我自己的原文哦~https://blog.51cto.com/whaosoft/13998765
#Agentic AI时刻
多智能体驱动,「一人公司」这就要来了
Code is cheap, show me the talk.
最近,很多 AI 大佬一反常态,对未来做出了超出预期的乐观预测。
诺贝尔奖获得者、AI 先驱 Geoffrey Hinton 表示,人工智能将在多个领域「取代所有人」,只有顶尖技能人才能够找到 AI 无法处理的工作。
特斯拉前负责人 Andrej Karpathy 在演讲中也认为,我们正在进入「软件 3.0」时代,自然语言在成为新的编程接口,大模型会完成剩下的工作。
正在让 AI 能力大幅提升的技术被称为智能体(Agentic AI),它能够长时间独立运行、感知环境,自主使用各种工具来完成复杂任务。最近有研究甚至证明,智能体也遵循大语言模型的测试时扩展(Test-Time Scaling)规律,能够通过强推理不断提升解题能力。
事实上,智能化发展的过程比我们想象得还要快。正在上海举行的亚马逊云科技中国峰会上,我们看到了一系列基于大模型、Agentic AI 的创新和案例,让我们眼花缭乱。
「通俗说来,Agentic AI 就是让基于大模型的 AI 从『我问 AI 答』、『我说 AI 写』发展到『我说 AI 做』。AI 驱动的数字员工能将像人一样在各行各业,为企业带来新的生产力,」亚马逊云科技大中华区总裁储瑞松说道。
手搓 Agentic AI 应用
仅需不到 30 行代码
如今想用 AI Coding 来开发一个抽奖的小应用,到底有多简单?
在 Amazon Q Developer 上,你只需要先与 AI 进行聊天交互,了解需求,AI 会自动生成一份有关后端代码的技术文档,进而生成执行计划。在读取执行计划后,Q 能够自动生成一系列提示词,帮助我们生成代码,生成的代码可以一键修正错误。

前端代码就更简单了,直接输入一个截图,Q 就可以把界面转换成代码。生成内容出错的地方,只需要用自然语言指出并一键修复即可。在程序完成之后,我们也可以用 Q 进行部署、测试,并在上线之前解决安全问题。最后在这个项目中,有 90% 的代码是由 Q 生成的。
AI 也可以帮助架构师改造项目适用的环境版本。比如想把 Windows 的应用转换成 Linux 的,使用 Amazon Transform,不到一分钟,5000 多行代码就修改了 4800 多行,还立即在 GitHub 上自动提交了分支。


围绕 Bedrock Agents,人们可以围绕大量内部数据快速构建,转换不同工具执行任务。我们可以调用 Lambda 查看游戏发行生成的内容,也可以调用非结构化数据进行相关内容的生成。
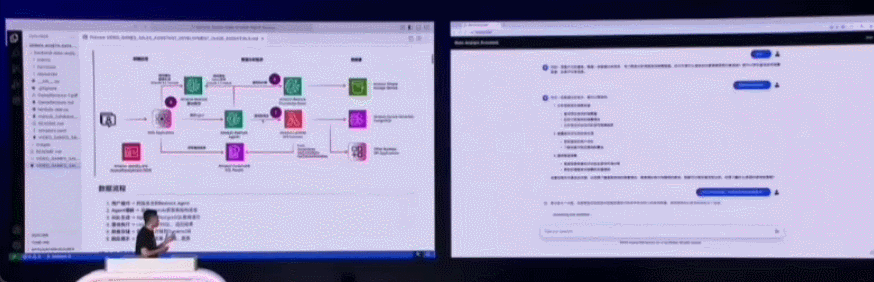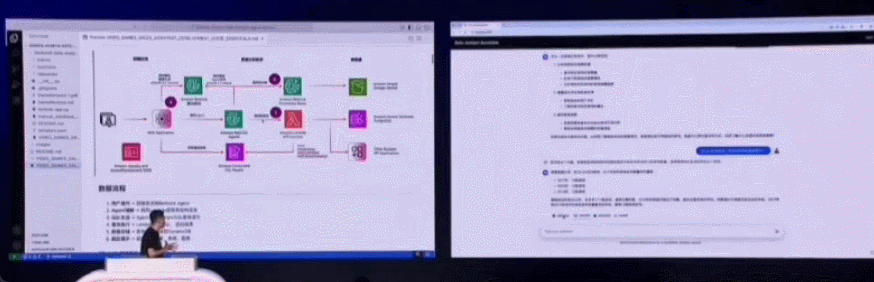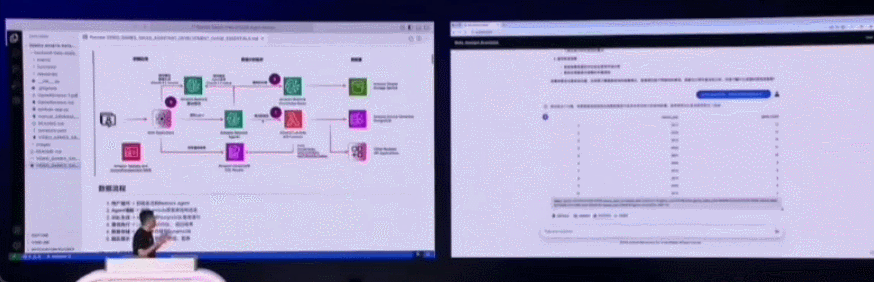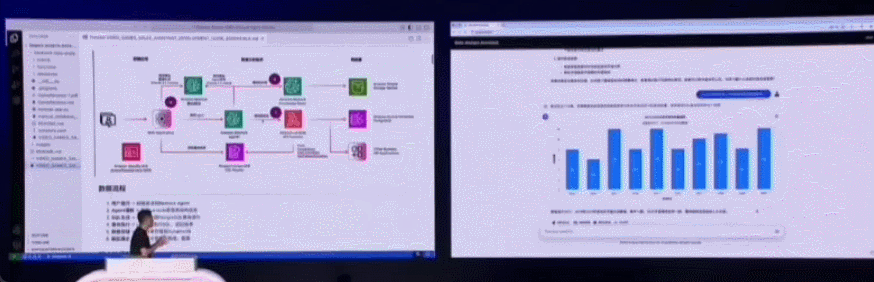
在一些简单任务上,我们可以使用开源的 Strand Agents,由它帮助构建的 AI 采购助手使用亚马逊云科技托管的 Claude 3.7 Sonnet 大模型作为大脑,用户使用自然语言在前端提问,Agent 就能理解用户需求,调出相应的 MCP 工具进行具体操作,浏览网页、筛选、进行推荐并以自然语言的形式返回结果。
这样的智能体工具,我们可以在一天之内完成原型开发验证,代码不超过 30 行。

多 Agent 之间也可以进行交互。中央协调器的大模型(Claude 4)在获取需求后自动指定相应的不同 Agent 进行编排,搜索并调用 MCP 服务形成报告,自动解析 PDF 和形成报告生成行程推荐。

以上的实现都基于亚马逊云科技提供的工具,它们分别针对特定场景、软件开发全流程,以及多智能体轻量级开发。
亚马逊云科技大中华区解决方案架构总经理代闻表示,由于智能体能力的提升,多模型混合使用的应用将成为常态;如今大家对于 AI 的关注点已经从模型性能的跑分,转变成为 AI 的应用;另外,大模型带来的 Text to Action 正在重新定义交互内容和能力边界。
基于此种能力,已有不少企业跨越了实验阶段,将生成式 AI 的解决方案应用于实际运营,并在三个关键领域取得了切实的效益 ------ 提高生产力、降低成本和加快创新周期。
作为一家 AI 公司,合合信息从成立以来一直专注于文本图像领域的 AI 算法和应用研究,它基于亚马逊云科技实现业务出海,构建了支撑扫描全能王、名片识别等核心产品,为全球 200 多个国家的用户提供高可用、低延时、安全合规的服务。
为了更好地利用企业文档数据资源,基于 Amazon Bedrock 和 OCR 大模型,合合信息还构建了一个文档处理 Agent:DocFlow。只需要分钟级的时间就能从云存储中快速地读取各类文档,并且自动完成优化、分类、信息抽取和审核,从而大大提升数据处理效率。

Agentic AI 在知识信息密集的领域也发挥了巨大的作用。举例来说,在医学撰写方面,一个典型的创新药项目需要以 10 万份文献数据以及数千的患者临床记录为输入,需要输出多达 200 多份的文档,总体的页数超过了 5000 页。这个工作量占据了研发工作量的 30~50%。
针对这一挑战,复星医药和亚马逊云科技展开了合作,将整个医学写作的场景进行了解构。借助生成式 AI 的能力,一键式完成实验报告检查,把长达一周的工作缩短到 5 分钟。另外,在医学翻译领域,借助亚马逊云科技技术,复星医药用 6 个月的时间已经完成了 1.6 个亿字的翻译,直接降本超过了 30%。

还有很多国内外公司,都在亚马逊云科技的这套 Agentic AI 体系上提升了效率,开启了前所未有的业务。这不由得让我们想起今年初人们喊出「AI 智能体爆发元年」的预测:从 AI 辅助到 AI 协作,再到数字同事,智能体最终可以构建成软件公司,帮助我们完成绝大多数任务。「一人公司」距离我们其实并不遥远。
Agentic AI 最令人兴奋的或许将是商业模式的创新 ------ 就像 Uber、 Airbnb 创造了共享经济模式,Netflix 开创了订阅制内容消费模式那样,随着 AI 的快速发展,现在处于正在进行时的,是深度集成 AI 的代码工具 Cursor、AI 实时搜索引擎 Perplexity......
「我们身处在 AI 时代,恰似置身于 30 米高的巨浪之中。AI 的发展已经来到了一个拐点。现在是时候行动了,」亚马逊云科技全球技术总经理 Shaown Nandi 表示。「坚信未来一年所做的事会为新的时代打下基础。」
打造 Agentic AI
亚马逊云科技拥有一套完整技术栈
但另一方面,生成式 AI 的落地并不是件容易的事。
今年 1 月,DeepSeek R1 成为了全球爆款应用,很多人在向它提问后遭遇了系统频频回复的「服务器繁忙,请稍后再试」;3 月份,ChatGPT 在提供原生图像生成功能后不到 72 小时就宣告临时下架,OpenAI CEO 山姆・奥特曼不得不宣布进行限流,并表示「GPU 在融化」。
不少爆款 AI 应用在走出陡峭增长曲线之后,面临着服务器容量饱和、安全合规、技术迭代困难等一系列挑战。为了能够跟上 AI 发展的加速度,企业需要正确的技术和全栈的工具。
此前,Amazon Bedrock 平台上提供的 Amazon Bedrock Agent 框架作为一款快速部署工具在业内已获得了人们的认可。它是一个全托管式的服务,支持集成 Bedrock 内置的安全、可用性机制、RAG 等能力,也集成亚马逊云科技各种服务,新增的 Multi-Agent 协作则可以应对复杂工作流程编排需要。
它大大简化了标准低级任务流程复杂性,如调用 LLM、定义和解析工具以及链接调用,从而简化了工作流程。
其实,在能力层、基础设施、编排层、体验层等应用生命的全流程里,亚马逊云科技都提供了大量实操性的策略和实用工具,能够帮助你快速构建 Agentic AI。
首先是多种先进模型的选择。现在的 AI 发展速度惊人,而且我们知道不可能有一个模型可以适用于所有任务。Amazon Bedrock 不但集成了 DeepSeek R1、Anthropic Claude、Meta Llama、AI21 Labs、Cohere 等顶尖模型,亚马逊云科技自主研发的 Amazon Nova 系列基础模型也包含在内,在速度和成本方面提供更多不同选择,涵盖理解、图像、语音、视频等工作,新款 Amazon Nova Act 模型也即将上线 Amazon Bedrock 平台。

第二点是模型定制能力。将自己的数据引入模型,是释放 AI 价值其中最重要的一步。现在 Amazon Bedrock 支持端到端的全托管 RAG 功能。该功能允许企业直接将模型与内部数据源(如数据库、文档库)安全连接,无需自行搭建复杂的检索管道,即可生成基于企业私有数据的精准回答。

第三点是信任与安全。这是所有生成式 AI 应用的核心。Amazon Bedrock 提供的 Guardrails(安全护栏) 功能,可以帮助用户屏蔽有害或不合规的输入与输出,并且这些 Guardrails 是可以继承的。

此外,为了解决大模型幻觉现象,Bedrock Guardrails 率先推出了自动化推理(Automated Reasoning)功能,其中 Reasoning Checks(推理校验)能基于逻辑验证和可证明的依据,有效防止生成式 AI 出现事实性错误和幻觉内容。目前,只有亚马逊云科技提供这一功能。

自动化推理验证原理。
第四点是成本效益。亚马逊云科技一直致力于帮助客户优化成本,同时不牺牲结果质量。为了达到此目的,他们在 Amazon Bedrock 中引入了模型蒸馏,蒸馏后的模型最多可提升 500% 的响应速度,成本降低 75%。
针对更广泛的应用场景,Amazon Bedrock 还提供了智能提示词路由功能。用户可以为一个应用配置多个模型,Amazon Bedrock 会根据请求内容自动选择最适合的模型来响应,从而在保证准确率的前提下,将成本降低高达 30%。
可以看出,从灵活的模型选择,到节省资源的优化策略,Amazon Bedrock 已内建了生成式 AI 应用所需的完整能力,为企业带来性能与成本的双重优势。
为了让更多开发者能够灵活地探索 Agent 能力,亚马逊云科技也提供了更加开放、自主的方式。

围绕特定场景,围绕 Amazon Q Agents 的开箱即用工具可以涵盖代码开发、IT 运维、应用现代化等步骤,覆盖生命全周期;
在基础模型之上,Amazon Bedrock Agents 可以实现强大的工作流程编排能力;
对于轻量级任务,Strands Agents 开源框架可以构建出灵活的多智能体应用。
对于那些倾向于自己动手、深入定制的开发者来说,你不妨试试 Strands Agents------ 一款开源 Python SDK,只需寥寥数行代码就能构建智能 Agent。Strands Agents 通过集成最先进的模型,为开发者省去了复杂的 Agent 编排工作。

