在企业运营过程中,时常会面临处理海量 PDF 文件的挑战。从 PDF 指定区域提取内容并用于重命名文件,能极大地优化企业内部的文件管理流程,提升工作效率。以下为您详细介绍其在企业中的应用场景、具体使用步骤及注意事项。
详细使用步骤
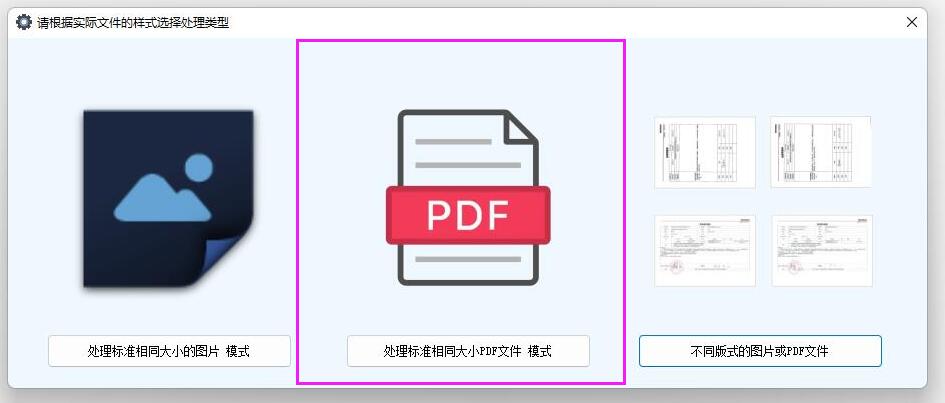
**选择处理模式:**启动软件后,若处理的是普通文本型 PDF 文件,选择 "PDF 识别模式";若是图片型 PDF 文件(如扫描件),必须选择此模式,以保障软件能正确识别文件中的文字内容。
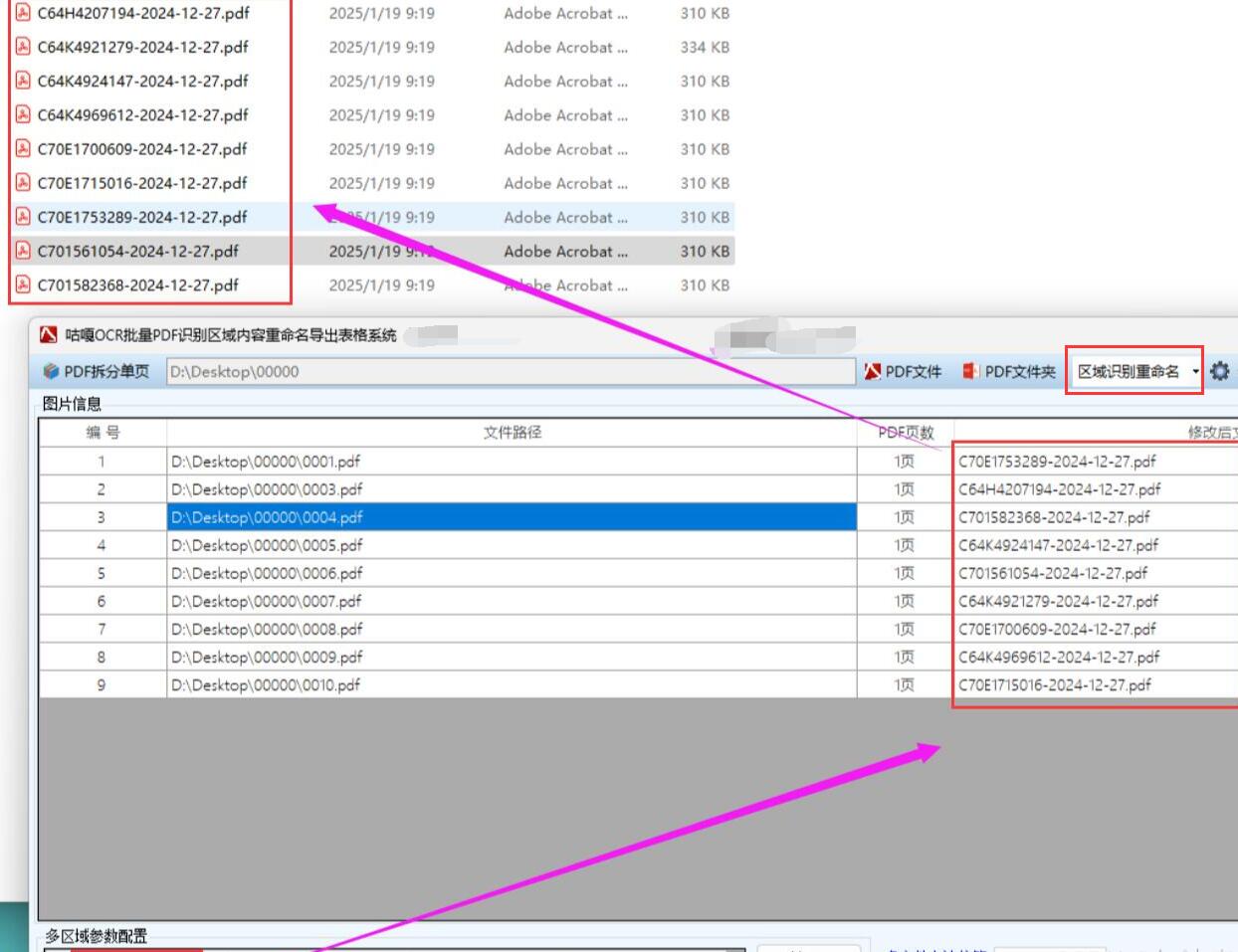
