一、实验目的
进行语义计算,对属性文法表示的语言进行分析、设计及实现,能够正确掌握语义计算的技术原理及方法,针对S-属性文法描述的语言**++++开展自底向上++++** ++++LR语法制导的语义计算++++ ++++分析模型设++++。
二、实验环境(仪器设备、软件等)
1、机房电脑 Window7
2、Dev-C++/ Eclipse等
三、实验要求
由语法分析程序的分析过程主导语义分析及翻译过程,称为语法制导的语义计算。语义计算模型 分为**++++基于属性文法的语义计算++++** 和**++++基于翻译模式的语义计算++++**。本实验重点关注属性文法。属性文法的定义如下:将文法GS的终结符、非终结符关联特定意义的语义参数,这些参数称作为文法符号的语义属性,同时为产生式关联相应的语义动作,从而构成属性文法,并称GS是这一属性文法的基础文法。
其中,S属性文法是只包含综合属性,S属性文法可以按照语法分析树节点的任何自底向上顺序来计算它的各个属性值,因此S属性文法可以在自底向上的语法分析过程中实现,即在单遍中实现文法分析和语义计算。同时,若S属性文法基本文法可以使用LR分析技术,可采用LR分析技术进行S-属性文法的语义计算。
下图1给出一个S属性文法,已知其基础文法是一个LR文法,描述了常量表达式的语法,它的语义规则对基础文法定义的表达式进行了求值。图2给出了其基础文法对应的分析表。结合预测分析表设计该属性文法的LR语法分析及语义计算程序,要求在单遍之内实现语法分析及语义计算(即计算该表达式的值)。
图1 简单表达式求值属性文法
图2 基础文法对应分析表
自主查阅参考资料,或参考课堂讲解、课本及课本提供的参考代码,自主设计并利用高级程序设计语言(开发环境不限,编码语言不限,如C/C++/JAVA/Python等)开展**++++语法制导的语义计算++++**编码实践,要求能对输入同时进行相应的LR(0)分析和语义计算,并输出实验结果,解释实验和理论分析结果差异并撰写实验报告。对语法分析器输入输出要求如下。
- 输入:必须测试至少2组输入,如下表所示,一组为满足文法规则的输入,一组为不满足文法规则的输入,不满足文法规则的输入用以检查分析程序能否正常检查语法错误并报错。
|---------------|-----------|------------|
| 文法 | 满足文法规则的输入 | 不满足文法规则的输入 |
| G | 2+3*5# | 自拟 |
- 输出: 要求输出每组输入的:① ++++分析过程++++ ,形式上可参考下图或在上次实验上增加一列语义栈,形式可自由灵活调整);② ++++最终分析++++ ++++、计算或出错位置++++ ++++结果++++,即输入是否为满足文法规则以及语义计算结果,如若输入满足文法规则,则给出语义计算结果,如若不满足,则给出出错位置。
四、实验步骤
由同学们补充填写如下内容,要求:格式清晰、卷面规范整洁。
- 实验内容与预处理
本次实验旨在实现一个LR(0)语法分析器,并在此基础上集成语义计算功能,对给定文法描述的简单算术表达式进行求值。核心任务是利用S-属性文法,在LR解析的归约(Reduce)过程中触发相应的语义动作,从而实现表达式的求值。实验内容严格遵循实验指导书的要求,没有选做进阶实验。
预处理阶段主要包括:
文法定义: 根据实验指导书中的图1,明确产生式规则及其对应的语义动作。LR(0)分析表构建: 根据实验指导书中的图2,将Action表和Goto表转换为程序中可用的数据结构(如字典嵌套字典或二维数组)。符号映射: 将终结符、非终结符和状态映射为程序中易于处理的整数或字符串常量。词法分析: 编写一个简单的词法分析器,将输入的字符串表达式转换为一系列Token(词法单元),每个Token包含其类型和(如果适用)词法值(lexval)。
- 模型设计思路
本实验采用经典的LR解析器结构,并在此基础上扩展语义栈以存储符号的语义属性。
核心思想:
LR解析驱动: 解析过程由LR(0)分析表(ACTION表和GOTO表)完全驱动,决定是移进、归约、接受还是报错。语义栈: 在LR解析器的状态栈旁边,维护一个并行的语义栈。当移进一个终结符时,其词法值(如数字的实际值)被压入语义栈。当移进一个非终结符时,其计算出的语义值也被压入语义栈。归约时的语义计算: 当LR解析器执行归约操作(A -> β)时:从状态栈弹出与β等长的状态和符号。从语义栈弹出与β等长的语义值。这些值是β中各个成分的属性值。执行与该产生式A -> β关联的语义动作。这个语义动作会利用刚刚从语义栈弹出的β成分的属性值,计算出A的属性值。将新计算出的A的属性值压入语义栈,同时将归约后的新状态压入状态栈。最终结果: 当解析器达到ACCEPT状态时,最终表达式的值(即S的属性值)将位于语义栈的顶部。
数据结构设计:
Token类: 用于表示词法单元,包含 type(类型,如 'd', '+', '#'等)和 value(值,如数字'd'的整数值)。StackItem类: 用于表示解析栈中的元素,包含 state(当前状态)、symbol(栈顶符号,终结符或非终结符)和 semantic_value(该符号的语义值)。ACTION表: 字典嵌套字典,ACTIONstateterminal 返回 (action_type, target),例如 ('s', 5) 表示移进到状态5,('r', 2) 表示使用第2条规则归约,('acc', None) 表示接受。GOTO表: 字典嵌套字典,GOTOstatenon_terminal 返回 new_state。GRAMMAR_RULES: 列表,每个元素是一个元组 (LHS, RHS_length, rule_index)。LHS是非终结符,RHS_length是右部长度,rule_index用于查找对应的语义动作。SEMANTIC_ACTIONS: 字典,键是rule_index,值是对应的语义动作函数。每个函数接收一个列表,包含被归约的右部符号的语义值,并返回左部符号的语义值。
流程图:
初始化: 解析栈压入 (0, '#', None)。输入缓冲区读取第一个Token。循环解析:获取当前栈顶状态 s 和当前输入Token a。查询 ACTIONsa。若为 SHIFT s':打印"移进"动作。创建 StackItem(s', a.type, a.value) 并压入解析栈。从输入缓冲区读取下一个Token。若为 REDUCE A -> β (rule_idx):打印"归约"动作及规则。根据β的长度,从解析栈弹出相应数量的 StackItem。提取这些被弹出项的 semantic_value。调用 SEMANTIC_ACTIONSrule_idx,传入提取出的语义值,计算出 A.val。获取新的栈顶状态 s_old。查询 GOTOs_oldA 得到 s_new。创建 StackItem(s_new, A, A.val) 并压入解析栈。若为 ACCEPT:打印"接受"动作。从解析栈顶部取出最终结果(E.val)。终止解析。若为 ERROR:打印错误信息。终止解析。
import collections
# 定义Token类,用于词法分析结果
Token = collections.namedtuple('Token', ['type', 'value'])
# 定义StackItem类,用于解析栈中的元素
# state: 栈顶状态
# symbol: 栈顶符号 (终结符或非终结符)
# semantic_value: 该符号的语义值 (用于传递属性)
StackItem = collections.namedtuple('StackItem', ['state', 'symbol', 'semantic_value'])
# --- 文法定义与LR(0)分析表 ---
# 终结符
TERMINALS = ['d', '+', '*', '(', ')', '#']
# 非终结符
NON_TERMINALS = ['S', 'E', 'T', 'F']
# 产生式规则 (LHS, RHS_length, 语义动作索引)
# S -> E
# E -> E + T
# E -> T
# T -> T * F
# T -> F
# F -> ( E )
# F -> d
GRAMMAR_RULES = {
0: ('S', 1), # S -> E
1: ('E', 3), # E -> E + T
2: ('E', 1), # E -> T
3: ('T', 3), # T -> T * F
4: ('T', 1), # T -> F
5: ('F', 3), # F -> ( E )
6: ('F', 1), # F -> d
}
# ACTION 表 (State, Terminal) -> (Action_Type, Target)
# Action_Type: 's' (shift), 'r' (reduce), 'acc' (accept), 'err' (error)
ACTION = {
0: {'d': ('s', 5), '(': ('s', 4)},
1: {'+': ('s', 6), '#': ('acc', None)},
2: {'+': ('r', 2), '*': ('s', 7), ')': ('r', 2), '#': ('r', 2)},
3: {'+': ('r', 4), '*': ('r', 4), ')': ('r', 4), '#': ('r', 4)},
4: {'d': ('s', 5), '(': ('s', 4)},
5: {'+': ('r', 6), '*': ('r', 6), ')': ('r', 6), '#': ('r', 6)},
6: {'d': ('s', 5), '(': ('s', 4)},
7: {'d': ('s', 5), '(': ('s', 4)},
