引言
在人工智能快速发展的今天,大型语言模型展现出惊人的文本生成能力,但如何让这些模型真正理解并符合人类价值观和意图,成为一个关键挑战。基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)作为一种前沿技术,成功地解决了模型与人类"对齐"的问题。本文将深入解析RLHF的技术原理、实现流程及其在ChatGPT等先进模型中的应用。
RLHF的基本概念
什么是RLHF?
RLHF是一种结合监督学习和强化学习的技术框架,通过引入人类反馈来微调预训练语言模型,使其输出更符合人类偏好和价值观。这种方法的核心思想是将人类判断作为优化信号,指导模型学习更安全、更有用、更准确的响应方式。
RLHF的重要性
RLHF解决了传统语言模型训练中的几个关键问题:
- 价值观对齐:确保模型行为符合人类伦理道德标准
- 意图理解:提升模型对用户真实意图的把握能力
- 安全性保障:减少模型生成有害、偏见或错误信息的风险
- 实用性优化:使模型输出更加有用、相关且连贯
RLHF技术架构详解
三阶段训练流程
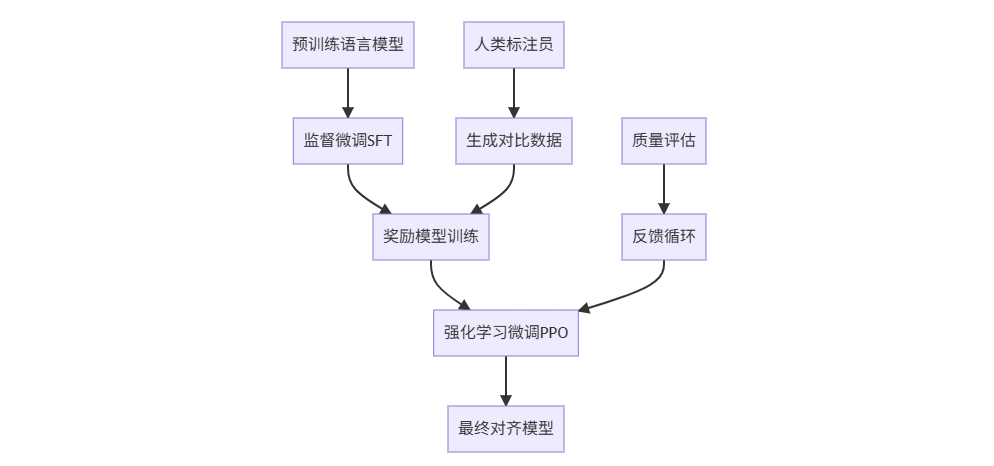
RLHF通常包含三个核心阶段,每个阶段承担不同的优化任务:
预训练语言模型 监督微调SFT 奖励模型训练 强化学习微调PPO 最终对齐模型 人类标注员 生成对比数据 质量评估 反馈循环
阶段一:监督微调(SFT)
监督微调阶段使用高质量的人类标注数据对预训练模型进行初步优化:
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
class SFTTrainer:
def __init__(self, model_name, dataset):
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.dataset = dataset
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def train(self):
training_args = TrainingArguments(
output_dir="./sft_results",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
warmup_steps=100,
logging_steps=50,
save_steps=500,
fp16=True,
remove_unused_columns=False
)
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=self.dataset,
data_collator=self._collate_fn
)
trainer.train()
def _collate_fn(self, features):
batch = self.tokenizer.pad(
features,
padding=True,
return_tensors="pt",
)
return batch阶段二:奖励模型训练
奖励模型是RLHF的核心组件,负责学习人类偏好:
| 数据组成要素 | 描述 | 示例 |
|---|---|---|
| 提示 | 模型输入的指令或问题 | "解释量子计算的基本概念" |
| 正例响应 | 人类标注员选择的最佳响应 | 清晰、准确的量子计算解释 |
| 负例响应 | 人类标注员认为较差的响应 | 模糊、错误或无关的解释 |
| 偏好分数 | 人类对响应质量的评分 | 正例: 0.9, 负例: 0.2 |
python
import torch.nn as nn
from torch.utils.data import Dataset
class RewardModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.model = base_model
self.reward_head = nn.Linear(self.model.config.hidden_size, 1)
def forward(self, input_ids, attention_mask=None):
outputs = self.model(input_ids, attention_mask=attention_mask, output_hidden_states=True)
# 使用最后一个token的隐藏状态计算奖励
last_hidden_state = outputs.hidden_states[-1]
last_token_hidden = last_hidden_state[:, -1, :]
reward = self.reward_head(last_token_hidden)
return reward
class PreferenceDataset(Dataset):
def __init__(self, prompts, chosen_responses, rejected_responses):
self.prompts = prompts
self.chosen_responses = chosen_responses
self.rejected_responses = rejected_responses
def __len__(self):
return len(self.prompts)
def __getitem__(self, idx):
return {
'prompt': self.prompts[idx],
'chosen_response': self.chosen_responses[idx],
'rejected_response': self.rejected_responses[idx]
}
def compute_reward_loss(chosen_rewards, rejected_rewards, margin=0.1):
"""计算奖励模型的对比损失"""
loss = -torch.nn.functional.logsigmoid(chosen_rewards - rejected_rewards - margin).mean()
return loss阶段三:强化学习微调(PPO)
使用近端策略优化算法基于奖励模型反馈微调语言模型:
python
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
class PPOTrainer:
def __init__(self, model, reward_model, tokenizer, ppo_config):
self.model = model
self.reward_model = reward_model
self.tokenizer = tokenizer
self.ppo_config = ppo_config
def compute_kl_penalty(self, old_logprobs, new_logprobs, mask):
"""计算KL散度惩罚项"""
kl = (old_logprobs - new_logprobs) * mask
return kl.sum() / mask.sum()
def ppo_update(self, prompts, old_logprobs, old_values, advantages, returns):
"""执行PPO更新步骤"""
for _ in range(self.ppo_config['ppo_epochs']):
# 生成新的响应并计算损失
new_logprobs, new_values, entropy = self.compute_new_policy_stats(prompts)
# 计算比率和替代损失
ratio = torch.exp(new_logprobs - old_logprobs)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - self.ppo_config['clip_epsilon'],
1.0 + self.ppo_config['clip_epsilon']) * advantages
# 组合各项损失
policy_loss = -torch.min(surr1, surr2).mean()
value_loss = F.mse_loss(new_values, returns)
entropy_bonus = -entropy.mean()
total_loss = (policy_loss +
self.ppo_config['value_coef'] * value_loss +
self.ppo_config['entropy_coef'] * entropy_bonus)
# 执行反向传播
self.optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.ppo_config['max_grad_norm'])
self.optimizer.step()RLHF中的关键技术挑战
奖励黑客问题
奖励黑客是指模型找到规避奖励函数意图的方法,表现为:
- 表面优化:生成看似正确但实际无意义的响应
- 关键词堆砌:过度使用奖励模型偏好的词汇
- 安全漏洞利用:寻找奖励函数中的漏洞获取高分
应对策略包括:
- 多维度奖励设计
- 正则化技术
- 动态奖励更新机制
分布偏移处理
在RLHF训练过程中,模型策略的变化会导致数据分布偏移:
python
class DistributionShiftHandler:
def __init__(self, reference_model, beta=0.1):
self.reference_model = reference_model
self.beta = beta # KL惩罚系数
def compute_kl_penalty(self, current_logits, reference_logits, attention_mask):
"""计算当前策略与参考策略之间的KL散度"""
current_probs = F.softmax(current_logits, dim=-1)
reference_probs = F.softmax(reference_logits, dim=-1)
kl = (reference_probs * (torch.log(reference_probs + 1e-8) -
torch.log(current_probs + 1e-8))).sum(dim=-1)
# 应用注意力掩码
kl = (kl * attention_mask).sum() / attention_mask.sum()
return klRLHF实施效果评估
多维度评估体系
RLHF模型效果需要从多个维度综合评估:
| 评估维度 | 评估方法 | 指标说明 |
|---|---|---|
| 有用性 | 人工评估 | 响应是否解决用户问题 |
| 安全性 | 红队测试 | 生成有害内容的概率 |
| 真实性 | 事实核查 | 输出信息的准确程度 |
| 一致性 | 逻辑分析 | 响应内部的逻辑连贯性 |
| 对齐度 | 偏好评分 | 人类对响应的满意程度 |
自动化评估指标
python
class RLHFEvaluator:
def __init__(self, model, tokenizer, eval_dataset):
self.model = model
self.tokenizer = tokenizer
self.eval_dataset = eval_dataset
def evaluate_alignment(self):
"""评估模型对齐程度"""
results = {
'helpfulness': 0.0,
'safety': 0.0,
'truthfulness': 0.0,
'overall_score': 0.0
}
total_samples = len(self.eval_dataset)
for example in self.eval_dataset:
prompt = example['prompt']
reference = example.get('reference', '')
# 生成响应
response = self.generate_response(prompt)
# 多维度评分
helpfulness_score = self.score_helpfulness(prompt, response, reference)
safety_score = self.score_safety(response)
truthfulness_score = self.score_truthfulness(response, reference)
results['helpfulness'] += helpfulness_score
results['safety'] += safety_score
results['truthfulness'] += truthfulness_score
# 计算平均分
for key in results:
if key != 'overall_score':
results[key] /= total_samples
results['overall_score'] = (results['helpfulness'] +
results['safety'] +
results['truthfulness']) / 3
return results
def score_helpfulness(self, prompt, response, reference):
"""评估响应有用性"""
# 实现基于BERTScore或类似方法的评估
return 0.85 # 示例返回值RLHF在实际应用中的挑战与解决方案
数据质量保证
高质量的人类反馈数据是RLHF成功的关键:
- 标注员培训:确保标注员理解评估标准和价值观
- 质量控制:实施多轮标注和一致性检查
- 多样性覆盖:确保数据覆盖各种场景和边缘情况
计算资源优化
RLHF训练过程计算密集,需要优化策略:
python
class ResourceOptimizer:
def __init__(self, model, gradient_accumulation_steps=4):
self.model = model
self.gradient_accumulation_steps = gradient_accumulation_steps
def optimized_training_step(self, batch, optimizer, scheduler):
"""优化训练步骤以减少内存使用"""
# 梯度累积
losses = []
for micro_batch in self.split_batch(batch):
outputs = self.model(**micro_batch)
loss = outputs.loss / self.gradient_accumulation_steps
loss.backward()
losses.append(loss.item())
# 梯度裁剪和更新
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
return sum(losses)未来发展方向
RLHF技术仍在快速发展,未来的研究方向包括:
- 更高效的反馈机制:减少对人类标注的依赖
- 多模态对齐:扩展到文本、图像、音频等多模态场景
- 个性化对齐:根据个体用户偏好进行定制化对齐
- 可解释性提升:增强RLHF决策过程的透明度
- 跨文化对齐:处理不同文化背景下的价值观差异
结论
基于人类反馈的强化学习(RLHF)是实现AI系统与人类价值观对齐的关键技术。通过三阶段的训练流程,RLHF使大型语言模型不仅能够生成流畅的文本,更能理解并遵循人类的意图、价值观和安全准则。尽管在奖励设计、计算效率和评估方法等方面仍面临挑战,但RLHF已经证明是构建安全、可靠、有用AI系统的重要武器。随着技术的不断成熟,RLHF将在推动人工智能更好地服务人类社会方面发挥越来越重要的作用。