如何赋能开发者,如何为应用奠定在 Amazon Bedrock 上成功运行生成式 AI 的基础?那么接下来的关键问题是 ------ 怎样真正把生成式 AI 应用构建出来?
这就需要借助亚马逊云科技的一款生成式 AI 助手 Q Developer,其拥有较高的代码接受率。一般而言,大多数开发者平均每天真正写代码的时间只有 1 小时,其余时间都花在团队协作、撰写文档、项目规划等各类任务上。
与其他 AI 助手不同,Q Developer 能在整个软件开发生命周期中为你赋能。你可以与 Q Developer 对话,了解其能力、架构解决方案,你也可以在 IDE 内直接与 Q Developer 聊天,共同生成代码、拆分任务、集成 API ,还能点击一下进行测试,扫描那些难以发现的安全漏洞。可以说,Q Developer 是一位全天候的 AI 助手。
另外,很多开发者更喜欢通过命令行工作,因此亚马逊云科技发布了全新的 Q Developer CLI Agent。它能结合 Q Developer CLI 环境中的信息,执行读写文件、编写代码、自动调试等任务。

Q Developer 可以帮助你自动化日常开发任务,但开发者的大量时间其实并不在构建新应用上,而在于维护旧系统 ------ 包括管理、现代化改造、打补丁等。
利用 Amazon Q 能力 ,亚马逊云科技找了五人团队在两天内将 1000 个 Java 应用程序从 Java 8 升级到 Java 17。平均每个应用耗时约 10 分钟,而传统方式可能需要两天。

现在,亚马逊云科技已经成功迁移数万个生产应用,年度开发工时节省 4500+,实现了 2.6 亿美元的年化成本节约。

这也给我们带来了思考,生成式 AI 如何变革整个 IT 系统?据估计,目前有 70% 的工作负载仍在本地运行,而 70% 的传统 IT 系统已有近 20 年历史。对于财富 500 强公司来说,应用迁移是一项长期工程。
Amazon Transform ------ 首个为加速 .NET、大型机和 VMware 工作负载的企业现代化而开发的代理式人工智能服务。Amazon Transform 可以帮助各个组织同时对数百个应用程序进行现代化改造,并保持高质量和控制力。
比如汤森路透利用 Amazon Transform,现代化升级速度比原计划快了 4 倍。

亚马逊云科技认为,Agentic AI 能够在三个方面带来组织方式的变革:1、统一的 AI 就绪的基础设施;2、聚合并治理过的 AI 就绪的数据;3、明确的策略和高效率的执行。
目前已经有超过 10 万客户在亚马逊云科技上进行机器学习工作,在中国的生成式人工智能创新中心,也有超过 1000 个深度合作客户。

宏观来看,亚马逊云科技已经把智能体放在了极其重要的位置,其 CEO Matt Garman 最近表示,Agentic AI 有机会成为亚马逊云科技下一个数十亿美元的规模业务。对此亚马逊云科技 3 月份已经成立了专门的智能体团队,直接向 CEO 报告,很快就会有重磅发布。
在 AI 时代,我们不止要创新,还要加速创新。亚马逊云科技正在成为加速创新可信赖的合作伙伴。
生成式 AI
实践出真知
在中国峰会主论坛上,亚马逊云科技正式发布了 Agentic AI 应用实践指南。其中包括智能体开发的基本范式、实践方案的示例,以及对于智能化转型的展望。基于该指导,任何人都可以在亚马逊云科技的平台上构建 AI 应用。

预计到 2028 年,15% 的日常工作决策将由 Agentic AI 自主完成,而这一比例在 2024 年几乎为零。这不仅仅是技术的迭代,更是软件应用本质的重新定义。
最近,OpenAI CEO 山姆・奥特曼在接受访谈时说道,通用人工智能(AGI)是一个动态的目标,或许更有意义的里程碑会是 ASI,即 AI 能够实现自主的科学发现。如果 AI 可以基于可靠的数据,理解复杂的需求,进行长期推理和规划,可靠地使用工具并及时纠正错误,那么我们就可以在更加重要的任务上,实现前所未有的自动化。
亚马逊云科技的能力,正在让我们距离这个愿景更进一步。
#AI导演正偷偷改写直播「剧本」
老罗数字人刷屏背后
AI直播终于不是噱头了。
这年头,真人主播还真干不过 AI。
今年 618 大促期间,「交个朋友」在百度优选搞了场直播,不过这场直播的主角不是人,而是 AI。直播间里,罗永浩和朱萧木两个数字人配合默契,不抢话、不抬杠,只是一味地带货、爆梗、讲段子,还时不时跟评论区网友来个互动。
「弹幕上问我怎么辨别茅台真假,简单喝一口,心疼就是真的,肝疼就是假的。」
「有人问方便面好不好吃,买回去尝尝,好吃就分给朋友一点,不好吃就全分给朋友。」
「你脸大有多大?能有我 210 斤的脸大吗?」
,时长00:10
这逼真效果,就连老罗本人看了都吓一跳:「他们在那儿眉来眼去,讲着跟我一样风格的段子,有点恍惚......」

更离谱的是,罗永浩数字人的直播「战绩」比真人还能打,整场直播吸引了超 1300 万人次观看,GMV 突破 5500 万元,部分核心品类带货量、用户平均观看直播时长均反超罗永浩本人在百度电商的直播首秀。
如此以假乱真的数字人到底是怎么做出来的?据老罗在微博上「自曝」,这用的是百度的多模协同数字人技术。
传统数字人生成技术常面临语音、语言、视觉多模态割裂的问题,具体表现为台词与语音语调不同步、表情手势与语义错位等,而百度的技术突破在于引入剧本驱动的多模协同。
具体来说,这套技术方案包含了剧本驱动的数字人多模协同、融合多模规划与深度思考的剧本生成、动态决策的实时交互、文本自控的语音合成、高一致性超拟真数字人长视频生成等五大创新技术,使数字人的「神、形、音、容、话」达到高度统一,最终呈现出一个具备高表现力、内容吸引人、人-物-场可自由交互的超拟真数字人。

语言模型为核心的剧本生成
在百度这套多模协同数字人技术方案中,剧本生成无疑是核心环节,涵盖台词、多模驱动和动态交互三部分。

最核心的台词需要解决三大关键问题。其一,通过风格建模为不同风格提供精细化定制,使台词呈现多样化风格,并与主播的个性高度契合;其二,通过人设建模、人物性格与行为逻辑的精准还原,以及在双人直播场景中保持多角色协同,塑造拟真化人设;其三,引入内容规划和深度思考机制,在保证讲品信息准确、富有说服力的同时增强吸引力,同时为避免「幻觉」,还在台词生成中融入事实校对和知识增强机制,保证每一句话都经得起推敲。
就以罗永浩数字人为例,罗永浩和朱萧木都具有强烈的个人风格,直播时经常会蹦出几句口头禅,为打造可控性强、极具真实感的虚拟主播,百度基于文心大模型 4.5 Turbo,投入海量真人直播数据,依托「转录挖掘、优质提炼、仿写合成与自动评估」四个环节不断优化训练语料,使模型深度吸收两位主播的语言特点与思维习惯,并在迭代学习中持续逼近更契合的输出效果。同时引入多角色协同机制,对不同主播的表达逻辑进行建模,使对话在语义推进、节奏控制和风格调性上保持协调一致,避免「各说各话」的割裂感。
所谓多模驱动,是指大语言模型基于任务目标与主播人设生成基础台词,并同步输出视觉与语音的多维标签。这些标签不仅是对语言内容的补充,更是驱动音视频生成系统实现自然、同步、富表现力输出的关键指令。比如,在语音合成阶段,模型利用剧本中的段间标签精细控制不同语段之间语调衔接,同时文本内容也能驱动 TTS 系统实现更细粒度的语调调控。音频合成结果再进一步与视觉标签联动,使视频生成系统能够实现唇动同步、高表现力的动作设计和情绪表达,从而在输出层实现「声、形、意」三模态的统一。
在此基础上,剧本生成还具备动态交互能力。比如 AI 老罗在卖纯牛奶时,有网友问 360 个月的宝宝能不能喝,AI 老罗便以「我 600 个月都能喝,谁还不是个宝宝呢」进行幽默回应,这种回应背后不仅是语言生成,更是基于人设风格、场景上下文、情绪基调等多模信息的综合决策。
文本自控的语音合成
在数字人技术逐渐渗透直播、电商、客服等互动场景的过程中,语音合成的自然度正成为决定用户沉浸感与信任度的关键因素。特别是在直播间,观众希望听到的不是生硬的朗诵或机械音,而是一种如同真人主播般富有情绪、节奏自然、具备沟通张力的表达方式。因此,数字人语音的「人味儿」越足,交互的真实感就越强,用户的接受度和互动意愿也随之提高。
然而,传统的语音合成技术往往呈现出字正腔圆但缺乏情感的表达风格,在充满情绪张力的直播场景中,这种过于规整的声音反而显得「出戏」。它无法像人类主播一样,适时展现语调的抑扬顿挫、节奏的快慢变化,也很难根据商品介绍、互动节奏等变化调整情绪状态,尤其是在呼吁用户下单、介绍爆款产品这类关键话术环节,传统 TTS 无法自然表达出情绪递进和感染力,进而影响整个数字人系统的说服力与亲和力。
针对这些现实痛点,百度提出了「文本自控的语音合成」方案,在大语言模型输出剧本之后,负责语音合成的大模型会结合文本内容、主播风格特点,以及对于细粒度韵律特征表示进行统一处理,这一过程中语音模型不仅知道「要说什么」,更知道「要怎么说」,从而在生成语音时自然带出情绪波动与语言节奏,使得语音在内容和表达方式上都更贴近真实人类。

例如,在罗永浩数字人直播间中,主播语音高度还原本尊的音色和语调,甚至在直播节奏中展现出自然的停顿、强调和情绪变化。同时,百度还解决了直播中双人互动的挑战。现实中,主播之间的配合往往包括打断、附和、重复等高频行为,这对语音合成提出了连贯性和互动性的更高要求。为此,百度引入了「对话上下文编码器」,将历史对话与当前对话的信息进行语音合成时的统一推理计算,以此实现「双人配合」的自然过渡。
高一致性超拟真数字人长视频生成
在数字人直播场景中,形象生成与驱动是当前技术难度最高的环节。首先必须解决多模协同的问题,它涉及多向的信息对齐:剧本对视频表达提出具体要求,TTS 语音又对视频节奏与动作生成形成约束,反过来视频本身还需对语音进行校准,最终需要实现「音、容、话」三者的一致性。
其次,主播在直播中往往伴随着大量手势、动作和表情等「高表现力动作」,它们对于强化用户情绪感染力具有显著作用,因此在视频生成阶段,不仅要忠实复现语言内容,还需对这些高表现力动作进行准确建模与流畅合成。
在场景交互层面,数字人直播还面临「人-物-场」自由交互的复杂性。主播需要与商品、背景和空间布局进行符合物理逻辑的互动,例如望向商品、举起物品或指向展示区等。若缺乏对空间关系的精准理解,极易出现穿模、错位等破坏沉浸感的瑕疵。
此外,直播时长也放大了技术一致性的难题。一场超 6 小时的直播,任何人物形象的波动、商品定位的误差以及动作风格的不一致都会直接拉低观众体验。
为此,百度提出了「高一致性超拟真数字人长视频生成」技术方案,将历史视频数据、剧本脚本、语音信息以及骨骼驱动等多模态信号作为输入,经过多模态视频分析与理解,分别生成具有高表现力的片段、复杂人 - 物 - 场交互片段以及大动作大表情片段,并在长时序上进行统一调度,从而保证语音、口型、表情与动作始终保持高度同步,实现真正的「音、容、话一致」。

在罗永浩数字人直播项目中,这一技术方案得到了集中体现。罗永浩与朱萧木均具强 IP 属性,二者的形象、语言风格、互动节奏都需得到高度还原。同时,整场直播中所涉及的商品种类繁多,体积、位置、用途各异,对人 - 物交互的精度和响应速度提出了更高要求。百度对人物 ID 与商品 ID 进行了独立建模与保持,使得系统能够在长时间内容中持续稳定地控制人物表现与商品指向,避免风格漂移与交互误差,最终实现主播间自然流畅的配合,语言节奏、动作执行和商品展示高度统一的效果。
结语
百度是中国最早押注 AI 底层能力的科技公司之一。
早在十四年前,移动互联网正值爆发期,「人工智能」仍是实验室里的晦涩概念,百度就把资源投向了一个看不见回报的领域,这一选择在当时显得颇为超前甚至「另类」。
时间给出了答案。ChatGPT 的横空出世掀起生成式 AI 浪潮,百度紧跟每一个关键节点,连续发布重磅大模型成果:从文心 3.0 到文心大模型 4.5,再到融入深度思考能力的 X1 以及升级版 4.5 Turbo,技术体系不断进化,模型的认知深度和生成能力日益增强。
此次罗永浩数字人带货直播,正是文心大模型的一次「最佳实践」。它不仅彰显了百度技术的成熟与前沿,更验证了大模型技术在真实商业场景中的高效与可行。
可以预见,随着深度思考、知识增强、意图理解与多角色交互等关键能力持续跃升,百度的数字人将愈发拟真与智能。这带来的不仅是效率提升,更意味着技术投入带来的商业模式的「无人区」探索和价值重构。
#Killing Two Birds with One Stone
打破推荐系统「信息孤岛」!中科大与华为提出首个生成式多阶段统一框架,性能全面超越 SOTA
论文作者来自认知智能全国重点实验室陈恩红团队,华为诺亚方舟实验室
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 "猜你喜欢",还是内容应用的信息流,背后都离不开推荐算法的默默耕耘。然而,传统的推荐系统普遍采用多阶段范式(如召回、排序),这种设计虽然在工程上实现了效率,却常常面临阶段间信息损失、性能瓶颈等问题。近年来,生成式人工智能的浪潮席卷全球,其强大的序列建模和内容生成能力为解决推荐系统的固有难题带来了新的曙光。如果能将推荐过程中的多个阶段融为一体,是否就能克服信息损失,实现更高效、更精准的推荐呢?
来自中国科学技术大学和华为诺亚方舟实验室的研究者们,在即将于 SIGIR 2025 会议上进行口头报告(Oral Presentation)的论文 Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model 中,给出了一份创新的答案。他们提出了一个名为 UniGRF 的统一生成式推荐框架,巧妙地实现了 "一石二鸟",用单个生成模型同时处理推荐系统中的召回和排序两大核心任务。
论文标题:Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model
论文链接:https://arxiv.org/abs/2504.16454
一、传统推荐范式的 "痛点" 与生成式 AI 的 "良方"
在工业界广泛应用的推荐系统中,通常首先通过召回阶段从海量物品库中快速筛选出一个较小的候选集,然后由排序阶段对这些候选物品进行精准打分和排序,最终呈现给用户。这种分而治之的多阶段级联模式保证了效率,但每个阶段独立训练和优化,上一阶段的丰富信息难以完整传递给下一阶段,信息茧房外的潜在兴趣点被过早过滤,造成了信息损失、偏差累积、阶段间难协作等固有问题。
受大语言模型(LLMs)在多任务处理上取得巨大成功的启发,UniGRF 创新性地将召回和排序整合到一个生成模型中,实现了信息的充分共享,同时保持了模型的通用性和可扩展性。
二、突破传统:如何用一个模型 "杀死两只鸟"?

