一、教程概述
本教程将基于数眼智能 API,结合 AI 智能体工作流的核心设计理念,手把手教你搭建一套可复用、高灵活的智能工作流。通过数眼智能 API 的多场景能力(如数据识别、智能分析、结果输出等),配合工作流的步骤拆分与逻辑编排,实现复杂任务的自动化处理。
适用场景:文档智能审核、数据批量处理、客户咨询自动响应、供应链数据协同等需要多步骤流程化的业务场景。前置条件:
已注册数眼智能平台账号并获取 API 密钥(Access Key/Secret Key)
具备基础的接口调用知识(HTTP/HTTPS)
了解 JSON 数据格式
可选工具:Postman(接口测试)、Draw.io(流程图绘制)、Python/Java(代码集成)
二、核心概念铺垫
在搭建前,先明确两个关键概念:
数眼智能 API:提供标准化的智能能力接口,支持数据识别、内容审核、信息提取、智能分析等核心功能,可理解为工作流中的 "专业工具"。
AI 智能体工作流:将复杂任务拆分为有序的步骤,通过 API 调用、规则判断、结果流转,实现任务的自动化执行(参考文档中 "流水线" 类比)。
本教程将采用「提示链 + 路由器」混合设计模式(文档核心模式组合):
提示链:按顺序执行 API 调用步骤,上一步输出作为下一步输入
路由器:根据 API 返回结果动态分支,处理不同场景(如正常结果 / 异常情况)
三、搭建步骤(附流程图)
第一步:需求拆解与工作流设计
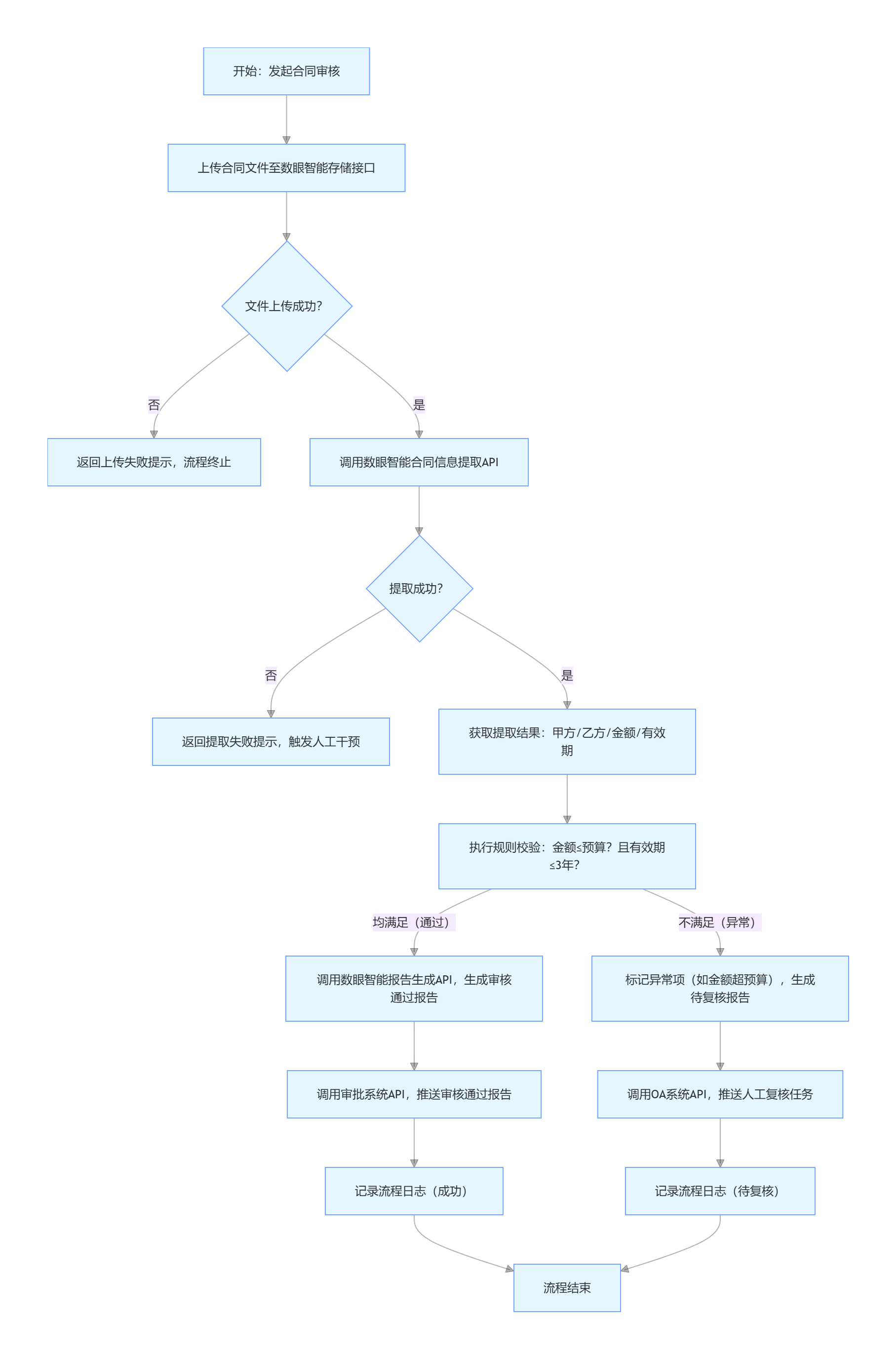
以「企业合同智能审核工作流」为例,拆解核心需求与步骤:
上传合同文件(支持 PDF/Word)
调用数眼智能 API 提取合同关键信息(甲方、乙方、金额、有效期等)
规则校验(判断金额是否超预算、有效期是否合理)
结果分支处理:
校验通过:生成审核报告并推送至审批系统
校验异常:标记问题点并推送人工复核
记录流程日志(便于追溯)
工作流可视化流程图
第二步:数眼智能 API 准备
登录数眼智能开放平台,进入「API 管理」页面,申请以下核心 API 权限:
文件存储 API:用于上传合同文件(接口地址:https://api.shuyanai.com/v1/storage/upload)
合同信息提取 API:提取关键字段(接口地址:https://api.shuyanai.com/v1/contract/extract)
报告生成 API:生成标准化审核报告(接口地址:https://api.shuyanai.com/v1/report/generate)
获取 API 密钥:在「个人中心 - 开发者设置」中查看 Access Key 和 Secret Key(用于接口鉴权)
接口调用格式(通用):
- 请求方式:POST
- 请求头:
javascript
{
"Authorization": "Bearer {Access Key}_{Secret Key}",
"Content-Type": "application/json"
}- 响应格式:JSON(包含 code/msg/data 字段,code=200 表示成功)
第三步:分步骤实现工作流(附代码示例)
以下以 Python 为例,实现核心步骤的 API 调用与流程编排(实际生产可集成到业务系统中)。
- 工具准备
安装依赖库:
bash
pip install requests # 用于API调用
pip install python-dotenv # 用于管理API密钥- 核心代码实现
python
import requests
import os
from dotenv import load_dotenv
# 加载API密钥(建议放在.env文件中,避免硬编码)
load_dotenv()
ACCESS_KEY = os.getenv("SHUYAN_ACCESS_KEY")
SECRET_KEY = os.getenv("SHUYAN_SECRET_KEY")
BASE_URL = "https://api.shuyanai.com/v1"
# 1. 上传合同文件
def upload_contract(file_path):
url = f"{BASE_URL}/storage/upload"
headers = {
"Authorization": f"Bearer {ACCESS_KEY}_{SECRET_KEY}"
}
files = {
"file": open(file_path, "rb")
}
response = requests.post(url, headers=headers, files=files)
result = response.json()
if result["code"] == 200:
return result["data"]["file_id"] # 返回文件ID,用于后续提取
else:
raise Exception(f"文件上传失败:{result['msg']}")
# 2. 提取合同关键信息
def extract_contract_info(file_id):
url = f"{BASE_URL}/contract/extract"
headers = {
