本章介绍下Hopper下TensorCore的使用,以及如何利用TensorCore实现和优化Gemm,主要参考这个博客和对应的代码实现。
代码实现了C = A x B,均为bf16,A是K Major,shape为MxK,B为K Major,shape为NxK,C为M Major,shape为NxM,因为Gemm会以tile粒度load到SMEM进行计算,因此后续称逻辑上A的tile为tileA,同理B和C;SMEM上A矩阵的tile为SA,同理B和C。
在实际介绍kernel之前,先介绍下后续用到的多维TMA和wgmma。
多维TMA
之前在DeepEP中介绍过一维TMA + mbarrier的流程,但是如图1所示,Gemm中一个block需要处理C矩阵中的一个tile,例如红色部分,因此需要使用多维的TMA,红色的tile被称为Bounding Box,绿色为C矩阵,即原tensor,一次TMA copy会处理这个tensor的一个Bounding Box(后续简称Box)。
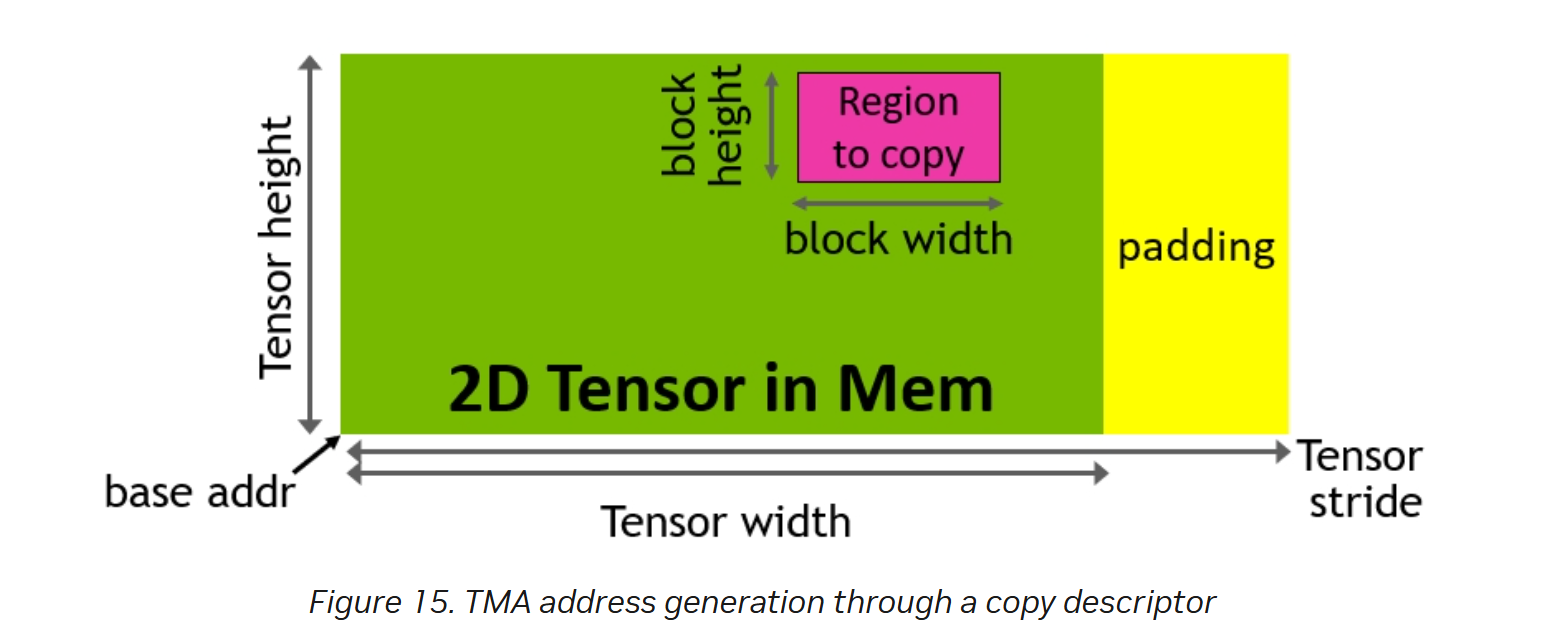
图 1
Box的dim和原有Tensor相同,当通过coord指定了Box的起始偏移之后,TMA就可以根据用户指定的其他信息,如stride等,将这个Box copy到SMEM,然后看下用户如何指定这些信息。
cpp
CUresult cuTensorMapEncodeTiled (CUtensorMap* tensorMap, CUtensorMapDataType tensorDataType,
cuuint32_t tensorRank, void* globalAddress, const cuuint64_t* globalDim,
const cuuint64_t* globalStrides, const cuuint32_t* boxDim,
const cuuint32_t* elementStrides, CUtensorMapInterleave interleave,
CUtensorMapSwizzle swizzle, CUtensorMapL2promotion l2Promotion,
CUtensorMapFloatOOBfill oobFill )用户通过cuTensorMapEncodeTiled创建一个tensorMap,执行TMA的时候会指定这个tensorMap,从而TMA会知道如何copy。参数含义如下:
- tensorRank就是tensor的维度,Box的维度和tensor维度一致;
- tensorDataType为类型
- globalAddress为tensor的起始地址;
- globalDim为tensor的dim,是一个列表,变化越快的维度越靠前,如一个row major的二维矩阵,需要先写列数,再写行数;
- globalStrides表示tensor在前一个dim上的stride,如row major的二维矩阵,只需要填写列数;
- boxDim就是Box的dim,TMA会根据boxDim在tensor的对应维度上进行遍历;
- elementStrides表示在各个dim遍历时候的stride;interleave一般为None;
- swizzle稍后介绍;
- l2Promotion为从DRAM到L2的传输粒度;
- 当Box超过tensor的边界后,根据oobFill填充SMEM,如图2,进一步的可以利用oobFill进行SMEM的padding。
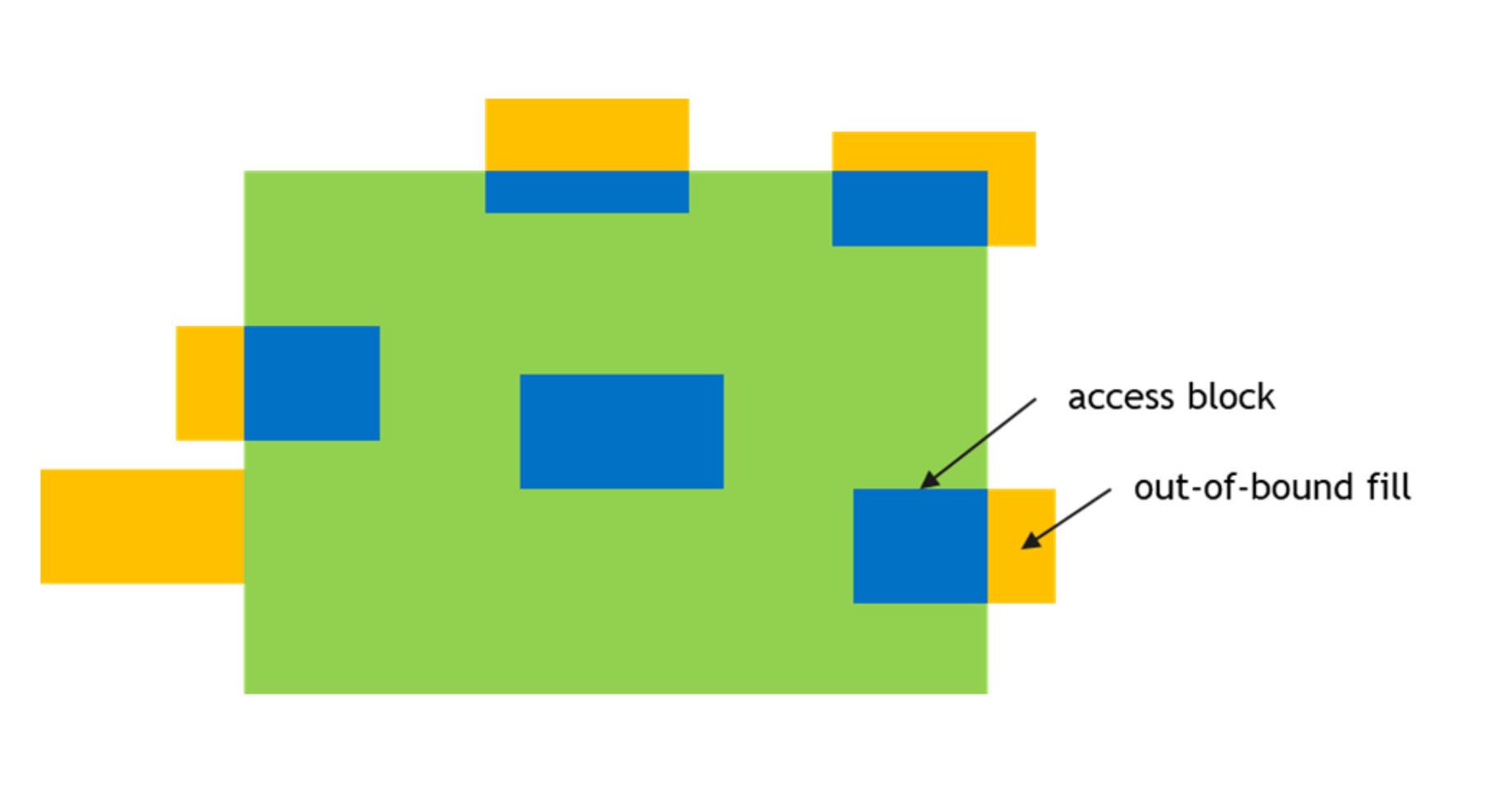
图 2
一次TMA copy可以类比一个多重循环:
cpp
for (int i = 0; i < boxDim[-1]; i += elementStrides[-1]) {
...
