大家好,欢迎来到code秘密花园,我是花园老师(ConardLi)。
今天我们来到 LLaMA Factory 微调教程的第二期,一起来学习如何构建高质量的微调数据集。
在开始学习之前,首先我们先补充演示一下,我们整体这次微调教程中,微调案例的一个最终效果。
在本教程中,我们微调的基础模型是 Qwen2.5-7B-Instruct ,目标是微调后让其在特定场景下具备一定的推理能力,并且在 Web 安全领域具备专家级水准。

对于企业内部的代码、需求文档等一般都属于企业内部的机密数据,若直接使用外部模型可能存在隐私泄漏风险,因此此类任务一般需要私有部署的模型承担,而满血版模型的部署成本非常昂贵,所以我们选择使用对小参数模型进行微调。 希望微调后的模型可用于在企业内部私有部署,回答 Web 安全相关问题,对可能引发安全问题的业务场景以及代码进行预警,并且在 Web 安全领域的能力上可和满血版模型持平甚至超越满血版模型。
以下是在部分问题下,模型微调前后的效果对比:

从对比可以得出结论,相比微调前的基础模型(Qwen2.5-7B-Instruct),模型微调后:
- 在数据集内部的特定问题上,具备推理能力,并且回答结果更丰富,说明学习到了数据集内部的知识;
- 在 Web 安全领域的特定问题上(不在数据集内),具备推理能力,并且回答结果更丰富,说明模型的泛化能力较好,没有过拟合;
- 在 Web 安全整体的知识体系上,具备推理能力,并且回答结果更丰富,说明模型能够系统性整合 Web 安全领域的知识框架,形成结构化的知识输出体系,同时具备跨知识点的关联推理能力,可基于底层逻辑对复杂知识体系进行演绎构建;
- 在非 Web 安全的某些其他领域上,具备推理能力,说明模型在聚焦 Web 安全领域专业能力强化的同时,未丧失基础模型的跨领域知识迁移能力,能够基于微调形成的推理框架对非专业领域问题进行逻辑拆解,保持了基础模型的知识泛化性与多领域适应性。
注意:在非 Web 安全领域下,模型并不一定能够稳定输出推理过程,因为我们仅针对 Web 安全领域的数据集进行了训练,这在一定程度上激发了模型的推理能力,想要让模型在更多领域稳定输出推理过程,需要更丰富的数据集
数据集在微调任务中起着至关重要的作用。毫不夸张的说,要想得到好的微调效果,数据集的质量要远大于其他参数的设置,如果数据集太小、多样性不足、数据噪声太大、样本偏差严重等问题都会导致微调任务失败。按照经验来讲,在一次微调任务中,大概 80% 的时间应该花在数据集的准备和处理上,因为微调的工具、流程和参数的调整都是有经验可循的,而数据集的构建却需要结合具体业务场景。从数据采集时需覆盖多维度场景,到清洗时剔除噪声与偏差样本,再到标注时确保一致性与准确性,每个环节都影响最终效果。此外,还需合理划分训练/验证/测试集,通过数据增强扩充样本多样性,让模型在微调中真正学习到关键特征。
数据集格式要求
在不同的微调阶段,使用的数据集的格式要求是不一样的,有关数据集的基础格式、以及不同微调阶段的数据集要求,大家可以看我之前的这期教程《想微调特定领域的模型,数据集究竟要怎么搞?》:

本次任务我们进行的是指令监督微调(SFT),在 LLaMA Factory 中主要支持 Alpaca 格式和 ShareGPT 两种格式:
Alpaca 格式的指令微调数据集:

ShareGPT 格式的指令微调数据集:

数据集配置文件
我们看到 LLaMA Factory 提供了两个数据集相关的配置:数据路径和数据集(名称):

数据路径默认配置的是项目文件夹下的 data 目录,其中的 dataset_info.json 包含了所有预定义数据集的关键配置:

- 基本结构:配置文件采用 JSON 格式,以数据集名称为顶层键名,值为对应数据集的配置对象:
json
{
"数据集名称": {
"配置项1": "值1",
"配置项2": "值2",
...
}
}- 数据源定义方式:支持三种数据源加载方式,覆盖在线数据集、本地文件及自定义脚本生成数据:
- 在线数据集来源平台:Hugging Face Hub、ModelScope Hub、OpenMind Hub
- 配置示例:
json
"alpaca_en": {
"hf_hub_url": "llamafactory/alpaca_en",
"ms_hub_url": "llamafactory/alpaca_en",
"om_hub_url": "HaM/alpaca_en"
}- 本地文件配置方式:指定相对于 data 目录的相对路径,或本机绝对路径
- 配置示例:
json
"alpaca_en_demo": {
"file_name": "alpaca_en_demo.json"
}- 脚本生成数据集配置方式:指定自定义加载脚本名称
- 配置示例:
json
"belle_multiturn": {
"script_url": "belle_multiturn",
"formatting": "sharegpt"
}- 数据格式配置:通过多维度配置实现不同数据格式的兼容处理:
- 基本格式化类型(formatting 字段):分别支持格式化为 alpaca、sharegpt格式
- 配置示例:
json
"slimorca": {
"hf_hub_url": "Open-Orca/SlimOrca",
"formatting": "sharegpt"
}- 列映射配置(columns 字段):将数据集字段映射到标准字段名(如 prompt、response、system)
- 配置示例:
json
"openorca": {
"hf_hub_url": "Open-Orca/OpenOrca",
"columns": {
"prompt": "question",
"response": "response",
"system": "system_prompt"
}
}- 角色标签配置(针对 ShareGPT 格式,tags 字段):自定义对话角色标签(如用户、助手)
- 配置示例:
json
"mllm_demo": {
"formatting": "sharegpt",
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}- 多模态数据支持:通过字段映射处理图像、视频、音频等多模态数据:
json
"mllm_demo": {
"file_name": "mllm_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images" // 图像数据字段
}
}- 特殊训练任务配置
- 排序/对比学习数据(RLHF/DPO 训练),ranking 字段:标记为排序数据集
- 配置示例:
json
"webgpt": {
"hf_hub_url": "openai/webgpt_comparisons",
"ranking": true,
"columns": {
"prompt": "question",
"chosen": "answer_0",
"rejected": "answer_1"
}
}- 工具调用数据,tools 字段:指定工具定义字段
- 配置示例:
json
"glaive_toolcall_en_demo": {
"file_name": "glaive_toolcall_en_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"tools": "tools" // 工具定义字段
}
}数据集处理过程
LLaMA Factory 基于 dataset_info.json 实现了对多种不同的数据集格式兼容,一般情况下大家只需要了解 dataset_info.json 是怎么配置的即可,但是为了加深大家对数据集的理解,下面我们用一个具体的例子告诉大家一个你自定义的数据集最终会被处理成什么样子。
假定我们的原始原始数据结构是这样的(Alpaca 格式):
json
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
["今天会下雨吗?", "今天不会下雨,是个好天气。"],
["今天适合出去玩吗?", "非常适合,空气质量很好。"]
]
}
]在数据加载阶段,我们通过 dataset_info.json 配置数据集文件的路径:
json
"my_dataset": {
"file_name": "my_dataset.json",
"formatting": "alpaca"
}在微调任务开始后, LLaMA Factory 首先会将我们的数据集转换诶标准格式:
json
{
"_prompt": [
{"role": "user", "content": "今天会下雨吗?"},
{"role": "assistant", "content": "今天不会下雨..."},
{"role": "user", "content": "今天适合出去玩吗?"},
{"role": "assistant", "content": "非常适合..."},
{"role": "user", "content": "今天的天气怎么样?"}
],
"_response": [{"role": "assistant", "content": "今天的天气不错..."}]
}然后根据上面我们选择的对话模版,将数据集按照模版进行格式化,比如本次我们选择的模版是 Qwen:
ini
format_user = "<|im_start|>user\n{{content}}<|im_end|>\n<|im_start|>assistant\n"
format_assistant = "{{content}}<|im_end|>\n"
format_system = "<|im_start|>system\n{{content}}<|im_end|>\n"格式化后数据集就是这样的:
sql
<|im_start|>system
You are Qwen...<|im_end|>
