
第三章:MinIO存储(数据湖)
欢迎回来,数据探险家们!
-
在第一章:MySQL数据库(源系统)中,我们看到了原始咖啡销售数据的起点。
-
在第二章:Spark作业(数据处理)中,我们学习了Spark作业如何作为强大的工作者来清洗、转换和准备这些数据。
现在,处理后的数据去往何处?Spark作业在后续步骤中从哪里获取数据?我们需要一个中心位置,一个为海量多样化数据设计的大型存储区域。这就引出了我们的第三个关键概念:MinIO存储(数据湖)。
什么是数据湖?
想象您有大量不同类型的信息:来自MySQL的销售记录、网站点击数据、客户反馈笔记、库存电子表格等。
传统上,您可能会尝试将所有内容放入严格的数据库中,但如果数据没有完美结构化,这可能很困难。
-
数据湖 就像一个巨大、灵活的存储库,可以大规模存储
结构化或非结构化数据。 -
它是一个集中存储库,以原始或接近原始的格式收集来自各种来源的数据。在存入数据时,不必预先决定如何使用这些数据;可以稍后确定。这使其非常灵活。
在我们的流水线中,数据湖是数据离开源系统后 但完全准备好进行最终分析或报告前 的存储位置。这是中间(也是主要)的存储位置。
什么是MinIO?
MinIO是本项目中用作数据湖的具体工具。
-
将MinIO视为自己的本地版Amazon S3等云存储服务。
-
它提供与S3兼容的接口,这是通过互联网存储和检索大文件的流行方式。
为什么使用MinIO而不是实际云存储?
- 本地运行 :它
直接运行在项目的Docker环境中,无需云账户或互联网即可运行核心流水线 - S3兼容性:因其"对话方式"与S3相同,专为S3设计的工具(如Apache Spark)无需特殊配置即可轻松连接MinIO
- 简单易用:便于开发和学习的设置和管理
因此,MinIO是我们本地化、兼容S3的存储系统,充当数据的中心枢纽。
MinIO中的数据组织:存储桶与路径
在MinIO(及S3)等存储系统中,数据通过两个主要概念组织:
- 存储桶 :类似顶级文件夹或容器,需赋予唯一名称(如
bronze-layer或silver-layer) - 对象/文件 :实际数据文件(如包含订单的Parquet文件),对象存储在存储桶内部
将对象存入存储桶时,需指定键 或路径 ,即其在存储桶内的名称和位置。该路径通常类似计算机文件路径(如brz.orders/year=2023/month=10/day=26/part-00000.parquet)。
在本项目中,我们用存储桶表示不同数据层 (第四章:数据层(青铜、白银、黄金)),并通过路径组织表及分区(如按年/月/日)。
为什么选择MinIO?
- 中心存储:所有处理数据的统一存储位置,供后续步骤读取
- 可扩展性(概念):虽然本地MinIO规模小,但S3概念可扩展至PB级存储,这种设计模式能很好转化为真实云数据湖
- 基于文件 :数据湖通常以文件(如Parquet)形式存储数据,这与MySQL等事务型数据库的行式存储不同,
文件存储更适合Spark等工具的大规模分析读取 - 支持数据分层:可轻松为青铜、白银和黄金层创建独立存储桶或文件夹,保持数据处理层级的组织性
Spark作业与MinIO的交互
在第二章中我们简要看到,Spark作业需要知道如何连接MinIO。这种连接通过SparkSession配置建立。
重看create_SparkSession函数片段:
python
# 来源: scripts/batch/bronze_dimension_fact_load.py
def create_SparkSession() -> SparkSession:
return SparkSession.builder \
.appName("从MySQL到MinIO的数据导入") \
.config("spark.hadoop.fs.s3a.endpoint", "http://minio:9000") \
.config("spark.hadoop.fs.s3a.access.key", "minioadmin") \
.config("spark.hadoop.fs.s3a.secret.key", "minioadmin") \
.config("spark.hadoop.fs.s3a.path.style.access", "true") \
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
# ... 其他配置 ...
.getOrCreate()以spark.hadoop.fs.s3a.开头的行是关键:
spark.hadoop.fs.s3a.endpoint:指定MinIO服务器网络地址(minio对应docker-compose.yaml中的服务名)和端口(9000)spark.hadoop.fs.s3a.access.key和spark.hadoop.fs.s3a.secret.key:提供Spark连接MinIO所需的用户名和密码(与docker-compose.yaml中的MINIO_ROOT_USER和MINIO_ROOT_PASSWORD匹配)spark.hadoop.fs.s3a.path.style.access:非真实Amazon S3服务时需要的技术设置,确保Spark正确构建请求路径spark.hadoop.fs.s3a.impl:指定Spark用于S3通信的库(文件系统实现),S3AFileSystem专用于S3兼容存储
配置完成后,Spark能将s3a://bronze-layer/brz.orders等路径转换为向MinIO服务器的请求。
后台工作原理
当Spark作业使用s3a://路径读写数据时,简化流程如下:

Spark脚本定义高级任务(读/写),SparkSession协调实际操作。S3A连接器将Spark文件操作转换为MinIO理解的S3协议。
MinIO接收请求,使用配置和凭证在物理存储(通过Docker卷映射到计算机文件夹)中查找或保存数据文件。
Docker Compose中的MinIO配置
通过docker-compose-batch.yaml文件查看MinIO的项目配置:
yaml
# 来源: docker-compose-batch.yaml
services:
# ... 其他服务 ...
minio:
image: minio/minio:latest # 使用官方MinIO Docker镜像
container_name: minio # 容器命名为'minio'
ports:
- "9000:9000" # 暴露S3 API端口(供Spark/工具连接)
- "9001:9001" # 暴露MinIO控制台端口(用于浏览数据)
environment: # 设置MinIO凭证
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
volumes:
- ./volumes/minio:/data # 将本地文件夹映射到MinIO数据存储位置
command: server /data --console-address ":9001" # 启动MinIO服务器的命令
restart: always # 始终重启
networks:
- myNetwork # 连接到共享网络该配置定义minio服务:
- 拉取官方镜像、设置网络和端口、定义根用户密码(Spark使用)
- 最重要的是通过
volume映射(./volumes/minio:/data)将MinIO内部/data目录的数据存储到本地./volumes/minio文件夹,即数据湖文件的实际存储位置。
Spark读写示例
从MinIO读取:
python
# 来源: scripts/batch/silver_dimensions.py
def read_bronze_layer(spark, table):
# 示例路径:s3a://bronze-layer/brz.stores
bronze_path = f"s3a://bronze-layer/{table}"
print(f"从 {bronze_path} 读取数据") # 添加打印说明
return spark.read.parquet(bronze_path)
# 使用示例:
# spark = create_SparkSession() # 假设已创建Spark会话
# stores_df = read_bronze_layer(spark, table="brz.stores")
# stores_df.show() # 显示前几行(示例输出如下)写入MinIO:
python
# 来源: scripts/batch/bronze_dimension_fact_load.py(简化)
# enriched_orders 是待保存的Spark DataFrame
orders_path = "s3a://bronze-layer/brz.orders"
print(f"写入数据到 {orders_path}") # 添加打印说明
enriched_orders.write \
.partitionBy("year", "month", "day") \
.mode("append") \
.parquet(orders_path)
# 执行过程:
# Spark获取'enriched_orders' DataFrame数据
# 按'year'、'month'和'day'列分组
# 将数据写入指定路径's3a://bronze-layer/brz.orders'
# 通过partitionBy创建子文件夹如:
# bronze-layer/brz.orders/year=2023/month=10/day=26/part-....parquet
# mode("append")表示若分区已存在数据,则追加新行
# 数据以Parquet格式保存总结
MinIO是本项目的本地数据湖,提供关键、可扩展且灵活的存储。
-
它作为中心仓库,存储从源系统提取后的数据,以及数据处理不同阶段的中间结果(第四章:数据层(青铜、白银、黄金))。
-
Spark作业通过S3兼容接口(
s3a://)连接MinIO,读取原始/处理数据并写入转换结果,通常采用Parquet等高效文件格式,通过存储桶和路径进行组织。
理解MinIO作为中心存储的角色至关重要,因为这是流水线所有中间和最终数据集的存储位置。
第四章:数据层(青铜、白银、黄金)
欢迎回到咖啡销售数据流水线构建之旅!