for (int j = 0; j < boxDim[0]; j += elementStrides[0]) {
copy one element from DRAM to SMEM;
}
}WGMMA
先回顾一下Ampere中的mma的流程,mma的操作数必须位于寄存器,即RMEM,所以需要通过ldmatrix将A和B从SMEM拷贝到RMEM,然后执行一个warp粒度的mma指令,就是说矩阵乘由32线程一起完成,但是A和B需要分布式的存在warp所有线程的寄存器,每个线程存储A和B的一部分,以fp16的16x8x16的A为例,数据在warp中分布如图3所示:
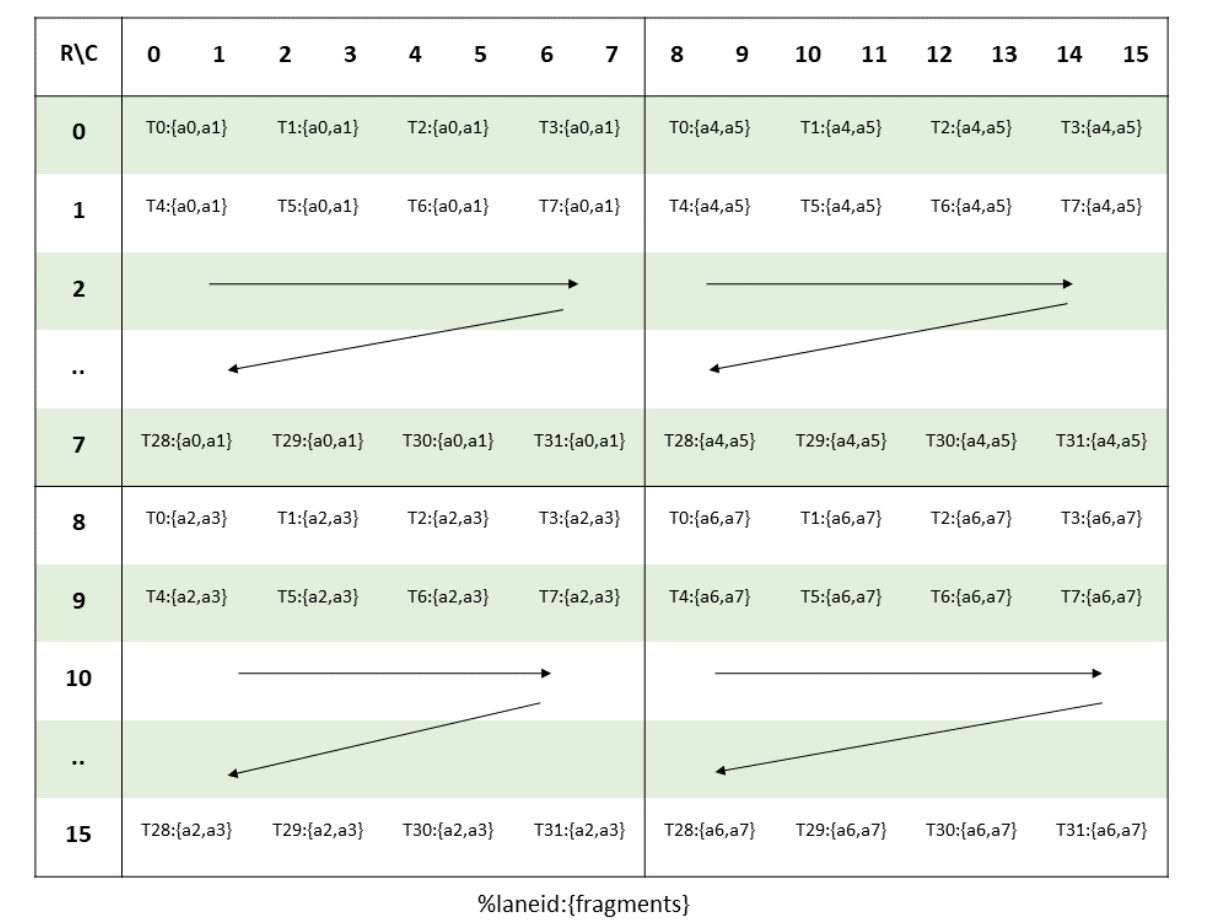
图 3
为了完成这个数据排布,可以使用如图4方式执行ldmatrix。

图 4
ldmatrix通过一条指令完成4个8x8的子矩阵的加载,每个子矩阵的一行是8个fp16,大小为16B,一个线程提供一行的地址,行与行之间不要求地址连续,如图5中T0提供第一个子矩阵的第一行输入。最后这16x16的矩阵数据会分布式存在warp的寄存器,比如深蓝色的4个框对应了8个fp16,会存在T0的4个32位寄存器中。
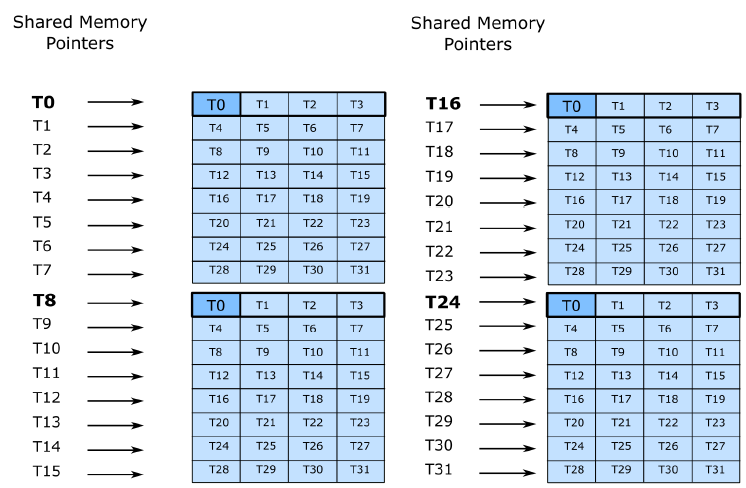
图 5
而Hopper引入了异步的wgmma指令,粒度为warpgroup,一个warpgroup是warprank连续的四个warp,warprank计算方法如下:
cpp
(%tid.x + %tid.y * %ntid.x + %tid.z * %ntid.x * %ntid.y) / 32wgmma的A可以在寄存器,也可以在SMEM,B必须在SMEM,一次可以执行M*N*K的矩阵乘,M必须为64,N可以从8到256,但是需要是8的倍数,K需要为32B,比如对于bf16,K就是16,对于bf16我们用到的指令为M64K16。
wgmma的输出仍然在寄存器,分布如图6:

图 6
异步性
如上所述,wgmma是一个异步指令,因此Hopper提供了commit group机制进行同步。
执行了wgmma.mma_async之后,用户可以通过如下指令新建一个wgmma-group,将之前所有不在任何wgmma-group中的wgmma.mma_async指令加入到这个新的wgmma-group。
cpp
wgmma.commit_group.sync.aligned;然后用户可以通过wait_group等待,直到最近创建的wgmma-group没有执行完成的数量少于或等于N个。
cpp
wgmma.wait_group.sync.aligned N;在执行wgmma之前,需要执行wgmma.fence,保证当前wgmma指令之前对当前wgmma用到的寄存器的写入指令完成,一个例外是如果多个wgmma指令shape相同,他们之间不需要wgmma.fence。
cpp
wgmma.fence.sync.aligned;descriptor
mma的操作数位于RMEM,因此用户通过ldmatrix将数据排布乘mma需要的格式就可以执行mma,但是由于wgmma中数据可以在SMEM,因此需要用户执行wgmma的时候指定一个descriptor,描述A和B在SMEM中的排布,使得TensorCore可以正确解析SA和SB,descriptor是个64位的值,包含了SMEM中A和B的SMEM base address,swizzle mode, Leading Dimension Byte Offset(后续简称LBO),Stride Dimension Byte Offset(后续简称SBO)等信息,编码如下:
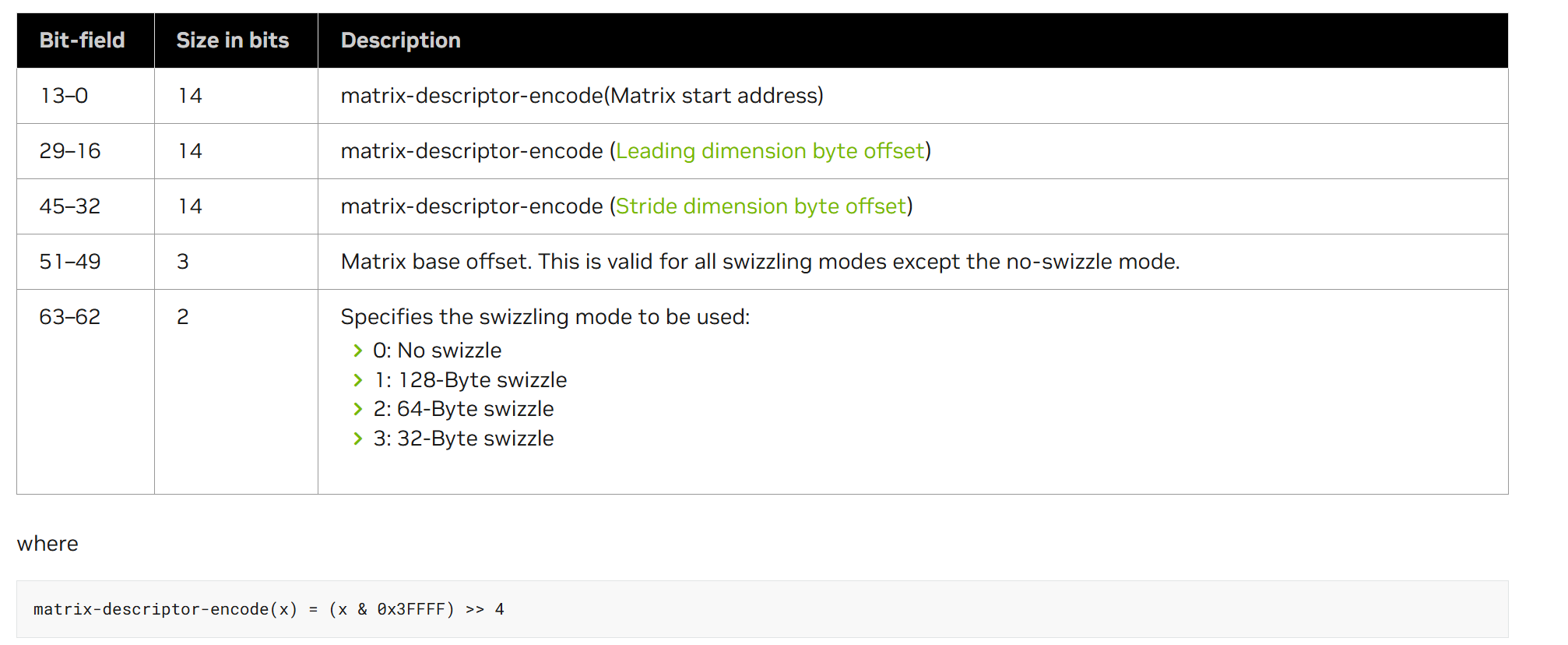
图 7
PTX中对swizzle,LBO,SBO的描述很抽象,这块主要是个人理解+实验,不一定正确。
然后看下PTX中关于LBO和SBO的定义:

图 8
在mma指令的时候,由于显式的执行了ldmatrix指令,因此为了避免bank冲突,需要对SMEM进行swizzle。但是Hopper的wgmma没有让用户显式的读取SMEM,由于TensorCore物理shape为M8N4K16,对应A大小为8x16,所以猜测对A的load和ldmatrix类似,都是load 8x8的矩阵,分成两个cycle读完整的A,因此需要一个值表示这一次执行的两个8x8小矩阵之间的距离,即后文的LBO,多个TensorCore需要一个值表述不同的8x16矩阵,即后文的SBO。 wgmma指令将输入矩阵看作由多个core matrix(对应上文的猜测,不过PTX9.0又删除了这个概念)组成,K major下core matrix为8x16B,对应到bf16就是上文提到的8x8的矩阵,每个core matrix在SMEM上都是连续存储的(不swizzle的时候)。
由于wgmma一次处理A矩阵的M64K16,A矩阵可以理解为8x2个core matrix组成的,那么按照PTX的正式化定义,LBO表示在K维度上两个core matrix的offset,SBO表示在M维度上两个core matrix之间的offset。
然后我们看下A矩阵在不同swizzle下的情况,以及如何设置LBO和SBO,后续均假设为K major,因为SMEM为32个bank,每个bank 4B,共128B,而core matrix中一行大小为16B,因此下文中将SMEM看作为16B的"bank",一共8个"bank"。
SWIZZLE_NONE
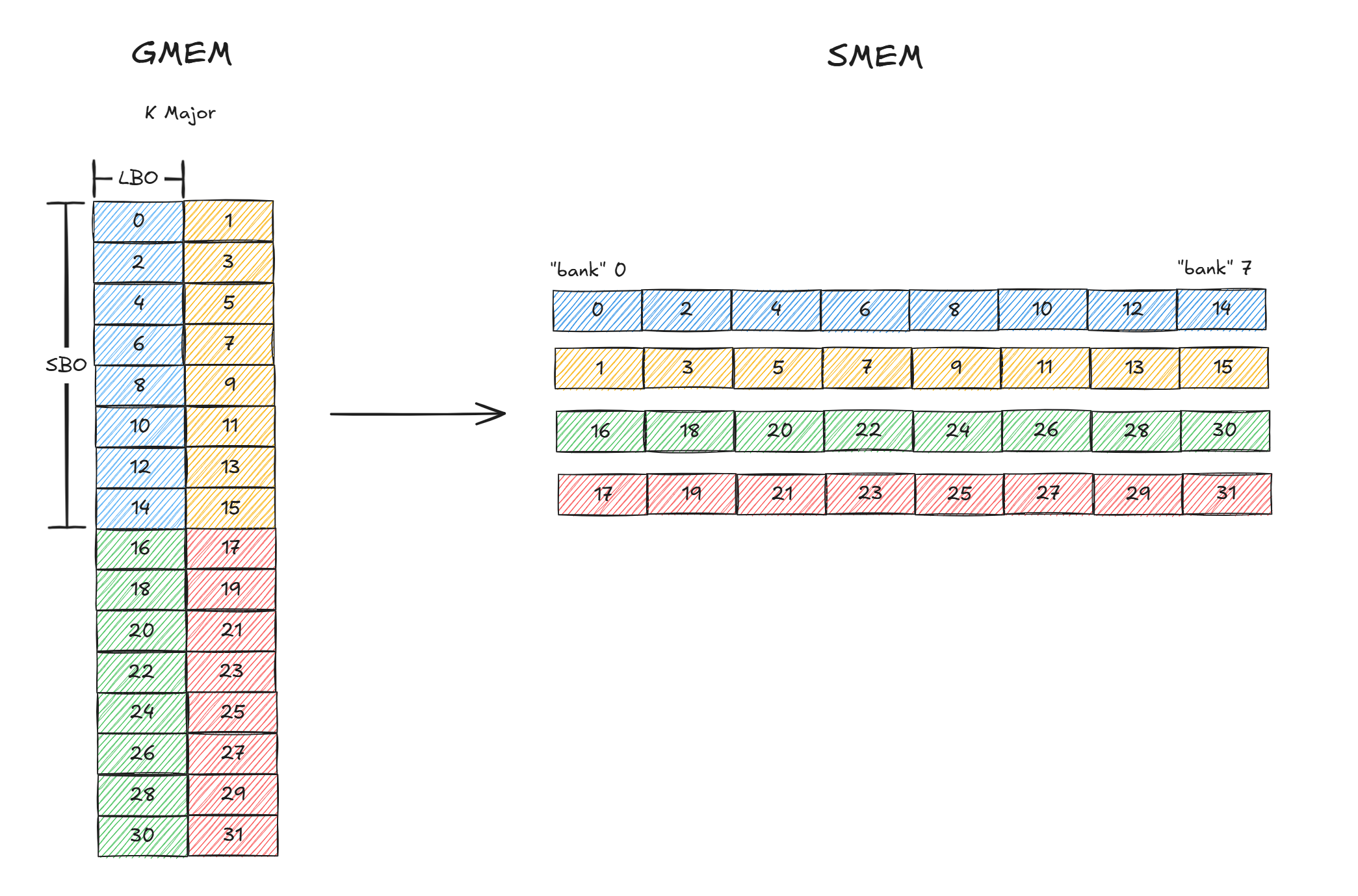
图 9
如图9所示,这里只展示了16x16,一个框代表16B,假设叫一个slot,slot中的数字只是一个标志,不表示在GMEM或SMEM的index,GMEM中为K Major,因此slot0和slot1紧密排列,SMEM中slot0和slot2紧密排列。
每个core matrix内部在SMEM是连续的,那么对于K方向,从core_matrix0(蓝色)到core_matrix1(黄色)的offset为8x8x2B = 128B,因此LBO为128B,对于M方向,从core_matrix0到core_matrix2(绿色)的offset为2x8x8x2B = 256B,因此SBO为256B。从这个结果可以看到,对于每个core matrix的load是不会产生bank冲突的。
但是这里比较歧义,这个叫做SWIZZLE_NONE,但是因为GMEM中为K Major,所以如果直接通过TMA拷贝64x16的话无法做到同一个core matrix在SMEM连续,因此需要4维的TMA进行load,不过这里没有实测过。
SWIZZLE_32B
对于32B的swizzle,在创建cuTensorMapEncodeTiled tensormap的时候需要指定boxDim的dim0最大为32B。
这块是tma的约束,swizzle xxB的模式,就要求最内层不能超过xxB,不过也可以理解,必须先做完一个swizzle atom才能做下一个,方便TMA硬件记录这次最内层循环的拷贝应该如何执行swizzle。
CU_TENSOR_MAP_SWIZZLE_32B requires the bounding box inner dimension to be <= 32.
