前言
最近加入了一个新团队,完成了一个较简单的项目,没有部署经验,为了后续团队的可持续发展,研究了一套交付部署的流程,以及支持这套流程的基础设施方案,这是这篇文章的由来。
笔者没有 ci/cd 的经验,不理解这算不算持续交付、部署,可能有点文不对题。
基础设施配置
为了项目的可持续性发展,需要部署基础设施,这是围绕 Docker 容器化技术和 Docker 管理工具 Portaienr 实施的。
如果你希望跟文章一起实操,最好有一台 2 核 2 GB 的服务器。
Docker
根据 Docker 文档 在不同平台安装 Docker CE(Docker 社区版),如果使用 Mac、Windows,也可以通过 Docker Desktop 安装管理 Docker。
为了后续的横向扩展,我们开启 Docker 的 Swarm 模式。
Docker Swarm 是 Docker 的原生集群管理工具。 它的主要作用是将多个 Docker 主机集成到一个虚拟的 Docker 主机中,为 Docker 容器提供集群和调度功能。 通过 Docker Swarm,您可以轻松地管理多个 Docker 主机,并能在这些主机上调度容器的部署。
简单来说就是允许多服务器主机部署,由 manager 节点进行管理,这通过命令实现:
sh
docker swarm init这会将当前主机作为 manager 节点初始化集群服务。为了加入这个集群,我们可以用以下命令获取 token:
sh
docker swarm join-token worker
# or
docker swarm join-token manager参数 worker、manager 表示获取的 token 类型,manager 是管理节点,worker 是工作节点;对于中小型公司来说,有一个管理节点提供集中化管理足够了。
它会输出如下形式的命令,复制粘贴到另一个包含 Dokcer 的服务器主机中即可加入当前集群:
sh
docker swarm join --token xxxxxxx ip:2377ip 应该是 manager 节点的公网 ip,2377 是 Docker swarm 模式的默认侦听端口,需要在防火墙中开放。