**框选识别区域:**将一份具有代表性的样本 PDF 文件拖入软件操作界面,利用软件提供的区域选择工具,在 PDF 页面上精准框选出需要识别文字的区域。
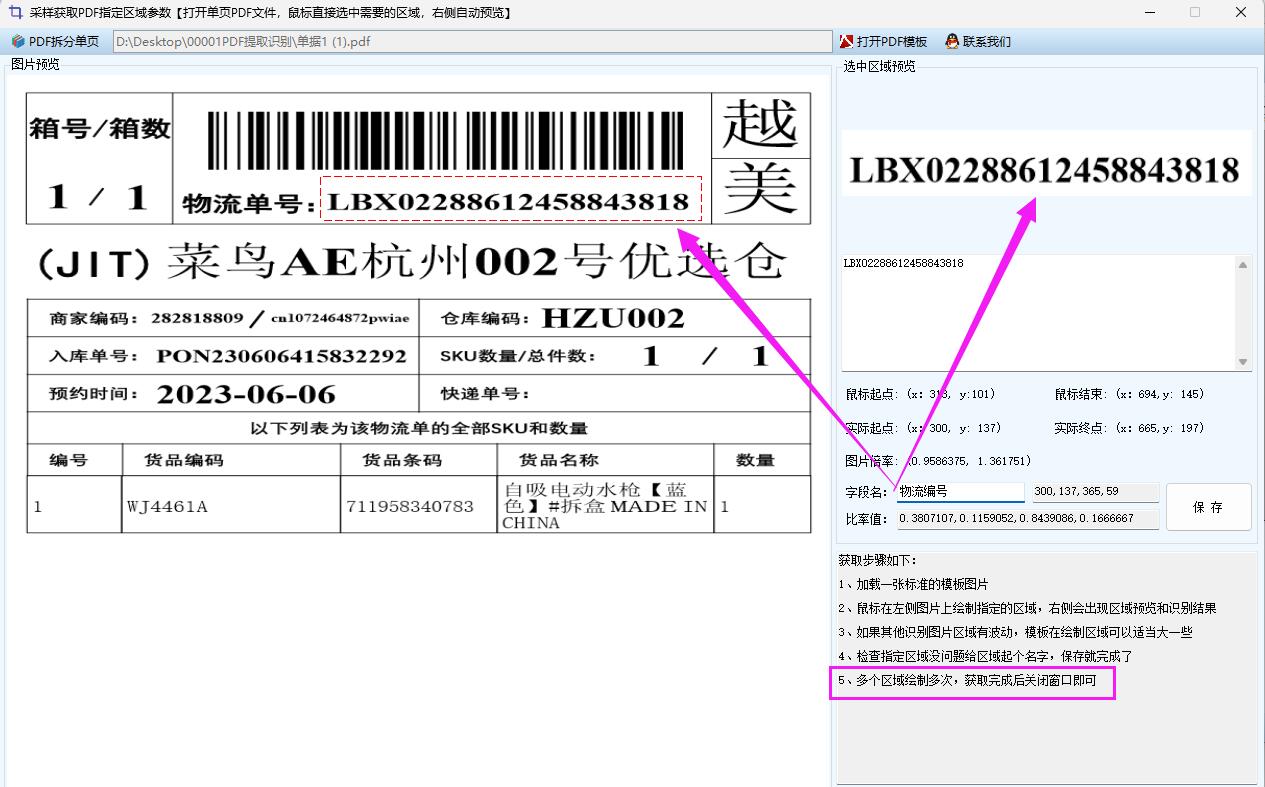
框选时应注意确保完全覆盖目标文字,同时避免选取过多无关区域,以免降低识别效率和准确性。若需识别多个区域,可多次进行框选操作。完成框选后,为每个框选区域赋予有意义的名称,如 "合同编号""发票金额""项目阶段" 等,这些名称将作为后续导出表格的列名,方便对识别结果进行整理和分析。保存区域坐标:完成所有识别区域的框选和命名后,保存每个绘制区域的坐标信息。若存在多个识别区域,需分别保存各区域的坐标,以便后续对其他 PDF 文件进行相同区域的识别操作。