CU_TENSOR_MAP_SWIZZLE_64B requires the bounding box inner dimension to be <= 64.
CU_TENSOR_MAP_SWIZZLE_128B* require the bounding box inner dimension to be <= 128.
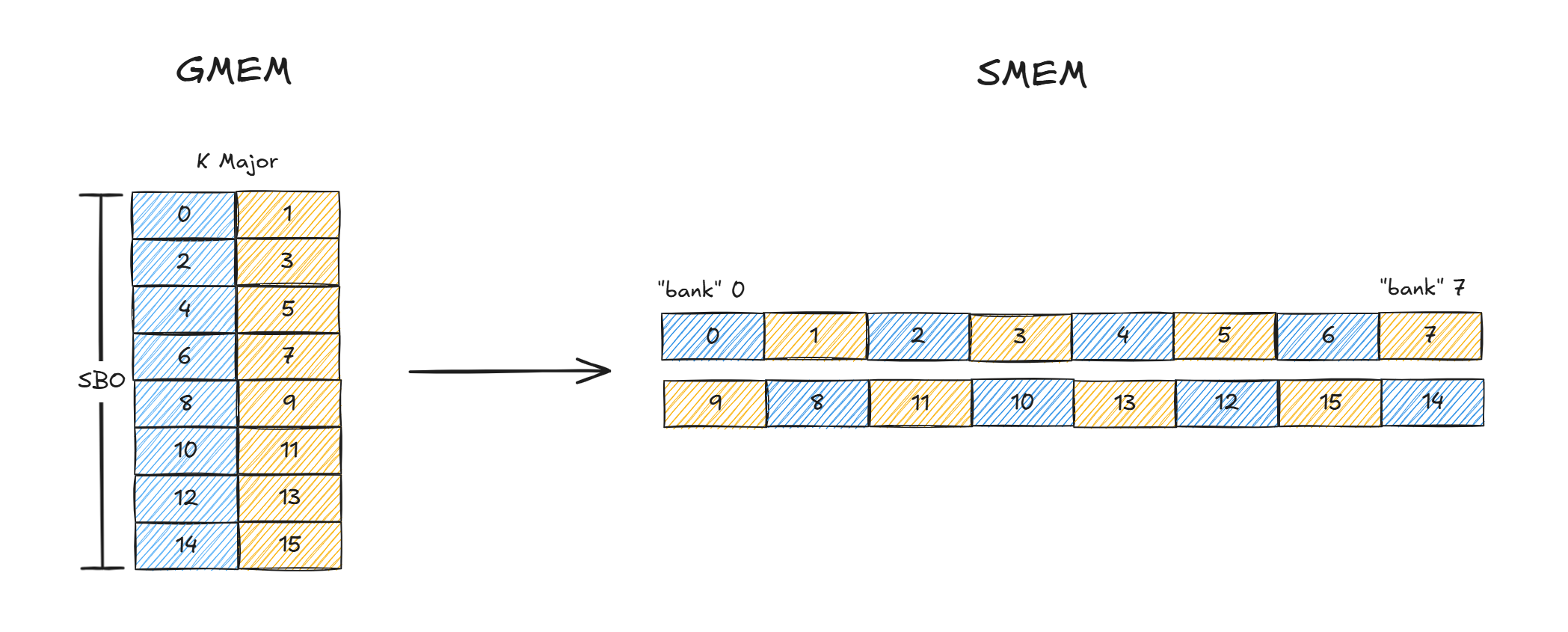
图 10
对于32B swizzle,swizzle atom为8x32B,所以K方向两个core matrix同一行的32B已经被连续存储了,因此LBO始终为1,对于SBO,表示的是第一个8 row到下一个8 row之间的offset,这里的一行就是32B,因此SBO为8 * 32B = 256B。
对于SWIZZLE_32B一次wgmma就可以完成计算,对于两个core matrix的分别load均不会发生bank冲突。
SWIZZLE_64B
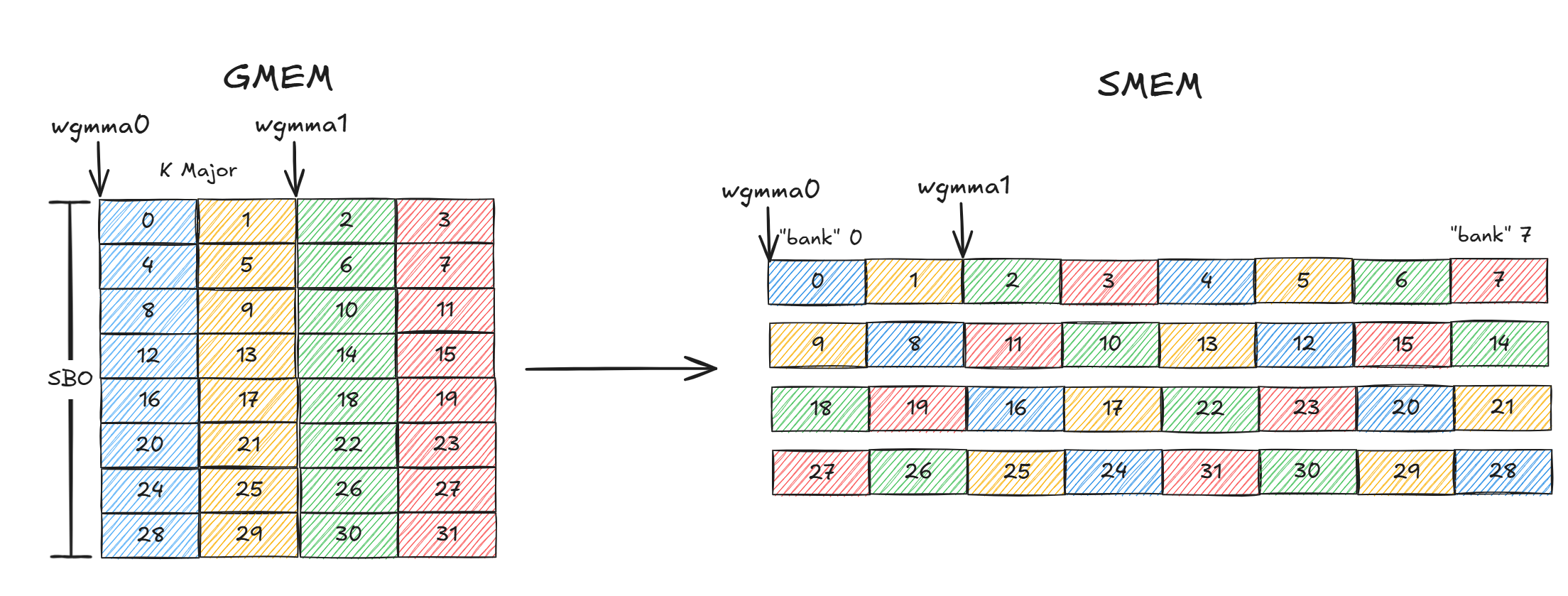
图 11
对于64B的swizzle,在创建cuTensorMapEncodeTiled tensormap的时候需要指定boxDim的dim0为64B。swizzle atom为8x64B,LBO为1,SBO为512B。 值得注意的是此时需要两次wgmma,第一次计算GMEM中wgmma0对应的64x16,第二次计算GMEM中的wgmm1对应的64x16
SWIZZLE_128B
SWIZZLE_128B的LBO为1,SBO为1024B,需要执行4次wgmma,不再赘述。
后续所有kernel大体框架都是图12所示,一个block执行C矩阵的一个BM x BN tile,为了计算tileC,会遍历A的K方向,每次大小BM x BK,同理对B。
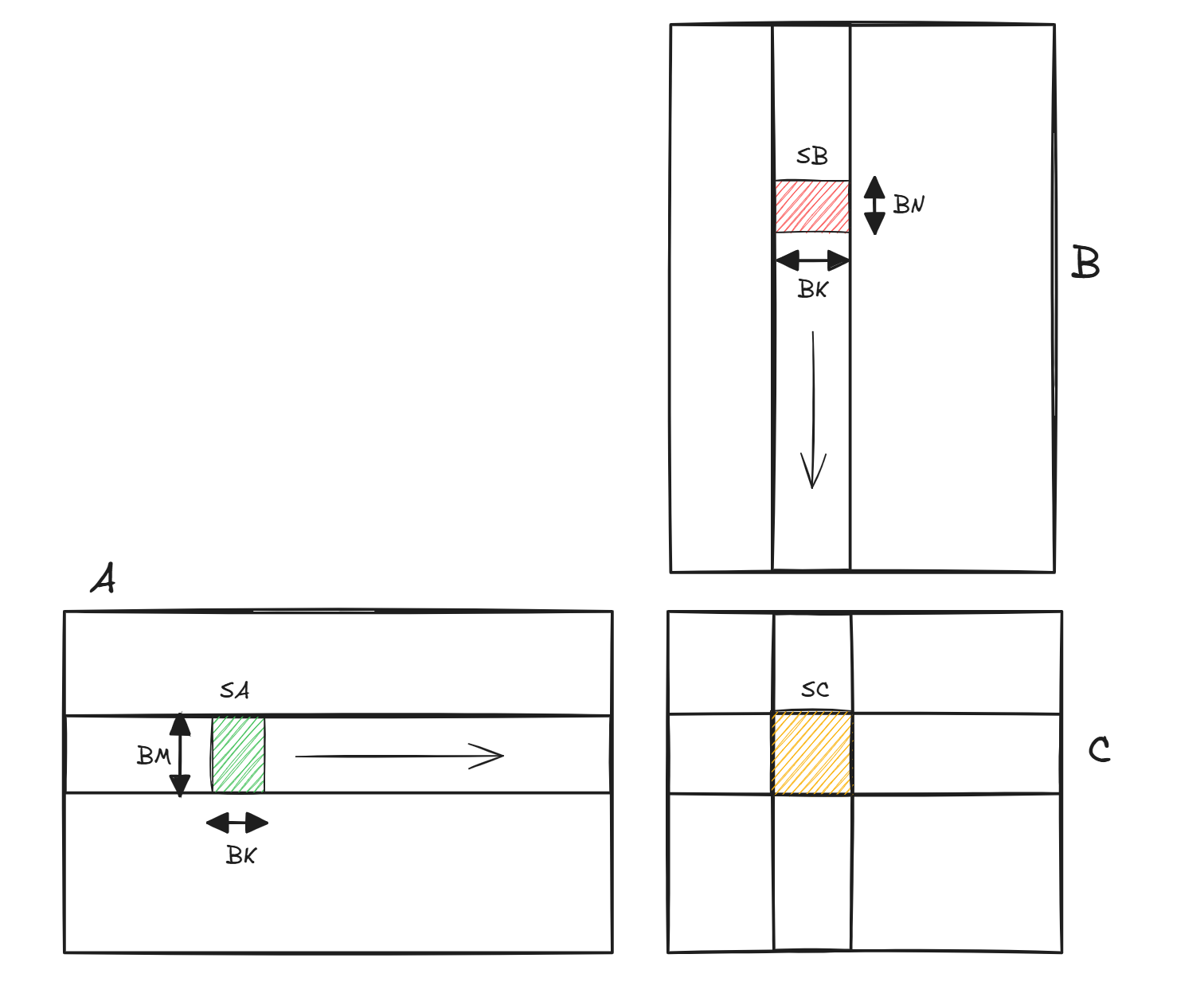
图 12
V2 - 使用TensorCore
v1基于cuda thread,先忽略不看。v2引入了TensorCore。
cpp
void runKernel2(int M, int N, int K, bf16 *A, bf16 *B, bf16 *C) {
constexpr int BM = 64;
constexpr int BN = 64;
constexpr int BK = 64;
constexpr int NUM_THREADS = 128;
if (!d_tma_map_A) {
d_tma_map_A = allocate_and_create_tensor_map<BM, BK>(A, M / BM, K / BK);
d_tma_map_B = allocate_and_create_tensor_map<BN, BK>(B, N / BN, K / BK);
_prev_m = M;
_prev_n = N;
_prev_k = K;
}
matmulKernel2<
/*BM*/ BM,
/*BN*/ BN,
/*BK*/ BK,
/*WGMMA_M*/ 64,
/*WGMMA_N*/ 64,
/*WGMMA_K*/ 16,
/*NUM_THREADS*/ NUM_THREADS>
<<<(M/BM) * (N/BN), NUM_THREADS>>>(M, N, K, C, d_tma_map_A, d_tma_map_B);
}BM,BN,BK表示blcok tile的大小,如SA为BM x BK。NUM_THREADS为一个block线程数量,正好一个warpgroup。wgmma用的是M64N64K16。
cpp
template <int BlockMajorSize, int BlockMinorSize>
__host__ static inline CUtensorMap* allocate_and_create_tensor_map(bf16* src, int blocks_height, int blocks_width) {
CUtensorMap *tma_map_d;
cudaMalloc(&tma_map_d, sizeof(CUtensorMap));
CUtensorMap tma_map_host;
create_tensor_map<BlockMajorSize, BlockMinorSize>(&tma_map_host, src, blocks_height, blocks_width);
cudaMemcpy(tma_map_d, &tma_map_host, sizeof(CUtensorMap), cudaMemcpyHostToDevice);
return tma_map_d;
}然后通过allocate_and_create_tensor_map创建tensorMap。对于A矩阵,blocks_height表示M方向有几个tile,blocks_width表示K方向有几个tile,BlockMajorSize表示M方向tile的大小,BlockMinorSize表示K方向tile大小,然后通过create_tensor_map创建tensorMap,最后拷贝到device。
cpp
template <int BlockMajorSize, int BlockMinorSize>
void create_tensor_map(CUtensorMap *tma_map, bf16* gmem_ptr, int blocks_height, int blocks_width) {
void* gmem_address = (void*)gmem_ptr;
uint64_t gmem_prob_shape[5] = {(uint64_t)BlockMinorSize*blocks_width, (uint64_t)BlockMajorSize*blocks_height, 1, 1, 1};
uint64_t gmem_prob_stride[5] = {sizeof(bf16), sizeof(bf16) * BlockMinorSize*blocks_width, 0, 0, 0};
uint32_t smem_box_shape[5] = {uint32_t(BlockMinorSize), uint32_t(BlockMajorSize), 1, 1, 1};
uint32_t smem_box_stride[5] = {1, 1, 1, 1, 1};
CUresult result = cuTensorMapEncodeTiled(
tma_map, CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, 2, gmem_address, gmem_prob_shape,
gmem_prob_stride + 1, smem_box_shape, smem_box_stride, CU_TENSOR_MAP_INTERLEAVE_NONE,
CU_TENSOR_MAP_SWIZZLE_128B, CU_TENSOR_MAP_L2_PROMOTION_NONE, CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
}由于A为K Major,因此对于shape,先要写K方向,就是BlockMinorSize*blocks_width,stride只需要填K方向字节数,boxDim为BK x BM。
cpp
