通常先装vs后装cuda,cuda会自动集成到vs中。而如果先装cuda,后装vs则需要进行额外的配置。
1 VS新建项目中增加CUDA选项
1.1 关闭vs2019(如果已经打开)
1.2 检查CUDA安装路径C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\extras\visual_studio_integration\CudaProjectVsWizards下,是否存在VS集成扩展支持
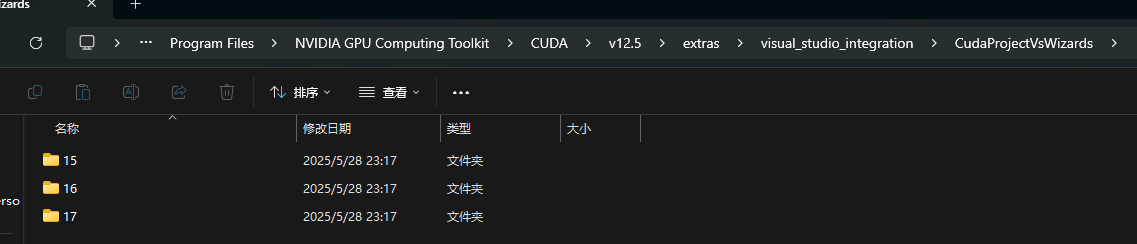
这里15对应Visual Studio 2017,16对应Visual Studio 2019,17对应Visual Studio 2022,如果不存在相应扩展,请参照1.3获取
1.3 运行cuda_12.5.0_555.85_windows.exewindows安装包,它首先会解压cuda,在解压路径cuda12.5\visual_studio_integration\CUDAVisualStudioIntegration\extras\visual_studio_integration\CudaProjectVsWizards下有3个文件夹,就是1.2需要的VS扩展支持
1.4 将对应VS2019的16文件夹下内容拷贝到C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\Common7\IDE\Extensions下的NVIDIA\CUDA 12.5 Wizards\12.5中
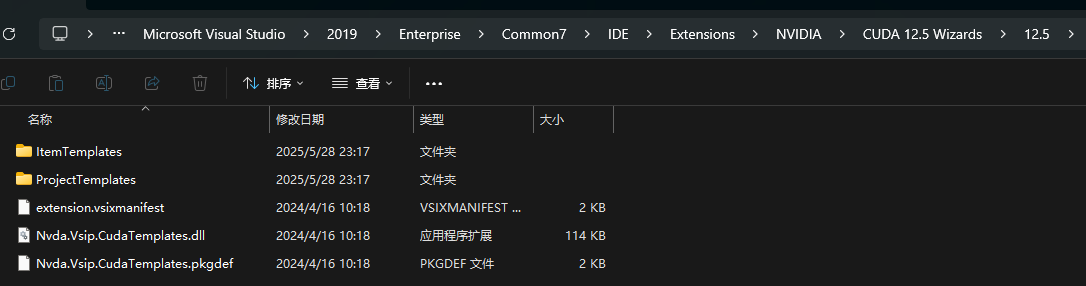
注意:上述三级文件夹NVIDIA\CUDA 12.5 Wizards\12.5可能需要手动创建,另外相依文件也可以不直接拷贝,而是通过创建链接的方式来进行
mklink /d "C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\Common7\IDE\Extensions\NVIDIA\CUDA 12.5 Wizards\12.5" "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\extras\visual_studio_integration\CudaProjectVsWizards\16"
这个命令的作用是,对C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\extras\visual_studio_integration\CudaProjectVsWizards下的16文件夹创建一个符号链接(类似创建快捷方式),创建的符号链接位于第一步中新建的CUDA 112.5 Wizards文件夹,该符号链接名为12.5:

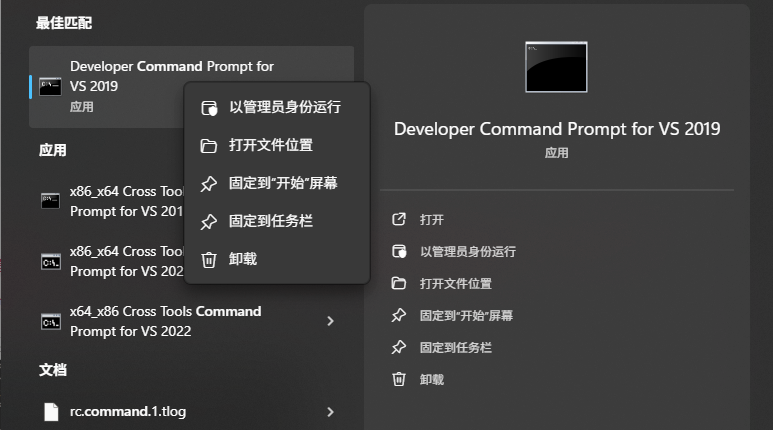
1.5 Ctrl+S打开搜索框,输入command,找到Developer Command Prompt for VS 2019,右键,选择以管理员方式运行,运行以下命令:devenv.com /setup /nosetupvstemplates
1.6 将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\extras\visual_studio_integration\MSBuildExtensions中文件拷贝到C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\MSBuild\Microsoft\VC\v160\BuildCustomizations中
1.7 重启Visual Studio 2019,这样在新建工程的时候就可以看到CUDA工程模板出现了。
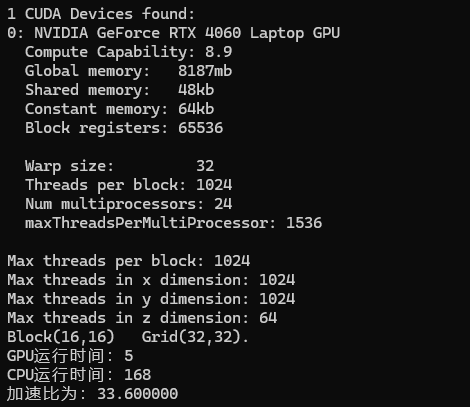
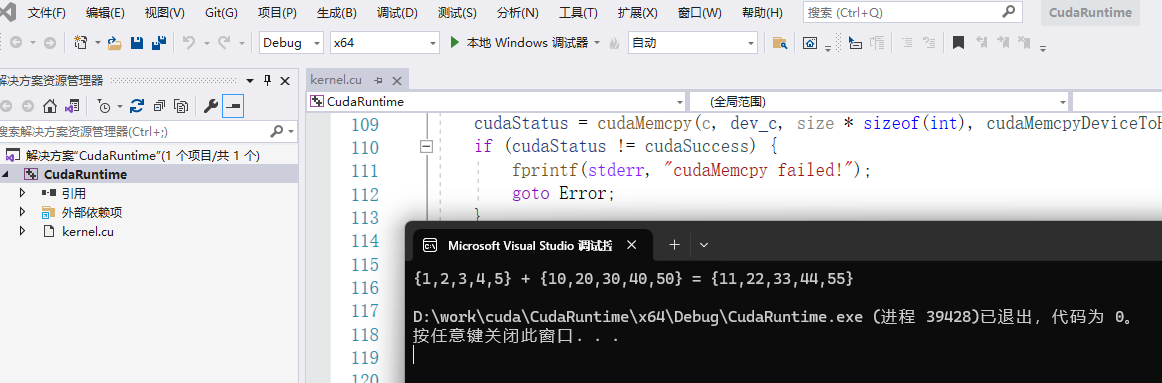
1.8 点击创建后就会进入如下界面。此时会生成一个模板kernel.cu文件。可以通过运行该文件来测试是否可以成功进行CUDA编程,如果编译通过,在命令行窗口中生成如下结果,说明编译成功。
2 关键概念
2.1 global、device和host
用host指代CPU及其内存,而用device指代GPU及其内存。
• global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
• device:在device上执行,仅可以从device中调用,不可以和__global__同时用。
• host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__同时用,此时函数会在device和host都编译。
2.2 CUDA的整体结构
kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要运行的线程,在CUDA中,每一个线程都要执行核函数。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间。每一个grid由多个block组成,每一个block由多个线程组成。
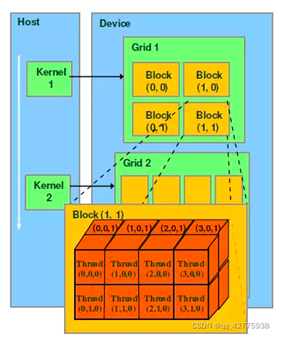 从上图可以看出每一个block可以组织成三维的,但其实block可以1维、2维或3维组织。Grid可以1维、2维组织。
从上图可以看出每一个block可以组织成三维的,但其实block可以1维、2维或3维组织。Grid可以1维、2维组织。
2.3 CUDA内存模型
如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。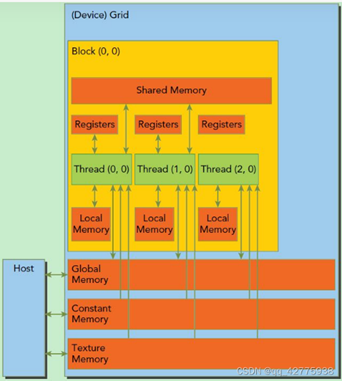 2.4 Streaming Multiprocessor,SM
2.4 Streaming Multiprocessor,SM
SM是GPU的处理器,SM可以并发地执行数百个线程。
• 当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。
• SM一般可以调度多个线程块,一个kernel的各个线程块可能被分配多个SM。
• 当线程块被划分到某个SM上时,它将被进一步划分为多个线程束(一个线程束包含32个线程),因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。
• 由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
SM中包含多个SP,一个GPU可以有多个SM(比如16个),最终一个GPU可能包含有上千个SP。
每个线程由每个线程处理器(SP)执行,线程块由多核处理器(SM)执行,一个kernel其实由一个grid来执行,一个kernel一次只能在一个GPU上执行。
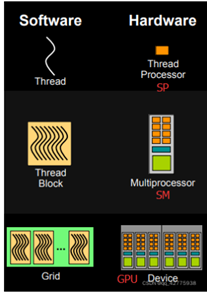 block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。
3 自己进行CUDA编程验证
以下程序给出了一个矩阵乘法的例子


1 #include "cuda_runtime.h"
2 #include "device_launch_parameters.h"
3
4 #include <stdio.h>
5 #include <iostream>
6
7 #define KB 1024
8 #define MB (1024*1024)
9
10 using namespace std;
11
12 const int Row = 512; // 行数
13 const int Col = 512; // 列数
14
15 __global__
16 void matrix_mul_gpu(int* M, int* N, int* P, int width) // width代表列数
17 {
18 int i = threadIdx.x + blockDim.x * blockIdx.x; // 第i列的线程
19 int j = threadIdx.y + blockDim.y * blockIdx.y; // 第j行的线程
20
21 int sum = 0;
22 for (int k = 0; k < width; k++)
23 {
24 int a = M[j * width + k]; // 第j行的某一个值
25 int b = N[k * width + i]; // 第i列的某一个值
26 sum += a * b;
27 }
28 P[j * width + i] = sum;
29 }
30
31 void matrix_mul_cpu(int* M, int* N, int* P, int width)
32 {
33 for (int i = 0; i < width; i++)
34 for (int j = 0; j < width; j++)
35 {
36 int sum = 0;
37 for (int k = 0; k < width; k++)
38 {
39 int a = M[i * width + k];
40 int b = N[k * width + j];
41 sum += a * b;
42 }
43 P[i * width + j] = sum;
44 }
45 }
46
47 __host__ int main(int argc, char* argv[])