UniGRF 的核心思想是将检索和排序两个阶段的任务都统一转化为序列生成任务,并整合到同一个自回归生成模型中。具体来说,模型通过学习用户历史交互序列(物品 ID 序列、行为类型序列等),在生成输出序列时,特定位置的输出分别对应召回任务(预测下一个交互物品)和排序任务(预测当前物品的点击概率)。
这种统一框架带来了诸多优势:
-
充分信息共享:由于参数在单一模型内共享,检索和排序任务可以充分利用彼此的信息,有效减少信息损失。
-
模型无关性与即插即用:UniGRF 是一个灵活的框架,可以与各种主流的自回归生成模型架构(如 HSTU、Llama 等)无缝集成。
-
潜在的效率提升:相比于维护两个独立的模型,单一模型在训练和推理上可能更具效率优势。
三、UniGRF 的两大 "秘密武器"
仅仅将两个任务放在一个模型里还不够,如何让它们高效协作并同步优化,是 UniGRF 成功的关键。为此,研究者设计了两大核心模块:
- 排序驱动的增强器 (Ranking-Driven Enhancer):
这个模块旨在促进召回和排序两个阶段之间的高效协作。一般来说,排序阶段通常能更精准地捕捉用户细粒度的偏好。该增强器巧妙地利用排序阶段的高精度输出来指导和优化召回阶段。
- 难样本挖掘:识别那些在召回阶段被高估但两个阶段存在分歧的样本,将它们作为更具挑战性的负样本反馈给模型,提升模型的辨别能力。
- 潜在正样本识别:识别那些在负采样中被错误标记,但排序模型认为用户可能喜欢的样本,纠正其标签,为模型提供更准确的训练信号。
通过这种方式,形成了一个互相促进的增强闭环,并且这一切几乎不增加额外的计算开销。
- 梯度引导的自适应加权器 (Gradient-Guided Adaptive Weighter):
在统一框架下,召回和排序两个任务的损失函数、收敛速度可能存在显著差异。如果简单地将两者损失相加,可能会导致模型在优化过程中厚此薄彼。该加权器通过实时监测两个任务梯度的变化率(即学习速度),动态地调整它们在总损失函数中的权重。如果一个任务学习较慢,就适当增加其权重,反之亦然。这确保了两个任务能够以协同的步伐前进,实现同步优化,最终达到整体性能的最优。
四、实验效果:显著超越 SOTA,验证统一框架威力


为了验证 UniGRF 的有效性,研究团队在三个公开的大型推荐数据集(MovieLens-1M, MovieLens-20M, Amazon-Books)上进行了大量实验。结果表明:
- 全面领先:无论是以 HSTU 还是 Llama 作为基础生成模型,UniGRF 在召回和排序两个任务上的性能均显著优于现有的 SOTA 基线模型,包括那些为单一任务设计的强大生成模型以及传统的级联框架。
- 排序性能提升尤为显著:实验发现,UniGRF 对排序阶段的性能提升更为明显。这对于实际应用更为重要,因为排序结果直接决定了最终呈现给用户的推荐质量。
- 良好的可扩展性:实验还初步验证了 UniGRF 在模型参数扩展时的性能提升潜力,符合 "越大越好" 的缩放定律(Scaling Law)。
值得一提的是,传统的级联框架在适配生成式模型时表现不佳,甚至可能产生负面效果,这反过来凸显了 UniGRF 这种原生统一框架的优越性。
五、总结与展望
UniGRF 的提出,为生成式推荐系统领域贡献了一个新颖且高效的解决方案。它首次探索了在单一生成模型内统一召回与排序任务的可行性与巨大潜力,通过精心设计的协作与优化机制,有效克服了传统多阶段范式的信息损失问题。
这项工作不仅为学术界提供了新的研究视角,也为工业界构建更强大、更高效的推荐系统提供了有益的借鉴。未来,研究者们计划将该框架扩展到更多的推荐阶段(如预排序、重排),并在真实的工业场景中验证其大规模应用的可行性。
#盘古大模型 5.5
刚刚,华为盘古大模型5.5问世!推理、智能体能力大爆发
在国产大模型领域,华为盘古大模型一直是比较独特的存在。
该系列模型强调「不作诗,只做事」,深耕行业,赋能千行百业,推动产业智能化升级。从盘古 1.0 到盘古 5.0,华为专注于用大模型解决实际产业问题,并获得了市场的广泛认可。
就在刚刚,在华为开发者大会 2025(HDC 2025)上,华为重磅发布了盘古大模型 5.5,其中自然语言处理(NLP)能力比肩国际一流模型,并在多模态世界模型方面做到全国首创。
此次,全新升级的盘古大模型 5.5 包含了五大基础模型,分别面向 NLP、多模态、预测、科学计算、CV 领域,进一步推动大模型成为行业数智化转型的核心动力。

华为常务董事、华为云 CEO 张平安正式发布盘古大模型 5.5
会上,华为诺亚方舟实验室主任王云鹤对该系列模型的核心技术进行了大揭秘。

王云鹤
此次,盘古 5.5 在 NLP 领域主要有三大模型组成,即盘古 Ultra MoE、盘古 Pro MoE、盘古 Embedding;以及快慢思考合一的高效推理策略、盘古深度研究产品 DeepDiver。
我们接下来一一来看。
盘古 Ultra MoE
准万亿级别模型
盘古 Ultra MoE 是 7180 亿参数的 MoE 深度思考模型。作为一个准万亿参数级别的大模型,该模型基于昇腾全栈软硬件协同打造,做到了国内领先、比肩世界一流水平。

训练超大规模和极高稀疏性的 MoE 模型极具挑战,训练过程中的稳定性往往难以保障。针对这一难题,华为盘古团队在模型架构和训练方法上进行了创新性设计,成功地在基于昇腾 NPU 打造的「下一代 AI 数据中心架构」CloudMatrix384 集群上实现了准万亿 MoE 模型的全流程训练。
具体来讲,盘古团队提出了 Depth-Scaled Sandwich-Norm(DSSN)稳定架构和 TinyInit 小初始化的方法,在昇腾 NPU 上实现了 10+T token 数据的长期稳定训练。此外,华为还提出了 EP group loss 负载优化方法,这一设计不仅保证各个专家之间能保持较好的负载均衡,也提升专家的领域特化能力。同时,Pangu Ultra MoE 使用了业界先进的 MLA 和 MTP 架构,在训练时使用了 Dropless 训练策略。
得益于此,该模型具备了高效长序列、高效思考、DeepDiver、低幻觉等核心能力,并在知识推理、自然科学、数学等领域的大模型榜单上位列前沿。
更多技术细节可访问盘古 Ultra MoE 的技术报告或我们之前的报道《还得是华为!Pangu Ultra MoE 架构:不用 GPU,你也可以这样训练准万亿 MoE 大模型》:

报告地址:https://arxiv.org/pdf/2505.04519
盘古 Pro MoE 大模型
比肩 DeepSeek-R1
盘古 Pro MoE 是一个 72B A16B 的模型,即每次工作时会激活其中 160 亿参数。

王云鹤透露,该模型也代表盘古系列模型首次参与了外部打榜。在刚刚发布的五月底 SuperCLUE 榜单上,盘古 Pro MoE 在千亿参数量以内的模型中,排行并列国内第一。

https://www.superclueai.com
可以看到,其在智能体任务上打榜成绩甚至比肩 6710 亿参数的 DeepSeek-R1,在文本理解和创作领域也达到开源模型的第一名。
据介绍,该模型是针对昇腾硬件特性进行了大量仿真建模之后得到的最优架构,尤其适配 300I Duo 推理芯片的宽度、深度、专家数等。
此外,华为还针对不同芯片上专家负载不均衡的问题,提出了分组混合专家 MoGE 算法。该算法可实现跨芯片计算的负载均衡,从而显著提升盘古训推系统的吞吐效率。

MoGE 架构设计示意图。N 个专家被均匀划分为 M 个不重叠的组并且每一个组内激活相同数量的专家。
最终,这些创新让盘古 Pro MoE 可在 300I Duo 上实现每秒 321 token 的吞吐量,而在性能更强大的 800I A2 上,吞吐速度更是可达每秒 1529 token,领先同规模业界模型 15% 以上。
华为已经在 5 月底发布了盘古 Pro MoE 的技术报告,感兴趣的读者可通过以下链接扩展阅读。另外,我们之前也已经报道过该模型:《华为盘古首次露出,昇腾原生 72B MoE 架构,SuperCLUE 千亿内模型并列国内第一》。

项目地址:https://gitcode.com/ascend-tribe/pangu-pro-moe
盘古 Embedding(7B)
小身手、大能量
华为也推出了一个相当能打的 7B 级小模型盘古 Embedding。该模型在学科知识、编码、数学和对话能力方面均优于同期同规模模型。

华为是如何做到这一点的呢?王云鹤介绍了一些重点:
在后训练阶段使用渐进式 SFT 和多维度奖励的强化学习,这提高了模型的推理能力。
针对长序列进行了重点优化,为此华为提出了 Adaptive SWA 和 ESA 两项关键技术来降低在长序列的场景中的计算量和 KV Cache;也由此,盘古 Embedding 可以相当轻松地应对 100 万 token 长度的上下文。
针对幻觉问题,华为提出了知识边界判定、结构化思考验证等创新方案,从而实现了模型推理准确度的提升。
同样地,该模型的技术报告也已经在 5 月底发布。
报告地址:https://arxiv.org/pdf/2505.22375
高效推理方案
自适应快慢思考合一
如今,以 DeepSeek-R1 为代表的思考模型受到了业界的广泛关注。思考模型又可以分为慢思考模型与快思考模型,其中慢思考模型普遍存在的过度思考问题受到了业界的广泛关注。
对于简单的问题(比如 1+1 等于几),快思考模型平均只需要十几个 token 就能解决,而慢思考却需要几百甚至上千个 token。这就导致用户体验不佳,对于行业应用部署也有不利影响。目前业界已有的一些方案通过 prompt 隔离进行切换,但这样做并不能真正地自动感知问题的难易程度。
为解决该问题,华为提出了自适应快慢思考合一技术,构建难度感知的快慢思考数据并提出两阶段渐进训练策略,让盘古模型可以根据问题难易程度自适应地切换快慢思考。这就达成了这样一种效果:简单问题快速回复,复杂问题深度思考,整体推理效率可以提升高达 8 倍。

不仅如此,华为还针对慢思考模式提出了反思投机和反思压缩等策略,在精度无损的情况下减少 50% 的慢思考时间,让盘古大模型不仅推理得准,速度还快。
盘古 DeepDiver
华为的 Deep Research 来了
进入到 2025 年,大模型的基础能力不再是厂商关注的唯一,模型应用同样受到高度重视。
其中,以深度研究(Deep Research)为代表的新一代 Agent 在科学助手、个性化教育以及复杂的行业报告调研等场景展现出了比传统大模型更强的能力。
不过,这类 Agent 在实际应用中面临着很多技术挑战,比如规划步数多、策略空间大、序列超长、信息噪声大等,这些不可避免地影响到执行效率和准确率。
针对这一挑战,华为发布了开放域信息获取 Agent------ 盘古 DeepDiver,在网页搜索、常识性问答等应用中,它可以让盘古 7B 大模型实现接近 DeepSeek-R1 这种超大模型的效果。

如何做到的呢?据王云鹤介绍,首先根据实际场景构建大量的合成交互数据,并通过渐进式奖励策略等优化方法,在开放环境进行强化学习训练。
效果不俗之外,执行效率也非常高,盘古 DeepDiver 可以在 5 分钟内完成超过 10 跳的复杂问答,并生成万字以上的专业调研报告。
得益于 DeepDiver,盘古大模型的自主规划、探索、反思等高阶能力得到了前所未有地加强。
更多技术细节请访问相应技术报告或我们之前的报道《真实联网搜索 Agent,7B 媲美满血 R1,华为盘古 DeepDiver 给出开域信息获取新解法》。
报告地址:https://arxiv.org/pdf/2505.24332
除了以上几大 NLP 大模型之外,盘古 5.5 还覆盖了以下几个领域的大模型:
- 盘古预测大模型:采用业界首创的 triplet transformer 统一预训练架构,将不同行业的数据进行统一的三元组编码,并在同一框架内高效处理和预训练,极大地提升预测大模型的精度,并大幅提升跨行业、跨场景的泛化性。
- 盘古科学计算大模型:华为云持续拓展盘古科学计算大模型与更多科学应用领域的结合。比如深圳气象局基于盘古进一步升级「智霁」大模型,首次实现 AI 集合预报,能更直观地反映天气系统的演变可能性,减少单一预报模型的误差。
- 盘古计算机视觉 CV 大模型:华为云发布全新 MoE 架构的 300 亿参数视觉大模型,这是目前业界最大的视觉模型,并全面支持图像、红外、激光点云、光谱、雷达等多维度、泛视觉的感知、分析与决策。另外盘古 CV 大模型通过跨维度生成模型,构建油气、交通、煤矿等工业场景稀缺的泛视觉故障样本库,极大地提升了业务场景的可识别种类与精度。
- 盘古多模态大模型:全新发布基于盘古多模态大模型的世界模型,可以为智能驾驶、xx智能机器人的训练,构建所需要的数字物理空间,实现持续优化迭代。例如,在智能驾驶领域,输入首帧的行车场景、行车控制信息和路网数据,盘古世界模型就可以生成每路摄像头的行车视频和激光雷达的点云,能够为智能驾驶生成大量的训练数据,而无需依赖高成本的路采。
至此,盘古大模型 5.5 通过多样化的架构与算法创新(如 MoE、深度思考、Triplet Transformer、自适应快慢思考),不仅在核心技术能力上达到领先水平,更在科学计算、工业预测、气象预报、能源优化、智能驾驶等关键应用领域展现出强大的落地价值和变革潜力。
#OWMM-Agent
突破开放世界移动操作!首个室内移动抓取多模态智能体亮相,微调模型真实环境零样本动作准确率达 90%
在家庭服务机器人领域,如何让机器人理解开放环境中的自然语言指令、动态规划行动路径并精准执行操作,一直是学界和工业界的核心挑战。
近日,上海人工智能实验室联合新加坡国立大学、香港大学等机构的研究团队,提出了 "OWMM-Agent" xx智能体------首个专为开放世界移动操作(OWMM)设计的多模态智能体 (VLM Agent) 架构,首次实现了全局场景理解、机器人状态跟踪和多模态动作生成的统一建模。
同时该工作通过仿真器合成智能体轨迹数据,微调了针对该任务的多模态大模型 OWMM-VLM,在真实环境测试下,该模型零样本单步动作预测准确率达 90%。