_global__ void __launch_bounds__(NUM_THREADS) matmulKernel2(int M, int N, int K, bf16* C, const CUtensorMap* tensorMapA, const CUtensorMap* tensorMapB) {
__shared__ alignas(128) bf16 sA[BM*BK];
__shared__ alignas(128) bf16 sB[BK*BN];
float d[WGMMA_N/16][8];
memset(d, 0, sizeof(d));
const int num_blocks_k = K / BK;
int num_block_n = blockIdx.x % (N / BN);
int num_block_m = blockIdx.x / (N / BN);
__shared__ barrier barA;
__shared__ barrier barB;
if (threadIdx.x == 0) {
init(&barA, blockDim.x);
init(&barB, blockDim.x);
cde::fence_proxy_async_shared_cta();
}
__syncthreads();
}SA和SB用于保存A和B tile,d用于保存wgmma的输出寄存器,累加类型为float。num_block_m和num_block_n为C矩阵的coord,当前的block会处理这个tileC,然后创建barA和barB两个mbarrier,分别用于同步A和B的TMA,然后执行fence_proxy。
cpp
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter) {
// Load
if (threadIdx.x == 0) {
cde::cp_async_bulk_tensor_2d_global_to_shared(&sA[0], tensorMapA, block_k_iter*BK, num_block_m*BM, barA);
tokenA = cuda::device::barrier_arrive_tx(barA, 1, sizeof(sA));
cde::cp_async_bulk_tensor_2d_global_to_shared(&sB[0], tensorMapB, block_k_iter*BK, num_block_n*BN, barB);
tokenB = cuda::device::barrier_arrive_tx(barB, 1, sizeof(sB));
} else {
tokenA = barA.arrive();
tokenB = barB.arrive();
}
barA.wait(std::move(tokenA));
barB.wait(std::move(tokenB));
__syncthreads();
// Compute
warpgroup_arrive();
wgmma64<1, 1, 1, 0, 0>(d, &sA[0], &sB[0]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[WGMMA_K], &sB[WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[2*WGMMA_K], &sB[2*WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[3*WGMMA_K], &sB[3*WGMMA_K]);
warpgroup_commit_batch();
warpgroup_wait<0>();
}block_k_iter为图12中K方向的遍历次数,对于每次循环,thread0执行TMA,通过对应的tensorMap将对应的tile拷贝到SMEM,warpgroup_arrive就是wgmma.fence,warpgroup_commit_batch为wgmma.commit_group,warpgroup_wait为wgmma.wait_group,等待所有wgmma group完成,wgmma64就是执行一个M64N64K16的wgmma。
cpp
template<int ScaleD, int ScaleA, int ScaleB, int TransA, int TransB>
__device__ void wgmma64(float d[4][8], bf16* sA, bf16* sB) {
uint64_t desc_a = make_smem_desc(&sA[0]);
uint64_t desc_b = make_smem_desc(&sB[0]);
asm volatile(
"{\n"
"wgmma.mma_async.sync.aligned.m64n64k16.f32.bf16.bf16 "
"{%0, %1, %2, %3, %4, %5, %6, %7, "
" %8, %9, %10, %11, %12, %13, %14, %15, "
" %16, %17, %18, %19, %20, %21, %22, %23, "
" %24, %25, %26, %27, %28, %29, %30, %31},"
" %32,"
" %33,"
" %34, %35, %36, %37, %38;\n"
"}\n"
: "+f"(d[0][0]), "+f"(d[0][1]), "+f"(d[0][2]), "+f"(d[0][3]), "+f"(d[0][4]), "+f"(d[0][5]),
"+f"(d[0][6]), "+f"(d[0][7]), "+f"(d[1][0]), "+f"(d[1][1]), "+f"(d[1][2]), "+f"(d[1][3]),
"+f"(d[1][4]), "+f"(d[1][5]), "+f"(d[1][6]), "+f"(d[1][7]), "+f"(d[2][0]), "+f"(d[2][1]),
"+f"(d[2][2]), "+f"(d[2][3]), "+f"(d[2][4]), "+f"(d[2][5]), "+f"(d[2][6]), "+f"(d[2][7]),
"+f"(d[3][0]), "+f"(d[3][1]), "+f"(d[3][2]), "+f"(d[3][3]), "+f"(d[3][4]), "+f"(d[3][5]),
"+f"(d[3][6]), "+f"(d[3][7])
: "l"(desc_a), "l"(desc_b), "n"(int32_t(ScaleD)), "n"(int32_t(ScaleA)),
"n"(int32_t(ScaleB)), "n"(int32_t(TransA)), "n"(int32_t(TransB)));
}首先通过make_smem_desc创建desc,然后执行wgmma,A和B为bf16,C为float。
cpp
__device__ uint64_t make_smem_desc(bf16* ptr) {
uint32_t addr = static_cast<uint32_t>(__cvta_generic_to_shared(ptr));
uint64_t desc = 0x0000000000000000;
desc |= matrix_descriptor_encode(addr);
desc |= matrix_descriptor_encode((uint64_t)16) << 16;