**导入待处理文件:**点击软件界面中的 "导入 PDF" 按钮,在弹出的文件选择对话框中,选中包含待处理 PDF 文件的文件夹,将所有相关文件导入软件。
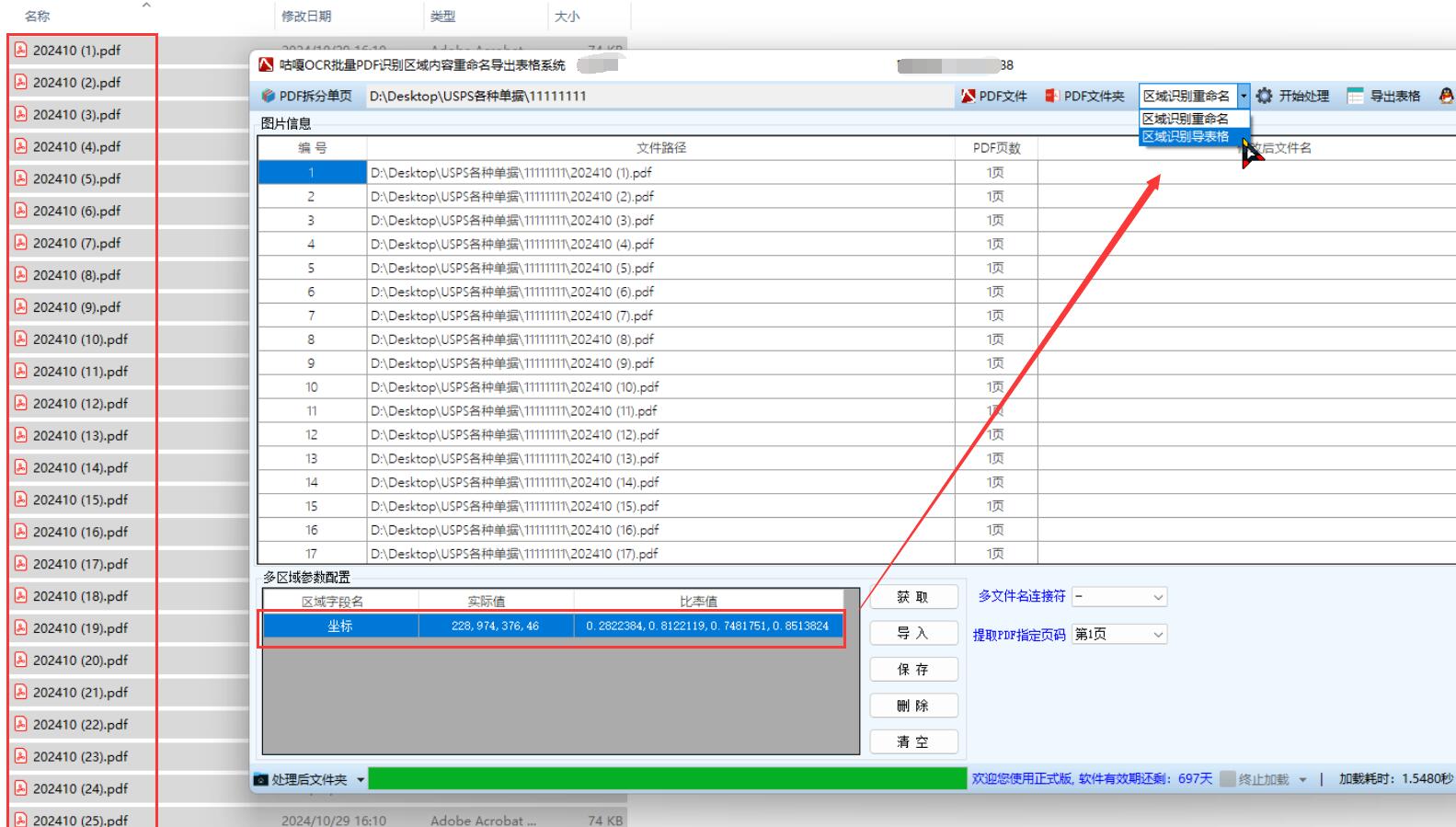
加载区域坐标:文件导入完成后,加载之前保存的区域坐标,确保软件在后续处理过程中,能按照预设的指定区域对每个 PDF 文件进行识别。
开始批量处理: 确认所有设置无误后,点击 "开始处理" 按钮,软件将自动遍历导入的所有 PDF 文件,提取指定区域的文字内容,并按照设定的重命名规则对文件进行重命名。