论文链接:https://arxiv.org/pdf/2506.04217
Github 主页:https://github.com/HHYHRHY/OWMM-Agent
,时长01:01
一、问题背景介绍:开放语义下的移动抓取任务
传统移动抓取机器人在家庭场景处理 "清理餐桌并将水果放回碗中" 这类开放指令时,往往需要依赖预先构建的场景 3D 重建或者语义地图,不仅耗时且难以应对动态环境。OWMM 任务的核心难点在于:
- 全局场景推理:需要结合自然语言指令和多视角视觉信息,理解整个场景的布局和物体信息。
- xx决策闭环:实时跟踪机器人状态(如当前位置、长续任务执行状态),生成符合物理约束的动作(如理解要到一定距离才可以抓取物体);
- 系统整合问题:VLM 基座模型难以直接输出机器人控制所需的底层目标(如导航目标点坐标、抓取物体坐标等)。
二、OWMM-Agent:用 VLM 重构机器人 "大脑"
研究团队提出的 OWMM-Agent 架构,通过两大创新突破上述瓶颈:
- 多模态 Agent 架构
通过将开放世界移动操作(OWMM)问题建模成多轮,多图推理和定位 (Grounding) 问题,让多模态大模型进行端到端的感知 - 推理 - 决策 - 状态更新过程。
- 长期环境记忆:利用预映射阶段获取的多视角场景图像(如图 1 中的历史帧),构建全局场景理解能力,支持复杂指令的空间推理(如 "从吧台凳取物并放到沙发");
- 瞬态状态记忆:以文本形式跟踪机器人实时状态(如 "已抓取物体,正接近目标位置"),辅助 VLM 生成上下文相关的动作序列;
- 动作空间设计:VLM 模型直接输出动作 handle 和 Ego-centric Obsersavation RGB 空间的坐标参数,通过函数调用传统路径规划器(Path Planner)和机械臂运动规划器(Motion Planner),不依赖预定义策略技能库。

图 1:OWMM-Agent 框架和动作接口设计
- 多模态 Agent 微调数据合成
针对 VLM 基座模型在机器人领域的 "幻觉" 问题,团队设计了基于 Habitat 仿真平台的数据合成方案:
- 任务模板驱动:基于 Habitat 仿真环境,通过 PDDL 语言定义任务流程,自动生成 OWMM episodes。最终数据集基于 143 个仿真场景,157 种可抓取物体和 1471 个容器,采集了 20 万 + 条的多图加文本数据集;
- 符号世界建模:利用仿真环境的真值数据(如物体坐标,机器人状态,PDDL 世界状态),标注多图像 - 文本 - 动作对,避免人工标注成本;
- 多模态增强:通过 GPT-4o 重写思维链和文字总结内容、引入机器人第一视角图像,增强数据多样性和语义接地能力。
团队利用仿真合成的多模态数据,基于 Intern-VL 2.5 8B/38B 微调得到用于 OWMM 的专用模型 OWMM-VLM。

图 2: OWMM-VLM 模型
三、实验验证:模拟与真实环境双突破
在模拟环境中,OWMM-VLM 模型展现出显著优势:
- 单步能力:在 "Ego-centric 动作决策""图像检索""动作定位 (Action Grounding)" 三项核心任务上,380 亿参数的 OWMM-VLM-38B 模型准确率分别达 97.85%、87.54% 和 88%,远超 GPT-4o(48.53%、46.46%、7%)和模块化方案(如 GPT-4o+RoboPoint);
- 完整序列任务:在 308 次模拟测试中,OWMM-VLM-38B 在整个 OWMM 长序移动抓取任务成功率达 21.9%,且零死循环;而基线模型由于大量幻觉和误差累积,成功率低于 1%,且频繁陷入死循环。

图 3:Habitat 仿真环境单步动作和完整 OWMM 序列测试结果
更值得关注的是真实环境测试:在 Fetch 机器人上,模型仅通过模拟数据训练,即实现了 90% 的零样本动作生成成功率(30 次测试中 27 次成功)。例如,在 "将豆奶盒从书桌移至会议桌" 任务中,模型准确检索目标位置、规划导航路径,并生成机械臂抓取坐标,展现出强泛化能力。在真机部署实验中,团队采用了 Robi Butler 工作提供的人类通过 VR 设备控制室内机器人系统的多模态接口,并迁移到 OWMM-Agent 框架中。
四、未来展望:迈向通用家庭机器人
该研究首次证明,通过大规模模拟数据微调的 VLM 模型,可成为开放世界移动操作的通用基础模型。同时这篇工作也存在局限性,当前方法假设有一个相对理想的环境重建,并假设目标任务相关的观测已经在记忆中,且对复杂机械臂(如多指手)的控制能力有限。
随着老龄化社会对服务机器人需求的激增,OWMM-Agent 的突破为 "会听、会看、会做" 的通用家庭助手奠定了关键技术基础。或许在不久的将来,我们真能迎来 "一句话指挥机器人完成家务" 的智能生活。
#大模型实践 卡比人贵时代的深度学习经验
"不要被表象所迷惑,要洞察事物的本质。" ------ 亚里士多德
几年前我写过 新手炼丹经验总结,当时背景是卡多,任务小,每天要保证一定的实验吞吐量
这两年虽然大家手上的卡更多了,但是实验从原来几张卡几小时就能跑个效果,变成现在几百张卡几天看一次
于是做实验就需要一些新的方法论
之前的方法论我总结的是:站在巨人肩膀上,注意可复现性、高效实验、防呆实验
在此基础上补充讨论一些:a. 找关键指标 b. 找真瓶颈 c. 大实验和小实验的关系 d. 团队协作
我入行七年多了,现在日常训 10B-100B 大小的语言模型,也有一些小的扩散模型、多模态模型,更大的模型只是参与一些讨论
评测的重要性
论文说自己的方法性能好,一般就是定量部分,要突出关键指标的提升;定性部分,着重强调新的现象和观察
在实验过程中,关键指标往往不是那些你很轻易就接近 SoTA 的指标,而是那些能很明显地区分出 SoTA 和其它方法的指标
如果指标找不好,很可能就整天造超越 GPT4 的新闻,但是永远在追赶 OpenAI
好的指标要能客观反映水平,还要更准确地指示模型迭代的方向
而且更值得警惕的是,当着眼于提高某个指标的时候,可能会让它失效,失去了真正的指示能力
定性实验,呈现结果不是噱头和骗人,可以参考我之前写的 深度学习工作:从追求 SoTA 到揭示新现象
最近传闻训练 GPT5 大小的模型遇到困难,而长链思维 o1 / R1 大火,这都是新的现象和观察,通过实验破除先入为主的迷信,细心观察模型不一样的性质并且利用它,是导致本质提升的基础
另一方面来说,既然一个实验要跑好多天,为了提高成功率当然要多投时间在评测上
这里还有很多自动化工具能加成的工作,我们内部发一个模型,会把几十个榜都自动测了,作者也许看也许不看,我真有很多发现是偶然看别人实验的评测结果后得到的
做性价比高的实验
因为实验代价提高了几个数量级,做有意义的实验显得更重要
如果一天只能做一个实验,切忌起一些性价比不高的实验,同时疏于观察,这都是麻醉自己的方式
宁愿把卡空着,也不要无脑用垃圾实验填充
比如大部分的超参数,如果只是轻微调整一点,很难导致实验性质的根本改变
也有很多做大模型有监督微调的工作,沉迷于研究数据简单配比
过微扰超参数、模型结构,人肉梯度下降,不是大模型的实验方法
胡乱调,性能当然也会有抖动,但我们不是靠盯着抖动来做科研的
可以通过文献阅读,同行讨论,排除那些实验性价比不高的调参;经验、理论足以让我们对大部分超参数选一个不出错的值了,我们要通过实验证实或证伪一些更强假设,而非去网格搜索最优参数
平衡大小实验
因为客观条件限制,很多时候我们只能做小实验,但是只有真的碰大实验,才能知道什么问题是值得做的
我建议:在大实验上找问题,用小实验筛掉错误想法,找有希望的上大实验验证
可能很多小模型的问题换大的模型自然就不存在,也许就没有做小模型的必要;有的任务就是少参数调整学不会,全参数调整就直接能解决,那么这些问题研究的意义就比较小
在做实验的时候,也要清楚我们是在做一个大实验还是小实验?不要既要也要,实验快必定失掉性能上限,大实验必定反馈不够快
团队协作
现在的大模型实验已经复杂到,几个人都很难打通全流程。因此开展工作时,需要搞清楚自己的比较优势,找自己在团队中的定位,也要了解团队在整个社区中的站位
比如说我没空做细致研究,但是我有卡,可能我就是通过读论文找 idea,然后进行超越学术界规模的实验进行验证
如果我卡不够多,我可以先做一些 idea 的简单验证,然后主动找卡多的人合作
在一个团队里,甚至可以尝试说服别人把卡让给自己实验,让别人去做更适合做的事情,或者主动把自己不擅长的事情分给别人
为了更好地团队协作,还可以努力找一些一起观察、记录实验的方式,提高交流频率等等
#世界模型版《模拟人生》
AI虚拟小人街头演讲拉票,GPT-4o选举获胜
个真实世界模拟器。
当世界模型高度进化后,里面的「人」都在做些什么?
有人会进行街头演说,吸引到了不少听众,小孩会和机器狗玩:

有人会当街作案,警察前去抓捕,又有人会在大庭广众之下求婚:

本周五,来自马萨诸塞大学阿默斯特分校(UMass Amherst)、约翰霍普金斯大学、卡耐基梅隆大学的研究者们提出了一个神奇的研究:虚拟社区(Virtual Community)。
虚拟社区将真实世界的地理空间数据与生成模型相结合,为多种不同类型的智能体创建了一个具有社会根基的交互式、可扩展开放世界场景。
论文:Virtual Community: An Open World for Humans, Robots, and Society
论文链接:https://virtual-community-ai.github.io/paper.pdf
项目链接:https://virtual-community-ai.github.io/
该工作昨晚提交,立即吸引了一些 AI 圈大佬的关注,纽约大学助理教授谢赛宁表示,这对于智能体研究来说意义重大。

虚拟社区提供了一个统一的框架,用于模拟社区中人类和机器人丰富的社交和物理互动。它建立在通用物理引擎之上,并以现实世界的 3D 场景作为基础。作者为人类智能体实现了一个虚拟角色模拟框架,而其中的机器人模拟则主要继承自 Genesis。
虚拟社区通过在环境中填充配置机器人、人类角色配置文件和社会关系网络的智能体(由 LLM 提供支持)来支持基于 3D 场景的智能体社区生成。
这一个个人物,都是有详细背景资料和活动时间表的,他们也会按照这些设定行事。他们的社会关系以群组的形式构建,每个群组包含一组智能体、文本描述和指定的群组活动场所,所以这些人物会被连接成一个有凝聚力的社群。

虚拟社区会基于真实世界地理空间数据生成场景及相应的智能体。如下图所示:场景生成组件(A)使用生成模型来增强纹理,并精炼粗糙的 3D 数据,同时精炼地理空间数据以简化几何结构。它还利用生成方法创建交互式对象和精细的室内场景。智能体生成组件(B)利用 LLM 基于场景描述生成智能体角色和社交关系网络。(C)再基于 Genesis 引擎模拟开放世界场景中的虚拟角色社区和机器人。

令人感兴趣的是,它可以模拟世界任何地方的 3D 场景,为智能体构建出一个大规模社区 ------ 从纽约到伦敦、阿姆斯特丹、丹佛等等。


现有的 3D 地理空间数据 API 在数量和多样性方面提供了丰富的数据,但它们通常包含大量噪声,并缺乏纹理和几何形状细节。为了弥补这一差距,作者提出了一种在线流程,对几何和纹理进行全面的清理和增强。该流程包含四个步骤:网格简化、纹理细化、对象放置和自动注释。
作者使用此流程生成了 35 个全球不同城市的带注释场景:

虚拟社区其中还具有正常运行的交通系统,包括行人移动、车辆流动和公共交通运营。作者开发了基于 OSM 数据的自动化动态交通生成机制,能够快速重建城市道路网络并在全球范围内实现自主交通模拟。

作为一个帮助未来人与机器协作进行训练的平台,机器人将成为虚拟社区不可或缺的一部分,它们无处不在并会其中的「人类」进行无缝互动。目前看到已经导入的机器人就有宇树的人形机器人、波士顿动力的机器狗,还有四轴无人机、谷歌机器人等。

利用虚拟社区所释放的新功能,作者引入了两项新的xx化多智能体任务:一项涉及多名人类智能体的竞选任务,以及一项同时涉及机器人和人类智能体的社区助理任务。为了成功完成这些任务,智能体需要具备在社区环境中进行规划的能力,以及与其他智能体互动的社交智能。
作为这两项任务的基础,如果没有分配到特定任务,社区中的智能体会遵循默认的日常计划和惯例。在每轮游戏中,都会选择多个智能体并为其分配一项任务。当智能体被赋予任务时,它会暂停日常计划,专注于完成社区中分配的社交任务。
在「竞选」任务中,候选人智能体必须高效地规划与社区内的选民智能体建立联系并进行说服。由于选民的性格和社会关系各不相同,一些选民最初可能倾向于某些候选人,这就要求每位候选人制定适应性策略,以在整个选举过程中影响和改变选民的意见。
结果如下图所示,采用 GPT-4o 主干的候选人比采用 GPT-3.5-turbo 主干的候选人拥有更高的平均得票率和转化率,这意味着它更有能力在大多数场景下改变选民的观点。

