一.rocksDB
1.什么是rocksDB
RocksDB 是一种可以存储任意二进制kv数据的嵌入式存储。RocksDB 按顺序组织所有数据,他们 的通用操作是 Get(key) , NewIterator() , Put(key, value) , Delete(Key) 以及SingleDelete(key) 。
LSM-Tree
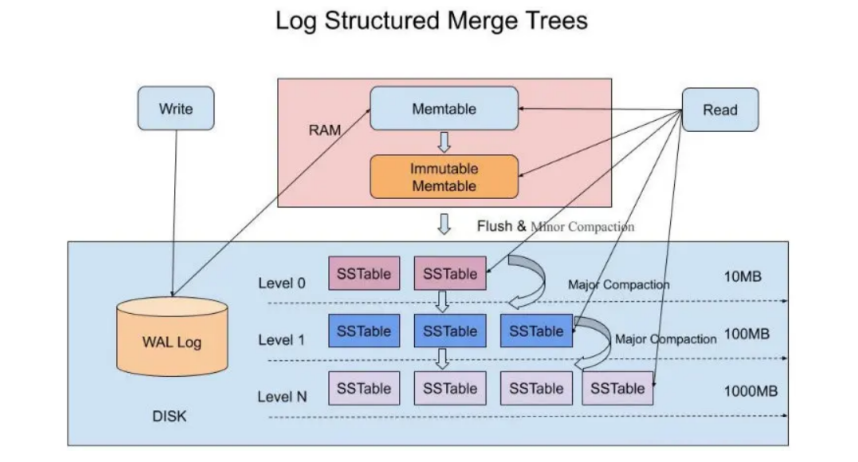
WAL Log(预写日志)
写入操作首先记录到WAL(Write Ahead Log),保证数据不丢失。
Memtable(内存表)数据写入后先进入内存中的Memtable,Memtable是一个有序的数据结构(如跳表、红黑树)。
Immutable Memtable当Memtable满了,会变成Immutable Memtable,新的写入进入新的Memtable。Immutable Memtable会被异步刷写到磁盘。
SSTable(有序字符串表)Immutable Memtable刷写到磁盘后,形成SSTable文件。SSTable是不可变的、按key有序的文件。
多级存储(Level 0, Level 1, ... Level N)SSTable文件分为多个层级,每一层容量递增。
Level 0容量最小,文件最多,容易有重叠。
随着数据量增加,SSTable会通过**Compaction(合并压缩)**操作向下合并到更高层,减少重叠和空间浪费。
读操作读请求会先查Memtable、Immutable Memtable,再查各级SSTable,通常会用Bloom Filter等加速查找。
LSM-Tree广泛应用于NoSQL数据库、日志系统等需要高写入吞吐的系统。
2.RocksDB 如何实现高效的读操作?
通过 Bloom Filter、Block Cache、索引等机制加速查找,先查内存再查磁盘。
3.RocksDB 支持事务吗?
支持,RocksDB 提供了事务 API,可以实现原子性和隔离性。
4.RocksDB 的 Level Compaction 和 Universal Compaction 有什么区别?
Level Compaction 按层级合并,适合大多数场景;Universal Compaction 适合写多读少、延迟敏感的场景。
5.RocksDB 如何进行数据恢复?
通过重放 WAL 日志和加载 SSTable 文件恢复数据。
6.RocksDB 如何进行参数调优?
可以通过调整 MemTable 大小、Compaction 策略、Block Cache 大小等参数优化性能。
二.TiDB
1.TiDB 是什么?适合哪些场景?
TiDB 是一款开源的分布式关系型数据库,兼容 MySQL 协议,适合高可用、高扩展、高并发的 OLTP 和 HTAP 场景。
2.TiDB 的核心组件有哪些?
主要包括 TiDB Server(SQL 计算层)、TiKV(分布式存储层)、PD(Placement Driver,调度和元数据管理)、TiFlash(列存,分析型场景)。
3.TiDB 如何实现分布式事务?
基于 Percolator 两阶段提交协议(2PC),通过 Prewrite 和 Commit 两步保证分布式事务的原子性和一致性。
4.TiDB 的数据是如何分片和分布的?
数据以 Region 为单位分片,每个 Region 默认 96MB,分布在不同的 TiKV 节点上,PD 负责调度和负载均衡。
5.TiDB 如何保证高可用和数据安全?
通过 Raft 协议实现多副本强一致,Region 有多个副本,主从自动切换,节点故障自动恢复。
6.TiDB 如何进行水平扩展?
通过增加 TiDB、TiKV、TiFlash 节点即可实现计算和存储的弹性扩展,无需停机。
7.TiDB 和 MySQL 有哪些区别?
TiDB 是分布式架构,支持弹性扩展和高可用,MySQL 是单机或主从架构,扩展性有限。
8.TiDB 如何实现 SQL 兼容性?
TiDB 兼容 MySQL 协议和大部分 MySQL 语法,方便迁移和使用。
9.TiDB 如何处理大表和大事务?
通过分片、分布式事务和批量写入等机制优化大表和大事务的处理能力。
10.TiDB 常用的调优手段有哪些?
包括 SQL 优化(如加索引、合理分表)、参数调优(如 Region 大小、并发数)、硬件资源优化等。
三.etcd
1.etcd中一个任期是什么意思
etcd是分布式小型kv数据库,用于解决共享配置和服务发现
ectd架构图