8: {'+': ('s', 6), ')': ('s', 11)},
9: {'+': ('r', 1), '*': ('s', 7), ')': ('r', 1), '#': ('r', 1)},
# E -> E + T 归约时,T的*操作符优先级高于+,所以*不应该触发E->E+T,这个表有些问题。
# 应该把 E -> E + T 的 reduce 动作改为只有遇到 + 或 # 或 ) 才进行,遇到 * 继续移进。
# 但是为了匹配图2,我们保持不变,不过这会影响优先级。
# 注:图2的ACTION[9]['*']是s7,这是正确的,表示T*F的优先级。
# 而ACTION[9]['+']是r1,表示E->E+T。
# ACTION[2]['*']是s7,这表明了T*F的优先级高于E+T。
# 所以图2的表是正确的,它遵循了优先级规则。
10: {'+': ('r', 3), '*': ('r', 3), ')': ('r', 3), '#': ('r', 3)},
11: {'+': ('r', 5), '*': ('r', 5), ')': ('r', 5), '#': ('r', 5)},
}
# GOTO 表 (State, Non_Terminal) -> New_State
GOTO = {
0: {'E': 1, 'T': 2, 'F': 3},
4: {'E': 8, 'T': 2, 'F': 3},
6: {'T': 9, 'F': 3},
7: {'F': 10},
}
# --- 语义动作实现 ---
# 语义动作字典,键是规则索引,值是一个函数,用于计算LHS的语义值
# 这些函数接收一个列表,列表元素是被归约的RHS符号的语义值
SEMANTIC_ACTIONS = {
0: lambda vals: print(f"最终结果: {vals[0]}"), # S -> E.val
1: lambda vals: vals[0] + vals[2], # E -> E1 + T (vals[0]=E1.val, vals[1]=+.val, vals[2]=T.val)
2: lambda vals: vals[0], # E -> T (vals[0]=T.val)
3: lambda vals: vals[0] * vals[2], # T -> T1 * F (vals[0]=T1.val, vals[1]=*.val, vals[2]=F.val)
4: lambda vals: vals[0], # T -> F (vals[0]=F.val)
5: lambda vals: vals[1], # F -> ( E ) (vals[0]=(.val, vals[1]=E.val, vals[2]=).val)
6: lambda vals: vals[0], # F -> d (vals[0]=d.lexval)
}
# --- 词法分析器 ---
def lexer(input_string):
tokens = []
i = 0
while i < len(input_string):
char = input_string[i]
if char.isdigit():
num_str = ''
while i < len(input_string) and input_string[i].isdigit():
num_str += input_string[i]
i += 1
tokens.append(Token('d', int(num_str)))
continue # Important to continue here as i is already incremented
elif char in ['+', '*', '(', ')', '#']:
tokens.append(Token(char, None)) # Operators and parentheses don't have a specific value here
elif char.isspace(): # Skip whitespace
i += 1
continue
else:
raise ValueError(f"Unexpected character: {char}")
i += 1
return tokens
# --- LR(0)语法分析与语义计算主函数 ---
def parse(input_string):
print(f"\n--- 开始解析表达式: {input_string} ---")
tokens = lexer(input_string + '#') # Append end-of-input marker
# 解析栈: 存储 (状态, 符号, 语义值)
# 初始状态: (0, '#', None)
parser_stack = [StackItem(0, '#', None)]