在前几章中,我们建立了数据起点(第一章:MySQL数据库(源系统)、了解了数据处理引擎(第二章:Spark作业(数据处理)),并搭建了中心存储区(第三章:MinIO存储(数据湖))。
-
现在有了存储海量数据的场所(MinIO数据湖),我们需要分阶段组织和处理数据。
-
简单堆砌所有数据会迅速导致混乱!
-
回想工厂的比喻:原材料进入后不会立即成为成品,而是经历初筛清洗、部件加工、最终组装等阶段。
-
我们的数据流水线也通过数据层 实现类似的分级提炼,这是数据工程中常见且有效的模式CITE_6 CITE_2。
在coffee-sales-data-pipeline项目中,我们使用三个核心数据层:青铜层 、白银层 和黄金层,代表数据提炼的不同阶段。
1. 青铜层(原材料堆)
- 类比:工厂接收的原材料堆
- 目的 :以
原始格式存储从源系统提取的数据,也称为"原始区" - 特性 :
- 不可变性:数据一旦存入通常不再修改,源系统变更时添加新版本,保留历史记录
- 历史存档:完整记录源系统不同时间点的数据状态
- 最小化转换:仅基础格式转换(如数据库行转Parquet文件),无清洗/过滤/关联操作
- 全量保留:包含所有字段(含冗余/无效字段)
- 使用者:数据工程师(用于下游处理调试或重处理)
- 项目实现 :存储在MinIO的
bronze-layer存储桶,文件如brz.orders、brz.stores等
数据入青铜层流程
Spark作业(scripts/batch/bronze_dimension_fact_load.py)从MySQL直接读取数据并写入MinIO青铜层:
python
# 来源: scripts/batch/bronze_dimension_fact_load.py
def read_mysql_table(spark: SparkSession, table: str):
# ... MySQL连接配置 ...
return spark.read \
.format("jdbc") \
.option("dbtable", table) \
.load() # <<< 从MySQL读取DataFrame
def incremental_load_orders(spark: SparkSession) -> None:
orders_df = read_mysql_table(spark, "orders") # 读取订单表
orders_path = "s3a://bronze-layer/brz.orders" # MinIO目标路径
# ... 增量加载检查逻辑 ...
enriched_orders = orders_df.withColumn("year", year("timestamp")) \
.withColumn("month", month("timestamp")) \
.withColumn("day", dayofmonth("timestamp")) # 添加日期分区列
logger.info("[BRONZE][orders] 正在写入青铜层...")
