我自己的原文哦~https://blog.51cto.com/whaosoft/13977368
#从图像生成到端到端轨迹规划
一、 扩散模型原理
扩散模型Diffusion Models是一种生成式模型,本质是去噪,噪音符合某种特定分布。其原理基于对数据分布的学习和模拟,主要包括正向扩散过程和反向生成过程。
其名字来源于一滴墨水滴进清水,以随机运动的方式弥散到清水乃至于彻底消融。
扩散模型学习这个弥散过程,目的是把融化进清水(纯噪音)里面的墨水(原始数据)恢复出来。
模型训练好后,给定一杯滴了墨水的清水,变魔术一般恢复出原始的墨水。这里的魔术只是某种学习了分布规律的神经网络。
正向扩散过程
从初始数据分布(如真实图像分布)开始,逐步向数据中添加噪声,这个过程遵循一个马尔可夫链。在每一步,根据前一步的状态和一个固定的噪声分布,生成下一个更具噪声的数据点。随着时间步的增加,数据逐渐变得更像噪声,最终达到一个近似纯噪声分布。
反向生成过程
从纯噪声开始,通过学习一个逆过程来逐步去除噪声,以恢复出原始数据。这个逆过程通过神经网络来参数化,网络的目标是根据当前带噪声的数据点和时间步,预测出前一个时间步的更接近原始数据的点。在训练过程中,通过最大化似然估计或其他损失函数来调整神经网络的参数,使得模型能够逐渐学会从噪声中生成真实的数据样本。
扩散模型通过正向扩散过程来定义数据的噪声化过程,然后通过反向生成过程来学习如何从噪声中恢复数据,从而实现对数据分布的建模和生成新的数据样本。
图 正向-反向diffusion过程,图片来自网络
马尔可夫链(Markov Chain)是一种具有马尔可夫性(无记忆性)的随机过程,描述系统在状态空间中随时间转移的规律。其核心特征是:未来状态的概率仅依赖于当前状态,与历史状态无关。所以马尔科夫性这个性质其实是个人为简化。
|------|----|-----------------------|
| 过程 | 公式 | 说明 |
| 正向单步 | | |
| 正向多步 | | 累积噪声的线性组合 |
| 反向单步 | | 神经网络预测噪声驱动去噪,ϵ′ 为随机噪声 |
| 损失函数 | | 最小化预测噪声与真实噪声的均方差 |
扩散模型扩散过程每一层的概率分布类型通常是一样的,只是参数不一样。
在常见的扩散模型中,比如基于高斯分布假设的扩散模型,每一层(时间步)的条件概率分布通常都被建模为高斯分布。虽然不同层的均值和方差等参数会根据扩散过程而变化,但分布类型保持一致,这样的设定有助于模型的数学推导和计算。当然,也有一些扩散模型可能会采用其他类型的分布,如拉普拉斯分布等,在这种情况下,模型各层也会基于相同类型的分布来构建。
扩散模型(Diffusion Models)通常结合多种类型的神经网络来实现核心功能,包括去噪过程建模、概率分布学习和多尺度特征提取。其最常用的神经网络类型是u-net:
图 U-net架构图,来自网络
U-Net作为最核心架构,其结构特点完全是对称的,直观讲就是两个卷积神经网络尾对尾嫁接在一起。
编码器 - 解码器架构:编码器:通过卷积层逐步降低特征图分辨率,提取高层语义信息(如物体形状、纹理)。
解码器:通过上采样和跳跃连接恢复分辨率,将高层语义与低层细节结合。
跳跃连接:缓解深层网络的梯度消失问题,增强细节恢复能力。
其在扩散模型中的作用是作为去噪核心,功能是输入带噪声的图像和时间步长(表示噪声强度),输出去噪后的图像或预测噪声。
图像生成模型如 DALL-E 2、Stable Diffusion 均以U-Net 为骨干网络。
作为U-net的核心创新的跳跃连接,其思想非常类似resnet的残差链接,直接越过多层叠加。其操作是将编码器特征图Fi和解码器特征图Gj沿通道维度拼接,生成新的特征图 H。示例代码如下:
二、 扩散模型和生成对抗网络的对比
生成对抗网络(Generative Adversarial Networks,GANs) 是一种深度学习模型,由 生成器(Generator)和判别器(Discriminator)组成,通过两者的对抗博弈来学习数据分布并生成新样本。它于2014年由 Ian Goodfellow(就是人工智能花书的作者)等人提出,已广泛应用于图像生成、视频合成、数据增强等领域。
生成对抗网络和扩散模型都存在加噪和去噪过程,目的都是去噪。从输入输出角度看,二者有一定的可替换性。
目前并无文献表明二者谁更优。也有文献使用生成对抗网络来做自动驾驶的长尾场景生成。
生成对抗网络是在生成器的输入中加入噪声,可以使生成器更灵活地探索潜在空间,从而生成更加多样化的样本。
具体实现步骤如下:
- 在生成器的输入向量 ( z ) 中加入噪声。
- 噪声通常是从一个简单的分布(如标准正态分布 ( N(0, 1) ) 或均匀分布 ( U(-a, a) ))采样得到的。
图 生成对抗网络的加噪过程,来自网络
生成对抗网络(GAN)在自动驾驶领域的应用几乎和扩散模型重合,主要涵盖数据生成、场景仿真、感知增强和决策优化等方面。比如SurfelGAN(Google)利用激光雷达和摄像头数据生成逼真的相机图像,用于自动驾驶仿真模型训练。
扩散模型像"考古修复"(从碎片还原文物),GAN像"造假大师"(不断改进伪造技术)。
|------|-------------------------|----------------------------------------|
| 维度 | 扩散模型 | 生成对抗网络(GANs) |
| 核心机制 | 基于正向扩散与逆向去噪的概率建模 | 基于生成器与判别器的对抗博弈 |
| 训练方式 | 非对抗训练,仅需优化单一神经网络 | 对抗训练,需同时优化生成器和判别器 |
| 稳定性 | 训练更稳定,不易出现模式崩溃 | 训练难度高,易因梯度消失或模式崩溃失败 |
| 样本质量 | 生成图像通常更清晰、多样性更强(尤其高分辨率) | 早期 GANs 在高分辨率下可能出现模糊,需改进架构(如 StyleGAN) |
| 计算成本 | 训练和生成需多步迭代,计算复杂度高 | 生成阶段仅需单次前向传播,速度快 |
| 理论基础 | 基于热力学扩散过程和变分推断 | 基于博弈论和概率分布匹配 |
| 数学工具 | 随机微分方程(SDE)、马尔可夫链 | 概率分布散度(如 JS 散度、Wasserstein 距离) |
目前看扩散模型似乎比生成对抗网络更受欢迎,一个原因是生成对抗网络需要训练至少两个神经网络:生成器和判别器,计算量很大,训练好的模型体积也大。
但是生成对抗网络也有优势,就是其加噪过程往往融合多种分布类型的噪音,叠加的噪音更复杂;而不像基于马尔可夫链加噪的扩散模型,噪音分布类型在一般情况下不变,只是变化分布参数。
三、 扩散模型在自动驾驶领域的应用
扩散模型由于其去噪的本质,在自动驾驶领域的应用主要集中在数据生成、场景预测、感知增强和路径规划等方面。需要说明,扩散模型不仅可以用来对连续分布噪音进行去噪,也可以对离散分布噪音(和数据)去噪,所以它也可以用于离散问题,比如决策规划。
以下是具体的应用场景和技术优势:
1. 合成数据生成
扩散模型能够生成高度逼真的驾驶场景数据,解决真实数据不足或标注成本高的问题。
罕见场景生成,如极端天气(暴雨、大雾)、突发障碍物(行人横穿、车辆逆行)等,提升模型的泛化能力。
而且这种生成是可控的,通过条件控制(如BEV布局、3D标注)生成特定场景,例如NuScenes和KITTI数据集的扩展。
比如SynDiff-AD,基于潜在扩散模型的数据生成pipeline,显著提升模型在低光照、极端天气等条件下的性能。
2. 场景预测与视频生成
扩散模型可用于预测未来驾驶场景的动态变化,
包括多模态预测,也就是生成可能的交通参与者行为(如车辆变道、行人轨迹),支持决策系统。还有视频生成,比如DriveGenVLM结合视觉语言模型(VLMs)生成真实驾驶视频,用于仿真测试。
3. 感知任务优化
扩散模型在感知任务中可去除噪声并增强数据质量:
BEV去噪:利用扩散模型清理鸟瞰图(BEV)中的噪声,提升目标检测精度。
多传感器融合:生成一致的雷达与摄像头数据,改善感知鲁棒性。
4. 路径规划与决策
扩散模型通过概率建模支持多模态路径生成:
Diffusion Planner:清华AIR团队提出的规划算法,利用扩散模型的引导机制适应复杂路况,提升安全性和泛化能力。
实时端到端控制:DiffusionDrive通过截断扩散步骤实现实时决策,直接从人类驾驶数据学习。
其中所谓截断扩散就是跳跃性地去噪,本来去噪要像加噪过程一样经过多步打磨,现在则是直接越过几步,去噪时通过采样来模拟多步加噪的叠加分布,至于越过几步为好则是调参的艺术。
5. 端到端自动驾驶
扩散模型直接学习驾驶策略,简化传统模块化流程。
比如动作分布建模,也就是处理多模式驾驶行为(如避障或变道),避免传统方法的单一输出限制。
6. 小众应用
除了直接用于自动驾驶的扩散模型,还可以用于优化算法(也就是求最大或最小值),从而间接服务于自动驾驶。
自动驾驶有许多最小化优化问题,比如最小能量消耗路径,在商用车重卡领域用的非常多。其目标函数是:
其中F函数式车辆在速度vi下的单位距离能耗。
而Diffusion-ES(Diffusion Evolution Strategy) 是一种将扩散模型(Diffusion Model)与进化策略(Evolution Strategy, ES)相结合的优化算法,旨在利用扩散模型强大的生成能力和进化策略的全局搜索能力,高效求解复杂优化问题,比如上面的最小能量消耗路径求解。
技术优势总结
|--------|----------------|------------------------|
| 应用方向 | 技术优势 | 典型案例 |
| 合成数据生成 | 解决数据稀缺,支持可控生成 | SynDiff-AD 、ControlNet |
| 场景预测 | 多模态未来帧生成,动态适应性 | DriveGenVLM |
| 感知优化 | BEV去噪、多传感器一致性 | BEV-Guided Diffusion |
| 路径规划 | 多模态路径生成,高泛化能力 | Diffusion Planner |
| 端到端控制 | 实时性高,直接学习人类策略 | DiffusionDrive |
四、总结
扩散模型在自动驾驶中的应用仍处于快速发展阶段,未来可能与BEV、大语言模型(LLMs)进一步结合,推动全栈技术革新。
业界和学术多有基于扩散模型的技术方案,本文更偏重企业方案,列举三个:
毫末智行在2025 年 1 月 28 日,毫末智行联合清华大学 AIR 智能产业研究院等机构在 ICLR 2025 上发布了 Diffusion Planner。该算法基于 Diffusion Transformer,能高效处理复杂场景输入,联合建模周车运动预测与自车规划中的多模态驾驶行为。通过扩散模型强大的数据分布拟合能力,精准捕捉复杂场景中周车与自车的多模态驾驶行为,实现周车预测与自车规划的联合建模。在大规模真实数据集 nuPlan 的闭环评估中取得 SOTA 级表现,大幅降低了对后处理的依赖,并在 200 小时物流小车数据上验证了多种驾驶风格下的鲁棒性和迁移能力。目前,毫末团队已进入实车测试阶段,率先实现端到端方案在末端物流自动配送场景的应用落地。
地平线与香港大学等团队提出了 HE - Drive,这是首个以类人驾驶为核心的端到端自动驾驶系统。该系统利用稀疏感知技术生成三维空间表示,作为条件输入到基于条件去噪扩散概率模型(DDPM)的运动规划器中,生成具备时间一致性的多模态轨迹。然后,基于视觉语言模型引导的轨迹评分器从候选轨迹中选择最舒适的轨迹来控制车辆。HE - Drive 在 nuScenes 和 OpenScene 数据集上实现了 SOTA 性能和效率,同时在真实世界数据中提供了更舒适的驾驶体验。
理想汽车在 2025 年推出的下一代自动驾驶架构 MindVLA,整合了空间智能、语言智能和行为智能。该技术基于端到端和 VLM 双系统架构,通过 3D 空间编码器和逻辑推理生成合理的驾驶决策,并利用扩散模型优化驾驶轨迹。MindVLA 采用 3D 高斯作为中间表征,利用海量数据进行自监督训练,其 LLM 基座模型采用 MoE 混合专家架构和稀疏注意力技术。通过 Diffusion 模型将动作词元解码为优化轨迹,并结合自车行为生成和他车轨迹预测,提升复杂交通环境中的博弈能力。
最后,本文列举一个有代表意义的学术方案。
在2024年机器人顶会 CoRL 上,《One Model to Drift Them All: Physics-Informed Conditional Diffusion Model for Driving at the Limits》一文的作者们Franck Djeumou等提出利用包含多种车辆在多样环境下行驶轨迹的未标记数据集,训练一个高性能车辆控制的条件扩散模型。条件扩散模型(Conditional Diffusion Models, CDMs)是一类基于扩散过程的生成模型,在生成过程中引入了额外的条件信息,从而能够生成更为符合特定需求的样本,例如生成符合特定文本描述、类别标签或其他先验信息的图像。
这里的drift就是头文字D里面的飘移,在极限情况下的飘移动作(横向滑动),该模型能通过基于物理信息的数据驱动动态模型的参数多模态分布,捕捉复杂数据集中的轨迹分布。通过将在线测量数据作为生成过程的条件,将扩散模型融入实时模型预测控制框架中,用于极限驾驶。据报道,在丰田 Supra 和雷克萨斯 LC 500 上的实验表明,单一扩散模型可使两辆车在不同路况下使用不同轮胎时实现可靠的自动漂移,在对未知条件的泛化方面优于专家模型。
#VLA模型
元戎启行周光:携手火山引擎,基于豆包大模型打造物理世界Agent
2025年6月11日,元戎启行CEO周光受邀出席2025年火山引擎Force原动力大会,宣布元戎启行将携手火山引擎,基于豆包大模型,共同研发VLA等前瞻技术,打造物理世界的Agent。同时,周光宣布元戎启行的VLA模型将于2025年第三季度推向消费者市场,并展示了VLA模型的四大功能------空间语义理解、异形障碍物识别、文字类引导牌理解、语音控车,功能将随量产逐步释放。
元戎启行CEO周光
周光:"VLA的四大核心功能,相当于为AI汽车增加'透视眼''百事通''翻译官''应答灵'等属性,让AI汽车更全面地了解驾驶环境,准确预测潜在驾驶危险因素,显著提升辅助驾驶的安全性。"
空间语义理解:驾驶"透视眼"
VLA模型能够全维度解构驾驶环境,精准破解桥洞通行、公交车遮挡视野等动静态驾驶盲区场景驾驶风险。
例如,在通过无红绿灯的路口时,VLA模型能提前识别到"注意横穿,减速慢行"的指示牌,即使公交车通行造成动态盲区,VLA也会结合公交车的动作去做出准确的决策。当公交车进行减速时,它会通过推理前方可能有行人穿行,并做出"立即减速、注意风险、谨慎通行"的决策。
,时长00:16
公交车动态盲区遮挡
异形障碍物识别:驾驶"百事通"
vla模型是一个超级学霸,它通过互联网迅速获取知识并转换成自己的经验,有自己的驾驶"知识库",对驾驶过程中出现的各类障碍物了如指掌,准确判断潜在危险因素,行驶更安全。例如,VLA模型能够识别"变形"的超载小货车,结合实际路况,执行减速绕行或靠边驾驶。
,时长00:16
异形障碍物识别
文字引导牌理解:驾驶"翻译官"
搭载VLA模型的AI 汽车不仅能 "看见" 道路标识,更能 "读懂" 文字背后的通行规则,解析复杂路况里蕴含的路况信息,让复杂路况决策如 "开卷考试" 般从容。面对左转待行区、可变车道、潮汐车道等 "动态规则路段",VLA模型能够读懂字符与图标的含义,高效匹配实时路况。在多车道复杂路口选道直行的场景中,能够准确识别车辆前方的文字及图案标识牌,从左转右转混杂的路口准确找到左转车道,并执行操作。
,时长00:14
特殊路标识别
语音交互控车:驾驶"应答灵"
通过VLA模型,AI汽车可以与用户高效交流,根据语音指令做出对应的驾驶决策,随叫随应,交互更拟人,体验更舒适。并且当用户意愿与导航信息相冲突时,VLA模型会优先采纳用户意愿。

