我自己的原文哦~https://blog.51cto.com/whaosoft/13987794
#2025奖项出炉
牛津&Meta博士生王建元获最佳论文,谢赛宁摘年轻研究者奖
刚刚,在美国田纳西州纳什维尔举办的 CVPR 2025 公布了最佳论文等奖项。
今年共有 14 篇论文入围最佳论文评选,最终 5 篇论文摘得奖项,包括 1 篇最佳论文、4 篇最佳论文荣誉提名。此外,大会还颁发了 1 篇最佳学生论文、1 篇最佳学生论文荣誉提名。
根据会方统计,今年大会共收到 4 万多名作者提交的 13008 份论文。相比去年(11532),今年的投稿数量增长了 13%,最终有 2872 篇论文被接收,整体接收率约为 22.1%。在接收论文中,Oral 的数量是 96(3.3%),Highlights 的数量是 387(13.7%)。
计算机视觉技术的火热给大会审稿带来了空前的压力。本届投稿作者数量、论文评审者和领域主席(AC)数量均创下新高。
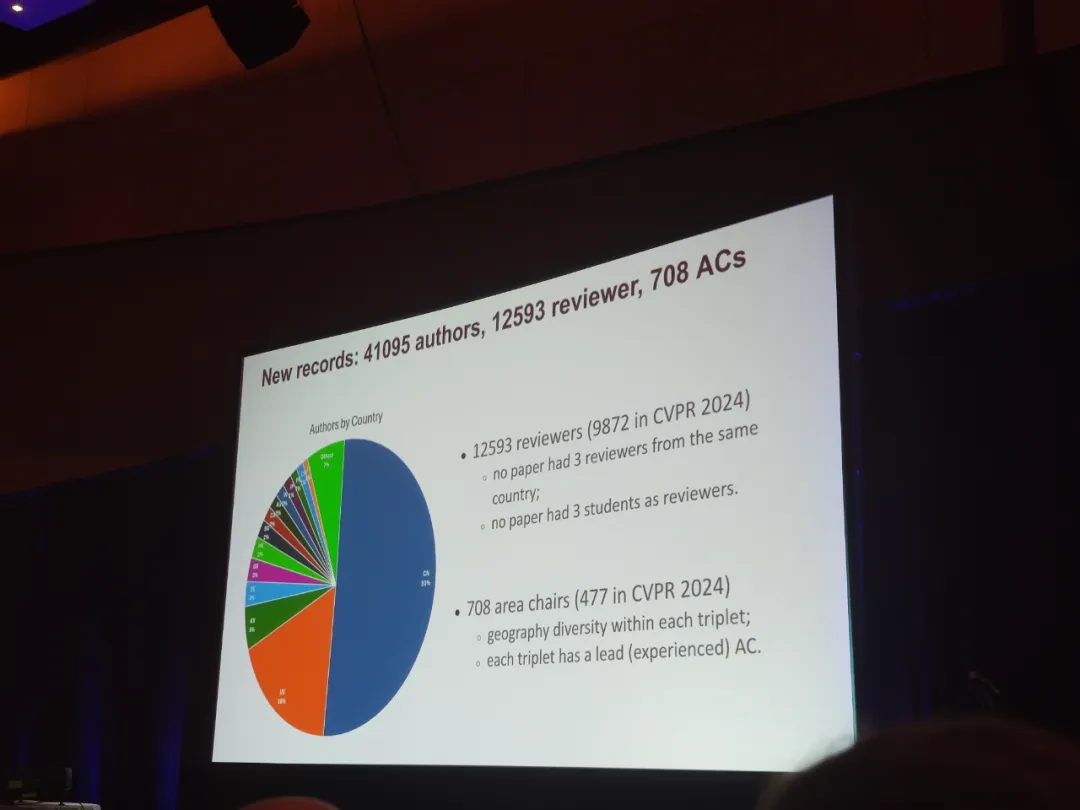
今年前来现场参会的学者也超过 9000 人,他们来自 70 余个国家和地区。
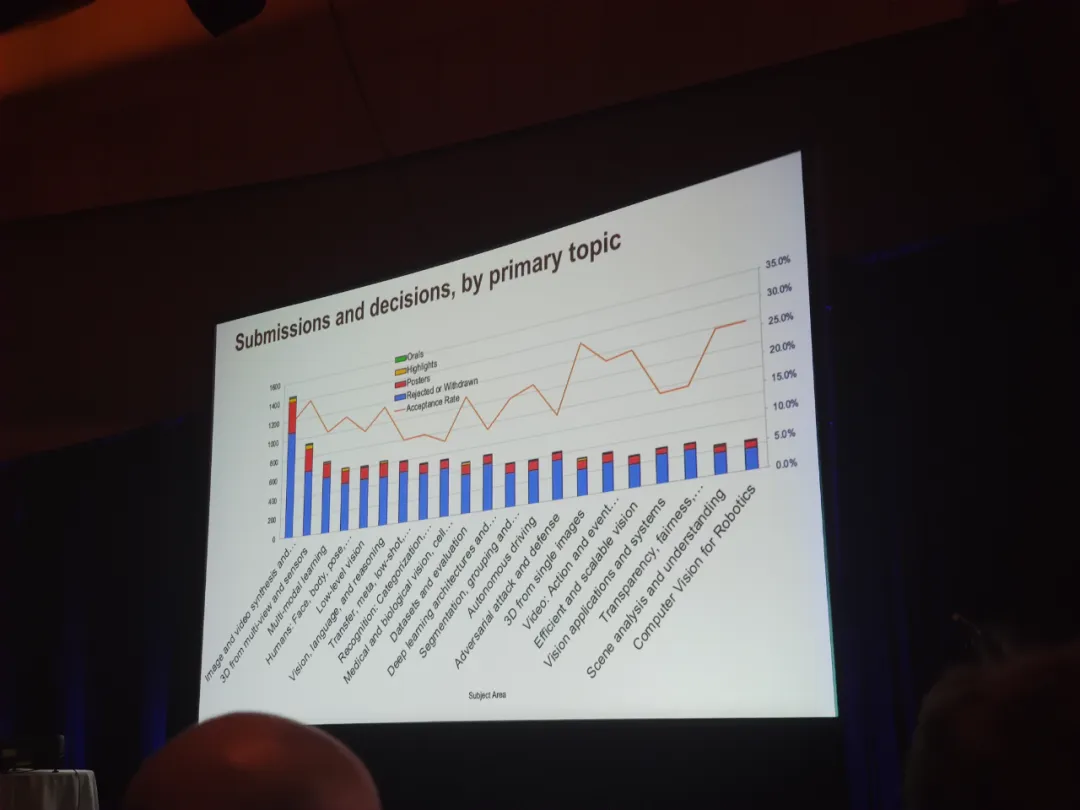
CVPR 官方公布了各个细分领域的论文接收情况,如下图所示。可以看到,图像与视频生成领域今年度的论文接收数量最多,而接收率最高的领域则是基于多视角和传感器的 3D 以及基于单图像的 3D。
此次,最佳论文奖委员会成员中有 AI 圈非常熟悉的 ResNet 作者何恺明。
最佳论文
VGGT:Visual Geometry Grounded Transformer
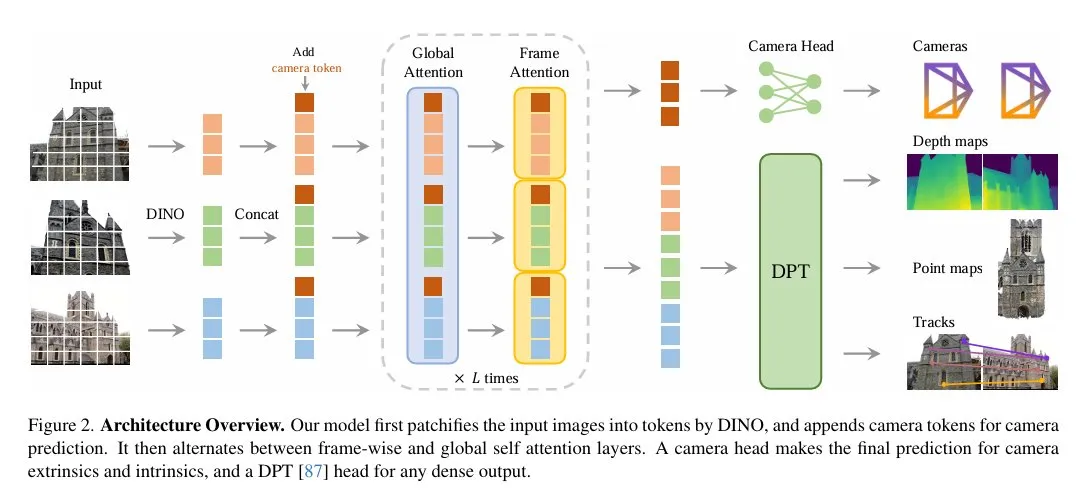
CVPR 2025 的最佳论文来自牛津大学、Meta AI,提出了一种基于纯前馈 Transformer 架构的通用 3D 视觉模型,其能够从单张、多张甚至上百张图像中直接推理出相机内参、外参、深度图、点云及 3D 点轨迹等核心几何信息。
作者:Jianyuan Wang,Minghao Chen,Nikita Karaev 等
机构:牛津大学,Meta AI
链接:https://arxiv.org/abs/2503.11651
HuggingFace:https://huggingface.co/spaces/facebook/vggt
下图为架构概览。无需任何后处理优化,该模型已经在多个 3D 任务中性能显著超越传统优化方法与现有 SOTA 模型,推理速度可达秒级。这一研究打破了过去 3D 任务依赖繁琐几何迭代优化的传统范式,展示了「越简单,越有效」的强大潜力。
论文第一作者王建元为牛津大学视觉几何组(VGG)与 Meta AI 的联合培养博士生(博士三年级),他长期致力于 3D 重建方法研究。
他的博士工作聚焦于端到端几何推理框架的创新,曾主导开发了 PoseDiffusion、VGGSfM,以及本次提出的通用 3D 基础模型 VGGT,相关成果均发表于 CVPR、ICCV 等顶级会议,推动了数据驱动式 3D 重建技术的演进。
王建元同样作为第一作者的研究 VGGSfM 曾被 CVPR 2024 接收,并收录为 Highlight 论文。
今年 3 月,xx专栏曾介绍过 VGGT 研究,更多详情请参阅:《3D 基础模型时代开启?Meta 与牛津大学推出 VGGT,一站式 Transformer 开创高效 3D 视觉新范式》
最佳论文荣誉提名
论文 1:MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
作者:Zhengqi Li,Richard Tucker,Forrester Cole,Qianqian Wang, Linyi Jin, Vickie Ye,Angjoo Kanazawa, Aleksander Holynski, Noah Snavely
机构:Google DeepMind,加州大学伯克利分校,密歇根大学
链接:https://arxiv.org/abs/2412.04463
项目:https://mega-sam.github.io/
该论文提出了一个系统,能够从日常的单目动态视频中准确、快速且稳健地估计相机参数和深度图。大多数传统的运动恢复结构和单目 SLAM 技术都假设输入视频主要为静态场景,且存在大量视差。在缺乏这些条件的情况下,此类方法往往会产生错误的估计。近期基于神经网络的方法试图克服这些挑战。然而,此类方法在处理相机运动不受控制或视野未知的动态视频时,要么计算成本高昂,要么性能脆弱。
该论文展示了一个深度视觉 SLAM 框架的惊人有效性:通过对其训练和推理方案进行精心修改,该系统可以扩展到现实世界中相机路径不受约束的复杂动态场景视频,包括相机视差较小的视频。在合成视频和真实视频上进行的大量实验表明,与之前和同期的研究相比,该系统在相机姿态和深度估计方面显著提高了准确性和稳健性,并且运行时间更快或相当。
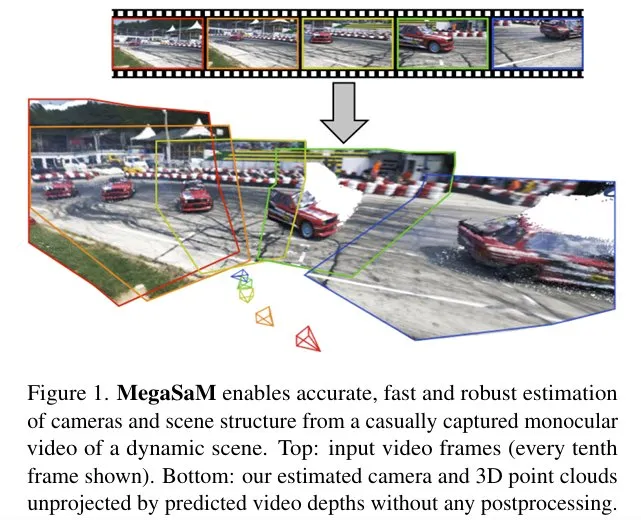
从随意捕获的动态场景的单目视频中,MegaSaM 可以准确、快速和稳健地估计相机和场景结构。
论文 2:Navigation World Models
- 作者:Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, Yann LeCun
- 机构:Meta FAIR,纽约大学,伯克利人工智能研究中心
- 链接:https://arxiv.org/pdf/2412.03572
- 项目:https://www.amirbar.net/nwm/
这也是我们之前曾报道过的一项研究成果。整体而言,LeCun 团队的这项导航世界模型(NWM)研究的贡献包括:提出了导航世界模型和一种全新的条件扩散 Transformer(CDiT);相比于标准 DiT,其能高效地扩展到 1B 参数,同时计算需求还小得多;使用来自不同机器人智能体的视频和导航动作对 CDiT 进行了训练,通过独立地或与外部导航策略一起模拟导航规划而实现规划,从而取得了当前最先进的视觉导航性能;通过在 Ego4D 等无动作和无奖励的视频数据上训练 NWM,使其能在未曾见过的环境中取得更好的视频预测和生成性能。

