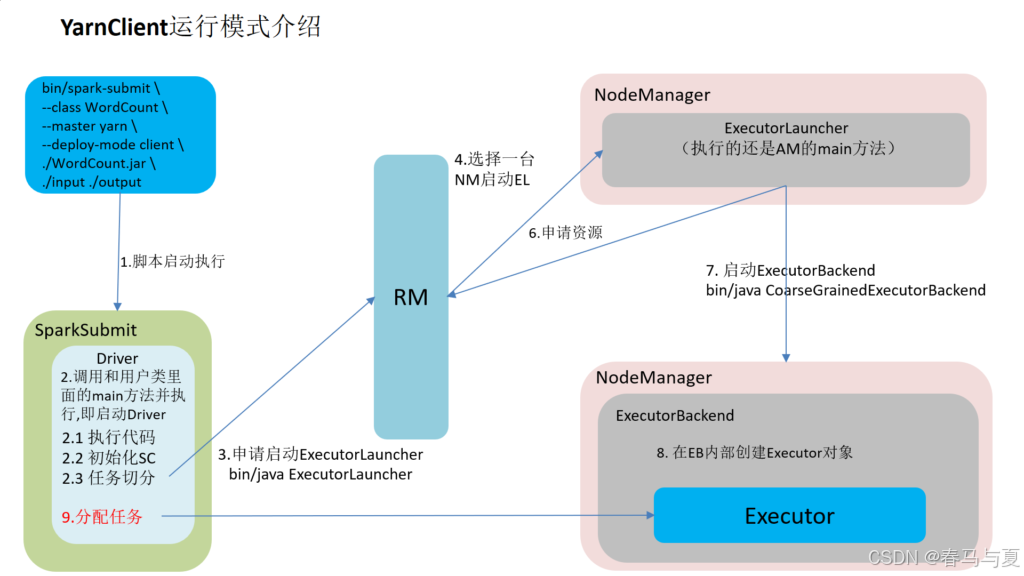
一、YarnClient
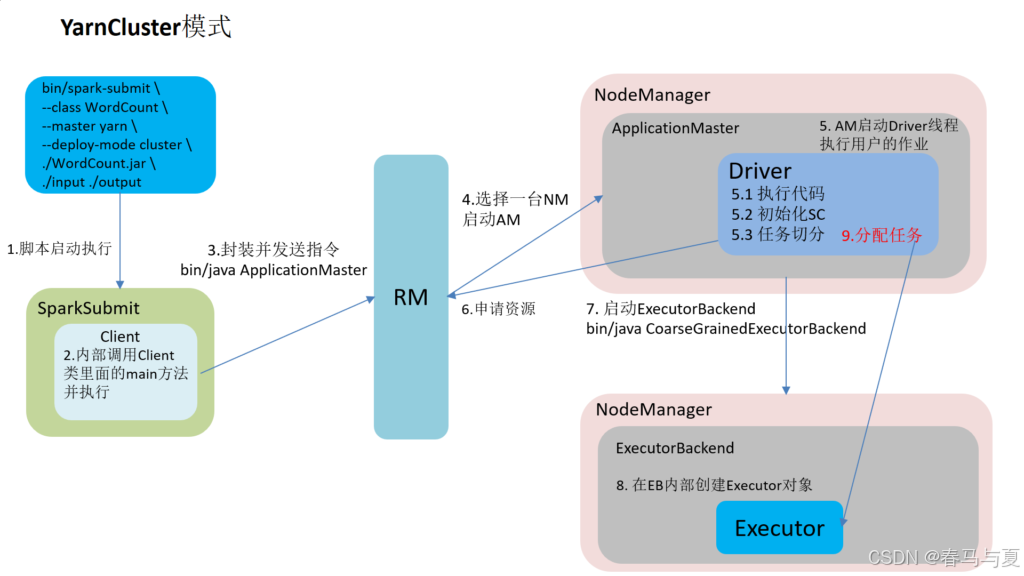
二、YarnCluster
三、详细描述
- 客户端(Client)通过YARN的ResourceManager提交应用程序。在此过程中,客户端进行权限验证,生成Job
ID和资源上传路径,并将这些信息返回给客户端。 - 客户端将jar包、配置文件、第三方包等文件上传到指定的HDFS路径。完成后,客户端再次向ResourceManager提交作业执行请求。
- ResourceManager收到请求后,将其封装为一个任务,并将其插入Scheduler的任务队列中,等待空闲资源。
- 一旦集群中有空闲资源,Scheduler将任务分配给NodeManager,NodeManager创建容器,并启动ApplicationMaster。
- ApplicationMaster启动后,从HDFS中拉取jar包,解析数据流(DAG),根据数据流生成阶段(Stage),确定任务的并发度,并向ResourceManager申请资源。
- ResourceManager接收到请求后,将任务封装为Task,并将其插入任务队列。
- 一旦集群中有空闲资源,ResourceManager将任务分配给NodeManager,NodeManager启动容器,并与ApplicationMaster通信,以在容器中启动Executor进程。
- Executor向ApplicationMaster注册,并申请任务。ApplicationMaster对任务进行解析,并将Task发送到Executor上。
- Executor执行Task,并将执行结果或状态报告给ApplicationMaster。
- 当所有任务执行完毕时,ApplicationMaster通知ResourceManager注销应用,回收资源。至此,整个作业的提交流程结束。