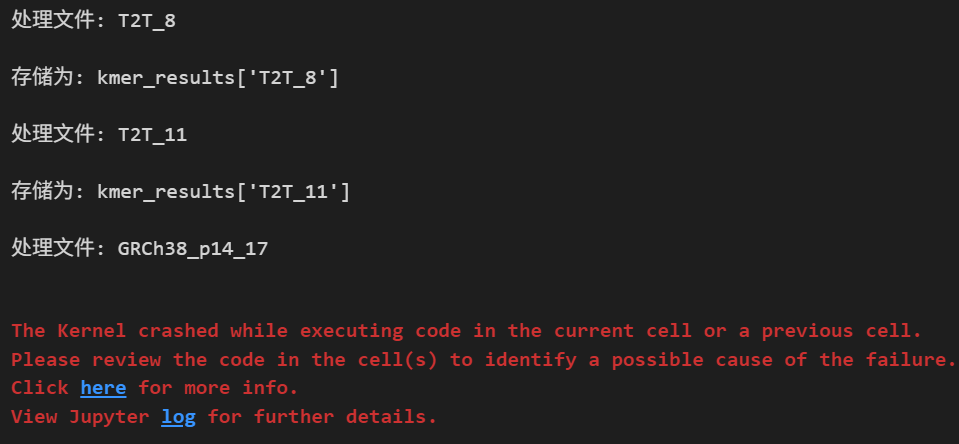
最近在做用k-mer评估基因组规模的任务,其中一个局部程序,想偷懒,直接在jupyter中跑了下结果,想看看这一小步处理如何,结果没想到内核崩溃了!
这一步我的草稿代码如下:
bash
import pandas as pd
import glob
from pathlib import Path
def kmer_dict(jf_txt_file,top_m):
"""
Args:
jf_txt_file (str): 主要是dump命令的输出文件路径
top_m(int):从k-mer文件中要提取的top几个k-mer
Fun:
从输入文件中返回该k-mer文件中top M的k-mer的字典,key为k-mer,value为该k-mer的计数,按照count的降序整理,返回该dict,同时输出为tsv格式的文件
后续如果要使用输出文件,可以继续使用pandas等进行处理;
如果要使用返回的字典变量,可以直接使用该函数的返回值
"""
kmer = pd.read_csv(jf_txt_file,sep=" ",header=None,names=["mer","count"])
# 按照降序排列,顺便只看前top_m行
kmer = kmer.sort_values(by="count",ascending=False).head(top_m)
# 输出为tsv格式文件
kmer.to_csv(jf_txt_file.replace(".txt",f"_{top_m}.tsv"),sep="\t",header=True)
# 同时返回每一个k-mer的字典
kmer_dict = dict(zip(kmer["mer"],kmer["count"]))
return kmer_dict
# 对于两个基因组的所有k-mer文件,使用前面定义的kmer_dict函数来提取top M的k-mer字典
Q1_dir = "/data1/project/omics_final/Q1"
kmer_files = glob.glob(f"{Q1_dir}/*.txt")
kmer_results = {}
for each_kmer in kmer_files:
each_kmer_name = Path(each_kmer).stem # 获取文件名,不包含路径和扩展名
print(f"处理文件: {each_kmer_name}\n")
# 此处对于每一个k-mer文件,提取其前10个对应的k-mer,并将结果输出为对应的变量
kmer_results[each_kmer_name] = kmer_dict(each_kmer,top_m=10)
print(f"存储为: kmer_results['{each_kmer_name}']\n")
做的事情呢,其实很简单,就是用jellyfish count,在自己的测试基因组组装数据集上统计了一下k-mer,
然后用jellyfish dump命令,将统计结果,用python稍微处理一下整理成字典形式,存到一个字典中;
我测试的数据只有2个新组装的人类基因组,各自大小也就在3G左右,k-mer文件将近30个,每个大小不一,k小的文件才几M,k大的文件组合花样多,一般都几十G,
任务是在jupyter中跑的,结果爆了,推测是处理大量k-mer数据导致的内存或计算资源耗尽。
问题来了:
我放在后台跑,比如python xxx.py,肯定能够成功执行,比放在cell中稳妥多了;
但是我的变量已经return出来了,我肯定还是想之后能够直接在python环境中访问的,虽然我用pandas再将结果文件读进去都一样的内容,但是太麻烦了,我太懒了。
有没有什么一般的策略,不仅仅局限于这个问题,就是可能会导致内核崩溃的稍微大型计算任务,
我又想像放在后台稳定运行一样能够跑完这个任务,又希望就放在cell中跑,跑完之后直接访问结果变量?