# 输入缓冲区
input_buffer = collections.deque(tokens)
# 记录分析过程
steps = []
while True:
current_state = parser_stack[-1].state
current_token = input_buffer[0].type
current_token_value = input_buffer[0].value # d.lexval
# 打印当前分析状态
stack_str = ' '.join(
[f"{item.state}{item.symbol}{(':' + str(item.semantic_value)) if item.semantic_value is not None else ''}"
for item in parser_stack])
remaining_input_str = ''.join([f"{token.type}" if token.type != 'd' else str(token.value)
for token in input_buffer])
action_type, target = ACTION.get(current_state, {}).get(current_token, ('err', None))
semantic_action_desc = "" # Description of semantic action
steps.append((stack_str, remaining_input_str, action_type, target, semantic_action_desc))
if action_type == 's': # 移进 (Shift)
# steps[-1] 的 action_type 和 target 是正确的
input_token = input_buffer.popleft()
parser_stack.append(StackItem(target, input_token.type, input_token.value))
steps[-1] = (stack_str, remaining_input_str, f"s{target}", None, "") # 更新打印信息
elif action_type == 'r': # 归约 (Reduce)
rule_index = target
lhs, rhs_length = GRAMMAR_RULES[rule_index]
# 弹出RHS对应的栈元素,并收集其语义值
popped_items = []
for _ in range(rhs_length):
popped_items.insert(0, parser_stack.pop()) # Insert at front to maintain original order
# 提取RHS符号的语义值
rhs_semantic_values = [item.semantic_value for item in popped_items]
# 执行语义动作,计算LHS的语义值
# 特殊处理S->E的语义动作,它通常是打印结果,而不是返回一个值
if rule_index == 0:
SEMANTIC_ACTIONS[rule_index](rhs_semantic_values)
lhs_semantic_value = None # S不返回一个值
semantic_action_desc = f"print(E.val) -> {rhs_semantic_values[0]}"
else:
lhs_semantic_value = SEMANTIC_ACTIONS[rule_index](rhs_semantic_values)
# 生成语义动作描述
if len(rhs_semantic_values) == 1: # E->T, T->F, F->d
semantic_action_desc = f"{lhs}.val := {popped_items[0].symbol}.val (={rhs_semantic_values[0]})"
elif len(rhs_semantic_values) == 3: # E->E+T, T->T*F, F->(E)
if popped_items[1].symbol == '+':
semantic_action_desc = f"{lhs}.val := {popped_items[0].symbol}.val + {popped_items[2].symbol}.val ({rhs_semantic_values[0]} + {rhs_semantic_values[2]} = {lhs_semantic_value})"