etcd leader 用于读写服务 ,follower用于备份同步
任期开始于一个选举,选举之后将会产生一个leader,在它的任期内会管理整个集群直至任期结束
集群启动时,产生选举
leader不可用的时候,重新选举
2.etcd中raft状态机是怎么样切换的

节点状态:follower,candidate,leader
初始状态:所有节点初始为Follower状态。超时触发选举:如果Follower在一定时间内没有收到Leader的心跳(AppendEntries RPC),就会变为Candidate,发起新一轮选举。
发起投票:Candidate节点向其他所有节点发送RequestVote请求,并为自己投票。
投票统计:如果Candidate收到超过半数节点的投票(包括自己),则成为新的Leader。
选举失败:如果没有节点获得多数票,或出现投票冲突,所有节点会重新进入下一轮选举,直到选出Leader。
Leader发送心跳:新Leader产生后,定期向其他节点发送心跳,维持自己的领导地位。
为什么有时候要增加precandidate状态避免数据落后太多的节点参与选举
状态迁移图

3.如何防止候选者在遗漏数据的情况下成为总统
在Raft算法中,为了防止日志不完整或落后的候选者成为Leader,Raft在选举时采用了**"日志新鲜度"检查机制**:
RequestVote RPC请求中,候选者会携带自己的最后一条日志的索引和任期(lastLogIndex, lastLogTerm)。follower在收到投票请求时,会比较自己的最后一条日志和候选者的日志新鲜度
只有当候选者的日志至少和自己一样新时,才会投票给候选者。
如果候选者的日志比自己的旧(任期小,或任期相同但索引小),则拒绝投票。
4.etcd中某个节点宕机后会怎么做
自动检测:其他节点会通过心跳检测到该节点不可用。
继续服务:只要集群中存活节点数量超过半数(有法定票数),etcd集群仍可正常读写和选举Leader。
重新选举:如果宕机节点是Leader,剩余节点会自动发起Leader选举,选出新的Leader。
数据同步:宕机节点恢复上线后,会自动与集群中最新的节点进行数据同步,补齐缺失的数据日志,重新加入集群。
etcd具备高可用和自动恢复能力,单个节点宕机不会影响集群整体服务。
5.etcd中如何选举出leader节点
初始状态:所有节点都是Follower。
超时触发选举:如果Follower在一定时间内没有收到Leader的心跳,会变为Candidate,发起选举。
发起投票:Candidate向其他节点发送RequestVote请求,并为自己投票。
投票统计:如果Candidate获得超过半数节点的投票,就成为Leader。
选举失败:如果没有节点获得多数票,进入新一轮选举,直到选出Leader。
Leader维持:Leader定期发送心跳,维持领导地位。
6.etcd如何保持数据一致性
日志复制:所有写操作先写入Leader节点,Leader将操作日志同步(AppendEntries)到大多数Follower节点。
多数确认:只有当大多数节点写入成功后,Leader才提交该操作,并通知Follower提交。
顺序一致:所有节点按相同顺序应用日志,保证数据状态一致。
自动恢复:节点宕机恢复后,会自动从Leader同步缺失的日志,保证数据一致。
强一致读写:客户端可通过Leader进行强一致性读写,确保读取到最新数据。