enriched_orders.write.partitionBy("year", "month", "day").mode("append").parquet(orders_path) # <<< 写入青铜层关键步骤:
- 通过
read_mysql_table读取MySQL原始数据 - 定义
s3a://bronze-layer/brz.orders存储路径(使用S3A协议连接MinIO) - 添加年月日分区列(基础转换)
- 使用
.write.parquet()写入MinIO,partitionBy实现日期分区,append模式追加新数据
2. 白银层(清洁标准件)
- 类比:经过清洗和标准化处理的零部件
- 目的 :存储清洗验证后的结构化数据,称为"清洁集成区"
- 特性 :
- 数据清洗:处理格式不一致/缺失值/错误记录
- 标准化 :统一命名规范与数据类型
- 基础转换:简单关联(如商品与类目关联),不含聚合计算
- 字段筛选 :
剔除青铜层冗余字段 - 结构化存储:Parquet等列式存储格式
- 使用者:数据科学家(特征工程)、分析师(探索性分析)
- 项目实现 :存储在MinIO的
silver-layer存储桶,文件如slv.stores、slv.products等
数据入白银层流程
Spark作业从青铜层读取数据,清洗后写入白银层。以stores表处理为例:
python
# 来源: scripts/batch/silver_dimensions.py
def read_bronze_layer(spark, table):
return spark.read.parquet(f"s3a://bronze-layer/{table}") # <<< 从青铜层读取
def cleand_stores(spark, silver_path, table):
source_df = read_bronze_layer(spark, table="brz.stores") # 读取原始门店数据
# 清洗示例:移除城市名称中的\r字符
cleaned_df = source_df.withColumn("city_cleaned", expr("regexp_replace(city, '\\\\r$', '')")) # <<< 数据清洗
# 字段选择与重命名
output_df = cleaned_df.selectExpr(
"id AS store_id",
"name AS store_name",
"address",
"district",
"city_cleaned AS city", # 使用清洗后字段
"updated_at"
)
output_df.write.mode("overwrite").parquet(f"{silver_path}/{table}") # <<< 写入白银层关键步骤:
- 从青铜层读取原始数据
python
def cleand_stores(spark, silver_path, table):
source_df = read_bronze_layer(spark, table="brz.stores") # 读取原始门店数据- 使用正则表达式清洗
city字段 - 选择关键字段并标准化命名
overwrite模式覆写最新清洗数据(维度表常用)
3. 黄金层(终端成品)
- 类比:组装完毕待售的成品
- 目的 :存储高度聚合/建模数据,采用星型/雪花模型等分析友好结构,称为"消费区"
- 特性 :
- 即席查询:直接供BI工具(Tableau/Power BI)使用
