一、哪些情况会导致索引失效
- 创建了组合索引,但查询条件未遵守最左匹配原则;
- 在索引列上进行计算、函数、类型转换等操作;
- 发生隐式转换
- 没覆盖索引时,以 % 开头的LIKE 查询比如 LIKE '%abc';
- 查询条件中使用 OR,且 OR的前后条件中有一个列没有索引,涉及的索引都不会被使用到(MySQL里,即使or左边条件满足,右边条件依然要进行判断)
- IN的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
- 范围条件右边的列索引失效,例如(a,b,c)联合索引,查询条件a,b,c,如果b使用了范围查询,那么b右边的c索引失效
- 不同的字符集进行比较前需要进行转换会造成索引失效。
- ...
二、分析原因
挑几个好玩的条件进行分析:
2.1、为什么联合索引的使用要遵循最佳左前缀?
举例:创建一个(a,b)的联合索引,那么它的索引树就是下图的样子
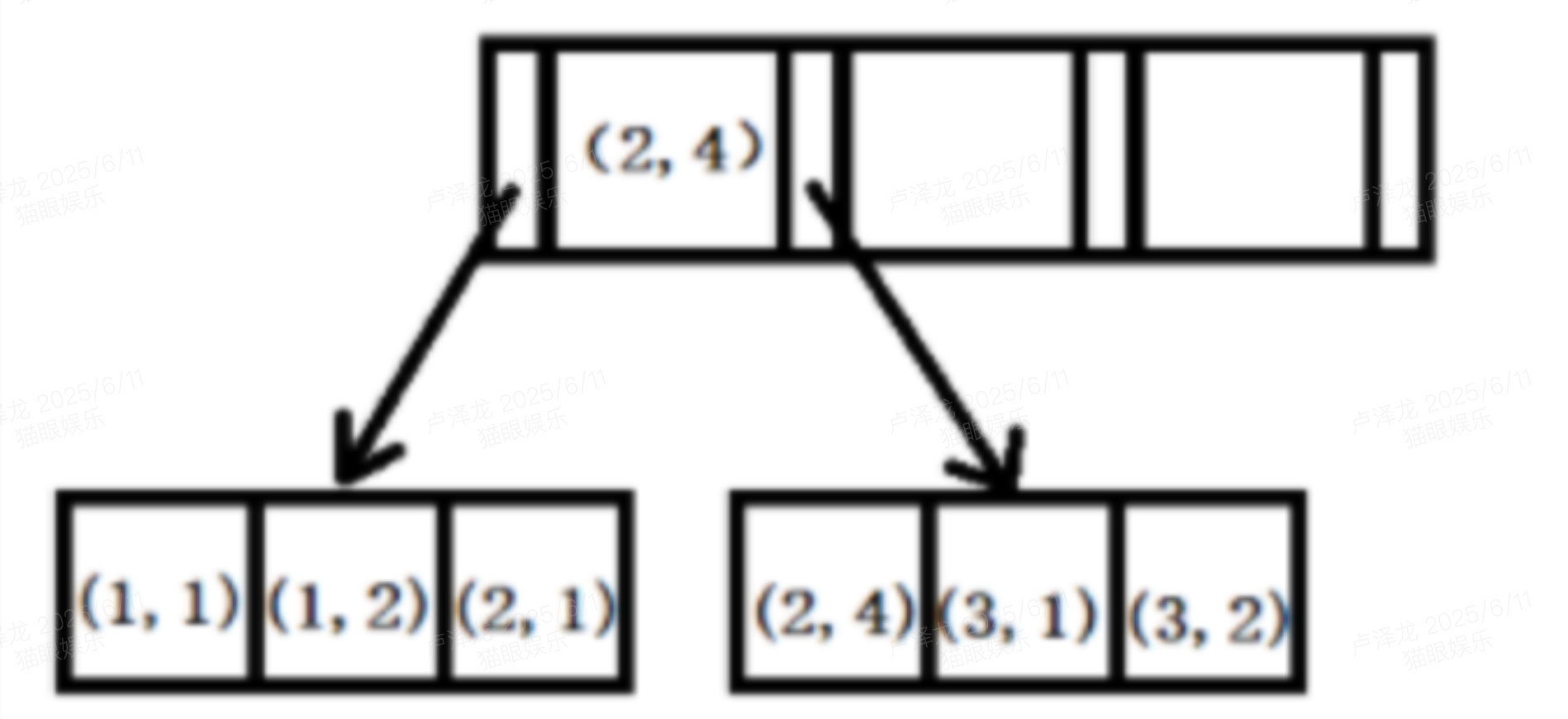
直接看图中第二排:可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。
但是我们又可发现a在等值的情况下,b值又是按顺序排列的,但是这种顺序是相对的。
这是因为MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序。所以b=2这种查询条件没有办法利用索引。
2.2、类型转化为什么会导致索引失效?发生类型转化会一定导致索引失效吗?