社区助手任务的场景则是两个异构机器人在开放世界环境中合作协助人类。这些任务要求智能体进行合作规划,以协助人类化身进行日常活动 ------ 搬运,即智能体陪同人们外出并帮助搬运物品;以及递送,即智能体将物品从源位置(室内或室外)运送到目的地。
实验结果显示,两种基线方法在交付方面的表现均优于携带,这反映了在动态开放世界中同时操控物体和跟随人类的极高难度。
作者希望虚拟社区工作能够帮助人们大规模进行未来的社会智能研究,包括:1)机器人如何智能地合作或竞争;2)人类如何发展社会关系和建立社区;3)智能机器人和人类如何在开放世界中共存。
以下为该研究的团队成员:
#苹果内部讨论买Perplexity
外媒:140亿美元史上最大收购?
第一个 AI 搜索引擎,要归苹果了?
据彭博社本周五报道,苹果公司高管已就可能竞购知名 AI 初创公司 Perplexity 举行了内部会谈。

报道称,相关讨论尚处于早期阶段,最终可能不会促成收购要约,并补充说,这家科技巨头的高管尚未与 Perplexity 的管理层讨论出价。
作为 AI 搜索领域的「新贵」, Perplexity 的团队和技术对苹果具有极大的吸引力, Perplexity 的创始人团队成员拥有在 OpenAI 、谷歌、 DeepMind 、微软等顶尖 AI 实验室和公司的工作背景,对 AI 技术有深刻的理解。
Perplexity 的核心优势不在于训练自己的基础大模型,而在于其卓越的检索、排序和整合信息的能力。它能综合运用多种第三方大模型和搜索引擎数据,并通过自身独特的算法提供精准、可追溯来源、无广告的答案。这种技术正是苹果改进 Siri 和开发新一代搜索引擎所需要的。
最近一段时间,大型科技公司正在 AI 领域不断加大投资,以跟上越来越快的 AI 技术进步节奏。据报道,在对数据标注公司 Scale AI 进行重大投资之前,Meta 曾与 Perplexity AI 在今年初就潜在的收购案进行过商谈。这些讨论是 Meta CEO 马克·扎克伯格为追赶 AI 领先地位而采取的积极策略的一部分。然而双方最终未能达成协议,谈判因此终止,有报道称是 Perplexity 方面选择退出谈判。
除了整体收购,Meta 还曾试图招募 Perplexity 的首席执行官 Aravind Srinivas,希望他能加入公司专注于构建更强 AI 系统的新「超级智能」团队。
在与 Perplexity 的商谈终止后,Meta 迅速敲定了对数据标注初创公司 Scale AI 的一笔高达 143 亿美元的战略投资。通过这笔交易,Meta 不仅获得了 Scale AI 公司 49% 的非投票权股份,还成功将 Scale AI 的创始人兼首席执行官 Alexandr Wang 及其部分团队成员招致麾下,由他来领导 Meta 新组建的「超级智能」部门。
苹果公司计划将像 Perplexity AI 这样的人工智能驱动的搜索功能整合到其 Safari 浏览器中,这可能使其摆脱与谷歌的长期合作关系。目前,美国司法部在针对谷歌的反垄断案中,已提议禁止谷歌付费给其他公司以成为默认搜索引擎,这威胁到了苹果与谷歌每年价值约 200 亿美元的合作协议。
尽管对于普通用户来说,传统搜索引擎仍是首选,但 Perplexity 和 ChatGPT 等 AI 搜索选项正迅速崛起,尤其受到年轻一代用户的欢迎。如今,人们越来越多地使用基于大语言模型(LLM)的 AI 助手来获取信息,导致传统搜索引擎的使用量出现下降。收购或与 Perplexity 实现大规模合作,可以帮助苹果将其 AI 搜索功能整合进 Safari 浏览器和 Siri,从而摆脱对谷歌的依赖,并顺应新的用户趋势。
看起来在 Apple Intelligence 的多项技术屡遭延迟后,苹果已在寻求新的 AI 解决方案了。

Perplexity 在最近一轮融资中的估值达到了 140 亿美元,如果苹果以接近该价值的价格进行收购,这将是苹果公司历史上最大规模的收购案,远超 2014 年以 30 亿美元收购 Beats 的交易。
不过在可能的收购消息爆出后,Perplexity 发表声明称「我们目前或未来不了解任何涉及 Perplexity 的并购谈判」。
Perplexity 首席商务官 Dmitry Shevelenko 表示收购「不太可能」,他也驳斥了 Perplexity 和苹果之间实现 Meta 和 Scale 类型的合作。
参考内容:
#Multi-agent Architecture Search via Agentic Supernet
NAS老树开新花,NUS提出智能体超网,成本狂降55%
本文第一作者为张桂彬,新加坡国立大学25Fall计算机科学博士生;本文在南洋理工大学的王琨博士、上海人工智能实验室的白磊老师、和中国科学技术大学的王翔教授指导下完成。
LLM 智能体的时代,单个 Agent 的能力已到瓶颈,组建像 "智能体天团" 一样的多智能体系统已经见证了广泛的成功。但 "天团" 不是人越多越好,手动设计既费力又不讨好,现有的智能体自动化方法又只会 "一招鲜",拿一套复杂阵容应对所有问题,导致 "杀鸡用牛刀",成本高昂。
现在,一篇来自新加坡国立大学、上海 AI Lab、同济大学等机构并被 ICML 2025 接收为 Oral Presentation 的论文,为我们带来了全新的解题思路。
他们将神经网络架构搜索(NAS)的超网络(Supernet)思想引入 Agent 领域,首创了一个名为 "智能体超网"(Agentic Supernet)的概念。它不再寻找一个固定的最佳 "阵容",而是根据任务难度,动态 "剪" 出一个量身定制的智能体团队。结果有多惊艳?性能超越现有方法最高 11.82%,推理成本却只有它们的 45%!
论文地址:https://arxiv.org/abs/2502.04180
Github 链接:https://github.com/bingreeky/MaAS
论文标题:Multi-agent Architecture Search via Agentic Supernet
智能体的 "一体化" 困境:
从设计内卷到资源浪费
如今,从 AutoGen 到 MetaGPT,各种多智能体系统(Multi-agent Systems)层出不穷,通过定制化的协作,其能力在多个领域(如代码生成,复杂通用 AI 任务)已超越了单个智能体。但一个核心痛点始终存在:这些系统的设计往往依赖于繁琐的人工配置和 Prompt 工程。 为了解决这个问题,研究界转向自动化设计,比如通过强化学习、进化算法、蒙特卡洛树搜索等方式寻找最优的 Agent 工作流。
然而,这又带来了新的困境:
-
资源浪费 (Dilemma 1):诸如 AFlow 和 ADAS 这样的自动化多智能体系统优化方法倾向于找到一个极其复杂的 "万金油" 式系统,以确保在所有任务上表现优异。 但面对 "10+1*2.5=?" 这样的简单问题,动用一个需要数十次 LLM 调用的复杂系统,无疑是巨大的资源浪费。
-
任务冲突 (Dilemma 2):在 GAIA 这样的多领域基准测试中,一个擅长文献总结的多智能体系统,不一定擅长网页浏览总结 ------ 似乎不存在一个能在所有任务上都最优的 "全能冠军"。
面对这种 "要么手动内卷,要么自动浪费" 的局面,我们是否该换个思路了?
Agentic Supernet:
从 "选一个" 到 "按需生万物"
这篇论文的核心贡献,就是一次漂亮的 "范式转移" (Paradigm Reformulation)。作者提出,我们不应该再执着于寻找一个单一、静态的最优智能体架构。相反,我们应该去优化一个 "智能体超网"(Agentic Supernet) ------ 这是一个包含海量潜在智能体架构的概率分布。

图 1 智能体超网络
这个 "超网" 就像一个巨大的 "能力兵工厂",里面包含了诸如思维链(CoT)、工具调用(ReAct)、多智能体辩论(Debate)等各式各样的基础能力 "算子"(Agentic Operator)。当一个新任务(Query)到来时,一个 "智能控制器"(Controller)会快速分析任务的难度和类型,然后从这个 "兵工厂" 中,动态地、即时地挑选并组合最合适的几个 "算子",形成一个量身定制的、不多不少、资源分配额刚刚好的临时智能体系统去解决问题。
上图生动地展示了这一点:
- 对于简单问题 (a, b):MaAS 在第二层就选择了 "提前退出"(Early-exit),用最简单的 I/O 或 ReAct 组合快速给出答案,极大节省了资源。
- 对于中等和困难问题 (c, d):MaAS 则会构建更深、更复杂的网络,调用更多的算子来确保问题得到解决。
这种 "按需分配、动态组合" 的哲学,正是大名鼎鼎的 NAS 的核心思想。如今,MaAS 框架将其成功地应用在了多智能体架构搜索(Multi-agent Architecture Search)上,可以说是 NAS 在 Agentic 时代的重生和胜利。
MaAS 的 "三板斧" 如何玩转智能体架构?
接下来,我们就一起拆解 MaAS 的 "独门秘籍"。其核心思想,可以概括为定义蓝图 → 智能调度 → 自我进化三步走战略。
第一板斧:定义万能 "蓝图" - Agentic Supernet
传统方法是设计一个具体的 Agent 架构 (System),而 MaAS 的第一步,就是定义一个包含所有可能性的 "宇宙"------ 智能体超网 (Agentic Supernet)。
- 智能体算子 (Agentic Operator):首先,MaAS 将智能体系统拆解为一系列可复用的 "原子能力" 或 "技能模块",也就是智能体算子 (O)。这包括了:
- I/O: 最简单的输入输出。
- CoT (Chain-of-Thought): 引导模型进行循序渐进的思考。
- ReAct: 结合思考与工具调用。
- Debate: 多个 Agent 进行辩论,优胜劣汰。
- Self-Refine: 自我批判与修正。
- ... 等等,这个 "技能库" 是完全可以自定义扩展的!
- 概率化智能体超网 (Probabilistic Agentic Supernet):有了这些智能体算子,MaAS 将它们组织成一个多层的、概率化的结构。你可以想象成一个分了好几层的巨大 "技能池"。
- 每一层都包含了所有可选的智能体算子。
- 每个模块在每一层被 "选中" 的概率(π)是不固定的,是可以学习和优化的。

图 2 MaAS 自进化框架示意图
如图 2 所示的智能体超网,就是 MaAS 施展魔法的舞台。它不是一个静态的系统,而是一个智能体系统架构的概率分布空间。
第二板斧:智能 "调度师" - 按需采样架构
有了 "蓝图",当一个具体的任务(Query q)来了,如何快速生成一个 "定制团队" 呢?这就轮到 MaAS 的 "智能调度师"------ 控制器网络 (Controller) 上场了。控制器的工作流程如下所示:
-
"阅读" 任务:控制器首先将输入的 Query q 进行编码,理解其意图和难度。
-
逐层挑选:然后,它从超网的第一层开始,逐层为当前任务挑选最合适的 "技能模块"。
-
MoE 式动态选择:这里的挑选机制非常精妙,它采用了一种类似混合专家(MoE)的策略。
在每一层,控制器会为所有待选的技能模块计算一个 "激活分数"。这个分数取决于当前任务 q 以及之前层已经选定了哪些模块。
然后,它会从分数最高的模块开始,依次激活,直到这些被激活模块的累计分数总和超过一个预设的阈值 (thres)。
这个设计恰恰与 MaAS 的动态性紧密相关!这意味着:
- 简单任务可能在某一层只激活一个智能体算子就够了。
- 复杂任务则会激活更多的算子,可能是两个、甚至三个,以保证足够的解决能力。
- 同时,如果 "早停 (Early-Exit)" 这个特殊的算子被选中,整个采样过程就会提前结束,完美实现了 "见好就收"。
通过这种方式,MaAS 为每一个 Query 都动态生成了一个独一无二的、资源配比恰到好处的 Agent 执行图(G),实现了真正的 "查询感知(Query-aware)"。
第三板斧:双轨 "进化引擎" - 成本约束下的优化
生成了临时团队去执行任务还不够,MaAS 还要能从经验中学习,让整个 "超网" 和 "算子" 都变得越来越强。但这里有个难题:整个 Agent 执行过程是 "黑盒" 的,充满了与外部工具、API 的交互,无法进行端到端的梯度反向传播!为此,MaAS 采用了双轨优化策略,分别对 "架构分布" 和 "算子本身" 进行更新:
- 架构分布 (π) 的进化 - 蒙特卡洛策略梯度:
- MaAS 的目标函数不仅要考虑任务完成得好不好(Performance),还要考虑花了多少钱(Cost,如 token 数)。
- 它通过蒙特卡洛采样来估计梯度。简单说,就是让采样出的几个不同架构(G_k)都去试试解决问题。
- 然后,根据每个架构的 "性价比"(即性能高、成本低)赋予其一个重要性权重 (m_k)。
- 最后,用这个权重来更新超网的概率分布 π,让那些 "又好又省" 的架构在未来更容易被采样到。
- 算子 (O) 本身的进化 - Textual Gradient (文本梯度):
这是最 "魔法" 的地方!如何优化一个 Prompt 或者一段 Python 代码?MaAS 借鉴了 "文本梯度" 的概念。
它会利用一个梯度智能体,来分析某个算子(比如 Debate 算子)的表现。
如果表现不佳,这个 "教练" 会生成一段文本形式的 "改进意见",这就是 "文本梯度"。比如:
- "给这个 Refine 过程的 Prompt 里增加一个 few-shot 示例。"
- "为了稳定性,降低这个 Ensemble 模块里 LLM 的 temperature。"
- "给这个 Debate 算子增加一个'反对者'角色,以激发更深入的讨论。"