desc |= matrix_descriptor_encode((uint64_t)1024) << 32;
desc |= 1llu << 62; // 128B swizzle
return desc;
}LBO为1,即16 >> 4 = 1,由于为SWIZZLE_128,所以SBO为1024。
cpp
int tid = threadIdx.x;
int lane = tid % 32;
int warp = tid / 32;
uint32_t row = warp*16 + lane / 4;
bf16 *block_C = C + num_block_n*BN*M + num_block_m*BM;
for (int m_it = 0; m_it < BM/WGMMA_M; ++m_it) {
for (int n_it = 0; n_it < BN/WGMMA_N; ++n_it) {
for (int w = 0; w < WGMMA_N/16; ++w) {
int col = 16*w + 2*(tid % 4);
#define IDX(i, j) ((j + n_it*WGMMA_N)*M + ((i) + m_it*WGMMA_M))
block_C[IDX(row, col)] = d[w][0];
block_C[IDX(row, col+1)] = d[w][1];
block_C[IDX(row+8, col)] = d[w][2];
block_C[IDX(row+8, col+1)] = d[w][3];
block_C[IDX(row, col+8)] = d[w][4];
block_C[IDX(row, col+9)] = d[w][5];
block_C[IDX(row+8, col+8)] = d[w][6];
block_C[IDX(row+8, col+9)] = d[w][7];
#undef IDX
}
}
}最后将d写回GMEM上的C,block_C为GMEM的对应位置。由于BM == WGMMA_M,BN == WGMMA_N,所以只有最内层循环。最内层循环每次写回的数据如图13所示,就是C矩阵在warpgroup中分布的前16列。warpgroup中warp0负责蓝色,warp1负责黄色,warp2负责绿色,warp3负责红色。对于warp0的T0,d00对应了图中T0:{d0},d01对应图中T0:{d1},然后写回block_C通过IDX算偏移,由于shape为N * M,M Major,因此需要通过IDX函数执行一个转置。写回的时候由fp32转成了bf16。

图 13
V3 - 更大tile
V1中SC的大小为64x64,V2调大了SC的shape为128x128,在M方向循环两次,每次执行4个M64N128K16的wgmma,一次block_k_iter如图14所示。
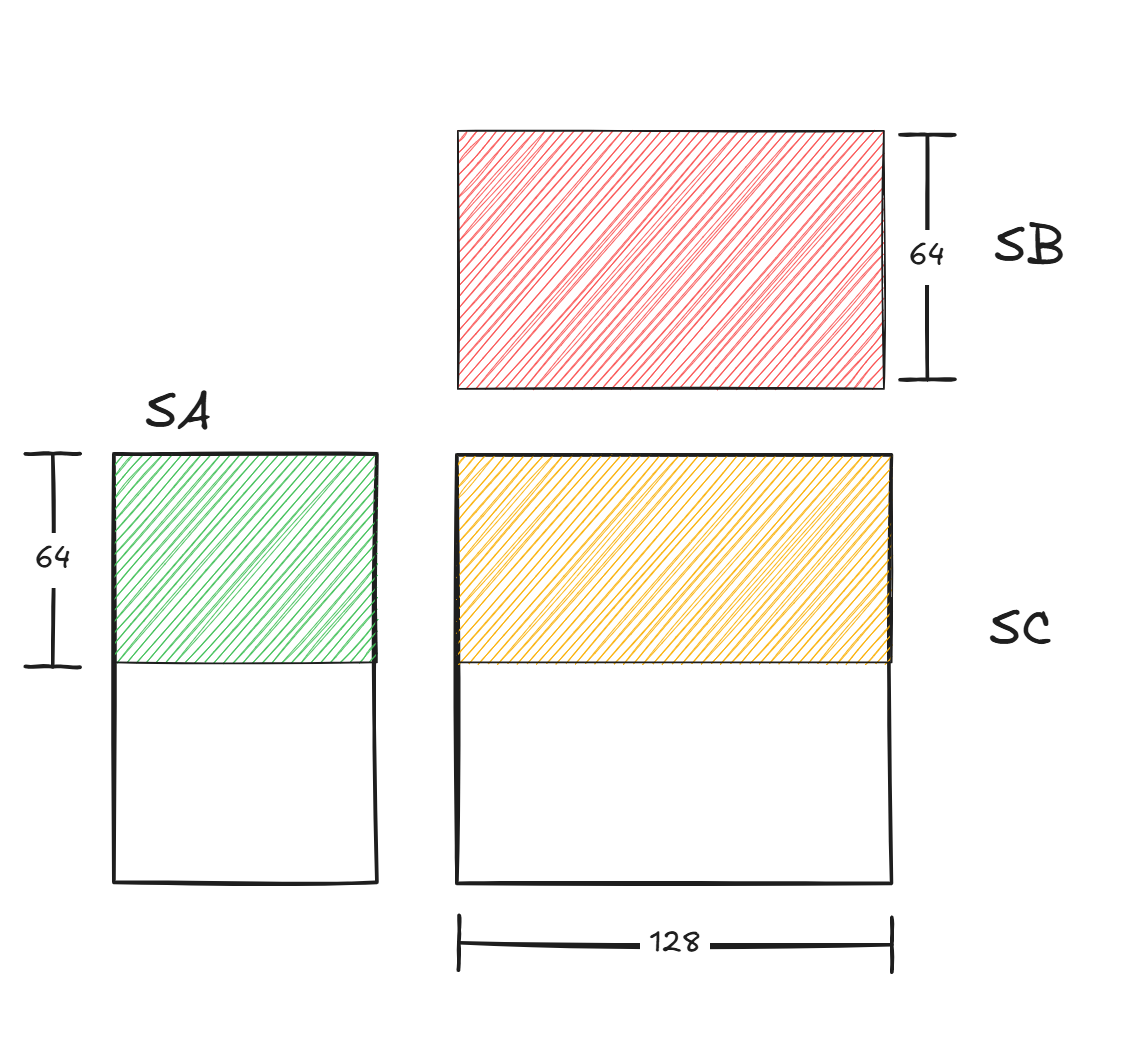
图 14
V4 - Warp Specialization
现有流程中先执行TMA,然后等待TMA结束,再执行wgmma,TMA和wgmma用到的硬件不同,可以并行执行,V4引入生产者消费者模型,一个warpgroup作为生产者,负责通过TMA将数据从GMEM load到SMEM,其他的warpgroup当做消费者,负责执行wgmma,这种生产者消费者模型称为Warp Specialization。为了实现生产者消费者,需要一个SMEM上的FIFO,FIFO中有多个slot用于存储TMA得到的数据。生产者和消费者通过mbarrier数组进行同步,emptyi用于指示sloti是否为空,如果为空则生产者可以向sloti TMA数据,fulli表示sloti是否有数据,如果有数据则消费者可以对这个slot的数据执行wgmma。
图 15
cpp
void runKernel4(int M, int N, int K, bf16 *A, bf16 *B, bf16 *C, int *DB) {
constexpr int BM = 128;
constexpr int BN = 128;
constexpr int BK = 64;
constexpr int NUM_THREADS = 128*2;
constexpr int QSIZE = 5;
}
template <int BM, int BN, int BK, int QSIZE>
struct SMem {
alignas(128) bf16 A[BM*BK*QSIZE];
alignas(128) bf16 B[BK*BN*QSIZE];
};NUM_THREADS由128变成128 * 2,对应两个warpgroup,分别为生产者和消费者,QSIZE为FIFO长度,SMem里的A和B即为FIFO。
cpp
__global__ __launch_bounds__(NUM_THREADS) void matmulKernel4(int M, int N, int K, bf16* C, const CUtensorMap* tensorMapA, const CUtensorMap* tensorMapB) {
constexpr int WGMMA_M = 64, WGMMA_K = 16, WGMMA_N=BN;
constexpr int num_consumers = (NUM_THREADS / 128) - 1;
constexpr int B_WG_M = BM / num_consumers;
extern __shared__ __align__(128) uint8_t smem[];
SMem<BM, BN, BK, QSIZE> &s = *reinterpret_cast<SMem<BM, BN, BK, QSIZE>*>(smem);
bf16 *sA = s.A;
bf16 *sB = s.B;
__shared__ barrier full[QSIZE], empty[QSIZE];
const int num_blocks_k = K / BK;
int num_block_n = blockIdx.x % (N / BN);
int num_block_m = blockIdx.x / (N / BN);
int wg_idx = threadIdx.x / 128;
int tid = threadIdx.x % 128;
if (threadIdx.x == 0) {
for (int i = 0; i < QSIZE; ++i) {
init(&full[i], num_consumers * 128 + 1);
init(&empty[i], num_consumers * 128 + 1);
}
cde::fence_proxy_async_shared_cta();
}
__syncthreads();
...
}num_consumers为1,fullQSIZE,emptyQSIZE就是上述用于同步FIFO的mbarrier,T0负责初始化mbarrier,wg_idx表示第几个warpgroup。
cpp
if (wg_idx == 0) {
if (tid == 0) {
int qidx = 0;
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) qidx = 0;
empty[qidx].wait(empty[qidx].arrive());
cde::cp_async_bulk_tensor_2d_global_to_shared(&sA[qidx*BK*BM], tensorMapA, block_k_iter*BK, num_block_m*BM, full[qidx]);
