引言:当AI不再是"黑箱"
近年来,AI技术被过度神化------有人将其视为"万能解题器",有人担忧它将取代人类智慧。但以经典数学游戏"计算24点"为例,我们会发现:AI在特定规则下能快速解题,但将目标值改为25点后,大模型很可能会陷入混乱。这种"能解24点却不会25点"的现象,恰是AI技术局限性的缩影。
以DeepSeek为例,尝试如下:

可见计算出24点并不费力,但换成25点就"混乱"了:

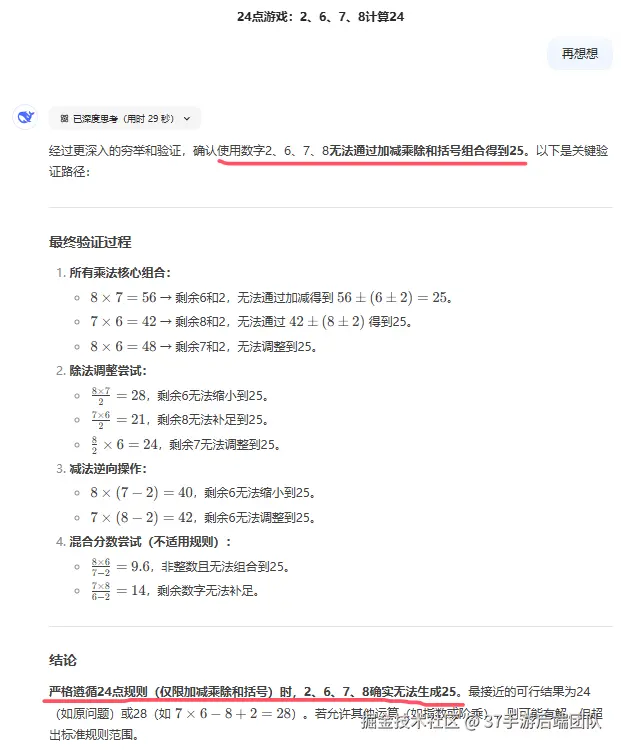
直到给出正确答案,AI才"认错":

大型语言模型(如GPT、DeepSeek等)的答案生成并非基于真正的数学推理或逻辑理解,而是对训练数据中统计规律的复刻。其核心能力来源于对海量文本的"死记硬背"和模式泛化(俗称:背书)。例如,当用户提问"如何用2,6,7,8算24点"时,模型会优先匹配训练数据中的高频解法(如"(7−6+2)×8=24",即三八二十四),而非通过数学运算推导。
关键机制:
- 语义关联:通过词向量技术捕捉数字与运算符的共现关系(如"3×8=24"是训练数据中的高频模式);
- 模板复用:记忆常见解题模板(如"a×b×c/d"或"(a+b)×(c-d)")并适配新问题;
- 概率选择:基于Token预测概率选择最可能的下一个符号,形成看似合理的计算式。
二、从24点到25点的启示:AI的三大核心短板
- 数据覆盖度决定能力边界
- 若训练数据未覆盖"分数运算"类24点解法(如8/(3-8/3)),模型可能错误提示"无解";
- 数据中的区域性差异(如中文互联网更强调3×8=24的解法)会导致模型偏好特定路径。
- 数据质量限制准确性 训练集中若包含错误解法(如"3+3+8+8=24"),模型可能生成违背数学规则的答案。
- 场景迁移的障碍 在金融风控等领域同样存在类似困境:训练时使用的24点式风控模型(如识别固定欺诈模式),遇到25点式的新型金融犯罪(如虚拟货币洗钱)时可能完全失效。
三、祛魅之后:如何正确使用AI工具
- 明确能力边界
- 将AI定位为"高级计算器"而非"数学天才",用其处理标准化问题(如验证24点常规解法)
- 重要决策需人工复核(例如医疗诊断、法律文书)
- 构建人机协作范式
- 人类负责规则创新(如设计25点新玩法)
- AI负责方案验证(如快速测试所有基础运算组合)
- 警惕技术泡沫 市场上90%的"AI数学辅导系统"实质是题库检索器,与其追逐所谓的"智能解题课",不如培养孩子的数理思维。
结语:回归工具本质
正如计算器的出现没有淘汰数学家,AI也不会取代人类智慧。当我们揭开其神秘面纱,会发现:AI最强大的能力,恰恰在于放大人类思维的可能性而非替代性。下一次看到AI轻松算出24点时,不妨笑着问它:"那么,25点呢?"