Portainer
基础设施高度依赖 Portainer CE,初期需要部署并完善它。
Portainer 社区版是一个轻量级的容器化应用服务交付平台,可用于管理 Docker、Swarm、Kubernetes 和 ACI 环境。它旨在简化部署和使用。该应用程序允许您通过 "智能" GUI 或丰富的 API 管理所有编排器资源(Contaienrs、Images、Volumes、Networks 等)。
我们通过 Portainer 最佳实践安装指南 的部分实践来部署它。
-
Portaienr 通过 Server 和 Agent 两个组件运行,主要用于主节点上的主要 Portainer 服务和其他节点进行通讯;他们使用 9001 端口进行通讯,所以我们需要开放集群上所有节点的 9001 端口。
-
运行命令部署 Portaienr
shcurl -L https://downloads.portainer.io/ce-lts/portainer-agent-stack.yml -o portainer-agent-stack.ymlshdocker stack deploy -c portainer-agent-stack.yml portainer -
在 5 分钟内访问
https://ip:9443,并设置初始管理员账号
然后我们就可以使用 Portaienr 的非商业功能了。
Docker registry 私有化部署
为了实现持续交付部署,需要私有化部署 Docker 注册表,以实现项目服务的版本管理、快速回退、自动部署等功能。
Registry 是一个无状态、高度可扩展的服务器端应用程序,用于存储并允许您分发容器镜像及其他内容。
通过 部署 Registry 服务器 开始部署:
-
最简单的方式:
shdocker run -d -p 5000:5000 --restart=always --name registry registry:3 -
使用 Portaienr 面板以服务的形式部署它:
-
基本配置
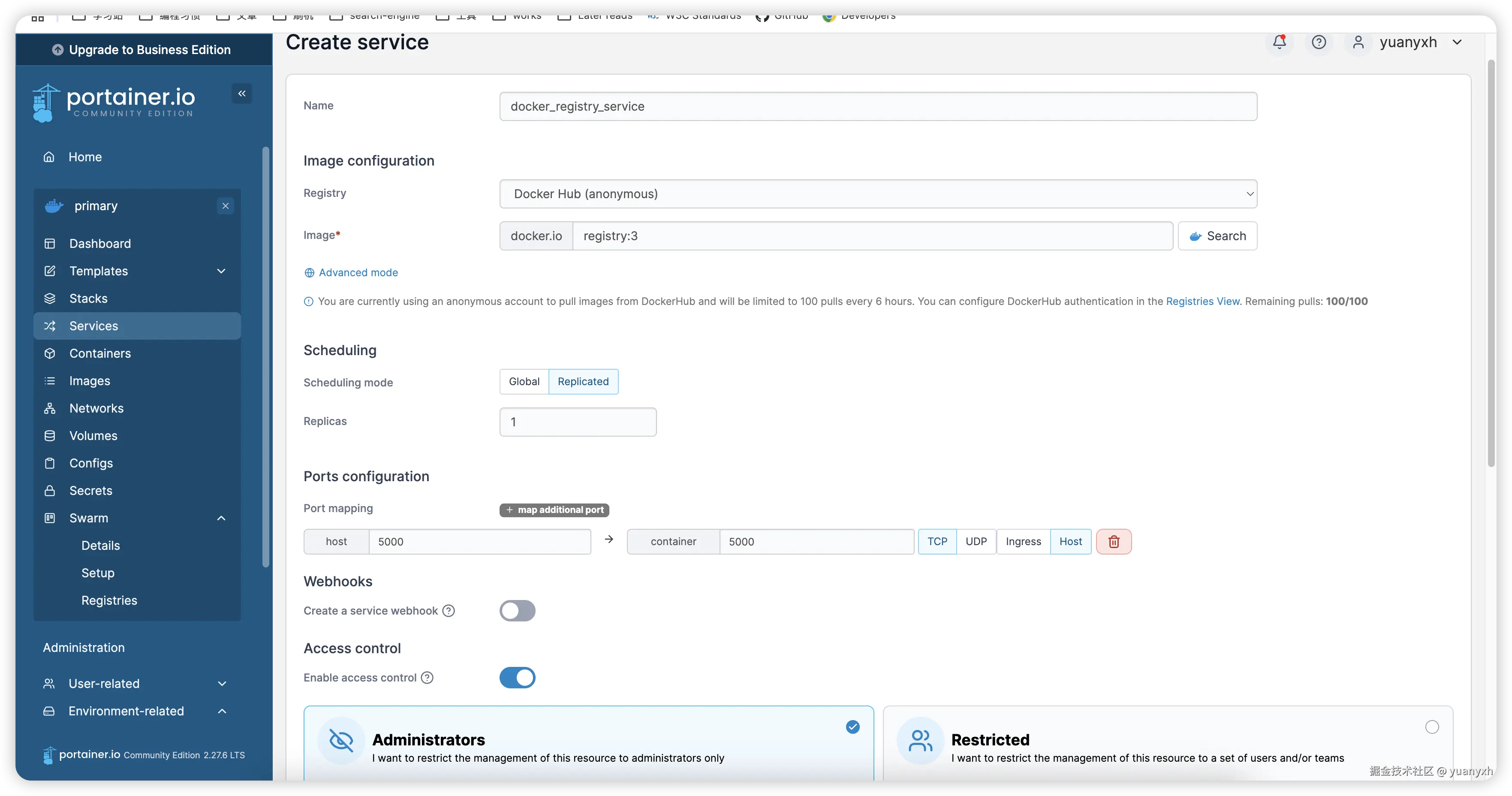
-
挂载主机目录,实现持久化