语音控车指令
目前,元戎启行已完成VLA模型的真实道路测试,预计今年将有超5款搭载元戎启行VLA模型的AI汽车陆续推入市场。其中,VLA模型支持激光雷达方案与纯视觉方案,将率先搭载在NVIDIA Drive Thor芯片上,后续元戎启行还将通过技术优化,让VLA模型可以适配更多芯片平台。
火山引擎汽车总经理、智慧出行和xx研究院院长杨立伟表示:"元戎启行作为业内率先推出VLA模型的企业之一,对人工智能的理解极为深刻。火山引擎作为行业领先的云服务提供商,在云计算领域拥有深厚的技术实力和丰富的经验。我们非常期待与元戎启行携手合作,共同推动基于豆包大模型的物理世界Agent的落地应用,助力智慧出行领域的创新发展。"
周光强调:"VLA模型作为当下最先进的AI技术,可以连接视觉、语言、动作等多种模态,打通物理世界与数字世界的壁垒,具有完善的任务规划和执行能力,是实现物理世界 agent 的关键技术。元戎启行很高兴能够与火山引擎达成合作,基于VLA模型共同打造物理世界的Agent,让双方的先进技术在物理世界的各个领域落地,推动生产力进阶。"
#理想司机Agent的一些细节
整体评价: 基于司机Agent 这个产品定义主要专注于 封闭园区/地下车库场景下的多模态信息融合感知输出决策。
产品整体定义,细节都是做的很完善了。
举几个细节点:
1️⃣: 首先Agent 产品已经全模型化输出轨迹,除了部分兜底还会有少量的规则。因此和过去的AVP产品体验完全不一样。最为直观的感受就是你感觉到在园区/地下车库 AD Max 自己开车和人类司机开车体验几乎无差异
【当然还是没有人类老司机开得好】。
2️⃣:基于2D/3D 信息编码整合进模型后,Agent 具备理解道路标牌【例如,出口,上下坡道,左右转,电梯口,不允许通行,区域B12345,ABCDEFGG区 etc】的能力,和语音交互感知【左右转,靠边停车,掉个头,快点慢点,甚至给出先去A区再靠边,或者掉头后再去C区】的能力。简单指令场景依赖的是本地的多模态LLM,复杂指令是Token化后上云大参量的LLM,将任务拆解后转换成顺序任务后在本地LLM执行。
3️⃣:具备自建关联点的能力【我这里为什么不说建地图而是建关联点】有就几个原因:首先更多的是行车的关联结构,而并非记忆了精准的道路结构。因此车辆在调用这个关联点记忆很像人在地下车库开车【大概要往哪个地方开,而并非是像Hd map 具有严格的驾驶轨迹限定】,换句话说,关联点建好后。理论上,给Agent 需求后,会直接进行关联点分析,规划出一条最近的【可以符合通行逻辑】的地下/园区驾驶轨迹。 当然现在他能力还有限,还是偶尔会出现开错路,然后触发掉头再开【对因为行车模型化后,理论上可以触发无限制掉头,几乎不会卡死】
4️⃣:具备感知推理能力,而且怀疑整个AD Max Agent 场景是将行车感知摄像头和泊车【鱼眼】感知摄像头对齐后输入到模型里面。甚至还前融合了激光雷达的数据。
基本可以做到全向规则/不规则的环境感知能力。
考虑到业内发展态势如此之快。从个人体验角度来看,我觉得AD Max 司机Agent 和 NIO AD 的NWM。
是目前唯二,将多模态感知信息整合到一个模型里实现复杂推理的应用场景。
NWM大家已经看到大量实测视频,地下寻路能力非常不错,而且多模态感知能力也非常好。
司机Agent。截至目前释放的范围:
1️⃣:多模态感知+语音交互;
2️⃣:地下车库收费杆感知,判断。衔接到封闭园区再到公开道路;
3️⃣:构建关联点记忆能力【第二次就不需要漫游出园区/地下车库】,直接可以跟着大概记忆走,记忆不对也会触发掉头,换路 etc。
#谢赛宁开炮,现场打脸CVPR评审?
在CVPR 2025上,谢赛宁发出振聋发聩的批判:如今的AI学术界,已经彻底畸形了!有巨大缺陷的学术激励制度,让所有研究者陷入内卷,精疲力竭。而自己的DiT、SiT等开山论文,也让CVPR评审被狠狠打脸了!
为什么如今的人工智能研究,有可能沦为一场「有限游戏」?
研究人员面临的压力,已经令人精疲力竭,当今的学术激励制度,是否存在着巨大缺陷?
刚刚在CVPR 2025上获得年轻研究者奖的谢赛宁,提出了这些深刻的问题,引起了全场深思。
作为纽约大学计算机科学助理教授,谢赛宁此次获奖可谓实至名归。
而他的演讲「研究作为一种无限游戏」,也成为本届CVPR上的精彩亮点之一。
有趣的是,谢赛宁特意回顾了自己的DiT、SiT两篇论文,分别被CVPR 2023和2024拒收的经历。
虽然当时被拒收,但紧接着,CVPR评审就被狠狠打脸:这两项工作,分别成为了Sora和Stable Diffusion 3的奠基性成果。
谢赛宁参加的这个CVPR社区建设研讨会,主题就是支持早期职业研究人员的成长。
活动现场,各位研究者们都发表了一系列精彩演讲,进行了坦诚的小组讨论。
下面,就让我们仔细看一下谢赛宁的演讲中都说了什么,准备好,思想盛宴开启!
AI研究,是一场「无限游戏」
在演讲开场,谢赛宁介绍了这样两种游戏。
其中一种是有限游戏,它有一套明确的规则,目的就是获胜。有人获胜,就意味着其他玩家失败。
而一旦宣布获胜者,游戏就结束了,所有玩家必须停止游戏。
而另一种,就是无限游戏。它的目标不是获胜,而是让所有玩家继续玩下去。
任何规则、界限,甚至是玩家,都可以随着时间推移而变化。唯一的必要条件,就是游戏永不终止。
以上概念,是由NYU历史学教授James Carse在自己的书中提出的。
而在本次演讲中,谢赛宁主要谈论了以下四部分的内容。
1. 为何研究理应是一场「无限游戏」?
2. 我,即是我自己的天才
3. AI研究正在陷入「有限游戏」困境?
4. 无人能孤身成局
为何研究理应是一场「无限游戏」?
所谓「无限游戏」,可以从反脆弱性、开放性、持久性和教育这4个方面说起。
A. 反脆弱
「反脆弱性」就是指任何在面对随机事件(或某些冲击)时,上行空间大于下行风险的事物。
无限游戏就是反脆弱性的,研究也是同样。
很典型的一个例子,就是一篇论文的影响力,对你职业生涯的影响。
所以,究竟该如何才能找到真正属于自己的研究思路呢?
**第一步:**追随你的好奇心与热情,让它们为你指引方向;
**第二步:**大胆探索,在数学推导和动手实验中反复尝试;
**第三步:**拥抱不期而遇的惊喜,真正的灵感往往源于意外------从混沌中获益!
注意,一定要避开这个陷阱:从第一天起就抱着一个僵化的想法,然后发表一篇固步自封的论文。而这,往往是最为平庸的作品。
B. 开放
经过训练,有限玩家可以预测未来的每一种可能性,以控制未来为目标。但无限玩家则继续游戏,期待着惊喜。
惊喜会导致有限游戏的结束,却是无限游戏得以延续的理由。
在开放的科学中,进步不是来自对知识的守旧,而是来自对知识的分享。只有发现的游戏才能持续,才能不断演化。
可以说,学术界是唯一一个你可以完全自由、开放地探索的空间。
对身处学术界的人来说,请充分利用这份独特的自由------这是一种特权。
而对身处工业界的人来说,学术界可以成为你强有力的盟友,帮你降低风险、开启新的方向。
C. 坚守
有限游戏的参与者,可能会在目标无法实现时选择放弃:「论文没被接收/没拿到资助/产品没上线,所以我失败了。」
而对无限游戏的参与者来说,坚持是一种存在方式:「这是更长远游戏的一部分。我该如何学习、适应,继续前行?」
在这里,谢赛宁就引用了自己DiT论文的典故。
2022年,他和William Peebles一起发表了DiT论文,首次把Transformer和扩散模型结合了起来。
从此,统治扩散模型的U-Net直接被取代。这一论文,成为了奠定他学术地位的开山之作。Diffusion Transformer,也成为了Sora的基础架构之一。
论文地址:https://arxiv.org/abs/2212.09748
然而,就是这样一篇神作,当初却因「缺乏创新性」的理由,直接被CVPR 2023拒了,还一连被多个大公司拒绝。
还有另外一个小插曲:谢赛宁是在deadline截止前三周,才转向这个项目的。
后来,他们重新提交了这篇论文,未经任何修改,就在ICCV 2023上获得了Oral。
而合著者William (Bill) Peebles随后加入了OpenAI,领导了Sora技术团队,让DiT的影响力在全世界无限扩大。
所以谢赛宁告诉我们:有时候,你需要等待;另一些时候,你需要换一种方法,来实现目标。
另外,他和Willis Ma等合著的SiT论文,也因「缺乏创新性」这个理由,被CVPR 2024拒了。
论文地址:https://arxiv.org/abs/2401.08740
在稍加修改后,论文被ECCV 2024接收。
就在几个月后,CVPR评审又被打脸了:Stable Diffusion 3发布,直接表明「结合了DiT架构和流匹配技术」,也就是基于SiT。
而谢赛宁等人的SiT,现在早已成为工业界常用的基准方法。
总之,谢赛宁表示,自己还可以继续讲很多,自己的许多被最多应用的论文,开始并没有得到最有力的评价。
但是坚持不懈,就是无限玩家会做的事!
D. 教育
如果把博士的「培养」视作一个「有限游戏」,会是下面这样。
· 规则目标
发表X篇论文、通过资格考试、完成毕业答辩。
· 参与成员
你自己、你的导师委员会,以及同届的其他博士生。
· 获胜条件
赢得「博士」头衔,收获学术声望。
· 游戏时限
毕业,即是这场游戏的明确终点。
但博士的「教育」,其实是一场「无限游戏」。
· 终身学习之道
博士教育的真谛在于教会你如何学习,如何提出深刻的问题,如何挑战既有假设------这些能力将伴你终身,其价值远超学位本身。
· 炼就自身心智
你将成为一个能安然于模糊混沌,能与盘根错节的复杂性深度共事,并能在失败与迭代中安之若素的人。
· 从汲取到反哺
你完成了从知识的汲取者到知识的创造者的蜕变------并开始为后来者引路。
· 游戏永不终局
即便毕业,你也并未「赢得」科研或教育这场游戏。你将永远身在局中,而你参与的目的,就是为了让这场游戏永远进行下去。
我,即是我自己的天才
讲到这里,谢赛宁告诉我们:所有人都能够并理应开创自己的赛局。
首先,需要思考一个问题------我们究竟为什么要发表论文?
Hannah Arendt曾在1964年说:「我该为影响力而奔走吗?不,我渴望的是理解。而当他人也达成了与我同样的理解------那一刻,我便获得了一种满足感,一种深刻的归属感。」
而你,我的朋友,要做的就是定义属于自己的玩法!
在无限游戏中要脱颖而出,靠的不是战胜对手,而是成为你自己,并去鼓舞他人!
这也就是我们常说的「讲好一个故事」,以及「研究的品味」。
接下来,谢赛宁提出了一个非常有意思的观点------研究人员就像是时尚设计师。
比如在他看来,何恺明就是最好的设计师之一。
你或许对这些说法不陌生:「一表一核心!」
或者这个:「简洁且有理有据的方法。」
「一步一步地进行消融实验,厘清混淆变量。」
而这些设计,也让谢赛宁等人获得了业界的诸多肯定。
正如谢赛宁一直以来都会为自己的项目打造一个专属的主页。
你也应该为自己的论文、工作、甚至是本人,打造鲜明的品牌。
不要只做一个学术的「缝补匠」。
(指那些沉迷于对现有模型/工作进行微小改进的研究者)
要知道,在如今这个时代,人们早已没有时间去读那么多paper。
因此,怎样做好知识共享,让自己的学术成果得到最大化的传播,就成了一门很重要的学问。
而谢赛宁的模板由于效果十分拔群,在圈子里可谓是相当火爆------有不少研究者都复用在了自己的项目里。
AI研究正在陷入「有限游戏」困境?
接下来这一部分,谢赛宁提出了很多相当令人担忧的问题。
面对正在陷入「有限游戏」泥沼的AI研究,「无限玩家」必须挺身抗衡。
如今,业界形成的一些研究范式,着实令人担忧。
比如我们经常看到的下面这个局面------
一个关键的「有限玩家」(比如OpenAI)发布了一篇新论文(比如4v, r1, GRPO, o1, 4o...)。
紧接着,一波跟风之作便会随之而来。之后,所有人都会蜂拥而上,争相发表同一主题的论文。
由此,大家陷入了一场唯「快」是图的竞赛。
原因在于,一旦论文率先发表,就能收获更多引用和关注,成为赢家。后来的贡献者,往往就被直接忽视,成为输家。
而一旦某项「开山之作」问世,其他人就会迅速放弃这个课题。
由此,研究人员也被逼得身负重压。
巨大的科研压力,时常压得他们喘不过气来,尤其是学生和青年学者。
所有人都在为争夺有限的认可而拼命内卷,维持着让人身心俱疲、难以为继的节奏。
而现在的学术界,也已经形成了一套颇为畸形的学术激励机制。
比如重视速度,轻视深度和创造力;奖励短期的快速胜利,而不是持久的贡献。
这就十分危险------当学术界也玩起了「有限游戏」,惨败的结局就已经注定!
而破局之道,就是定义新的问题。毕竟,问题是无穷无尽的。
举例来说,谢赛宁和Penghao Wu早在2023年7月就启动了引导视觉搜索作为多模态LLM核心机制的「V*」项目。
当时他们的动机在于,根据人类心理学的相关研究,视觉搜索是一种核心认知机制。
论文地址:https://arxiv.org/abs/2312.14135
在这项研究中,谢赛宁等人将VQA LLM与视觉搜索模型相结合。借助大模型的世界知识,V*会对视觉目标进行多轮引导搜索。接着,它会提取局部特征并将其添加到工作记忆中,最终利用搜索到的数据生成响应。
扩展阅读:
· CV大神谢赛宁新作:V*重磅「视觉搜索」算法让LLM理解力逼近人类
虽然有些人对此表示不解:「这项能力有什么必要吗?它明明会拖慢整个系统。」
但随着新问题的诞生,新的赛局也悄然打响。
时间来到2025年,当OpenAI在发布最新版o3和o4-mini的时候,不仅在模型评测中加入了基于V*的视觉搜索基准,而且还将基于图像的思考能力作为重中之重,直接放在了标题上。
扩展阅读:
· OpenAI震撼发布o3/o4-mini,直逼视觉推理巅峰!首用图像思考,十倍算力爆表
· o3精准破译照片位置,只靠几行Python代码?人类在AI面前已裸奔
· 两张图定位全球,o3碾压T0级高手!人类「诡计」被看穿,跨模态推理爆表
一句话总结就是:「有限游戏」或许能带来财富、地位、权力与认可;但「无限游戏」所提供的,是某种更深刻、也更有意义的回报。
当然,我们并不能指望青年学者从一开始就自然具备这种着眼长远、胸怀利他的格局。
真正的问题在于:我们该如何构建一个正向的反馈闭环,来孕育并守护这种格局?
无人能孤身成局
PPT最后,就到了上价值这趴了。
作为总结,谢赛宁先是通过引述,写出了自己的一些思考和感悟。
「要是搞计算机视觉,你绝对找不到工作。」------某篇博客,2010年
「你应该投身于计算机视觉。CVPR这个社区开放、包容,从不排外。」------一位导师,2013年
正如前文所述,「玩家」从不稀缺,但更多的玩家并不一定意味着「无限游戏」。
因此谢赛宁呼吁,希望大家能够共同努力让整个科研环境变得更好。
我们切莫将社区的存在视为理所当然------它的强大与包容,你我皆有责任。
最后,致各位无限游戏中的同道者们:尽情享受这场游戏吧,谢谢大家!
参考资料:
https://x.com/sainingxie/status/1933009474949652546
#完全端到端的主流方法
1. 从原始传感器数据到控制策略的端到端方法
端到端自动驾驶基本流程:
(1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型;
(2)由数据驱动的方式来解决长尾问题,取代rule-based的结构。
优点:
(1)直接输出控车指令,避免信息损失;
(2)具备零样本学习能力,更好解决OOD问题;
(3)数据驱动方式解决自动驾驶长尾问题;
(4)避免上下游模块误差的过度传导;
(5)模型集成统一,提升计算效率。
2. 完全端到端是怎么做的
评估指标
开环指标:
(2)碰撞率
闭环仿真:
(1)路线完成率(RC)路线完成的百分比
(2)违规分数(IS)衡量触发的违规行为
(3)驾驶分数(DS)表示驾驶进度和安全性
3. UniAD算法详解
3.1 算法动机
(1)跨模块信息丢失、错误积累和特征misalignment;
(2)负向传输;
(3)安全保障和可解释性方面;
(4)考虑模块较少。
3.2 开创性思路
(1)第一项全面研究自动驾驶领域包括感知、预测和规划在内的多种任务的联合合作的工作;
(2)以查询方式链接各模块的灵活设计;
(3)一种以决策为导向的端到端框架。
3.3 主体结构
特征提取,特征转换,感知模块(目标检测+多目标跟踪+建图部分,TrackFormer、MapFormer),预测模块(MotionFormer、OccFormer),规划模块(指令导航、Occ矫正轨迹)。
全景分割:对前景进行实例分割,对背景进行语义分割。
前景 thing queries --> 车道、边界和人行横道
背景 stuff queries --> 可行驶区域
3.4 损失函数
每个模块都有一个损失函数,第一阶段去训练Perception模块,;第二阶段冻结Perception模块,去训练Perception和Prediction和Planning所有模块,。
3.5 性能对比
消融实验证明各个模块都是不可或缺的,然后再去对比单个模块的性能。各个模块的对比这里不再展开。
整体对比
4. VAD算法详解
跟UniAD一样,也是一个纯视觉方案
4.1 算法动机&开创性思路
(1)栅格化表示计算量大,并且缺少关键的实例级结构信息;
(2)矢量化表示,计算方面效率高。
4.2 主体结构
包括特征提取、特征转换、矢量化场景学习、规划模块;
4.3 损失函数
自车的预测轨迹和gt之间是一个模仿学习的过程,所以添加了一个模仿学习的loss,,即轨迹与gt之间的回归误差。
总的loss的话,还需要加上地图重建的loss和每个agent运动预测的loss(位置预测、类别分类、多模态轨迹的预测和得分),当前自车轨迹与其他agent避免碰撞的loss,自车避免撞到边界的loss,自车与车道的方向一致的loss。
4.4 性能对比
开环指标
闭环仿真指标
运行时间
4.5 VADv2优化了什么
自车在某个场景下可能有多个表现,但是模型训练出来,可能学到了一个中间轨迹,会导致与其他agent发生碰撞。
所以,(1)提出,在训练集中的这些轨迹应该赋予一个权重,以什么样的概率去学习,所以在训练集中计算轨迹概率分布去约束训练的情况;
(2)同时将训练集中的轨迹进行了最远点采样,作为轨迹词典,将其作为token给到transformer,从而提升规划模块的效果。
5. UAD算法详解
没有模块化和人工标注的
5.1 算法动机
(1)现存方法的标注和计算开销过大,所以本篇没有人工标注的需求
(2)感知模块的标注不是提升规划性能的关键,扩大数据量才是关键。只对数据量扩大但不增加标注成本。
5.2 开创性思路
(1)无监督代理任务
(2)自监督方向感知策略
5.3 主体结构
5.3.1 无监督的代理任务Angular Perception Pretext
输入是一个环视的图像,通过GroundingDINO(开集检测器,在训练集中10个类别的数据,但是验证集中有多出来的其他类别也要要求能检测出来),然后得到BEV特征,经过Dreaming Decoder得到预测结果与刚才说获取的标签去计算一个loss(二分类交叉loss)
用于对物体预测的Dreaming decoder的整体结构是:初始化K个角度的Query,BEV特征被分成了K个区域跟Query一一对应,经过GRU模块(用t-1时刻的Query和当前时刻t的特征F去计算当前时刻t的Query),用t时刻的特征和t时刻的Query做一个CrossAttention得到下一时刻的特征。即自回归的一种方式。Query之间对平均值和方差进行一个DreamingLoss,让其分布尽量相似。
5.3.2 利用方向感知的规划模块Direction Aware Planning
包含三个部分
(1)PlanningHead规划头(通过模仿学习来计算未来轨迹,对BEV特征进行旋转,过规划头得到响应的预测轨迹,然后GT也要旋转,两者得到一个模仿学习的loss。)
(2)Directional Augmentation方向增强(先对轨迹沿着车辆行驶方向划分为直行、左转、右转,然后通过这个预测头做一个三分类)
(3)Directional Consistency方向一致性(旋转后的特征得到的轨迹再旋转回去之后,跟之前的对比得到loss。)
5.4 损失函数
: 预测哪个扇形区域中是有物体的,对周围环境下障碍物信息的感知,二分类的交叉熵损失
: 对前后两帧之间的Query的分布做KL散度的Loss
: 模仿学习的loss
: 对控车信号的分类头(直行、左右转)的loss
: 方向一致性loss
5.5 性能对比
开环对比
闭环仿真指标对比
6. SparseDrive算法详解
6.1 算法动机
认为传统方法中BEV特征计算成本高
忽略了自车对周围代理的影响
场景信息是在agent周围提取,忽略了自车
运动预测和规划都是多模态问题,应该输出多种轨迹
6.2 开创性思路
探索了端到端自动驾驶的稀疏场景表示,并提出了一种以稀疏为中心的范式
修改了运动预测和规划之间的巨大相似性,提出了一种分层规划选择策略
6.3 主体结构
输入环视的6幅图像,输出是其他agent的预测和规划结果。
中途处理过程包括:特征提取、对称稀疏感知、平行运动规划三大模块。
在对称稀疏感知模块中,主要包含:稀疏检测、稀疏跟踪、稀疏在线建图任务,我们来具体看一下。
在平行运动规划器模块中:作者认为其他agent的轨迹预测和自车的轨迹预测应该是一个任务,并且是互相影响的。
6.4 损失函数
loss函数有:检测阶段的、map检测的、其他agent未来轨迹的、自车规划的、深度的loss
训练阶段分为两部分:stage1是从头开始训练对称稀疏感知模块,以学习稀疏场景表示;stage2是稀疏感知模块和并行运动规划器一起训练。
6.5 性能对比
7. ReasonNet算法详解
这是一个时序+多模态的方案,这篇论文对一些特殊的场景进行了考虑。
如图中,黄车视角中的红车被蓝车挡住,能否通过蓝车的行为来判断有红车的可能性。
7.1 算法动机
应该对驾驶场景的未来发展做出高保真的预测;
处理长尾分布中罕见不利事件,遮挡区域中未被发现但相关的物体。
7.2 开创性思路
提出一种新型的时间和全局推理网络,增加历史的场景推理,提高全局情景的感知性能;
提出一种新基准,由城市驾驶中各种遮挡场景所组成,用于系统性地评估遮挡事件。
7.3 主体结构
这篇文章是多模态的,所以其输入是图像输入和雷达点云的输入所组成的,输出是waypoints。
主体结构分为三个模块:
(1)感知模块,从Lidar和RGB数据中提取BEV特征;
(2)时间推理模块,处理时间信息并维护存储历史特征的存储库;
S用于计算存在Memory Bank中的历史特征和当前特征的相似度
(3)全局推理模块,捕获物体与环境之间的交互关系,以检测不利事件(如遮挡)并提高感知性能。
交互建模 ➡ 图注意网络(GAT)➡ 占据解码 ➡ 一致性损失
7.4 损失函数
首先是Preception模块,包括:Waypoints的回归loss,Traffic sign的分类loss,BEV Map分类+回归的loss;
二阶段有:一致性的loss,Traffic sign的loss,BEV Map的loss,占用图的loss。
7.5 性能对比
基于本文提出的新的benchmark叫做DOS benchmark:四种场景分别包含25种不同的情况,包括车辆和行人的遮挡,有间歇性遮挡和持续遮挡但有交互线索。
8. FusionAD算法详解
这是一篇多模态的方案,是在UniAD的基础上加入了点云数据,改造成了多模态的方案。
8.1 算法动机
(1)传统的模块化方法没办法支持梯度反传,会造成信息的丢失。
(2)UniAD只支持图像输入,不支持激光雷达信息。
8.2 开创性思路
(1)第一个统一的基于BEV多模态、多任务的端到端学习框架,重点关注自动驾驶的预测和规划任务;
(2)探索融合特征增强预测和规划任务,提出一个融合辅助模态感知预测和状态感知规划模块,称为FMSPnP。
8.3 主体结构
特征融合模块
预测模块
【名词解释】Anchor:在目标检测任务中,Anchor 是一种重要的概念,它指的是一组预定义的矩形框,这些框具有不同的尺寸、长宽比,用于在图像中表示潜在的目标对象。Anchor 的设计对于目标检测模型的性能至关重要,因为它们作为候选区域帮助模型更准确地定位和识别目标。
【名词解释】embed:通常指的是嵌入(embedding),它是一种将高维数据(如图像、文本或声音)转换为低维密集向量表示的方法。这些向量表示捕捉了数据的重要特征,通常用于机器学习模型的输入。例如,在自然语言处理中,单词或短语会被转换为词嵌入(word embeddings),这些嵌入能够捕捉单词的语义信息。在计算机视觉中,图像可以被转换为像素嵌入(pixel embeddings),这些嵌入包含了图像的视觉特征。
【名词解释】MLP:多层感知器(MLP,Multilayer Perceptron)是一种前馈人工神经网络模型,由多个神经元层组成,通常包括一个输入层、多个隐藏层和一个输出层。每个神经元会对输入数据进行加权求和,然后通过一个激活函数来引入非线性,使得 MLP 能够学习和模拟复杂的数据关系。
规划模块
新增一个自车信息的输入。
8.4 损失函数
与UniAD相比,将碰撞的loss进行了一个修改,在UniAD中的Lcol是预测的自车轨迹与其他agent的iou,这里的话,换成了预测的轨迹与其他车辆的轨迹沿中心点画一个圆,计算中心点的距离,以此来计算loss。
训练的时候,比UniAD多了一个阶段,stage1:BEV+感知;əstage2:冻结BEV+感知+预测+规划;əstage3:占用+规划+冻结其他部分。
8.5 性能对比
加入激光数据之后的性能比UniAD没加入激光的表现好。
9. Hydra-MDP算法详解
CVPR2024端到端自动驾驶挑战赛冠军+多模态方案,具备多个目标的多头蒸馏。
9.1 算法动机
比赛背景:(1)开环下的端到端驾驶有着各种问题;(2)nuScenes数据并非为规划设计,没有考虑到规划的一些场景;(3)NAVSIM对自车进行模拟,指标的计算考虑与其他车辆、道路的位置关系。
(1)轨迹回放带来的监督有限;
(2)推理时加不可微分的后处理。
我们先来对比下目前三种主流的方式:
第一种范式,我们之前讲的UAD、VAD都是这种范式,规划模块预测一个单模的规划输出;同时用于监督的也是一个单目标。具体来讲就是预测一条规划轨迹,并且这条规划轨迹的gt是由人驾的多个时刻的轨迹点来组成,大部分是用L2loss这种情况。
第二种范式,预测的轨迹是多模态的轨迹,监督它的目标是单一的目标,这个类似VADv2和SparseDrive这种方法,这种方法一般去监督与gt轨迹最近的一条轨迹。问题是这种轨迹是轨迹回放出来的,而不是车辆此时此刻走出来的轨迹,同一场景下,司机开的轨迹不一定是唯一和最优的,也就是说可能有好几条最优轨迹,但是如果只有一条司机开出来的轨迹作为gt进行轨迹的回归监督,监督是有限的,是弱监督。体现出了监督的有限性,而且没考虑到监督的安全、交通规则、舒适、效率。而且这个后处理模块,由于在后推理时用了感知模块的输入,当感知模块有问题的时候,信息传递就会出现误差累积,这个后处理模块本身是不可微分的,所以会造成信息的损失。
本文作者提出的新的范式,就是规划模块是多模的输出,同时,目标也是多样性的,即不仅是GT的轨迹也同时引入了更多的正样本,由不同的专家给出的。此外,将后处理的模块变成了可微分的用于训练的神经网络的模块,从而消除了第二种范式中由于不可微分而带来的信息损失的情况。
9.2 开创性思路
(1)引入了更多的正样本,由不同专家给出;
(2)感知真值引入规划模块用于训练。
9.3 主体结构
第一部分是感知的信息处理融合和提取,第二个模块是用前面得到的特征去解码出轨迹,最后一个模块是多目标学习范式部分。
感知模块用的Transfuser的baseline
轨迹解码器:计算不同的预测轨迹与GT轨迹的距离,这里用的是L2,用这个距离做softmax,然后去产生不同轨迹的得分情况,从而去监督得分。
多目标多头蒸馏模块:我们看到轨迹模仿学习之后的轨迹还过了其他的MLP,这就是其他头,它的目标也是不一样的,第一个是跟碰撞相关的,第二个是跟行驶区域相关的,第三个是跟舒适度相关的,也就是说不同的评判指标都有一个teacher,之前的模仿学习就是人类的teacher,那么这些teacher是怎么来的呢?怎么通过这些teacher来蒸馏的呢?我们看下作者是怎么去做的,首先我们得到规划词表Planning Vocabulary之后,对规划词表进行了一个模拟(用感知模块的GT进行训练的),有了这两个之后,我们就能算出来这些评估指标,从而计算每条轨迹的得分。总结一下就是对整个训练数据集的规划词汇进行离线模拟,在训练过程中引入每条轨迹的模拟分数的监督。
9.4 损失函数
训练阶段:感知损失+模仿学习损失+蒸馏损失;
推理阶段:由于模型不能完美拟合每一个独立的Teacher,不同的轨迹被分配不同的权重来计算最后的分数。
9.5 性能对比
其中,PDM-Closed的方法是2023年规划挑战赛的方案,用的是感知模块的输出结果作为输入去产生规划的路线,同时也加入了很多规则的手段。输入是感知模块的GT。
NC代表碰撞相关,DAC代表可行驶区域,EP衡量自车沿轨迹前进的距离,TTC代表碰撞时间,C代表舒适度相关,Score是利用这几个指标计算综合得到的评价结果。
可以看到,词表数量增加后,效果更好;只学整个PDM-Score不如单独分开几个teacher去学习更好;引入新的学习指标后,新指标对应的这栏表现会更好。
使用更大的backbone(骨干网络)会产生更好的规划性能;增大图像分辨率也可以提升性能。
#DriveAction
面向VLA模型的人类化驾驶决策基准
背景与挑战
当前自动驾驶领域的Vision-Language-Action (VLA) 模型虽取得进展,但现有评测基准存在三大局限:
- 场景多样性不足:依赖开源数据集(如nuScenes、Waymo),覆盖场景单一,关键场景(匝道汇入、施工区、行人交互)代表性弱。
- 动作标注可靠性低:多数基准缺失动作级标注,或依赖人工事后标注,无法真实反映实时驾驶意图。
- 评估逻辑偏离人类决策:主流评估采用前向链式逻辑(感知→预测→规划→动作),未建立以目标动作为核心的依赖关系。
核心创新1. 用户贡献的广覆盖驾驶场景
- 数据来源:量产自动驾驶车辆用户主动采集的真实驾驶数据,覆盖中国148个城市(Table 1对比)。
- 场景分类:7大类场景(Table 2),包括:
- 匝道汇入/分离(On/Off Ramp)
- 效率导向变道(Efficiency Lane Change)
- 弱势道路使用者避让(Bypass VRU)
- 复杂路口转向(Intersection)等
- 数据规模:2,610个驾驶场景生成16,185个QA对。
- 人类驾驶偏好对齐的真值标注
- 标注方式:直接记录用户实时操作(如方向盘转角、踏板深度),离散化为高层动作标签。
- 质量保障:人工验证排除错误/不合理/非法行为(如误加速、无故急刹、压实线)。
- 设计优势:匹配端到端大模型输出粒度,体现人类决策的离散性特征(对比Table 1的Label列)。
- 动作驱动的树状评估框架
- 框架设计(figure 1):
- 根节点:动作空间(如变道、路口转向)
- 中间层:语言任务(如导航跟随、交通灯理解)
- 叶节点:视觉任务(如车道线检测、标志识别)
- 场景信息注入:
- 连续3帧视觉输入(支持时序推理)
- 车载导航指令(提供路径规划目标)
- 自车/目标车速(量化驾驶状态)
- 灵活评估模式(Table 3):
关键实验结果多模态必要性验证
- 双模态依赖性:移除视觉输入平均精度下降3.3%,移除语言输入下降4.1%,同时移除下降8.0%(Table 3)。
- 典型案例:缺失导航信息时,模型在匝道前错误选择直行而非变道(figure 4)。
任务特异性表现
- 导航任务瓶颈:模型在车道定位(Navigation Position)任务准确率仅66.8-71.3%(Table 4)。
- 交通灯识别挑战:部分模型在Traffic Light Detection任务准确率低至40.3%(Table 5)。
- 效率决策保守性:面对慢车阻挡时,模型倾向保持车道而非高效变道(附录Table 13案例)。
模型稳定性
- 最佳稳定性:GPT-4.1 mini和Gemini 2.5 Pro在重复实验中标准差<0.3(Table 6)。
- 推理模型优势:在V-L-A模式下,o1模型精度达93.56%(Table 3),但该优势在信息缺失时减弱。
未来展望
- 驾驶风格个性化:分析模型决策偏好(保守型/主动型),为用户推荐适配模型。
- 长尾场景扩展:增强极端天气、夜间低光照等场景覆盖。
- 多模态依赖解耦:深入探究视觉/语言信号在复杂决策中的权重分配机制。
- 实时性优化:树状框架的动态任务组合机制可进一步压缩推理延迟。
核心价值 :DriveAction通过
动作驱动的评估范式,为VLA模型提供了紧贴人类驾驶逻辑的评测标尺。其树状框架设计(figure 1)和场景信息注入机制(如连续帧+导航指令)为自动驾驶的可解释性研究开辟了新路径。
参考
1 DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
#分层端到端VLA和纯端到端VLA有什么区别?
VLA,Vision-Language-Action模型,是xx智能领域的新范式,从给定的语言指令和视觉信号,直接生成出机器人可执行的动作。这种范式打破了以往只能在单个任务上训练大的局限性,提供了机器人模型往更加通用,场景更加泛化的方向发展。VLA模型在学术界和工业界的重要性主要体现在其将视觉信息、语言指令和行动决策有效整合,显著提升了机器人对复杂环境的理解和适应能力。
这种新范式打破了传统方法的单任务局限,使得机器人能够在多样化的场景中自主决策,灵活应对未见过的环境,广泛应用于制造业、物流和家庭服务等领域。此外,VLA模型已成为研究热点,推动了多个前沿项目的发展,如RT-2、OpenVLA、QUAR-VLA和HumanVLA,这些研究促进了学术界与工业界的合作。其适应性体现在能够应用于机械臂、四足机器人和人形机器人等多种平台,为各类智能机器人的发展提供了广泛的潜力和实际应用价值,成为智能机器人领域的关键驱动力。
对于VLA构成的机器人系统来说,主要包括:视觉的感知处理模块,语言指令的理解以及生成机器人可执行动作的策略网络。根据不同的需求,目前的VLA主要分为三类范式:显示端到到VLA,隐式端到端VLA以及分层端到端VLA。
显示端到到VLA,是最常见最经典的范式。通常是将视觉语言信息压缩成联合的表征,然后再基于这个表征去重新映射到动作空间,生成对应的动作。这类端到端的范式依赖于先前广泛的研究先验,通过不同架构(diffusion/ transformer/dit),不同的模型大小,不同的应用场景(2d/3d),不同的任务需求(从头训/下游微调),产生了各类不同的方案,取得了不错的性能。
隐式端到端VLA,则不同于前者,更加关注工作的可解释性,旨在利用当前的video diffusion模型实现未来状态的预测,再根据未来的状态通过逆运动学规律生成未来可执行的动作。通过显式的生成未来观测不仅提高了可解释性,同样也增加了避开机器人动作而scalingVLA模型的潜能。
分层端到端VLA,则关注于充分利用大小模型的特点,提升模型的泛化性同时也保留对于下游执行频率的高效性,近来也成为了研究的热点。
#ReCogDrive
超越DiffusionDrive!华科提出:结合强化学习的三阶段VLA训练框架~1. 引言
尽管当前基于端到端(End-to-End)的自动驾驶模型(如UniAD、VAD)在NuScenes等开环基准测试中表现优异,但这些方法在面对现实世界自动驾驶中的长尾场景 时,其性能往往显著下降 。为了应对这一挑战,近期涌现出大量研究工作尝试引入视觉-语言大模型(Vision-Language Models, VLMs) ,旨在利用其丰富的世界知识 和强大的泛化能力 来解决长尾问题。例如,DriveVLM、Senna、DiffVLA、AsyncDriver等双系统架构 将VLMs与传统端到端模型相结合;而EMMA、Omnidrive、Orion、GPT-Driver、LMDrive 、Sce2DriveX、Atlas、WiseAD等单系统框架则直接利用VLMs进行轨迹预测。
- 论文题目:ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/abs/2506.08052
- 代码链接:https://github.com/xiaomi-research/recogdrive(将陆续开源模型、代码、权重)
然而,当前基于VLMs的自动驾驶规划模型主要存在以下关键缺陷:
- VLMs通常在大规模的互联网图文数据上进行预训练,缺乏驾驶相关场景和关键的驾驶相关知识,限制了其在复杂多变真实驾驶环境中的应用。
- VLMs输出的离散文本空间 与自动驾驶所需的连续轨迹空间 之间存在巨大鸿沟。同时,VLMs的自回归解码过程 可能产生不符合预定格式的轨迹或错误的轨迹 ,这对于安全性要求极高的自动驾驶任务构成了不可接受的风险。
- 现有方法大多主要依赖模仿学习,导致模型往往最终学到次优的轨迹 ,模型只进行了记忆不会泛化。

