容器跑着跑着就"满了"?Pod 为什么频繁 OOM?Node 到底瓶颈在哪?这一讲,我们将带你从基础到实战,构建起完整的容器监控体系,为稳定运维保驾护航!
一、为什么容器监控至关重要?
在传统架构中,资源消耗相对固定,应用部署也较少变动。但在容器化环境中:
- 容器数量动态弹性伸缩
- 容器生命周期极短
- 单个宿主机承载多个容器,资源竞争剧烈
- 多层抽象结构:容器、Pod、Node、集群
因此,仅靠传统监控工具(如 top、htop、Zabbix)难以胜任,必须构建专门的容器可观测体系。
二、容器监控的关键维度
容器监控需覆盖多个层面,包括:
| 层级 | 关键指标 |
|---|---|
| 容器/Pod | CPU、内存、磁盘、网络使用情况 |
| Node(宿主机) | 系统负载、资源总量与剩余量 |
| 集群层 | 节点健康、调度状态、控制器状况 |
| 应用层 | QPS、响应时间、错误率等 |
三、容器监控主流方案对比
| 方案 | 组成 | 特点 |
|---|---|---|
| cAdvisor | Docker 原生监控组件 | 轻量、实时,但功能有限 |
| Prometheus | 指标采集 + 时序存储 | 社区主流,扩展性强 |
| Grafana | 可视化展示平台 | 多数据源、支持告警 |
| kube-state-metrics | K8s 对象状态指标 | 集群维度指标补充 |
| node-exporter | 宿主机指标采集器 | 采集 CPU、磁盘、内存等主机资源 |
四、容器监控架构图
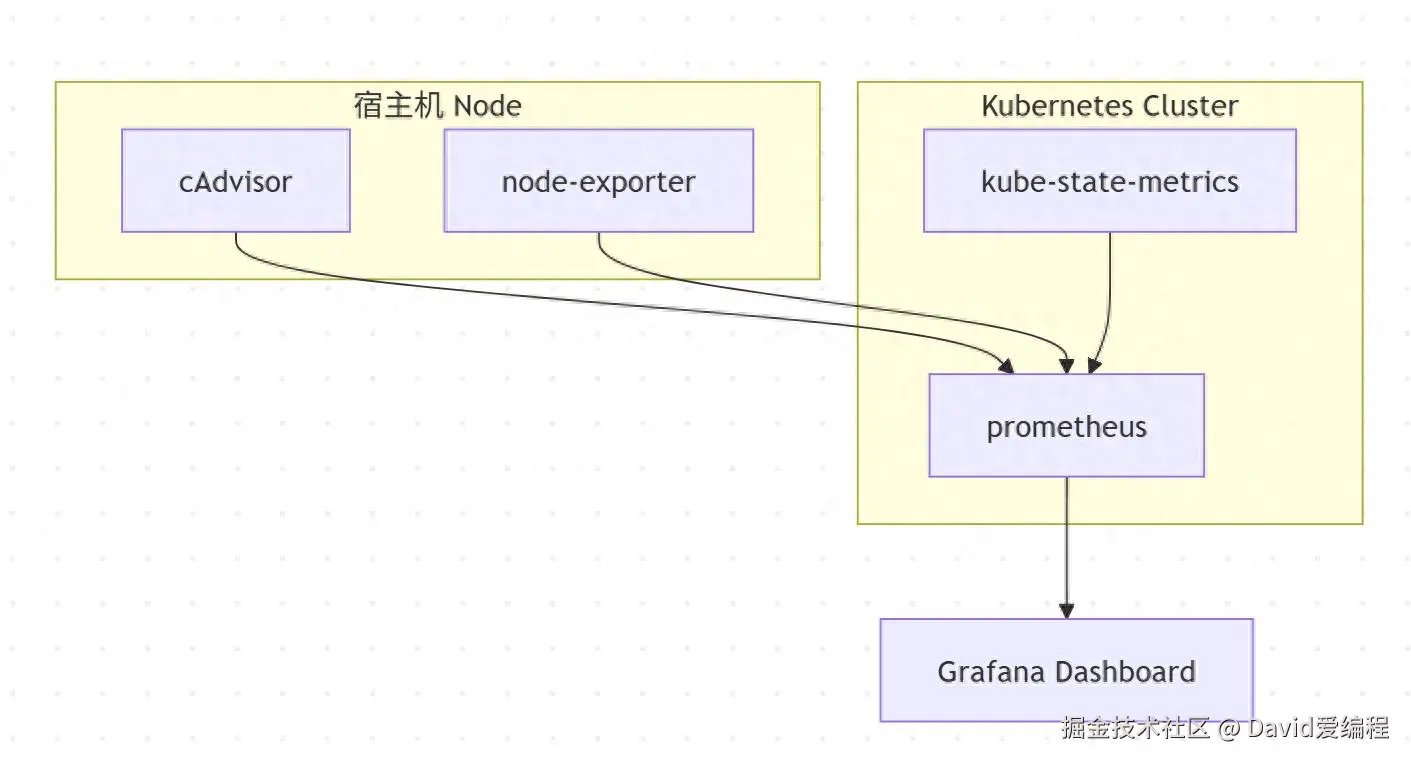
说明:
- cAdvisor:实时采集容器级别的 CPU、内存等使用信息;
- node-exporter:采集宿主机指标;
- kube-state-metrics:提供集群对象状态指标;
- 所有指标统一送入 Prometheus;
- Grafana 展示可视化仪表盘、设置告警规则。
五、部署 Prometheus + Grafana 监控平台
5.1 使用 kube-prometheus 快速部署(推荐)
kube-prometheus 是官方维护的 K8s 全栈监控部署方案,涵盖以下组件:
- Prometheus
- Alertmanager
- Grafana
- node-exporter
- kube-state-metrics
部署方式(基于 Kustomize):
bash
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
kubectl apply -f manifests/setup
kubectl apply -f manifests/5.2 安装完成后访问路径