"Authorization": f"Bearer {ACCESS_KEY}_{SECRET_KEY}",
"Content-Type": "application/json"
}
data = {
"file_id": file_id,
"extract_fields": ["party_a", "party_b", "amount", "valid_period"] # 指定提取字段
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
if result["code"] == 200:
return result["data"] # 返回提取结果:{"party_a": "XX公司", ...}
else:
raise Exception(f"信息提取失败:{result['msg']}")
# 3. 规则校验逻辑
def validate_contract(contract_info, max_budget=1000000, max_valid_period=3):
"""
校验规则:金额≤预算(默认100万),有效期≤3年
返回:(校验结果, 异常信息)
"""
amount = contract_info.get("amount", 0)
valid_period = contract_info.get("valid_period", 0)
errors = []
if amount > max_budget:
errors.append(f"合同金额{amount}元,超出预算{max_budget}元")
if valid_period > max_valid_period:
errors.append(f"合同有效期{valid_period}年,超出最大允许期限{max_valid_period}年")
return len(errors) == 0, errors
# 4. 生成审核报告
def generate_report(contract_info, is_pass, errors=None):
url = f"{BASE_URL}/report/generate"
headers = {
"Authorization": f"Bearer {ACCESS_KEY}_{SECRET_KEY}",
"Content-Type": "application/json"
}
data = {
"contract_info": contract_info,
"audit_result": "通过" if is_pass else "待复核",
"error_details": errors or []
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
if result["code"] == 200:
return result["data"]["report_url"] # 报告访问URL
else:
raise Exception(f"报告生成失败:{result['msg']}")
# 5. 推送结果至下游系统(示例:审批系统/OA系统)
def push_to_system(report_url, is_pass, contract_info):
if is_pass:
# 推送至审批系统
approval_url = "https://your-approval-system.com/api/push"
data = {
"contract_name": f"{contract_info['party_a']}与{contract_info['party_b']}合同",
"report_url": report_url,
"status": "待审批"
}
else:
# 推送至OA系统(人工复核)
approval_url = "https://your-oa-system.com/api/push-task"
data = {
"contract_name": f"{contract_info['party_a']}与{contract_info['party_b']}合同",
"report_url": report_url,
"status": "待复核",
"error_details": contract_info.get("error_details", [])
}
response = requests.post(approval_url, json=data)
return response.json()
# 6. 流程日志记录
def record_log(contract_info, status, log_path="contract_audit_logs.txt"):
log_content = (
f"时间:{pd.Timestamp.now()}\n"
f"合同:{contract_info['party_a']} - {contract_info['party_b']}\n"
f"状态:{status}\n"
f"----------------------------------------\n"
)