48 {
49 int devCount = 0;
50 cudaError_t err = cudaGetDeviceCount(&devCount);
51 if (err != cudaSuccess)
52 {
53 printf("CUDA error: '%s'. You probably don't have Nvidia CUDA drivers installed or don't have any cards.\n", cudaGetErrorName(err));
54 return -1;
55 }
56 printf("%d CUDA Devices found:\n", devCount);
57
58 for (int i = 0; i < devCount; ++i)
59 {
60 cudaDeviceProp props;
61 cudaGetDeviceProperties(&props, i);
62 printf("%d: %s\n", i, props.name);
63 printf(" Compute Capability: %d.%d\n", props.major, props.minor);
64 cout << " Global memory: " << props.totalGlobalMem / MB << "mb" << endl;
65 cout << " Shared memory: " << props.sharedMemPerBlock / KB << "kb" << endl;
66 cout << " Constant memory: " << props.totalConstMem / KB << "kb" << endl;
67 cout << " Block registers: " << props.regsPerBlock << endl << endl;
68
69 cout << " Warp size: " << props.warpSize << endl;
70 cout << " Threads per block: " << props.maxThreadsPerBlock << endl;
71 // I think this is a virtual result, not the real hardware
72 // printf(" Max blocks per multiprocessor: %lu\n",props.maxBlocksPerMultiProcessor);
73 cout << " Num multiprocessors: " << props.multiProcessorCount << endl;
74 cout << " maxThreadsPerMultiProcessor: " << props.maxThreadsPerMultiProcessor << endl;
75 // I think these are virtual dimensions
76 // cout << " Max block dimensions: [ " << props.maxThreadsDim[0] << ", " << props.maxThreadsDim[1] << ", " << props.maxThreadsDim[2] << " ]" << endl;
77 // cout << " Max grid dimensions: [ " << props.maxGridSize[0] << ", " << props.maxGridSize[1] << ", " << props.maxGridSize[2] << " ]" << endl;
78 cout << endl;
79
80 printf("Max threads per block: %d\n", props.maxThreadsPerBlock);
81 printf("Max threads in x dimension: %d\n", props.maxThreadsDim[0]);
82 printf("Max threads in y dimension: %d\n", props.maxThreadsDim[1]);
83 printf("Max threads in z dimension: %d\n", props.maxThreadsDim[2]);
84 }
85
86 clock_t GPUstart, GPUend;
87
88 // 选择第一个GPU为默认
89 err = cudaSetDevice(0);
90 if (err != cudaSuccess) {
91 printf("cudaSetDevice failed please check\n");
92 return -1;
93 }