法1:使用批处理 + 保存中间结果
其实就是很简单,分批嘛,batch,我一次处理30多个数据多麻烦,每次只处理一小部分,比如说5个,如果还是太大了,就3个文件一处理;
重要的是我要及时将结果文件保存,所以还是输出到硬盘上了(其实理论上来讲,那我还是可以全部都放在后台运行,然后在代码上添加每一步都保存的命令,这样我还是可以保证结果变量能够访问);
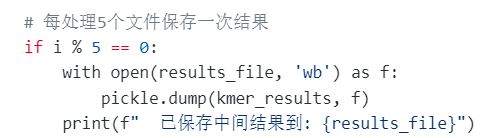
总之一小批一小批的运行并pickle输出到硬盘中保存,然后下一次运行判断哪些已经跑过了(这里比较重要,如果内核又崩溃了,我们就需要再次重启内核在cell中跑,但是已经跑过的结果就不用再跑了)。
当然,有人会担心如果我每次跑的时候,保存保存了一部分然后内核就崩溃了,那么文件系统检查的时候如果重新加载了这个变量,然后它一看如果发现我加载的字典中已经有这个结果了,哪怕是一部分,会不会直接跳过,然后导致我其实这个应该被关注留意的结果其实并没有得到重视?
比如说下面的这里?

其实这个问题我也考虑到了,所以我要确保每次保存结果的时候,都要完整保存或者说保存命令执行成功了,我才打印进程提醒:
比如说下面这里的进程------》
代码整体逻辑如下:
bash
import pandas as pd
import glob
import pickle
import os
from pathlib import Path
import gc
def kmer_dict(jf_txt_file, top_m):
"""k-mer处理函数,添加错误处理"""
try:
print(f" 正在读取文件: {jf_txt_file}")
kmer = pd.read_csv(jf_txt_file, sep=" ", header=None, names=["mer", "count"])
print(f" 数据形状: {kmer.shape}")
kmer = kmer.sort_values(by="count", ascending=False).head(top_m)
# 输出TSV文件
output_file = jf_txt_file.replace(".txt", f"_{top_m}.tsv")
kmer.to_csv(output_file, sep="\t", header=True, index=False)
# 返回字典
kmer_dict = dict(zip(kmer["mer"], kmer["count"]))
# 清理内存
del kmer
gc.collect()
return kmer_dict
except Exception as e:
print(f" 处理文件 {jf_txt_file} 时出错: {e}")
return None
def process_kmer_files_safely():
"""安全处理k-mer文件,支持断点续传"""
Q1_dir = "/data1/project/omics_final/Q1"
kmer_files = glob.glob(f"{Q1_dir}/*.txt")
# 结果保存文件
results_file = f"{Q1_dir}/kmer_results.pkl"
# 如果已有结果文件,先加载
if os.path.exists(results_file):
print(f"加载已有结果: {results_file}")
with open(results_file, 'rb') as f:
kmer_results = pickle.load(f)
print(f"已加载 {len(kmer_results)} 个结果")
else:
kmer_results = {}
print(f"找到 {len(kmer_files)} 个txt文件")
# 处理每个文件
for i, each_kmer in enumerate(kmer_files, 1):
each_kmer_name = Path(each_kmer).stem
