一.数据库的三大范式
1.第一范式
数据库字段具有原子性,不可拆分
2.第二范式
满足第一范式
一个表必须含有一个主键
非主键列必须完全依赖于主键,而不是依赖主键的一部分
3.第三范式
满足第二范式
非主键直接依赖于主键列,不能存在依赖传递
4.第二范式和第三范式的区别
完全依赖主键,而不是部分依赖
直接依赖主键,而不是间接依赖
二.MySQL CUP飙升,该怎么处理
1.怎么确认MySQL造成CPU飙升的?
top/htop观察mysql进程的cpu占有率是否过高,且持续增长
2.哪些原因可能造成CPU飙升
**慢查询:**查询语句不当,索引不当
**mysql配置不当:**缓存设置过小,连接数过多
**硬件资源限制:**CPU核心数太多或太少,内存分配过少
mysql版本太低
3.解决方案
查询语句不当:
定期清理无用数据,避免select*查询,避免不必要的子查询,避免join查询过多的表
索引不当:
没有索引创建索引
过多索引,避免不必要的索引,减少维护成本
Mysql配置不当:
配置修改缓存大小
配置修改最大连接数
硬件资源限制:
看情况增加或减少CPU的核心数
扩展内存,避免数据频繁的换入换出
Mysql版本过低:
提升mysql的版本
三.如何定位以及优化SQL语句的性能问题
1.定位
慢查询日志:
找出执行时间超过一定时间限制的SQL语句
explain分析执行计划:
增加索引或者优化SQL语句
2.优化
表设计是否合理:
避免冗余和重复计算
索引是否合理:
设置索引但是没走索引(全表扫描),调整索引
没有索引,创建索引
索引过多,精简索引
数据量是否过大:
分表,降低B+树层高,减小查询范围
SQL语句是否合理:
检查数据类型
检测查询条件
四.什么是视图,为什么要使用视图?
1.什么是视图
视图是一种虚拟表,一种逻辑上的表,不包含数据
通过SQL来定义 create_view_name as <SQL>
用来创建视图的表叫做基表,通过视图可以展现基表的部分或者全部内容
可以用来描述基表的增删改查,通常只用于查询,增删有限制
2.为什么使用视图
简单可复用:无需关心基表,用户只需要关系过滤后的数据
安全:权限安全
数据独立:和基表的数据独立
五.SQL语句在MySQL是如何执行的
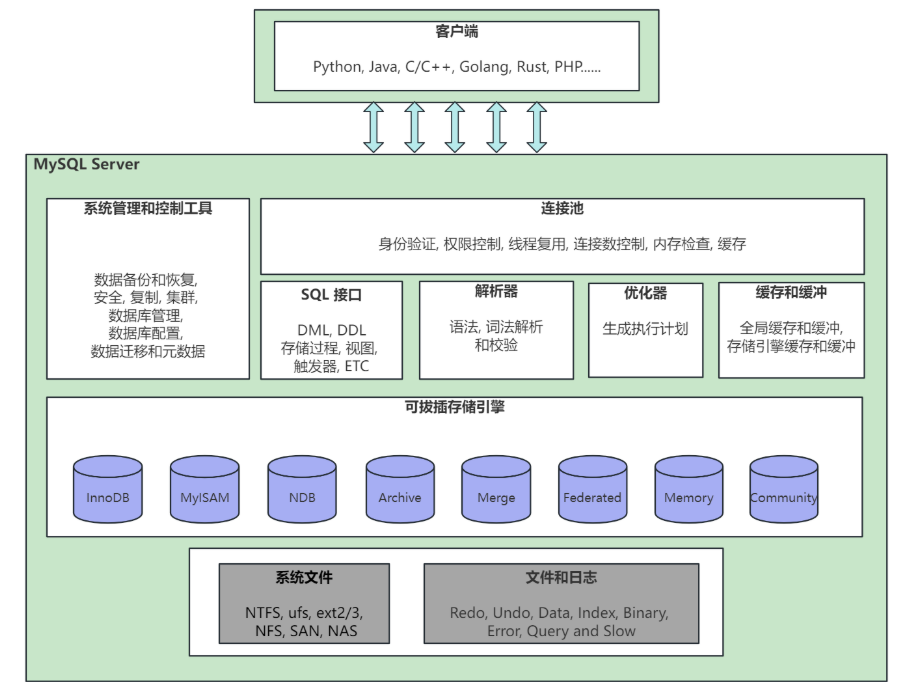

连接器:建立连接,管理连接,校验用户信息
分析器:词法句法分析,生成语法树
查询缓存(select):kv存储,命中直接返回,否则继续执行 (8.0版本已经删除)
优化器:制定执行计划,选择成本最小的计划进行执行
执行器:指定执行计划,选择成本最小的计划进行执行
写undo log(dml): 用于回滚事务/记录历史版本信息
目标页是否在缓存中:在或者不在
写redo log:用于事务崩溃恢复,将随机写转变为顺序写提高性能
写bin log:用于数据备份/主从复制

六.索引
1.索引是什么
一种有序的存储结构,按照单个或多个值进行排序,对应着一个B+树
2.索引使用的场景
where
group by
order by
3.不会使用索引的场景
没有where/group by /order by 中使用
区分度不高的列
经常修改的列
表的数据少
4.MySQL索引失效的场景
在索引列上进行函数或表达式操作
SELECT * FROM user WHERE YEAR(create_time) = 2024;在索引列上使用模糊查询且通配符在前
