基本概念

时间复杂度

(i=i*2)外层循环次数为 log₂n,(j<i)内层循环次数为 1+2+4+...+2^(log₂n) ≈ 2n,因此总时间复杂度为 O(n)。

队
初始时队列为空,front和rear应指向同一位置(通常为0),且第一个元素入队时直接放入A0,rear后移。
循环队列的元素个数为 (rear - front + M) % M
rear的计算公式为 (front + size) % M
出队是front+ ,入队是rear+ 。然后两个都要对队列大小取余

注意看题目,是一个队列 不是两个开口不一样的队列


串
子串个数

算数表达
考虑计算式的优先级 谁先算

栈
入栈时,注意top的初值:若为0,则++;若为某一数值,则--。
出栈后的计算结果不再入栈,接着跟着后面的算,位于第二位操作数


稀疏矩阵
保存行列数即可

链表
插入s
先连接p后面的,再让s连上p

删首尾元素

链接地址即指向下一个元素的地址
如图 a-e变成了a-f,则链接地址从1010变到f的1014了。f-e则为e的地址1010
答案为c

删除循环双链表p节点:


插到头结点之后


上三角-行优先
坐标(6,6),前五行之和为50

树
结点

无右孩子结点数 = 非叶结点数 = 2011 - 116 = 1895
中
按照经过每个结点的顺序 即为排序顺序
前中后------左下右,都从根节点出发
前序:中左右





无图判断排序

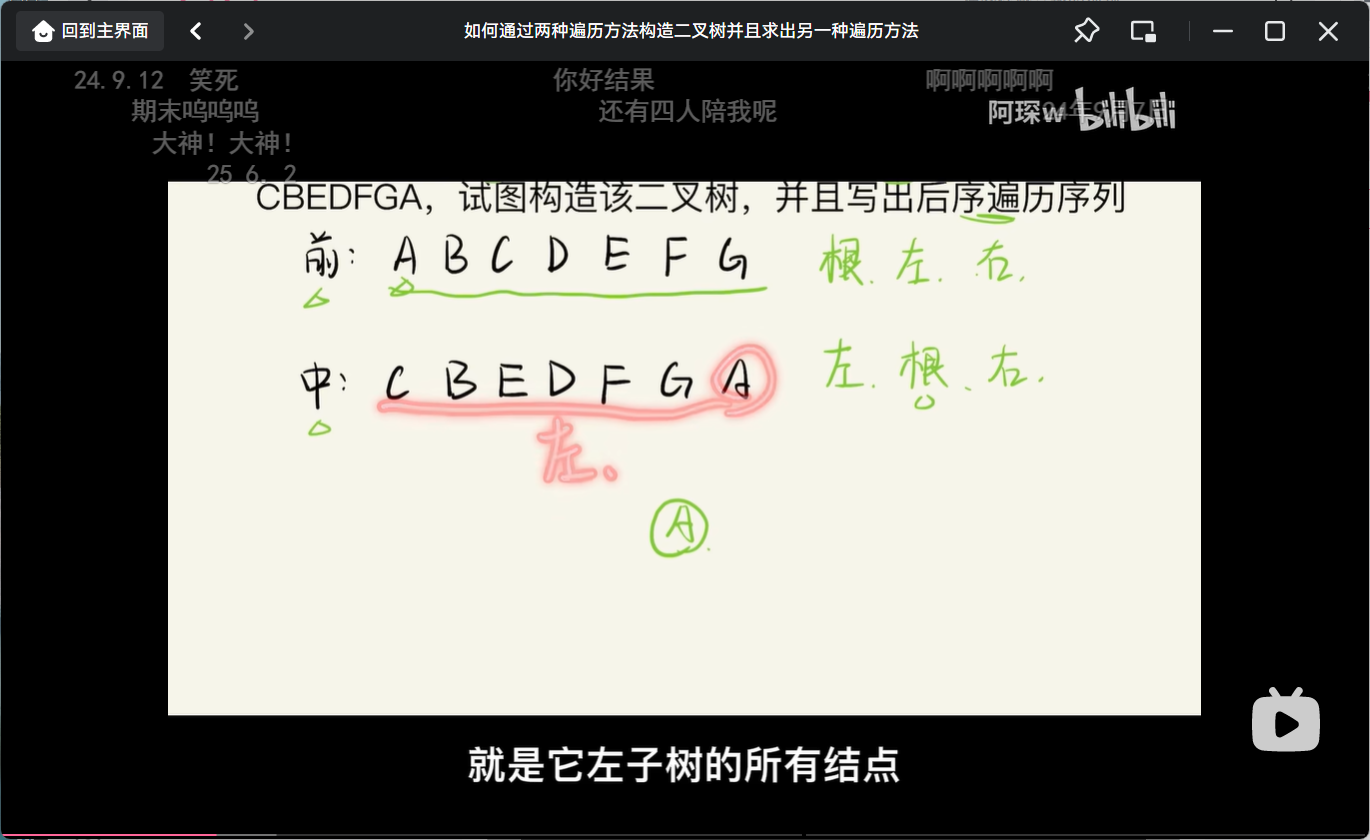
根节点右边就是右子树的所有节点
除开根节点,第一个是左子树的根节点 在中序中 左边就是左子树
变得就是根节点