<|im_start|>user
今天会下雨吗?<|im_end|>
<|im_start|>assistant
今天不会下雨...<|im_end|>
<|im_start|>user
今天适合出去玩吗?<|im_end|>
<|im_start|>assistant
非常适合...<|im_end|>
<|im_start|>user
今天的天气怎么样?<|im_end|>
<|im_start|>assistant
今天的天气不错...<|im_end|>随后, LLaMA Factory 将会对数据进行分词处理,将文本转换为数字序列(token IDs)。这一步骤至关重要,因为模型仅能处理数字而非原始文本:
yaml
[151, 8243, 29973, 29901, 29871, 29896, 29889, 29877, 29889, 29889, 152, 151, 8251, 29901, 29871, 29896, 29889, 29877, 29889, 29889, 152]随后,LLaMA Factory 会对数据集进行标签分配,标签分配是微调过程的核心环节,决定模型在哪些部分计算损失并学习生成内容。在对话模型训练中,模型需学会:理解用户输入(不生成用户输入)、生成助手回复,因此,需明确标记模型应生成的部分(助手回复)和仅需理解的部分(用户输入)。所以这一步就是把不参与损失计算(用户输入)的部分标记出来,LLaMA Factory 使用特殊值IGNORE_INDEX(值为-100)标记不参与损失计算的位置。以示例文本为例:
sql
<|im_start|>user
今天会下雨吗?
<|im_end|>
<|im_start|>assistant
今天不会下雨,是个好天气。
<|im_end|>标签分配规则为: 用户部分(含特殊标记):全部为-100 助手部分(含回复内容和结束标记):实际 token ID 。
训练时,模型仅因未正确预测助手回复而计算损失,避免因未预测用户输入而受惩罚。
数据完成分词和标签分配后,组织为以下格式传递给训练循环:
json
{
"input_ids": [所有token IDs],
"attention_mask": [全部为1的序列,表示所有token都需要关注],
"labels": [混合了-100和实际token ID的序列]
}- 前向传播 :模型接收完整
input_ids输入,生成每个位置的预测。 - 损失计算 :仅在
labels不为-100的位置计算损失。 - 反向传播:基于损失更新模型参数。
数据集的构造思路
数据集的质量好坏直接决定着微调任务的成败,根据最近我收集的各种微调后效果不好的案例中,大部分也都是数据集质量的问题,我总结了以下几个可能会导致微调任务失败的问题:
- 数据量太小: 数据量不足时,模型无法学习到足够的特征规律,如果你调的训练轮数很大,非常容易出现过拟合(仅记住少量样本的噪声信息),导致泛化能力差,在新数据上表现不佳。当然不同的微调任务对数据量的要求不一样,如果是领域知识注入类任务,(7B模型)至少要 1000 条数据起步,数据集的数量的扩大也要随着模型参数的变大而增加。另外也别迷信 "数据越多越好",若数据质量差,海量数据反而会放大噪声影响。优先保证单条数据的有效性,再考虑扩充数量。
- 噪声数据多:如文本数据中存在大量错别字、格式混乱,图像数据模糊、标注错误等,会误导模型学习错误的映射关系。所以数据集一定要进行清洗,文本数据重点筛除乱码、重复内容、与任务无关的段落(比如微调法律模型时混入娱乐新闻);标注数据需检查标签 - 内容一致性(如情感分类中 "好评" 文本误标为 "差评")。
- 样本偏差严重: 数据分布与实际应用场景差异大(如训练数据中 90% 是正面评论,而实际测试数据正负比例均衡),导致模型在真实场景下失效。
- 任务相关性不够:要模型学会一个领域的知识,不是说这个领域的所有数据都建议用于训练,比如你要微调一个金融问答模型时,就不要混入大量的财经新闻,因为新闻侧重事件描述,而问答侧重问题解答,数据形式需贴近实际应用场景(如 "问题 - 答案" 对)。
- 数据多样性不足: 样本覆盖的场景、特征维度单一(如文本数据仅包含短句子,缺乏长句或复杂句式;图像数据仅包含晴天场景,没有雨天、夜晚等),模型无法适应真实应用中的多样性需求。此外,若指令类型单一(如仅包含「解释型」指令),缺乏「推理型」「操作型」指令,会导致模型在实际应用中能力受限。
在本地微调任务中,我们将使用 Easy Dataset(简称 EDS)来构造数据集,以下是我们的构造思路:
- 为确保模型能学习到专业的 Web 安全知识,我们选择从 Web 安全领域的专业书籍《白帽子讲 Web 安全》来提取部分数据集;
- 为确保模型能学习到 Web 安全领域最前沿的知识,我们精选几篇 Web 安全相关的最新论文来提取部分数据集:
- 《The Hidden Risks of LLM-Generated Web Application Code: A Security-Centric Evaluation of Code Generation Capabilities in Large Language Models》
- 《WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks》
- 《A Human Study of Cognitive Biases in Web Application Security》
- 为确保模型能够学习均衡,不遗漏 Web 安全领域的知识,弥补和满血版大模型的差距,我们选取更为强大的满血版大模型(DeepSeek R1 0528)作为教师模型来蒸馏部分数据集;同时我们讲提取教师模型的推理过程(COT)来作为数据集的一部分,用于训练基础模型的推理能力;
- 为确保数据集的多样性,在数据集构造过程中我们将使用 GA(Genre-Audience)的思路来对数据集进行增强;
- 在数据集构造完成后,邀请 Web 安全领域专家来对数据集进行 Review,确保数据集最终质量。
使用 EDS 构造数据集
Easy Dataset(简称 EDS) 是一个专为创建大型语言模型数据集而设计的应用程序。通过 Easy Dataset,你可以将领域知识转化为结构化数据集,兼容所有遵循 OpenAI 格式的 LLM API,使数据集构造过程变得简单高效:

Github:github.com/ConardLi/ea...
项目配置
跟随文档完成软件的部署或安装后,打开 Easy Dataset,首先我们创建一个项目:

建议将项目命名为目标要微调的领域,在后续的数据蒸馏任务中,将默认使用项目名称作为顶级蒸馏主题。
进入【项目配置-模型配置】配置后续数据集提取任务所需模型,在本次任务中,我将使用如下模型:
- Doubao-1.5-pro-256k:用于建立领域树、从文本块中提取问题(速度快、结构化输出更稳定)
- DeepSeek-r1-250528:用户从文本块中为指定问题提取答案(推理模型,可获取思维链)
- Doubao-1.5-vision-pro-32k:用于自定义视觉模型解析 PDF(比基础解析效果更好)

如果你处理的是中文文献,或者需要生成中文数据集,建议使用国产模型,对中文理解能力更好。
进入【项目配置-任务配置】,调整本次数据集提取任务相关配置:

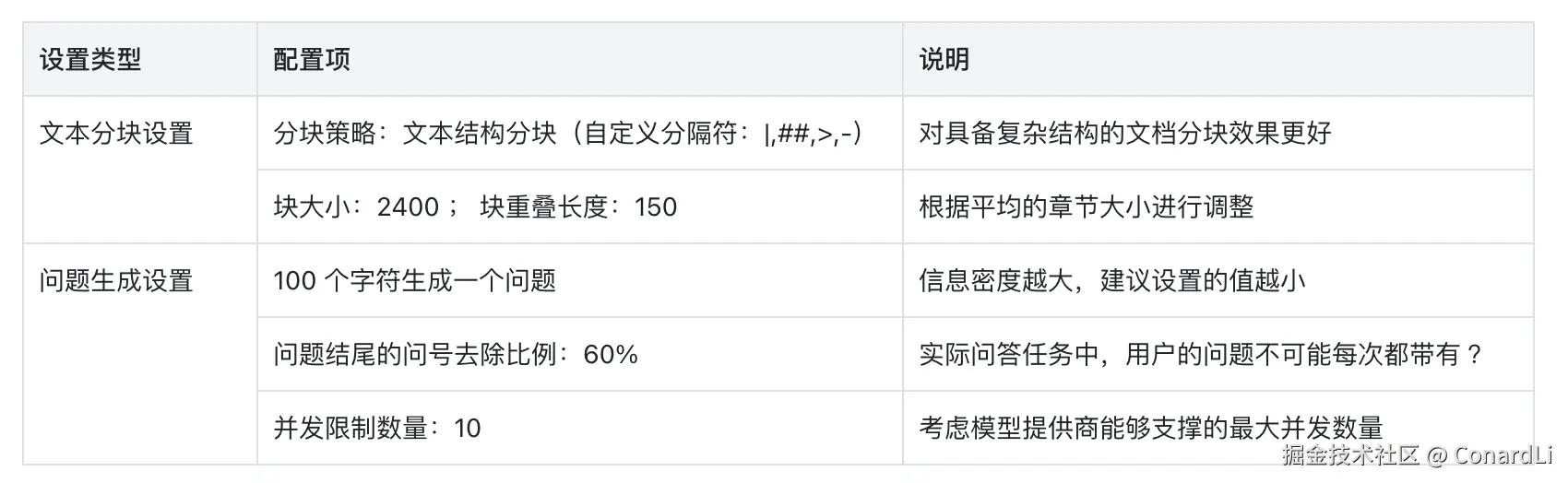
进入【项目配置-提示词配置】,配置部分提示词来干预后续数据集生成任务:

- 全局提示词:"语言:中文"(文献中含有部分英文论文,通过提示词控制永远生成中文提示词)。
- 生成问题提示词:"生成的问题要和 Web 安全领域相关,禁止生成和论文引用文献、论文作者、图片和表格数据描述相关问题"。
- 生成答案提示词:"生成的答案要和 Web 安全领域相关"。
注意:这一步一般情况下不用配置,当你尝试生成出的数据集不符合需求时,再来通过提示词进行干预和调整。
文献处理
进入【文献处理】,上传我们已经准备好的文献(1个书籍+3篇论文),选择 PDF 解析方式:

注意:选择自定义视觉模型解析将消耗自己的 Token,如果你想省钱,建议去申请免费的 MinerU API mineru.net/apiManage(有 14 期限,过期需要重新申请)
为了保障后续文本分段、数据集提取的质量,需要先将 PDF 转换为标准的 Markdown 格式,这个过程可能消耗比较长的时间,平台将在后台异步处理这些任务,并且详细展示任务进度:

文献处理完成后,为保证后续数据集生成的多样性,我们选择在部分文献上生成 GA(Genre-Audience)对:

- Genre(类型): 指内容的"知识表达框架",通过多个维度定义,包括:
- 沟通目的(如教育、分析、叙事)、内容结构(如分步教程、学术论文、对话体)
- 语言风格(如严谨学术风、通俗故事风)、知识深度(如初学者入门、专业研究者深度分析)。 例如,将同一篇科普文章重构为"学术论文"或"儿童故事",会采用不同的结构和语言风格,但保留核心知识。
- Audience(受众): 指内容的目标读者群体,结合以下特征:
- 人口统计学因素(年龄、职业、教育背景,如"12-15岁中学生""医学专业研究生");
- 知识背景与动机(如"对化学感兴趣的初学者""需要教学素材的中学教师")。 例如,针对"办公室工作人员"的急救指南会侧重实用性和通俗表达,而针对"医学生"的版本则会包含更多专业术语和深度理论。 通过"类型-受众"对驱动内容多样性:每个"类型-受众"组合定义了一种重构方向,使同一原始文本能以不同形式呈现(如将科学知识转化为面向儿童的故事、面向学者的分析报告等),从而避免数据重复,增强模型对不同场景的泛化能力。本质上是一种数据增强策略,通过系统化地生成海量"类型-受众"组合,将现有文本重构为多样化的变体,既保留核心信息,又覆盖不同表达形式和读者群体,对模型训练数据进行增强,从而提升模型性能。
具体可以看看这篇文章:新思路!如何在数据稀缺下构建高质量丰富数据集?
Review 领域树的准确性,若质量不佳,建议手动调整后再进行后续动作:

Review 文本分块的质量,若质量不佳,可点击文献,进行自定义分块

生成问题
选择指定文本块,或者批量、全选文本块,进行批量问题提取:


建议选择自动提取问题,将创建后台异步任务,可随时到【问题管理】 Review 已生成的问题:

建议对所有已生成的问题进行人工 Review,剔除和本次微调任务不相关、质量较差的问题,例如:
-
- 问题:"文献中提到的用户隐私保护政策是否符合 GDPR 标准?"
- 剔除理由:关注政策合规性,而非数据集中的技术要素(如漏洞样本、攻击日志、网页代码数据等)。
-
- 问题:"该研究的实验环境配置是什么?"
- 剔除理由:询问硬件 / 软件环境,与数据集本身的构成(如数据格式、标注规则、样本量)无关。
-
- 问题:"作者在结论中提到的未来工作有哪些?"
- 剔除理由:指向研究展望,不涉及当前文献已使用的数据集信息。
-
- 问题:"文献里的 Web 安全数据是什么?"
- 剔除理由:表述过于笼统,未明确询问数据类型(如攻击样本、日志数据、漏洞报告)或特征,无法精准提取数据集信息。
-
- 问题:"数组变量$c'Servers'的key是什么"
- 剔除理由:问题和文本内容具有强相关性,不具备微调价值
生成答案
问题 Review 完成后,将模型切换为推理模型(DeepSeek R1),点击自动生成数据集:

点击后将自动创建后台异步提取任务。
数据蒸馏
为确保模型能够学习均衡,不遗漏 Web 安全领域的知识,弥补和满血版大模型的差距,我们选取更为强大的满血版大模型(DeepSeek R1 0528)作为教师模型来蒸馏部分数据集;进入【数据蒸馏】,选择【全自动蒸馏数据集】,配置要蒸馏的标签层级和单标签生产问题数量:


数据集确认

随后可到【数据集管理】Review 已生成的(从文献中提取的 + 从大模型蒸馏来的)数据集:

虽然工具在一定程度上加速了数据生产的过程,但最终结果也不能完全在不经过任何确认的情况下就直接使用!!!任何的数据合成工具都无法 100% 的保障能合成完美的数据,最终一定要经过人工确认、过滤和润色的环节,这往往决定了最终微调任务的成败。
以下是我在数据集 Review 环节总结的一些标准:
- 答案与文献事实一致:无样本量、漏洞类型、数据来源等关键信息错误
- 不超出文献范围:答案仅包含文献明确提及的内容,不添加未提及的数据集应用场景、评估指标等推断信息。
- 答案直接回应问题:不堆砌无关信息(如问题问"数据集来源",答案不可包含"模型训练效果")。
- 问题聚焦数据集属性:优先保留指向"数据构成、标注方式、样本特征"的问题,剔除与数据集无关的模型方法、政策合规等提问。
- 无关键信息缺失:时间范围、数据格式字段、标注一致性指标等需明确(如"2023年数据"应补充"2023.1-2023.12")。
- 术语统一:相同概念表述一致(如"跨站脚本攻击"与"XSS"需统一为一种说法)。
- 重复问题合并:同一数据集的同类问题(如"来源是哪里"与"采集渠道")仅保留一个。
- 模糊答案修正:"质量较高""包含多种攻击"等表述需补充具体数据(如"标注Kappa系数0.85""包含XSS/SQL注入/CSRF")。
经过人工(Web 安全专家)Review, 最终我们得到 2876 条高质量 Web 安全数据集,用于本次微调任务:

加载和验证数据集
我们可以将整理好的数据集导出到本地(比如 security.json),然后在 dataset_info.json 中定义 security 数据集:
 或者选择直接生成 LLaMA Factory 数据集配置:
或者选择直接生成 LLaMA Factory 数据集配置:

我们到 Easy Dataset 的项目数据目录,可以看到已经生成好的 dataset_info.json

回到 LLaMA Factory ,在数据路径处粘贴以上在 Easy Dataset 中生成好的配置文件路径:

然后点击预览数据集,能够加载到数据,说明数据集配置成功:

今天这一期,我们就讲到这里,下一期,我会带大家一起学习微调过程中各种参数如何设置,以及如何估算微调过程中的显存消耗,以及一些显存优化的技巧。