-
配置异常策略,这里我们设置任意情况都需要重启,以保证服务可用,同时设置最大重试次数为 0(不限制)

-
配置资源限制与部署策略,这里我们不限制其使用资源,然后只在 manager 节点上部署此服务

-
部署服务后我们可以运行 netstat -tuln | grep 5000 命令查看 5000 端口是否有服务正在侦听。
由于 Docker 只信任包含有效 ssl 证书的域名,这里我们部署的 Docker registry 是 http 的,默认无法拉取、推送镜像,所以我们需要在需要拉取、推送镜像的主机上(通常是你的电脑和部署了 Portainer 的服务器)修改配置,以允许不安全的域:
json
{
"insecure-registries" : [
"ip:port"
]
}Docker registry 应该以 https 运行,且必须提供有效的身份验证措施,否则别人可以随意拉取、推送镜像。
这样可以使用他:
sh
docker pull image:tag
docker tag image:tag ip:port/image:tag
docker push ip:port/image:tag
docker pull ip:port/image:tag然后我们可以在 Portaienr 面板中配置自定义镜像:

在同一个服务器内可以使用内网 ip。
WUD 镜像更新与通知
为了自动更新镜像(仅测试镜像 )、获取镜像更新(测试与生产镜像)并以指定方式获取通知,我们需要部署 WUD。
WUD 不需要依靠容器的 latest tag 来检查镜像更新,可以使用语义化的 tag(eg: v1.0、v1.1),WUD 会自动获取到最新的 tag,并通过触发器触发容器更新或发送通知。
我们通过它的 文档 配置,使用 Portaienr 来部署它:
-
基本配置(WUD 容器默认端口应该是 3000)

-
持久化、部署策略与 Docker registry 类似(需要挂载主机的
/var/run/docker.sock到/var/run/docker.sock以获取 Docker 运行环境信息) -
我们配置 WUD 专用的环境变量,以控制其内部行为:

解释一下:
WUD_REGISTRY_CUSTOM_YJZT_URL=http://ip:port配置 Docker registry 私有部署地址WUD_WATCHER_YJZT_CRON=*/5 * * * *每 5 分钟观察一次WUD_TRIGGER_DOCKER_YJZT_PRUNE=true这是一个触发器配置,触发器类型为 docker,名字为 yjzt,这个触发器的作用是发现镜像更新时自动更新容器WUD_WATCHER_YJZT_WATCHBYDEFAULT=false禁用观察全部容器,我们不观察所有容器,只观察我们需要的,所以关闭观察全部的选项
现在,我们需要给指定容器添加 Labels 以观察它:

上图表示 WUD 需要观察这个容器,且每次发现更新时,只触发 docker.yjzt 这个触发器;还有一个相反的用于排除触发器的选项 wud.trigger.exclude。
通过这些配置,我们可以只观察想要的,并对部分容器应用自动更新触发器,部分容器应用更新通知触发器。
监控
Portainer 未提供任何告警系统,可通过接入 Prometheus & Grafana 监控系统实现。
因为需要部署多个服务,我们使用 Portianer 提供的 stacks 功能,编写 docker-compose.yml 来部署它:

下面是 docker-compose.yml 配置与注释:
yml
# Docker Compose 配置文件版本(V3 支持大多数现代 Docker 功能)
version: '3.8'
# 卷定义:用于持久化存储数据,避免容器重启后数据丢失
volumes:
prometheus-data: # 存储 Prometheus 的监控数据(如时间序列数据库)
driver: local # 使用宿主机本地存储,默认路径:/var/lib/docker/volumes/prometheus-data/_data
grafana-data: # 存储 Grafana 的仪表盘配置和用户数据
driver: local # 宿主机本地存储,默认路径:/var/lib/docker/volumes/grafana-data/_data
x-global-policy: &global_policy # 定义锚点
mode: global # 每个节点运行一个实例
restart_policy:
condition: any # 除非手动停止,否则自动重启
max_attempts: 6 # 最多重启 6 次
delay: 10s # 重启延迟 10 秒
networks:
portainer_agent_network:
external: true # 引用已存在的 Overlay 网络
# 服务定义:每个服务对应一个容器
services:
prometheus:
image: prom/prometheus:latest # 使用 Prometheus 官方镜像(生产环境建议锁定版本,如 v2.50.0)
container_name: prometheus # 自定义容器名,便于管理
networks:
- portainer_agent_network
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
ports:
- "5002:9090" # 将容器内 9090 端口映射到宿主机,用于访问 Prometheus Web UI(http://宿主机 IP:5002)
volumes:
- /etc/prometheus:/etc/prometheus # 挂载宿主机配置文件目录:容器启动前需创建 /etc/prometheus/prometheus.yml
- prometheus-data:/prometheus # 持久化存储卷:用于保存监控数据
restart: unless-stopped # 容器异常退出时自动重启(除非手动停止)
command:
- "--config.file=/etc/prometheus/prometheus.yml" # 指定配置文件路径:需提前在宿主机准备此文件
grafana:
image: grafana/grafana:latest # Grafana 官方镜像(建议锁定版本,如 v10.4.0)
container_name: grafana
networks:
- portainer_agent_network
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
ports:
- "5003:3000" # 映射端口,用于访问 Grafana 可视化界面(默认账号 admin/admin)
volumes:
- grafana-data:/var/lib/grafana # 持久化存储卷:保存仪表盘、用户设置等
restart: unless-stopped
# 隐含依赖:Grafana 需配置 Prometheus 数据源(访问 http://宿主机 IP:5003 > Configuration > Data Sources)
node_exporter:
image: quay.io/prometheus/node-exporter:latest # 监控宿主机指标的代理(注意:Quay 服务当前为只读模式,但拉取操作仍可成功 )
container_name: node_exporter
networks:
- portainer_agent_network
deploy: *global_policy # 通过锚点复用配置
command:
- '--path.rootfs=/host' # 指定根文件系统路径,用于采集宿主机资源数据
pid: host # 共享宿主机的 PID 命名空间,便于监控进程
volumes:
- '/:/host:ro,rslave' # 只读挂载宿主机根目录:安全隔离,避免误修改系统文件
cadvisor:
image: google/cadvisor:latest # 容器资源监控工具(由 Google 维护)
container_name: cadvisor
networks:
- portainer_agent_network
deploy: *global_policy # 通过锚点复用配置
#ports: # 默认注释端口映射(避免冲突),需用时取消注释
# - "5004:8080" # 映射后可访问 cAdvisor Web UI(http://宿主机 IP:5004)
volumes:
- /:/rootfs:ro # 只读挂载根目录
- /var/run:/var/run:ro # 挂载进程运行目录
- /sys:/sys:ro # 挂载系统信息
- /var/lib/docker:/var/lib/docker:ro # 挂载 Docker 数据目录
- /dev/disk/:/dev/disk:ro # 挂载磁盘信息
devices:
- /dev/kmsg # 暴露内核日志设备,用于监控内核事件Prometheus 配置 /etc/prometheus/prometheus.yml:
yml
# ===== 全局配置(对所有监控任务生效)=====
global:
# 抓取指标的默认间隔(每15秒从目标收集一次数据)
scrape_interval: 15s
# ▼ 外部标签配置(取消注释后生效)▼
# 当与外部系统交互时(如 federation、远程存储、Alertmanager),
# 这些标签会附加到所有时间序列和告警上,用于区分监控系统来源
# external_labels:
# monitor: 'codelab-monitor' # 示例标签:标识此监控系统为"codelab-monitor"
# ===== 监控目标抓取配置 =====
scrape_configs:
# ---------------------------------------------------------------------
# 监控任务1:Prometheus 自身监控
# ---------------------------------------------------------------------
- job_name: 'prometheus' # 任务名称(会作为标签 'job="prometheus"' 添加到数据中)
# 覆盖全局抓取间隔,此任务每 5 秒采集一次(更频繁监控核心组件)
scrape_interval: 5s
# 静态配置目标列表(无需服务发现)
static_configs:
- targets: ['localhost:5002'] # 监控本机 Prometheus 服务(端口 5002)
# ---------------------------------------------------------------------
# 监控任务2:主机资源监控(需配合 Node Exporter 使用)
# ---------------------------------------------------------------------
- job_name: 'node_exporter' # 任务名称:监控服务器硬件资源
# 使用静态配置(假设 Node Exporter 部署在主机名为 "node_exporter" 的容器上)
static_configs:
- targets: ['node_exporter:9100'] # Node Exporter 默认端口 9100
# ---------------------------------------------------------------------
# 监控任务3:容器资源监控(需配合 cAdvisor 使用)
# ---------------------------------------------------------------------
- job_name: 'cadvisor' # 任务名称:监控容器 CPU/内存/磁盘等资源
# 静态配置目标(假设 cAdvisor 部署在主机名为 "cadvisor" 的容器上)
static_configs:
- targets: ['cadvisor:5004'] # cAdvisor 默认端口 5004部分监控服务组件需要运行在集群内的所有节点上,以实现全局监控。
为此,我们需要保证这些监控服务组件不会影响或最小化影响应用服务,保证应用服务优先;从配置中可以看出,我们限制了全局监控服务组件的重启重试次数、能够使用的资源(最小必要原则)。
对于资源限制的额度,要额外小心,笔者测试时,限制使用资源后服务器通常会发生崩溃,最好在相同配置的测试服务器上调教好后再同步至生产服务器。
我们现在可以登录 Grafana 面板,设置数据源:

设置为 Prometheus:

这里需要配置公网 ip,然后进行测试保存,也可以进行更多配置:

然后导入面板:

我们导入 cadvisor(容器监控)的面板,id 为 14282(node_exporter(主机资源监控)为 1860):

现在可以查看各容器实例的资源占用情况:

可以在 Grafana 面板中设置告警规则与通知方式。
推荐阅读:
监控服务较复杂,需要日积月累的使用以积攒经验,笔者也未深入,所以这里只讲解基础的部署。
项目流程
这是规划的基本项目流程。
准备阶段
-
确认需求,项目周期
-
确认分配资源(硬件资源、开发人员)
-
登记需求至 DevOps 平台
确认项目 tag,同项目统一使用。
flowchart TD A[主需求 - Web 后台项目] -- 子需求 --> B[子需求 - UI 设计] A -- 子需求 --> C[子需求 - Web 开发] A -- 子需求 --> D[子需求 - API 开发] B -- 子任务 --> E[首页图...] C -- 子任务 --> F[首页...] D -- 子任务 --> G[首页仪表盘数据...] -
leader 创建 Portainer 群组,并添加相关开发人员,创建 test container、prod service 并指定群组权限:
tag description test-tag-(frontend)-container 前端测试容器(测试项目应该始终以容器模式运行) prod-tag-(frontend)-service 前端生产服务 -
开发人员评估任务时长
开发阶段
- 构建初始项目(前端、后端)
- 持续编写项目文档
- 配置环境变量区分开发、测试、生产环境
- 编写
Dockerfile,根据环境构建镜像 - 开发
- 本地测试
测试阶段
-
开发人员
- 代码合并到 test 分支,推送到 DevOps 平台
- 触发测试分支的 Webhook
- 扫描代码质量
- 代码构建
- 根据环境变量构建测试镜像
- 推送到私有部署的 Docker 注册表平台
- 镜像自动更新与通知
- 修改任务项为待测试、开发完成
-
测试人员
flowchart TD A[确认待测试项] -- 测试 --> B[提 Bug] A -- 测试 --> C[新需求] B -- 开发 --> D[修复 Bug] C -- 确认需求 --> E[登记需求] D --> F[提测] F --> A E -- 开发 --> F测试完成后修改任务为测试完成状态
-
运维人员
- 代码合并到 master 分支(或指定生产分支),推送到 DevOps 平台
- 触发生产分支的 Webhook
- 扫描代码质量
- 代码构建
- 根据环境变量构建生产镜像
- 推送到私有部署的 Docker 注册表平台
- 镜像通知至钉钉、企微或邮箱
- 登录 Portainer 面板或 WUD 面板,手动触发镜像更新,确保服务启动成功
- 确认项目运行正常
- 任务完结
维护阶段
- Portainer service
- 设置运行的目标节点、任务数量
- 资源的限制
- 重启策略
- 监控
- Grafana 设置告警规则,通知方式
- 定时查看面板数据
- 周期性导出报表,分析资源占用情况
- 异常处理
- 回退到正常镜像
- 排查异常
实践
我们走一遍基本流程,排除掉多数人工参与的阶段,跑通自动化设施部分。
新建一个目录,创建三个文件:
index.html:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>Welcome to here!</h1>
<p>
I am a frontend developer.
My blog in here: <a href="https://yuanyxh.com">yuanyxh & blog</a>
</p>
</body>
</html>default.conf:
yaml
events {}
http {
server {
listen 80; # 声明侦听的端口
location / { # 路径
root /webapp; # 根路径
index index.html; # 首页
}
}
}Dockerfile:
yaml
FROM nginx:1.27.5-alpine # 使用 nginx 镜像,开始一个构建流程
COPY . /webapp # copy 当前目录的所有文件到容器内的 /webapp
COPY default.conf /etc/nginx/nginx.conf # copy nginx 配置文件到容器内的 nginx 配置目录
EXPOSE 80 # 声明暴露的端口运行 Docker 编译命令
sh
docker build --platform linux/amd -t blog:v1.0 .--platform linux/amd指定镜像架构-t blog:v1.0是声明镜像的名称,v1.0 是这个镜像的 tag,.表示当前工作目录。
这会编译一个 blog:v1.0 amd64 架构的镜像出来,通过命令查看:
sh
docker images
# REPOSITORY TAG IMAGE ID CREATED SIZE
# blog v1.0 xxxxxxxxxx 8 minutes ago 75.9MB
# ...推送到 Docker registry 私服:
sh
docker tag blog:v1.0 ip:port/blog:v1.0
docker push ip:prot/blog:v1.0我们将它作为测试服务,创建一个容器来部署这个服务:
基本配置(容器端口应该是 80):