二叉树
根据度分别求和的别忘记加上根节点1=总结点数
二叉排序树
进入的节点和根节点、父节点比较,大往右,小往左
左子树完全小于根节点
右子树大于根节点
查找路径
对于路径上的每个节点,后续节点要么全部小于它(左子树),要么全部大于它(右子树)



给出的大小按照中序遍历输出
完全二叉树
叶节点向上取整,非叶结点向下取整

平衡二叉树
平衡因子定义为:左子树高度 - 右子树高度
求平衡因子=0的分支节点,直接总结点数-叶节点
左旋示范





最终

三叉树
最少结点数 Nmin=3的h-1次/2
森林
注意题目所问的F,是森林,则本题选D

哈夫曼树
结点数
哈夫曼树的总结点数 = 叶子结点数 + 内部结点数 = n + (n - 1) = 2n - 1
哈夫曼编码
前缀编码不能是其他编码的前缀


差不多大的可以放在同一行

最小带权路径WPL
构建哈夫曼树,乘以层数
加权平均长度
构建哈夫曼树,乘以层数。结果除以元素(频次)

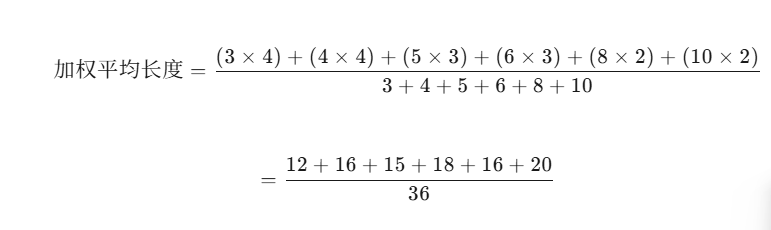
最小生成树
权值和最小,且无环路
Krusal------克鲁斯卡尔算法
边数少
按照权值大小单独连
按照边的权值大小,以次(按从小到大的顺序)把节点连起来,只要连通,就不必走完权值大小的尽头(最大的那个),不可以构成回路
相同权值大小,只要不构成回来,可以都连上,权值小的优先
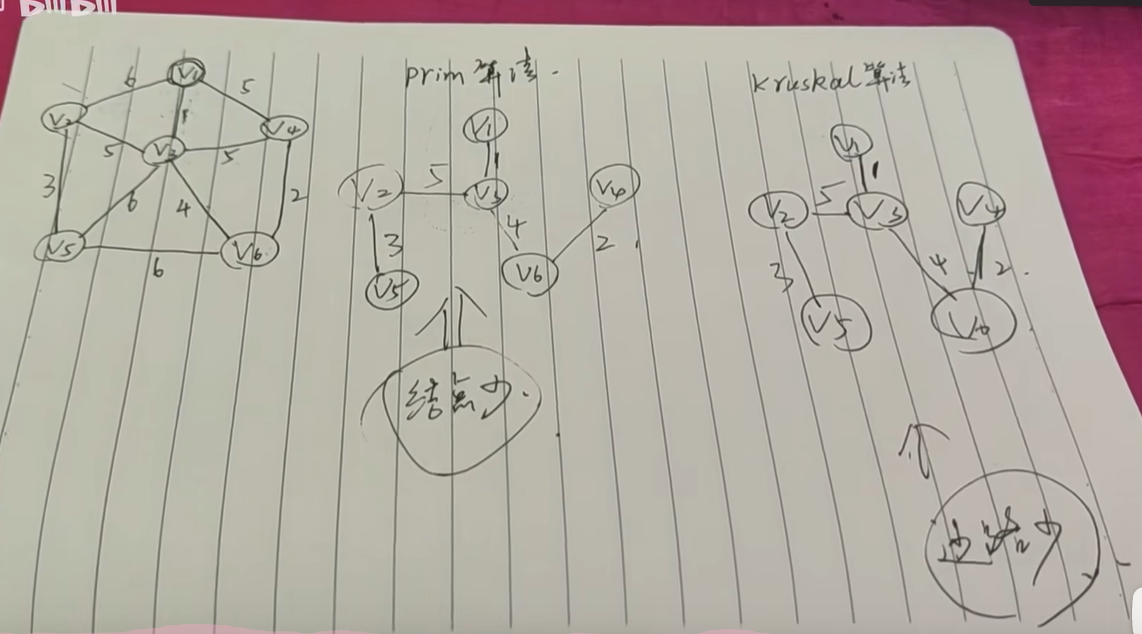
Prim
节点少的情况
把找到的节点当成整体
从当前节点出发,找连接的结点中,权值最小的那个结点,把这两个结点当成一个整体,再以次求最小权值和。注意 不可形成回路