SELECT * FROM user WHERE name LIKE '%abc';复合索引未遵循最左前缀原则
-- 索引为 (a, b),只用 b 查询 SELECT * FROM user WHERE b = 1;在索引列上使用不等于(<>、!=)或 IS NULL/IS NOT NULL
SELECT * FROM user WHERE age != 18;在索引列上使用 OR,且不是所有条件都用到索引
SELECT * FROM user WHERE id = 1 OR name = 'Tom';数据类型不一致导致隐式转换
-- id 为字符串类型,但用数字查询 SELECT * FROM user WHERE id = 123;对索引列进行运算
SELECT * FROM user WHERE age + 1 = 20;
5.索引的代价
空间:
存储空间占用的代价,一个表最多只能创建6个索引
时间:
维护B+树的代价
DML(增删改)操作
七.主键索引和唯一索引
1.什么是主键索引
非空唯一索引,一个表只能有一个主键索引,primary key (index)
2.什么是唯一索引
索引列不能出现相同的值,可以有null值,unique(index)
3.怎么确定主键索引
为什么要创建主键索引:
聚集索引B+树,包含所有行信息
显示设置primary key:
直接确定主键索引
没有显示设置primary key:
有非空唯一索引 ------------选择第一个作为主键
没有非空唯一索引 ------------系统自动生成主键
4.区别
约束上的区别:
主键索引有非空唯一的约束,唯一索引只有唯一约束
存储上的区别:
主键索引对应的存储结构包含所有的信息
唯一索引在没确定主键索引的情况下,对应的存储结构只包含索引信息以及主键信息
八.聚集索引和辅助索引
1.什么是聚集索引
主键索引对应的索引是聚集索引,也称为聚簇索引
2.什么是辅助索引
非主键索引对应的索引是辅助索引,也称之为二级索引
3.innodb中B+树

多路平衡搜索树,
多路,降低层高,降低磁盘IO,
平衡,增删改通过平衡确保搜索时间复杂度稳定 ,
搜索,有序
所有叶子节点都在同一层
并且叶子节点间构成一个双向链表,方便范围查询,降低磁盘IO
节点大小是固定的,大小为16K ,因为物理磁盘页通常是4K ,通常会隐射整数倍的物理磁盘页,每次组织的数据就是四个磁盘页的大小
非叶子节点只会记录索引信息,叶子节点记录数据信息
举个例子
select*from user where id >=18 and id<40

4.区别
数据存储的区别:
聚集索引对应的B+树叶子节点存储的是所有行信息
辅助索引对应的B+树叶子节点存储的是索引信息以及主键信息
获取数据的区别:
如果通过主键索引查询完整行信息只需通过一次获取
如果通过辅助索引查询完整行信息需要通过两个B+树,第二次称为回表查询
九.覆盖索引
聚集索引:包含完整的行记录信息
辅助索引:只包含索引信息和主键信息,不包含行记录其他信息
覆盖索引是一种数据查询方式
覆盖索引针对的是辅助索引
直接通过辅助索引B+树就能获取要查询的值,而无需通过回表查询获取
例子:select...from table where ...where条件中只有某个辅助索引列
select...from之间列出的字段都在辅助索引B+树中
满足上述条件则走覆盖索引
作用:减少磁盘IO次数
启示:
在select中之间列出的字段尽量是需要的
十. undolog和redolog有什么作用
1.事务
用户定义的一系列操作,这些操作要么都做,要么都不做,是一个不可分割的单位
MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种数据库并发控制机制。它通过为每个数据行保存多个版本,实现了读写操作的并发执行,避免了加锁带来的性能瓶颈。
ACID原子性:事务的操作要么都做,要么都不做
一致性:事务前后数据必须保持一致
隔离性:事务之间的互相影响程度,锁,MVCC
持久性:事务完成,数据变更会存储记录
2.bufferpool
在用户层缓存磁盘数据,避免频繁访问磁盘
buffer pool是按页来划分的,一个缓存页大小为16KB
构成:数据页,索引页,插入缓存页,undo页,自适应哈希索引 ,锁信息
3.undolog
undo log(回滚日志)是一种用于记录数据被修改前信息的日志。
作用:事务回滚:当事务执行失败或主动回滚时,undo log 可以将数据恢复到修改前的状态,实现原子性。
MVCC 支持:undo log 保存了历史版本的数据,支持多版本并发控制(MVCC),让快照读可以读取到旧版本数据,实现一致性读。
4.redolog
redo log(重做日志)是 MySQL InnoDB 存储引擎中的一种日志文件。
作用:保证事务的持久性(DURABILITY)
当事务提交时,InnoDB 会先将数据的修改记录到 redo log 中,即使系统崩溃,也能通过 redo log 恢复已提交事务的数据,保证数据不丢失。
崩溃恢复
数据库异常宕机后,重启时可以通过 redo log 重新执行未写入磁盘的数据修改操作,恢复到崩溃前的状态。
5.MVCC
MVCC 通过为每行数据维护多个版本(依赖 undo log 和隐藏字段),结合事务ID判断可见性,实现了高效的并发控制和一致性读。
十一.什么是最左匹配规则,原理是什么
针对的是组合索引
从左到右依次开始匹配,遇到> < between like就停止匹配
最左匹配原则是指:在使用联合索引(复合索引)时,查询条件必须从索引的最左前列开始,依次匹配,才能有效利用索引。
假设有如下联合索引:
CREATE INDEX idx_user_name_age ON user(name, age, gender);
能用到索引的查询:
SELECT * FROM user WHERE name = '张三'; -- 匹配最左列
SELECT * FROM user WHERE name = '张三' AND age = 20; -- 匹配前两列
SELECT * FROM user WHERE name = '张三' AND age = 20 AND gender = '男'; -- 匹配全部
SELECT * FROM user WHERE name = '张三' AND gender = '男'; -- 跳过age,但name在最左,仍可用到name索引部分
不能用到索引的查询:
SELECT * FROM user WHERE age = 20; -- 跳过最左列name,索引失效
SELECT * FROM user WHERE gender = '男'; -- 跳过最左列name,索引失效
只有从最左边的索引列开始连续匹配,才能用到联合索引,这就是最左匹配原则。启示:尽量扩展索引,减少B+树的创建,降低索引的空间占用和维护时间的代价