# 跳过已处理的文件
if each_kmer_name in kmer_results:
print(f"[{i}/{len(kmer_files)}] 跳过已处理文件: {each_kmer_name}")
continue
print(f"[{i}/{len(kmer_files)}] 处理文件: {each_kmer_name}")
try:
result = kmer_dict(each_kmer, top_m=10)
if result is not None:
kmer_results[each_kmer_name] = result
print(f" 成功处理,获得 {len(result)} 个k-mer")
# 每处理5个文件保存一次结果
if i % 5 == 0:
with open(results_file, 'wb') as f:
pickle.dump(kmer_results, f)
print(f" 已保存中间结果到: {results_file}")
else:
print(f" 处理失败,跳过")
except Exception as e:
print(f" 发生异常: {e}")
continue
# 强制垃圾回收
gc.collect()
# 保存最终结果
with open(results_file, 'wb') as f:
pickle.dump(kmer_results, f)
print(f"\n最终结果已保存到: {results_file}")
print(f"总共处理了 {len(kmer_results)} 个文件")
return kmer_results
# 运行处理
try:
kmer_results = process_kmer_files_safely()
except Exception as e:
print(f"处理过程中发生错误: {e}")
# 尝试加载已保存的结果
results_file = "/data1/project/omics_final/Q1/kmer_results.pkl"
if os.path.exists(results_file):
with open(results_file, 'rb') as f:
kmer_results = pickle.load(f)
print(f"加载了已保存的结果: {len(kmer_results)} 个文件")真实运行情况:
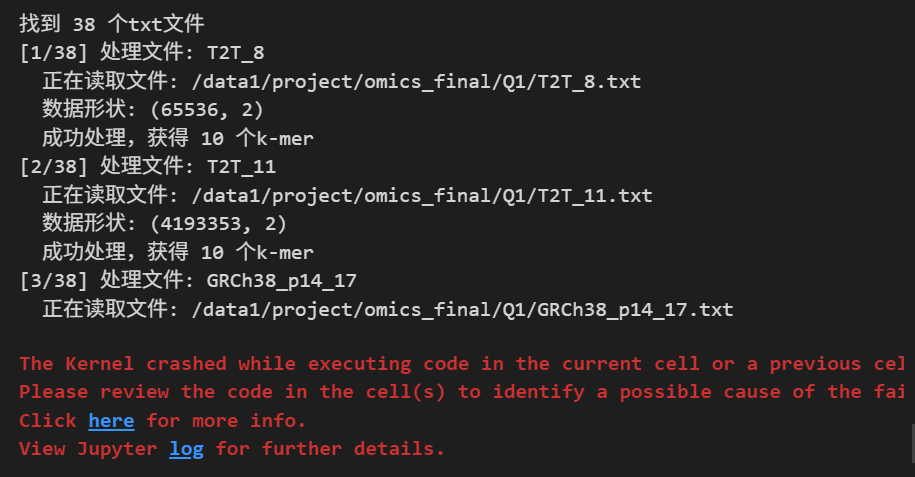
所以3个还是消耗太大了,对于我上面的执行逻辑,干脆就直接改为1,每运行1次就保存,当然我还是得蹲在前台一直看着这个代码的运行。
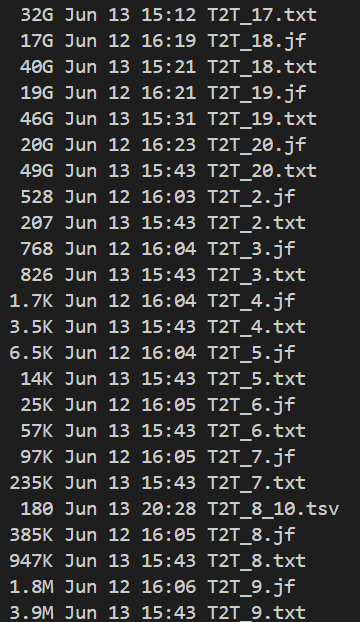
文件其实很多,我们先仔细看一下:
bash
ls -lh | awk -F " " '{print $5}' | grep "G" | awk -F "G" '{print $1}' | sort | uniq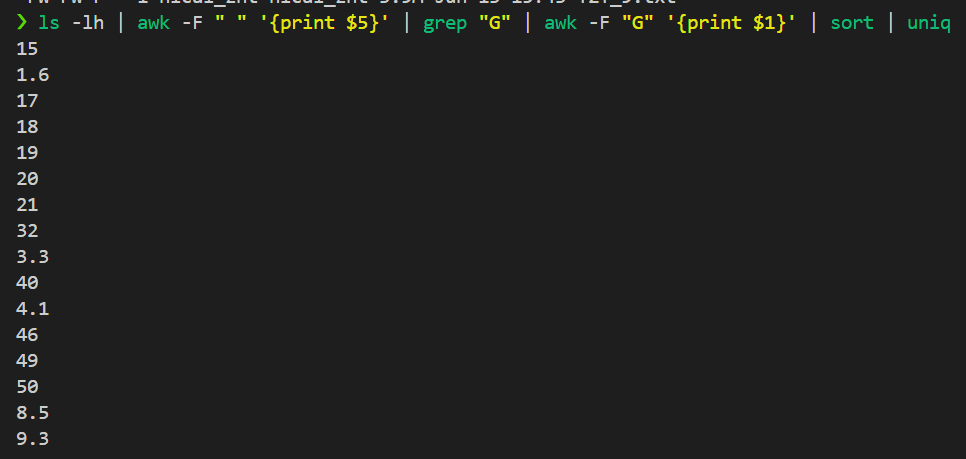
可以发现,其实最大的文件已经达到了50G了,比基因组规模3G大了十几倍,
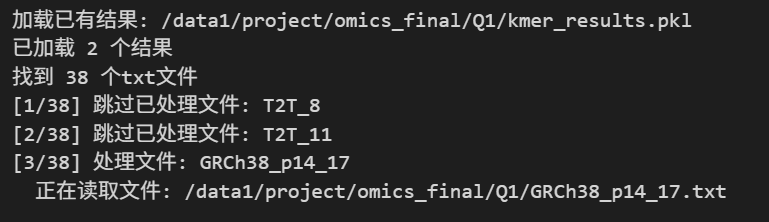
其实运行了好几次了,都是17-mer这个文件就一直卡着,其实我们也可以另外直接在shell中awk处理好输出top M的文件,也没必要什么都在python中处理,不然吃不消。
法2:使用Jupyter的后台执行
bash
# 在新的cell中运行
import threading
import time
def background_process():
"""后台处理函数"""
global kmer_results # 使用全局变量
try:
kmer_results = process_kmer_files_safely()
print("后台处理完成!")
