参考资料:
参考视频2:SQL优化(MySQL版;不适合初学者,需有数据库基础)
参考文章:为什么会使用内部临时表
参考文章:group by 的优化
参考文章:sql查询调优之where条件排序字段以及limit使用索引的奥秘
参考文章:Mysql-explain之Using temporary和Using filesort解决方案
参考文章:MySQL高级知识(八)------ORDER BY优化
参考文章:group by 优化大法
参考文章:MySQL 优化学习笔记 - 简书
参考文章:轻松优化MySQL-之Join、group by语句的优化 - 简书
参考文章:大能猫
参考文章:【MySQL】MySQL性能优化之Block Nested-Loop Join(BNL)_ITPUB博客
参考文章:https://zhuanlan.zhihu.com/p/144289721
参考文章:https://blog.csdn.net/weixin_43852196/article/details/117694947
参考文章:MySQL 处理大数据表的 3 种方案,建议收藏!!
概述:
想真的提高运行效率,可以试着分区,分库分表、冷热隔离,优化只是暂时提高效率
优化案例:
总体纲领
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE百分写最右,覆盖索引不写*;
不等空值还有OR,索引影响要注意;
varchar引号不可丢, SQL优化有诀窍
SQL解析顺序
编写过程:
select dinstinct ..from ..join ..on ..where ..group by ...having ..order by ..limit ..
解析过程
from .. on.. join ..where ..group by ....having ...select dinstinct ..order by limit ...
优化等级
|-------------------|------------------------------------------------------------------|
| Using index | 直接在索引中查,不需要回表,性能最佳 |
| Using where | 需要回表查询,浪费性能 |
| Using filesort | 多余的查询,浪费性能 一般出现在 where 和 order by 不按照最左前缀原则使用复合索引 |
| using temporary | 性能损耗大 ,用到了临时表。一般出现在group by 语句中 |
| impossible where | where子句永远为false |
| using join buffer | Mysql引擎使用了 连接缓存,大白话就是sql性能太差了,mysql 不得不 给这个sql加一个缓存 ,所以这个是需要优化的。 |
优化案例1
sql
create table test03
(
a1 int(4) not null,
a2 int(4) not null,
a3 int(4) not null,
a4 int(4) not null
);
alter table test03 add index idx_a1_a2_a3_4(a1,a2,a3,a4) ;
sql
explain select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a3=3 and a4 =4 ;--推荐写法,因为 索引的使用顺序(where后面的顺序) 和 复合索引的顺序一致
sql
explain select a1,a2,a3,a4 from test03 where a4=1 and a3=2 and a2=3 and a1 =4 ; --虽然编写的顺序 和索引顺序不一致,但是 sql在真正执行前 经过了SQL优化器的调整,结果与上条SQL是一致的。
--以上 2个SQL,使用了 全部的复合索引
以上这两个sql效果一样 ,且两项重要的指标也一致


sql
explain select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a4=4 order by a3; --以上SQL用到了a1 a2两个索引,该两个字段 不需要回表查询using index ;而a4因为跨列使用,造成了该索引失效,需要回表查询 因此是using where;以上可以通过 key_len进行验证
然后这个sql只有两个字段生效 即a1,a2,并且回表查询,所以出现了using where,a3,a4索引失效,且order by a3 和前面生效的 a1,a2拼接起来满足索引顺序,所以a3不会造成using filesort

sql
explain select a1,a2,a3,a4 from test03 where a1=1 and a4=4 order by a3; --以上SQL出现了 using filesort(文件内排序,"多了一次额外的查找/排序") :不要跨列使用( where和order by 拼起来,不要跨列使用)
因为order by a3 和前面生效的索引a1连起来,并没有满足复合索引的顺序 ,所以 a1造成的 using index ,a3,a4造成的using where 回表查询 , a3是因为where 和 order by 连起来没有遵循最左前缀原则,造成的 using filesort 额外查询。

如下,首先 a1是个生效的索引,所以using index ,又 a1和a3并没有遵循最左前缀原则,所以造成using filesot,又需要按照a3来排序,所以 造成回表查询 using where
sql
explain select a1,a2,a3,a4 from test03 where a1=1 order by a3;
sql
explain select a1,a2,a3,a4 from test03 where a1=1 and a4=4 order by a2 , a3;--不会using filesort

因为where 中 生效的 a1 索引,,order by 生效的是a2,a3索引,符合 最左前缀原则,所以没有using filesorft 又 a4以及 a2,a3需要回表重新查询 所以 using where
注意: where 和 order by 也不应该违背最左前缀原则
优化案例2-单表优化
sql
create table book
(
bid int(4) primary key,
name varchar(20) not null,
authorid int(4) not null,
publicid int(4) not null,
typeid int(4) not null
);
insert into book values(1,'tjava',1,1,2) ;
insert into book values(2,'tc',2,1,2) ;
insert into book values(3,'wx',3,2,1) ;
insert into book values(4,'math',4,2,3) ;
commit;
可以看到,索引是主键 bid查询authorid=1且 typeid为2或3的 bid
sql
explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;
可以看到,这条语句是很糟糕的,type 为all这是性能最差的类型,然后key和possible key都为空,并且 using where 和 using filesort都出现了
根据

根据SQL实际解析的顺序,调整索引的顺序:
sql
alter table book add index idx_tab (typeid,authorid,bid);--将bid放到索引中 可以提升使用using index ,如果不加 ,还需要 回表查询 ,变为 using where
添加上述索引后 然后再执行 ,变为

可以看到,这次优化,将 type提升为 index ,生成了key 和possible key ,然后 extra 提升为 using where 和 using index
注意 : 索引一旦进行升级优化 需要将原先的索引删掉,防止干扰
但是这个优化还是不是很彻底 ,标准的是 type 在ref>range 为最优 ,而且 extra 还有多余的using where
又 in 所在的字段 很容易使该字段的索引失效 ,所以(typeid,authorid,bid)这类索引,一旦 typeid失效 ,根据最左前缀原则,那么剩余的都会失效 ,所以 typeid应该尽量靠后 ,所以 再次优化后的索引为
sql
drop index idx_tab on book; -- 删除之前的索引
alter table book add index idx_atb (authorid,typeid,bid); --添加新的索引
explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc ; --查看执行计划
可以看到 新的sql type上升为 ref
1.首先要明白索引的最左前缀原则
2.其次要明白sql的解析顺序
3.in的使用会导致索引列失效 ,所以尽量在where句子中靠后使用,创建索引也尽量靠后建立,这样做也会使执行计划 type升级
4.索引需要逐步优化
本例中同时出现了Using where(需要回原表); Using index(不需要回原表):原因,where authorid=1 and typeid in(2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到);而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使该typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表(using where);
例如以下没有了In,则不会出现using where
explain select bid from book where authorid=1 and typeid =3 order by typeid desc ;
还可以通过key_len证明In可以使索引失效。

优化案例3-双表优化
sql
create table teacher2
(
tid int(4) primary key,
cid int(4) not null
);
insert into teacher2 values(1,2);
insert into teacher2 values(2,1);
insert into teacher2 values(3,3);
create table course2
(
cid int(4) ,
cname varchar(20)
);
insert into course2 values(1,'java');
insert into course2 values(2,'python');
insert into course2 values(3,'kotlin');
commit;执行以下sql:
sql
select *from teacher2 t left outer join course2 c
on t.cid=c.cid where c.cname='java';查看执行计划:
sql
explain select *from teacher2 t left outer join course2 c
on t.cid=c.cid where c.cname='java';
然后着手进行优化
遵循的原则:
小表驱动大表 : 就是说 当查询条件 是两个表的两个字段时 ,左边的表数据量小于右边的数据量 性能是最佳的。
如:select * from a left join b on a.id = b.aid 这个时候 a的数据量 小于 b的数据量 性能是最佳的 当 a的数据量大于 b的数据量时 ,可以改为:
select * from a left join b on b.aid = a.id
同理 出现以下语句
Select * from a ,b where a.id = b.aid and a.name = b.name
同样 当 a的数据量 小于 b的数据量时 这个时候性能最佳
但是当 a 的数据量 大于 b的数据量时 这个时候就需要改为
Select * from a ,b where b.aid = a.id and b.name = a.name
上述 sql中 teacher2 和 course2 数据量 一致 所以 谁在前都一样
索引建立在经常查询的字段上 左插入时一般给左表查询的字段 加索引 ,右插入时 一般给右表所查询的字段加索引
where 常查询的字段 加索引
所以:上述sql语句 不需要更改 然后需要 加索引 分别为: teacher2 的 cid 以及 course2 的cname
sql
ALTER TABLE teacher2 ADD INDEX index_teacher2_cid(cid);
ALTER TABLE course2 ADD INDEX index_course2_cname(cname);然后可以看到 type 由 ALL 升级到了ref

using join buffer
还有就是在 没加索引前,extra 出现了一个字段 using join buffer Mysql引擎使用了 连接缓存,大白话就是sql性能太差了,mysql 不得不 给这个sql加一个缓存 ,所以这个是需要优化的。
优化案例4-三表优化
遵循的原则同上 :
小表驱动 大表
索引建立在经常查询的字段上 如 左插入的 左表 右插入的右表 以及where 条件的查询字段
优化案例5-其他
- exist和in
sql
select ..from table where exist (子查询) ;
select ..from table where 字段 in (子查询) ;如果主查询的数据集大,则使用In ,效率高。
如果子查询的数据集大,则使用exist,效率高。
exist语法: 将主查询的结果,放到子查需结果中进行条件校验(看子查询是否有数据,如果有数据 则校验成功)如果 复合校验,则保留数据;
select tname from teacher where exists (select * from teacher) ;
--等价于select tname from teacher
select tname from teacher where exists (select * from teacher where tid =9999) ;
in:
select ..from table where tid in (1,3,5) ;
- order by 优化
using filesort 有两种算法:双路排序、单路排序 (根据IO的次数)
MySQL4.1之前 默认使用 双路排序;双路:扫描2次磁盘(1:从磁盘读取排序字段 ,对排序字段进行排序(在buffer中进行的排序) 2:扫描其他字段 )--IO较消耗性能
MySQL4.1之后 默认使用 单路排序 : 只读取一次(全部字段),在buffer中进行排序。但种单路排序 会有一定的隐患 (不一定真的是"单路|1次IO",有可能多次IO)。原因:如果数据量特别大,则无法 将所有字段的数据 一次性读取完毕,因此 会进行"分片读取、多次读取"。
注意:单路排序 比双路排序 会占用更多的buffer。
单路排序在使用时,如果数据大,可以考虑调大buffer的容量大小: set max_length_for_sort_data = 1024 单位byte
如果max_length_for_sort_data值太低,则mysql会自动从 单路->双路 (太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数)
提高order by查询的策略:
a.选择使用单路、双路 ;调整buffer的容量大小;
b.避免select * ...
c.复合索引 不要跨列使用 ,避免using filesort
d.保证全部的排序字段 排序的一致性(都是升序 或 降序)
- 其他
sql逻辑写的不对也会导致慢
字符集不一致也会导致慢
优化案例6-关于left join/right join/inner join 索引生效范围说明
|-----------------------------------------------------------------------------------------|
| L eft join: 左表为驱动表,右表被驱动表 |
| R ight join: 右边为驱动表,左表为被驱动表 |
| I nner join: mysql 一般 会选择数据量比较小的表作为驱动表,大表作为被驱动表 |
优化案例7-order/group by 在join系列
A.没有内联查询的情况:连接查询,中间没有内联查询,order/group by 有索引且位于驱动表上,那么是生效的,反之则不生效,例子如下:

- Group by 位于驱动表

- Group by 位于非驱动表

- Order by 位于驱动表

- Order by 位于非驱动表

- 对于位于非驱动表上的order/group by的优化
(1) inner join,STRAIGHT_JOIN功能和inner join和STRAIGHT_JOIN相同,可以强制使左表成为驱动表,(注意由于mysql优化器的存在,所以有时可能会大表驱动小表,通过执行计划explain查看)例子如下:

Inner join 小表驱动大表

STRAIGHT_JOIN 强制使左表的表作为驱动表

(2) 对于非驱动表上的group by,因为group by默认是先排序后分组,我们对顺序要求不高的情况下,仅仅需要分组,可以使用order by null,来取消排序操作,加快查询,例子如下:

使用order by null 可以减少using filesort

(3) 对于非驱动表上的order by,在无法调整为驱动表的情况下,可以通过适当增加排序区的大小来提高查询效率。
++++查询排序区++++Innodb查看Buffer Pool 的个数和大小_如何查看生产环境的buffer pool的大小、buffer pool的数量-CSDN博客
sql
SHOW VARIABLES LIKE '%innodb_buffer%'
sql
SHOW VARIABLES LIKE '%max_length_for_sort_data%'
调整排序区大小(注意不是越大越好,太大了会很浪费CPU资源)
sql
set max_length_for_sort_data = 1024 单位byteB. 对于有内联表的情况:order/group by之间有内联查询,那么即使是驱动表的索引,也会失效
|----------|-------|--------|
| 以left join为例 |||
| 有内联查询的情况 | Join前 | Join 后 |
| Order by | ① | ② |
| Group by | ③ | ④ |
(一) 情况①
相关问题引出 → 找出年龄组中 最大的手机号的相关信息 ,并按照ID降序排列
sql
EXPLAIN
SELECT * FROM baseinfo a LEFT JOIN (
SELECT Age,MAX(Phone) phone FROM baseinfo GROUP BY Age )b ON a.Age = b.Age AND a.Phone = b.phone ORDER BY a.QQID DESC;执行计划如下

可以看到,这条语句是很糟糕的,没有用到索引,且还有临时表和额外的排序
所以我们的优化策略如下
根据SQL的解析顺序:
from .. on.. join ..where ..group by ....having ...select dinstinct ..order by limit ...
添加索引如下:

所以,经过分析只要建立复合索引(Age和Phone)以及(QQID)就可以使Group By和Order By都使用上索引,且联合查询也用到索引
按照上述分析,建立索引如下

然后重新查看执行计划为

可以看到,只有内联查询baseinfo 时采用到了复合索引中的Age这个索引(key_len为5),a表用到了复合索引(Age和Phone),索引长度为158,但是QQID主键索引失效,导致了临时表和多余的排序。
相关解释
- Group By 或者order By 中间最好不要有内联查询,否则即使在他们上面建立了索引,也很有可能失效,例子如上
- 包装后的表,索引是失效的。例子如下:
首先根据第一条,更改查询语句为:
sql
SELECT * FROM (SELECT * FROM baseinfo ORDER BY QQID DESC) a
INNER JOIN (
SELECT Age,MAX(Phone) phone FROM baseinfo GROUP BY Age
)b ON a.Age = b.Age AND a.Phone = b.phone ;执行计划如下:
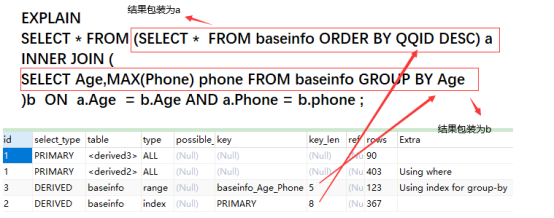
可以看到,只有包装中的group by 和 order by使用到了索引,但是复合索引(Age_Phone)并没有使用到,因为违反了第二条,On后面的关联条件为包装a,b两个的关联查询,并不能使索引生效,所以我们要将一个表裸露出来,改进如下:
sql
EXPLAIN
SELECT * FROM (SELECT * FROM baseinfo ORDER BY QQID DESC) a
INNER JOIN baseinfo c ON a.QQID = c.QQID
INNER JOIN (
SELECT Age,MAX(Phone) phone FROM baseinfo GROUP BY Age
)b ON c.Age = b.Age AND c.Phone = b.phone ;执行计划如下

避免索引失效方法:
(1)复合索引
a.复合索引,不要跨列或无序使用(最佳左前缀)(a,b,c)
b.复合索引,尽量使用全索引匹配(a,b,c)
(2)不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
select ..where A.x = .. ; --假设A.x是索引
不要:select ..where A.x*3 = .. ;
复合索引 (authorid,typeid)
explain select * from book where authorid = 1 and typeid = 2 ;--用到了at2个索引
explain select * from book where authorid = 1 and typeid*2 = 2 ;--用到了a1个索引
explain select * from book where authorid*2 = 1 and typeid*2 = 2 ;----用到了0个索引
explain select * from book where authorid*2 = 1 and typeid = 2 ;----用到了0个索引,原因:对于复合索引,如果左边失效,右侧全部失效。(a,b,c),例如如果 b失效,则b c同时失效。
drop index idx_atb on book ;
alter table book add index idx_authroid (authorid) ;
alter table book add index idx_typeid (typeid) ;
explain select * from book where authorid*2 = 1 and typeid = 2 ; --索引 typeid 生效,单独的索引 前面的失效 不会影响后续的索引
(3)复合索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效。
复合索引中如果有>,则自身和右侧索引全部失效。
sql
explain select * from book where authorid = 1 and typeid =2 ;
-- SQL优化,是一种概率层面的优化,原因是底层有sql优化器。至于是否实际使用了我们的优化,需要通过explain进行推测。
sql
explain select * from book where authorid != 1 and typeid =2 ;
explain select * from book where authorid != 1 and typeid !=2 ;

体验概率情况(< > =):原因是服务层中有SQL优化器,可能会影响我们的优化。
drop index idx_typeid on book;
drop index idx_authroid on book;
alter table book add index idx_book_at (authorid,typeid);
explain select * from book where authorid = 1 and typeid =2 ;--复合索引at全部使用
explain select * from book where authorid > 1 and typeid =2 ; --复合索引中如果有>,则自身和右侧索引全部失效。
explain select * from book where authorid = 1 and typeid >2 ;--复合索引at全部使用
----明显的概率问题---
explain select * from book where authorid < 1 and typeid =2 ;--复合索引at只用到了1个索引
explain select * from book where authorid < 4 and typeid =2 ;--复合索引全部失效
--我们学习索引优化 ,是一个大部分情况适用的结论,但由于SQL优化器等原因 该结论不是100%正确。
--一般而言, 范围查询(> < in),之后的索引失效。
(4)补救,补救概率问题。尽量使用索引覆盖(using index)(a,b,c)
sql
select a,b,c from xx..where a= .. and b =.. ;(5) like尽量以"常量"开头,不要以'%'开头,否则索引失效
sql
select * from xx where name like '%x%' ; --name索引失效
explain select * from teacher where tname like '%x%'; --tname索引失效
explain select * from teacher where tname like 'x%';explain select tname from teacher where tname like '%x%'; --如果必须使用like '%x%'进行模糊查询,可以使用索引覆盖 挽救一部分。
(6)尽量不要使用类型转换(显示、隐式),否则索引失效
explain select * from teacher where tname = 'abc' ;
explain select * from teacher where tname = 123 ;//程序底层将 123 -> '123',即进行了类型转换,因此索引失效
(7)尽量不要使用or,否则索引失效
explain select * from teacher where tname ='' or tcid >1 ; --将or左侧的tname 失效。