一个 NVIDIA GPU 芯片由多个 SM 组成。SM 是 GPU 的 "CPU 内核",但专为高度并行计算设计。GPU 的整体并行能力和吞吐量主要取决于其拥有的 SM 数量和每个 SM 的计算能力。
1. SM 的核心功能
SM 的主要任务是执行线程块(Thread Blocks)。CUDA 运行时会将一个 Kernel 启动的 Grid 中的一个或多个线程块调度到一个可用的 SM 上执行。
-
线程调度: SM 内部的 Warp 调度器负责管理和调度 Warp(32 个线程的组)的执行。
-
资源管理: SM 为其上的线程块提供计算核心、缓存、寄存器文件和共享内存等资源。
2. SM 的主要组成部分
一个 SM 是一个自包含的并行处理单元,包含了以下关键组件:
2.1 CUDA 核心 (CUDA Cores)
CUDA 核心是 SM 内部执行浮点和整数指令的基本算术逻辑单元 (ALU)。
-
数量: 每个 SM 包含数百个 CUDA 核心。
-
并行性: 这些核心以 Warp 为单位接收和执行指令。
2.2 Tensor Core (张量核心)
自 Volta 架构引入,Tensor Core 是专为加速深度学习和高性能计算中的矩阵乘法而设计的专用硬件单元。
-
功能: 高效执行低精度(FP16/BF16/INT8)的矩阵乘法累加运算。
-
用途: 显著提高了 GPU 在 AI 训练和推理中的吞吐量。
2.3 寄存器文件 (Register File, RF)
寄存器用于存储线程私有的局部变量,是 SM 中最快的内存资源。
-
特点: 寄存器文件是所有并发线程块共享的有限资源。
-
影响: 如果 Kernel 使用了过多的寄存器,会导致每个 SM 上能运行的线程块数量减少(低占用率),从而影响性能。
2.4 共享内存 (Shared Memory) / L1 缓存
SM 拥有一块快速的片上内存,可以根据配置用于共享内存或 L1 缓存。
-
共享内存: 供同一线程块内的线程进行高速数据交换和重用。
-
L1 缓存: 缓存全局内存的读取数据,以隐藏高延迟。
-
统一结构: 在现代 GPU 架构中,共享内存和 L1 缓存通常共享同一物理资源,开发者可以通过配置来调整两者的分配比例。
2.5 Warp 调度器 (Warp Scheduler)
这是 SM 的"大脑",负责决定下一个要执行指令的 Warp。
-
任务: 持续地监控和选择处于准备就绪状态(即数据已就绪,没有停滞)的 Warp,并将其指令分发给 CUDA 核心和 Tensor Core 执行。
-
隐藏延迟: 通过快速切换和交错执行来自不同 Warp 的指令,调度器可以隐藏因内存访问或指令依赖导致的延迟。
2.6 加载/存储单元 (Load/Store Units)
这些单元负责处理所有对 SM 外部存储器(如全局内存)的数据加载和存储请求。它们是实现内存合并的关键。
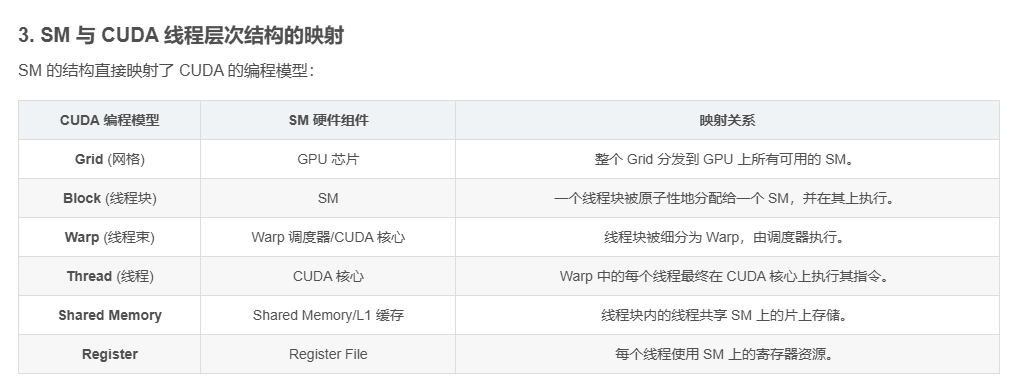
3. SM 与 CUDA 线程层次结构的映射
SM 的结构直接映射了 CUDA 的编程模型:
| CUDA 编程模型 | SM 硬件组件 | 映射关系 |
|---|---|---|
| Grid (网格) | GPU 芯片 | 整个 Grid 分发到 GPU 上所有可用的 SM。 |
| Block (线程块) | SM | 一个线程块被原子性地分配给一个 SM,并在其上执行。 |
| Warp (线程束) | Warp 调度器/CUDA 核心 | 线程块被细分为 Warp,由调度器执行。 |
| Thread (线程) | CUDA 核心 | Warp 中的每个线程最终在 CUDA 核心上执行其指令。 |
| Shared Memory | Shared Memory/L1 缓存 | 线程块内的线程共享 SM 上的片上存储。 |
| Register | Register File | 每个线程使用 SM 上的寄存器资源。 |
4. 占用率(Occupancy):衡量 SM 效率的关键
占用率(Occupancy) 是衡量 SM 利用率的关键指标。
-
定义: 实际活跃的 Warp/线程块数量与 SM 支持的最大 Warp/线程块数量之比。
-
目标: 高占用率确保 SM 上总是有足够多的 Warp 处于就绪状态,从而让 Warp 调度器能够有效地隐藏内存访问延迟。
-
限制因素: 线程块对寄存器和共享内存的需求越高,单个 SM 能容纳的线程块数量就越少,可能导致占用率降低。
总结:
SM 是 NVIDIA GPU 的计算核心,它通过集成大量的并行核心(CUDA Cores, Tensor Cores)和高速片上存储器(共享内存/L1 缓存),并配合高效的 Warp 调度器,实现了 CUDA 程序所需的大规模并行计算能力。理解 SM 的资源限制和调度机制,是编写出能充分利用 GPU 潜力的优化代码的前提。