- Grafana Dashboard:http://:30000
- 默认用户名密码:admin/admin
- 可导入 ID:1860 的容器监控仪表盘模板
六、如何监控 Docker 容器?cAdvisor 使用指南
6.1 什么是 cAdvisor?
- 全称:Container Advisor
- Google 开发,原生支持 Docker,能实时采集:
- 容器 CPU/内存/网络/Disk I/O 使用
- 容器生命周期信息
6.2 部署方式
bash
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest6.3 效果展示
- 访问 http://localhost:8080
- 可查看所有容器实时资源使用情况
- Prometheus 可通过抓取 /metrics 接口采集数据
七、Grafana 可视化仪表盘推荐
| 仪表盘名称 | Grafana Dashboard ID |
|---|---|
| Docker 容器监控 | 179 |
| Node Exporter | 1860 |
| Kubernetes 总览 | 6417 |
| Pod 级别资源使用 | 315 |
通过导入对应 Dashboard ID,可以快速搭建出丰富的监控界面。
八、监控告警设置
借助 Prometheus Alertmanager,可以设置监控告警:
示例:Pod OOM 告警规则
yaml
- alert: ContainerMemoryUsageHigh
expr: container_memory_usage_bytes / container_spec_memory_limit_bytes > 0.9
for: 1m
labels:
severity: warning
annotations:
summary: "容器内存使用过高(超过90%)"可将告警通过邮件、钉钉、Slack、飞书等方式发送。
九、容器监控最佳实践
| 建议 | 说明 |
|---|---|
| 采集频率合理 | 容器生命周期短,建议抓取周期 ≤ 30s |
| 标签管理规范 | 给容器打上业务标签,便于查询 |
| 告警设置分级 | warning / critical 分层处理 |
| 日志 + 指标结合 | 单独指标不足以定位问题,需结合日志/Trace |
| 自动化仪表盘 | 使用 Helm、Json 模板自动化部署和复用仪表盘 |
十、总结
本文带你全面了解了容器监控的现状与解决方案,从单节点 cAdvisor,到集群级 Prometheus + Grafana 架构,并实战部署了核心组件与仪表盘设置,为下一步打造可观测平台打下基础。