- 聚合建模:按日/门店汇总销售数据,构建事实表与维度表
- 业务逻辑 :集成复杂
计算规则(如促销计算) - 读取优化 :
列式存储+分区+索引加速查询 - 数据融合:整合多白银表及外部数据源
- 使用者:商业分析师/报表系统/机器学习模型
- 项目实现 :存储在MinIO的
gold-layer存储桶,使用Delta Lake格式,包含gld.dim_stores等维度表和gld.fact_orders事实表
数据入黄金层流程
Spark作业整合白银层数据和现有黄金维度表,构建最终数据集:
python
# 来源: scripts/batch/gold_fact_orders.py
def write_to_fact_orders(spark, gold_path):
# 读取白银层订单数据
orders = read_silver_layer(spark, table="orders")
order_details = read_silver_layer(spark, table="order_details")
# 读取黄金维度表
dim_products = read_gold_layer(spark, table="dim_products")
dim_stores = read_gold_layer(spark, table="dim_stores")
# 关联事实数据与维度表
join_df = new_orders.join(order_details, ...) # 关联订单明细
join_df = join_df.join(broadcast(dim_products), ...) # 关联商品维度
# 构建事实表结构
final_fact_df = join_df.selectExpr(
"year", "month", "day",
"s_store_key AS store_key", # 维度代理键
"od_quantity AS quantity" # 度量值
)
final_fact_df.write.format("delta").partitionBy("year", "month", "day").save(f"{gold_path}/gld.fact_orders") # <<< 写入黄金层关键步骤:
- 从白银层读取订单明细数据
- 关联黄金维度表获取代理键(实现SCD逻辑)
- 构建星型模型结构(事实表+维度键)
使用Delta格式写入,实现ACID事务支持
数据层对比
| 特性 | 青铜层 | 白银层 | 黄金层 |
|---|---|---|---|
| 数据状态 | 原始数据 | 清洗结构化数据 | 聚合建模数据 |
| 转换复杂度 | 格式转换 | 清洗/标准化 | 业务逻辑/关联聚合 |
| 使用者 | 数据工程师 | 数据科学家/工程师 | 分析师/BI工具 |
| 存储路径 | s3a://bronze-layer/ |
s3a://silver-layer/ |
s3a://gold-layer/ |
| 存储格式 | Parquet | Parquet | Delta Lake |
数据流动图
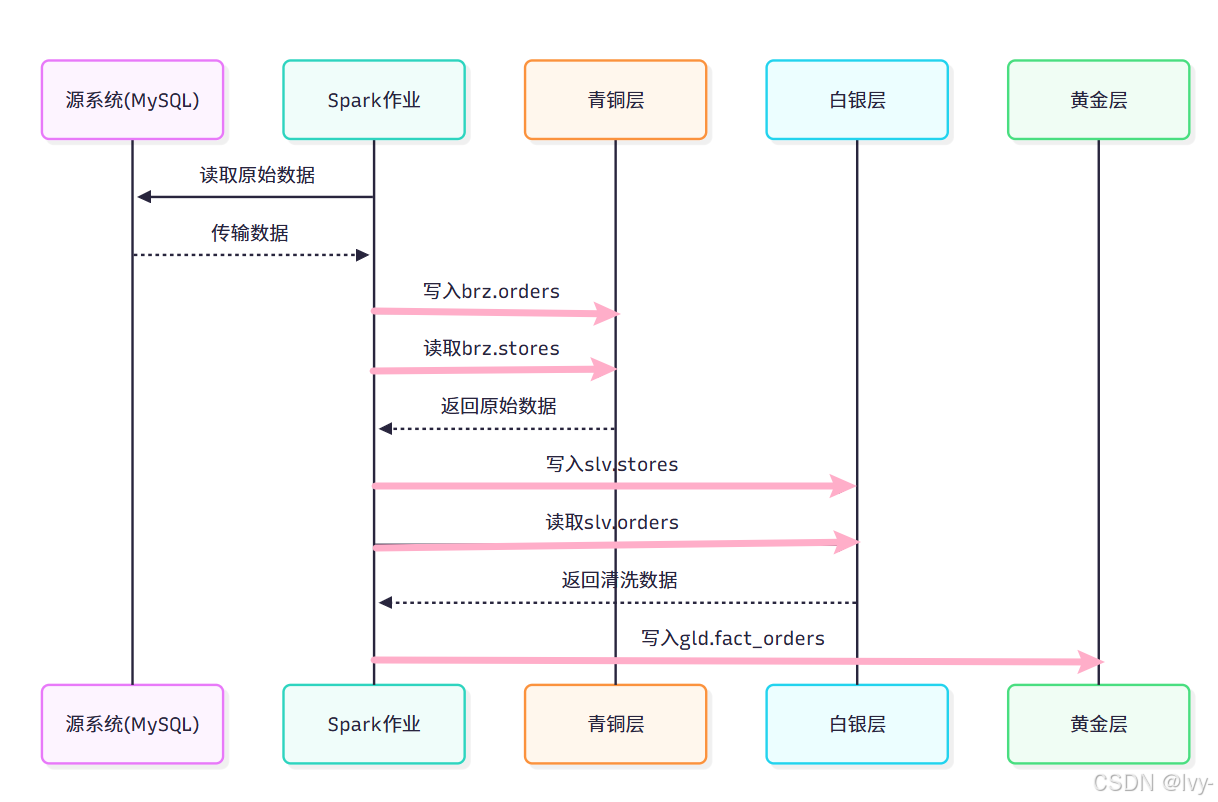
总结
数据层(青铜/白银/黄金)在MinIO数据湖中构建了分级处理体系$CITE_6:
- 青铜层 作为
不可变原始数据存档 - 白银层 提供
标准化清洗数据 - 黄金层 交付
业务就绪型数据集
该分层架构支撑了从原始数据到商业洞察的全链路处理,各层特性满足不同角色的数据消费需求