若同时选择了导出表格功能,软件还会将识别结果整理成表格形式。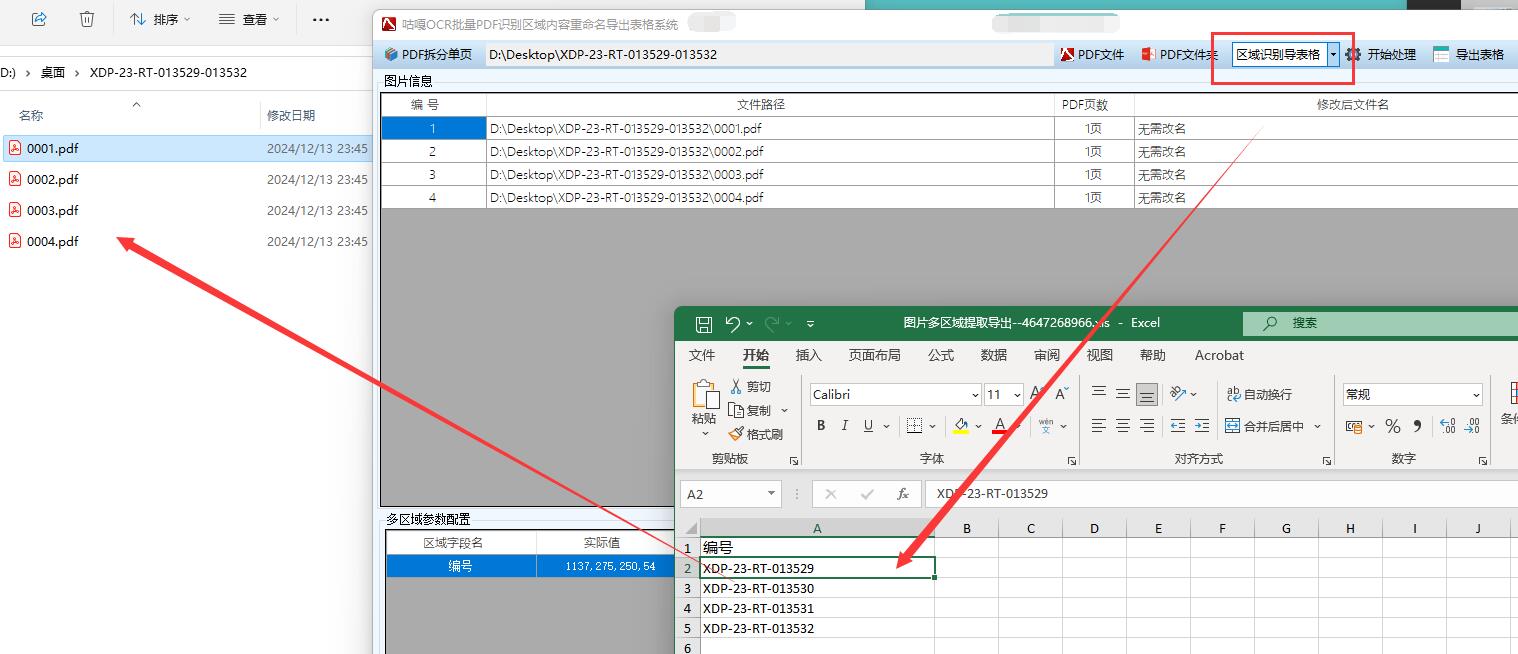
**校验结果:**批量处理完成后,仔细检查文件名是否准确反映了文件中指定区域的文字内容,确保所有文件都已成功重命名,无遗漏或重命名错误的情况。若选择了 "区域识别导表格" 功能,还需检查导出表格中的内容是否完整、准确,数据与 PDF 文件中的识别结果是否一致。如有错误或不符合预期的地方,及时返回相应步骤进行修正,如重新调整识别区域、修改重命名规则等,然后再次执行识别和重命名操作,直至结果符合要求。
还有操作不会或不懂的地方欢迎私信交流 !