sql
CREATE TABLE `test1` (
`id` int(11) NOT NULL,
`num1` int(11) NOT NULL DEFAULT '0',
`num2` varchar(11) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `num1` (`num1`),
KEY `num2` (`num2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1: SELECT * FROM test1 WHERE num1 = 10000; ✅
2: SELECT * FROM test1 WHERE num1 = '10000';✅
3: SELECT* FROM test1 WHERE num2 = 10000;❌
4: SELECT * FROM test1 WHERE num2 = '10000';✅
经测试这四条 SQL 最后的执行结果却相差很大,在千万级的数据量下,其中 124 三条 SQL 基本都是瞬间出结果,大概在 0.001~0.005 秒,这样的结果可以判定这三条 SQL 性能基本没差别了。
但是第三条 SQL,多次测试耗时基本在 4.5~4.8 秒之间。
这四条sql的执行计划如下:

问题点来了:为什么2和3左右两边的类型不一致,2可以用索引,3却不能用索引?
请看MYSQL官方文档:https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben
切换成中文模式,我截了一个比较转化规则的图片:

根据官方文档的描述,我们的第 23 两条 SQL 都发生了隐式转换,第 2 条 SQL 的查询条件num1 = '10000',左边是int类型右边是字符串,第 3 条 SQL 相反,那么根据官方转换规则第 7 条,左右两边都会转换为浮点数再进行比较。
第 3 条 SQL:SELECT * FROM test1 WHERE num2 = 10000; 右边int类型10000转换浮是唯一的。但是左边是检索条件,'10000'转到10000是唯一,但是其他字符串也可以转换为10000,比如'10000a','010000','10000'等等都能转为浮点数10000,这样的情况下,是不能用到索引的。