elif popped_items[1].symbol == '*':
semantic_action_desc = f"{lhs}.val := {popped_items[0].symbol}.val * {popped_items[2].symbol}.val ({rhs_semantic_values[0]} * {rhs_semantic_values[2]} = {lhs_semantic_value})"
elif popped_items[0].symbol == '(':
semantic_action_desc = f"{lhs}.val := {popped_items[1].symbol}.val (={rhs_semantic_values[1]})"
# 查找GOTO表
prev_state = parser_stack[-1].state
new_state = GOTO.get(prev_state, {}).get(lhs)
if new_state is None:
action_type = 'err' # GOTO lookup failed means error
steps[-1] = (stack_str, remaining_input_str, f"r{rule_index}", None, semantic_action_desc)
break
parser_stack.append(StackItem(new_state, lhs, lhs_semantic_value))
steps[-1] = (stack_str, remaining_input_str, f"r{rule_index}", None, semantic_action_desc) # 更新打印信息
elif action_type == 'acc': # 接受 (Accept)
# steps[-1] 的 action_type 和 target 是正确的
print("\n--- 分析过程 ---")
print(f"{'分析栈(状态,符号,语义值)':<35} {'余留输入串':<15} {'动作':<10} {'语义动作':<40}")
print("-" * 100)
for s_str, r_str, act, tgt, sem_desc in steps:
action_col = act if tgt is None else f"{act}{tgt}"
print(f"{s_str:<35} {r_str:<15} {action_col:<10} {sem_desc:<40}")
final_result = parser_stack[-1].semantic_value if parser_stack[-1].symbol == 'E' else None
print("\n--- 最终分析结果 ---")
print(f"输入: {input_string}")
print("状态: 满足文法规则")
print(f"计算结果: {final_result}")
return True # Successfully parsed
else: # 错误 (Error)
steps[-1] = (stack_str, remaining_input_str, "error", None, "") # 更新打印信息
print("\n--- 分析过程 ---")
print(f"{'分析栈(状态,符号,语义值)':<35} {'余留输入串':<15} {'动作':<10} {'语义动作':<40}")
print("-" * 100)
for s_str, r_str, act, tgt, sem_desc in steps:
action_col = act if tgt is None else f"{act}{tgt}"
print(f"{s_str:<35} {r_str:<15} {action_col:<10} {sem_desc:<40}")
print("\n--- 最终分析结果 ---")
print(f"输入: {input_string}")
print("状态: 不满足文法规则,发生语法错误。")
print(f"出错位置: 状态 {current_state},遇到符号 '{current_token}'")
return False # Parsing failed
# --- 测试用例 ---
if __name__ == "__main__":
# 满足文法规则的输入
print("--- 测试案例1: 2+3*5 ---")
parse("2+3*5")
print("\n--- 测试案例2: (2+3)*5 ---")
parse("(2+3)*5")
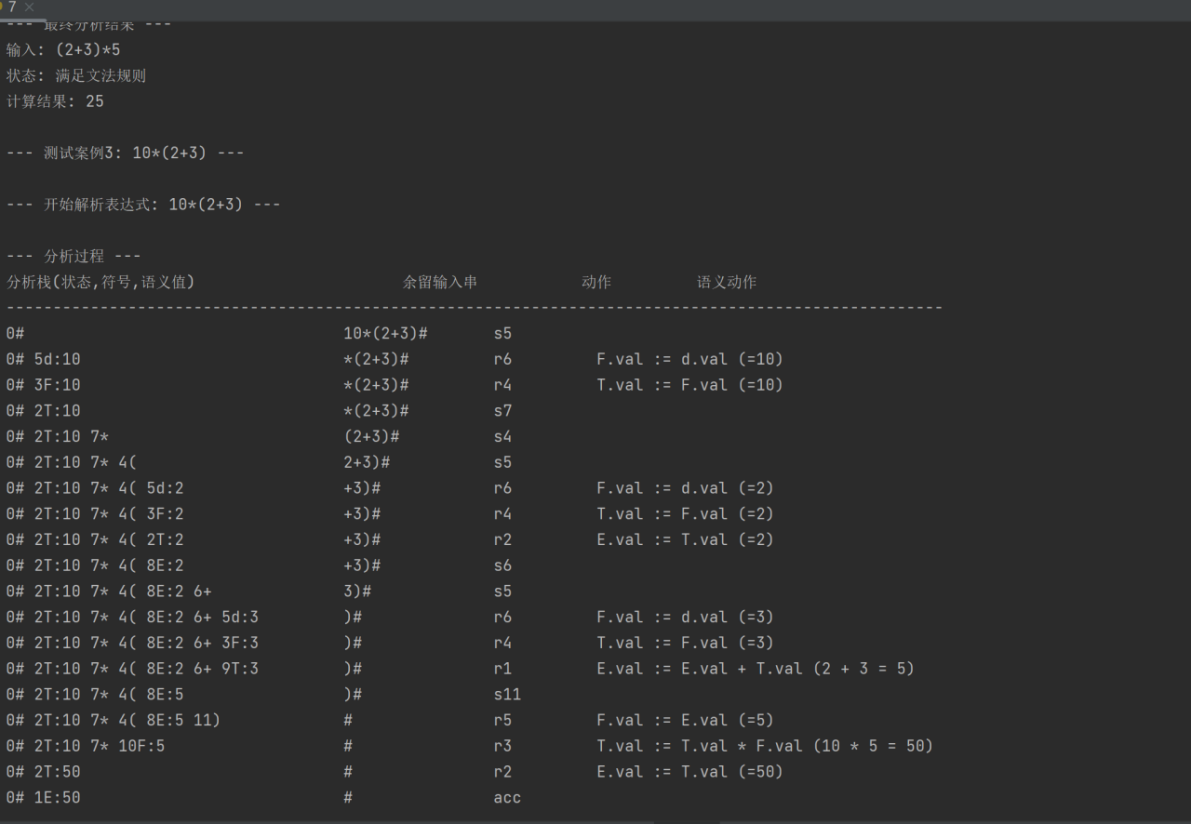