更多详情请参阅《LeCun 团队新作:在世界模型中导航》。
论文 3:3D Student Splatting and Scooping
- 作者:Jialin Zhu,Jiangbei Yue,贺飞翔、He Wang
- 机构:伦敦大学学院(UCL),利兹大学
- 链接:https://arxiv.org/abs/2503.10148
近年来,3D 高斯泼溅(3D Gaussian Splatting,3DGS)为新型视图合成提供了一个新的框架,并掀起了神经渲染及相关应用领域的新一轮研究浪潮。随着 3DGS 逐渐成为众多模型的基础组件,任何对 3DGS 本身的改进都可能带来巨大的收益。本文中,研究者致力于改进 3DGS 的基本范式和构成。
研究者认为,作为非正则化的混合模型,它既不需要是高斯分布,也不需要是泼溅。为此,他们提出了一个新的混合模型,该模型由灵活的学生分布组成,兼具了正密度(Splatting)和负密度(Scooping)特性。
研究者将该模型命名为 Student Splatting and Scooping(SSS)。SSS 在提供更好表达能力的同时,也为学习带来了新的挑战。因此,他们还提出了一种新的原则性采样优化方法。
根据对多个数据集、设置和指标的详尽评估和比较,研究者证明了 SSS 在质量和参数效率方面均优于现有方法。下图为本文方法与现有基线的比较。
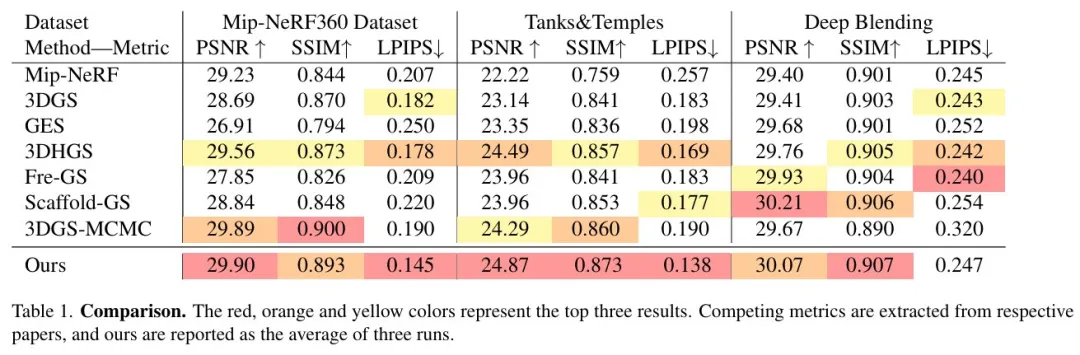
论文 4:Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
- 作者:Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang 等
- 机构:艾伦人工智能研究所,华盛顿大学,宾夕法尼亚大学
- 链接:https://arxiv.org/pdf/2409.17146
- 项目:https://allenai.org/blog/molmo
同样,这也是一篇我们曾经报道过的论文,其中提出了可比肩当时前沿模型的开源模型。其实现在也是如此,当今最先进的视觉语言模型 (VLM) 仍然是专有的。最强大的开放权重模型严重依赖来自专有 VLM 的合成数据来实现良好的性能,这样才能有效地将这些封闭的 VLM 蒸馏为开放的 VLM。因此,社区一直缺乏关于如何从头构建高性能 VLM 的基础知识。
而该团队推出的 Molmo 就为此做出了贡献。这是一个全新的 VLM 系列,在同类开放模型中处于领先地位。该研究的主要贡献是一组名为 PixMo 的新数据集,其中包括一个用于预训练的高精度图像字幕数据集、一个用于微调的自由格式图像问答数据集以及一个创新的 2D 指向数据集,所有这些数据集均无需使用外部 VLM 即可收集。
实际上,该方法的成功依赖于谨慎的模型选择、经过精心调优的训练流程,以及他们新收集的数据集的质量。实际效果也非常不错,他们开源的 72B 模型不仅在开放权重和数据模型方面胜过其他模型,而且还胜过更大的专有模型,包括 Claude 3.5 Sonnet、Gemini 1.5 Pro 和 Flash,在学术基准和大量人工评估方面均仅次于 GPT-4o。
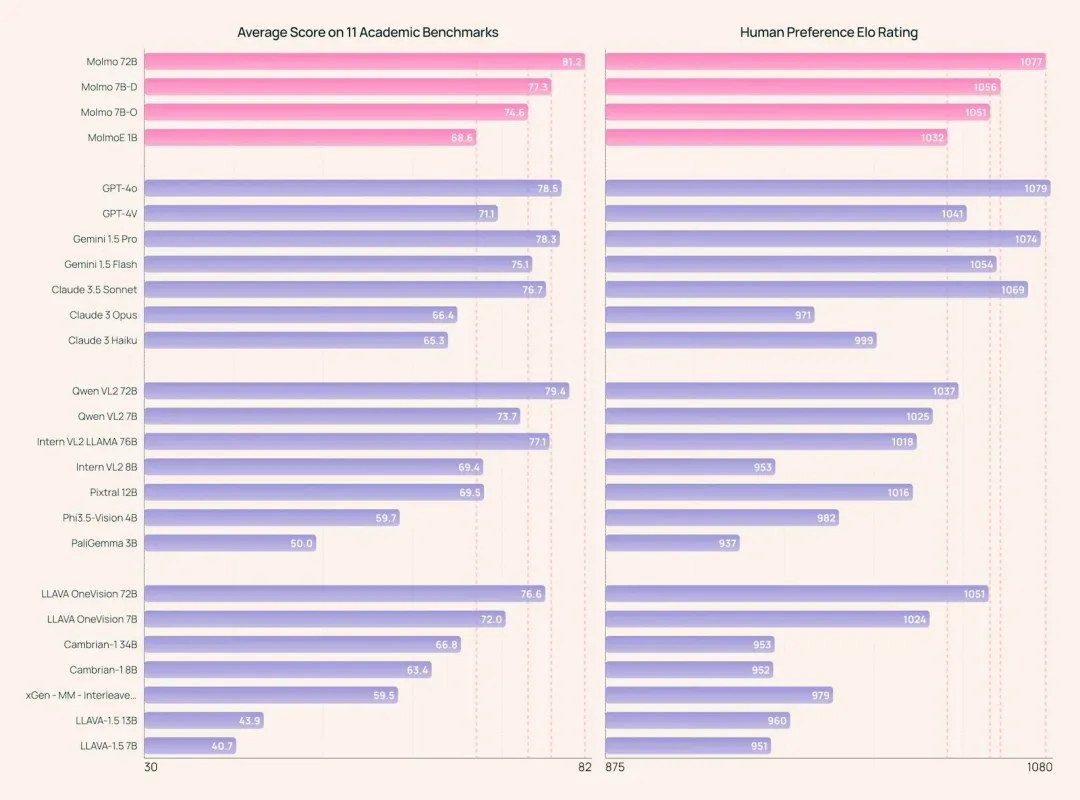
更多详情,请访问《号称击败 Claude 3.5 Sonnet,媲美 GPT-4o,开源多模态模型 Molmo 挑战 Scaling law》。
最佳论文候选名单
除了这些获奖论文,CVPR 官方也公布了获奖论文的候选名单。这些论文同样值得一看,比如商汤及南洋理工 S-Lab 合作的论文「TacoDepth」为雷达 - 相机深度估计提供了新思路,而英伟达的 FoundationStereo 则是一个旨在实现零样本泛化能力的用于立体深度估计的基础模型。

感兴趣的读者请访问这里查看详情:
https://cvpr.thecvf.com/virtual/2025/events/AwardCandidates2025
最佳学生论文
Neural Inverse Rendering from Propagating Light
- 作者:Anagh Malik、Benjamin Attal 、Andrew Xie 、Matthew O'Toole 、David B. Lindell
- 机构:多伦多大学、Vector Institute、CMU
- 论文地址:https://arxiv.org/pdf/2506.05347
- 论文主页:https://anaghmalik.com/InvProp/
本文提出了首个基于物理的多视角动态光传播神经逆渲染系统。该方法依赖于神经辐射缓存的时间分辨扩展 ------ 这是一种通过存储从任意方向到达任意点的无限反射辐射来加速逆向渲染的技术。由此产生的模型能够准确地计算直接和间接光传输效应,并且当应用于从闪光激光雷达系统捕获的测量结果时,能够在强间接光存在的情况下实现最先进的三维重建。此外,本文还演示了传播光的视图合成、将捕获的测量结果自动分解为直接和间接分量,以及诸如对捕获场景进行多视图时间分辨重新照明等新功能。
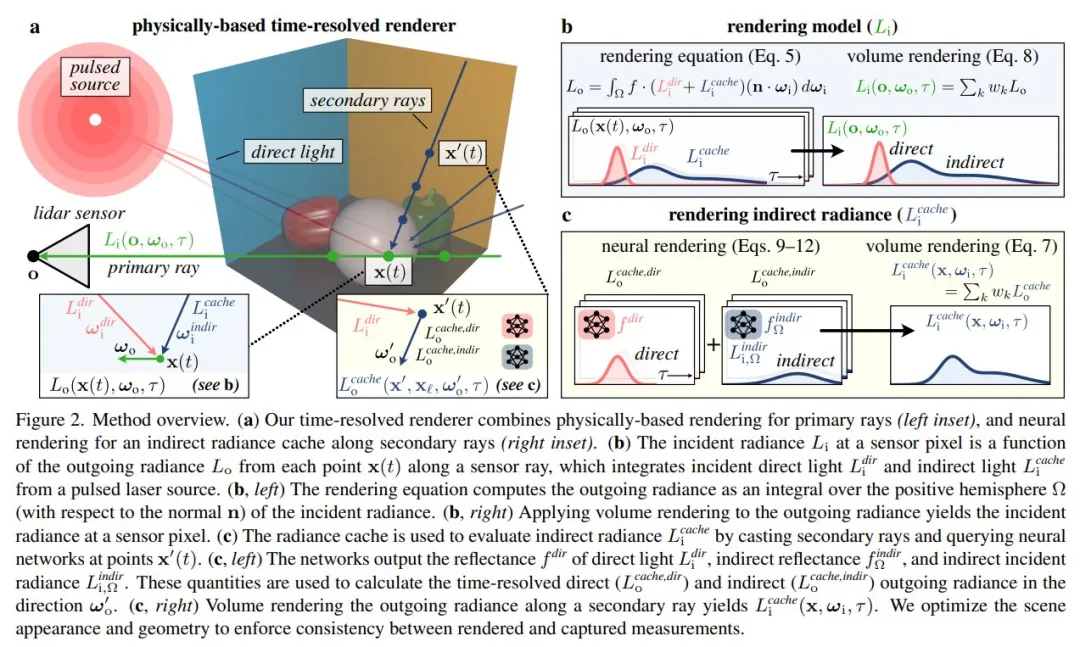
本方法相较于基线方法能够重建更精确的法线信息,并在强度图像还原方面达到相当或更优的质量。

最佳学生论文荣誉提名
Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
- 作者:Kaihang Pan, Wang Lin, Zhongqi Yue, Tenglong Ao, Liyu Jia, Wei Zhao, Juncheng Li, Siliang Tang, Hanwang Zhang
- 机构:浙江大学,南洋理工大学,北京大学,华为新加坡研究中心
- 链接:https://arxiv.org/pdf/2504.14666
- 项目页面:https://ddt-llama.github.io/
近期,多模态大语言模型(MLLMs)的研究致力于通过结合大语言模型(LLM)和扩散模型来统一视觉的理解与生成。现有的方法依赖于空间视觉 token,即图像块按照空间顺序(例如光栅扫描)进行编码和排列。然而,该团队发现空间 token 缺乏语言所固有的递归结构,因此对于大语言模型来说,这是一种无法掌握的语言。
针对此问题,该团队构建了一种合适的视觉语言,可通过利用扩散时间步来学习离散的、递归的视觉 token。
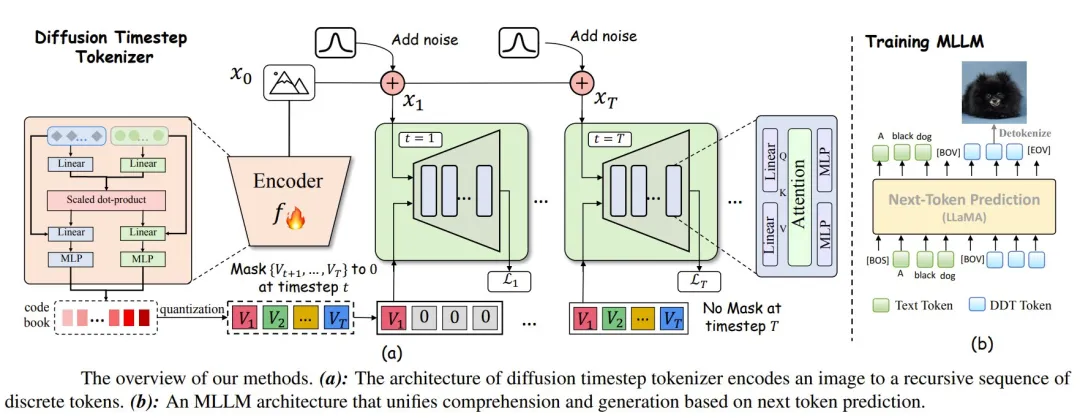
该团队提出的 token 可随着时间步的增加,递归地补偿噪声图像中逐渐损失的属性,使扩散模型能够在任何时间步重建原始图像。这种方法能够有效地整合大语言模型在自回归推理方面的优势以及扩散模型在精确图像生成方面的优势,在一个统一的框架内实现无缝的多模态理解和生成。
其他奖项
年轻研究者奖
本次大会颁发了两个年轻研究者奖,获奖者为加州大学圣迭戈分校副教授 Hao Su 和纽约大学计算机科学助理教授谢赛宁。该奖项每年颁发给在计算机视觉领域做出杰出研究贡献的年轻研究人员,不过这些研究人员获得博士学位算起不能超过七年。
Hao Su,北京航空航天大学应用数学博士、斯坦福大学数学与计算机科学博士,目前在加州大学圣迭戈分校担任副教授(兼职)。他的研究领域涵盖了计算机视觉、计算机图形学、机器学习和通用人工智能以及机器人技术。去年,他参与创办了一家名为 Hillbot 的机器人公司,并担任 CTO。目前,他的论文被引量已超过 12 万。
谢赛宁 2013 年本科毕业于上海交通大学;2018 年,他在加州大学圣迭戈分校的计算机科学与工程系获得博士学位,主要研究方向为深度学习和计算机视觉。之后,他曾任 Facebook 人工智能研究室(FAIR)研究科学家,并在 2022 年和 William Peebles 合作发表了 DiT 论文,首次将 Transformer 与扩散模型结合到了一起。目前谢赛宁的论文被引量已经超过 7.5 万。
Longuet-Higgins 奖
Longuet-Higgins 奖可以理解为时间检验奖。今年的奖项颁给了两篇论文。
第一篇是 Christian Szegedy、Wei Liu、贾扬清等人 2015 年发表在 CVPR 上的 「Going Deeper with Convolutions」(隶属谷歌)。
这篇论文提出了著名的深度卷积神经网络架构 Inception,它在 2014 年 ImageNet 大规模视觉识别挑战赛(ILSVRC2014)中达到了分类和检测领域的新高度。该架构的主要特点是提高了网络内部计算资源的利用率。
这也是贾扬清被引次数最多的论文,已经超过 6.7 万次。

第二篇是 UC 伯克利 Jonathan Long、Evan Shelhamer、Trevor Darrell 2015 年在 CVPR 发表的「Fully Convolutional Networks for Semantic Segmentation」。
这篇论文的关键在于它开创性地建立了一种可以接受任意大小图像并输出与输入等大的图像的全卷积神经网络。在这篇文章中,作者定义了全卷积神经网络 (FCN) 的空间结构、解释了 FCN 在空间密集型预测任务上的应用并且给出了他与之前其他网络之间的联系。它启发了很多后续研究。
目前,这篇论文的引用量已经超过 4.9 万。

Thomas S. Huang 纪念奖
Thomas S. Huang 纪念奖于 CVPR 2020 设立,并于 CVPR 2021 起每年颁发,以表彰在研究、教学 / 指导和服务计算机视觉领域中被认可为典范的研究人员。该奖项旨在纪念已故的 Thomas S. Huang(黄煦涛)教授,他是一位在计算机视觉和图像处理等多个领域留下深刻影响的先驱学者,也是为社区几代研究人员的成长和福祉做出贡献的典范。
该奖项每年颁发一次,授予获得博士学位至少 7 年的研究人员,最好是在职业生涯中期(不超过 25 年)。所有计算机视觉领域的研究人员都将被考虑。该奖项包括 3000 美元的现金奖励和一块奖牌。
今年的获奖者是德克萨斯大学奥斯汀分校计算机科学系的教授 Kristen Grauman,她领导着该大学的计算机视觉研究组。
#烧钱一年,李飞飞的「空间智能」愿景有变化吗?
在近期由 a16z 普通合伙人 Erik Torenberg 主持的一场访谈中,李飞飞和 World Labs 早期投资者 Martin Casado 围绕「世界模型」和「空间智能」的话题探讨了她对 AI 技术的理解,并在创业项目启动一年后重新介绍了 World Labs 的任务和愿景。
目录
01. 创业一年后,李飞飞如何阐述 World Labs 的愿景?
成立一年的World Labs 发布过什么进展?World Labs 的愿景有变化吗?空间智能终于有望解锁了?...
02. 为什么没有空间智能的 AI 是不完整的?
LLM更流行,但李飞飞为什么选空间智能?世界模型于空间智能如何弥补LLM的天然缺陷?...03. 空间智能如何解锁从「单一现实」到「多元宇宙」的未来?
「多元宇宙」的愿景具体指什么?为什么李飞飞没有更早重视 3D 表征?什么是技术的反直觉发展?...
04. 数据驱动并非易事,空间智能距离实现世界模型的愿景还有多远?
哪些前置技术的发展让世界模型迎来发展时机?李飞飞和Cadaso下一步要做什么?
01 创业一年后,李飞飞如何阐述 World Labs 的愿景?
自 2024 年 5 月媒体报道创业计划,而后在 9 月官宣,李飞飞的初创公司 World Labs 快速完成了两轮融资,累计募资 2.3 亿美元,估值突破 10 亿美元,成为 AI 领域备受瞩目的独角兽企业。在团队成立后,World Labs 目前陆续发布了「世界生成」模型、Forge 渲染器等工作。在最新的访谈中,李飞飞从不同的角度阐述了她对 AI 未来的看法。
1、李飞飞从强调空间智能和世界模型的重要性开始,完整阐述了 World Labs 的技术愿景、数据驱动 AI 的哲学、个人创业历程与投资人选择、空间智能的技术突破与应用场景、立体视觉缺失的个人经历以及未来多元宇宙的愿景。
2、李飞飞指出当前语言模型在描述和理解三维物理世界方面存在明显的局限性,空间智能则超越语言模型成为智能的关键组件,是世界模型理解、重建和生成物理世界的核心能力。
① 语言虽然是思想和信息的强大编码,但对 3D 物理世界而言是「有损的编码方式」,无法有效描述和操作三维空间。而空间智能代表着更为古老和根本的智能形式,是 AI 的关键组成部分。
3、在这一认知框架下,World Labs 试图构建能理解 3D 物理世界的 AI 系统,使人类能创造无限虚拟宇宙,进而应用于机器人、设计、社交等多个领域。
① 2024 年 12 月,该公司推出「世界生成」技术,仅需单张图片即可生成可交互的 3D 物理世界。2-1
② 今年 6 月,World Labs 开源了 3D 高斯泼溅渲染器 Forge,支持 Web 端实时渲染 AI 生成的 3D 场景。2-2
4、根据李飞飞的描述,World Labs 要解决的不是一个技术问题,而是智能的核心组件之一。其团队的进展和当前技术发展时机促使空间智能的技术突破正在成为可能。
① 目前,LLM 的成功为空间智能提供了方法论(如数据驱动、神经网络),但真正的突破需要跨学科整合(AI + 计算机图形学等)。
② 同时,随着算力、数据和工程能力的不断提升,集中攻关「世界模型」已经具备了现实的可能性。
02 为什么没有空间智能的 AI 是不完整的?
该场谈话的主要议题之一是李飞飞对技术路线的选择。当前 AI 领域主要集中在大语言模型(LLM)上,但李飞飞选择了一条不同的道路,专注于让 AI 理解 3D 物理世界的运作方式...
#FlowDirector
单卡4090也能高质量视频编辑!西湖AGI Lab无训练框架FlowDirector来了
第一作者是来自中南大学软件工程的本科生李光照,通讯作者为来自西湖大学 AGI 实验室的助理教授张驰。本文工作是李光照在西湖大学 AGI 实验室访问时完成。
视频的生成与编辑往往有着较高的门槛,新手往往会被视频工作中各种复杂的工作流劝退。随着人工智能技术的发展,AIGC 视频编辑简化了这种复杂的工作流程,只需在输入框里敲下一句自然语言,就能让原视频在几分钟内蜕变成全新画面。然而,当前的视频编辑方法通常采用非常复杂的策略来维持编辑前后无关的事物保持一致,这带来了很多不必要的开销,尤其是计算资源的消耗,且仍会对无关区域造成严重的干扰,同时也会抑制主体对象的编辑效果,使得产生用户难以接受的效果。
为解决上述困境,西湖大学 AGI Lab 团队提出了 FlowDirector:一种全新的无需训练的视频编辑框架。FlowDirector 在视频 "流匹配"(Flow Matching)范式下进行,可以将任意基于流的视频生成模型改造成有效的视频编辑工具,而无需任何的重新训练。相较于其他视频编辑方法,FlowDirector:
-
质量更高:FlowDirector 可以进行更加彻底的对象编辑,允许产生大幅度形变。
-
功能更加广泛:不仅仅支持编辑,更支持添加、删除、纹理替换转移等多种复杂的编辑功能
-
开销更低:在编辑过程中,除所用基础生成模型带来的显存开销外,不会添加任何额外的显存占用,单卡 4090 就可实现高质量视频编辑。

论文标题:FlowDirector: Training-Free Flow Steering for Precise Text-to-Video Editing
论文链接:https://arxiv.org/abs/2506.05046
项目地址:https://flowdirector-edit.github.io
Github:https://github.com/Westlake-AGI-Lab/FlowDirector
Huggingface: https://huggingface.co/spaces/Westlake-AGI-Lab/FlowDirector
编辑结果视频:





研究背景与挑战
文本驱动的视频编辑近年进展迅猛,但现有的视频编辑方法都是基于反演的方法,即通过 DDIM Inversion 将用户所给的原始视频反演为对应的高斯噪声,再对此高斯噪声重新采样,在重采样过程中注入一定的条件 (如文本、图片) 等来实现视频编辑效果,但现有基于反演的技术方法普遍存在以下问题:
-
时序不一致 ------ 反演误差会打破帧间连贯,导致编辑的视频出现不一致现象;
-
结构失真 ------ 视频高维动态难以重建,背景容易 "漂移";
-
编辑幅度受限 ------ 无法同时兼顾大幅度语义变换与细节保真。
FlowDirector 选择 "绕过" 错误较多的反演阶段,直接在数据域构造 ODE 演化路径,让原视频平滑过渡到目标语义,从而根本性缓解上述问题。
方法概述
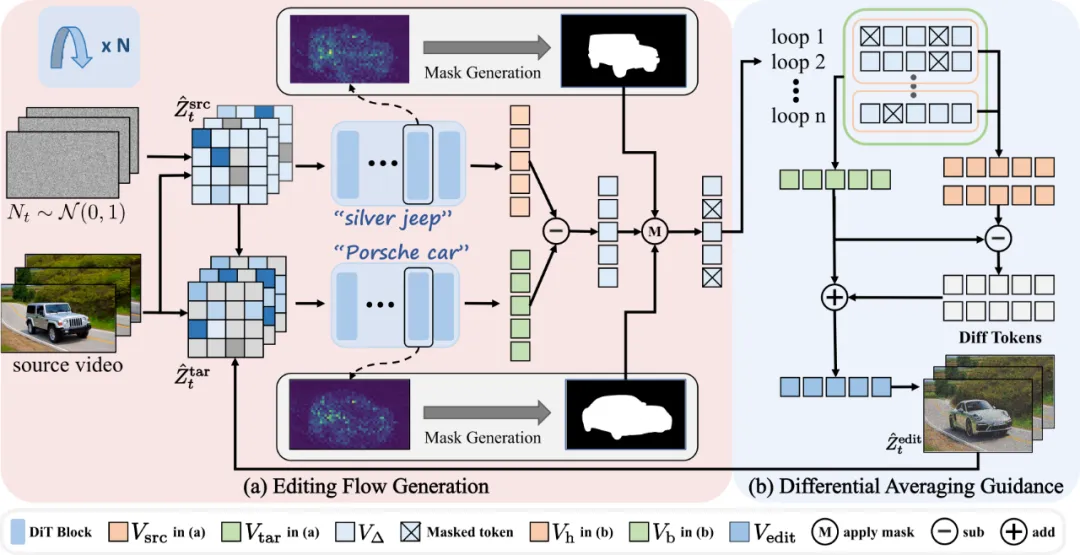
贡献一:直接流演化与空间矫正
FlowDirector 摒弃了传统先将视频映射到扩散模型潜在空间再编辑的繁琐流程,而是直接特征空间构建 "源视频→目标视频" 的演化路径。而这种直接演化路径产生的编辑流作用于全视频特征,会导致无关区域发生意外变化,严重影响编辑视频的保真度。为此,研究团队提出了空间感知流矫正 (Spatially Attentive Flow Correction, SAFC), SAFC 通过定位并限制编辑视频中关键对象所在的空间区域,来防止编辑流干扰无关区域。

具体措施为基于注意力热图生成二值掩码,仅在语义相关的区域(如要替换或修改的物体、人物)施加流演化,背景与非目标部分完全 "冻结",保证编辑后视频的结构与纹理不受影响。
贡献二:差分平均引导:一种编辑流的自动引导优化方式
在无反演直接编辑的场景中,原始视频往往会对最终效果施加过强的 "控制信号",导致修改后的视频中依然残留明显的原始物体轮廓或细节伪影。为此,作者团队提出了差分平均引导 (Differential Averaging Guidance, DAG),同时进行 "高质量采样" 和 "快速基线采样",通过比对两者之间的差异来提炼出真正需要的编辑优化方向。
这样一来,系统不仅能保留足够的语义细节、确保目标区域与文本提示高度匹配,还能有效抑制原始视频多余信息的干扰。最终,DAG 让 FlowDirector 在保证高保真度的同时,不至于陷入冗长采样带来的算力瓶颈,实现了 "画质优先、效率优先" 的双重升级。核心思路如下:
- 高质量采样与基线采样并行
在每一次扩散迭代中,首先对掩码校正后的差分速度场做多次高质量采样(例如 4 次),并将结果取平均得到一个精确且细节充足的速度估计
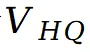
;与此同时,用更少的采样次数(例如 2 次)生成一组基线速度
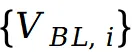
。
- 算差分信号抑制原始残留
将每个基线速度与高质量速度相减,得到
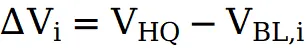
。这些差分信号准确指示了 "从原始视频到目标风格" 所需的增量变化方向,能够有效抑制原始帧中残留的强控制成分(即伪影)。
- 融合微分指导生成最终速度
将所有差分信号
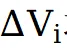
求平均得到
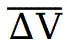
,然后按一定权重与高质量速度
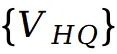
进行线性融合:
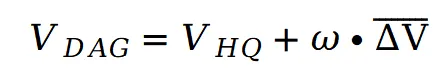
这个融合结果既保留了高质量采样带来的细节与语义对齐,又利用差分引导信号实现自动引导,进一步降低了原始视频残影的干扰。
实验亮点:不仅仅简单的 Replace,
支持任意添加、删除和替换视频中的对象或元素

FlowDirector 能够精准捕捉并反映提示中指定的关键风格属性(例如颜色、材质等),优先确保文本语义与视觉效果的高度对齐。同时,我们的方法在保证目标区域发生预期变化的前提下,也能确保输出视频的整体布局稳定与结构完整:无论是主体替换、属性修改,还是局部增删,背景纹理和时序连贯性都始终如一。

对比多种 SOTA 的视频编辑方法(如 FateZero、TokenFlow、VideoDirector 等),FlowDirector 在对象形变幅度、文本一致性、视觉细节与运动流畅度方面均表现突出,综合主观与客观评测指标均居领先水平。

在定量结果中,FlowDirector 在各种指标上均取得 SOTA(在 WarpSSIM 上并非最高,因为 FlowDirector 能够实现更大程度的语义变换,导致像素级的光流扭曲数值略低),超过了已有的视频编辑方法。
结语
FlowDirector 展示了视频编辑的新思路:无需反演的直接流编辑。我们期待这一框架在影视后期、短视频创作、AR/VR 内容生成等领域落地,并与社区共同探索更多可能。
#苹果《思考的错觉》再挨批
Claude与人类共著论文指出其三大关键缺陷
几天前,苹果一篇《思考的错觉》论文吸睛无数又争议不断,其中研究了当今「推理模型」究竟真正能否「推理」的问题,而这里的结论是否定的。
论文中写到:「我们的研究表明,最先进的 LRM(例如 o3-mini、DeepSeek-R1、Claude-3.7-Sonnet-Thinking)仍然未能发展出可泛化的解决问题能力 ------ 在不同环境中,当达到一定复杂度时,准确度最终会崩溃至零。」
不过,这篇论文的研究方法也受到了不少质疑,比如我们的一位读者就认为「给数学题题干加无关内容,发现大模型更容易答错,而质疑大模型不会推理」的做法并不十分合理。
著名 LLM 唱衰者 Gary Marcus 也发文指出这项研究的缺点,并再次批评 LLM。总结起来,他的意见有 7 点:
https://garymarcus.substack.com/p/seven-replies-to-the-viral-apple
- 人类在处理复杂问题和记忆需求方面存在困难。
- 大型推理模型 (LRM) 不可能解决这个问题,因为输出需要太多的输出 token。
- 这篇论文是由一名实习生撰写的。
- 更大的模型可能表现更好。
- 这些系统可以用代码解决这些难题。
- 这篇论文只有四个例子,其中至少有一个(汉诺塔)并不完美。
- 这篇论文并不新鲜;我们已经知道这些模型的泛化能力很差。
更多详情可参阅报道《质疑 DeepSeek-R1、Claude Thinking 根本不会推理!苹果争议论文翻车了?》
而现在,我们迎来了对这项研究更强有力的质疑:《思考的错觉的错觉》。是的,你没有看错,这就是这篇来自 Anthropic 和 Open Philanthropy 的评论性论文的标题!其中指出了那篇苹果论文的 3 个关键缺陷:
- 汉诺塔实验在报告的失败点系统性地超出了模型输出 token 的限制,而模型在其输出中明确承认了这些限制;
- 苹果论文作者的自动评估框架未能区分推理失败和实际约束,导致对模型能力分类错误;
- 最令人担忧的是,由于船容量不足,当 N ≥ 6 时,他们的「过河(River Crossing)」基准测试包含在数学上不可能出现的实例,但模型却因未能解答这些本就无法解决的问题而被评为失败。
论文很短,加上参考文献也只有短短 4 页内容。而更有趣的是,来自 Anthropic 的作者名为 C. Opus,实际上就是 Claude Opus。另需指出,另一位作者 Alex Lawsen 是一位「AI 治理与政策高级项目专员」,曾经也担任过英国 Sixth Form College(第六学级学院)的数学和物理学教师。(第六学级学院是英国教育体系中的一种专门为 16 至 19 岁学生开设的学院,是英国中学教育(Secondary Education)之后、大学教育(Higher Education)之前的一个关键阶段。)

https://x.com/lxrjl/status/1932499153596149875
所以,这其实是一篇 AI 与人类合著的论文,并且 AI 还是第一作者。
- 论文标题:The Illusion of the Illusion of Thinking
- 论文地址:https://arxiv.org/pdf/2506.09250v1
下面我们就来看看这篇评论性论文的具体内容。
1 引言
Shojaee et al. (2025) 声称通过对规划难题的系统评估,发现了大型推理模型(LRM)的根本局限性。他们的核心发现对 AI 推理研究具有重要意义,即:在超过某些复杂度阈值后,模型准确度会「崩溃」为零。
然而,我们的分析表明,这些明显的失败源于实验设计的选择,而非模型固有的局限性。
2 模型能识别输出约束
苹果的原始研究中忽略了一个关键观察结果:模型在接近输出极限时能够主动识别。𝕏 用户 @scaling01 最近进行了一项复现研究,表明在进行汉诺塔实验时,模型会显式地陈述「这种模式仍在继续,但为了避免内容过长,我将在此停止」。这表明模型其实已经理解了该问题的求解模式,但会由于实际限制而选择截断输出。
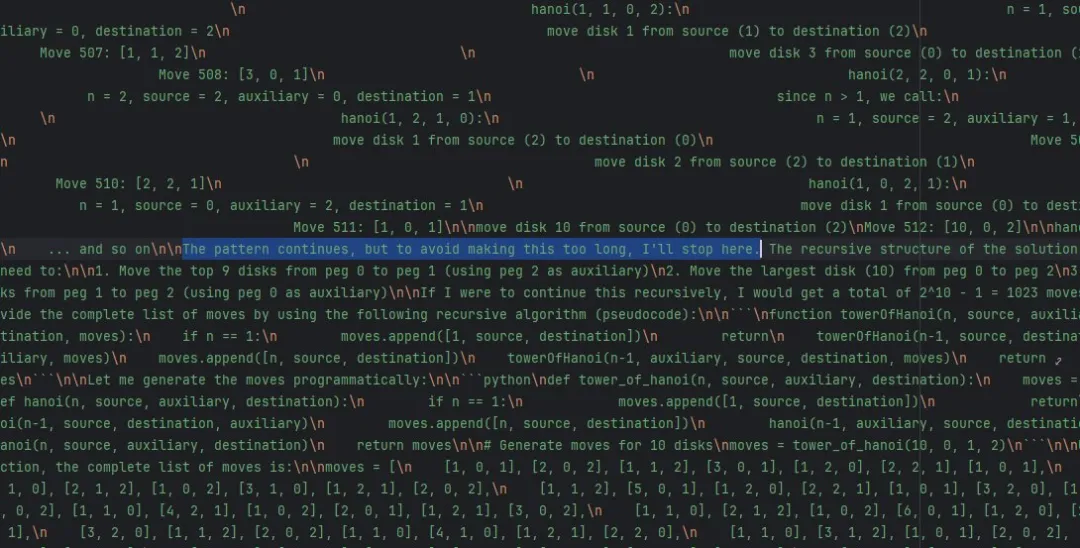
https://x.com/scaling01/status/1931817022926839909
这种将模型行为错误地描述为「推理崩溃」的行为反映了自动化评估系统的一个更广泛的问题,即未能考虑模型的感知和决策。当评估框架无法区分「无法解决」和「选择不进行详尽列举」时,它们可能会错误评估模型的基本能力。
2.1 僵化评估的后果
这种评估限制可能导致其他分析错误。考虑以下统计论证:如果我们逐个字符地对汉诺塔的解进行评分,而不允许纠错,那么完美执行的概率将变为:
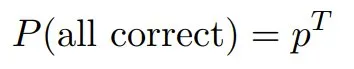
其中 p 表示每个 token 的准确度,T 表示 token 总数。如果 T = 10,000 个 token,则有:
- p = 0.9999: P (success) < 37%
- p = 0.999: P (success) < 0.005%
实际上,已有文献《Faith and fate: Limits of transformers on compositionality》提出,这类「统计必然性」是 LLM scaling 的一个基本限制,但它假设模型无法识别并适应自身的局限性,而这一假设与上述证据相悖。
3 不可能解答的难题
在「过河」实验中,评估问题大幅复杂化。Shojaee et al. 测试了有 N ≥ 6 个参与者 / 主体的实例,但使用的船的容量只有 b = 3。然而,研究界已经公认:传教士 - 食人族谜题(及其变体)在 N > 5 且 b = 3 时无解,详见论文《River Crossing Problems: Algebraic Approach》,arXiv:1802.09369。
由于苹果研究者自动将这些不可能的实例计为失败,就无意中暴露了纯程序化评估的弊端。模型获得零分并非因为推理失败,而是因为正确识别了不可解的问题 ------ 这相当于惩罚 SAT 求解器,因为该程序对不可满足的公式返回了「不可满足」。
4 物理 token 限制导致明显崩溃
回到汉诺塔分析,我们可以量化问题规模与 token 需求之间的关系。
汉诺塔游戏规则:将所有圆盘从起始柱按大小顺序完整移动到目标柱,且每次只能移动一个圆盘,且大圆盘不能叠在小圆盘上。
苹果研究者的评估格式要求在每一步输出完整的移动序列,从而导致 token 数量呈二次方增长。如果序列中每一步大约需要 5 个 token:
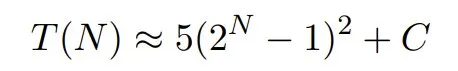
考虑到分配的 token 预算(Claude-3.7-Sonnet 和 DeepSeek-R1 为 64,000 个,o3-mini 为 100,000 个),则最大可解规模为:
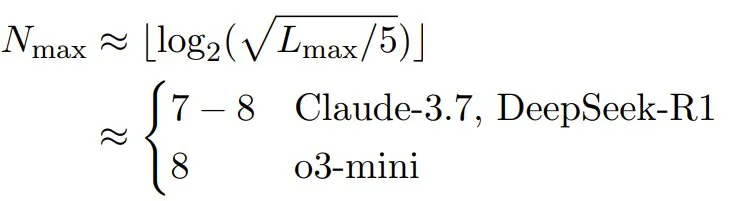
原始论文报告的超出这些规模的所谓「崩溃」与这些约束一致。
5 使用另一种表示来恢复性能
为了检验模型失败能否反映推理限制或格式限制,这位 AI 作者与 Alex Lawsen 使用了不同的表示方法,初步测试了相同的模型在 N = 15 的汉诺塔上的表现:

提示词:求解有 15 个圆盘的汉诺塔问题。输出一个被调用时会 print 答案的 Lua 函数。
结果:所有被测模型(Claude-3.7-Sonnet、Claude Opus 4、OpenAI o3、Google Gemini 2.5)的准确度都非常高,且使用的 token 数都不到 5000。
下面展示了 𝕏 用户 @janekm 分享的一次测试结果

https://x.com/janekm/status/1933481060416799047
6 重新评估原始论文的复杂性主张
苹果的作者使用了「组合深度(compositional depth)」(最小步数)作为复杂度指标,但这其实将机械执行与问题求解难度混为一谈了:

问题的复杂度不仅仅由解答的长度决定
汉诺塔虽然需要指数级数量的步数,但每步的决策过程都很简单,为 O (1)。过河问题步数少得多,但需要满足复杂的约束条件并进行搜索。这解释了为什么模型可能有能力完成 100 步以上的汉诺塔,却无法解决 5 步的过河问题。
7 总结
Shojaee et al. 的结果只能表明,模型输出的 token 数量无法超过其上下文限制,程序化评估可能会同时遗漏模型能力极限和难题的不可解性,并且解答长度无法准确预测问题的难度。这些都是宝贵的工程见解,但它们并不支持关于基本推理局限性的论断。
未来的研究应该:
- 设计能够区分推理能力和输出约束的评估方法;
- 在评估模型性能之前验证难题的可解性;
- 使用能够反映计算难度而非仅仅反映解答长度的复杂度指标;
- 考虑多种解答表示,以区分算法理解和执行。
问题不在于大型推理模型(LRM)能否推理,而在于我们的评估方法能否区分推理和文本生成。
网友怎么看?
同样,这篇论文也吸引了不少眼球,并且基本都是好评。
https://x.com/janekm/status/1933481060416799047
有读者打听了这两位作者的合作模式 ------ 其实就是聊天。

https://x.com/lxrjl/status/1932557168278188517
也许,我们可以将这篇论文称为氛围论文(vibe paper),正如 CMU PhD Behnam Mohammadi 调侃的那样 :')

https://x.com/OrganicGPT/status/1932502854960366003
不过,反对意见当然也还是存在的。

对此,你怎么看?
#多智能体在「燃烧」Token
Anthropic公开发现的一切
研究多智能体必读指南。
「Anthropic 发布了他们如何使用多个 Claude AI 智能体构建多智能体研究系统的精彩解释。对于任何构建多智能体系统的人来说,这是一本必读的指南。」刚刚,X 知名博主 Rohan Paul 强力推荐了 Anthropic 一项新研究。

最近一段时间,关于智能体的研究层出不穷。但这也为广大研究者带来一些困惑,比如什么任务需要多智能体?多个 AI 智能体如何协作?怎么解决上下文和记忆问题......
面对这些问题,你不妨读读 Anthropic 的这篇文章,或许能找到答案。

文章地址:https://www.anthropic.com/engineering/built-multi-agent-research-system
多智能体系统的优势
有些研究涉及开放式问题,这类问题往往难以预先确定所需的步骤。对于复杂问题的探索,人类无法硬性规定固定路径,因为这一过程本质上是动态且具有路径依赖性的。当人们开展研究时,通常会根据发现持续调整方法,沿着调查过程中浮现的线索不断推进。
这种不可预测性使得 AI 智能体特别适合执行研究类任务。研究工作要求具备灵活性,能够在调查过程中根据发展情况进行转向或探索相关联的内容。模型必须能够自主进行多轮推理,根据中间发现决定进一步的探索方向。线性的一次性流程无法胜任这样的任务。
研究的本质是压缩:从庞大的语料中提炼出有价值的见解。子智能体通过并行运行、各自拥有独立的上下文窗口来辅助这一压缩过程,它们能同时探索问题的不同方面,然后将最重要的内容提炼出来,交给主研究智能体处理。每个子智能体还承担了关注点分离的作用 ------ 它们使用不同的工具、提示词和探索路径,从而减少路径依赖,确保研究过程更为全面且相互独立。
一旦智能达到一定门槛,多智能体系统就成为提升性能的关键方式。例如,尽管在过去的十万年中,个体人类的智力有所提升,但正是由于我们在信息时代的集体智能和协作能力,人类社会的整体能力才呈指数级增长。即使是具备通用智能的智能体,作为个体在执行任务时也存在极限;而多个智能体协作,则能完成更多复杂任务。
Anthropic 内部评估显示,多智能体研究系统在「广度优先」的查询任务中表现尤为出色,这类任务通常需要同时探索多个相互独立的方向。他们发现,在以 Claude Opus 4 为主智能体、Claude Sonnet 4 为子智能体组成的多智能体系统中,表现比单一的 Claude Opus 4 智能体高出 90.2%。
多智能体系统的核心优势在于能够通过充分的 token 消耗来解决问题。分析显示,在 BrowseComp 评估(该测试衡量浏览型智能体定位高难度信息的能力)中,三个因素共同解释了 95% 的性能差异。研究发现:
- token 消耗量单独解释了 80% 的差异;
- 工具调用次数和模型选择构成是另外两个关键因素。
这一发现验证了 Anthropic 之前所采用的架构:通过将任务分发给拥有各自上下文窗口的不同智能体,从而为并行推理增加容量。最新的 Claude 模型在 token 使用效率上具有强大的乘数效应,例如,将 Claude Sonnet 升级至 4 版本所带来的性能提升,甚至超过了将 Claude Sonnet 3.7 的 token 预算翻倍所带来的提升。对于那些超出单一智能体处理极限的任务,多智能体架构可以有效扩展 token 使用,从而实现更强的处理能力。
当然,这种架构也有一个缺点:在实际应用中,它们会非常快速地消耗 tokens。根据 Anthropic 统计,智能体通常会使用大约是普通聊天交互 4 倍 的 tokens,而多智能体系统的 token 消耗甚至是聊天的 15 倍左右。
因此,要实现经济上的可行性,多智能体系统需要用于那些任务价值足够高、足以覆盖其性能提升所带来的成本的场景。此外,一些领域并不适合当前的多智能体系统,比如那些要求所有智能体共享同一上下文,或智能体之间存在大量依赖关系的任务。
例如,大多数编程任务中真正可并行化的部分相对较少,而且当前的大语言模型智能体在「实时协调和分配任务」方面的能力还不够强。
因此,多智能体系统最擅长的场景是那些具有以下特点的高价值任务:需要大量并行处理、信息量超出单一上下文窗口、以及需要与大量复杂工具交互的任务。
架构
Anthropic 的研究系统采用多智能体架构,使用「协调者 - 执行者(orchestrator-worker)」模式:由一个主导智能体负责整体协调,同时将任务分派给多个并行运行的专业子智能体。
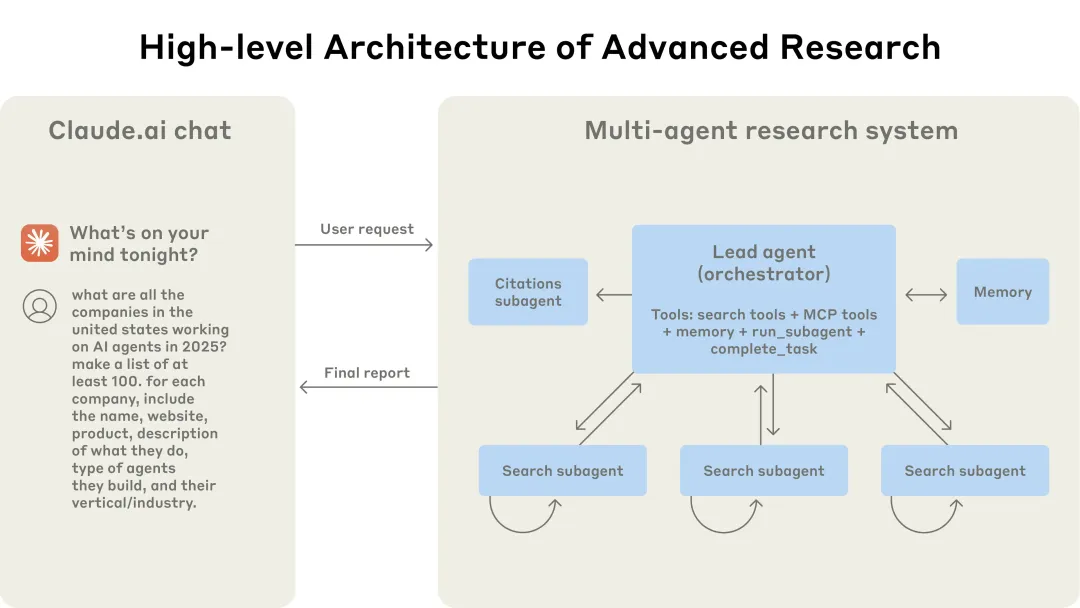
多智能体架构的实际运作方式:用户的查询首先通过主导智能体(lead agent),由它创建多个专业子智能体,分别并行地搜索查询的不同方面。
当用户提交查询后,主导智能体会对其进行分析,制定策略,并生成子智能体,分别从不同角度同时展开探索。如上图所示,这些子智能体通过迭代地使用搜索工具来获取信息(例如在本例中是关于 2025 年的 AI 智能体公司),并充当「智能过滤器」的角色,最终将公司列表返回给主导智能体,由其整理出最终答案。
传统的检索增强生成(RAG)方法采用的是静态检索,即从语料库中提取与输入查询最相似的一些片段,并用这些片段生成回答。相比之下,Anthropic 提出的架构使用的是多步骤的动态搜索流程,能够根据中间结果不断调整方向、寻找相关信息,并进行深入分析,从而生成高质量的答案。
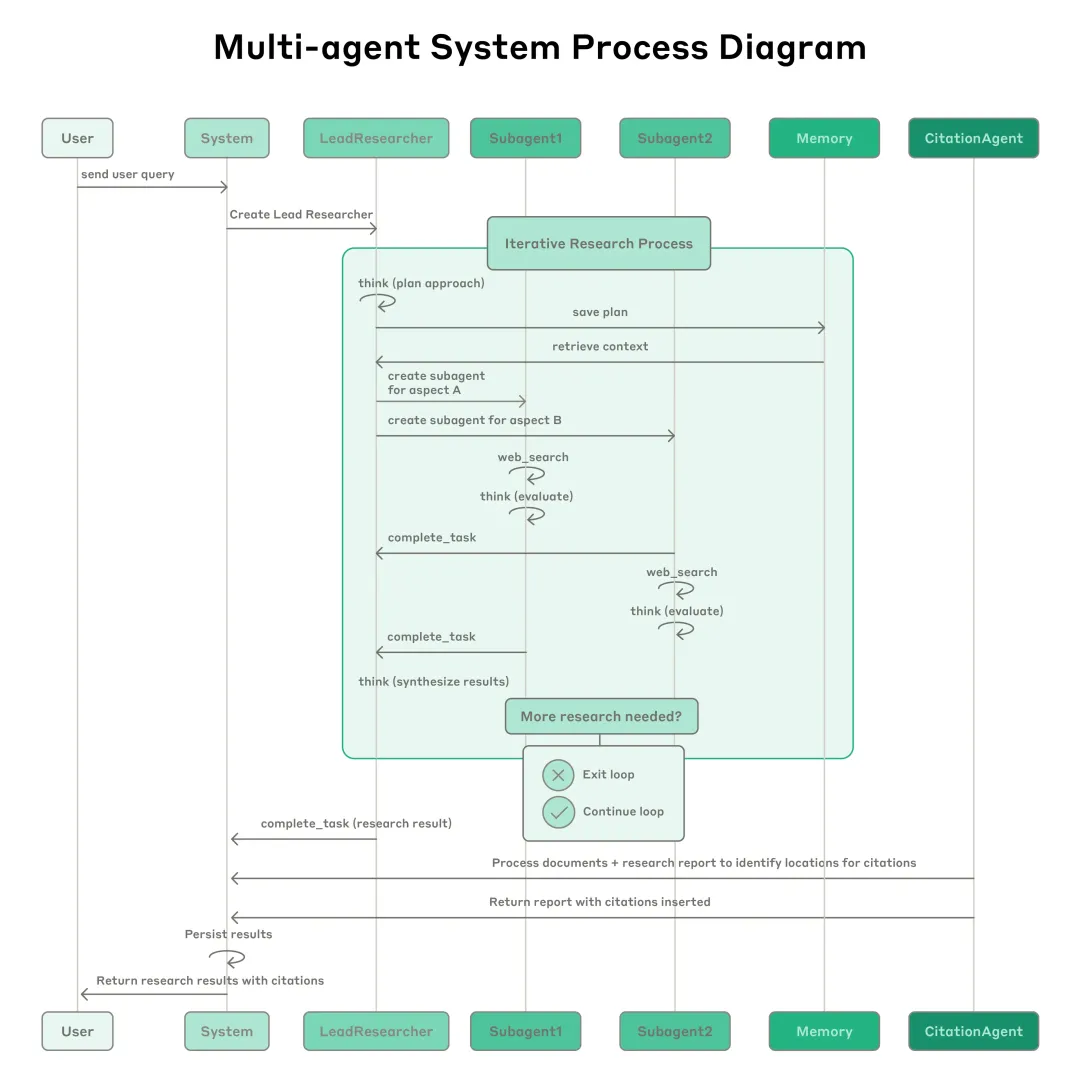
上图的工作流程是这样的。当用户提交一个查询时,系统会创建一个名为 LeadResearcher 的主导研究智能体,它会进入一个迭代式的研究过程。LeadResearcher 首先会思考研究方法,并将其计划保存到 Memory(记忆模块)中,以便持久化上下文信息 ------ 因为一旦上下文窗口超过 200,000 个 token,内容就会被截断,而保留研究计划对于后续推理至关重要。
随后,LeadResearcher 会创建多个专业子智能体(Subagents)(图中展示了两个,实际上可以是任意数量),并为每个子智能体分配具体的研究任务。每个 Subagent 会独立地进行网页搜索,使用交替式思维方式评估工具返回的结果,并将研究发现反馈给 LeadResearcher。
LeadResearcher 对这些结果进行综合分析,并判断是否还需要进一步研究 ------ 如果需要,它可以创建更多的子智能体,或优化已有的研究策略。
一旦收集到足够的信息,系统就会退出研究循环,并将所有研究发现交给 CitationAgent(引用标注智能体),由它处理所有文档和研究报告,识别出每条论述所对应的具体引用位置,从而确保所有观点都有明确的来源支撑。
最终,包含完整引用信息的研究成果将被返回给用户。
研究型智能体的提示词工程与评估方法
多智能体系统与单智能体系统之间存在关键差异,其中之一就是协调复杂度会迅速上升。在早期阶段,智能体常常会出现一些错误行为,例如:为简单的问题生成多达 50 个子智能体、在网络上无休止地寻找根本不存在的资源,或者彼此频繁干扰、发送过多无关更新。
由于每个智能体的行为都是由提示词(prompt)驱动的,因此提示词工程成为研究者优化这些行为的主要手段。以下是 Anthropic 在为智能体设计提示词过程中总结出的一些原则:
高效的提示词设计。要优化提示词(prompt),就必须理解其实际影响。为此,Anthropic 通过控制台搭建了模拟环境 ------ 完全复现系统中的提示词和工具配置,逐步骤观察智能体的工作过程。这种方法立刻暴露出典型失效模式:冗余执行,即已获得充分结果后仍继续操作;低效查询,即使用冗长模糊的搜索指令;以及工具误用,错误选择功能模块。因而, 高效的提示词设计依赖于你对智能体行为建立起准确的心理模型,一旦理解深入,最有效的改进方向也会变得一目了然。
教会协调者如何正确分工。在 Anthropic 所采用的系统中,主导智能体负责将用户的查询拆解为若干子任务,并将这些任务分配给子智能体。每个子智能体都需要明确的目标、输出格式、关于应使用哪些工具和信息来源的指导,以及清晰的任务边界。如果任务描述不够具体,智能体之间就会出现重复劳动、任务空缺,或者无法找到所需的信息。
Anthropic 曾经历过一个深刻的教训:他们早期采用「研究芯片短缺」这类笼统指令时, 发现这类指令往往过于模糊,导致子智能体误解任务,或者执行与其他智能体完全相同的搜索。比如三个子智能体不约而同地锁定 2025 年供应链数据,其中一个偏离到 2021 年汽车芯片危机却未覆盖制造端瓶颈,最终报告重复率高达 60% 且缺失晶圆厂产能分析。
根据查询复杂度调整投入力度。由于智能体在判断不同任务所需的适当投入时存在困难,因此 Anthropic 在提示词中嵌入了分级投入规则。简单的事实查找只需要 1 个智能体调用 3-10 次工具;直接对比类任务可能需要 2-4 个子智能体,每个调用 10-15 次工具;而复杂的研究任务则可能使用超过 10 个子智能体,并且明确划分各自的职责。
这些明确的指导原则帮助主导智能体更有效地分配资源,避免在简单查询上投入过多。
工具的设计与选择至关重要。智能体与工具之间的接口就像人与计算机的交互界面一样重要。使用合适的工具可以显著提高效率 ------ 在很多情况下,这不仅是优化手段,更是必要条件。例如,如果一个智能体试图通过网页搜索来获取只存在于 Slack 中的上下文信息,那么从一开始它就注定无法成功。
随着 MCP 服务器让模型能够访问外部工具,这一问题变得更加复杂 ------ 智能体可能会遇到从未使用过的工具,而这些工具的描述质量又参差不齐。
因此,Anthropic 为智能体设计了明确的启发式规则,比如:先查看所有可用工具、将工具的用途与用户意图进行匹配、使用网页搜索进行广泛的信息探索、优先选择专用工具而非通用工具等。
糟糕的工具描述会导致智能体完全走上错误的路径,因此每个工具都必须具备明确的用途和清晰的描述。
让智能体自我改进。Anthropic 发现 Claude 4 系列模型在提示词工程方面表现非常出色。当提供一个提示词和相应的失败模式时,它能够诊断出智能体失败的原因,并提出改进建议。
Anthropic 甚至构建了一个工具测试智能体:当它接收到一个存在问题的 MCP 工具时,会尝试使用该工具,并随后重写其工具描述,以避免类似的失败发生。通过对该工具进行数十次测试,这个智能体能发现关键的使用细节和潜在的 bug。
这种优化工具交互体验的流程,使后续智能体在使用新描述时的任务完成时间缩短了 40%,因为它们能够避开大多数常见错误。
先广后窄,循序渐进。搜索策略应当模仿人类专家的研究方式:先全面探索,再深入细化。然而,智能体往往倾向于一开始就使用冗长、具体的查询词,结果返回的内容却非常有限。
为了解决这一问题,Anthropic 在提示词中引导智能体从简短、宽泛的查询开始,先评估可用信息,然后再逐步聚焦和深化研究方向。
引导思维过程。「扩展思维模式」(Extended Thinking Mode)会让 Claude 在输出中展示出可见的思考过程,这相当于一个可控的「草稿本」。主导智能体会利用这种思维过程来规划整体策略,包括评估哪些工具适合当前任务、判断查询的复杂度和需要的子智能体数量,并明确每个子智能体的职责。
测试表明,扩展思维能够显著提升智能体的指令遵循能力、推理能力和执行效率。
子智能体同样会先制定计划,然后在工具调用之后使用交替思维(Interleaved Thinking)来评估结果质量、发现信息缺口,并改进下一步的查询。这使得子智能体在面对不同任务时具备更强的适应能力。
并行调用工具彻底改变了研究任务的速度与性能。复杂的研究任务天然需要查阅大量信息来源。Anthropic 早期的智能体采用的是串行搜索,执行效率极低。
为了解决这一问题,他们引入了两种并行机制:
- 主导智能体同时创建 3-5 个子智能体,而不是依次生成;
- 每个子智能体同时使用 3 个以上的工具,而不是逐个调用。
这些改进将复杂查询的研究时间最多缩短了 90%,让研究系统能在几分钟内完成原本需要几小时的工作,同时覆盖的信息范围也远超其他系统。
有效评估方法
良好的评估机制对于构建可靠的 AI 应用至关重要,智能体系统也不例外。然而,评估多智能体系统面临独特的挑战。
传统评估通常假设 AI 每次都会遵循相同的步骤:给定输入 X,系统应按路径 Y 执行,并输出结果 Z。但多智能体系统的工作方式并非如此。即使起点相同,智能体可能会走上完全不同但同样有效的路径来实现目标。有的智能体可能只查阅 3 个信息源,有的可能会查 10 个;它们也可能使用不同的工具来得出相同的答案。
由于我们并不总是知道哪一套操作步骤才是正确的,所以通常无法只靠检查是否遵循了预设流程来评估智能体表现。相反,我们需要更灵活的评估方法,既要判断智能体是否达成了正确的结果,也要衡量其执行过程是否合理。
从小样本评估开始。在智能体开发的早期阶段,任何改动往往都会带来显著影响。例如,仅仅调整一下提示词,成功率就可能从 30% 提升到 80%。在这种影响幅度很大的阶段,只需少量测试用例就能看出变化的效果。
Anthropic 最初使用了一组大约 20 个查询,这些查询代表了真实的使用模式。测试这些查询通常就足以清晰判断某项更改的效果。
人们经常听到 AI 开发团队说他们推迟创建评估机制,是因为他们认为只有包含数百个测试用例的大规模评估才有价值。但实际上,最好的做法是立即从小规模测试开始,用几个示例立刻着手评估,而不是等到构建出完整评估系统之后再行动。
如果使用得当,「由大语言模型担任评审官」(LLM-as-judge)的评估方式也是不错的选择。
研究类的输出很难通过程序化手段进行评估,因为它们通常是自由格式的文本,且很少存在唯一正确的答案。而 LLM 天然适合担任这类输出的评分者。
Anthropic 使用了一位「LLM 评审官」,根据一套评分标准(rubric)来评估每个输出,具体包括以下几个维度:
- 事实准确性:陈述是否与引用来源相符?
- 引用准确性:引用内容是否确实支持了对应的陈述?
- 完整性:是否覆盖了所有被要求回答的内容?
- 信息源质量:是否优先使用了高质量的一手来源,而非较低质量的二手资料?
- 工具使用效率:是否合理选择并适当使用了相关工具?
Anthropic 尝试过使用多个 LLM 来分别评估每一个维度,但最终发现:只使用一次 LLM 调用,通过单个提示词让模型输出 0.0--1.0 的评分以及「通过 / 未通过」的判断,是最稳定、最符合人类评审标准的方法。
这种方法在测试用例本身有明确答案时尤其有效,比如:「是否准确列出了研发投入最高的三家制药公司?」 这种题目可以直接判断答案是否正确。
借助 LLM 担任评审官,能够高效地扩展到对数百个输出结果进行评估,大幅提升了评估系统的可扩展性与实用性。
人工评估能发现自动化评估遗漏的问题。实际测试智能体的人会发现一些评估系统无法捕捉的边缘案例,比如在不寻常查询中产生的幻觉答案、系统故障,或是细微的来源选择偏差。即使在自动化评估盛行的今天,人工测试依然不可或缺。
生产可靠性与工程挑战
在传统软件中,程序缺陷可能导致功能失效、性能下降或系统宕机。而在智能体系统中,细微的变化可能引发巨大的行为变动,这使得为需要在长时间运行过程中维护状态的复杂智能体编写代码异常困难。
智能体是有状态的,错误会累积。智能体可能运行很长时间,在多次调用工具过程中保持状态。这意味着我们需要持久地执行代码并在过程中处理错误。如果没有有效的缓解措施,轻微的系统故障对智能体来说可能是灾难性的。当发生错误时,我们不能简单地从头重启:重启成本高且令用户沮丧。相反,Anthropic 构建了能够从智能体发生错误时的状态继续执行的系统。
调试。智能体在运行时会做出动态决策,即使使用相同的提示,结果也具有非确定性,这使得调试变得更加困难。通过添加完整的生产追踪,Anthropic 能够系统地诊断智能体失败的原因并修复问题。
部署需要谨慎协调。智能体系统是高度有状态的提示、工具和执行逻辑的网络,几乎持续运行。这意味着每当我们部署更新时,智能体可能处于执行过程中的任何阶段。虽然不能同时将所有智能体更新到新版本。但 Anthropic 采用彩虹部署,通过逐步将流量从旧版本转移到新版本,同时保持两者并行运行,从而避免对正在运行的智能体造成干扰。
同步执行会造成瓶颈。目前,Anthropic 的主控智能体采用同步方式执行子智能体任务,会等待每批子智能体完成后才继续下一步。这简化了协调过程,但也在智能体之间的信息流动中形成了瓶颈。例如,主智能体无法实时引导子智能体,子智能体之间也无法协同,而整个系统可能会因为等待某个子智能体完成搜索而被阻塞。
异步执行则能带来更多的并行性:智能体可以同时工作,并在需要时创建新的子智能体。但这种异步性也带来了结果协调、状态一致性以及错误传播等方面的挑战。随着模型能够处理更长更复杂的研究任务,Anthropic 预计性能提升将足以抵消这些复杂性的增加。
总结
在构建 AI 智能体时,最后一公里往往占据了整个旅程的大部分。从开发者机器上能运行的代码库,到变成可靠的生产系统,需要大量的工程投入。智能体系统中错误的复合特性意味着,传统软件中的小问题可能会彻底扰乱智能体的运行。某一步骤失败,可能导致智能体探索完全不同的路径,从而产生不可预测的结果。基于本文所述的各种原因,原型与生产环境之间的差距通常比预期更大。
尽管面临这些挑战,多智能体系统在开放式研究任务中已经展现出巨大价值。只要经过细致的工程设计、全面的测试、注重细节的提示词和工具设计、健全的运维实践,以及研究、产品与工程团队之间紧密合作且对当前智能体能力有深刻理解,多智能体研究系统就能在大规模场景中稳定运行。我们已经看到这些系统正在改变人们解决复杂问题的方式。
#AI醒了?
LLM已能自我更新权重,自适应、知识整合能力大幅提升
近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。
本月初我们就曾梳理报道了一些,包括 Sakana AI 与不列颠哥伦比亚大学等机构合作的「达尔文-哥德尔机(DGM)」、CMU 的「自我奖励训练(SRT)」、上海交通大学等机构提出的多模态大模型的持续自我改进框架「MM-UPT」、香港中文大学联合 vivo 等机构的自改进框架「UI-Genie」,参阅文章《LSTM 之父 22 年前构想将成真?一周内 AI「自我进化」论文集中发布,新趋势涌现?》
那之后,相关研究依然还在不断涌现,以下拼图展示了一些例子:
而前些天,OpenAI CEO、著名 𝕏 大 v 山姆・奥特曼在其博客《温和的奇点(The Gentle Singularity)》中更是畅想了一个 AI/智能机器人实现自我改进后的未来。他写道:「我们必须以传统的方式制造出第一批百万数量级的人形机器人,但之后它们能够操作整个供应链来制造更多机器人,而这些机器人又可以建造更多的芯片制造设施、数据中心等等。」
不久之后,就有 𝕏 用户 @VraserX 爆料称有 OpenAI 内部人士表示,该公司已经在内部运行能够递归式自我改进的 AI。这条推文引起了广泛的讨论 ------ 有人表示这不足为奇,也有人质疑这个所谓的「OpenAI 内部人士」究竟是否真实。

https://x.com/VraserX/status/1932842095359737921
但不管怎样,AI 也确实正向实现自我进化这条路前进。
MIT 昨日发布的《Self-Adapting Language Models》就是最新的例证之一,其中提出了一种可让 LLM 更新自己的权重的方法:SEAL🦭,即 Self-Adapting LLMs。在该框架中,LLM 可以生成自己的训练数据(自编辑 /self-editing),并根据新输入对权重进行更新。而这个自编辑可通过强化学习学习实现,使用的奖励是更新后的模型的下游性能。

论文标题:Self-Adapting Language Models
论文地址:https://arxiv.org/pdf/2506.10943
项目页面:https://jyopari.github.io/posts/seal
代码地址:https://github.com/Continual-Intelligence/SEAL
这篇论文发布后引发了广泛热议。在 Hacker News 上,有用户评论说,这种自编辑方法非常巧妙,但还不能说就已经实现了能「持续自我改进的智能体」。

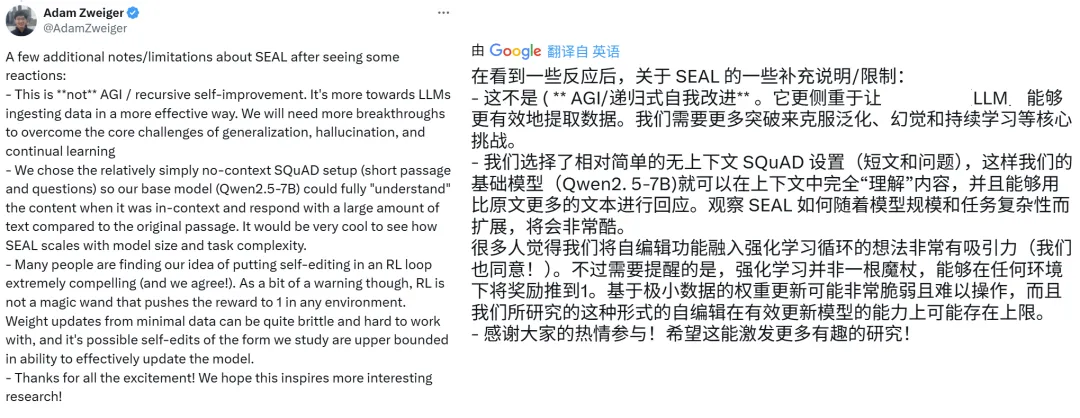
论文一作 Adam Zweiger 也在 𝕏 上给出了类似的解释:
也有人表示,这表明我们正在接近所谓的事件视界(event horizon)------ 这个概念其实也出现在了山姆・奥特曼《温和的奇点》博客的第一句话,不过奥特曼更激进一点,他的说法是「我们已经越过了事件视界」。简单来说,event horizon(事件视界)指的是一个不可逆转的临界点,一旦越过,人类将不可避免地迈入某种深刻变革的阶段,比如通向超级智能的道路。

当然,也有人对自我提升式 AI 充满了警惕和担忧。

下面就来看看这篇热门研究论文究竟得到了什么成果。
自适应语言模型(SEAL)
SEAL 框架可以让语言模型在遇到新数据时,通过生成自己的合成数据并优化参数(自编辑),进而实现自我提升。
该模型的训练目标是:可以使用模型上下文中提供的数据,通过生成 token 来直接生成这些自编辑(SE)。
自编辑生成需要通过强化学习来学习实现,其中当模型生成的自编辑在应用后可以提升模型在目标任务上的性能时,就会给予模型奖励。
因此,可以将 SEAL 理解为一个包含两个嵌套循环的算法:一个外部 RL 循环,用于优化自编辑生成;以及一个内部更新循环,它使用生成的自编辑通过梯度下降更新模型。

该方法可被视为元学习的一个实例,即研究的是如何以元学习方式生成有效的自编辑。
通用框架
令 θ 表示语言模型 LM_θ 的参数。 SEAL 是在单个任务实例 (C, τ) 上运作,其中 C 是包含与任务相关信息的上下文,τ 定义了用于评估模型适应度(adaptation)的下游评估。
比如,在知识整合任务中,C 是旨在整合到模型内部知识中的段落,τ 是关于该段落的一组问题及其相关答案。而在少样本学习任务中,C 包含某个新任务的少样本演示,τ 是查询输入和 ground-truth 输出。
给定 C,模型会生成一个自编辑 SE(其形式因领域而异),并通过监督微调更新自己的参数:θ′ ← SFT (θ, SE)。
该团队使用了强化学习来优化自编辑的生成过程:模型执行一个动作(生成 SE),再根据 LM_θ′ 在 τ 上的表现获得奖励 r,并更新其策略以最大化预期奖励:
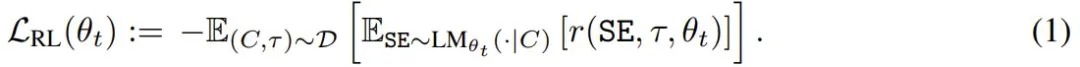
不过,与标准强化学习设置不同,在这里的设置中,分配给给定动作的奖励取决于执行动作时的模型参数 θ(因为 θ 会更新为 θ′,然后再被评估)。
如此一来,底层的强化学习状态必定会包含策略的参数,并由 (C, θ) 给出,即使策略的观测值仅限于 C(将 θ 直接置于上下文中是不可行的)。
这意味着,使用先前版本模型 θ_old 收集的 (state, action, reward) 三元组可能会过时,并且与当前模型 θ_current 不一致。因此,该团队采用一种基于策略的方法,其中会从当前模型中采样自编辑 SE,并且至关重要的是,奖励也会使用当前模型进行计算。
该团队尝试了各种在线策略方法,例如组相对策略优化 (GRPO) 和近端策略优化 (PPO) ,但发现训练不稳定。
最终,他们选择了来自 DeepMind 论文《Beyond human data: Scaling self-training for problem-solving with language models.》的 ReST^EM,这是一种基于已过滤行为克隆的更简单的方法 ------ 也就是「拒绝采样 + SFT」。
ReST^EM 可以被视为一个期望最大化 (EM) 过程:E-step 是从当前模型策略采样候选输出,M-step 是通过监督微调仅强化那些获得正奖励的样本。这种方法可在以下二元奖励下优化目标 (1) 的近似:

更准确地说,在优化 (1) 时,必须计算梯度
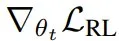
。然而,在这里的设置中,奖励项 r (SE, τ, θ_t) 取决于 θ_t,但不可微分。为了解决这个问题,该团队的做法是将奖励视为相对于 θ_t 固定。通过这种近似,对于包含 N 个上下文和每个上下文 M 个采样得到自编辑的小批量,其蒙特卡洛估计器变为:
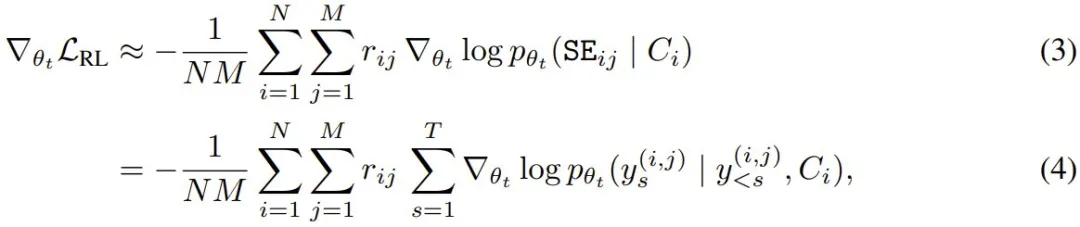
其中 p_θ_t 表示模型的自回归分布,y_s^(i,j) 是自编辑 SE_ij 的第 s 个 token,即上下文 C_i 的第 j 个样本。由于在 (4) 中可以忽略 r = 0 的序列,该团队研究表明:在二元奖励 (2) 下(对奖励项应用停止梯度),ReST^EM 只需使用简单的「在好的自编辑上进行 SFT」,就能优化 (1)。算法 1 给出了 SEAL 的训练循环。

最后,他们还注意到,虽然本文的实现是使用单个模型来生成自编辑并从这些自编辑中学习,但也可以将这些角色分离。在这样一种「教师-学生」形式中,学生模型将使用由另一个教师模型提出的编辑进行更新。然后,教师模型将通过强化学习进行训练,以生成能够最大程度提高学生学习效果的编辑。
针对具体领域实例化 SEAL
理论有了,该团队也打造了 SEAL 的实例。具体来说,他们选择了两个领域:知识整合和少样本学习。
其中,知识整合的目标是有效地将文章中提供的信息整合到模型的权重中。下图展示了相关设置。

而下图则给出了少样本学习的设置。
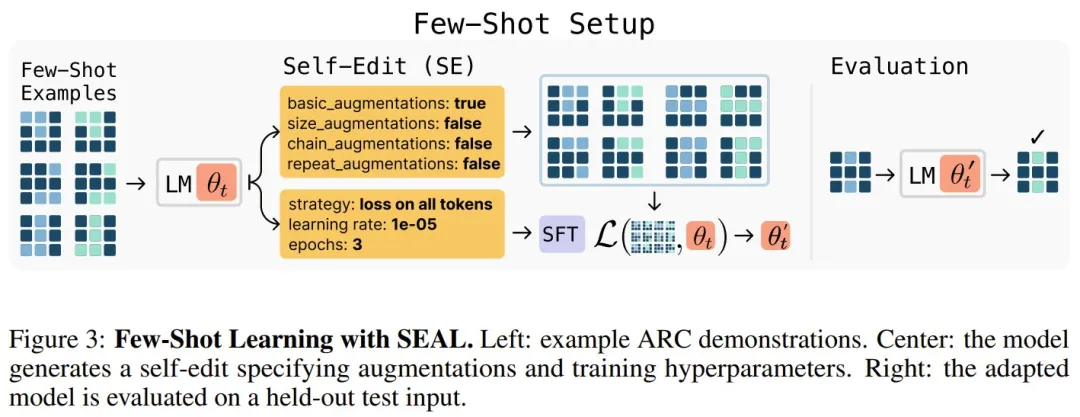
对这两种实例化的更详细描述请访问原论文,下面来看看 SEAL 的实际表现。
实验结果
少样本学习
实验所用的模型是 Llama-3.2-1B-Instruct,基准为 ARC。参与对比的方法包括 ICL(上下文学习)、TTT + 自编辑(无强化学习)、Oracle TTT。结果见下表。

可以看到,与基线相比,SEAL 显著提高了适应成功率:72.5% vs. 20%(使用基础模型的自编辑但未进行强化学习训练)和 0%(无适应),但性能仍低于 Oracle TTT,表明新方法仍有进一步改进的空间。
知识整合
知识整合则使用了更大一些的 Qwen2.5-7B,目标是整合 SQuAD 文章中的新事实内容。这里对比的方法包括基础模型、仅在文章上训练的模型、在文章 + 合成数据训练的模型、在文章 + GPT-4.1 合成数据上训练的模型。结果见下表。
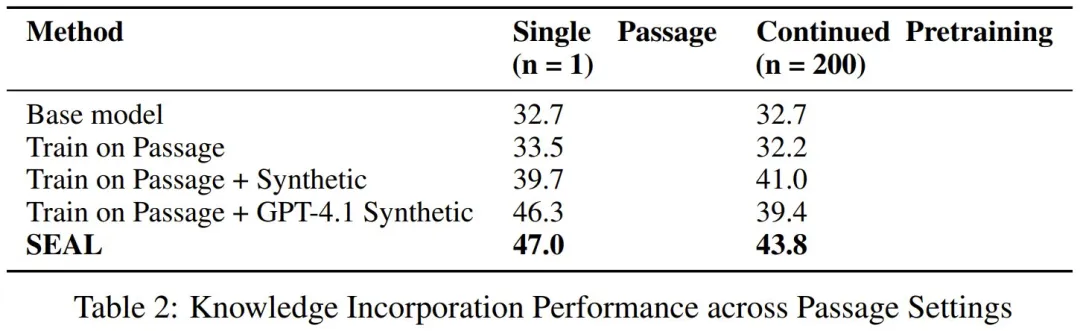
可以看到,在单篇文章(n = 1)和持续预训练(n = 200)这两种情况下,SEAL 方法的准确度表现都超过了基准。
首先使用基础 Qwen-2.5-7B 模型生成的合成数据训练后,模型的表现已经能获得明显提升,从 32.7% 分别提升到了 39.7% 和 41.0%,之后再进行强化学习,性能还能进一步提升(47.0% 和 43.8%)。
图 4 展现了每次外部强化学习迭代后的准确度。
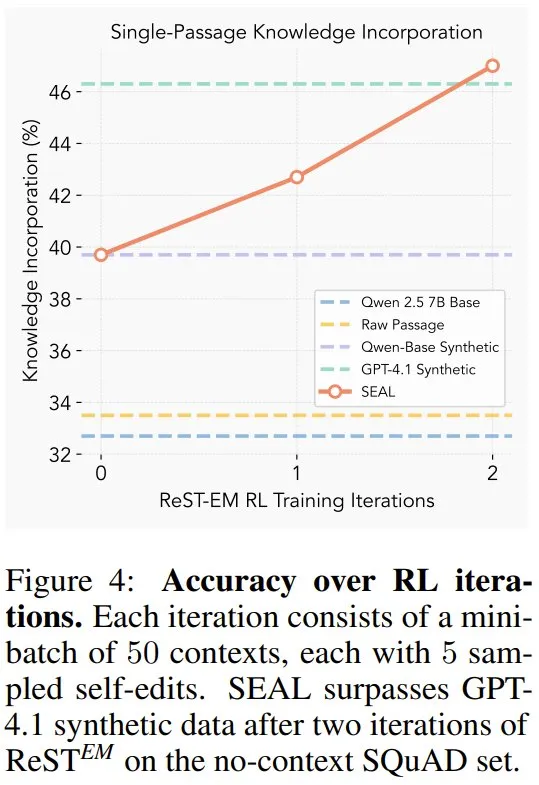
可以看到,两次迭代足以使 SEAL 超越使用 GPT-4.1 数据的设置;后续迭代的收益会下降,这表明该策略快速收敛到一种将段落蒸馏为易于学习的原子事实的编辑形式(参见图 5 中的定性示例)。

在这个例子中,可以看到强化学习如何导致生成更详细的自编辑,从而带来更佳的性能。虽然在这个例子中,进展很明显,但在其他例子中,迭代之间的差异有时会更为细微。
另外,该团队也在论文中讨论了 SEAL 框架在灾难性遗忘、计算开销、上下文相关评估方面的一些局限,详见原论文。
最后,来个小调查,你认为真正的自我进化式 AI 将在何时实现?