我们提出了 ReCogDrive ,一个端到端的自动驾驶系统。其核心创新在于将视觉-语言大模型(VLMs)的认知能力与强化学习增强的扩散规划器(diffusion planner)融合。不同于以往的单系统方法,ReCogDrive 结合了 VLMs 的泛化能力 与 扩散模型的轨迹生成能力 ,以预测平滑、舒适、安全的驾驶轨迹。具体而言,我们首先精心构建了一个包含 310 万条高质量驾驶问答对 的数据集(包括处理开源的驾驶数据集以及通过搭建的自动标注流水线进行生成),用于对 VLMs 进行驾驶领域预训练,使其深度理解真实驾驶场景。随后,我们引入一个基于扩散模型的规划器,它作为桥梁有效弥合了 VLMs 语言空间与车辆连续动作空间之间的鸿沟 ,将高层次的语义表征映射为连续的轨迹,同时保留了 VLMs 原有的泛化性。为进一步提升轨迹质量,我们创新性地通过 模拟器辅助的强化学习(NAVSIM) 对扩散模型进行强化微调。与仅能复制专家行为的模仿学习不同,强化学习使模型能够主动探索驾驶行为,在模拟器的反馈循环中迭代优化,最终生成更安全、更稳定、更舒适的驾驶轨迹。通过在 NAVSIM 基准上进行实验,我们验证了 ReCogDrive 的有效性,其达到了 89.6 PDMS 分数 ,超过之前纯视觉的方案 5.6 PDMS ,充分证明了该系统的优越性能和现实可行性。
2. 相关工作
视觉语言模型在自动驾驶中的应用
最近许多研究探索将视觉语言模型(VLMs)的世界知识应用到自动驾驶场景中,解决现有模型的泛化性问题,当前现有方法可分为双系统与单系统两类架构:双系统方案(如 DriveVLM 和 Senna)将 VLMs 与端到端驾驶系统结合,通过 VLMs 生成低频轨迹或高层指令并由端到端模型输出最终轨迹;单系统方案中,GPT-Driver、EMMA 和 OpenEMMA 将轨迹规划任务重构为语言建模任务并引入思维链推理增强可解释性,Agent-Driver 集成工具库与认知记忆模块扩展大语言模型的感知-决策能力,OmniDrive、Orion 和 Atlas 通过引入 3D 视觉特征提取器提升模型 3D 感知能力,LMDrive 与 WiseAD 在闭环中验证 VLMs 的驾驶能力,Sce2DriveX 采用多模态联合学习优化 3D 感知。而我们的 ReCogDrive 融合 VLMs 与扩散模型,实现预测稳定、安全的轨迹。
扩散模型在xx智能和自动驾驶应用
扩散模型在xx智能与自动驾驶领域展现出独特优势。Diffusion Policy 将扩散模型扩展至机器人领域,有效处理多模态动作分布问题,π0、π0.5、GR00T-N1 等工作将 VLMs 与 Flow Matching 结合,保留 VLMs 泛化性的同时精准地预测未来工作轨迹;RDT-1B 提出首个面向双手操作的扩散基础模型,通过统一物理可解释动作空间解决异构机器人数据兼容性问题;DiffusionDrive、TrackVLA 等工作引入截断扩散策略,有效缓解模态坍塌并降低计算开销;Diffusion Planner 创新性地将规划任务重构为多轨迹生成问题,同时预测自车轨迹和其他车辆轨迹。我们也将扩散模型与多模态大模型结合,同时不同于以往方法只采用模仿学习训练,我们还引入强化学习对扩散模型进行训练,提升模型泛化性。
强化学习在自动驾驶中应用
强化学习(RL)作为一种关键技术,已在大型语言模型和游戏智能体中验证其有效性,并应用于自动驾驶特定场景。现有方法多在非真实感模拟器(如 CARLA)中直接学习控制空间策略。为弥合仿真与现实差距,RAD 在 3DGS 环境中训练端到端驾驶模型;CarPlanner 提出自回归多模态轨迹规划器,其 RL 策略在 nuPlan 数据集上超越模仿学习方法;最近由于 Deepseek-R1 的成功,GRPO 算法被引入规划领域------AlphaDrive 首次集成 GRPO 强化学习与驾驶多模态大模型,通过引入思考更准确地预测高阶指令;TrajHF 则构建人类反馈驱动的微调框架,实现生成轨迹与多样化驾驶偏好的对齐。而我们 ReCogDrive 通过仿真器协助的强化学习来让模型预测更安全、舒适的轨迹。
3.方法
ReCogDrive的结构主要由驾驶多模态大模型和基于扩散模型的规划器组成,推理时,将前视图以及导航指令,历史轨迹,任务指令输入给多模态大模型,多模态大模型输出隐藏特征作为Diffusion的Condition,Diffusion从噪声中逐步去噪生成最终轨迹。训练采用三阶段训练方式,首先,我们收集了一个包含310万条高质量问答对的驾驶数据集,用于训练视觉语言模型(VLMs),将驾驶特定的认知知识注入模型中。接着,我们将预训练的视觉语言模型与基于扩散的轨迹规划器结合,实现稳定的语言到动作映射,将潜在的语言空间转化为连续动作空间。最后,我们引入仿真辅助的强化学习,将通过多轨迹探索获得的泛化驾驶认知整合进扩散规划器中。
3.1 驾驶场景多模态大模型训练
由于通用大模型通常在互联网图像文本数据集上进行预训练,直接将多模态大模型应用于驾驶轨迹预测很困难 ,我们首先使用310万高质量驾驶数据集来让大模型适应驾驶场景。具体而言,我们从12个开源驾驶数据集收集数据,进行归一化处理,统一格式,重新标注回答,打分过滤低质量数据,最终得到230万条高质量驾驶问答对,我们还构建了一个自动标注流水线,结合 Qwen2.5-VL 和数据集标签,生成高质量的问答数据,涵盖场景描述、关键物体描述、规划解释等任务,此外,还融合 LLaVA 指令调优数据,以保持视觉语言模型的指令遵循能力。
我们采用 InternVL3-8B 作为基础模型,该模型采用"原生多模态预训练"范式,在多个基准测试中表现优异。每张图像被切分为 448×448 的图块及一个 448×448 的缩略图,并由经过 InternViT 编码。通过 pixel shuffle,将图像特征压缩为每个图块 256 个 Token,这些 Token 与文本 Token 拼接后输入大语言模型(LLM)。经过在310万条高质量驾驶问答对和指令遵循数据的混合数据集上微调后,模型能够以文本的形式生成轨迹 、驾驶解释 以及场景描述 等:
其中 和 为驾驶决策过程提供解释性。
3.2 基于扩散模型的轨迹规划器
虽然视觉语言大模型能够以自回归形式生成轨迹,但由于动作空间与语言空间的巨大差异,这种方法存在根本限制。一方面多模态大模型本身不擅长精确数值预测,另一方面,视觉语言大模型偶尔会出现幻觉现象,降低其在驾驶场景中的可靠性。 受xx智能领域 π0、GR00T-N1 相关研究启发,我们采用基于扩散模型的轨迹规划器作为动作解码器,从高维特征空间解码出平滑轨迹。
给定一个服从高斯分布的噪声轨迹样本 ,其中 是时间维度,列维度对应平面坐标 和航向角 ,我们首先通过动作编码器 将其编码到高维特征空间。同时我们从视觉语言大模型中提取最终层隐藏特征 ,其中 是序列长度,通过均值池化操作,得到全局上下文信息的语义特征。为了保证轨迹的平滑性,我们用编码器 将历史轨迹编码成高维嵌入 ,然后将这些嵌入在通道维度上拼接,作为 DiT 模块的输入:
DiT结构如上图所示,通过 AdaLayerNorm 融合自车状态和时间信息,**随后交叉注意力层融合视觉语言模型输出的隐藏特征 **,最后,动作解码器输出去噪的连续轨迹:
我们采用 DDPM 作为扩散策略,通过最小化扩散模型预测的噪声 与真实噪声 之间的均方误差,损失函数定义为:
其中 , 是条件变量。
3.3 仿真器辅助的强化学习

仅依赖模仿学习进行训练存在局限性,因为同一个场景可能存在很多条不相同的专家轨迹,导致优化到次优的轨迹,如图(a)所示,在一个交叉路口转弯场景中,存在多条专家轨迹,模型倾向于学习平均轨迹以实现全局最优,最终可能导致错误或不安全的行驶。
更符合人类学习驾驶的方式是让模型在一个驾驶环境中自主驾驶,模拟真实世界的学习过程,但构建具有交互式的真实场景闭环仿真器非常困难,因此我们使用 NAVSIM 非交互式的仿真器评估碰撞、舒适度等指标,来进行强化学习训练。 强化学习训练过程如下:
扩散策略 可视为从高斯噪声逐步去噪生成动作序列的马尔可夫决策过程,具体地,我们首先采样 条轨迹,获取其扩散去噪链:
其中 是去噪步骤总数,对于该链:
这些轨迹在 NAVSIM 仿真器中执行,仿真器根据碰撞情况、行驶区域合规性及驾驶舒适度给出驾驶评分(PDMS),作为奖励 。随后计算组内标准化优势:
扩散链中每一步的条件策略符合高斯分布:
其中 是模型预测的均值, 是固定协方差。
因此,完整链条 在策略 下的对数策略概率为:
最后,我们参考 REINFORCE、RLOO、GRPO 等算法计算策略损失,同时引入行为克隆损失以防止探索过程中模型崩溃。
其中,** 是用于缓解去噪初期不稳定性的折扣因子, 是行为克隆损失的权重, 是从参考策略 中采样的值,折扣因子和行为克隆损失权重对于模型训练效果都非常重要。**
4.实验
表1 展示了我们的方法与现有方法在 NAVSIM 数据集上的比较结果。ReCogDrive 实现了 89.6 的 PDMS,超过了 DiffusionDrive 等 SOTA 模型 。而且,我们仅使用前视相机数据,ReCogDrive 依然比同时使用相机和激光雷达输入的 DiffusionDrive 和 WoTE 分别高出 1.5 和 1.2 的 PDMS 。此外,相比我们复现的 InternVL3 和 QwenVL2.5 这两个直接在 NAVSIM 轨迹上训练的基线方法,ReCogDrive 的 PDMS 提高了 6.3,展示了我们方法的有效性。同时,它还比纯视觉方案的 SOTA 模型 PARA-Drive 高出 5.6 的 PDMS。
表2 展示了我们方法中各个关键组件的消融实验结果,当仅在NAVSIM轨迹数据上训练时,模型的PDMS为83.3 ,在此基础上,结合我们的大规模驾驶问答数据对视觉语言大模型进行驾驶场景适应后,PDMS提高了2.9 ,引入扩散模型规划器以实现连续轨迹预测,进一步提升了0.6的PDMS ,最后,通过引入模拟器辅助的强化学习,PDMS提升至89.6,增加了2.8,验证了我们强化学习在提升驾驶安全性方面的有效性。

我们首先探索了驾驶问答数据的 scaling law,发现随着数据量的增加和数据质量的提升,模型的规划性能(PDMS )显著改善。同时,我们在强化学习阶段深入研究了三个关键超参数的作用。折扣因子 用于调控不同时间步对策略更新的贡献 ,较小的折扣值能够抑制早期高噪声步骤的干扰,从而增强训练稳定性并提升最终性能。行为克隆损失权重 用于平衡模仿学习与强化学习之间的关系 ,适当的设置能有效防止策略崩溃或过度模仿,确保策略优化空间。此外,最小扩散噪声 的设定影响生成轨迹的多样性和训练稳定性,适当的裁剪下限能鼓励策略探索而不导致训练不稳定。实验表明,这三项设置共同促进了更高效、安全的驾驶策略学习。

如图所示,可视化展示了ReCogDrive在 NAVSIM 上的感知与规划的能力。除了生成平滑的轨迹预测外,ReCogDrive 还能输出描述性的场景总结和高层次的驾驶指令。它能够准确识别关键物体,如出租车和红绿灯等。
5.结论
在本工作中,我们提出了 ReCogDrive,一个端到端的自动驾驶系统,集成了视觉语言大模型与基于扩散模型的轨迹规划器,并采用了三阶段的训练范式。首先,我们收集并过滤处理得到了一个包含310万条高质量驾驶问答对的数据集,将驾驶特定相关知识注入到预训练的视觉语言大模型中。其次,我们通过基于扩散模型的轨迹规划器,将离散的语言特征映射为平滑且连续的轨迹,同时保留视觉语言大模型的世界知识和驾驶知识。最后,我们通过强化学习增强扩散策略,以将通用的驾驶认知整合进扩散规划器中。在NAVSIM数据集上的实验证明,ReCogDrive在无激光雷达输入的条件下,实现了闭环评测指标的领先水平。
#赛力斯智能驾驶发展
在中国新能源汽车产业经历深度洗牌与智能化重构的背景下,赛力斯作为行业中由传统汽配体系转型而来的代表企业,其技术路径、产业协同与市场策略日益受到资本市场与产业界的高度关注。近年来,赛力斯通过与华为等信息技术企业的深度融合,在产品定义、技术架构和渠道构建等方面逐步建立起新的发展范式。尤其在三电系统集成、电动平台开发、智能座舱和增程技术等领域,公司展现出较强的研发自主性与平台化制造能力。结合其产业链垂直整合优势和智选车商业模式的持续强化,赛力斯已初步具备从产品爆款向生态闭环演进的可能路径。
赛力斯的发展并非一蹴而就。公司起步于1986年,当时主营汽车座椅弹簧等零部件,是典型的传统汽配制造商。2003年,公司通过与东风汽车集团合资设立东风小康,进入微型汽车整车制造领域,发展阶段与五菱、长安等品牌重叠。2016年,公司正式启动第三次"创业",成立金康新能源并快速进军新能源汽车整车制造领域。在新能源战略明确后,公司开始围绕"整车+三电"双主线同步推进,并将品牌全面整合为"赛力斯"。
2021年起,赛力斯与华为的战略合作加速演化,由最初的技术供应链关系,演进为联合研发与市场联营双轨驱动。赛力斯通过赛力斯汽车和华为终端联合运营"AITO问界"品牌,形成行业内较早实现高阶自动驾驶系统、HarmonyOS智能座舱与三合一电驱平台全面落地的整车制造商之一。据数据显示,赛力斯2024年新能源汽车销量426,885辆,同比增长182.84%,实现了销量倍增目标,2024年经营活动产生的现金流量净额225.15亿元。
赛力斯发展历程
在核心技术架构上,赛力斯构建了较为完整的三电系统产业链,覆盖电驱、电控、增程器和动力电池组,具备较强的自主研发能力。其动力BU体系下设小康动力、金康动力、容大变速器、小康部品四大公司,负责电驱动、电控模块、增程器总成和混动专用发动机研发制造。通过该体系,赛力斯已具备大规模独立供货能力,既服务自身整车产品,也对外进行模块级技术输出。
在电驱动系统方面,公司产品具备高集成度与高效率特征。公司在电驱领域成功推出高集成电驱七合一总成,其电机、电控与减速器高度集成,具备体积小、热管理效率高、响应速度快的优势,其电控体积降低30%,整机减重15%,最高系统效率达96%。
在电控与电子电气架构(EEA)方面,赛力斯基于华为"魔方"平台构建了一套可适配多能源驱动形态的整车智能底座。该平台支持纯电、增程与混动等多种动力架构,能够承载从B级至D级、轿车至SUV/MPV等不同形态产品,具备较强的拓展性和模块兼容能力。在控制架构设计上,公司采用集中式架构+域控制器+标准化接入模块的设计思路,通过中央集中计算与各功能域分布式执行组合,实现整车信息流的集中处理与高频任务的快速响应,有助于支持高阶辅助驾驶系统和多屏异构座舱布局的灵活调用。
在与华为的合作中,赛力斯的技术体系得到了系统性的升级。从最初的车型技术赋能关系逐步扩展到平台级共研,双方的协同不仅体现在车端硬件集成层面,更在产品定义、操作系统部署、用户交互体验设计及全栈解决方案落地等维度实现了深度耦合。赛力斯与华为联合开发的智能平台实现了整车核心功能的端到端集成,包括DriveONE电驱系统、HarmonyOS智能座舱、ADS智能驾驶系统以及针对混动平台定制化的能量控制策略等。
以智能座舱系统为例,问界M9搭载了HarmonyOS 4操作系统,在人机交互体验、多屏异构架构与多设备协同能力方面较此前产品形成明显升级。M9全车配备10屏交互系统,包括中控大屏、副驾娱乐屏、后排多媒体屏与HUD抬头显示等,用户可在多个屏幕之间自由拖动任务,实现不同功能的无缝切换。这一多终端协同系统由华为主导底层开发,并结合赛力斯整车通信架构进行适配,实现了硬件层与应用层的有效融合。此外,系统还支持车机与鸿蒙生态设备之间的跨端流转,大幅提升了车内数字体验的灵活性与延展性。
在智能驾驶方面,赛力斯借助华为ADS高阶智能驾驶系统,在感知融合、路径规划与自动控制三大模块建立了较强的技术依托。问界M9是首款搭载ADS3.0系统的车型,整车搭载1颗192线激光雷达、3颗高精度固态激光雷达、11颗摄像头与12颗超声波雷达,同时还升级了5颗4D毫米波雷达,以实现更精准的环境感知和更智能的驾驶辅助。
赛力斯在混动系统能量管理方面同样采取高度智能化设计。其增程5.0系统的热效率达到行业领先的45%,油电转化效率为3.65kWh/L,在当前主流增程系统中具备较强的竞争力。赛力斯超级增程系统通过中汽中心"Premium Drive高品质增程"认证,成为首批通过该项认证的增程动力系统,通过高效增程器与电池组协同控制。公司基于ERi平台开发的这套动力系统,既能够在城市低速工况下提供稳定的纯电驱动体验,也可在长途高速场景中以燃油发电形式延长续航。
在品牌与生态拓展层面,赛力斯不仅通过问界品牌在终端市场获得持续热度,同时也在公司层面构建起与华为更具深度协同的资本机制与产业绑定关系。2024年,赛力斯宣布以支付现金的方式,购买华为持有的深圳引望智能技术有限公司10%股权,交易金额为人民币115亿元。这一投资行为不仅体现了赛力斯对智选车生态价值的高度认可,也反向强化了其在未来车型合作、技术共享及渠道协同中的话语权与优先合作位次。
引望科技作为华为智选车新成立的全资子公司,承担所有华为智选车品牌业务的运营主体,其产品布局、技术方向与市场推广均与赛力斯主力产品紧密相关。赛力斯此次直接入股,也标志着其在"技术合资"模式基础上,更进一步参与到品牌资产与业务增长中,拓宽了利润来源的结构性边界。此外,赛力斯还有望从引望未来盈利中获得投资收益,并因持股关系在智选车生态中保持核心合作方地位。
赛力斯在与华为合作过程中并非简单的"代工厂"角色,而是在技术主导、整车设计、系统架构集成、产能部署及服务支持等多个环节都深度参与,并逐步形成具备一定话语权的联合主导模型。公司在内部管理方面也多维度学习华为,两者通过IPD项目协同模式进行闭环管理,该模式的典型特征是"对等联合、资源共享、成果共担",区别于传统车厂与科技企业的工具化协作,意味着赛力斯已在技术+品牌双体系中逐步取得核心角色。
截至目前,赛力斯已在整车平台、动力总成、电控系统、智能网联与座舱交互等领域构建出较完整的能力矩阵,并依托华为的系统能力加速完成产品市场化与品牌塑造。同时,其在资本端与智选生态进一步绑定,提升了盈利模型的稳定性与长期可持续性。在高端新能源车市场格局未定、智能化红利持续释放的背景下,赛力斯的路径可视为传统车企向软硬一体化、平台化运营模式转型的代表性样本。
#Genesis
世界模型SOTA!华科&小米:跨模态时空一致性,更真实更可用!
论文题目:Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
论文链接:https://arxiv.org/abs/2506.07497
Github链接:https://github.com/xiaomi-research/genesis
本文提出了 Genesis,这是一个用于联合生成多视角驾驶视频与激光雷达序列的统一框架,能够实现时空与跨模态一致性。Genesis 采用两阶段架构:首阶段将基于 DiT 的视频扩散模型与 3D 变分自编码器(3D-VAE)编码深度融合,次阶段构建具备鸟瞰视角(BEV)感知能力的激光雷达生成器,该模块融合了基于 NeRF 的渲染技术与自适应采样策略。两种模态通过共享潜在空间直接耦合,从而在视觉与点云领域实现连贯的生成。为了以结构化语义引导生成过程,本文引入了 DataCrafter(一个基于VLM的数据标注模块),可提供场景级与实例级的监督信号。在 nuScenes 基准数据集上的大量实验表明,Genesis 在视频与激光雷达指标上均达到了当前SOTA水平。并且对分割与 3D 检测等下游任务具有显著增益,验证了生成数据的语义保真度与实际应用价值。
主要贡献
本文的主要贡献总结如下:
- 统一的多模态生成架构。Genesis 采用统一的pipeline,视频和 LiDAR 分支都在共享的潜在空间内运行。视觉和几何通过一种新颖的跨模态调节机制直接耦合,实现跨模态的一致时间演变和几何对齐,而无需依赖occupancy或体素中间体。
- 通过 DataCrafter 进行结构化语义监督。为了提高语义可控性,本文引入了 DataCrafter,这是一个基于视觉语言模型构建的caption数据处理模块。它提取多视图、场景级和实例级描述,这些描述融合到密集的语言引导式先验中。这些caption数据为视频和 LiDAR 生成器提供了详细的语义指导,从而产生不仅逼真而且可解释和可控的输出。
相关工作
如图 1 所示,现有的驾驶场景生成方法通常侧重于以单一模态生成数据,通常是 RGB 视频或 LiDAR 点云。虽然这些方法显著推动了驾驶场景生成领域的发展,但它们忽视了多模态生成的协同潜力,并且在将 RGB 视频与各种传感器数据对齐方面缺乏一致性,从而导致实际应用受到限制。其中许多方法依赖于仅以粗略空间先验为条件的一步式布局到数据管道,例如 BEV map或 3D box,这限制了它们捕获复杂场景动态和细粒度语义的能力。为了将驾驶场景生成推向多模态领域,最近的工作,如 UniScene 引入了用于多模态生成的占用网格,但其解耦设计和弱语义监督限制了跨模态对齐和场景保真度。此外,与大多数现有的多模态生成方法一样,目前的方法通常依赖于有限的语义监督,通常以粗略标签或通用标题模型的形式而没有充分利用现代视觉语言模型 (VLM) 的细粒度描述能力。这种缺乏结构化语义基础限制了生成场景的保真度、可控性和上下文对齐。

图 1:多模式场景生成pipeline比较:(a) 纯视频生成,(b) 纯 LiDAR 生成,(c) 基于Occ的双分支生成,(d) 本文的Genesis。
具体工作

图2:用于联合视频和激光雷达生成的Genesis架构概述。双分支设计通过相机和激光雷达路径处理共享语义条件,使用STDiT模块进行时空生成,并使用鸟瞰图(BEV)编码器进行几何对齐。
DataCrafter 模块

图3:用于多视角caption数据生成的DataCrafter流程。视频通过基于视觉语言模型(VLM)的质量检查器进行分割和过滤(1-2),然后生成每个视角的caption数据,并融合为连贯的结构化描述(3-4)。step 1-4用于训练,而推理时仅使用step 3-4。
本文提出了 DataCrafter 是专为多视角自动驾驶视频设计的caption数据生成模块,其核心目标是通过视觉语言模型提取细粒度场景语义,为多模态生成提供结构化监督。具体流程如下:首先,将多视角输入视频 通过场景边界检测器分割为片段,每个片段都由基于视觉语言模型的模块进行评分:
其中Q项表示由视觉语言模型得出的子分数, 为固定权重。
为确保重叠视图间的一致性,多视角场景描述 经预训练 VLM 的语言编码器和冗余消除函数处理,去除冗余并生成统一语义表示 。最终,每个片段生成层次化场景描述。
其中 编码全局场景语境(如天气、道路类型、时间),每个物体实例由类别、边界框和接地描述构成。该模块通过分层设计实现跨时间和视角的场景描述生成,为视频和 LiDAR 生成提供细粒度语义引导,提升生成内容的可控性与语义保真度。
视频生成模型
如图2中camera_branch,视频生成模块致力于实现多视角视频的连贯生成,其核心是在基于DiT的扩散主干网络基础上,通过引入3D感知潜在编码和场景级先验条件来保障空间对齐、时间一致性与语义保真度。具体而言,首先构建包含车道段、人体姿态关键点和3D车辆边界框的结构化BEV布局,将其投影到各视角2D图像平面形成语义控制图,再通过Control-DiT模块的交叉注意力机制在每个去噪时间步融入这些结构化先验,实现对生成过程的引导。同时,利用YOLOv8x-Pose检测行人姿态并投影到各视角,以此增强动态场景的语义表达。在潜在编码方面,借助3D变分自编码器将多帧BEV草图压缩为潜在表示,解码器从去噪词元中重建BEV语义,通过交叉熵损失、KL散度和Lovasz损失的联合优化,确保语义信息的准确捕捉。此外,通过DataCrafter模块生成的场景描述经T5编码器处理为文本嵌入,与BEV草图编码后的特征共同作为条件输入DiT块,通过交叉注意力实现高层语义对生成的调制。最后,模块集成的语义对齐控制Transformer通过控制注意力将语义特征注入扩散块早期阶段,并结合空间自注意力、跨视角注意力和时间注意力机制,全面保障多视角视频生成的时空连贯性与语义保真度。
激光雷达生成模型
如图2中lidar_branch,激光雷达生成模块致力于生成几何精确且时空连贯的点云序列,通过点云自动编码器与时空扩散模块的协同设计,结合跨模态语义条件实现多传感器数据的一致性生成。其核心架构如下:首先,点云自动编码器将稀疏点云体素化为BEV网格,利用Swin Transformer骨干网络压缩为潜在特征,再通过Swin解码器与NeRF渲染模块重建点云,过程中采用空间跳跃算法减少空网格误差,并通过深度L1损失、占用损失和表面正则化损失优化训练,同时引入后处理过滤噪声点。时空扩散模块以自动编码器的潜在特征为基础,采用双DiT网络结合ControlNet架构,集成场景描述、道路草图等语义条件,以及3D边界框几何条件;为保证跨模态一致,通过LSS算法将视频分支的RGB图像转为BEV特征,与道路草图特征拼接后输入ControlNet。扩散过程中,潜在词元通过交叉注意力融合语义与几何嵌入,并利用STDiT-Block-L的多头自注意力机制维持时间序列的几何连贯性,整体采用整流流调度提升生成质量。该模块通过BEV特征压缩与NeRF渲染解决点云稀疏性问题,借助跨模态条件实现视觉与几何模态的空间对齐,为自动驾驶多传感器数据生成提供了兼顾几何精确性与语义一致性的解决方案。
实验结果
视频生成结果

在无首帧条件设定下,本文的方法实现了83.10的多帧FVD和14.90的多帧FID,优于DriveDreamer-2、MagicDrive-V2和Drive-WM等先前的工作。在有首帧条件设定下,本文的方法进一步提升至16.95的FVD和4.24的FID,与MiLA 相比展现出具有竞争力的结果,同时保持了时间一致性和结构保真度。在噪声潜在设定下,在6019个样本上实现了67.87的FVD和6.45的FID,超过了UniScene报告的先前最佳结果。
LiDAR 生成结果

表2报告了先前最先进的方法与本文提出的Genesis框架在激光雷达序列生成性能方面的定量比较。评估遵循HERMES 的设定进行,在水平面−51.2, 51.2米以及高度−3, 5米的空间范围内,使用 Chamfer distance作为主要指标。在短期和长期预测方面,Genesis始终优于现有方法。在预测时长为1秒时,它的 Chamfer distance达到0.611,比之前的最佳值(HERMES 的0.78)高出21%。在预测时长为3秒时,优势扩大到相对减少45%(从1.17降至0.633)。
下游任务实验

本文的方法在多个下游感知任务上评估了生成数据的效用。如表5所示,本文的方法在BEVFormer 3D目标检测中取得了最佳的平均交并比(38.01)和平均精度均值(27.90)。如表 6 所示,本文评估了生成数据在 BEVFusion 3D目标检测框架上的有效性。在所有设置中,本文的方法都取得了一致的改进,mAP 从 66.87 提高到 67.78,NDS从 69.65 提高到 71.13。摄像头和激光雷达模态的联合生成实现了的最高增益(+0.91 mAP / +1.48 NDS),证明了多模态生成的互补优势。
定性结果

图4:LiDAR 和多视角视频的联合生成。以路口布局为条件,生成空间对齐的激光雷达和摄像机视图。

图5:视频生成的定性比较。从上到下:(1) GT,(2) Road Sketch,(3) Panacea,(4) MagicDrive,(5) Ours。
Panacea存在幻觉纹理和几何对齐错误的问题。MagicDrive出现车辆变形和结构损坏的情况。相比之下,本文的方法保留了准确的布局、物体形状和背景完整性。

图6:昼夜的可控生成。通过改变场景级条件,本文的方法可以生成与同一基础地图和物体布局对齐的一致多视图视频。

图7:以轨迹为条件的新颖视图合成。给定地面真实轨迹(中),本文通过将自我路径右移 4 米(下)来修改布局(上)。在这些布局变化下,本文的模型在所有视图中生成了合理且一致的场景。
#X-Scene
浙大最新!具有高保真度和灵活可控性的大规模驾驶场景生成!AutoVLA
- 论文标题:AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
- 论文链接:https://arxiv.org/abs/2506.13757
- 项目主页:https://autovla.github.io/

核心创新点:
1. 统一的自回归模型架构
- 创新点 :首次将视觉-语言模型(VLM)与物理动作标记(Physical Action Tokens)直接集成,构建端到端的自回归规划策略框架,避免中间表示破坏端到端优化范式。
- 技术细节 :通过预训练的VLM主干(如Qwen2.5-VL)直接学习动作序列生成,联合优化高阶场景推理(Scene Reasoning)与低阶轨迹规划(Trajectory Planning)。
2. 双模式自适应推理机制
- 创新点 :提出"快思考"(Fast Thinking)与"慢思考"(Slow Thinking)的双推理模式,自适应切换以应对不同复杂度场景。
- 快思考 :直接生成轨迹(Direct Trajectory Generation),适用于简单场景。
- 慢思考 :基于链式思维(Chain-of-Thought, CoT)的复杂推理,用于处理长尾或交互密集场景。
- 实现方式 :通过监督微调(Supervised Fine-Tuning, SFT)联合训练轨迹数据与CoT推理数据,赋予模型"双过程能力"(Dual-Process Capability)。
3. 强化微调策略(RFT)与Group Relative Policy Optimization (GRPO)
- 创新点 :引入强化微调 (Reinforcement Fine-Tuning, RFT),通过惩罚冗余推理和对齐奖励函数优化策略,提升性能与效率。
- 技术细节 :
- 设计组相对策略优化 (GRPO)算法,计算组内相对优势(Relative Advantage)以指导策略更新。
- 目标函数包含策略梯度项(Policy Gradient)与KL散度正则化项,平衡探索与利用。
4. 物理动作标记化与可行动性约束
- 创新点 :提出物理感知动作标记化 (Physical Action Tokenization),将动作空间(如加速度、转向角)离散化为可学习的标记,确保生成轨迹的物理可行性。
- 优势 :避免传统方法依赖下游规划器生成轨迹的复杂性,直接输出符合动力学约束的动作序列。
5. 高质量推理数据集与自动化标注
- 创新点 :构建大规模、多模态的驾驶推理数据集 ,覆盖nuScenes、CARLA等真实与仿真场景。
- 技术实现 :
- 使用Qwen2.5-VL-72B模型自动生成高精度CoT标注(场景描述、关键物体识别、意图推理、动作决策)。
- 支持知识蒸馏(Knowledge Distillation),将大模型能力迁移至轻量化模型。
6. 实验验证与泛化能力
- 成果 :在nuPlan、Waymo、CARLA等真实与仿真数据集的开环/闭环测试中,AutoVLA在规划性能(如碰撞率、轨迹平滑度)与推理效率(减少冗余计算)上均达到SOTA。
- 核心优势 :通过自适应推理 (Adaptive Reasoning)显著降低简单场景的推理延迟,同时保持复杂场景的高精度规划。
X-Scene
- 论文标题:X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
- 论文链接:https://arxiv.org/abs/2506.13558
- 项目主页:https://x-scene.github.io/

核心创新点:
1. 多粒度可控生成框架 (Multi-Granular Controllability)
- 双模控制机制:
- 高层语义引导:用户自然语言提示经LLM(如GPT-4o)增强为结构化场景描述 ,包含场景风格、对象属性及空间关系(场景图 )。
- 底层几何约束 :支持用户直接输入布局图或通过文本驱动布局生成模块(Scene-Graph-to-Layout Diffusion)自动生成精确的3D包围框与车道线。
- RAG增强泛化:基于FAISS构建场景描述记忆库 ,实现少样本检索与上下文感知的场景生成(式1)。
2. 几何-外观联合生成与对齐 (Joint Geometry-Appearance Fidelity)
- 三平面形变注意力机制 (Triplane Deformable Attention):
- 提出新型三平面编码器(式2),通过可学习偏移 聚合多平面特征,解决降采样几何信息丢失问题,提升3D语义占据(Semantic Occupancy)重建精度(表1:mIoU 92.4%,较UniScene +19.5%)。
- 3D感知图像生成:
- 级联生成流程:3D占据栅格 → 渲染语义/深度图 → 引导多视角图像扩散模型。
- 引入对象位置嵌入 强化几何对齐,确保2D图像与3D结构一致性(图5)。
3. 一致性感知的大场景外推 (Consistency-Aware Large-Scale Extrapolation)
- 三平面外推算法 (Triplane Extrapolation):
- 将3D场景扩展分解为三正交平面外推,通过重叠掩码 同步参考区域与新区域去噪过程(式3),保障空间连续性(图3a)。
- 视觉连贯图像外推:
- 融合参考图像 与相机位姿嵌入 微调扩散模型,解决跨视角外观不一致问题(图3b)。
- 大规模场景重建 :生成结果可转换为3D高斯表达(3DGS),支持自由视角渲染与仿真应用(图4,9)。
4. 性能优势 (Quantitative Superiority)
- 占据生成 :17类设定下FID³ᴰ=258.8 (较UniScene↓51.2%),F-Score=0.785(表2)。
- 图像生成 :448×800分辨率下BEV分割mIoU=69.06 %(道路类),NDS=34.48(表3)。
- 下游任务 :生成数据训练3D检测器mAP=28.2 %(较MagicDrive↑15.9%),语义占据预测IoU=37.1%(表4,5)。
RelTopo
- 论文标题:RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
- 论文链接:https://arxiv.org/abs/2506.13553

核心创新点:
1. 关系感知的车道检测器
- 几何偏差自注意力(Geometry-Biased Self-Attention, GBSA)
将车道间的几何关系(如最小端点距离、角度差异)编码为注意力偏置,通过正弦嵌入和MLP生成高维几何关系特征,显式建模车道间的平行性、连通性等空间结构。 - 曲线引导交叉注意力(Curve-Guided Cross-Attention, CGCA)
基于Bézier曲线参数化车道,通过采样曲线上点作为参考位置,利用共享车道查询动态生成偏移量和权重,聚合长程上下文信息,解决稀疏控制点的特征提取难题。
2. 几何增强的L2L拓扑推理模块
- 多模态关系嵌入
融合车道特征(MLP生成的前驱/后继嵌入)与几何距离特征(端点到起点距离的MLP编码),构建高维L2L关系嵌入(GL2L),降低对微小感知误差的敏感性。 - 端到端优化
直接通过MLP预测拓扑关系,避免传统方法依赖后处理(如TopoLogic的几何距离拓扑后修正)。
3. 跨视图L2T拓扑推理模块
- BEV-FV特征对齐融合
将BEV车道投影至前视图(FV)图像空间,提取对应FV特征并与BEV车道查询融合,结合位置编码(PE)对齐空间关系,解决BEV车道与FV交通元素(如红绿灯、标志)的空间表征差异问题。 - 双视角关系嵌入
通过广播拼接生成L2T关系嵌入(GL2T),联合BEV和FV信息实现鲁棒的车道-交通元素关系推理。
4. 对比学习策略
- InfoNCE损失优化
引入对比学习,增强模型区分正负样本对(连通/非连通)的能力。通过硬负样本挖掘(Top-n hardest negatives)和对称损失函数(Symmetric InfoNCE Loss),提升拓扑关系嵌入的判别性。
#大家都对这个感兴趣
2024年第一季度,Waymo、清华AIR等机构密集投下VLA技术"核弹":
- DriveVLM (CVPR'24)以视觉语言大模型重构感知架构,在nuScenes数据集上实现84.3%的开放场景识别准确率,超越传统方法37个百分点
- VAD(ICLR'24 Spotlight)用语言指令替代人工编码规则,让自动驾驶系统真正理解"施工路段缓行"等模糊语义
- GAIA-1 (奔驰合作项目)更直接构建世界模型 ,实现对车辆变道时机的生成式预判这些突破正在改写行业游戏规则 :特斯拉被曝用语言模型优化Occupancy Network,小鹏城市NGP紧急引入视觉语义融合模块------当算法不再依赖标注数据暴力穷举,VLA正成为L4落地的关键破局点。
学习圈子近期调研了大家感兴趣的内容,VLA是很多小伙伴提到的关键词,以下是部分的整理内容 :
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
尽管端到端自动驾驶取得了显著进展,但在罕见和长尾的情况下,其性能会显著下降。近期研究尝试通过视觉语言模型(VLM)知识缓解该问题,但存在三大局限:
领域鸿沟:VLM预训练数据与真实驾驶场景差距显著
维度失配:离散语言空间与连续动作空间难以对齐
行为偏差:模仿学习易捕捉数据集中次优(甚至危险)的平均行为
本文提出ReCogDrive创新框架,采用三阶段训练范式:
阶段1:用驾驶QA数据集训练VLM,弥合通用知识与驾驶场景的差异
阶段2:扩散规划器将语言空间映射为连续驾驶动作
阶段3 :基于NAVSIM模拟器的强化学习微调,生成更安全、拟人化轨迹 在NAVSIM基准测试中达到89.6 PDMS,刷新SOTA记录(提升5.6 PDMS)

Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
为解决VLA模型在非结构化极端场景的表现瓶颈,本研究提出Impromptu VLA数据集:
数据规模:从200万+开源片段中提炼8万+精选视频
创新分类:基于4类非结构化场景构建(如极端天气/复杂交互)
多模态标注:含驾驶决策QA注释 + 动作轨迹
核心突破:
性能提升:在NeuroNCAP闭环测试中显著降低碰撞率,nuScenes开环预测达SOTA级L2精度
诊断价值:QA套件揭示VLM在感知/预测/规划的全面优化

DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
痛点揭示:
E2E-AD需处理多视角传感数据与复杂场景(如激进转弯)
现有关键模型易受模态平均效应干扰
技术创新:
构建双级MoE架构DriveMoE:
- Vision MoE:训练路由器动态选关键摄像头(模拟人类选择性注意力)
- Action MoE:激活专家模块处理专项驾驶行为
基于VLA基线Drive-π0(源自xx智能领域)升级
实验成果:
Bench2Drive闭环测试达SOTA性能验证视觉/动作双MoE在AD任务有效性

#在全球AI顶会展示下一代自动驾驶模型
垃圾国产家电车又开始吹了~~~
首个转型AI公司的新势力
L3 级别智能驾驶的关键:大算力、大模型、大数据。
端到端智能驾驶,正在沿着大模型 Scaling Laws 的道路狂奔。
上周三,全球首款 L3 级算力「AI 汽车」小鹏 G7 正式亮相,其首发搭载的三颗自研图灵 AI 芯片,超过 2200TOPS 有效算力,本地部署的 VLA+VLM 模型等特性引发了关注。
基于超高端侧算力,小鹏 G7 行业首发了智驾大脑 + 小脑 VLA-OL 模型,第一次给智能辅助驾驶加入了「运动型大脑」的决策判断能力。

小鹏 G7 同时首发了 VLM(视觉大模型),它可以作为车辆理解世界的 AI 大脑,将会是人与汽车交互的新一代入口。作为车辆行动的中枢,可以指导智能辅助驾驶和智舱等整车能力,未来还可以实现本地聊天、主动服务、多语言等功能。
同样是在上周,美国纳什维尔举行的全球计算机视觉顶会 CVPR 2025 上,小鹏作为唯一受邀的中国车企分享了其自动驾驶基座模型的研发进展。

小鹏自去年 5 月就宣布了量产端到端大模型上车,并构建了从算力、算法到数据的全面体系。今年 4 月,小鹏官宣正在研发下一代自动驾驶基座模型。今年的 CVPR 上,小鹏首次对外晒出了其世界基座模型的技术细节。
小鹏世界基座模型负责人刘先明展示了基座模型在真实城市环境复杂路面的控车能力。在没有任何规则代码托底的情况下,AI 面对复杂路口可以实现正确变道绕行,避开侵入车道的大货车,再避让逆行的自行车:

在经过施工区域前,它能提前绕行避障:

还可以完成一连串的复杂动作:直行道上,前方大车切出后,看到临停车变道绕行;遇到突然横穿马路的电动摩托车,成功避让;左侧忽然有一辆大货车加塞,减速灵活应对。

尽管只是在后装算力的车辆上用早期版本的模型进行测试,小鹏自动驾驶基模已经展现出令人惊叹的智能和拟人水平。
今年的 CVPR 大会上,与小鹏共同登台的是 Waymo、英伟达、UCLA、图宾根大学等工业界、学术界的自动驾驶顶流。看起来,小鹏的智能驾驶已走到了业界领先的位置,其智能驾驶体系开始在主流 AI 圈层「上桌吃饭」。
从端到端到世界模型
开启智能驾驶下一个 Level
过去几年,在智驾和智能座舱上,我们都见证了不少新功能的上线,但不论是城市范围的智能驾驶,还是让汽车有了「人的温度」的座舱语音助手,其进步都往往体现在细节能力的横向扩展,从智能化的高度来看,纵向的提升却不明显。
ChatGPT 引爆的新一轮 AI 技术跃进,让基于端到端的全新技术范式,逐渐成为了驾驶通向 L3、L4 智能驾驶的敲门砖。
整个智能驾驶行业在 L2 阶段已经停留太久。小鹏认为,「大算力 + 大模型」时代的到来,已为整个行业的 L3 进阶铺好了基石。
小鹏汽车董事长何小鹏在前几天的 G7 新车发布会上指出,迈向 L3 级算力 AI 汽车需要满足两个前提条件:本地有效算力大于 2000TOPS,在本地部署 VLA+VLM 大模型。为此,他们很早就开始布局自动驾驶基座模型赛道,并构建了从算力、算法到数据的全面体系,在新方向上一直保持着领先的身位。
在 CVPR 2025 的自动驾驶研讨会 WAD(Workshop on Autonomous Driving)上,刘先明发表了题为《通过大规模基础模型实现自动驾驶的规模化》(Scaling up Autonomous Driving via Large Foudation Models)的演讲,介绍了小鹏自研业界首个超大规模自动驾驶基座模型的历程,还披露了其在模型预训练、强化学习、模型车端部署、AI 基础设施搭建方面的一系列探索。
在发布 G7 时,小鹏表示「大算力 + 物理世界大模型 + 大数据」将共同定义未来「AI 汽车」的能力上限,其中的「物理世界大模型」正是刘先明团队研发的自动驾驶基座模型。
对于自动驾驶来说,如何能够保证行驶的安全、稳定,让 AI 系统在出现「前所未见」情况时能够做出正确决策,一直是技术的最大挑战。基于世界基座模型的新一代架构,为业界带来了希望。
今年 4 月,小鹏汽车首次披露了自身的下一代自动驾驶基座模型。该云端基础模型参数规模达到 720 亿,目前训练数据已超过 2000 万条视频片段(每条时长 30 秒)。它以大语言模型为骨干,使用海量优质多模态驾驶数据进行训练,具备视觉理解、链式推理(CoT)和动作生成能力。通过强化学习(RL)后训练,它可以不断自我进化,逐步发展出了更全面、更拟人的自动驾驶技术。
世界基座模型的一大优势是具备 CoT 能力。就像 DeepSeek R1 在回答问题时展示的「强推理」过程一样,自动驾驶的 AI 模型也能在充分理解现实世界规律的基础上,像人类一样进行相对复杂的常识推理,做出行动决策,如输出打方向盘、刹车等控制信号,实现与物理世界的交互。

这大幅提升了自动驾驶的能力。现在 AI 在遇到复杂、危险或特别少见(训练时未见过)的场景时,能够进行条理清晰的逻辑推理,正确分析道路交通环境,关注到对自车行为有影响的关键目标、交通信号灯等指示,并对自身下一步决策作出推理,随后形成动作规划,生成下一步的轨迹。
如果说传统的自动驾驶模型是负责「开车」这项运动的「小脑」,基于大语言模型和海量优质数据训练的新一代基座模型,则是同时具备开车和思考能力的「大脑」------ 它能像人类一样主动思考并理解世界,丝滑地处理训练数据中未见过的长尾场景(corner case),相比上代基于大量内嵌规则的智能驾驶更加安全,更具可解释性,驾驶风格也更加拟人化。
有了「云端超级大脑」,接下来的挑战,就是让它在车辆端侧高效运行。
由于车端算力的限制,能够部署上车的 AI 模型必须经过剪枝、蒸馏等方法进行压缩,目前业界主流的车端模型参数一般在几百万到十亿级别。如果比照车端算力的容量直接训练小模型,模型的性能上限会受到极大限制,更无从实现 CoT 等能力。
小鹏选择了蒸馏的技术路线,先在云端「不计成本」地训练大规模基座模型,再通过蒸馏的方式压缩以适配车端算力,通过知识迁移的方式最大限度保留基模核心能力,帮助车端模型提升性能。
「云端基座模型 + 强化学习的组合,是让模型性能突破的最好方法。云端基座模型好比一个人天生的智商,强化学习好比能力激化器,用来激发云端基座模型的智力潜能,提高基模的泛化能力,」刘先明表示。

在基座模型完成预训练、监督精调(SFT)之后,模型会进入强化训练阶段。小鹏开发了自己的强化学习奖励模型(Reward Model),主要从安全、效率、合规三个方向提升模型能力。
「这也是人类驾驶行为中的几个核心原则,遇到不认识的障碍物要绕行,这是为了安全;路上遇到特别慢的车,适时变道超车,可以提高效率;按照红绿灯、车道线、道路标牌的指示开车,这是合规,」刘先明表示。
在这个阶段,小鹏以往辅助驾驶能力的研发经验也被用于设计强化学习的奖励函数,转化成了新的生产力。
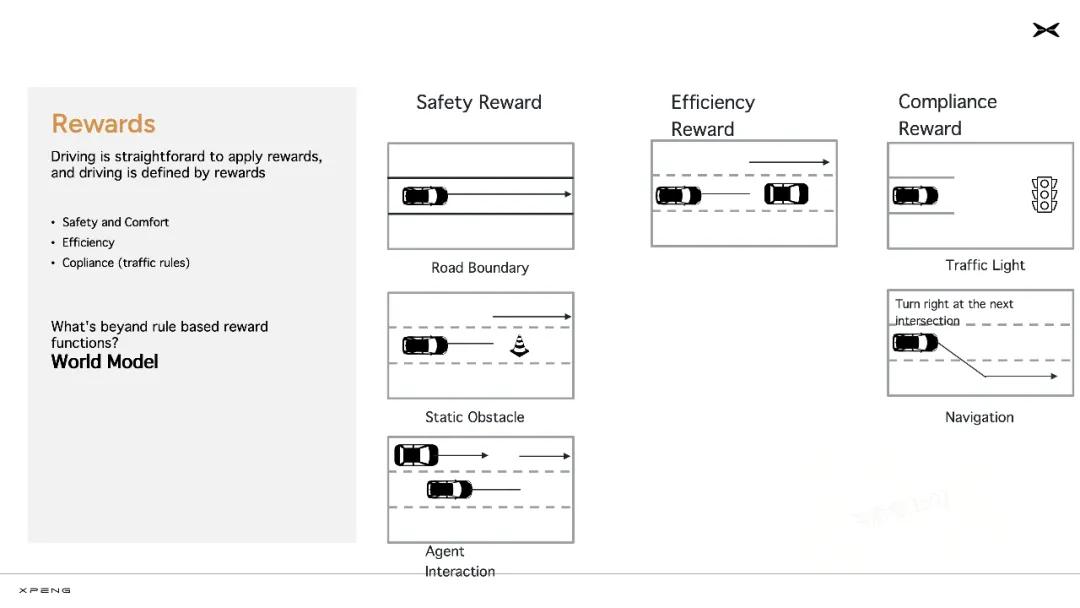
为了进一步提升自动驾驶的能力,提升泛化性,自动驾驶系统还需要接入世界模型。
小鹏自动驾驶团队正在开发世界模型(World Model),未来计划将其用作一种实时建模和反馈系统,基于动作信号模拟出真实环境状态,渲染场景,并生成场景内其他智能体(也即交通参与者)的响应,从而构建一个闭环的反馈网络,帮助基座模型进行强化学习等训练。
也就是说,小鹏训练好之后的基座模型并不是静态的,它会持续学习、不断迭代提升。
小鹏汽车的基座模型迭代过程分成内、外两个循环,内循环是指包含预训练、后训练(包括监督精调 SFT 和强化学习 RL)和蒸馏部署的模型训练过程;外循环,是指模型在车端部署之后,持续获取新的驾驶数据和用户反馈,数据回流云端,继续用于云端基模的训练。

说到世界模型,最近越来越多的 AI 研究者已经把它摆在了「通向 AGI 方向」的位置。图灵奖得主 Yann LeCun 认为,世界模型是 AI 系统用于模拟和理解外部世界运作方式的内部模型。基于世界模型,AI 系统可以不断适应新的动态环境,并高效地学习新技能。
Google DeepMind 近日提交的一份研究甚至证明:如果一个大模型智能体能够处理复杂、长期的任务,那么它就一定学习过一个内部世界模型,越是通用的 AI,就学习得越精确。大模型和世界模型的发展,或许是殊途同归。
小鹏在智能驾驶上的实践,可以说提前判断到了正确方向。未来,小鹏还将用这套技术赋能 AI 机器人、飞行汽车等设备。
转型 AI 公司
验证自动驾驶的 Scaling Laws
如果说端到端、世界模型是智能驾驶通向下一阶段的方向,那么 AI 规模的扩展则可以说是验证这一路线的核心标尺。
过去两年半时间里,AI 性能的提升很大程度上得益于规模的扩展。大模型第一性原理扩展定律(Scaling Laws)不断获得验证,已经让 AI 在很多领域中获得了接近甚至超越人类的能力。
进入大模型时代的自动驾驶又是如何?
近日,Waymo 使用大量内部数据进行了一项全面的研究,发现与大语言模型(LLM)类似,自动驾驶过程中 AI 对于运动预测的质量也遵循训练计算的幂律 ------ 模型参数规模扩大、训练数据量的扩展、大规模的并行计算对于提高模型处理更具挑战性的驾驶场景的能力来说至关重要。

图片来自 Waymo。
其实小鹏此前在构建智驾系统时,也清晰地观察到了 Scaling Laws 显现。他们是大模型浪潮以来,行业内首个基于大规模量产车队和海量真实用户数据,对自动驾驶 Scaling Laws 做出验证的研发团队。

事实上,小鹏很早就启动了向 AI 公司转型的进程。
小鹏自 2024 年开始布局 AI 基础设施,建成了国内汽车行业首个万卡智算集群,用以支持基座模型的预训练、后训练、模型蒸馏、车端模型训练等任务。这套从云到端的生产流程被称为「云端模型工厂」,拥有 10 EFLOPS 的算力,集群运行效率常年保持在 90% 以上,全链路迭代周期可快至平均五天一次。
如此算力规模和运营效率,堪比头部 AI 企业。
从行业的视角看,我们或许可以从特斯拉 FSD 领先的能力中窥见大规模 AI 基础设施的重要性。但在造车新旧势力中,目前拥抱 AI、敢于投入大量资源的玩家尚不多见。
这其中有机遇,必然也意味着挑战。刘先明表示,比起大语言模型,自动驾驶基座模型的研发更复杂、更具挑战性。自动驾驶的训练数据模态更多、信息量多出几个数量级,对于自动驾驶任务来说,所有技术都要基于对物理世界的认知进行从头验证。
敢于转型 AI 公司的玩家,必须要做到长期大规模投入,并发展出完善、高效率的技术栈。
在 CVPR 大会现场,小鹏揭秘了两个核心数据:
小鹏的云上基模在训练过程中已处理超过 40 万小时的视频数据;
其流式多处理器的利用率(streaming multiprocessor utilization)已达到 85%。
前者验证了小鹏的数据处理能力,后者是指 GPU 的核心计算单元的运行效率,是评判计算资源使用效率的重要指标。据业内人士评估,85% 的利用率数字基本摸到了行业天花板,在大模型圈内也属于顶尖水平。
刘先明透露,小鹏对标业内领先 AI 公司的标准,从头搭建了自己的数据和 AI 基础设施,有充分的信心做到行业前列。他从云端模型训练和车端模型部署两个层面,分别介绍了自动驾驶团队提升模型训练效率的方法。

在模型训练层面,研发团队分别对 CPU、GPU 的效率、容错性等方面进行联合优化,着重解决数据加载、并行通信等瓶颈问题。在 CPU 的利用上,团队启用了额外 CPU 节点提升数据加载能力,对 PyTorch 进行定制化,采取了激进的数据物化策略,并通过优化打乱模式,在速度与随机性之间取得了平衡。
在 GPU 计算资源的利用上,研发团队使用 FSDP 2 实现了模型分片,使用 FP8 混合精度进行训练,自定义了 Triton 内核,并引入了 Flash Attention 3 加快计算速度。
到了模型部署层面,小鹏为 AI 大模型定制的「图灵 AI 芯片」、全链路调优的优势进一步显现。在 G7 新车落地的过程中,模型、编译器、芯片团队针对下一代模型开展联合研发,比如定制 AI 编译器以最大化执行效率,协同设计硬件、量化友好的模型架构,确保软硬件充分耦合,最终「榨干」了车端算力。
「车端计算负载的重要来源是输入 token 数量。以配备 7 个摄像头的 VLA 模型为例,每输入约两秒视频就会产生超过 5000 token。我们一方面要压缩输入中的冗余信息,降低计算延迟。另一方面要确保输入视频的长度,以获得更丰富的上下文信息,」刘先明介绍道。
小鹏团队为此专门设计了针对 VLA 模型的 token 压缩方法,可在不影响上下文长度的情况下,将车端芯片的 token 处理量压缩 70%。
从「软件开发汽车」走向「AI 开发汽车」
从 AI 基础设施做起,进行全链路优化,打造高度自研的体系,这条路线或许会成为未来自动驾驶技术向上突破的范式。
更长远地看,在转型成为 AI 公司之后,逐渐理解世界的通用化模型不仅能服务自动驾驶,也能够为更多全新的自动化能力打开想象空间。或许正如黄仁勋所说的,在不远的未来,AI 芯片的集群将不再是芯片,而会化身为「思考机器」,实现自我思考、自我进化。
小鹏 G7 发布时,何小鹏就透露道,就在今年内,G7 还会拥有「极其重大」的新功能。
期待 AI 进化的下一个节点。
#JarvisIR
感知性能飙升50%!JarvisIR:VLM掌舵,为自动驾驶装上"火眼金睛",不惧恶劣天气
JarvisIR 是首个将视觉语言模型(VLM)作为控制器的智能图像恢复系统,通过动态调度多个专家模型,有效提升了自动驾驶在恶劣天气下的感知性能,平均指标提升达 50%。该研究还构建了大规模数据集 CleanBench 并提出 MRRHF 对齐算法,解决了真实场景下数据无标签的训练难题。
论文链接:https://arxiv.org/pdf/2504.04158
项目主页:https://cvpr2025-jarvisir.github.io/
Github仓库:https://github.com/LYL1015/JarvisIR
Huggingface Online Demo: https://huggingface.co/spaces/LYL1015/JarvisIR

背景与动机
在自动驾驶等现实应用场景中,视觉感知系统常常受到多种天气退化(如雨、雾、夜间、雪)的影响。传统的单任务方法依赖特定先验知识,而 all-in-one 方法只能解决有限的退化组合同时又存在严重的领域差异,难以应对复杂的实际场景。
为了解决这一问题,研究团队提出了 JarvisIR ------ 一个基于视觉语言模型(VLM)的智能图像恢复系统。该系统通过 VLM 作为控制器,动态调度多个专家模型来处理复杂天气下的图像退化问题,从而实现更鲁棒、更通用的图像恢复能力。

核心贡献
- 提出 JarvisIR 架构:首个将 VLM 作为控制器的图像恢复系统,能够根据输入图像内容和用户指令,自主规划任务顺序并选择合适的专家模型进行图像修复。
- 构建 CleanBench 数据集:包含 150K 合成数据 + 80K 真实世界数据,涵盖多种恶劣天气条件,支持训练与评估。
- 设计 MRRHF 对齐算法:结合监督微调(SFT)与基于人类反馈的人类对齐(MRRHF),提升模型在真实场景下的泛化能力和决策稳定性。
- 显著性能提升:在 CleanBench-Real 上平均感知指标提升 50%,优于现有所有方法。
🛠️ 方法详解
- JarvisIR 架构设计
JarvisIR 的核心思想是将视觉语言模型(VLM)作为"大脑",协调多个专家模型完成图像恢复任务。其工作流程如下:
- 任务解析:接收用户指令和输入图像,分析图像中的退化类型。
- 任务规划:根据图像内容和用户需求,生成最优的任务执行序列。
- 模型调度:依次调用对应的专家模型(如去噪、超分、去雨等)进行图像恢复。
- 结果整合:将各阶段的结果整合为最终输出图像,并附上解释性推理过程。

可参考论文图4理解整体流程。
- CleanBench 数据集
CleanBench 是本文的核心训练与评估数据集,分为两个部分:
- CleanBench-Synthetic:150K 合成数据,用于监督微调(SFT)阶段训练。
- CleanBench-Real:80K 真实世界图像,用于 MRRHF 阶段的无监督对齐训练。

可参考论文图2理解CleanBench构建的过程。

可参考论文附录图8了解构建数据所用到的合成退化库。
该数据集涵盖了四种主要天气退化场景类型:夜景、雨天、雾天、雪天。注意每个退化场景中可能包含多种退化(比如夜晚可能是暗光、噪声、雾、低分辨率)。
📚 数据构成
每条训练样本是一个包含三个元素的三元组:
其中:
- :用户指令(instruction),描述希望执行的图像恢复任务;
- :退化图像(degraded image),即待处理的原始图像;
- :响应(response),包含了 Chain-of-Thought(COT)推理过程和最终选定的任务序列及模型选择。
例如:
- 指令:"请改善这张夜晚拍摄的照片质量。"
- 退化图像:一张夜间低光模糊照片;
- 响应:先进行低光增强,再进行去噪,使用的模型为
Img2img-turbo和SCUnet。

合成的退化样本。
- 两阶段训练框架第一阶段:监督微调(SFT)
在 JarvisIR 的整体训练流程中,监督微调(SFT)是第一阶段的核心任务。其目的是让视觉语言模型(VLM)初步掌握如何:
- 理解用户输入的图像恢复指令;
- 分析图像中的退化类型(如雨、雾、夜景等);
- 规划合理的恢复任务顺序;
- 选择正确的专家模型组合进行图像修复。
这个阶段使用的是 CleanBench 数据集中的合成数据部分(CleanBench-Synthetic),这些数据具备完整的标注信息(即已知退化类型和最优恢复路径),因此适合用于有监督学习。SFT 的训练目标是最小化以下损失函数:
其中:
- 是第 条样本的真实响应;
- 是对应的用户指令;
- 是对应的退化图像;
- R_{\
- 是模型参数;
- 是响应 token 的总数量。
这是一个典型的自回归语言建模目标,鼓励模型根据给定的上下文(图像和指令)准确预测出期望的响应。
第二阶段: 人类反馈对齐(MRRHF)
在 JarvisIR 中,人类反馈对齐(Human Feedback Alignment) 是训练过程中的关键阶段。由于真实世界图像缺乏配对标注数据,传统的监督微调(SFT)无法直接应用于 CleanBench-Real 数据集。因此,研究者提出了一种基于奖励模型的无监督对齐方法:MRRHF(Mixed-Rank Reward-based Human Feedback)。
MRRHF 是 RRHF(Rank Responses to Align Human Feedback)的一种扩展,旨在通过结合离线采样与在线采样策略 、引入熵正则化项,提升 VLM 在真实世界恶劣天气图像恢复任务中的稳定性、泛化能力和响应多样性。
MRRHF 的核心组成
- 奖励建模(Reward Modeling)
MRRHF 使用多个基于 VLM 的 IQA(Image Quality Assessment)模型来构建一个统一的奖励函数:
其中:
- :第 个 IQA 模型对图像质量的评分;
- :该模型评分的历史均值与标准差;
- :参与评估的 IQA 模型数量(如 Q-instruct、MUSIQ、MANIQA 等)。
这个奖励函数用于衡量系统输出的图像恢复结果的质量,并作为训练信号指导 VLM 的优化。
- 混合采样策略(Hybrid Sampling Strategy)
为了在保持性能下限的同时扩展探索空间,MRRHF 结合了两种样本生成方式:
- 离线采样(Offline Sampling):使用 SFT 模型进行多样 beam search 生成多个候选响应。
- 在线采样(Online Sampling):使用当前训练中的 policy model 动态生成响应。
最终将两者合并为候选响应集合 ,从而在训练过程中提供更丰富的探索路径。
- 多任务损失函数
MRRHF 的目标是通过以下三种 loss 共同优化模型:
(1) 排名损失(Ranking Loss, )
作用:
- 鼓励模型对高奖励响应赋予更高的概率 ,低奖励响应赋予更低的概率。
- 通过对比不同响应的得分和模型预测概率,引导模型学习排序能力。
- 保证模型在面对多个可能响应时,能够选出最优解。
✅ 目的:让模型学会"好响应"比"坏响应"更好。
(2) 微调损失(Fine-tuning Loss, )
作用:
- 对于奖励最高的响应 ,强制模型学习其完整生成过程。
- 相当于一种强化学习中的"模仿学习",确保模型掌握最优响应的生成逻辑。
✅ 目的:让模型准确复现最高奖励的响应内容。
(3) 熵正则化损失(Entropy Regularization Loss, )
作用:
- 增加响应的多样性,防止模型陷入局部最优,只生成重复或保守的回答。
- 通过最大化输出分布的熵,鼓励模型探索更多合理的响应路径。
✅ 目的:增强模型的探索能力,避免过拟合单一响应模式。
总体损失函数
最终,MRRHF 的总体损失函数由三部分组成:
其中:
- :控制各 loss 权重的超参数(论文中设为 )。
这三部分 loss 协同工作,使得 JarvisIR 能够在没有人工标注的情况下,利用大量真实世界数据完成有效的对齐训练。

可参考论文图5理解两阶段的训练框架。
实验与结果分析1. 决策能力对比(CleanBench-Real 验证集)

✅ 结论:JarvisIR-MRRHF 在工具决策能力上显著优于其他策略。
- 图像恢复性能对比



✅ 结论:在所有天气场景下均优于现有 all-in-one 方法,提升显著(平均改善指标50%)。
- Ablation Study
- 样本生成策略对比:混合采样策略(结合离线和在线的优势)在奖励分数和响应多样性方面均表现最佳。它既能保证训练的稳定性,又能提供足够的探索空间,优于单纯的离线或在线采样。
- 熵正则化影响:加入熵正则化能显著提升系统响应的多样性,并有助于提高奖励分数。这是因为它鼓励模型进行更广泛的探索,产生更多样化的高质量响应。
- MRRHF 与 Vanilla RRHF 的对比: MRRHF 通过其混合样本生成和熵正则化策略,在奖励和多样性方面均显著优于 Vanilla RRHF。这表明 MRRHF 能更有效地利用人类反馈进行对齐。


技术亮点总结
- VLM 作为控制器:首次将视觉语言模型应用于图像恢复系统的控制中枢,具备强大的上下文理解和任务规划能力。
- 专家模型协同机制:多个专业模型按需调用,适应不同天气条件下的图像退化问题。
- 大规模真实数据集 CleanBench:填补了真实世界图像恢复数据的空白。
- MRRHF 对齐算法:无需人工标注,即可利用大量真实数据进行模型优化,提升泛化能力。
总结
JarvisIR 是一项具有开创性的研究成果,标志着图像恢复从单一任务向智能化、多模型协同方向迈进的重要一步。其核心价值在于:
- 将 VLM 用于图像恢复系统的控制
- 提出 MRRHF 对齐算法,解决真实数据无标签问题
- 发布高质量数据集 CleanBench,推动社区发展
如果你正在研究图像恢复、视觉语言模型或多模态系统,JarvisIR 提供了一个全新的视角和实践路径,值得深入学习与应用。
参考文献
1 JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
#FocalAD
北航:局部交互感知端到端规划新框架,碰撞率降低超过40%~
在端到端的自动驾驶中,运动预测在自车规划中起着关键作用。然而,现有方法通常依赖于全局聚合的运动特征,忽视了规划决策主要受一小部分局部交互代理影响的事实。未能关注这些关键的局部交互可能会掩盖潜在风险并削弱规划的可靠性。在本研究中,我们提出了FocalAD,一种新的端到端自动驾驶框架,该框架专注于关键的局部邻居,并通过增强局部运动表示来优化规划。具体而言,FocalAD包含两个核心模块:Ego-Local-Agents Interactor(ELAI)和Focal-Local-Agents Loss(FLA Loss)。ELAI执行基于图的自车中心交互表示,捕捉与局部邻居的运动动态,以增强自车规划和代理运动查询。FLA Loss增加了决策关键邻近代理的权重,引导模型优先考虑那些与规划更相关的代理。广泛的实验表明,FocalAD在开环nuScenes数据集和闭环Bench2Drive基准上优于现有的最先进方法。值得注意的是,在注重鲁棒性的Adv-nuScenes数据集上,FocalAD相比DiffusionDrive将平均碰撞率降低了41.9%,相比SparseDrive则降低了15.6%。
端到端的自动驾驶已成为一种有前景的范式,它通过完全可微分的统一模型直接将原始传感器输入映射到驾驶动作。在传统的模块化流水线中,感知、预测和规划通常作为独立组件处理,往往导致模块之间误差的累积。相比之下,端到端框架能够实现全局优化,从而提高鲁棒性和可解释性,并带来更简洁的架构。
在此范式中,自车轨迹规划仍然是核心且最具挑战性的任务,生成的轨迹质量严重依赖于对周围交通代理运动的准确建模。这一需求促使了各种不同的框架的产生,它们在结构预测和规划的方式上有所不同。顺序范式首先基于鸟瞰图(BEV)表示预测周围代理的未来运动,然后将这些预测传递给单独的规划模块。相比之下,并行框架则通过利用共享的感知特征同时生成规划和预测轨迹。这种设计允许运动预测和自车规划之间更加紧密的耦合,使得在动态环境中做出更加一致的决策。

尽管这些方法在规划性能上取得了进展,但它们通常依赖于全局聚合的运动特征,缺乏明确的机制来识别对自车决策最为关键的代理,如图1(a)所示。然而,在实际驾驶场景中,自车车辆的规划行为主要受到有限数量附近代理的影响,这些代理的运动对其决策具有直接而即时的影响。这些代理通常与自车车辆进行实时互动,例如合并、让行或交叉,因此构成了规划风险和约束的主要来源。对于端到端框架来说,缺乏交互感知建模会导致忽略重要的局部线索,损害模型在动态交通环境中的有效推理能力。结果,规划输出可能在解释性、可靠性和安全性方面有所下降,特别是在密集或复杂的环境中。
从经验丰富的驾驶员身上获得灵感,驾驶员直觉上会优先考虑附近的代理而非较远的代理。因此,我们认为端到端的自动驾驶方法应明确引导模型关注来自关键局部代理的运动线索,以优化自车轨迹生成。
在这项工作中,我们提出了FocalAD,这是一种端到端的自动驾驶框架,通过增强本地运动感知来加强自车规划,如图1(b)所示。这一改进是通过两个方面实现的:丰富包含交互感知特征的规划和运动查询,并引入焦点损失来引导训练期间对关键邻居运动特征的关注。具体而言,FocalAD集成了两个紧密耦合的模块。Ego-Local-Agents Interactor(ELAI)通过显式建模自车车辆与其局部邻居之间的运动动态,构建以自车为中心的交互表示。它专注于捕捉最相关于自车车辆决策过程的细粒度、局部化的交互。Focal-Local-Agents Loss(FLA Loss)引入了一种焦点监督机制,将模型注意力引向决策关键的代理。通过利用来自有影响力的邻居的运动线索,它在训练中强化高影响的交互,以优先考虑那些显著影响自车车辆未来轨迹的代理。这种表示和监督之间的协同作用提高了运动理解,从而改善了规划的安全性和可解释性。
在nuScenes和Bench2Drive上的实验结果表明,FocalAD优于基线。重要的是,在具有挑战性和复杂性的Adv-nuScenes数据集上,FocalAD将碰撞率相对于DiffusionDrive降低了41.9%,相对于SparseDrive降低了15.6%,突出了其在具有挑战性的驾驶场景中的卓越鲁棒性。这些结果验证了我们以焦点交互为中心的设计的有效性,并强调了交互感知学习在安全和稳健的自主规划中的价值。
相关工作回顾
端到端的自动驾驶取得了快速进展,研究重点逐渐从统一的感知-控制学习转向任务解耦和模块化的端到端设计。基于Transformer的架构通过将多视角图像投射到鸟瞰图(BEV)空间,显著改进了特征表示,从而实现了统一且高效的场景理解。
ThinkTwice强调了解码器在场景预测和风险评估等任务中的被忽视作用,提出了级联解码器设计,但仍然缺乏完整的端到端集成。UniAD通过基于密集BEV表示的规划导向端到端框架实现了感知和规划的联合优化。这种设计促进了各阶段之间的信息流动,从而提高了规划的整体性能。除了基于密集BEV的框架,VAD引入了一种矢量化场景表示方法,将道路边界、车道标记和代理轨迹编码为结构化向量,提高了可解释性和可控性,同时减少了冗余。SparseDrive引入了一种稀疏对称感知架构,仅编码关键代理和地图元素,并采用并行运动规划流水线,在不牺牲性能的情况下减少计算开销。除了架构上的并行性,PPAD通过在每个时间步交错规划和预测引入了时间并行性,实现了双向耦合,考虑了不断演变的代理交互。
为了增强多模态轨迹优化,VADv2引入了一种概率规划机制,将聚类的人类轨迹建模为分布,提高了未来场景的多样性和预测能力。DiffusionDrive在扩散框架内使用锚定高斯先验和两阶段去噪,以提高端到端驾驶中轨迹的准确性和可控性。GenAD通过使用变分自编码器(VAE)构建结构化潜在空间,并采用时间GRU更好地建模交互动态,将轨迹预测和规划制定为一个统一的生成建模任务。在交互感知场景理解的背景下,GraphAD提出了一种统一的基于图的框架,模拟自车车辆、周围代理和地图元素之间的空间关系。这种设计增强了交互推理并改善了决策质量。此外,FASIONAD++受认知双过程理论("快与慢思维")的启发,引入了一种双重系统架构,结合了快速端到端规划器和基于视觉语言模型(VLM)的较慢逻辑模块。
尽管先前的工作大幅提升了规划性能,但大多数框架仍依赖全局聚合的运动特征进行轨迹生成。然而,忽略局部交互可能会掩盖关键风险,导致次优或不安全的计划。为了解决这一问题,我们引入了FocalAD,这是一种端到端框架,利用来自关键局部交互的运动信息来优化规划决策。
算法详解
框架概述。与以往依赖全局聚合运动特征的方法不同,我们的 FocalAD 聚焦于一小部分局部代理,这些代理的行为对自车规划具有即时且显著的影响。为了捕捉并强调这些局部交互,FocalAD 建立了一种交互驱动的机制,该机制将特征表示与损失监督相结合。如图 2 所示,FocalAD 包含两个核心模块:(1) Ego-Local-Agents Interactor, ELAI通过图结构显式建模自车中心的交互。它捕捉了自车与其最相关的 Top-k 邻居之间的动态,从而为运动和计划查询生成结构丰富的特征。(2) Focal-Local-Agents Loss, FLA Loss根据邻居的交互得分和索引为其分配焦点权重,并应用交互引导的监督来优化邻居运动特征的学习。这形成了一种交互感知机制,通过将模型注意力与决策关键的运动线索对齐,持续优化运动和规划表示。

这些组件共同增强了 FocalAD 推理局部风险和理解动态驾驶环境的能力,从而提高了轨迹预测精度、规划鲁棒性和整体可解释性。
Ego-Local-Agents Interactor
自车-局部代理交互器(ELAI)旨在显式建模自车与其周围代理之间的局部交互,实现交互感知的自车规划。如图 3 所示,ELAI 包含四个主要步骤:状态提取、图嵌入、交互得分和 K-邻居选择。
状态提取
过程开始时,从检测输出中提取自车和代理的动态状态。每个代理(包括自车)由其运动学和位置特征表示,这些特征作为交互建模的初始输入。
图嵌入
为了构建交互图,我们首先将每个代理的个体运动状态编码为节点特征表示。具体来说,每个代理 的节点特征 计算如下:
其中 分别表示代理 的位置、大小和速度向量, 表示代理 的航向角。为了建模成对交互,

我们定义从每个代理 到自车的有向边,并计算相应的边特征:
其中 和 分别表示代理 相对于自车的相对位置、航向和速度。
交互得分
一个交互 Transformer 被用来计算自车与周围代理之间的成对交互得分,捕捉它们对自车决策的潜在影响。我们首先应用多头注意力机制来聚合局部交互特征,其中自车特征 被视为查询向量,每个代理结合的节点边特征形成键和值向量:
其中 MHCA 表示多头交叉注意, 表示自车中心的交互上下文。此上下文通过捕捉自车与代理之间的相对动态、空间关系和交互强度来编码与规划相关的运动语义。为了量化每个代理对规划的影响,一个多层感知机(MLP)处理其原始运动特征 、边特征 和共享的交互上下文 。它联合输出一个增强的特征表示 及其交互得分 ,表示该代理对自车决策的贡献:
K-邻居选择
通过交互得分识别出的 Top-k 最相关邻居,由集合 索引。相关的关键邻居特征表示为 ,代表关键邻居 的交互感知运动特征。为了纳入局部交互特征,每个代理的全局运动查询 使用来自重要邻居的交互感知修改进行细化,如下所示:
如果否则
其中 是一个缩放因子, 是通过对得分 应用 softmax 得到的注意力权重。为了加强规划查询中的局部交互表示,自车表示 通过与关键邻居特征 融合进行细化。
这个增强的自车表示捕捉了局部场景中的结构化交互语义,并作为下游计算的基础。使用更新后的 细化全局规划查询 :
其中 是缩放因子。
Focal-Local-Agents Loss
在前面的模块中,我们获得了 Top-k 关键邻居的信息表示。如图 4 所示,提出的焦点-局部代理损失(FLA Loss)引入了一种交互感知的训练策略,将运动监督与邻居特征学习联系起来,引导模型关注与决策相关的代理。

为了获得关键邻居的监督权重,我们对从前面模块获得的交互得分 应用 softmax 操作。这为每个邻居 生成归一化的焦点权重 。这些焦点权重反映了邻居对自车决策的估计影响。每个邻居 对应一个轨迹回归损失 ,根据其索引进行采样,并随后加权焦点系数 。整体 FLA Loss 定义如下:
该公式鼓励模型在训练期间关注决策关键的邻居,使更针对性的运动监督和交互感知特征细化成为可能。为了将焦点指导集成到整体训练目标中,最终的运动损失定义为标准全局运动损失和 FLA Loss 的组合:
与应用均匀权重的标准监督策略不同,FLA Loss 利用基于规划相关性的加权来增强复杂交互设置中的规划可靠性和训练效率。这种交互感知的监督解决了传统范式的这一关键限制,即通常缺乏对决策关键代理的针对性指导。结果,模型将关键邻居的运动与面向规划的特征细化结合起来,更好地捕捉关键交互。
实验
数据集与评估指标
nuScenes。对于开环评估,我们在 nuScenes 数据集上进行了广泛的实验,该数据集包含 1,000 个 20 秒的驾驶场景,并以 2 Hz 的频率进行标注。它提供了丰富的多模态传感器数据,包括每个关键帧的六个相机视角、3D 物体检测标签和高精度语义地图。
Bench2Drive。闭环评估是在 Bench2Drive上进行的,这是一个基于 CARLA 模拟器在 CARLA Leaderboard 2.0 协议下构建的大规模基准测试平台。它包含了超过 200 万帧,涵盖 44 种交互场景和 23 种天气条件,允许在复杂环境中对端到端规划进行真实且细粒度的评估。我们使用官方提供的 220 条路线进行评估。
Adv-nuSc。除了常规的开环和闭环评估外,我们还在 Adv-nuSc 数据集上进一步评估了模型的鲁棒性,该数据集是使用 Challenger 框架构建的。这个扩展的数据集基于 nuScenes 构建,专门设计用于揭示复杂交通条件下规划中的脆弱性。Challenger 框架生成了一系列激进的驾驶场景,例如突然切入、急转弯、尾随和盲区侵入,并将这些场景渲染成带有 3D 注释的逼真多视角视频。Adv-nuSc 包含 156 个安全关键场景(共 6,115 个样本),每个场景都旨在模拟高风险交互,以考验自动驾驶系统的决策能力。
规划评估指标 。对于规划评估,我们采用了两个常用的指标:L2 位移误差 (L2) 和碰撞率,两者均按照 SparseDrive中定义的协议计算,以确保与之前工作的可比性。
实现细节
为了捕捉自车周围的动态和静态实例,我们采用了一个基于 SparseDrive的稀疏感知模块。多视角图像由 ResNet-50骨干网络处理,输入图像大小为 256×704。提取的特征在每个时间步被聚合为交通代理和地图元素的实例级表示。对于交互建模,默认情况下选择的 Top-k 最相关邻居数量设置为 5,除非另有说明。为了评估鲁棒性,我们的模型在标准 nuScenes 训练集上按照常规实践进行训练,然后分别在对抗性的 Adv-nuSc 数据集上进行评估,以测试其在挑战性条件下的性能。
主要结果
nuScenes 结果。如表 1(a) 所示,FocalAD 在所有指标上均取得了最佳的整体运动预测性能,将 minADE、minFDE 和 MR 分别降低至 0.61m、0.95m 和 0.134。此外,FocalAD 达到了最高的 EPA 值 0.494,优于所有强基线方法。这些结果突出了我们局部交互建模的有效性,使得能够更准确和自信地进行多智能体轨迹预测。表 1(b) 进一步显示,FocalAD 实现了最低的平均规划误差 0.60m,以及极低的平均碰撞率 0.09%,展示了与最佳基线相当的性能。值得注意的是,FocalAD 在早期规划阶段表现出色,在 1s 和 2s 时达到了最低的 L2 误差,并完全消除了 1s 时的碰撞。尽管其 3s 性能在一定程度上略逊于 SparseDrive 和 DiffusionDrive,但仍具有竞争力。这些结果表明,FocalAD 显著提高了局部交互场景中的规划性能和安全性,特别是在短期决策任务中。

Bench2Drive 结果。在多能力基准测试(表 2)中,FocalAD 在所有五个关键驾驶任务上均优于 UniAD-Base、VAD 和 SparseDrive,达到了最高的平均能力得分 20.53%。它在合并、超车、让行和交通标志识别任务中始终排名第一,在紧急制动任务中排名第二。在基于指标的评估(表 3)中,FocalAD 实现了最佳整体性能,开环 L2 误差最低(0.85),驾驶评分最高(45.77),成功率(17.30%)和效率(174.01)。相比 SparseDrive,FocalAD 将驾驶评分提高了 +1.23,成功率提高了 +0.59%,L2 误差降低了 0.02m。这些结果突出了建模局部交互对于提高规划性能的重要性。

鲁棒性分析
尽管大规模数据集如 nuScenes、NAVSIM和 Bench2Drive已经推动了自动驾驶系统在各种场景中的评估取得重大进展,但它们主要由自然交通流组成。因此,它们缺乏对罕见但至关重要的交互的覆盖,这对规划和决策提出了显著挑战。这一局限性阻碍了在高风险或复杂驾驶场景下对模型鲁棒性的系统评估。为了解决这一问题,我们在 Adv-nuSc 数据集上进行了额外的评估。我们将模型在原始 nuScenes 验证集和 Adv-nuSc 数据集上的性能进行比较,以评估我们的方法在面对激进、意外或高度互动的驾驶行为时保持规划可靠性的能力。
表 4 比较了不同方法在 Adv-nuSc† 数据集上的运动预测性能,基于官方发布的检查点。FocalAD 在所有评估指标上均优于 SparseDrive 和 DiffusionDrive,展示了更高的准确性、更低的遗漏率和更好的终点对齐。表 5 的实验结果表明,FocalAD 在复杂或具有挑战性的交通场景中表现出优越的规划性能,与 DiffusionDrive 相比,碰撞率降低了 41.9%。具体而言,FocalAD 的平均碰撞率从 nuScenes 上的 0.09% 上升到 Adv-nuSc 上的 0.97%,这是所有评估方法中最低的。相比之下,最先进的基线方法如 SparseDrive 和 DiffusionDrive 表现出更显著的退化,平均碰撞率分别从 0.10% 上升到 1.03% 和 0.09% 上升到 1.67%。VAD 的上升幅度最大,从 0.26% 上升到 7.05%,而 UniAD 则从 0.63% 上升到 3.95%。这些增加的更直观比较如图 5 所示。值得注意的是,FocalAD 从 nuScenes 到 Adv-nuSc 的碰撞率增加因子最小,仅为 10.8 倍,进一步证明了其在挑战性交通场景中的鲁棒性。
这些结果证实了 FocalAD 不仅在标准条件下保持了强大的规划性能,而且在安全关键场景中也表现出显著更好的泛化能力,突出了其在动态城市环境中的卓越鲁棒性。
消融研究
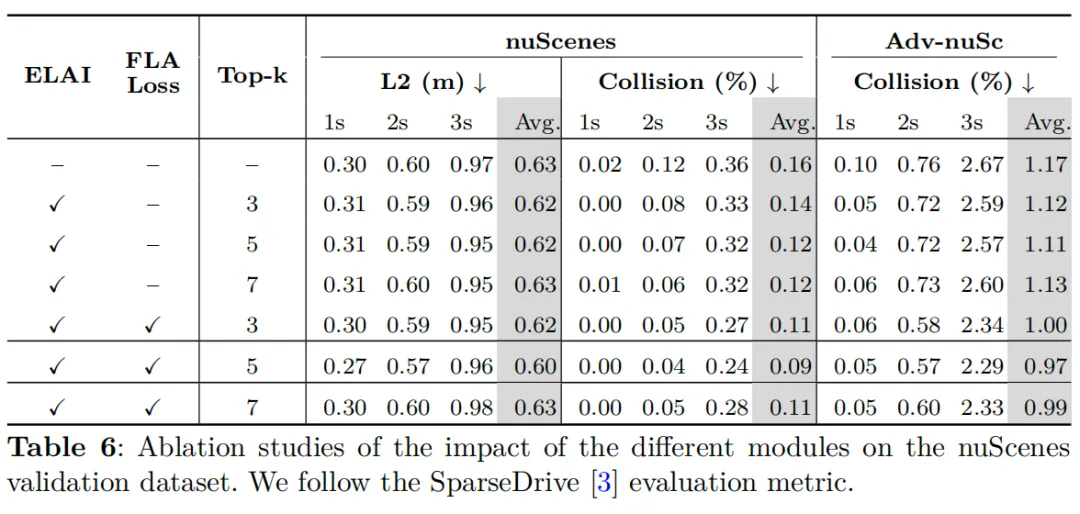
为了评估每个提出组件的贡献,我们在 nuScenes 和 Adv-nuSc 验证集上进行了消融研究,结果如表 6 所示。
nuScenes 验证集。我们首先评估了 ELAI 模块的影响。当单独启用 ELAI(不使用 FLA Loss)时,模型在规划准确性和安全性方面均一致地优于基线,将平均 L2 误差降低至 0.62m,平均碰撞率降低至 0.12%。这一结果突出了显式建模与局部代理的自车中心交互的价值。引入 FLA Loss 后,性能进一步提升,尤其是在安全性方面。当 Top-k=5 时,碰撞率降至 0.09%,平均 L2 误差降至 0.60m。这表明 FLA Loss 有效地引导模型关注决策关键的邻居,通过交互感知监督增强了运动和规划表示。为进一步验证此配置,我们尝试了不同的 Top-k 值,发现 Top-k=5 始终提供最佳的整体性能。
Adv-nuSc 验证集。在涉及更多复杂和风险场景的 Adv-nuSc 数据集上观察到了类似的趋势。ELAI 和 FLA Loss 结合使用 Top-k=5 时实现了最低的平均碰撞率(0.97%),优于所有其他变体。Adv-nuSc 上更大的性能差距进一步突出了各组件在挑战性条件下的更强贡献,提供了更有说服力的证据,确认了我们方法的鲁棒性和泛化能力。

定性分析
为了更好地理解 SparseDrive 和我们提出的 FocalAD 模型之间的行为差异,我们在 Adv-nuScenes 数据集的代表性场景中进行了定性分析。在图 6(a) 中,SparseDrive 未能捕捉局部代理交互,忽视了环境中的潜在风险。相比之下,FocalAD 准确地建模了附近的代理,为规划提供了更广泛的风险意识。在图 6(b) 中,一辆邻近的公交车在一个交叉口开始右转。SparseDrive 未能让行,生成了一条冲突的轨迹,而 FocalAD 成功预判了公交车的意图并相应地调整了计划。在图 6(c) 中,一辆邻近车辆突然切入。SparseDrive 维持了原有的路径,面临碰撞风险,而 FocalAD 迅速识别了这一动作并调整了轨迹以确保安全。这些对比表明,FocalAD 通过显式建模局部代理交互,提高了规划的安全性和可解释性。

结论
本文提出了 FocalAD,这是一种通过显式建模关键局部运动交互来增强规划的端到端自动驾驶框架。与依赖全局聚合特征的先前方法不同,FocalAD 通过自车-局部代理交互器(ELAI)利用以自车为中心的交互表示,并通过焦点-局部代理损失(FLA Loss)引入交互感知训练机制。在开环 nuScenes 数据集和闭环 Bench2Drive 基准上的大量实验表明,FocalAD 在规划准确性和安全性方面优于最先进的方法。此外,在更具挑战性的对抗性 Adv-nuScenes 数据集上,FocalAD 在高风险交互场景中表现出强大的鲁棒性,突出了关注决策关键的局部代理的有效性。未来的工作将探索生成式规划框架和轨迹优化策略,以进一步提高轨迹多样性并增强规划安全性。
参考
1 FocalAD Local Motion Planning for End-to-End Autonomous Driving