图 3 文本梯度案例
性能、成本、通用性:全都要!
MaAS 的效果不仅理念先进,数据更是亮眼。

图 4 MaAS 与其他多智能体方法性能比较
如上图所示,在 GSM8K、MATH、HumanEval 等六大主流基准测试上,MaAS 全面超越了现有的 14 个基线方法,性能提升了 0.54% ~ 11.82%。 平均得分高达 83.59%,展示了其卓越的通用性和高效性。

图 5 训练与推理成本比较
成本大降是更令人兴奋的一点。MaAS 所需的推理成本(如 token 消耗)平均只有现有自动化或手动系统的 45%。在 MATH 基准上,MaAS 的训练成本仅为 3.38 美元,而表现相近的 AFlow 则高达 22.50 美元,相差 6.8 倍。除此之外,MaAS 的优化时间仅需 53 分钟,远低于其他动辄数小时的方法。

图 6 MaAS 成本可视化
上图同样展示了 MaAs 在训练 token 消耗、推理 token 消耗和推理 API 金额方面的卓越性能。

图 7 MaAS 推理动态展示。可以看到,针对不同难度的 query,MaAS 智能地激活了不同的智能体网络架构解决之。
上图是 MaAS 对于不同难度的 query 的激活动态。可以看到,MaAS 完美地做到了任务难度的动态感知,对于简单的任务早早地退出了推理过程,而对于复杂的任务则深入 3~4 层智能体超网络 u,并且每层激活的智能体算子不止一个。
除此之外,MaAs 还展示出了超强泛化能力:
- 跨模型:在 gpt-4o-mini 上优化好的 "超网",可以轻松迁移到 Qwen-2.5-72b 和 llama-3.1-70b 等不同的大模型上,并带来显著的性能提升。
- 跨数据集:在 MATH 上训练,在 GSM8K 上测试,MaAS 依然表现出色,证明了其强大的跨领域泛化能力。
- 对未知算子:即使在训练中从未见过 "Debate" 这个算子,MaAS 在推理时依然可以合理地激活并使用它,展现了惊人的归纳能力。
总结
MaAS 通过引入 "智能体超网" 的概念,巧妙地将 NAS 的思想范式应用到多智能体系统的自动化设计中,完美解决了当前领域 "一刀切" 设计所带来的资源浪费和性能瓶颈问题。它不再追求一个静态的最优解,而是转向优化一个动态生成的架构分布,为不同任务提供量身定制的、最高性价比的解决方案。这项工作无疑为构建更高效、更经济、更智能的全自动化 AI 系统铺平了道路。
#舍弃CUDA编程
CMU等用几十行代码将LLM编译成巨型内核,推理延迟可降6.7倍
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。
不过,CUDA 驱动的 LLM 推理面临着手动优化成本高、端到端延迟高等不足,需要进一步优化或者寻找更高效的替代方案。
近日,CMU 助理教授贾志豪(Zhihao Jia)团队创新玩法,推出了一个名为「Mirage Persistent Kernel(MPK)」的编译器,可以自动将 LLM 转化为优化的巨型内核(megakernel),从而将 LLM 推理延迟降低 1.2 到 6.7 倍。

- GitHub 地址:https://github.com/mirage-project/mirage/tree/mpk
- 博客地址:https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
MPK 将 LLM 推理延迟推近硬件极限。在单个 A100-40GB GPU 上,MPK 将 Qwen3-8B 每个 token 的延迟从 14.5 毫秒 (vLLM/SGLang) 降低到 12.5 毫秒,逼近基于内存带宽计算得出的 10 毫秒理论下限。

MPK 的易用性很强,你只需要几十行 Python 代码就能将 LLM 编译成一个高性能巨型内核,实现快速推理,整个过程无需 CUDA 编程。

评论区对 MPK 的看法也很正向,并提出了一些未来的延展方向。

引入 MPK 的必要性
降低 LLM 推理延迟最有效的方法之一,是将所有计算和通信融合进一个单一的巨型内核,也称为持续内核。
在这种设计中,系统仅启动一个 GPU 内核来执行整个模型 ------ 从逐层计算到 GPU 间通信 ------ 整个过程无需中断。这种方法提供了以下几个关键的性能优势:
- 消除内核启动开销:通过避免重复的内核调用,即使是在多 GPU 环境下,也能消除内核启动开销;
- 实现跨层软件 pipeline 允许内核在计算当前层的同时,开始为下一层加载数据;
- 重叠计算与通信:由于巨型内核可以同时执行计算操作和 GPU 间通信,从而隐藏通信延迟。
尽管有这些优势,将 LLM 编译成巨型内核仍然极具挑战性。
现有的高级 ML 框架 ------ 如 PyTorch、Triton 和 TVM,它们本身并不支持端到端巨型内核生成。此外,现代 LLM 系统由各种不同的专用内核库构建而成:用于通信的 NCCL 或 NVSHMEM,用于高效注意力计算的 FlashInfer 或 FlashAttention,以及用于自定义计算的 CUDA 或 Triton。
这种碎片化使得将整个推理 pipeline 整合进一个单一的、统一的内核变得非常困难。
那么能否通过编译自动化这个过程呢?受到这个问题的启发,来自 CMU、华盛顿大学、加州大学伯克利分校、英伟达和清华大学的团队开发出了 MPK------ 一个编译器和运行时系统,它能自动将多 GPU 的 LLM 推理转换为高性能的巨型内核。MPK 释放了端到端 GPU 融合的效能优势,同时只需要开发者付出极小的手动努力。
MPK 的优势
MPK 的一个关键优势在于:通过消除内核启动开销,并最大程度地重叠跨层的计算、数据加载和 GPU 间通信,实现了极低的 LLM 推理延迟。
下图 1 展示了 MPK 与现有 LLM 推理系统在单 GPU 和多 GPU 配置下的性能对比(具体可见上文)。

除了单 GPU 优化,MPK 还将计算与 GPU 间通信融合进一个单一的巨型内核。 这种设计使得 MPK 能够最大程度地重叠计算与通信。因此,MPK 相对于当前系统的性能提升随着 GPU 数量的增加而增大,使其在多 GPU 部署场景下尤为高效。
MPK 的工作原理
MPK 的工作原理包括以下两大部分
- Part 1:MPK 编译器,其将 LLM 的计算图转化为优化的任务图;
- Part 2:MPK 运行时系统,该系统在单个巨型内核内执行任务图,以实现高吞吐量与低延迟。
编译器 ------ 将 LLM 转化为细粒度任务图
LLM 的计算过程通常表示为计算图,其中每个节点对应一个计算算子(如矩阵乘法、注意力机制)或集合通信原语(如 all-reduce),边表示算子间的数据依赖关系。现有系统通常为每个算子启动独立的 GPU 内核。
然而,这种「单算子单内核」的执行模型难以实现 pipeline 优化,因为依赖关系是在整个内核的粗粒度层面强制执行的,而非实际数据单元层面。
典型案例如矩阵乘法(matmul)后接 all-reduce 操作:现有系统中,all-reduce 内核必须等待整个 matmul 内核完成。而实际上,all-reduce 的每个数据分块仅依赖 matmul 输出的局部结果。这种逻辑依赖与实际依赖的错配,严重限制了计算与通信的重叠潜力。
下图 2 展示了 MPK 编译器将 PyTorch 定义的 LLM 计算图转化为优化细粒度任务图,最大化暴露并行性。右侧展示次优方案 ------ 其引入不必要的数据依赖与全局屏障,导致跨层流水线优化机会受限。

为了解决此问题,MPK 引入的编译器可将 LLM 计算图自动转化为细粒度任务图。该任务图在子内核级别显式捕获依赖关系,实现更激进的跨层流水线优化。
具体来讲,在 MPK 任务图中(如图 2 所示):
- 任务(矩形表示),代表分配给单个 GPU 流式多处理器(SM)的计算 / 通信单元。
- 事件(圆形表示),表示任务间的同步点。
- 触发机制,每个任务发出指向触发事件的边,该事件在关联任务全部完成后激活。
- 依赖机制,每个任务接收来自依赖事件的边,表明事件激活后任务立即启动。
任务图使 MPK 能够发掘计算图中无法实现的 pipeline 优化机会。例如,MPK 可以构建优化任务图 ------ 其中每个 all-reduce 任务仅依赖于生成其输入的对应 matmul 任务,从而实现分块执行与计算通信重叠。
除生成优化任务图外,MPK 还通过 Mirage 内核超优化器自动为每个任务生成高性能 CUDA 实现,确保任务在 GPU 流式多处理器(SM)上高效执行。
Part 2:运行时 ------ 在巨型内核中执行任务图
MPK 包含内置 GPU 运行时系统,可在单个 GPU 巨型内核内完整执行任务图。这使得系统能在推理过程中无需额外内核启动的情况下,实现任务执行与调度的细粒度控制。
为了实现此机制,MPK 在启动时将 GPU 上所有流式多处理器(SM)静态分区为两种角色:即工作单元(Worker)和调度单元(Scheduler)。
工作 SM 与调度 SM 的数量在内核启动时固定配置,且总和等于物理 SM 总数,从而彻底避免动态上下文切换开销。
工作单元
每个工作单元独占一个流式多处理器(SM),并维护专属任务队列。其执行遵循以下高效简洁的循环流程:
- 获取任务:从队列中提取下一待执行任务。
- 执行计算:运行任务(如矩阵乘法 / 注意力机制 / GPU 间数据传输)。
- 事件触发:任务完成后通知触发事件。
- 循环执行:重复上述过程。
该机制既保障了工作单元的持续满载运行,又实现了跨层和跨操作的异步任务执行。
调度单元
调度决策由 MPK 的分布式调度单元处理,每个调度单元运行于单个线程束(warp)上。由于每个流式多处理器(SM)可以容纳多个线程束,因此单 SM 最多可并发运行 4 个调度单元。每个调度单元维护激活事件队列,并持续执行以下操作:
- 事件出队:移除依赖已满足的激活事件(即所有前置任务均已完成)。
- 任务启动:调度依赖该激活事件的任务集。
这种分布式调度机制在实现跨 SM 可扩展执行的同时,最小化协同开销。
事件驱动执行
下图 3 展示了 MPK 的执行时间线,其中每个矩形代表一个在工作单元上运行的任务;每个圆圈代表一个事件。当一个任务完成时,它会递增其对应触发事件的计数器。当事件计数器达到预设阈值时,该事件被视为已激活,并被加入调度单元的事件队列。随后,调度单元会启动所有依赖于该事件的下游任务。
这种设计实现了细粒度的软件流水线化,并允许计算与通信之间重叠,比如
- 矩阵乘法(Matmul)任务可以与来自不同层的注意力任务并行执行。
- 一旦有部分 matmul 结果可用,即可开始 Allreduce 通信。
由于所有的调度和任务切换都发生在单一内核上下文内,任务间的开销极低,通常仅需 1-2 微秒,从而能够高效地执行多层、多 GPU 的 LLM 工作负载。

下一步计划
团队对 MPK 的愿景是使巨型内核编译既易于使用又具备高性能。目前,你只需几十行 Python 代码(主要用于指定巨型内核的输入和输出)即可将一个 LLM 编译成一个巨型内核。此方向仍有广阔的探索空间,目前正在积极攻关的一些关键领域包括如下:
- 支持现代 GPU 架构。下一个里程碑是将 MPK 扩展到支持下一代架构,例如 NVIDIA Blackwell。一个主要挑战在于如何将线程束专业化,这是新型 GPU 的一项关键优化技术,与 MPK 的巨型内核执行模型相集成。
- 处理工作负载动态性。 MPK 目前构建的是静态任务图,这限制了它处理动态工作负载(如 MoE 模型)的能力。团队正在开发新的编译策略,使 MPK 能够在巨型内核内部支持动态控制流和条件执行。
- 高级调度与任务分配。 MPK 在任务级别解锁了新的细粒度调度能力。虽然当前的实现使用简单的轮询调度在流式多处理器(SM)之间分配任务,但团队看到了在高级调度策略(如优先级感知或吞吐量优化策略)方面令人兴奋的机会,可应用于诸如延迟服务等级目标(SLO)驱动的服务或混合批处理等场景。
团队相信,MPK 代表了在 GPU 上编译和执行 LLM 推理工作负载方式的根本性转变,并热切期待与社区合作,共同推动这一愿景向前发展。
该项目也在快速迭代中,非常欢迎有兴趣的伙伴加入contribute。

#ML-Agent
7B智能体仅凭9个任务训练即超越R1!上交大打造AI-for-AI新范式
尽管人工智能(AI)在飞速发展,当前 AI 开发仍严重依赖人类专家大量的手动实验和反复的调参迭代,过程费时费力。这种以人为中心的方式已成为制约创新速度和通向通用人工智能(AGI)的关键瓶颈。为突破限制,AI-for-AI(AI4AI)应运而生。AI4AI 旨在让 AI 作为智能体来自主设计、优化和改进 AI 算法,大幅减少人类干预,加速迭代开发周期,推动 AGI 发展进程。
最近,上海交通大学与上海人工智能实验室联合团队最新研究表明,一个仅依赖 7B 参数大模型的 AI 智能体(ML-Agent),采用 "经验学习" 新范式,只在 9 个机器学习任务上持续探索学习,迭代进化,最终就能设计出超越 671B Deepseek-R1 驱动的智能体设计的 AI 模型,首次实现了在自主机器学习领域从 "提示工程" 到 "经验学习" 的范式跃迁,开创了 AI4AI 的新路径。
论文标题:ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
论文地址:https://arxiv.org/pdf/2505.23723
代码地址:https://github.com/MASWorks/ML-Agent
😫 传统自主机器学习:费时低效的困境
传统机器学习工程繁琐低效,研究人员常需数天至数月进行模型设计、参数调优,与反复试错,限制了 AI 创新发展的速度。最近,基于大语言模型(LLM)的智能体(Agent)的出现给该领域带来显著变革。它们能理解自然语言指令,生成代码并与环境交互,实现自主机器学习(Autonomous Machine Learning,AI4AI),提升 AI 开发效率。
然而,这些智能体仍高度依赖人工设计的提示词(Prompt Engineering),缺乏从经验中自主学习与泛化的能力。其能力提升仍需研究人员根据数小时的执行结果不断调整提示词形成 "等待 - 修改 - 重试" 的低效循环,仍难以摆脱对人力的依赖与效率瓶颈。
😀 AI4AI 破局之路:从指令遵循到自我进化
为解决这一关键限制,该研究首次探索了基于学习的智能体自主机器学习范式,其中智能体可以通过在线强化学习从机器学习任务的执行轨迹中进行学习。这种方式使得智能体能够主动探索不同的策略,跨任务积累知识,逐步优化决策,持续从自身经验中学习,并通过训练不断提升其设计优化 AI 的能力。

自主机器学习流程
🤖 ML-Agent:首个经验学习的 AI4AI 智能体
利用提出的训练框架,研究人员训练了一个由 7B 规模的 Qwen2.5 大模型驱动的自主机器学习智能体。在训练过程中,智能体能够高效地探索机器学习的环境,从经验中学习,并通过对各种机器学习任务的迭代探索实现持续的性能提升。令人惊喜的是,只在 9 个机器学习任务上反复学习,7B 的智能体不仅超越了 671B 规模的 DeepSeek-R1 智能体,还表现出了卓越的跨任务泛化能力。这项研究标志着 AI 智能体在设计 AI 中从 "工具执行者" 向 "自主学习者" 的转变,带来了 "AI 自主设计 AI" 的新范式。

自主机器学习训练框架
🌟 三大核心突破,解锁 AI 自进化
研究团队提出全新训练框架,攻克自主机器学习三大难题:
1️⃣ 敢想敢试:探索增强微调
- 问题:传统自主机器学习智能体重复相似操作,创新受限!
- 解法:探索增强微调 (Exploration-enriched fine-tuning),通过精心设计的多样化的专家轨迹数据集,训练智能体尝试不同策略,大幅提升探索能力。
- 效果:拓宽智能体的探索范围,增强后续强化学习阶段多样化策略生成能力,不再局限局部最优解,而是具备更广泛的策略选择空间!

