:

参考该解决方案,成功实现Ubuntu的非root用户安装cuda。在安装Cuda12.2.2的配置下,重新按照llamafactory的部署步骤进行安装,最后成功实现模型的加载。
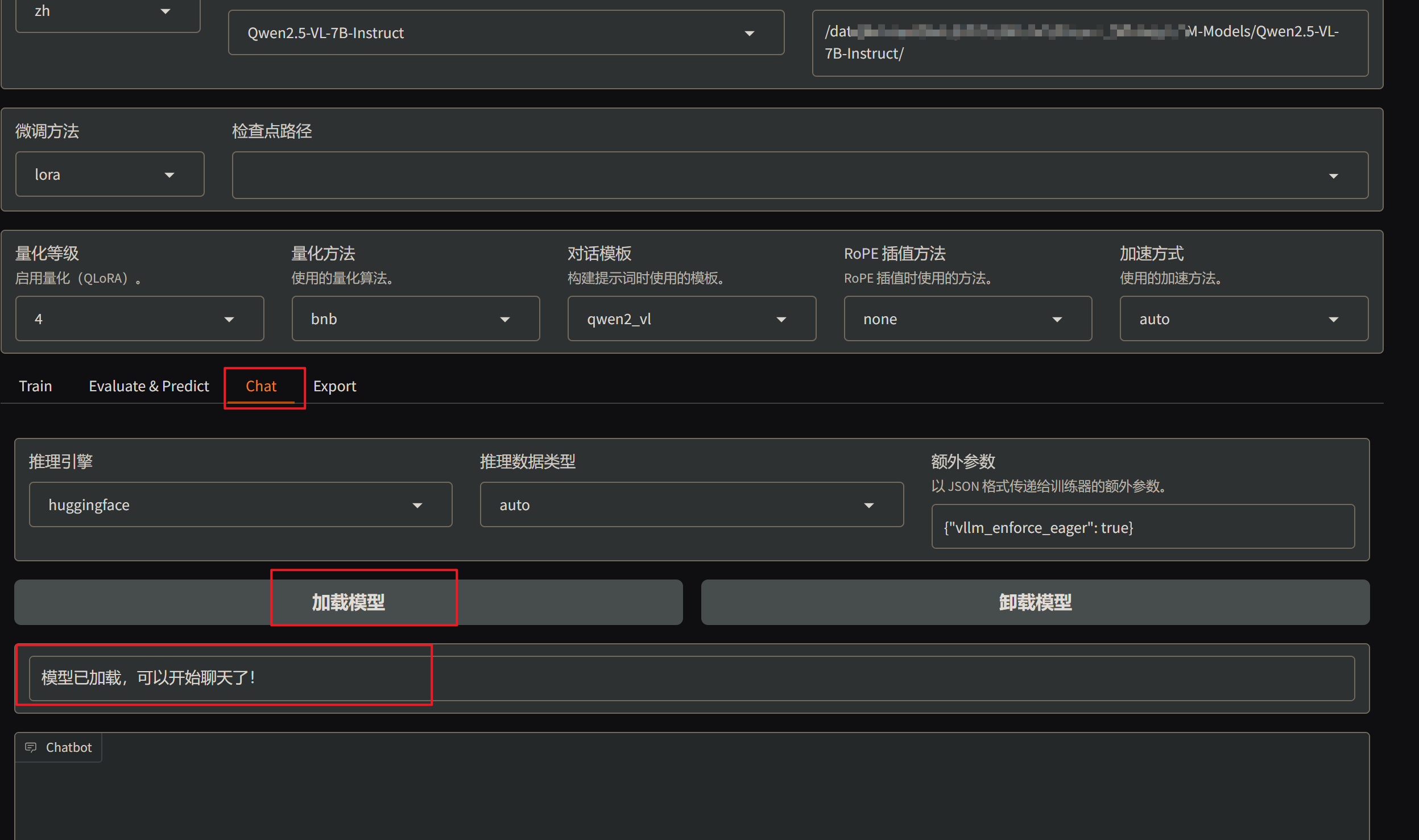
总结:部署llamafactory需要CUDA12.x版本。
llamafactory单机多卡训练
在完成模型下载和数据集准备后,接着进行训练。所使用的服务器配备了4个4090,结果出现如下错误ModuleNotFoundError: No module named 'llamafactory'以及subprocess.CalledProcessError: Command '['torchrun', '--nnodes', '1', '--node_rank', '0', '--nproc_per_node', '4', '--master_addr', '127.0.0.1', '--master_port', '41333', '/data/account/wangshun/TechPro/LLaMA-Factory/src/llamafactory/launcher.py', '-h']' returned non-zero exit status 1.
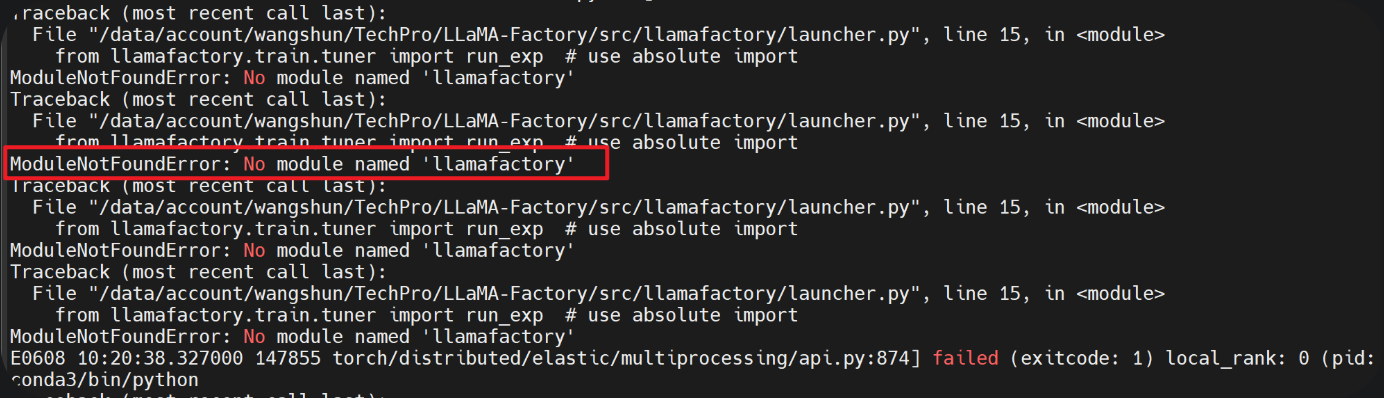
先是参考了这个链接,以及相关解决方案的博客,均没有解决。无论如何执行export PATH="xxx/.conda/envs/factory/bin:$PATH"以及将其放在~/.bashrc文件中的哪个位置,均相同错误。
接着,参考了该方法,成功实现单机多卡的训练。通过web界面设置好参数后,预览复制对应的命令行代码,最后执行的指令如下:
CUDA_VISIBLE_DEVICES=2,3 python -m torch.distributed.run --nproc_per_node=2 src/train.py --stage sft --do_train True .......通过该指令实现多卡训练,并可以指定对应的卡号。
其他问题
另外,在非root用户安装cuda过程中还有个小插曲,执行sh xxx.run时报错:Log file not open. Segmentation fault

参考该链接,联系管理员设置了目录/tmp的用户访问权限,成功实现cuda安装,而无需将其删除。