except Exception as e:
print(f"后台处理出错: {e}")
# 启动后台线程
processing_thread = threading.Thread(target=background_process)
processing_thread.daemon = True # 设置为守护线程
processing_thread.start()
print("后台处理已启动,您可以继续使用其他cell")
print("使用 processing_thread.is_alive() 检查处理状态")其实就是多线程库threading的使用,主要函数继承前面的,主要改了点运行
法3:分批处理 + 内存优化
其实batch的想法还是和1一样的,只不过是多了个内存的监控强制优化
python
import pandas as pd
import glob
import pickle
from pathlib import Path
import gc
import psutil
import os
def get_memory_usage():
"""获取当前内存使用情况"""
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024 # MB
def process_kmer_batch(file_batch, batch_num):
"""处理一批文件"""
print(f"\n=== 处理批次 {batch_num} ===")
print(f"内存使用: {get_memory_usage():.1f} MB")
batch_results = {}
for i, file_path in enumerate(file_batch, 1):
filename = Path(file_path).stem
print(f" [{i}/{len(file_batch)}] 处理: {filename}")
try:
# 检查内存使用
memory_usage = get_memory_usage()
if memory_usage > 4000: # 超过4GB则强制清理
print(f" 内存使用过高 ({memory_usage:.1f} MB),执行垃圾回收")
gc.collect()
result = kmer_dict(file_path, top_m=10)
if result is not None:
batch_results[filename] = result
print(f" 成功,获得 {len(result)} 个k-mer")
except Exception as e:
print(f" 失败: {e}")
continue
return batch_results
def process_all_files_in_batches(batch_size=5):
"""分批处理所有文件"""
Q1_dir = "/data1/project/omics_final/Q1"
kmer_files = glob.glob(f"{Q1_dir}/*.txt")
print(f"总共找到 {len(kmer_files)} 个文件")
print(f"将分 {len(kmer_files)//batch_size + 1} 批处理,每批 {batch_size} 个文件")
all_results = {}
# 分批处理
for i in range(0, len(kmer_files), batch_size):
batch = kmer_files[i:i+batch_size]
batch_num = i//batch_size + 1
batch_results = process_kmer_batch(batch, batch_num)
all_results.update(batch_results)
# 每批处理完后保存结果
results_file = f"{Q1_dir}/kmer_results_batch_{batch_num}.pkl"
with open(results_file, 'wb') as f:
pickle.dump(batch_results, f)
print(f" 批次结果已保存: {results_file}")
# 强制垃圾回收
gc.collect()
print(f" 当前总结果数: {len(all_results)}")
# 保存最终合并结果
final_results_file = f"{Q1_dir}/kmer_results_final.pkl"
with open(final_results_file, 'wb') as f:
pickle.dump(all_results, f)
print(f"\n处理完成!最终结果已保存: {final_results_file}")
return all_results
# 执行分批处理
kmer_results = process_all_files_in_batches(batch_size=3)法4:访问已保存的结果
这个其实就是最原始的想法,全都放在后台,只保留全部运行之后的结果变量,执行过程当然是用到什么变量就得保存什么变量,还是保存为pkl格式。
当然,实际运行的时候,其实发现真的很耗费计算资源的任务,你放在cell中内核会崩溃,其实放在后台则是会被kill,其实都是同样有极大可能性失败的;
bash
# 在任何时候都可以加载已保存的结果
import pickle
import os
def load_saved_results():
"""加载已保存的结果"""
Q1_dir = "/data1/project/omics_final/Q1"
# 尝试加载最终结果
final_file = f"{Q1_dir}/kmer_results_final.pkl"
if os.path.exists(final_file):
with open(final_file, 'rb') as f:
results = pickle.load(f)
print(f"加载最终结果: {len(results)} 个文件")
return results
# 如果没有最终结果,尝试加载中间结果
intermediate_file = f"{Q1_dir}/kmer_results.pkl"
if os.path.exists(intermediate_file):
with open(intermediate_file, 'rb') as f:
results = pickle.load(f)
print(f"加载中间结果: {len(results)} 个文件")
return results
print("没有找到已保存的结果")
return {}
# 加载结果
kmer_results = load_saved_results()
# 查看结果概况
if kmer_results:
print(f"加载了 {len(kmer_results)} 个文件的结果")
print("文件列表:")
for name in sorted(kmer_results.keys()):
print(f" {name}: {len(kmer_results[name])} 个k-mer")所以,如果仅仅只是简单的文本文件处理,只要不涉及到非常复杂的数据处理,pandas能够简单应付的任务,还是直接用awk算了(也就是shell中批量处理得了)