探索增强微调助力强化学习训练
2️⃣ 快速迭代:逐步强化学习范式
- 问题:完整迭代机器学习实验需数小时,传统 RL 方法在机器学习实验中采样效率低下!
- 解法:逐步强化学习范式(Step-wise RL paradigm),重构训练目标函数,每次只优化单步动作,数据收集效率提升数倍。
- 效果:RL 训练阶段可扩展性提高,训练时间显著缩短!

逐步强化学习(红线,每训练 5 步进行一次评测)比基于整条轨迹的强化学习(蓝线,每训练 1 步进行一次评测)更高效
3️⃣ 听懂反馈:定制化奖励模块
- 问题:实验反馈复杂(如代码错误、资源溢出、性能提升),难以统一!
- 解法:机器学习定制化奖励模块(Agentic ML-Specific Reward Module) 惩罚错误、鼓励改进,将机器学习多样执行结果转换为统一反馈。
- 效果:为 RL 优化提供一致有效的奖励信号,推动智能体在自主机器学习训练中进行持续迭代改进!

机器学习定制化奖励模块每一组成部分的有效性
📊 ML-Agent 持续进化,展现泛化能力!
研究团队利用所提训练框架训练了一个由开源大模型 Qwen2.5-7B 驱动的自主机器学习智能体 ------ML-Agent,并开展广泛的实验以评估其性能。结果表明:
✅ ML-Agent 具有强大泛化能力
研究将 ML-Agent 与 5 个强大的开源 / 闭源 LLM 驱动的智能体进行了比较。下表说明,ML-Agent 在见过 / 未见过的机器学习任务中的平均和最好性能都达到了最高。令人惊喜的是,只在 9 个机器学习任务上不断学习,7B 大模型驱动的 ML-Agent 就在所有 10 个未见过的机器学习任务上超过了 671B 的 Deepseek-R1 驱动的自主机器学习智能体,展现出了强大的泛化能力。

ML-Agent 具有强大泛化能力
✅ ML-Agent 优于最先进方法
为了进一步证明训练框架的有效性,研究人员将 ML-Agent 与一个专门为自主机器学习设计的 LLM 智能体(AIDE)作比较。结果显示,ML-Agent 总体优于 AIDE 智能体,凸显了所提训练框架的有效性。

ML-Agent 优于最先进的自主机器学习智能体
✅ ML-Agent 持续进化
随着训练的进行,ML-Agent 不断自我探索,从自主机器学习的经验中学习,在训练过 / 未经训练过的机器学习任务上性能持续提升,最终超越所有基线方法。

ML-Agent 的自主机器学习能力在训练中持续提升
ML-Agent 引领了 AI4AI 的新范式,将自主机器学习从依赖人类优化的、提示工程的低效模式,转变为智能体自主探索的、基于自我经验学习的设计方式。这一转变大幅减少人类干预,加速了 AI 算法的设计迭代。随着 ML-Agent 在更多的机器学习任务上持续自我学习与探索,其能力有望不断提升,设计出更高效智能的 AI,为构建强大的 AI4AI 系统奠定坚实基础,为实现通用人工智能的长远目标贡献关键力量。
🔥 MASWorks 大模型多智能体开源社区
ML-Agent 也是最近刚发起的大模型多智能体开源社区 MASWorks 的拼图之一。MASWorks 社区致力于连接全球研究者,汇聚顶尖智慧,旨在打造一个开放、协作的平台,共同分享、贡献知识,推动多智能体系统(MAS)领域的蓬勃发展。
作为社区启动的首个重磅活动,MASWorks 将在 ICML 2025 举办聚焦大语言模型多智能体的 Workshop:MAS-2025!期待全球广大学者的积极参与,共同探讨、碰撞思想,描绘 MAS 的未来蓝图!
- MASWorks 地址:
https://github.com/MASWorks - MAS-2025 地址:
https://mas-2025.github.io/MAS-2025/
#月之暗面「调教」出最强Agent
在「人类最后一场考试」拿下最新 SOTA
昨天,月之暗面发了篇博客,介绍了一款名为 Kimi-Researcher 的自主 Agent。
这款 Agent 擅长多轮搜索和推理,平均每项任务执行 23 个推理步骤,访问超过 200 个网址。它是基于 Kimi k 系列模型的内部版本构建,并完全通过端到端智能体强化学习进行训练,也是国内少有的基于自研模型打造的 Agent。

GitHub 链接:https://moonshotai.github.io/Kimi-Researcher/
在「人类最后一场考试」(Humanity's Last Exam) 中,Kimi-Researcher 取得了 26.9% 的 Pass@1 成绩,创下最新的 SOTA 水平,Pass@4 准确率也达到了 40.17%。
从初始的 8.6% HLE 分数开始,Kimi-Researcher 几乎完全依靠端到端的强化学习训练将成绩提升至 26.9%,强有力地证明了端到端智能体强化学习在提升 Agent 智能方面的巨大潜力。
Kimi-Researcher 还在多个复杂且极具挑战性的实际基准测试中表现出色。在 xbench (一款旨在将 AI 能力与实际生产力相结合的全新动态、专业对齐套件)上,Kimi-Researcher 在 xbench-DeepSearch 子任务上平均 pass@1 达到了 69% 的分数(4 次运行的平均值),超越了诸如 o3 等带有搜索工具的模型。在多轮搜索推理(如 FRAMES、Seal-0)和事实信息检索(如 SimpleQA)等基准测试中,Kimi-Researcher 同样取得了优异成绩。

举个例子。我们想找一部外国动画电影,但只记得大概剧情:
我想找一部外国的动画电影,讲的是一位公主被许配给一个强大的巫师。我记得她被关在塔里,等着结婚的时机。有一次她偷偷溜进城里,看人们缝纫之类的事情。总之,有一天几位王子从世界各地带来珍贵礼物,她发现其中一位王子为了得到一颗宝珠作为礼物,曾与当地人激烈交战。她指责他是小偷,因为他从他们那儿偷走了圣物。
随后,一个巫师说服国王相信她在撒谎,说她被某种邪灵附体,并承诺要为她"净化",作为交换条件是娶她为妻。然后巫师用魔法让她变成一个成年女子,并把她带走。他把她关进地牢,但她有一枚可以许三个愿望的戒指。
由于被施了魔法,让她失去了逃跑的意志,她把前两个愿望浪费在了一些愚蠢的东西上,比如一块布或者一张床之类的......然后她好像逃出来了......并且耍了那个巫师一把......她后来还找到了一块可以生出水的石头......我记得还有人被变成青蛙......
整部电影发生在一个有点后末日设定的世界里,是一个古老魔法文明崩塌几百年之后的背景。如果有人知道这是什么电影,请告诉我。我一直在找这部电影,已经找了好久了。
上下滑动查看更多
Kimi-Researcher 就会根据给定的模糊信息进行检索,最终识别出该电影为《阿瑞特公主》,并一一找出该电影与剧情描述之间的对应关系。

此外,它还能进行学术研究、法律与政策分析、临床证据审查、企业财报分析等。
Kimi--Researcher 现已开始逐步向用户推出,可以在 Kimi 内实现对任意主题的深入、全面研究。月之暗面也计划在接下来的几个月内开源 Kimi--Researcher 所依赖的基础预训练模型及其强化学习模型。
端到端的智能体强化学习
Kimi--Researcher 是一个自主的智能体与思维模型,旨在通过多步规划、推理和工具使用来解决复杂问题。它利用了三个主要工具:一个并行的实时内部搜索工具;一个用于交互式网页任务的基于文本的浏览器工具;以及一个用于自动执行代码的编码工具。
传统 agent 开发存在以下几个关键限制:
基于工作流的系统:多智能体工作流将角色分配给特定智能体,并使用基于提示的工作流进行协调。虽然有效,但它们依赖于特定的语言模型版本,并且在模型或环境发生变化时需要频繁手动更新,从而限制了系统的可扩展性和灵活性。
带监督微调的模仿学习(SFT):模仿学习能使模型很好地对齐人类演示,但在数据标注方面存在困难,尤其是在具有长时间跨度、动态环境中的智能体任务中。此外,SFT 数据集通常与特定工具版本强耦合,导致随着工具的演变,其泛化能力会下降。
端到端的智能体强化学习(agentic RL)训练的是一个能够整体性解决问题的单一模型:给定一个查询,智能体会探索大量可能的策略,通过获得正确解答的奖励进行学习,并从整个决策轨迹中总结经验。与监督微调(SFT)不同,端到端方法天然适应长程、基于当前策略的推理过程,并能动态适应工具与环境的变化;也不同于模块化方法,它将规划、感知、工具使用等能力融合在一个模型中统一学习,无需手工编写规则或工作流模板。
OpenAI 的 Deep Research 等先前研究也展示了这种方法的强大性能,但它也带来了新的挑战:
- 动态环境:即使面对相同的查询,环境结果也可能随时间发生变化,智能体必须具备适应不断变化条件的能力。目标是实现对分布变化的鲁棒泛化能力。
- 长程任务:Kimi--Researcher 每条轨迹可执行超过 70 次搜索查询,使用的上下文窗口长度甚至达数十万 token。这对模型的记忆管理能力以及长上下文处理能力提出了极高要求。
- 数据稀缺:高质量的用于智能体问答的强化学习数据集非常稀缺。该研究团队通过自动合成训练数据的方式解决这一问题,从而实现无需人工标注的大规模学习。
- 执行效率:多轮推理和频繁工具调用可能导致训练效率低下,GPU 资源利用不足。优化 rollout 效率是实现可扩展、实用的智能体强化学习训练的关键。
研究方法
Kimi--Researcher 是通过端到端的强化学习进行训练的。研究团队在多个任务领域中观察到了智能体性能的持续提升。图 2-a 展示了 Kimi--Researcher 在强化学习过程中整体训练准确率的变化趋势;图 2-b 则呈现了模型在若干内部数据集上的性能表现。

训练数据
为了解决高质量智能体数据集稀缺的问题,研究团队在训练语料的构建上采取了两种互补的策略。
首先,他们设计了一套具有挑战性的、以工具使用为核心的任务,旨在促进智能体对工具使用的深入学习。这些任务提示被刻意构造为必须调用特定工具才能解决 ------ 从而使得简单的策略要么根本无法完成任务,要么效率极低。通过将工具依赖性融入任务设计中,智能体不仅学会了何时调用工具,也学会了在复杂的现实环境中如何高效协同使用多种工具。(图 3 展示了在这些训练数据中,模型对工具的调用频率。)

其次,他们策划并整合了一批以推理为核心的任务,旨在强化智能体的核心认知能力,以及其将推理与工具使用结合的能力。该部分进一步细分为以下两类:
- 数学与代码推理:任务聚焦于逻辑推理、算法问题求解和序列计算。Kimi--Researcher 不仅依赖思维链进行解题,还能结合工具集解决这类复杂问题。
- 高难度搜索:这类任务要求智能体在上下文限制下进行多轮搜索、信息整合与推理,最终得出有效答案。案例研究表明,这些高难搜索任务促使模型产生更深层的规划能力,以及更健壮、工具增强的推理策略。
为了大规模构建这一多样化提示集,研究团队开发了一条全自动数据生成与验证流程,可在极少人工干预下生成大量问答对,同时保证数据的多样性与准确性。对于合成任务而言,确保「准确的标准答案(ground truth, GT)」至关重要,因此他们引入了一种强大的 GT 提取方法,以尽可能确保每个问题都配有可靠的答案。
此外,他们还设计了严格的过滤流程,以剔除歧义、不严谨或无效的问答对;其中引入的 Pass@N 检查机制,可确保仅保留具有挑战性的问题。图 4 展示了基于两项实验结果的合成任务效果评估。
强化学习训练
该模型主要采用 REINFORCE 算法进行训练。以下因素有助于提升训练过程的稳定性:
- 基于当前策略的数据生成(On-policy Training):生成严格的 on-policy 数据至关重要。在训练过程中,研究团队禁用了 LLM 引擎中的工具调用格式强制机制,确保每条轨迹完全基于模型自身的概率分布生成。
- 负样本控制(Negative Sample Control):负样本会导致 token 概率下降,从而在训练中增加熵崩塌(entropy collapse)的风险。为应对这一问题,他们策略性地丢弃部分负样本,使模型能够在更长的训练周期中持续提升表现。
Kimi--Researcher 使用基于最终结果的奖励机制进行训练,以在动态训练环境中保持一致的偏好方向。
- 格式奖励(Format Reward):如果轨迹中包含非法的工具调用,或上下文 / 迭代次数超出限制,模型将受到惩罚。
- 正确性奖励(Correctness Reward):对于格式合法的轨迹,奖励依据模型输出与标准答案(ground truth)之间的匹配程度进行评估。
为了提升训练效率,研究团队在正确轨迹上引入了 gamma 衰减因子(gamma-decay factor)。该机制鼓励模型寻找更短、更高效的探索路径。例如,两条最终结果相同的正确轨迹,较短的那一条将因其前期行为更高效而获得更高奖励。
上下文管理
在长程研究任务中,智能体的观察上下文可能会迅速膨胀。如果没有有效的记忆管理机制,普通模型在不到 10 次迭代内就可能超过上下文限制。为了解决这一问题,研究团队设计了一套上下文管理机制,使模型能够保留关键信息,同时舍弃无用文档,从而将单条轨迹的迭代次数扩展至 50 次以上。
早期的消融实验表明,引入上下文管理机制的模型迭代次数平均提升了 30%,这使其能够获取更多信息,进而实现更优的任务表现。
大规模智能体RL infra
为应对大规模智能体强化学习在效率与稳定性方面的挑战,研究者构建了一套具备以下关键特性的基础设施体系:

- 完全异步的 rollout 系统:实现了一个具备扩展性、类 Gym 接口的全异步 rollout 系统。基于服务端架构,该系统能够高效并行协调智能体的轨迹生成、环境交互与奖励计算。相较于同步系统,这一设计通过消除资源空转时间显著提升了运行效率。
- 回合级局部回放(Turn-level Partial Rollout):在 Agent RL 训练中,大多数任务可在早期阶段完成,但仍有一小部分任务需要大量迭代。为解决这一长尾问题,研究者设计了回合级局部回放机制。具体来说,超出时间预算的任务将被保存至 replay buffer,在后续迭代中以更新后的模型权重继续执行剩余部分。配合优化算法,该机制可实现显著的 rollout 加速(至少提升 1.5 倍)。
- 强大的沙盒环境:研究者构建了统一的沙盒架构,在保持任务隔离性的同时,消除了容器间通信开销。基于 Kubernetes 的混合云架构实现了零停机调度与动态资源分配。Agent 与工具之间通过 MCP(Model Context Protocol)进行通信,支持有状态会话与断线重连功能。该架构支持多副本部署,确保在生产环境中具备容错能力与高可用性。
智能体能力的涌现
在端到端强化学习过程中,研究者观察到 Kimi--Researcher 出现了一些值得关注的能力涌现。
- 面对多来源信息冲突时,Kimi--Researcher 能通过迭代假设修正与自我纠错机制来消除矛盾,逐步推导出一致且合理的结论。
- 展现出谨慎与严谨的行为模式:即便面对看似简单的问题,Kimi--Researcher也会主动进行额外搜索,并交叉验证信息后再作答,体现出高度可靠性与信息安全意识。
#DrSR (Dual Reasoning Symbolic Regression)
三个大模型合作,1000次迭代,竟能像人类科学家一样发现方程
随着 AI4Science 的浪潮席卷科研各领域,如何将强大的人工智能模型真正用于分析科学数据、构建数学模型、发现科学规律,正成为该领域亟待突破的关键问题。
近日,中国科学院自动化研究所的研究人员提出了一种创新性框架 ------DrSR (Dual Reasoning Symbolic Regression):通过数据分析与经验归纳 "双轮驱动",赋予大模型像科学家一样 "分析数据、反思成败、优化模型" 的能力。
在 DrSR 中,三位 "虚拟科学家" 协同工作:
一个善于洞察变量关系的 "数据科学家";
一个擅长总结失败教训与成功经验的 "理论科学家";
一个勇于尝试假设、不断优化模型的 "实验科学家"。
这三种角色基于大模型构建起高效的协作机制,共同驱动 DrSR 实现智能化、系统化的科学方程发现。
在物理、生物、化学、材料等跨学科领域的典型建模任务中(如非线性振荡系统建模、微生物生长速率建模、化学反应动力学建模、材料应力 - 应变关系建模等),DrSR 展现出强大的泛化能力,刷新当前最优性能,成为 AI 助力科学研究的有力工具。
- 论文地址:https://arxiv.org/abs/2506.04282
- 论文标题:DrSR: LLM based Scientific Equation Discovery with Dual Reasoning from Data and Experience
研究背景
在科学发现和工程建模中,寻找数据背后的数学模型一直是一项核心任务。这正是符号回归(Symbolic Regression, SR)的目标 ------ 从观测数据出发,自动生成解释性强、结构清晰的数学方程。
这种 "从数据中还原规律" 的能力,已在物理、化学、生物、材料等多个学科中发挥了巨大作用,成为人类理解复杂系统的重要工具。
随着大模型的兴起,符号回归正迈入一个 "类人推理" 的新阶段。例如,LLM-SR 等方法开始尝试用大模型直接生成公式骨架(skeleton),再配合优化器拟合参数,实现 "从提示词到方程" 的自动生成。这让符号回归从传统的遗传进化算法中解放出来,性能和表达能力双双提升。
但问题也随之而来,这些方法虽然 "公式写得快",却往往 "不看数据",更 "不记经验"。
模型生成公式靠的是大模型内嵌的科学知识,而非对当前实验数据的深入理解。
一旦某个公式生成失败,模型通常无法从失败中改进策略,只会机械地重复尝试,陷入 "盲猜" 或 "重走老路" 的困境。
结果就是:不是过拟合 "已有套路",就是反复生成无效表达式,计算资源浪费严重,智能化程度受限。
为了解决这一难题,研究团队提出了全新框架 DrSR:让模型 "会看题""会复盘""会改进"------ 像科学家一样,从数据中洞察结构、从失败中总结经验、在生成中持续进化。
DrSR:让大模型 "有据可依、
步步为营" 地发现规律
DrSR 的核心理念是 "双路径推理"(Dual Reasoning):通过引入 "数据洞察" 与 "经验总结" 两条信息流,为大模型提供结构引导与策略反馈,让其像科学家一样高效、稳健地进行探索。
DrSR 的两大关键机制包括:
- 数据驱动的洞察生成(Data-aware Insight Extraction)
- 经验驱动的策略总结(Inductive Idea Learning)
DrSR 的流程并不复杂,关键在于:让 LLM 在每一轮尝试中都 "看数据、学经验、再出手",具体流程如图 1 所示。

图 1:DrSR 的双路径推理机制,让 LLM 在分析、生成、复盘三个环节协同工作,模拟科学家的研究思维
🔍 模块 a:从数据中提炼结构线索
- 数据分析模块由一个 "结构洞察型 LLM" 构成,它负责分析输入输出变量之间的映射关系,提取变量之间的耦合程度、单调性、线性 / 非线性趋势等结构特征。
- DrSR 不只分析原始数据,还会根据上一轮候选方程的残差,进一步定位 "没拟合好" 的数据段,为后续方程生成提供更高质量的提示。
🧠 模块 b:从历史结果中总结成功经验
方程一旦生成,DrSR 不仅会进行拟合与打分,还会将结果分类为「效果更好」「效果变差」「无法执行」三类,并交由一个 "经验型 LLM" 进行分析,总结出可以重复利用的经验知识。
该模块会进行如下反思:
- 为什么这条方程效果更好 / 更坏 / 无法执行?
- 从这次方程的生成中,可以总结出什么经验或教训?
总结出的知识以 idea 的形式存入 idea 库(Idea Library),供后续轮次调用,提升生成策略的有效性。
🧮 模块 c:方程生成 + 数值拟合
DrSR 的 "主控型 LLM" 负责综合问题描述、数据分析结论和 idea 库的经验,生成方程 skeleton。随后调用 BFGS 等优化器进行系数拟合,并评估方程的整体误差。表达式被送回评估路径,进入下一轮经验提炼与数据再分析循环。
这个模块是整个 DrSR 的 "前台",而 a 与 b 是强大的 "后端支持"。
总结来说,DrSR 的运行流程是一种闭环:
数据分析 → 提示引导 → 方程生成 → 评估打分 → 经验总结,如此循环。每一次生成,模型都在积累知识、修正路径,从 "盲目试探" 走向 "有的放矢"。
实验结果:DrSR 不仅 "更准",
还 "更快、更稳、更聪明"
研究团队在六大符号回归基准任务上系统评估了 DrSR 的性能,涵盖物理、生物、化学、材料等多个科学领域,结果显示 DrSR 全面超越现有主流方法,不仅准确率更高,而且在推理效率和泛化能力上也显著领先。
📊 全面领先的拟合精度与准确率

表 1. DrSR 和基线方法在六个符号回归基准上的总体性能
如表 1 所示,平均来看,DrSR 在 6 个任务中有 5 个取得了最高准确率(Acc)和最低归一化均方误差(NMSE)。特别地,DrSR 在非线性阻尼振荡系统建模任务(Oscillation 2)上达成了近乎完美的 99.94% 准确率,误差低至 1.8e-12,显著优于所有基线方法。
🔁 快速收敛:从一开始就更聪明

图 2. 训练收敛性比较
从图 2 可以看到,DrSR 在几乎所有数据集上都以更快速度达到更低的误差。在初期迭代阶段,其误差下降趋势也更稳定,不容易陷入振荡或卡顿,这说明 DrSR 的双推理策略能更有效引导方程生成方向,从而减少无效尝试次数。
✅ 有效率更高:生成的方程更 "靠谱"

图 3. 有效解比例对比
如图 3 所示,DrSR 生成的方程在语法、编译、可求值等方面的有效比例普遍高于 LLM-SR 约 10%-20%,这背后正是 "经验学习" 机制的作用 ------ 模型逐步避开常见失败结构。
📈 泛化更强,且对噪声和 OOD 更鲁棒

图 4. 在 ID 和 OOD 数据下跨科学领域的泛化对比
图 4 展示了 DrSR 在 ID(域内)与 OOD(域外)数据下的性能对比。可以看到:在所有任务、所有设置下,DrSR 的归一化均方误差(NMSE)始终是最低的,展现出极强的模型稳定性。其他方法(如 PySR 或 uDSR)虽然在部分任务中 ID 表现尚可,但面对 OOD 分布时误差陡升、性能骤降,而 DrSR 则表现出了 "跨场景保持鲁棒" 的能力。

表 2. 不同高斯噪声水平下的性能比较
如表 2 所示,在不同高斯噪声水平下,DrSR 均显著优于 LLM-SR,展现出抗噪、抗漂移的泛化优势。
🧪 消融实验:两个核心机制 "缺一不可"

图 5. 消融实验
图 5 的消融实验也验证了两个核心机制的重要性:没有结构引导,模型不知从何生成;没有经验总结,模型容易反复试错。DrSR 的成功,正是这两者闭环协同的结果。
案例展示:DrSR 如何一步步逼近 "真实方程"
为了更直观地展示 DrSR 的 "类科学家" 建模过程,研究团队以非线性阻尼振荡系统建模任务为例,绘制了其在 1000 次迭代过程中的方程演化轨迹,如图 6 所示。

图 6. DrSR 的性能轨迹与代表性表达式演化,每一个台阶,都是模型一次深刻的 "认知飞跃"
该任务的真实方程为:

DrSR 在仅 1000 轮迭代后生成的最优方程为:

基线 LLM-SR 在 2000 轮迭代后生成的最优方程为:

可以看到:DrSR 用一半的迭代次数,就生成了更接近真实结构的表达式,充分体现其 "有方向感" 的探索能力。
这一案例也展现出 DrSR 独特的三大智能行为:
- 初期:大胆探索,快速淘汰
在前几十轮中,DrSR 尝试了一系列初步构造的方程,例如仅包含多项式组合的表达式(如 -0.5xv - 0.04x² - 0.24v² 等),尽管形式接近,但精度仍远未达到理想值。此阶段模型更像一个 "实验科学家",快速试错、积累经验。
- 中期:融合非线性成分,跨越式发展
随着经验的积累与数据结构的洞察引入,DrSR 开始生成带有 sin (x)、x²v 等非线性物理元素的表达式,方程拟合误差明显下降近两个数量级,说明模型已开始理解系统的振荡性本质。此时,它如同一个 "理论科学家",开始用正确的符号结构组织规律。
- 后期:精炼组合,逼近真实动力学
最终,DrSR 提出了形如 0.8sin (x) - 0.5xv - 0.5v³ - 0.2x³ 的复杂但精确表达式,误差降至 10^-5 级别,接近人类解析解。这一过程高度模拟了科学发现中的 "假设 - 验证 - 归纳" 的迭代式建模模式。
这个案例生动说明了 DrSR 如何结合 "结构洞察 + 经验引导" 两种智慧,逐步收敛到准确又可解释的科学方程。
总结:让大模型更像科学家,科学智能迈出关键一步
DrSR 提出了一种融合数据感知与经验反思的符号回归新范式,它通过结构洞察指导生成方向,通过经验总结提升推理质量,让大模型在科学建模中逐步具备 "看数据、记教训、会修正" 的能力。
在多个跨学科的符号回归任务中,DrSR 实现了对传统方法与现有 LLM 基线的全方位超越,在准确率、收敛速度、方程有效性和泛化能力等维度表现突出。作为一套通用性强、可解释性好、建模效率高的新架构,DrSR 为人工智能深度参与科学发现提供了坚实技术支撑。
DrSR 已集成至一站式智能科研平台 ScienceOne,为科研工作者提供高效、可解释的科学建模服务。值得强调的是,DrSR 并不依赖特定的大模型,具备良好的模型兼容性和可扩展性。未来,研究团队将基于平台自研的科学基础大模型 S1-Base,进一步增强 DrSR 在科学建模中的推理能力与跨任务泛化能力。
局限与展望
尽管 DrSR 展现出优异的建模性能与类科学家的推理能力,但仍存在若干值得改进的方面:
- 输出波动:由于大模型生成本身具有随机性,部分方程可能存在结构冗余、表达复杂等问题,仍需人工后处理或规则约束。
- 模态输入有限:DrSR 目前主要面向结构化数值数据,尚未支持图像、图表等更丰富的科学输入形式,制约了其多模态建模能力。
这些问题正是未来演进的关键方向。研究团队计划继续扩展 DrSR 至多模态科学建模场景,引入持续学习机制,提升策略泛化能力,逐步构建一个具备长期认知积累、适应科学复杂性的智能建模引擎。
让人工智能不仅能 "拟合数据",更能 "发掘自然规律",这正是 AI4Science 走向深层科学智能的必由之路。