94 int* A = (int*)malloc(sizeof(int) * Row * Col);
95 int* B = (int*)malloc(sizeof(int) * Row * Col);
96 int* C = (int*)malloc(sizeof(int) * Row * Col);
97 //malloc device memory
98 int* d_dataA, * d_dataB, * d_dataC;
99 cudaMalloc((void**)&d_dataA, sizeof(int) * Row * Col);
100 cudaMalloc((void**)&d_dataB, sizeof(int) * Row * Col);
101 cudaMalloc((void**)&d_dataC, sizeof(int) * Row * Col);
102 //set value
103 for (int i = 0; i < Row * Col; i++) {
104 A[i] = 90;
105 B[i] = 10;
106 }
107
108 GPUstart = clock();
109 cudaMemcpy(d_dataA, A, sizeof(int) * Row * Col, cudaMemcpyHostToDevice);
110 cudaMemcpy(d_dataB, B, sizeof(int) * Row * Col, cudaMemcpyHostToDevice);
111 dim3 threadPerBlock(16, 16);
112 // (Col + threadPerBlock.x - 1)/threadPerBlock.x=Col/threadPerBlock.x+1,即多拿一个block来装不能整除的部分
113 dim3 blockNumber((Col + threadPerBlock.x - 1) / threadPerBlock.x, (Row + threadPerBlock.y - 1) / threadPerBlock.y);
114 printf("Block(%d,%d) Grid(%d,%d).\n", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y);
115 // 每一个线程进行某行乘某列的计算,得到结果中的一个元素。也就是d_dataC中的每一个计算结果都和GPU中线程的布局<blockNumber, threadPerBlock >一致
116 matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataB, d_dataC, Col);
117 //拷贝计算数据-一级数据指针
118 cudaMemcpy(C, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost);
119
120 //释放内存
121 free(A);
122 free(B);
123 free(C);
124 cudaFree(d_dataA);
125 cudaFree(d_dataB);
126 cudaFree(d_dataC);
127
128 GPUend = clock();
129 int GPUtime = GPUend - GPUstart;
130 printf("GPU运行时间:%d\n", GPUtime);
131
132 // CPU计算
133 clock_t CPUstart, CPUend;
134
135 int* A2 = (int*)malloc(sizeof(int) * Row * Col);
136 int* B2 = (int*)malloc(sizeof(int) * Row * Col);
137 int* C2 = (int*)malloc(sizeof(int) * Row * Col);
138
139 //set value
140 for (int i = 0; i < Row * Col; i++) {
141 A2[i] = 90;
142 B2[i] = 10;
143 }
144
145 CPUstart = clock();
146 matrix_mul_cpu(A2, B2, C2, Col);
147 CPUend = clock();
148 int CPUtime = CPUend - CPUstart;
149 printf("CPU运行时间:%d\n", CPUtime);
150 printf("加速比为:%lf\n", double(CPUtime) / GPUtime);
151
152 return 0;
153 }cuda sample
程序运行结果如下,可见GPU可以大大加速矩阵乘法运算过程。