一、什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了 信息检索(Retrieval) 与 自然语言生成(Generation) 的问答架构,旨在提升大语言模型的事实性、可追溯性与最新性。
传统的大语言模型(如 GPT 系列)虽然拥有强大的生成能力,但存在两个明显的限制:
- 知识封闭性:训练完成后的知识无法动态更新。
- 幻觉问题(Hallucination):模型会生成看似合理却不真实的内容。
RAG 的提出正是为了解决这些问题。
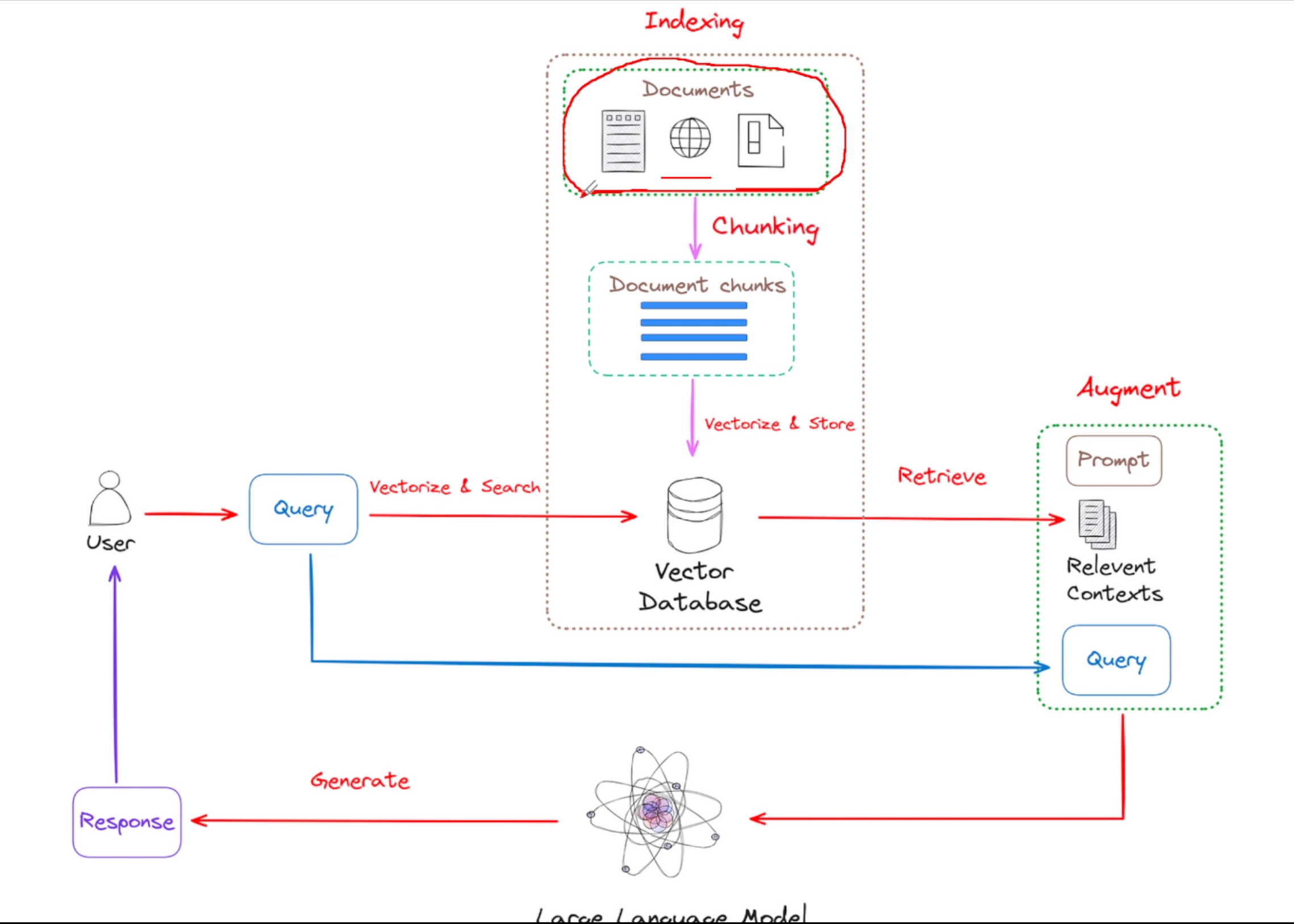
二、RAG 的流程详解
RAG 的整体流程如下:
1. 用户提问(User → Query)
用户提出一个查询(Query),系统开始处理请求。
2. 查询向量化并检索(Vectorize & Search)
查询被转换为向量表示,并在 向量数据库(Vector Database) 中进行相似度检索,以寻找与问题相关的文档内容。
3. 文档索引与预处理(Indexing)
系统预先将各种文档(如网页、PDF、Word 等)进行以下处理:
- 文档加载:将外部文档输入系统;
- 文档切分(Chunking):将大文档切分为更小的文本块(如段落、句子);
- 向量化存储:使用嵌入模型将每个文本块转为向量,并存入向量数据库中(如 FAISS、Milvus、Qdrant)。
4. 相关上下文检索(Retrieve Relevant Contexts)
系统根据查询从向量数据库中检索出最相关的文档片段,作为补充上下文信息(Relevant Contexts)。
5. 增强输入并生成(Augment + Generate)
将用户的原始问题与检索到的文档拼接为提示词(Prompt),一同输入到大语言模型(LLM)中生成最终回答。
Prompt:
根据以下内容回答问题:
[相关内容1]
[相关内容2]
[相关内容3]
用户的问题是:GPT-4 和 GPT-3.5 有什么区别?6. 返回响应(Response)
大语言模型(如 GPT、LLaMA、ChatGLM 等)在增强上下文的基础上生成回答,并将其返回给用户。
三、RAG 系统结构图
下面是 RAG 系统的结构图示意:
四、RAG 的核心模块组成
| 模块名称 | 功能描述 |
|---|---|
| 向量化模块 | 将文档片段与用户查询向量化,便于在向量空间中计算相似度。 |
| 文档加载与切分模块 | 加载原始文档,并按段落或句子切分成适合处理的文档块(Document Chunks)。 |
| 向量数据库 | 存储文档片段的向量表示,支持高效相似度检索(如 FAISS、Milvus 等)。 |
| 检索模块 | 根据用户 Query 检索出相关的文档片段,返回给生成模块使用。 |
| 大语言模型模块 | 接收查询与上下文,基于语义理解和知识生成最终回答。 |