with open(log_path, "a", encoding="utf-8") as f:
f.write(log_content)
# 主工作流执行函数
def run_contract_audit_workflow(file_path):
try:
# 步骤1:上传文件
file_id = upload_contract(file_path)
print(f"文件上传成功,file_id:{file_id}")
# 步骤2:提取信息
contract_info = extract_contract_info(file_id)
print(f"信息提取成功:{contract_info}")
# 步骤3:规则校验
is_pass, errors = validate_contract(contract_info)
contract_info["error_details"] = errors
print(f"规则校验结果:{'通过' if is_pass else '异常'},异常信息:{errors}")
# 步骤4:生成报告
report_url = generate_report(contract_info, is_pass, errors)
print(f"报告生成成功:{report_url}")
# 步骤5:推送下游系统
push_result = push_to_system(report_url, is_pass, contract_info)
print(f"结果推送成功:{push_result}")
# 步骤6:记录日志
status = "审核通过,已推送审批" if is_pass else "存在异常,已推送复核"
record_log(contract_info, status)
print("工作流执行完成!")
except Exception as e:
print(f"工作流执行失败:{str(e)}")
record_log({"party_a": "未知", "party_b": "未知"}, f"执行失败:{str(e)}")
# 执行工作流(传入合同文件路径)
if __name__ == "__main__":
run_contract_audit_workflow("test_contract.pdf")第四步:工作流测试与优化
- 测试场景覆盖:
- 正常场景:文件上传成功→信息提取完整→规则校验通过→报告生成→推送审批
- 异常场景 1:文件格式错误(如上传图片文件)→ 上传失败→流程终止
- 异常场景 2:合同信息提取不全(如缺少金额字段)→ 提取失败→触发人工干预
- 异常场景 3:金额超预算→校验异常→推送人工复核
- 优化方向:
- 增加重试机制:API 调用失败时(如网络波动),自动重试 2-3 次
- 扩展规则库:根据业务需求添加更多校验规则(如合同条款合规性检查)
- 性能优化:大文件上传采用分片上传,批量合同处理采用并行化(参考文档 Map-Reduce 模式)
- 监控告警:通过数眼智能 API 的监控接口,实时查看工作流执行状态,异常时触发邮件 / 短信告警
第五步:工作流发布与复用
- 发布:将工作流代码集成到业务系统(如企业 ERP、OA 平台),配置定时任务或触发条件(如用户上传合同后自动执行)
- 复用:通过参数化配置(如修改max_budget、extract_fields等参数),快速适配不同类型的合同审核(如采购合同、销售合同)
- 迭代:定期分析工作流日志,优化 API 调用顺序、规则校验逻辑,提升自动化率和准确性
四、常见问题排查
- API 调用报错 401:检查 Access Key/Secret Key 是否正确,是否过期
- 信息提取不完整:在extract_contract_info函数中扩展extract_fields字段,或联系数眼智能技术支持优化模型
- 流程执行超时:大文件处理时增加超时时间(requests.post(timeout=30)),或采用异步调用方式
- 报告格式不符合需求:通过generate_report接口的template_id参数,选择数眼智能提供的标准化模板,或自定义报告模板
五、扩展场景
基于本教程的搭建思路,可扩展其他数眼智能 API 工作流:
-
客户咨询自动响应工作流:
上传咨询记录→调用数眼智能意图识别 API→路由至对应回答模板→生成回复内容→推送客户
-
供应链数据处理工作流:
上传采购订单→调用数眼智能数据提取 API→库存校验→生成补货建议→推送供应商
-
文档智能分类工作流:
上传多类型文档→调用数眼智能文档分类 API→路由至对应处理流程(如合同→审核、发票→报销)
六、总结
使用数眼智能 API 搭建工作流的核心是「拆分步骤 + API 串联 + 规则驱动」,通过本教程的方法,你可以快速实现复杂任务的自动化处理,提升业务效率。关键在于:
- 合理拆解任务,确保每个步骤单一职责
- 灵活运用工作流设计模式(如提示链、路由器)
- 充分利用数眼智能 API 的标准化能力,减少重复开发
- 持续测试与优化,提升工作流的稳定性和适应性
随着 AI 技术的发展,可进一步引入数眼智能的高级能力(如多模态识别、智能决策),结合文档中的协调器 - 工作者模式,实现更复杂的动态任务处理,助力企业数字化转型。