添加 Labels 指示 WUD 观察镜像更新与自动升级:

现在可以访问 ip + 端口查看效果:

我们继续测试自动更新效果,修改 index.html 文件内容:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>欢迎来到这里!</h1>
<p>我是一名非资深前端开发人员,这是我的博客: <a href="https://yuanyxh.com">yuanyxh & blog</a></p>
</body>
</html>构建推送:
sh
docker build --platform linux/amd64 -t blog:v1.1 .
docker tag blog:v1.1 8.209.206.255:5000/blog:v1.1
docker push 8.209.206.255:5000/blog:v1.1静待一段时间,我们查看 Portaienr 面板,或查看 WUD 的 Web UI,会发现发现了容器已更新为最新镜像,查看网页内容也已变更:

我们可以免去手动编译镜像并推送更新的步骤,可以通过 git hook、webhook 等功能自动构建、测试,并推送更新。
测试通过!现在我们需要部署到正式环境,我们创建一个 Service:

注意我们添加的 Labels,触发器包含了 smtp.yjzt,这是用于 SMTP 邮件服务器通知的,为此我们需要添加 WUD 的环境变量配置:

首先配置 SMTP 邮箱为 QQ 邮箱的 HOST 和 PORT,接着指定发送人,这里接收人与发送人相同,然后需要指定账号密码(自行获取 QQ 邮箱授权码)。
部署后再次更新镜像并推送,我们会收到 QQ 邮箱的通知(如果没有,可能需要配置 WUD_TRIGGER_SMTP_YJZT_TLS_ENABLED=true)。

这时候,运维就需要登录 Portaienr 面板去手动更新生产环境下的服务了。
尾声
笔者没有实际 ci/cd 经验,完全靠自己的直觉、找到的文章经验进行研究,可能有很多不通的地方,欢迎讨论。
研究基于实践进行,一开始是想靠一台阿里轻量进行实操,但实践下来抗不住,于是进行了升级,另外为了集群部署,购买了另一台云服务器(想要实操注意服务器配置不能太低)。
文章的缺憾在于:
- 没有深入研究多节点下的监控系统,多节点下的监控服务笔者尝试了一天,依然是不可用状态,因此像是自动告警这类功能文章没有提及
- 没有完成各个被暴露出去的 Web UI、API 服务的验证
- 没有实现基于 DevOps 平台实现自动化测试、构建功能
--end