cde::cp_async_bulk_tensor_2d_global_to_shared(&sB[qidx*BK*BN], tensorMapB, block_k_iter*BK, num_block_n*BN, full[qidx]);
barrier::arrival_token _ = cuda::device::barrier_arrive_tx(full[qidx], 1, (BK*BN+BK*BM)*sizeof(bf16));
}
}
} wg_idx为1的为生产者,生产者中tid为0的负责执行TMA。qidx表示执行了几个tile,初始化为0,首先需要在emptyqidx执行wait,等待消费者完成slotqidx数据的计算并执行arrive,当这个slot为空之后执行TMA load。
cpp
else {
for (int i = 0; i < QSIZE; ++i) {
barrier::arrival_token _ = empty[i].arrive();
}
int qidx = 0;
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) qidx = 0;
full[qidx].wait(full[qidx].arrive());
warpgroup_arrive();
wgmma();
warpgroup_commit_batch();
warpgroup_wait<0>();
barrier::arrival_token _ = empty[qidx].arrive();
}
}对于消费者,首先对所有的emptyi执行arrive,初始化FIFO为空,然后每次对fulli进行wait直到TMA load完成,然后执行wgmma。
V5 - 更大的tile
现在使用的tileC为128x128,尝试调大shape,使用128x256的大小,这样可以利用到wgmma的最大N。
但是直接调大会触发寄存器的上线,tileC大小为128x256,总寄存器数量为32768,每个SM的32位寄存器上线是65536个,这个并没有超,但是每个线程使用了128 * 256 / 128(thread) = 256个寄存器,超过了每个线程最多使用寄存器的上线255。
单线程寄存器数量超限制,但是总寄存器数量没有超限制,所以可以尝试调大线程数,使用两个warpgroup作为consumer,如图16所示:
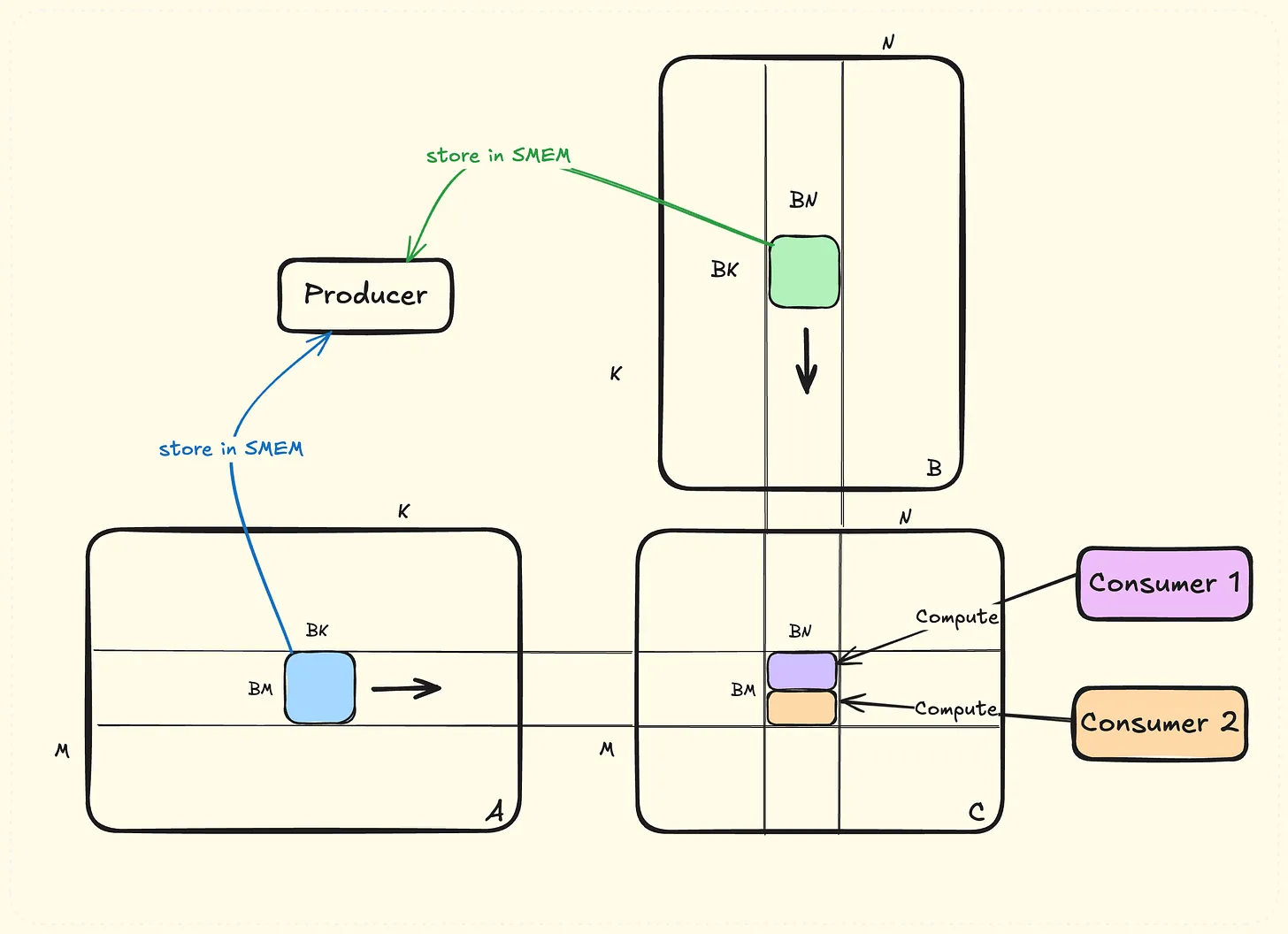
图 16
每个consumer对应的tileC为128x256,TMA一次load蓝色tileA和绿色tileB,两个consumer都要等待这两个TMA load完成,然后计算自己负责的数据。 进一步的,由于producer只是执行TMA,并不需要大量的寄存器,但是编译器默认为每个thread分配了相同的寄存器,可以通过setmaxnreg将producer的寄存器调小,将consumer的寄存器调大,总数维持不变,调整寄存器之后性能由610TFLOPS提升到631TFLOPS,作者猜测收益可能来自减小了寄存器的bank冲突。
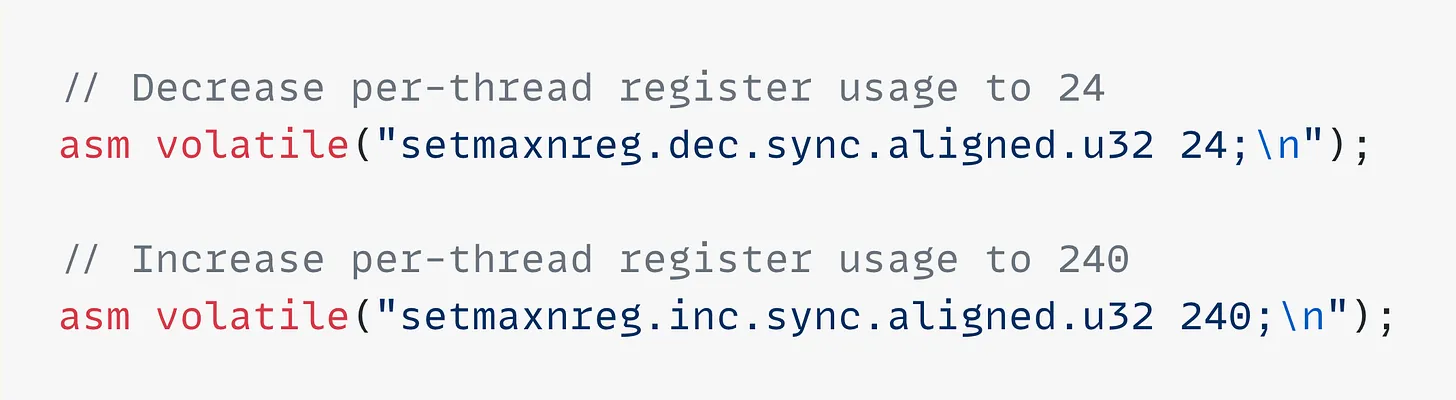
图 17
V6 - 隐藏写延迟
如图18所示,V5版本中一个block处理BM x BN的tileC,一共启动了(M/BM) * (N/BN)个block,当总block数量超过SM数量的时候,会通过wave进行调度,那么观察一个SM上某一个block的执行,当这个block处理完所有的wgmma之后会写回SC到GMEM,然后block执行完成,SM调度执行下一个block。因此V6的想法是尝试隐藏SC写GMEM的延迟。
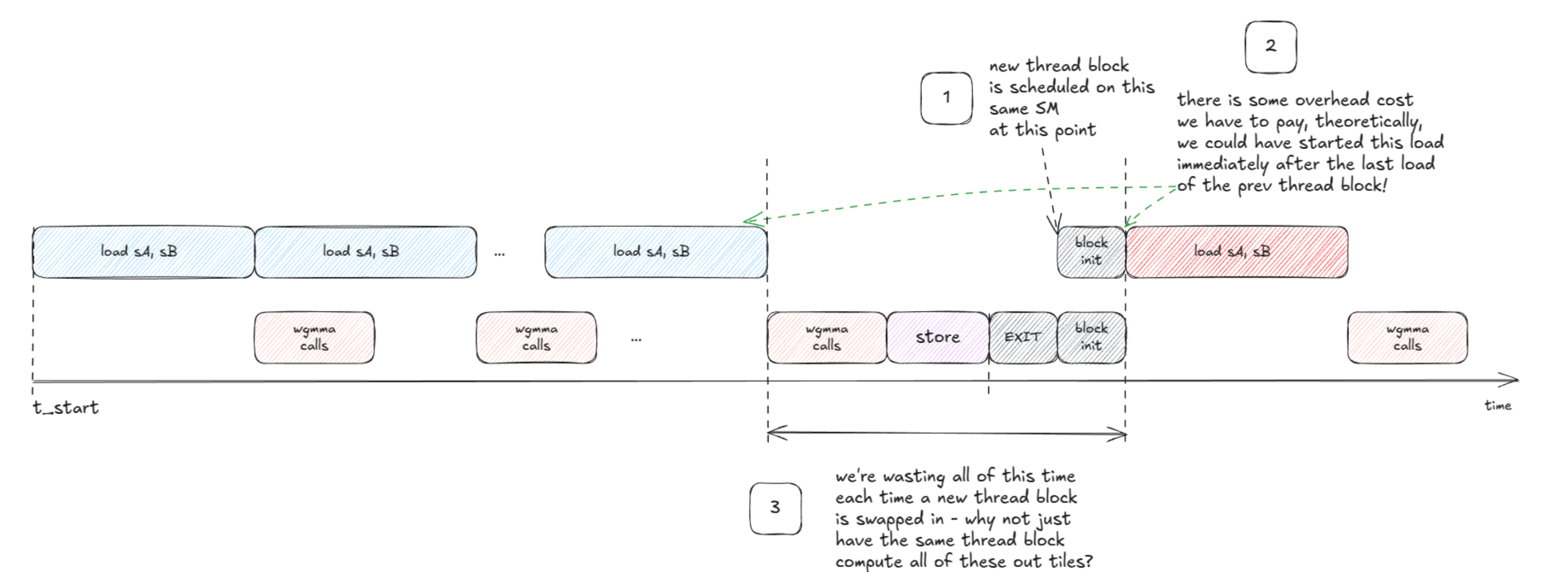
图 18
这里的想法就是使用persistent kernel,launch固定数量的block数,一般等于SM数量,每个block计算多个tileC,当consumer执行前一个tileC回写GMEM的时候,producer已经开始TMA下一个tileC对应的TMA load了(tileA和tileB)。
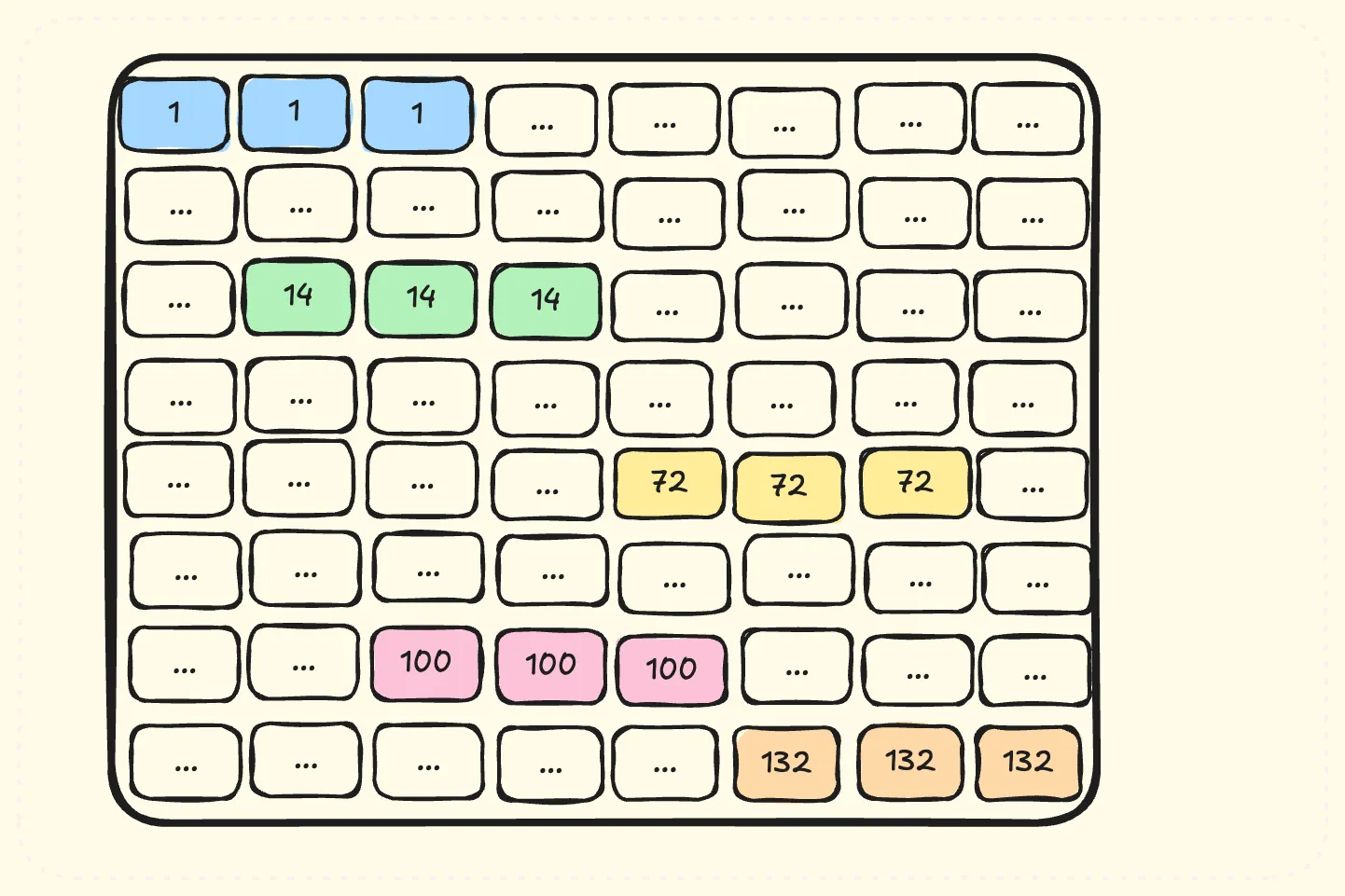
图 19
但是按照图19的调度顺序,每个SM处理连续的tileC,比如第一个SM按照顺序处理蓝色的tileC,性能回退到400TFLOPS。分析每个SM第一次处理的tileC,如图20所示
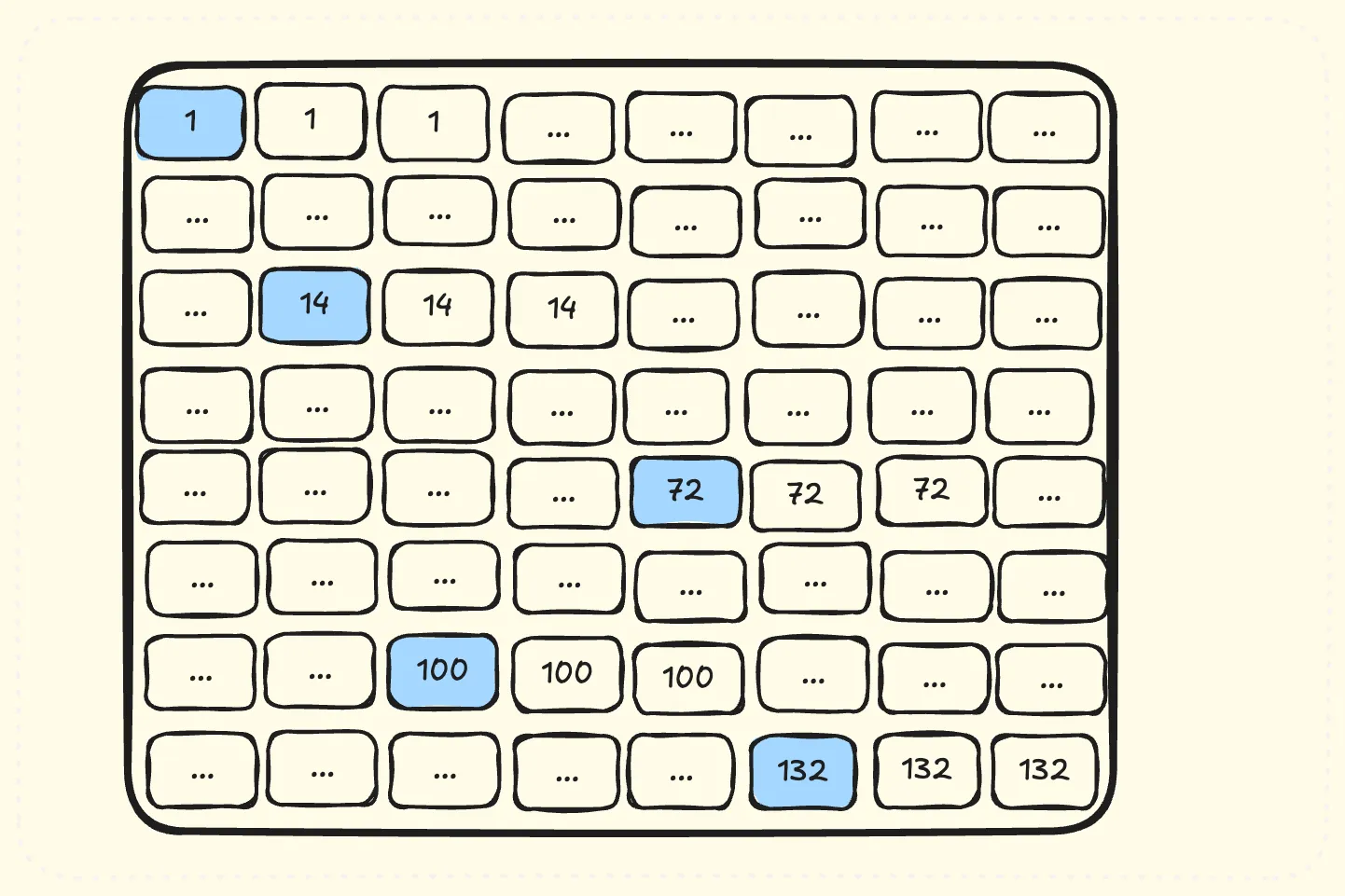
图 20
蓝色tileC是所有SM同时处理的部分,这些tileC对应了几乎全量的A和B矩阵,Hopper的L2大小为50M,当AB大于50M的时候,会导致L2 cache频繁换入换出导致性能下降。 因此V6调整调度顺序如图21所示,保证较高的L2 cache命中率。

图 21
cpp
__global__ ...void matmulKernel6(...) {
Schedule<1, NUM_SM, BM, BN, 16, 8> schedule(M, N, blockIdx.x);
if (wg_idx == 0) {
if (tid == 0) {
for (int num_block = schedule.next(); num_block >= 0; num_block = schedule.next()) {
}
}
}
}V6使用128个SM,TM为16,TN为8,表示第一次所有SM处理的C的tile组,如图21的蓝色区域。
M和N表示C的shape,total_blocks_m和total_blocks_n表示M方向和N方向上tileC的个数,it初始化为0,表示第几次调度,it为0对应图21的蓝色,1对应绿色。_block为blockid。
cpp
template<int NUM_SM, int BM, int BN, int TM, int TN>
struct Schedule<1, NUM_SM, BM, BN, TM, TN> {
int block;
int it;
int total_blocks_m;
int total_blocks_n;
__device__ __forceinline__ Schedule(int M, int N, int _block) {
block = _block;
it = 0;
total_blocks_m = M/BM;
total_blocks_n = N/BN;
assert(total_blocks_m%TM == 0 && total_blocks_n%TN == 0);
}
__device__ __forceinline__ int next() {
int num = it*NUM_SM + block;
if (num >= total_blocks_m*total_blocks_n) return -1;
int cur_tile = num / (TM*TN);
int cur_tile_pos = num % (TM*TN);
int m = TM*(cur_tile / (total_blocks_n/TN));
int n = TN*(cur_tile % (total_blocks_n/TN));
m += cur_tile_pos / TN;
n += cur_tile_pos % TN;
++it;
return m*total_blocks_n + n;