图
连通
强连通
删掉入度 / 出度为0的点。以此删去,剩下的不能再删的整体,为一个强连通分量。被删掉的顶点各为1位强连通分量

完全图
任意两个顶点之间都有边
保证连通
最少n-1,最大Cn2(组合)
确保 即Cn2 -1


保证(确保) n个顶点的无向图连通的最少边数为
相当于排列组合?

确保强连通
确保连通的结果*2

度
根据邻接矩阵,判断顶点的度数------画图,记边数,有向则都要记
广度
以顶点0为原点,把绳子拉直,一层一层读取


深度DFS
进入死胡同则后退一步回到上一个节点


DJ最短路径
纳入整体,再更新,大小,链接不到先放无穷
注意题目所问的是出现的顶点,而不是每个顶点的最短路径大小

先按照题目所给,再更新



拓扑排序



AOE关键路径
关键路径是从源点到汇点路径长度最长的路径,决定了工程的最短工期
关键活动的延迟会导致工期延长
查找
折半次数

排序
大概原理
1.选择排序

2.冒泡排序
重复比较相邻的

3.快速排序
适合顺序存储,要排序的数据已经基本有序的情况下不利
不一定选择最中间的

4.插入排序

5.希尔排序
按照增量序列分组,再进行插入排序

6.归并排序
先两两分组,进行过一趟以后不一定能选出一个放在最终位置

简单选择排序:每次选一个最小的数和第1(2 、3....)交换位置
3为排序:假装第一个不存在 从左找一个比原来大的,从右找一个比原来小的。大的和小的交换位置,小的和原来的交换位置

堆排序
把小的往上提

堆排序
其实是二叉树
大根堆、小根堆
大根堆删去顶端后,把最小的放到根节点,然后再进行比较
小根堆操作与之相反
给定序列------固定序列。

加入数据,自己建树,边建边改。填充的时候也要以此填充,如下图

大根堆排序
排序从(n/2)向下取整个节点开始比较,若子节点大,则交换,然后按照前面的顺序,以次比较
大根堆:最大的在上面,出去得到由大到小的排序
小跟堆 最小的在上面,由小到大
拓扑排序
基本规则:
-
选择一个无前驱的顶点(入度为0),输出并删除其出边。
-
重复直到所有顶点输出
哈希函数 散列
二次探测
不是单纯的+1往后退了
二次探测的增量序列为:1, -1, 4, -4, 9, -9, ...(即 ±i²,i=1,2,3,...)

优劣
数据表中有10000个元素,如果仅要求求出其中最大的10个元素,则采用( 堆排序)算法最节省时间