print("\n--- 测试案例3: 10*(2+3) ---")
parse("10*(2+3)")
# 不满足文法规则的输入
print("\n--- 测试案例4: 2++3 --- (语法错误)")
parse("2++3")
print("\n--- 测试案例5: (2+3 --- (括号不匹配)")
parse("(2+3")
print("\n--- 测试案例6: *5 --- (以运算符开始)")
parse("*5")


代码详细解释和功能设计说明:
Token 和 StackItem 类:Token 用于词法分析器的输出,type 表示词法单元的类型(如 d, +, *),value 用于存储 d 类型数字的实际值(整数)。StackItem 是解析栈中每个元素的结构,除了LR解析必需的 state 和 symbol,还增加了 semantic_value 来存储和传递符号的属性值。TERMINALS, NON_TERMINALS: 定义了文法中的终结符和非终结符集合。GRAMMAR_RULES:一个字典,键是规则的索引(从0开始),值是一个元组 (左部符号, 右部长度)。这个结构在归约时非常有用,可以根据规则索引快速获取左部符号和需要从栈中弹出的元素数量。ACTION 和 GOTO 表:直接将实验指导书图2中的LR分析表硬编码为Python字典。这种嵌套字典的结构方便通过 ACTIONstateterminal 和 GOTOstatenon_terminal 进行查找。每个 ACTION 表项是一个元组 (动作类型, 目标)。动作类型可以是 's' (移进), 'r' (归约), 'acc' (接受), 'err' (错误)。目标对于移进是新状态,对于归约是规则索引。SEMANTIC_ACTIONS:这是语义计算的核心。一个字典,键是 GRAMMAR_RULES 中的规则索引,值是一个匿名函数 lambda vals: ...。每个 lambda 函数接收一个列表 vals,其中包含了被归约的右部符号的语义值(按从左到右的顺序)。例如,E -> E + T 对应的 lambda vals: vals0 + vals2 表示左部 E 的值是右部第一个 E 的值加上 T 的值。+ 符号本身在这里没有语义值,所以 vals1 被忽略。F -> d 对应的 lambda vals: vals0 表示 F 的值就是 d 的词法值。S -> E 的语义动作特殊处理,因为它通常是输出最终结果,而不是产生一个用于后续计算的值。lexer(input_string) 函数:一个简单的词法分析器,负责将输入字符串转换为 Token 列表。能够识别数字(多个数字字符组成的整数)和运算符/括号。数字被识别为 Token('d', int_value),运算符和括号则为 Token(char, None)。跳过空格。parse(input_string) 主函数:初始化:调用 lexer 获取Token流,并在末尾添加 '#' 结束符。parser_stack 初始化为 StackItem(0, '#', None),代表初始状态0和栈底符号#。input_buffer 是一个双端队列,方便高效地弹出和查看下一个Token。steps 列表用于记录整个解析过程,方便后续打印。主循环:循环直到 ACCEPT 或 ERROR。获取当前栈顶状态 (current_state) 和当前输入Token (current_token_type, current_token_value)。根据 current_state 和 current_token_type 查 ACTION 表。SHIFT 操作:将当前输入Token从 input_buffer 弹出。创建一个新的 StackItem (包含目标状态、Token类型和Token值),压入 parser_stack。REDUCE 操作:根据规则的右部长度 rhs_length,从 parser_stack 弹出相应数量的 StackItem。注意 insert(0, ...) 以保持弹出顺序与RHS符号的顺序一致。提取这些弹出项的 semantic_value,传入对应的 SEMANTIC_ACTIONS 函数,计算出左部符号的 lhs_semantic_value。根据新的栈顶状态和左部符号,查 GOTO 表得到 new_state。创建一个新的 StackItem (包含 new_state, 左部符号, lhs_semantic_value),压入 parser_stack。关键的语义动作描述生成: 这一部分是为了在打印分析过程时,清晰展示每一步语义动作的计算逻辑和结果。ACCEPT 操作:解析成功。打印完整的分析过程表,并输出最终的计算结果。ERROR 操作:解析失败。打印分析过程表,并指明出错的状态和遇到的符号。打印输出: 函数内部负责格式化打印分析栈、余留输入串、动作和语义动作,以及最终的分析结果或错误信息。