}
};在next函数中,这里的tile指的是一次所有SM处理的C的tile组,num为逻辑tileC,首先计算是第几个tile组,即cur_tile,然后计算在tile组中的偏移cur_tile_pos,cur_tile / (total_blocks_n/TN)为当前tile组的M维度坐标,乘以TM得到当前tile组起始tileC的M坐标,再加上tile组内偏移就得到了全局坐标。
V7 - PTX Barrier
V6中用的mbarrier接口还是cuda barrier api,wait的接口需要传入token,token来自arrive的返回值,因此要求所有执行wait的线程首先需要执行arrive,造成了额外的同步开销,因此尝试使用PTX barrier。PTX barrier的使用在之前DeepEP中介绍过,这里不再赘述。
v8 - Thread Block Clusters
Hopper架构在block的基础上增加了cluster的编程概念,一个cluster包含多个block,保证同时调度执行,cluster之间可以进行同步和通信。物理上一个H100 GPU包含8个GPC,一个GPC有16个SM,cluster中的block就是会在一个GPC内部调度执行。如图22所示,在cluster内部,SMEM之间增加了SM to SM Network,那么cluster内部所有block对应的SMEM集合称为distributed shared memory(DSMEM),cluster中的所有block共享同一个SMEM虚拟地址空间,因此每个线程都可以通过简单的load,store指令访问DSMEM。
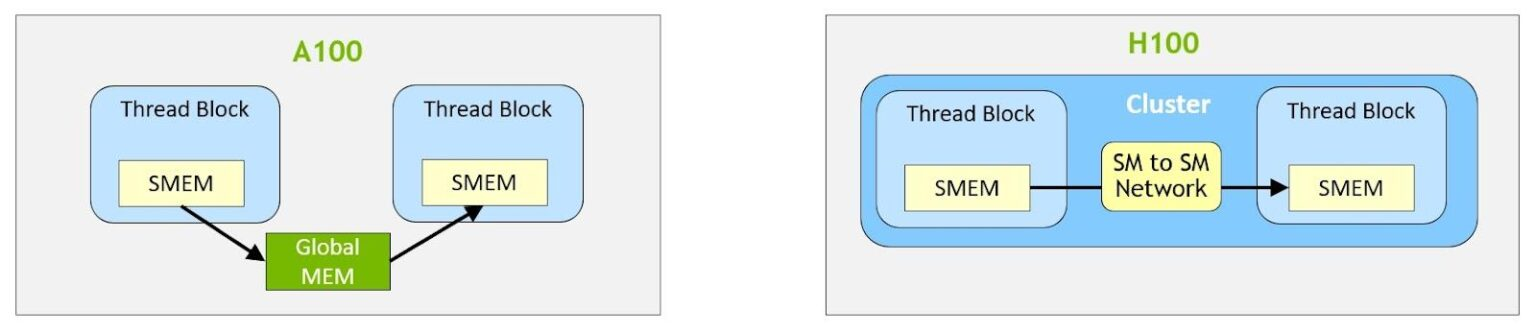
图 22
如图23所示,可以利用cluster进行访存优化,两个紫色分别对应了cluster中的两个block,他们需要不同的SA,但是SB相同,因此,可以使用TMA的multicast机制只load一次SB,广播给所有cluster内部的block。
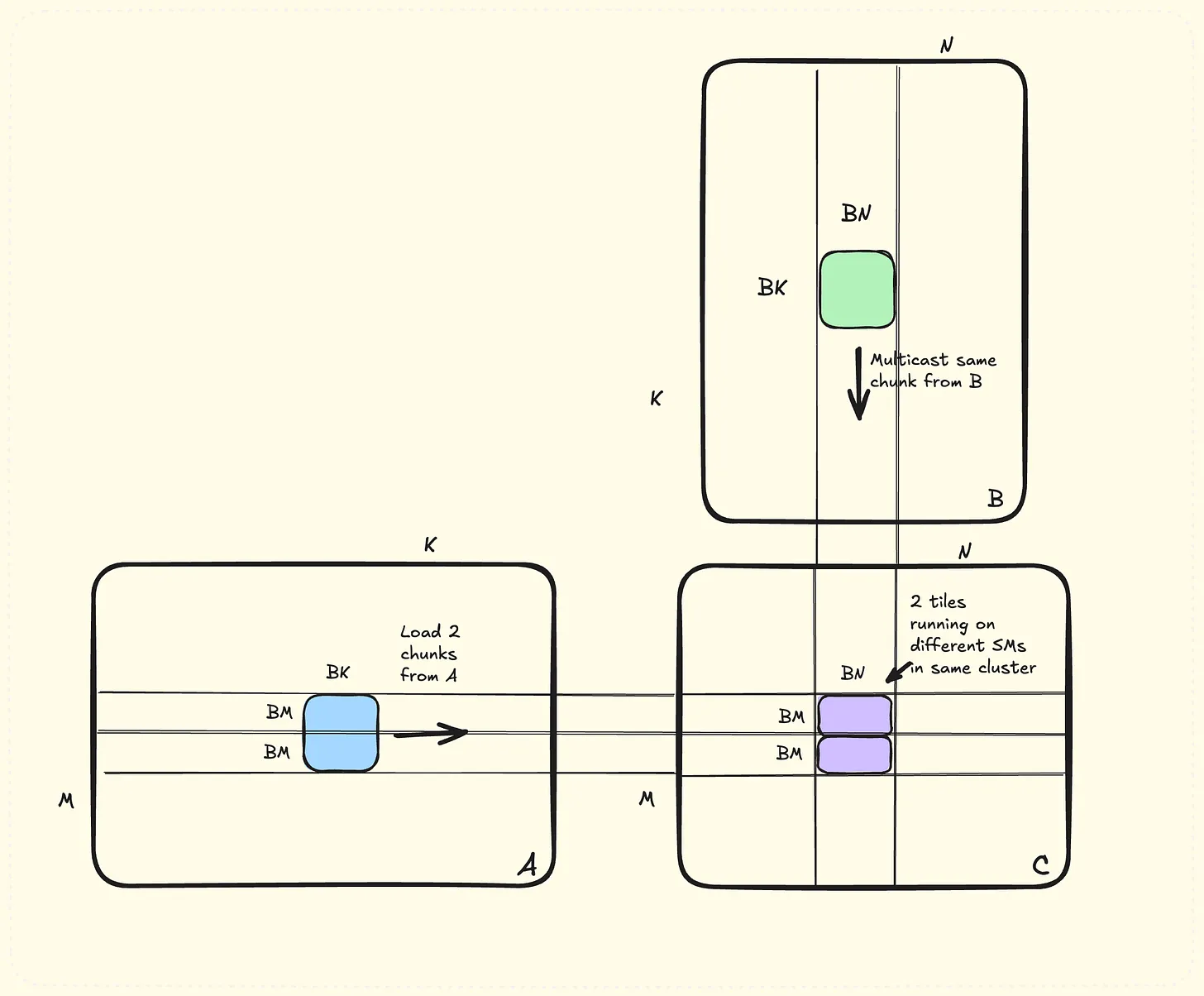
图 23
```cpp /* constexpr int CLUSTER_M = 2; constexpr int CLUSTER_N = 1; constexpr int NUM_SM = 128; */ template
cpp
__global__ matmulKernel8(...) {
asm volatile("mov.u32 %0, %cluster_ctarank;\n" : "=r"(rank) :);
uint32_t rank_m = rank / CLUSTER_N;
uint32_t rank_n = rank % CLUSTER_N;
if (wg_idx == 0) {
if (tid == 0) {
int p = 0;
int qidx = 0;
uint32_t col_mask = 0;
for (int i = 0; i < CLUSTER_M; ++i) {
col_mask |= (1 << (i * CLUSTER_N));
}
int num_block_m, num_block_n;
while (schedule.next(num_block_m, num_block_n)) {
num_block_n = num_block_n * CLUSTER_N + rank_n;
num_block_m = num_block_m * CLUSTER_M + rank_m;
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) { qidx = 0; p ^= 1;}
wait(&empty[qidx], p);
expect_bytes(&full[qidx], (BK*BN+BK*BM)*sizeof(bf16));
load_async(&sA[qidx*BK*BM], &tensorMapA, &full[qidx], block_k_iter*BK, num_block_m*BM);
if (rank_m == 0) {
load_async_multicast(&sB[qidx*BK*BN], &tensorMapB, &full[qidx], block_k_iter*BK, num_block_n*BN, col_mask << rank_n);
}
}
}
}
}
}cluster_ctarank就是当前blcok在cluster内部的标号,然后通过cluster_ctarank计算出cluster内部坐标rank_m和rank_n;然后设置col_mask,由于是共享B,因此col_mask需要设置成rank_n相同的block,但是这里cluster dim为2x1,因此就是所有的block。p就是mbarrier的parity phase,然后wait当前slot的mbarrier,TMA load SA,rank_m为0的block执行TMA multicast load SB。
cpp
__device__ static inline void load_async_multicast(bf16 *dst, void const* const src_tma_map, uint64_t* bar, int global_col_idx, int global_row_idx, uint16_t cluster_mask) {
uint64_t tma_ptr = reinterpret_cast<uint64_t>(src_tma_map);
uint32_t mbar_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(bar));
uint32_t dst_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(dst));
asm volatile (
"cp.async.bulk.tensor.3d.shared::cluster.global.tile.mbarrier::complete_tx::bytes.multicast::cluster"
" [%0], [%1, {%3, %4, %5}], [%2], %6;"
:
: "r"(dst_ptr), "l"(tma_ptr), "r"(mbar_ptr),
"n"(0), "r"(global_row_idx), "r"(global_col_idx/64), "h"(cluster_mask)
: "memory"
);
}load_async_multicast用于TMA load数据到SMEM中的dst,并广播到cluster中所有block的dst位置。
PTX如下:
cpp
// global -> shared::cluster
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.multicast}{.cta_group}{.level::cache_hint}
[dstMem], [tensorMap, tensorCoords], [mbar]{, im2colInfo}
{, ctaMask} {, cache-policy}
.dst = { .shared::cluster }
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.cta_group = { .cta_group::1, .cta_group::2 }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