tips:
- 不以数字开头的字符串都将转换为0。如'abc'、'a123bc'、'abc123'都会转化为0;
- 以数字开头的字符串转换时会进行截取,从第一个字符截取到第一个非数字内容为止。比如'123abc'会转换为123,'012abc'会转换为012也就是12,'5.3a66b78c'会转换为5.3,其他同理。
所以:SELECT* FROM test1 WHERE num2 = 10000; 这个 SQL 可以查出 num2 = '10000a','010000'这些数据
而第2条SQL,字符串'10000'转化为浮点数10000是固定的,根据这个条件去检索索引是ok的
2.3、 IN 的取值范围较大时会导致索引失效(我认为了解即可,主要和mysql优化器判断使用索引的成本有关)
其底层原理主要涉及查询优化器的决策过程和索引的使用成本。
下面是我问GPT,他给出的回答:
- 查询优化器的工作原理: MySQL 的查询优化器会根据查询条件生成多种执行计划,并选择其中成本最低的执行计划。成本的计算包括 I/O操作、CPU 消耗等。
- 索引的使用成本: 当 IN的取值范围较小时,查询优化器会认为使用索引进行多次查找的成本较低,因此会选择使用索引。然而,当 IN的取值范围较大时,查询优化器会认为使用索引进行多次查找的成本较高,因为每次查找都需要进行随机 I/O 操作,导致整体成本增加。
- 全表扫描的选择: 当 IN的取值范围较大时,查询优化器会认为全表扫描的成本较低,因为全表扫描只需要一次顺序读取所有数据,而使用索引则需要进行多次随机读取数据。顺序读取的I/O 操作通常比随机读取的 I/O 操作更快,因此在这种情况下,查询优化器会选择全表扫描。
下面是mysql官方文档的解释:(直接看第三条)
相关链接:https://dev.mysql.com/doc/refman/5.7/en/table-scan-avoidance.html
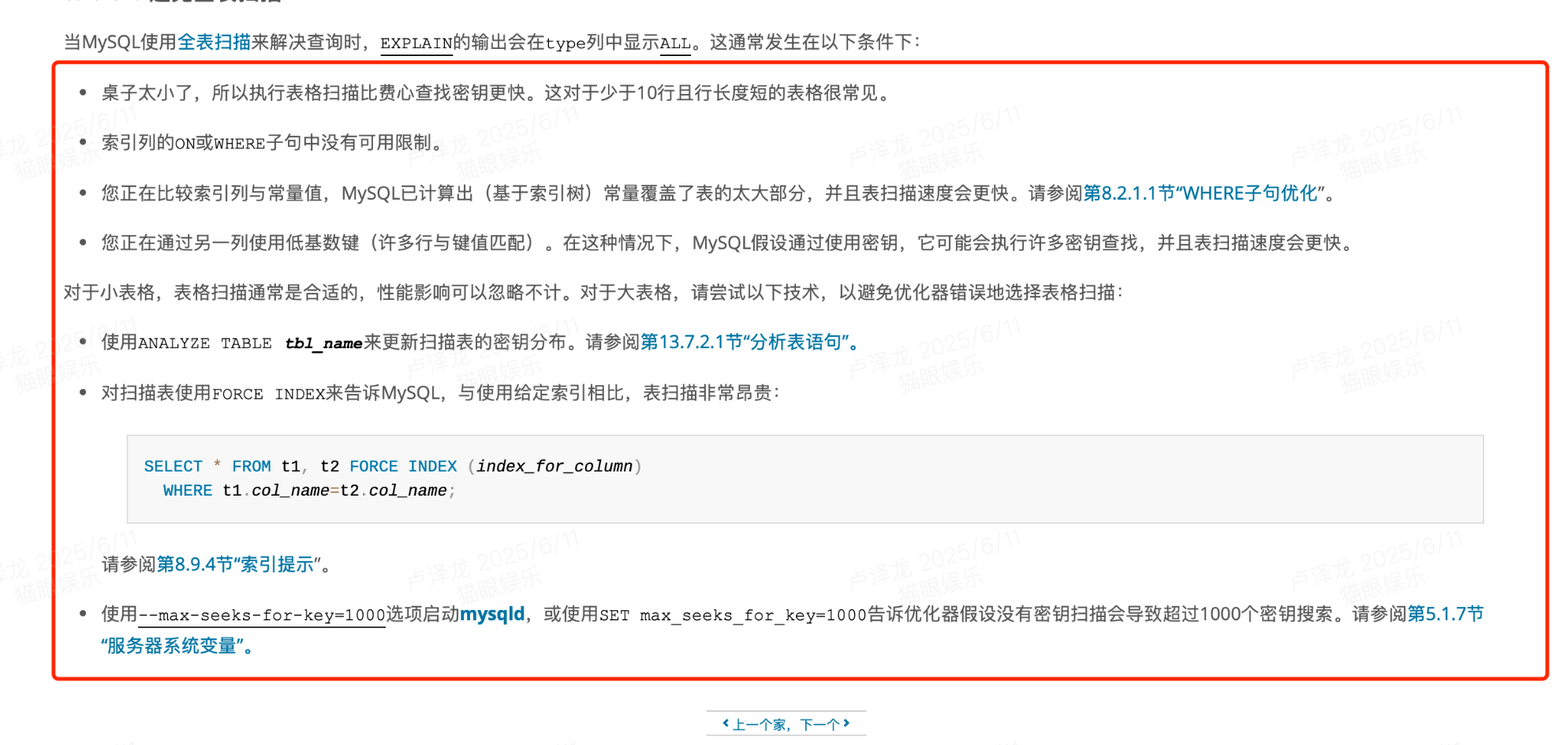
这张图也说明了其他索引可能失效的情况,比如表的数据太少了等等...