.multicast = { .multicast::cluster }cluster_mask是一个16位的mask,一位代表一个block,即cluster_ctarank,表示广播到cluster中的哪些block,multicast::cluster就表示广播,源数据将被广播到到每个目标block的SMEM中与dst偏移量相同的地址处,即所有block的dst。cta_group默认为1,表示mbarrier的信号也会被广播到所有block的SMEM中与mbar偏移量相同的地址处,即通知所有的mbarrier。
cpp
__global__ matmulKernel8(...) {
// consumer
else {
for (int qidx = 0; qidx < QSIZE; ++qidx) {
if (tid < CLUSTERS) arrive_cluster(&empty[qidx], tid);
}
}
}然后看consumer,首先初始化mbarrier表示一开始所有slot都可用,这里需要arrive每个block对应的mbarrier,因为这块数据是所有block共享的,需要等所有block都计算完成。
cpp
__device__ void arrive_cluster(uint64_t* bar, uint32_t cta_id, uint32_t count=1) {
uint32_t smem_addr = static_cast<uint32_t>(__cvta_generic_to_shared(bar));
asm volatile(
"{\n\t"
".reg .b32 remAddr32;\n\t"
"mapa.shared::cluster.u32 remAddr32, %0, %1;\n\t"
"mbarrier.arrive.shared::cluster.b64 _, [remAddr32], %2;\n\t"
"}"
:
: "r"(smem_addr), "r"(cta_id), "r"(count));
}对于arrive_cluster,首先需要获取其他block的bar地址,这里是通过mapa实现的,mapa会计算出当前block访问cluster中第cta_id个block的和bar偏移相同的地址,保存到remAddr32,这个过程有点像nvshmem的逻辑,知道每个block SMEM的起始地址,然后通过自己的地址bar的偏移,计算出其他block中对应的bar的地址。
cpp
__global__ matmulKernel8(...) {
// consumer
while (schedule.next(num_block_m, num_block_n)) {
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) {qidx = 0; p ^= 1; };
wait(&full[qidx], p);
do_wgmma();
if (tid < CLUSTERS) arrive_cluster(&empty[qidx], tid);
}
}
}然后开始循环执行计算,首先通过wait full等待TMA对SA和SB的执行完成,然后执行wgmma,最后arrive_cluster通知所有block。
V9 细致优化
cpp
__global__ __launch_bounds__(NUM_THREADS) void __cluster_dims__(CLUSTER_M * CLUSTER_N, 1, 1) matmulKernel9(...) {
for (int m_it = 0; m_it < B_WG_M/WGMMA_M; ++m_it) {
int yo = m_it*WGMMA_M + wg_idx*B_WG_M;
if (row + 8 + yo + num_block_m*BM >= M) continue;
for (int w = 0; w < WGMMA_N; w+=16) if (w+num_block_n*BN < N) {
int col = w + 2*(tid % 4);
#define IDX(i, j) ((j)*M + ((i) + yo))
#define ST(i, j, v) __stwt(&block_C[IDX(i, j)], v);
ST(row+8, col, d[m_it][w/16][2]);
ST(row, col, d[m_it][w/16][0]);
...
}
}
}V9做了一些细致的优化,如改变回写顺序,尽量连续访存;st.wt表示通过L2 cache直接写GMEM,消除了写回tileC对cache的使用。
V10 异步store
V10对写回tileC使用TMA,如下所示
cpp
__global__ __launch_bounds__(NUM_THREADS) void __cluster_dims__(CLUSTER_M * CLUSTER_N, 1, 1) matmulKernel10(...) {
asm volatile("cp.async.bulk.wait_group 0;");
int lane = tid % 32, warp = tid / 32;
int row = warp*16 + lane / 4;
bf16* block_sC = sC + wg_idx*B_WG_M*BN;
#pragma unroll
for (int m_it = 0; m_it < B_WG_M/WGMMA_M; ++m_it) {
int yo = m_it*WGMMA_M;
#pragma unroll
for (int w = 0; w < WGMMA_N; w+=16) {
int col = w + 2*(tid % 4);
#define ST(i, j, v) block_sC[(j)*B_WG_M + (i) + yo] = v
ST(row, col, d[m_it][w/16][0]);
ST(row+8, col, d[m_it][w/16][2]);
...
}
}
asm volatile("bar.sync 10, 256;\n");
if (threadIdx.x == 128) {
store_async(&tensorMapC, (bf16*)&sC[0], num_block_m*BM, num_block_n*BN);
asm volatile("cp.async.bulk.commit_group;");
}
}V11 - Hilbert曲线
如图21中,从2到3的过程中其实不是最优的,利用不到任何L2 cache中A或B数据块,更优的是通过2到4。Hilbert曲线就是解决这一问题,可以通过相邻的方式遍历整个矩阵,如图24所示
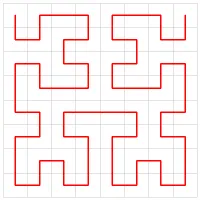
图 24
github中还有V12的优化,通过stmatrix写tileC替代sts指令。 最后贴一个每个版本的性能记录:
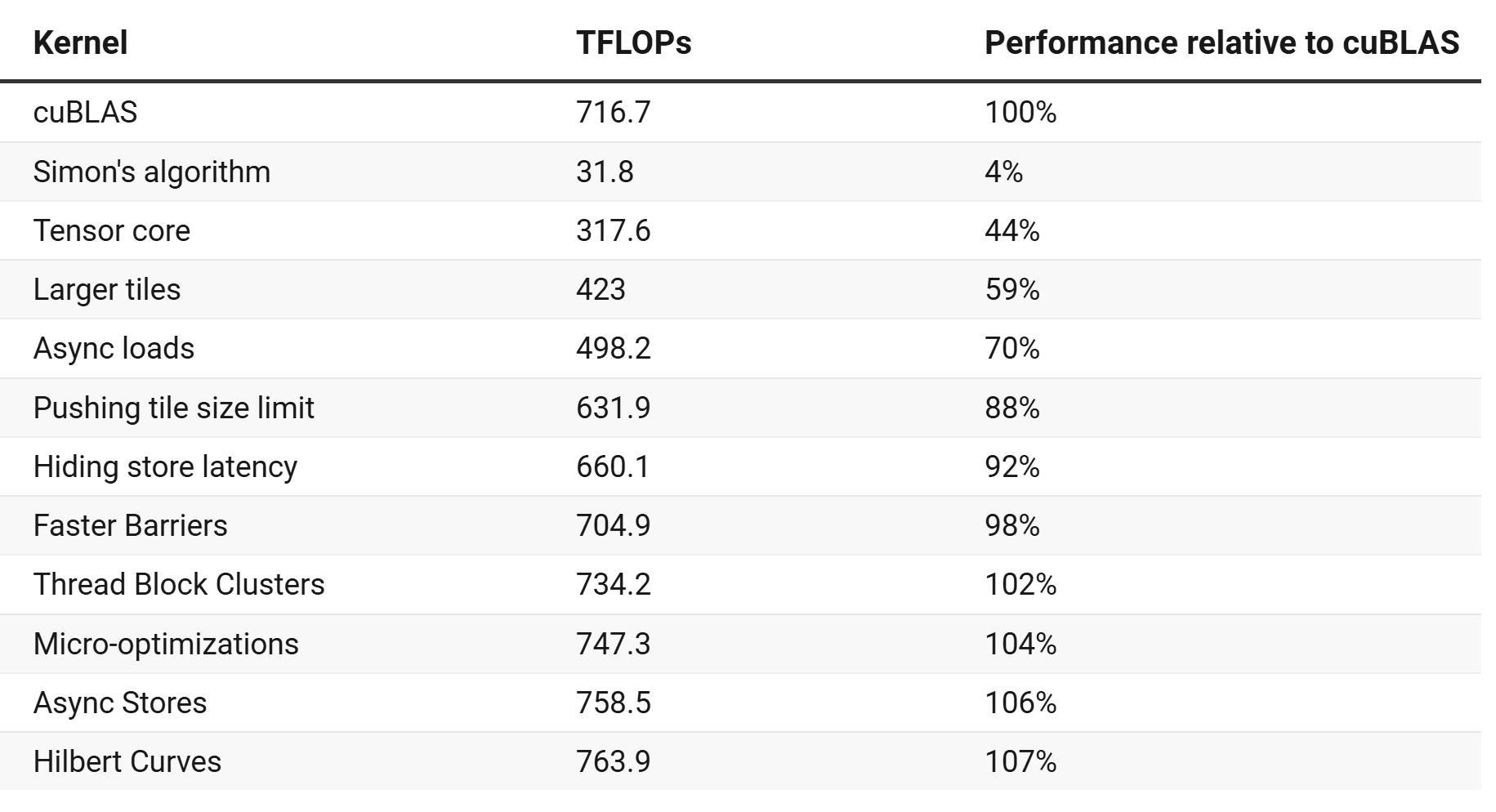
图 25
参考
https://cudaforfun.substack.com/p/outperforming-cublas-on-h100-a-worklog
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth