文章目录
-
- [一、 SQL Server简介](#一、 SQL Server简介)
-
- [1.1 什么是SQL Server](#1.1 什么是SQL Server)
-
- [1.1.1 SQL Server 架构](#1.1.1 SQL Server 架构)
- [1.1.2 SQL Server 服务和工具](#1.1.2 SQL Server 服务和工具)
- [1.1.3 SQL Server 版本](#1.1.3 SQL Server 版本)
- [1.2 安装SQL Server 2022](#1.2 安装SQL Server 2022)
- [1.3 SQL Server 示例数据库](#1.3 SQL Server 示例数据库)
- [1.4 加载示例数据库](#1.4 加载示例数据库)
- [1.5 SQL Server常用语句概览](#1.5 SQL Server常用语句概览)
- 二、基础查询语句
-
- [2.1 SELECT(查询)](#2.1 SELECT(查询))
-
- [2.1.1 SQL Server 表的基本概念](#2.1.1 SQL Server 表的基本概念)
- [2.1.2 查询指定列或所有列](#2.1.2 查询指定列或所有列)
- [2.1.3 扩展功能(过滤行、排序行、分组行和过滤分组)](#2.1.3 扩展功能(过滤行、排序行、分组行和过滤分组))
- [2.2 ORDER BY(排序)](#2.2 ORDER BY(排序))
-
- [2.2.1 按select 列表中的列进行排序](#2.2.1 按select 列表中的列进行排序)
- [2.2.2 按FROM表中的列排序](#2.2.2 按FROM表中的列排序)
- [2.2.3 按表达式排序](#2.2.3 按表达式排序)
- [2.2.4 OFFSET FETCH 子句](#2.2.4 OFFSET FETCH 子句)
- [2.3 TOP(返回前N行)](#2.3 TOP(返回前N行))
- [2.4 SELECT DISTINCT(查询去重)](#2.4 SELECT DISTINCT(查询去重))
-
- [2.4.1 基础用法](#2.4.1 基础用法)
- [2.4.2 DISTINCT vs. GROUP BY](#2.4.2 DISTINCT vs. GROUP BY)
- [2.5 列别名与表别名](#2.5 列别名与表别名)
-
- [2.5.1 列别名(Column Alias)](#2.5.1 列别名(Column Alias))
- [2.5.2 表别名(Table Alias)](#2.5.2 表别名(Table Alias))
- 三、数据筛选
-
- [3.1 NULL与与 IS NUL](#3.1 NULL与与 IS NUL)
-
- [3.1.1 三值逻辑](#3.1.1 三值逻辑)
- [3.1.2 IS NULL与IS NOT NULL](#3.1.2 IS NULL与IS NOT NULL)
- [3.2 WHERE (过滤)](#3.2 WHERE (过滤))
- [3.3 AND运算符](#3.3 AND运算符)
- [3.4 OR 运算符](#3.4 OR 运算符)
- [3.5 IN 与NOT IN(列表匹配)](#3.5 IN 与NOT IN(列表匹配))
-
- [3.5.1 基础语法与示例](#3.5.1 基础语法与示例)
- [3.5.2 与子查询结合使用](#3.5.2 与子查询结合使用)
- [3.6 BETWEEN 与 NOT BETWEEN (范围比较)](#3.6 BETWEEN 与 NOT BETWEEN (范围比较))
- [3.7 LIKE 与NOT LIKE (模糊匹配)](#3.7 LIKE 与NOT LIKE (模糊匹配))
-
- [3.7.1 使用 % 通配符 或 NOT LIKE](#3.7.1 使用 % 通配符 或 NOT LIKE)
- [3.7.2 使用 _ 通配符 或 character-character 通配符](#3.7.2 使用 _ 通配符 或 [character-character] 通配符)
- [3.7.3 使用 list of characters 通配符 或 \^character list or range 通配符](#3.7.3 使用 [list of characters] 通配符 或 [^character list or range] 通配符)
- [3.7.4 使用ESCAPE 子句定义转义字符](#3.7.4 使用ESCAPE 子句定义转义字符)
- 四、分组聚合
-
- [4.1 GROUP BY:分组查询与数据汇总](#4.1 GROUP BY:分组查询与数据汇总)
-
- [4.1.1 GROUP BY 简介](#4.1.1 GROUP BY 简介)
- [4.1.2 分组聚合](#4.1.2 分组聚合)
- [4.1.3 HAVING子句:过滤分组数据](#4.1.3 HAVING子句:过滤分组数据)
- [4.2 GROUPING SETS:自定义多个组集](#4.2 GROUPING SETS:自定义多个组集)
-
- [4.2.1 准备示例数据](#4.2.1 准备示例数据)
- [4.2.2 使用GROUP BY进行分组统计](#4.2.2 使用GROUP BY进行分组统计)
- [4.2.3 使用 UNION ALL 实现多分组集](#4.2.3 使用 UNION ALL 实现多分组集)
- [4.2.4 使用 GROUPING SETS 简化查询](#4.2.4 使用 GROUPING SETS 简化查询)
- [4.2.5 GROUPING 函数](#4.2.5 GROUPING 函数)
- [4.3 CUBE:生成多个分组集](#4.3 CUBE:生成多个分组集)
-
- [4.3.1 CUBE VS GROUPING SETS](#4.3.1 CUBE VS GROUPING SETS)
- [4.3.2 CUBE 语法](#4.3.2 CUBE 语法)
- [4.3.3 部分 CUBE](#4.3.3 部分 CUBE)
- [4.4 ROLLUP:计算分层汇总](#4.4 ROLLUP:计算分层汇总)
-
- [4.4.1 ROLLUP简介](#4.4.1 ROLLUP简介)
- [4.4.2 ROLLUP示例](#4.4.2 ROLLUP示例)
一、 SQL Server简介
1.1 什么是SQL Server
SQL Server 是由微软开发和销售的关系型数据库管理系统(RDBMS)。与其他 RDBMS 软件类似,SQL Server 基于 SQL,这是一种用于与关系型数据库交互的标准编程语言。SQL Server 与 Transact-SQL(T-SQL)密切相关,这是微软对 SQL 的实现,包含了一组专有的编程构造。
SQL Server 在过去 20 多年中一直仅限于 Windows 环境。2016 年,微软将其扩展到 Linux 系统。SQL Server 2017 于 2016 年 10 月正式发布,支持 Windows 和 Linux。
1.1.1 SQL Server 架构
下图表展示了 SQL Server 的架构, 包含两个主要组件:数据库引擎 和 SQL Server 操作系统(SQLOS) 。

-
数据库引擎 :SQL Server 的核心组件是数据库引擎,它包含一个处理查询的关系引擎和一个管理数据库文件、页面、索引等的存储引擎。此外,数据库引擎还创建诸如 存储过程、视图 和 触发器 等数据库对象。
-
关系引擎 :关系引擎包含用于确定执行查询的最佳方法的组件,也称为查询处理器。
关系引擎根据输入的查询从存储引擎请求数据并处理结果。关系引擎的一些任务包括查询处理、内存管理、线程和任务管理、缓冲区管理和分布式查询处理。
-
存储引擎:存储引擎负责从存储系统(如磁盘和 SAN)中存储和检索数据。
-
-
SQLOS:在关系引擎和存储引擎之下是 SQLOS。SQLOS 提供各种操作系统服务,例如内存和 I/O 管理,以及异常处理和同步服务。
1.1.2 SQL Server 服务和工具
微软为 SQL Server 提供了数据管理和商业智能(BI)工具和服务:
| 场景 | 工具/服务 | 说明 |
|---|---|---|
| 数据管理 | SQL Server Integration Services (SSIS) | 提供数据集成和 ETL(提取、转换、加载)功能,用于数据迁移和数据仓库构建。 |
| SQL Server Data Quality Services | 用于数据质量管理和数据清洗,确保数据的准确性和一致性。 | |
| SQL Server Master Data Services | 用于主数据管理,帮助组织和管理关键业务数据。 | |
| 数据库开发 | SQL Server Data Tools (SSDT) | 提供开发工具,支持数据库设计、开发和部署,集成在 Visual Studio 中。 |
| 数据库管理 | SQL Server Management Studio (SSMS) | 用于数据库的管理、部署和监控,提供图形化界面和脚本执行功能。 |
| 数据分析 | SQL Server Analysis Services (SSAS) | 提供多维数据分析和数据挖掘功能,支持商业智能应用。 |
| SQL Server Reporting Services (SSRS) | 提供报告生成和数据可视化功能,支持多种报告格式和交互式报表。 | |
| R Services | 最早在Server 2016 中提供机器学习功能,支持 Python 和 R 语言的脚本执行,用于数据分析和预测。 |
1.1.3 SQL Server 版本
SQL Server 提供四种主要版本,每个版本提供不同的服务和工具组合。其中两个版本可以免费使用:
| 版本名称 | 用途描述 | 特性与限制 |
|---|---|---|
| SQL Server Developer Edition | 用于数据库开发和测试目的,适合开发人员构建和测试应用程序。 | - 包含 SQL Server 的所有功能 - 仅限于开发和测试环境,不能用于生产环境 - 免费使用 |
| SQL Server Enterprise Edition | 适用于大型企业级应用,提供高性能、高可用性和高级功能。 | - 支持无限虚拟化(需 Software Assurance 许可) - 支持高可用性功能(如 Always On) - 支持高级分析和数据仓库功能 - 许可费用较高 |
| SQL Server Standard Edition | 提供 Enterprise Edition中基本的数据管理和商业智能功能 适用于中等规模的应用程序 | - 提供基本的数据库功能 - 对处理器核心数量和内存配置有限制 - 适合部门级和小型组织 - 许可费用低于 Enterprise Edition |
| SQL Server Express Edition | 适用于小型数据库应用,存储容量不超过 10 GB。 | 免费使用 - 数据库大小限制为 10 GB - 适合独立软件开发商、开发人员和爱好者 - 支持轻量级部署和快速开发 |
| SQL Server Web Edition | 适用于网络托管公司和 Web 应用程序,提供可扩展性和较低成本。 | - 适合 Web 托管和 Web 应用开发 - 支持大规模 Web 应用 - 许可费用较低 - 对处理器核心数量和内存配置有限制 |
有关 SQL Server 版本的详细信息,请查看 SQL Server 2022 版本。
1.2 安装SQL Server 2022
点击链接下载 SQL Server进行下载。为了学习目的,建议下载开发者版。具体安装教程,见《Install SQL Server》。
1.3 SQL Server 示例数据库
示例数据库 BikeStores 的 SQL Server 的关系图如下。可以看出,此数据库有两个架构 sales 和 production,以及9 个表。

-
sales.stores表(商店信息表):存储信息包括有商店名称、联系信息 (如电话和电子邮件)以及地址 (包括街道、城市、州和邮政编码)。
sqlCREATE TABLE sales.stores ( store_id INT IDENTITY (1, 1) PRIMARY KEY, store_name VARCHAR (255) NOT NULL, phone VARCHAR (25), email VARCHAR (255), street VARCHAR (255), city VARCHAR (255), state VARCHAR (10), zip_code VARCHAR (5) ); -
sales.staffs表(员工信息表):存储信息包括员工名字、姓氏。它还包含电子邮件和电话等通信信息。
-
员工在
store_id列中的值指定的商店工作。一个商店可以有一名或多名员工。 -
员工向
manager_id列中的值指定的商店经理报告。如果 manager_id 中的值为 null,则员工是最高经理。 -
如果员工不再为任何商店工作,则活动列中的值将设置为零。
sqlCREATE TABLE sales.staffs ( staff_id INT IDENTITY (1, 1) PRIMARY KEY, first_name VARCHAR (50) NOT NULL, last_name VARCHAR (50) NOT NULL, email VARCHAR (255) NOT NULL UNIQUE, phone VARCHAR (25), active tinyint NOT NULL, store_id INT NOT NULL, manager_id INT, FOREIGN KEY (store_id) REFERENCES sales.stores (store_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (manager_id) REFERENCES sales.staffs (staff_id) ON DELETE NO ACTION ON UPDATE NO ACTION ); -
-
production.categories表(产品类别表):存储产品(自行车)类别信息,例如儿童自行车、 舒适自行车和电动自行车。
sqlCREATE TABLE production.categories ( category_id INT IDENTITY (1, 1) PRIMARY KEY, category_name VARCHAR (255) NOT NULL ); -
production.brands表(产品品牌表):存储产品(自行车)品牌信息,例如 Electra、Haro 和 Heller。
sqlCREATE TABLE production.brands ( brand_id INT IDENTITY (1, 1) PRIMARY KEY, brand_name VARCHAR (255) NOT NULL ); -
production.products表(产品信息表):存储信息包括产品名称、品牌、类别、型号年份和标价。
-
每个产品都属于
brand_id列指定的品牌。因此,一个品牌可能有0件或多件商品。 -
每个产品还属于由
category_id列指定的类别。此外,每个分类可能有0件或多件商品。
sqlCREATE TABLE production.products ( product_id INT IDENTITY (1, 1) PRIMARY KEY, product_name VARCHAR (255) NOT NULL, brand_id INT NOT NULL, category_id INT NOT NULL, model_year SMALLINT NOT NULL, list_price DECIMAL (10, 2) NOT NULL, FOREIGN KEY (category_id) REFERENCES production.categories (category_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (brand_id) REFERENCES production.brands (brand_id) ON DELETE CASCADE ON UPDATE CASCADE ); -
-
sales.customers表(顾客信息表):存储信息包括顾客名字、姓氏、电话、电子邮件、街道、城市、州和邮政编码。
sqlCREATE TABLE sales.customers ( customer_id INT IDENTITY (1, 1) PRIMARY KEY, first_name VARCHAR (255) NOT NULL, last_name VARCHAR (255) NOT NULL, phone VARCHAR (25), email VARCHAR (255) NOT NULL, street VARCHAR (255), city VARCHAR (50), state VARCHAR (25), zip_code VARCHAR (5) ); -
sales.orders表(销售订单表):存储包括客户、订单状态、订单日期、所需日期、发货日期等订单信息,还存储有关销售交易的创建位置 (商店) 和创建者 (员工) 的信息。
- 每个销售订单在 sales_orders 表中都有一行。
- 销售订单在
sales.order_items表中存储了一个或多个行。
sqlCREATE TABLE sales.orders ( order_id INT IDENTITY (1, 1) PRIMARY KEY, customer_id INT, order_status tinyint NOT NULL, -- Order status: 1 = Pending; 2 = Processing; 3 = Rejected; 4 = Completed order_date DATE NOT NULL, required_date DATE NOT NULL, shipped_date DATE, store_id INT NOT NULL, staff_id INT NOT NULL, FOREIGN KEY (customer_id) REFERENCES sales.customers (customer_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (store_id) REFERENCES sales.stores (store_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (staff_id) REFERENCES sales.staffs (staff_id) ON DELETE NO ACTION ON UPDATE NO ACTION ); -
sales.order_items表(销售明细表) :存储销售订单的明细信息,每个行都属于由
order_id列指定的销售订单。销售订单行包括 product、order quantity、标价和 discount。sqlCREATE TABLE sales.order_items( order_id INT, item_id INT, product_id INT NOT NULL, quantity INT NOT NULL, list_price DECIMAL (10, 2) NOT NULL, discount DECIMAL (4, 2) NOT NULL DEFAULT 0, PRIMARY KEY (order_id, item_id), FOREIGN KEY (order_id) REFERENCES sales.orders (order_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (product_id) REFERENCES production.products (product_id) ON DELETE CASCADE ON UPDATE CASCADE ); -
production.stocks表(库存表):存储库存信息,即特定商店中特定产品的数量。
sqlCREATE TABLE production.stocks ( store_id INT, product_id INT, quantity INT, PRIMARY KEY (store_id, product_id), FOREIGN KEY (store_id) REFERENCES sales.stores (store_id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (product_id) REFERENCES production.products (product_id) ON DELETE CASCADE ON UPDATE CASCADE );
1.4 加载示例数据库
下载并解压示例数据库 文件(zip格式),将得到三个 SQL 脚本文件:
BikeStores Sample Database - create objects.sql: 此文件用于创建数据库对象,包括 Schema 和 Tables。BikeStores Sample Database - load data.sql: 此文件用于将数据插入表中BikeStores Sample Database - drop all objects.sql:此文件用于从 sample 数据库中删除 tables 及其架构。当您想要刷新示例数据库时,它非常有用。
现在,让我们创建一个数据库,创建架构和表,并加载示例数据。
-
连接SQL Server :(1) 选择服务器名称,(2) 输入用户和 (3) 密码,以及 (4) 单击 Connect 按钮。

-
新建数据库 :右键单击 Object Explorer 中的 Databases 节点,然后选择 New Database... 菜单项。然后(1) 输入数据库名称 作为 BikeStores,以及 (2) 单击确定 按钮以创建新数据库。

如果一切正常,您将看到数据库 BikeStores 出现在 Databases 节点下,如下面的屏幕截图所示:
-
打开数据库创建脚本 :从 File 菜单中,选择 Open > File 菜单项,选择 BikeStores Sample Database -- create objects.sql 文件, 单击 Open 按钮。

-
执行数据库创建脚本 :单击 Execute 按钮以执行 SQL 脚本

您应该会看到以下结果,指示查询已成功执行。如果展开 BikeStores > 表 ,您将看到如下所示的架构及表的创建方式:

-
加载数据库数据 :打开BikeStores Sample Database - load data.sql 文件,然后单击 Execute 按钮将数据加载到表中。

您应该会看到以下消息,指示脚本中的所有语句都已成功执行。
1.5 SQL Server常用语句概览
1. 基础查询
| 基础查询 | 查询语句 | 说明 | 基础查询 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 查询数据 | SELECT | 从单表中查询数据。 | 限制返回行数 | SELECT TOP | 限制查询返回的行数或百分比。 |
| 限制返回行数 | OFFSET FETCH | 限制查询返回的行数,常用于分页。 | 列/表别名 | Column & table aliases | 使用列别名表别名提高查询的可读性。 |
| 返回唯一值 | DISTINCT | 返回表中列的唯一值,去除重复行。 | 排序数据 | ORDER BY | 根据指定的列对结果集进行排序。 |
2. 数据筛选
| 数据筛选 | 查询语句 | 说明 | 数据筛选 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 筛选数据 | WHERE | 根据条件筛选数据。 | 组合条件 | AND | 组合布尔表达式,所有都为真才返回真。 |
| 组合条件 | OR | 组合布尔表达式,只要一个为真就返回真。 | 匹配列表值 | IN | 检查值是否匹配列表中的任意值或子查询返回的值。 |
| 范围测试 | BETWEEN | 检查值是否在指定范围内。 | 模糊匹配 | LIKE | 检查字符串是否符合指定的模式。 |
| IS NULL | IS NULL | 检查列值是否为NULL。 | EXISTS | EXISTS | 检查子查询是否返回行。 |
3. 分组聚合
| 分组聚合 | 查询语句 | 说明 | 分组聚合 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 分组数据 | GROUP BY | 根据指定的列对结果集进行分组。 | |||
| 筛选分组 | HAVING | 对分组后的结果进行筛选。 | 生成分组集 | GROUPING SETS | 生成多个分组集。 |
| 生成多维分组 | CUBE | 生成所有可能的分组组合。 | 生成分层分组 | ROLLUP | 生成分层分组,假设输入列之间存在层次关系。 |
4. 数据操作 (DML)
| 数据操作 | 查询语句 | 说明 | 数据操作 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 插入数据 | INSERT | 向表中插入一行。 | 插入多行 | INSERT multiple rows | 使用单个INSERT语句向表中插入多行。 |
| 插入查询结果 | INSERT INTO SELECT | 将查询结果插入表中。 | 更新数据 | UPDATE | 修改表中的现有值。 |
| 更新连接 | UPDATE JOIN | 使用JOIN子句根据另一表中的值更新表中的值。 | 删除数据 | DELETE | 删除表中的一行或多行。 |
| 合并操作 | MERGE | 使用单条语句执行插入、更新和删除的组合操作。 | 清空表 | TRUNCATE TABLE | 快速删除表中所有数据。 |
| 查找重复值 | Find duplicates | 查找表中一个或多个列的重复值。 | 删除重复值 | Delete duplicates | 描述如何从表中删除重复行。 |
5. 表连接
| 表连接 | 查询语句 | 说明 | 表连接 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 内连接 | INNER JOIN | 选择两个表中匹配的行。 | 左连接 | LEFT JOIN | 返回左表的所有行,以及右表中匹配的行。如果没有匹配,则右表的列值为NULL。 |
| 右连接 | RIGHT JOIN | 返回右表的所有行,以及左表中匹配的行。如果没有匹配,则左表的列值为NULL。 | 全外连接 | FULL OUTER JOIN | 返回两个表中所有匹配和不匹配的行。 |
| 交叉连接 | CROSS JOIN | 创建两个表的笛卡尔积。 | 自连接 | SELF JOIN | 在同一表内进行连接,用于查询层次化数据或比较表内的行。 |
| 内连接函数 | CROSS APPLY | 将表与表值函数或相关子查询进行内连接。 | 左连接函数 | OUTER APPLY | 将表与表值函数或相关子查询进行左连接。 |
6. 高级查询
| 高级查询 | 查询语句 | 说明 | 高级查询 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 子查询 | Subquery | 在SELECT、INSERT、UPDATE或DELETE语句中嵌套的查询。 | 相关子查询 | Correlated Subquery | 依赖于外部查询的子查询。 |
| 比较任意值 | ANY | 将值与子查询返回的单列值集进行比较,如果匹配任意值则返回TRUE。 | 比较所有值 | ALL | 将值与子查询返回的单列值集进行比较,如果匹配所有值则返回TRUE。 |
| 公共表表达式 | CTE | 使用公共表表达式使复杂查询更易读。 | 递归查询 | Recursive CTE | 使用递归CTE查询层次化数据。 |
| 行转列 | PIVOT | 将行转换为列。 | 列转行 | UNPIVOT | 将列转换为行。 |
| 添加条件逻辑 | CASE | 使用简单和搜索的CASE表达式在SQL查询中添加if-else逻辑。 | 处理NULL值 | COALESCE | 使用COALESCE表达式有效处理NULL值。 |
| 返回NULL条件 | NULLIF | 如果两个参数相等则返回NULL,否则返回第一个参数。 | 合并结果集 | UNION | 将两个或多个查询的结果集合并为一个结果集。 |
| 求交集 | INTERSECT | 返回两个或多个查询结果集的交集。 | 求差集 | EXCEPT | 返回两个输入查询结果集的差集。 |
7. 数据定义 (DDL)
| 数据定义 | 查询语句 | 说明 | 数据定义 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 创建数据库 | CREATE DATABASE | 在SQL Server实例中创建新数据库。 | 删除数据库 | DROP DATABASE | 删除现有数据库。 |
| 创建架构 | CREATE SCHEMA | 在数据库中创建新架构。 | 修改架构 | ALTER SCHEMA | 在同一数据库内将安全对象从一个架构转移到另一个架构。 |
| 删除架构 | DROP SCHEMA | 从数据库中删除架构。 | 创建表 | CREATE TABLE | 在数据库特定架构中创建新表。 |
| 身份列 | Identity column | 使用IDENTITY属性为表创建身份列。 | 序列 | Sequence | 根据规范生成一系列数值。 |
| 添加列 | ALTER TABLE ADD column | 向表中添加一个或多个列。 | 修改列定义 | ALTER TABLE ALTER COLUMN | 修改表中现有列的定义。 |
| 删除列 | ALTER TABLE DROP COLUMN | 从表中删除一个或多个列。 | 计算列 | Computed columns | 在多个查询中重用计算逻辑。 |
| 删除表 | DROP TABLE | 从数据库中删除表。 | 清空表 | TRUNCATE TABLE | 快速删除表中所有数据。 |
| 查询创建表 | SELECT INTO | 创建表并插入查询结果。 | 重命名表 | Rename a table | 将表重命名为新的名称。 |
| 临时表 | Temporary tables | 用于存储过程或数据库会话中临时数据。 | 同义词 | Synonym | 为数据库对象创建同义词。 |
| 创建索引 | CREATE INDEX | 在表上创建索引以提高查询性能。 | 删除索引 | DROP INDEX | 删除表上的索引。 |
| 创建视图 | CREATE VIEW | 创建基于查询的虚拟表。 | 修改视图 | ALTER VIEW | 修改现有视图的定义。 |
| 删除视图 | DROP VIEW | 删除视图。 | 创建存储过程 | CREATE PROCEDURE | 创建存储过程。 |
| 修改存储过程 | ALTER PROCEDURE | 修改存储过程。 | 删除存储过程 | DROP PROCEDURE | 删除存储过程。 |
| 创建函数 | CREATE FUNCTION | 创建用户定义函数。 | 修改函数 | ALTER FUNCTION | 修改用户定义函数。 |
| 删除函数 | DROP FUNCTION | 删除用户定义函数。 | 创建触发器 | CREATE TRIGGER | 创建触发器。 |
| 修改触发器 | ALTER TRIGGER | 修改触发器。 | 删除触发器 | DROP TRIGGER | 删除触发器。 |
8. 数据类型
| 数据类型 | 查询语句 | 说明 | 数据类型 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 数据类型概述 | SQL Server data types | 介绍SQL Server内置数据类型。 | 位数据类型 | BIT | 在数据库中存储位数据(0、1或NULL)。 |
| 整数类型 | INT | 了解SQL Server中的各种整数类型,包括BIGINT、INT、SMALLINT和TINYINT。 | 精确数值类型 | DECIMAL | 使用DECIMAL或NUMERIC数据类型在数据库中存储精确数值。 |
| 固定长度字符 | CHAR | 在数据库中存储固定长度的非Unicode字符字符串。 | 固定长度Unicode字符 | NCHAR | 存储固定长度的Unicode字符字符串,解释CHAR和NCHAR数据类型的区别。 |
| 可变长度字符 | VARCHAR | 在数据库中存储可变长度的非Unicode字符串数据。 | 可变长度Unicode字符 | NVARCHAR | 在表中存储可变长度的Unicode字符串数据,了解VARCHAR和NVARCHAR的主要区别。 |
| 日期时间类型 | DATETIME2 | 在数据库中存储日期和时间数据。 | 日期类型 | DATE | 讨论日期数据类型以及如何在表中存储日期。 |
| 时间类型 | TIME | 使用TIME数据类型在数据库中存储时间数据。 | 带时区的日期时间 | DATETIMEOFFSET | 操作带有时区的日期时间。 |
| 唯一标识符 | GUID | 了解GUID以及如何使用NEWID()函数生成GUID值。 | XML 数据类型 | XML | 存储XML数据。 |
| JSON 数据类型 | JSON | 存储JSON数据。 |
9. 约束与完整性
| 约束与完整性 | 查询语句 | 说明 | 约束与完整性 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 主键约束 | Primary key | 解释主键概念,并展示如何使用主键约束管理表的主键。 | 外键约束 | Foreign key | 介绍外键概念,并展示如何使用FOREIGN KEY约束在两个表之间建立数据链接。 |
| 非空约束 | NOT NULL constraint | 确保列不接受NULL值。 | 唯一约束 | UNIQUE constraint | 确保表中一列或多列的数据在行之间是唯一的。 |
| 检查约束 | CHECK constraint | 添加逻辑以在将数据存储到表之前进行检查。 | 默认值约束 | DEFAULT | 为列定义默认值。 |
| 身份列 | Identity column | 使用IDENTITY属性为表创建身份列。 | 序列 | Sequence | 根据规范生成一系列数值。 |
10. 事务控制
| 事务控制 | 查询语句 | 说明 | 事务控制 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 事务处理 | Transaction | 使用BEGIN TRANSACTION、COMMIT和ROLLBACK语句显式开始事务。 | 保存点 | SAVE TRANSACTION | 在事务内设置保存点。 |
| 事务设置 | SET TRANSACTION | 设置事务属性。 | 锁机制 | LOCKING | 控制事务的锁行为。 |
11. 系统函数
| 系统函数 | 查询语句 | 说明 | 系统函数 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 聚合函数 | Aggregate Functions | 如SUM, AVG, COUNT, MIN, MAX等。 | 字符串函数 | String Functions | 如CONCAT, SUBSTRING, LEN, REPLACE等。 |
| 日期函数 | Date Functions | 如GETDATE, DATEPART, DATEDIFF, DATEADD等。 | 数学函数 | Mathematical Functions | 如ABS, ROUND, RAND, SQRT等。 |
| 系统函数 | System Functions | 如CAST, CONVERT, ISNULL, SYSTEM_USER等。 | 窗口函数 | ROW_NUMBER/RANK | 为结果集的行生成序号或排名。 |
| 偏移分析函数 | LEAD/LAG | 访问结果集中其他行的数据。 |
12. 性能优化
| 性能优化 | 查询语句 | 说明 | 性能优化 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 执行计划 | EXPLAIN PLAN | 显示SQL语句的执行计划。 | 索引优化 | INDEX Tuning | 优化索引以提高查询性能。 |
| 统计信息 | STATISTICS | 管理查询优化器使用的统计信息。 | 查询提示 | QUERY HINTS | 使用提示影响查询优化器的决策。 |
| 临时表 | Temporary tables | 用于存储过程或数据库会话中临时数据。 | 表变量 | TABLE VARIABLES | 使用表变量存储临时结果集。 |
13. 安全管理
| 安全管理 | 查询语句 | 说明 | 安全管理 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 创建登录账号 | CREATE LOGIN | 创建服务器级别的登录账号。 | 修改登录账号 | ALTER LOGIN | 修改登录账号属性。 |
| 删除登录账号 | DROP LOGIN | 删除登录账号。 | 创建数据库用户 | CREATE USER | 创建数据库用户。 |
| 修改数据库用户 | ALTER USER | 修改数据库用户。 | 删除数据库用户 | DROP USER | 删除数据库用户。 |
| 授权 | GRANT | 授予权限。 | 撤销权限 | REVOKE | 撤销权限。 |
| 角色管理 | ROLES | 管理数据库角色。 | 数据加密 | ENCRYPTION | 加密数据。 |
| 审计 | AUDITING | 设置审计以跟踪数据库活动。 |
14. 维护操作
| 维护操作 | 查询语句 | 说明 | 维护操作 | 查询语句 | 说明 |
|---|---|---|---|---|---|
| 备份数据库 | BACKUP DATABASE | 备份整个数据库。 | 恢复数据库 | RESTORE DATABASE | 从备份恢复数据库。 |
| 数据库控制台命令 | DBCC | 运行数据库控制台命令。 | 恢复模式 | RECOVERY MODELS | 设置数据库的恢复模式。 |
| 索引重建 | REINDEX | 重建表索引以提高性能。 | 更新统计信息 | UPDATE STATISTICS | 更新查询优化器使用的统计信息。 |
二、基础查询语句
2.1 SELECT(查询)
2.1.1 SQL Server 表的基本概念
在 SQL Server 中,表是存储数据的基本对象,以行和列的形式组织数据。每一行代表表中的一条记录,每一列代表记录中的一个字段。例如,一个名为 customers 的表可能包含客户 ID、名字、姓氏、电话、电子邮件和地址等字段。

SQL Server 使用 schema(架构) 来逻辑地组织表和其他数据库对象。例如, BikeStores 示例数据库可能包含两个架构:sales 和 production。sales 架构包含所有与销售相关的表,而 production 架构则包含所有与生产相关的表。
2.1.2 查询指定列或所有列
要从表中检索数据,需要使用 SELECT 语句,其基本语法如下:
sql
SELECT
select_list
FROM
schema_name.table_name;select_list:一个由逗号分隔的列名列表,用于指定要查询的列。schema_name.table_name:用于指定表的架构和名称。
SQL Server 在处理 SELECT 语句时,会先处理 FROM 子句,然后是 SELECT 子句,尽管 SELECT 子句在语法中位于 FROM 子句之前。下面使用示例数据库中的 customers 表进行演示。

-
查询指定列 :以下查询语句用于检索所有客户的姓氏和名字, 查询结果通常称为 结果集:
sqlSELECT first_name, last_name email FROM sales.customers;
-
查询所有列 :1) 显式列出所有列名 2)使用
SELECT *作为快捷方式:sqlSELECT * FROM sales.customers;
在生产环境中不建议使用 SELECT *,因为它会检索所有列,包括应用程序不需要的额外数据,降低查询性能。此外,如果表中新增列,SELECT * 会返回这些新列,可能导致应用程序出现意外行为。
2.1.3 扩展功能(过滤行、排序行、分组行和过滤分组)
SELECT 语句还支持一些扩展功能,这些功能通过以下子句实现:
| 子句 | 功能描述 | 子句 | 功能描述 |
|---|---|---|---|
WHERE |
根据条件过滤结果集中的行 | ORDER BY |
按一个或多个列对结果集进行排序 |
GROUP BY |
将查询结果按列分组 | HAVING |
对分组后的结果进行过滤 |
-
WHERE 子句过滤行 :查找位于加利福尼亚州(
CA)的客户,此时SQL Server 的处理顺序为:
 sql
sqlSELECT * FROM sales.customers WHERE state = 'CA';
-
ORDER BY 子句排序行 :按客户名对加利福尼亚州的客户进行排序,此时SQL Server处理顺序为:
 sql
sqlSELECT * FROM sales.customers WHERE state = 'CA' ORDER BY first_name;
-
GROUP BY 子句分组 :返回加利福尼亚州所有城市的客户数量,此时SQL Server 的处理顺序为:
 sql
sqlSELECT city, COUNT(*) FROM sales.customers WHERE state = 'CA' GROUP BY city ORDER BY city;
-
HAVING 子句过滤分组:查找加利福尼亚州中客户数量超过 10 个的城市
FROM WHERE GROUP BY HAVING SELECT ORDER BY
sqlSELECT city, COUNT(*) FROM sales.customers WHERE state = 'CA' GROUP BY city HAVING COUNT(*) > 10 ORDER BY city;
2.2 ORDER BY(排序)
ORDER BY 子句是 SELECT 语句的一个可选部分,作用是根据指定的列或表达式对查询结果进行排序。其基本语法如下:
sql
SELECT
select_list
FROM
table_name
ORDER BY
column_name | expression [ASC | DESC];column_name或expression:指定要排序的列或表达式,必须是select 列表中的任一列或 FROM 子句中指定的表中定义的列ASC或DESC:指定排序顺序。ASC表示按升序排序(默认值),DESC表示按降序排序。- 如果使用多个列, 则
ORDER BY子句将首先按第一列对行进行排序,然后按第二列对已排序的行进行排序,依此类推。 - SQL Server 将
NULL视为最小值,即排序后默认将 NULL 放在其他值之前。 - 在处理具有
ORDER BY子句的SELECT语句时,SQL Server 最后处理ORDER BY子句。
2.2.1 按select 列表中的列进行排序
以下示例按城市(city)降序排序,按名字(first_name)升序排序:
sql
SELECT
city,
first_name,
last_name
FROM
sales.customers
ORDER BY
city DESC,
first_name ASC;
SQL Server 允许您根据选择列表中显示的列的序号位置,对结果集进行排序:
sql
SELECT
first_name,
last_name
FROM
sales.customers
ORDER BY
1,
2;在此示例中,ORDER BY 子句之后的1和2分别表示 first_name 列和 last_name 列。虽然这种方式在技术上是可行的,但不推荐使用,因为列的序号可能会因查询的修改而发生变化。建议始终显式指定列名。
2.2.2 按FROM表中的列排序
以下示例按 state 列排序,尽管 state 列未出现在 SELECT 列表中,但只要 state 列在表中定义,这种排序方式是合法的。
sql
SELECT
city,
first_name,
last_name
FROM
sales.customers
ORDER BY
state;
2.2.3 按表达式排序
ORDER BY 子句支持使用表达式作为排序依据,比如按名字长度进行降序排序:
sql
SELECT
first_name,
last_name
FROM
sales.customers
ORDER BY
LEN(first_name) DESC;
2.2.4 OFFSET FETCH 子句
OFFSET 和 FETCH 子句是 SQL Server 2012 及更高版本中引入的功能,用于控制 ORDER BY 子句结果的行数。它们的语法如下:
sql
ORDER BY column_list [ASC | DESC]
OFFSET offset_row_count {ROW | ROWS}
FETCH {FIRST | NEXT} fetch_row_count {ROW | ROWS} ONLY;OFFSET子句(必选) :指定在返回结果之前跳过的行数。offset_row_count可以是一个常量、变量或参数,值必须大于或等于零。FETCH子句(可选) :指定在处理完OFFSET子句后返回的行数。fetch_row_count可以是一个常量、变量或标量,值必须大于或等于一。FIRST和NEXT是同义词,ROW和ROWS也可以互换使用。
OFFSET和FETCH子句必须与ORDER BY子句一起使用,否则会报错。
下图说明了 OFFSET 和 FETCH 子句,与 TOP 子句相比,OFFSET 和 FETCH 子句更适合实现查询分页解决方案。

-
基础示例 :以下示例从
products表中检索所有产品,并按价格和名称排序。如果需要跳过前 10 行,并返回接下来的 10 行,可以同时使用OFFSET和FETCH子句:sqlSELECT product_name, list_price FROM production.products ORDER BY list_price, product_name OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
-
获取前 N 行:以下查询获取价格最高的 10 个产品。该查询首先按价格降序排序,然后跳过 0 行(即不跳过任何行),最后返回前 10 行。
sqlSELECT product_name, list_price FROM production.products ORDER BY list_price DESC, product_name OFFSET 0 ROWS FETCH FIRST 10 ROWS ONLY;
TOP 只能返回前 N 行,OFFSET FETCH 子句可以直接跳过前面的行,返回指定范围的数据,所以更加灵活,非常适合实现分页查询。在处理大数据量时,它能减少数据传输,提升查询性能。
2.3 TOP(返回前N行)
SELECT TOP 子句允许用户限制查询返回的行数或行的百分比。由于表中存储的行的顺序是未指定的,因此在使用 SELECT TOP 时,建议始终结合 ORDER BY 子句一起使用,以确保返回的是按指定顺序排列的前 N 行。SELECT TOP 的基本语法如下:
sql
SELECT TOP (expression) [PERCENT]
[WITH TIES]
FROM
table_name
ORDER BY
column_name;-
expression:指定要返回的行数或行的百分比。- 常量:直接指定一个整数,表示要返回的行数。例如,TOP 10 表示返回前 10 行。
- 表达式:可以是一个变量或计算表达式。例如,TOP (@RowCount) 或 TOP (10 * 2)。
- 百分比 :如果使用
PERCENT,则表达式会被评估为浮点值。例如,TOP 10 PERCENT 表示返回结果集前 10% 的行,最终结果向上取整。例如,如果计算结果为 3.21,则实际返回 4 行。
-
WITH TIES:允许返回额外的行,这些行的值与结果集中最后一行的值相同,避免遗漏数据。 -
ORDER BY子句是必需的,因为SELECT TOP需要根据排序结果来确定返回的行。
-
使用常量值限制返回的行数,并使用
WITH TIES返回额外行sql-- 返回价格最高的 3 个产品,允许返回额外行 SELECT TOP 3 WITH TIES product_name, list_price FROM production.products ORDER BY list_price DESC;
-
返回指定百分比的行
sql-- 返回价格最高的 1% 的产品 SELECT TOP 1 PERCENT product_name, list_price FROM production.products ORDER BY list_price DESC;
2.4 SELECT DISTINCT(查询去重)
2.4.1 基础用法
DISTINCT 的主要功能是从查询结果中返回唯一的行,去除重复的记录,其语法如下:
sql
SELECT DISTINCT
column_name1,
column_name2 ,
...
FROM
table_name;- DISTINCT 作用于 SELECT 列表中的所有列,返回唯一组合的行。
- 如果列中包含 NULL 值,DISTINCT 会将所有 NULL 视为相同的值,仅保留一个。
- DISTINCT 不能与聚合函数直接结合使用。
-
单列去重:对查询结果中的城市列进行去重。
sqlSELECT DISTINCT city FROM sales.customers ORDER BY city;
-
多列查询:返回客户的所在城市和州的所有唯一值组合。
sqlSELECT city, state FROM sales.customers ORDER BY city, state;
-
NULL 值处理 :当我们查询客户的电话号码时,如果某些客户的电话号码为
NULL,结果集中只返回一个NULL:sqlSELECT DISTINCT phone FROM sales.customers ORDER BY phone;
2.4.2 DISTINCT vs. GROUP BY
GROUP BY 也可以用于去除重复行。例如,以下查询使用 GROUP BY 返回唯一的 city、state 和 zip_code:
sql
SELECT city, state, zip_code
FROM sales.customers
GROUP BY city, state, zip_code
ORDER BY city, state, zip_code;
这与以下使用 SELECT DISTINCT 的查询等效:
sql
SELECT
DISTINCT city, state, zip_code
FROM
sales.customers;然而,当需要对分组后的数据应用聚合函数时,应使用 GROUP BY。例如,如果我们希望统计每个城市的客户数量,可以使用以下查询:
sql
SELECT city, COUNT(*)
FROM sales.customers
GROUP BY city;- DISTINCT:如果仅需去除重复行,不需要进行分组计算,应使用 DISTINCT,其语法简单,容易理解。
- GROUP BY:如果需要对数据进行分组计算,应使用 GROUP BY,它可以与聚合函数结合使用,支持更复杂的查询需求。虽然 GROUP BY 也可以去除重复行,但不是它的主要作用。
2.5 列别名与表别名
- 通过列别名,为查询结果中的列赋予更具意义的名称,提高结果的可读性。
- 通过表别名,简化复杂的多表查询语句,提高查询的可读性和易维护性。
2.5.1 列别名(Column Alias)
在使用 SELECT 语句查询数据时,SQL Server 默认使用列名作为输出结果的列标题。当我们需要对列进行更复杂的操作(如拼接字符串)时,查询返回的列标题为 (No column name)。例如:
sql
SELECT
first_name + ' ' + last_name
FROM
sales.customers
ORDER BY
first_name;
我们可以使用列别名(Column Alias)来设置查询结果的列标题。列别名的语法如下:
sql
column_name | expression AS column_alias或者省略 AS 关键字:
sql
column_name | expression column_alias例如为拼接后的full name列赋予一个更直观的别名:
sql
SELECT
first_name + ' ' + last_name AS full_name
FROM
sales.customers
ORDER BY
first_name;如果列别名中包含空格,需要用引号将其括起来:
sql
SELECT
first_name + ' ' + last_name AS 'Full Name'
FROM
sales.customers
ORDER BY
first_name;
列别名不仅可以用于简单的列重命名,还可以在 ORDER BY 子句中使用。例如:
sql
SELECT
category_name 'Product Category'
FROM
production.categories
ORDER BY
category_name;或者:
sql
...
ORDER BY
'Product Category';SQL Server 在处理
ORDER BY子句时会优先于SELECT子句,因此可以在ORDER BY中直接使用列别名。
2.5.2 表别名(Table Alias)
表别名(Table Alias)是为表指定的临时名称,通常用于简化复杂的查询语句,尤其是在涉及多表连接或多次引用同一表时。表别名的语法如下:
sql
table_name AS table_alias或者省略 AS 关键字:
sql
table_name table_alias例如,在以下查询中,customers 和 orders 表都包含名为 customer_id 的列,因此需要通过引用表名来区分它们:
sql
SELECT
sales.customers.customer_id,
first_name,
last_name,
order_id
FROM
sales.customers
INNER JOIN sales.orders ON sales.orders.customer_id = sales.customers.customer_id;
此查询的可读性较差,且表名重复较多。通过使用表别名,可以显著简化查询:
sql
SELECT
c.customer_id,
first_name,
last_name,
order_id
FROM
sales.customers c -- 令sales.customers表别名为c
INNER JOIN sales.orders o ON o.customer_id = c.customer_id; 在上述查询中,c 是 sales.customers 表的别名,o 是 sales.orders 表的别名。使用表别名后,查询语句更加简洁易读。需要注意的是,一旦为表指定了别名,必须使用别名来引用表中的列,否则 SQL Server 会报错。
三、数据筛选
3.1 NULL与与 IS NUL
- NULL 用于表示数据的缺失或未知状态。
- 在 SQL Server 中,逻辑表达式的结果可能是 TRUE、FALSE 或 UNKNOWN。
- 不能使用等号或不等号来比较 NULL,而应使用 IS NULL 和 IS NOT NULL 运算符。IS NULL 用于检查一个值是否为 NULL,而 IS NOT NULL 用于检查一个值是否不为 NULL。
3.1.1 三值逻辑
在数据库中,NULL 用于表示缺失的数据值。例如,在记录客户信息时,如果客户的电子邮件地址未知,可以在数据库中将其记录为 NULL。NULL 不是一个具体的值,而是表示数据的缺失或未知状态。
在 SQL Server 中,逻辑表达式的结果不仅仅是 TRUE 或 FALSE,还可能是一个特殊的值 UNKNOWN。当逻辑表达式中包含 NULL 时,表达式的结果可能是 UNKNOWN:
sql
NULL = 0; -- 结果为 UNKNOWN
NULL <> 0; -- 结果为 UNKNOWN
NULL > 0; -- 结果为 UNKNOWN
NULL = NULL; -- 结果为 UNKNOWNNULL 不等于任何值,包括它自己。这意味着 NULL 不能与任何值进行比较,因此不能直接使用等号或不等号来判断一个值是否为 NULL。例如,假设我们希望检索出 customers 表中所有没有记录电话号码的客户的信息 ,可能会这么写:
sql
SELECT
customer_id,
first_name,
last_name,
phone
FROM
sales.customers
WHERE
phone = NULL
ORDER BY
first_name,
last_name;然而,这个查询不会返回任何结果,因为 phone = NULL 的结果是 UNKNOWN,而不是 TRUE。
3.1.2 IS NULL与IS NOT NULL
在 SQL Server 中,如果要检查一个值是否为 NULL,则应该使用IS NULL 运算符。以上查询正确的实现方式是:
sql
SELECT
customer_id,
first_name,
last_name,
phone
FROM
sales.customers
WHERE
phone IS NULL
ORDER BY
first_name,
last_name;
与之对应的,IS NOT NULL 运算符用于检查一个值是否不为 NULL。例如,如果我们希望查询有电话号码的客户,可以使用以下查询:
sql
...
WHERE
phone IS NOT NULL
... 
3.2 WHERE (过滤)
WHERE 子句用于在 SELECT 查询中过滤数据,仅返回满足指定条件的行。其基本语法如下:
sql
SELECT
select_list
FROM
table_name
WHERE
search_condition;search_condition是一个逻辑表达式,可以是单个条件或多个条件的组合。在SQL中,逻辑表达式也被称为谓词。- SQL Server 使用三值逻辑来评估逻辑表达式,结果可以是
TRUE、FALSE或UNKNOWN。只有当search_condition的结果为TRUE时,对应的行才会被返回。
-
等值条件:返回所有分类 ID 为 1 的产品,并按列表价格降序排列。
sqlSELECT product_id, product_name, category_id, model_year, list_price FROM production.products WHERE category_id = 1 ORDER BY list_price DESC;
-
使用比较运算符:筛选出列表价格大于 300 且型号年份为 2018 的产品:
sqlWHERE list_price > 300 AND model_year = 2018
3.3 AND运算符
-
使用多个 AND 运算符:筛选出分类 ID 为 1、列表价格大于 400 且品牌 ID 为 1 的产品
sqlWHERE category_id = 1 AND model_year = 2018
-
结合使用其它逻辑运算符 :在复杂的逻辑表达式中,AND 的优先级高于 OR,可以通过括号改变运算顺序。
sqlSELECT * FROM production.products WHERE brand_id = 1 OR brand_id = 2 AND list_price > 1000 ORDER BY brand_id DESC;
由于 AND 运算符的优先级高于 OR,因此该查询会先计算 brand_id = 2 AND list_price > 1000,然后与 brand_id = 1 进行 OR 运算。如果需要筛选出品牌 ID 为 1 或 2 且列表价格大于 1000 的产品,需要通过括号改变运算顺序:
sqlSELECT * FROM production.products WHERE (brand_id = 1 OR brand_id = 2) AND list_price > 1000 ORDER BY brand_id;
3.4 OR 运算符
OR 运算符允许将两个布尔表达式组合在一起,以下是 OR 运算符的真值表:
| TRUE | FALSE | UNKNOWN | |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE | UNKNOWN |
| UNKNOWN | TRUE | UNKNOWN | UNKNOWN |
以下查询使用 OR 运算符,筛选出列表价格小于 200 或大于 6000 的产品:
sql
SELECT product_name, list_price
FROM production.products
WHERE list_price < 200
OR list_price > 6000
ORDER BY list_price;
使用多个 OR 运算符时,可以使用 IN 运算符来简化查询:
sql
SELECT product_name, brand_id
FROM production.products
WHERE brand_id = 1
OR brand_id = 2
OR brand_id = 4
ORDER BY brand_id DESC;以上查询筛选出品牌 ID 为 1、2 或 4 的产品,这等价于:
sql
SELECT product_name, brand_id
FROM production.products
WHERE brand_id IN (1, 2, 4)
ORDER BY brand_id DESC;
3.5 IN 与NOT IN(列表匹配)
3.5.1 基础语法与示例
IN 运算符用于检查某个值是否匹配列表或子查询返回的任意值。它提供了一种简洁的方式来替代多个 OR 运算符,使查询更加高效和易读,其基本语法如下:
sql
column | expression IN (v1, v2, v3, ...)column | expression:需要检查的列或表达式。(v1, v2, v3, ...):一个值列表,所有值的类型必须与列或表达式的类型一致。
以上表达式等价于:
sql
column = v1 OR column = v2 OR column = v3 ...如果需要否定 IN 运算符,可以使用 NOT IN:
sql
column | expression NOT IN (v1, v2, v3, ...)需要注意的是,如果列表中包含 NULL,则 IN 或 NOT IN 的结果可能为 UNKNOWN。
3.5.2 与子查询结合使用
以下查询返回store_id=1 且quantity≥ 30 的产品的 ID 列表:
sql
SELECT product_id
FROM production.stocks
WHERE
store_id = 1 AND quantity >= 30;可以将上述查询作为子查询,结合 IN 运算符来筛选产品:
sql
SELECT
product_name,
list_price
FROM
production.products
WHERE
product_id IN (
SELECT
product_id
FROM
production.stocks
WHERE
store_id = 1 AND quantity >= 30
)
ORDER BY
product_name;
在这个例子中,子查询返回了一个产品 ID 列表,外层查询根据子查询返回的 ID 列表,筛选出对应的产品名称和价格。
总结:
- 使用 IN 运算符可以检查某个值是否匹配列表或子查询返回的任意值,NOT IN作用相反;
- IN 运算符等价于多个 OR 运算符的组合,但更简洁高效。
- IN 运算符可以与子查询结合使用,实现复杂的查询逻辑。
3.6 BETWEEN 与 NOT BETWEEN (范围比较)
BETWEEN 运算符检查某个值是否在范围内,它提供了一种简洁的方式来替代多个比较运算符的组合,使查询更加高效和易读,其基本语法如下:
sql
column | expression BETWEEN start_expression AND end_expressioncolumn | expression:需要测试的列或表达式。start_expression , end_expression:定义范围的起始值和结束值。它们必须与被测试的列或表达式具有相同的数据类型。
这等价于:
sql
column | expression <= end_expression AND column | expression >= start_expression 如果需要否定 BETWEEN 的结果,可以使用 NOT BETWEEN 运算符:
sql
column | expression NOT BETWEEN start_expression AND end_expression这等价于:
sql
column | expression < start_expression OR column | expression > end_expressionBETWEEN 运算符一般用于筛选数字范围,例如筛选出列价格在 149.99 和 199.99 之间的产品:
sql
SELECT
product_id,
product_name,
list_price
FROM
production.products
WHERE
list_price BETWEEN 149.99 AND 199.99
ORDER BY
list_price;
除此之外,BETWEEN 运算符还可以筛选日期范围,比如筛选出订单日期在 2017 年 1 月 15 日和 2017 年 1 月 17 日之间的订单。
sql
SELECT
order_id,
customer_id,
order_date,
order_status
FROM
sales.orders
WHERE
order_date BETWEEN '20170115' AND '20170117'
ORDER BY
order_date;
总结:
- BETWEEN 运算符用于指定一个范围,并检查某个值是否在这个范围内。它等价于使用比较运算符 >= 和 <= 的组合。
- 使用 NOT BETWEEN 可以否定 BETWEEN 的结果。
- BETWEEN 运算符适用于数字、日期等数据类型,但要求所有参与比较的值具有相同的数据类型。
- 如果输入值中包含 NULL,则结果为 UNKNOWN
3.7 LIKE 与NOT LIKE (模糊匹配)
在 SQL Server 中,LIKE 运算符用于基于模式匹配过滤行。它广泛应用于 SELECT、UPDATE 和 DELETE 语句的 WHERE 子句中,其基本语法如下:
sql
column | expression LIKE pattern [ESCAPE escape_character]column | expression:需要测试的列或表达式。pattern:指定的模式,可以包含普通字符和通配符。ESCAPE escape_character:可选,用于指定转义字符,以便将通配符作为普通字符处理。
如果列或表达式的值与指定的模式匹配,LIKE 运算符返回 TRUE。如果需要否定匹配结果,可以使用 NOT LIKE。以下是所有支持的通配符:
| 通配符 | 说明 | 示例 | 示例说明 |
|---|---|---|---|
% |
匹配任意长度的字符序列 | a% |
匹配以字母 a 开头的任意字符串,如 apple、apricot 或 a |
_ |
匹配任意单个字符 | a_b |
匹配以 a 开头b结尾,中间有一个任意字符的字符串 如 aab 或 a1b |
[list of characters] |
匹配字符集中的任意单个字符 | [abc] |
匹配任意一个字符 a、b 或 c,如 apple 中的 a 或 banana 中的 b |
[character-character] |
匹配范围内的任意单个字符 | [a-c] |
匹配任意一个字符 a、b 或 c,如 apple 中的 a 或 banana 中的 b |
[^list of characters] |
匹配不在字符集中的任意单个字符 | [^abc] |
匹配除 a、b 和 c 之外的任意单个字符,如 dog 中的 d |
3.7.1 使用 % 通配符 或 NOT LIKE
- 筛选出 姓氏以
z开头的客户 - 筛选出姓氏以
er结尾的客户 - 筛选出姓氏以
t开头且以s结尾的客户 - 筛选出名字的第一个字符不是 A 的客户
sql
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE 'z%'
-- last_name LIKE '%er'
-- last_name LIKE 't%s'
-- first_name NOT LIKE 'A%'
ORDER BY
first_name;
3.7.2 使用 _ 通配符 或 character-character 通配符
以下查询使用 _ 通配符,筛选出姓氏的第二个字符为 u 的客户:
sql
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '_u%'
ORDER BY
first_name; 
以下查询使用 [character-character] 通配符,筛选出姓氏的第一个字符在 A 到 C 范围内的客户:
sql
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '[A-C]%'
ORDER BY
first_name;
3.7.3 使用 list of characters 通配符 或 \^character list or range 通配符
以下查询使用 list of characters 通配符,筛选出姓氏的第一个字符为 Y 或 Z 的客户:
sql
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '[YZ]%'
ORDER BY
last_name;
以下查询使用 \^character list or range 通配符,筛选出姓氏的第一个字符不在 A 到 X 范围内的客户:
sql
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name LIKE '[^A-X]%'
ORDER BY
last_name;
3.7.4 使用ESCAPE 子句定义转义字符
-
创建一个名为 sales.feedbacks 的表,用于存储客户反馈信息:
sqlCREATE TABLE sales.feedbacks ( feedback_id INT IDENTITY(1, 1) PRIMARY KEY, comment VARCHAR(255) NOT NULL ); -
向 sales.feedbacks 表中插入几条反馈数据:
sqlINSERT INTO sales.feedbacks(comment) VALUES ('Can you give me 30% discount?'), ('May I get 30USD off?'), ('Is this having 20% discount today?'); -
使用 LIKE 运算符进行模糊匹配 :假设我们需要查找包含 30% 的反馈信息。直接使用 LIKE 运算符可能会返回意外的结果,因为
%是一个通配符:sqlSELECT feedback_id, comment FROM sales.feedbacks WHERE comment LIKE '%30%';
-
使用 ESCAPE 子句解决通配符问题:为了避免 % 被当作通配符,可以使用 ESCAPE 子句指定一个转义字符。例如,使用 ! 作为转义字符:
sqlSELECT feedback_id, comment FROM sales.feedbacks WHERE comment LIKE '%30!%%' ESCAPE '!';
在此查询中,
30!%%表示匹配字符串 30%。其中!%被视为普通字符%,而不是通配符。SQL Server常用
!作为转义字符,MySQL 、PostgreSQL 和 SQLite则默认使用\。
四、分组聚合
4.1 GROUP BY:分组查询与数据汇总
4.1.1 GROUP BY 简介
GROUP BY 子句用于将查询结果按一个或多个列的值进行分组(类似于DAX中的SUMMARIZE),其基本语法如下:
sql
SELECT
select_list
FROM
table_name
GROUP BY
column_name1,
column_name2,
...;假设我们有一个 sales.orders 表,我们可以通过以下查询获取每个客户的订单年份:
sql
SELECT
customer_id,
YEAR(order_date) AS order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
ORDER BY
customer_id;
使用 GROUP BY 后,结果将按客户 ID 和订单年份进行分组,生成户 ID 和订单年份的唯一值组合
sql
SELECT
customer_id,
YEAR(order_date) AS order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR(order_date)
ORDER BY
customer_id;
从功能上讲,上述查询中的 GROUP BY 子句产生的结果与以下使用 DISTINCT 子句的查询相同:
sql
SELECT DISTINCT
customer_id,
YEAR (order_date) order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
ORDER BY
customer_id;但 GROUP BY 更常用于与聚合函数结合使用,生成汇总报告。
4.1.2 分组聚合
在实际应用中,GROUP BY 子句通常与聚合函数(如 COUNT、SUM、AVG、MIN 和 MAX)结合使用,以生成每个分组的汇总数据。
-
使用COUNT统计每个客户每年的订单数量:
sqlSELECT customer_id, YEAR(order_date) AS order_year, COUNT(order_id) AS order_placed FROM sales.orders WHERE customer_id IN (1, 2) GROUP BY customer_id, YEAR(order_date) ORDER BY customer_id;在上述查询中,
GROUP BY子句按客户 ID 和订单年份对订单进行分组,COUNT(order_id)则计算每个分组中的订单数量:

-
使用 MIN和 MAX 函数获取2018年产品的最低和最高价格 。在此示例中,
WHERE子句在GROUP BY子句之前处理,以筛选出 2018 年的产品。sqlSELECT brand_name, MIN(list_price) AS min_price, MAX(list_price) AS max_price FROM production.products p INNER JOIN production.brands b ON b.brand_id = p.brand_id WHERE model_year = 2018 GROUP BY brand_name ORDER BY brand_name;
需要注意的是,如果在 SELECT 列表中引用了未出现在 GROUP BY 子句中的列或表达式,那么这些列或表达式的值在每个分组中可能返回多个值,此时SQL Server 将报错。必须使用某个聚合函数进行处理以得到唯一值。例如,以下查询将失败:
sql
SELECT
customer_id,
YEAR (order_date) order_year,
order_status
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR (order_date)
ORDER BY
customer_id;4.1.3 HAVING子句:过滤分组数据
在 SQL Server 中,HAVING 子句通常与 GROUP BY 子句结合使用,用于根据指定条件过滤分组后的数据。HAVING 子句的语法如下:
sql
SELECT
select_list
FROM
table_name
GROUP BY
group_list
HAVING
conditions;GROUP BY子句将数据按指定列分组。HAVING子句对分组后的数据应用一个或多个条件,只有满足条件的分组才会被包含在结果中。- 由于
HAVING子句在GROUP BY之后处理,因此不能直接使用SELECT列表中的列别名引用聚合函数的结果。必须在HAVING子句中显式使用聚合函数表达式。
FROM WHERE GROUP BY HAVING SELECT ORDER BY
-
使用 COUNT函数统计每个城市的客户数量
假设我们有一个
orders表,存储了订单的客户 ID 和订单日期。以下查询使用HAVING子句查找每年至少下了两个订单的客户:sqlSELECT customer_id, YEAR(order_date) AS order_year, COUNT(order_id) AS order_count FROM sales.orders GROUP BY customer_id, YEAR(order_date) HAVING COUNT(order_id) >= 2 ORDER BY customer_id;
在这个示例中:
GROUP BY子句按客户 ID 和订单年份对订单进行分组。COUNT(order_id)计算每个客户每年下的订单数量。HAVING子句过滤出订单数量不少于 2 的客户。
-
使用 SUM函数计算订单的净价值(订单金额减去折扣) :以下查询使用
HAVING子句查找净价值大于 20,000 的销售订单:sqlSELECT order_id, SUM(quantity * list_price * (1 - discount)) AS net_value FROM sales.order_items GROUP BY order_id HAVING SUM(quantity * list_price * (1 - discount)) > 20000 ORDER BY net_value;
4.2 GROUPING SETS:自定义多个组集
GROUPING SETS 是GROUP BY的扩展功能,用于在单个查询中定义多个分组集。它允许我们一次性生成多个聚合结果,而无需多次执行查询并使用 UNION ALL 来合并结果集。通过 GROUPING SETS,可以显著提高查询效率并简化代码。
4.2.1 准备示例数据
创建一个示例表 sales.sales_summary,用于存储销售数据:
sql
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
ROUND(
SUM(quantity * i.list_price * (1 - discount)),
0
) AS sales
INTO
sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;查询此 sales.sales_summary 表:
sql
SELECT
*
FROM
sales.sales_summary
ORDER BY
brand,
category,
model_year;
4.2.2 使用GROUP BY进行分组统计
- 按品牌和类别分组,统计其销售总额:
sql
SELECT
brand,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
brand,
category
ORDER BY
brand,
category;
- 统计每个品牌的销售总额:
sql
SELECT
brand,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
brand
ORDER BY
brand;
- 统计每个类别的销售总额:
sql
SELECT
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
category
ORDER BY
category;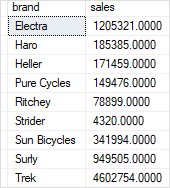
- 统计总销售额:
sql
SELECT
SUM(sales) AS sales
FROM
sales.sales_summary;
4.2.3 使用 UNION ALL 实现多分组集
为了将上述四个查询的结果合并为一个结果集,我们通常会使用 UNION ALL 操作符:
sql
SELECT
brand,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
brand,
category
UNION ALL
SELECT
brand,
NULL,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
brand
UNION ALL
SELECT
NULL,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
category
UNION ALL
SELECT
NULL,
NULL,
SUM(sales) AS sales
FROM
sales.sales_summary
ORDER BY
brand,
category;
然而,这种方法存在两个主要问题:
- 查询语句冗长,难以维护。
- 查询性能较低,因为 SQL Server 需要分别执行四个子查询并将结果集合并。
4.2.4 使用 GROUPING SETS 简化查询
GROUPING SETS 允许在单个查询中定义多个分组集,从而避免了多次执行查询和使用 UNION ALL 的开销。以下是 GROUPING SETS 的语法:
sql
SELECT
column1,
column2,
aggregate_function(column3)
FROM
table_name
GROUP BY
GROUPING SETS (
(column1, column2),
(column1),
(column2),
()
);以下是使用 GROUPING SETS 重写上述查询的示例:
sql
SELECT
brand,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
GROUPING SETS (
(brand, category),
(brand),
(category),
()
)
ORDER BY
brand,
category;查询结果与使用 UNION ALL 的结果相同,但查询语句更加简洁,查询性能也更高。
4.2.5 GROUPING 函数
GROUPING 函数用于指示 GROUP BY 子句中指定的列是否被聚合(1表示被聚合,0表示未被聚合)。以下是使用 GROUPING 函数的示例:
sql
SELECT
GROUPING(brand) AS grouping_brand,
GROUPING(category) AS grouping_category,
brand,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
GROUPING SETS (
(brand, category),
(brand),
(category),
()
)
ORDER BY
brand,
category;
grouping_brand列的值为 1 表示该行是按品牌聚合的结果。grouping_category列的值为 1 表示该行是按类别聚合的结果。
4.3 CUBE:生成多个分组集
4.3.1 CUBE VS GROUPING SETS
GROUPING SETS 允许用户自定义分组集,而CUBE 是 GROUPING SETS 的一种特殊形式,会生成所有可能的分组集 。例如,以下两个查询是等效的:
-
使用
GROUPING SETSsqlSELECT brand, category, SUM(sales) AS sales FROM sales.sales_summary GROUP BY GROUPING SETS ( (brand, category), (brand), (category), () ); -
使用
CUBE:sqlSELECT brand, category, SUM(sales) AS sales FROM sales.sales_summary GROUP BY CUBE(brand, category);
4.3.2 CUBE 语法
CUBE 也是 GROUP BY 子句的一个扩展功能,基于指定的维度列生成所有可能的分组组合,包括单个维度、多个维度的组合以及空分组集。
sql
SELECT
d1,
d2,
d3,
aggregate_function(c4)
FROM
table_name
GROUP BY
CUBE(d1, d2, d3); 在上述语法中,CUBE 会生成基于维度列 d1,d2 ,d3 的所有可能分组集。如果指定 N 个维度列,则会生成 2 N 2^N 2N个分组集。比如上一节中的CUBE(brand, category);会生成以下组合:
- 按
(brand, category)分组 - 按
(brand)分组 - 按
(category)分组 - 空分组集
(),即所有数据的总和
4.3.3 部分 CUBE
在某些情况下,我们可能不需要生成所有可能的分组集,而是希望减少分组集的数量。以下查询仅对类别进行 CUBE 操作,而品牌保持不变:
sql
SELECT
brand,
category,
SUM(sales) AS sales
FROM
sales.sales_summary
GROUP BY
brand,
CUBE(category);
在这种情况下,查询生成的分组集数量减少,仅包括:
- 按
(brand, category)分组 - 按
(brand)分组 - 按
()分组
由于是部分 CUBE,brand 始终参与分组,所以不会产生单独的(category)分组。
4.4 ROLLUP:计算分层汇总
4.4.1 ROLLUP简介
ROLLUP子句是GROUP BY子句的一个扩展,通常用于生成报表中的小计和总计。对于CUBE (d1,d2,d3)来说,会生成所有可能的分组集合(共8种),而ROLLUP(d1,d2,d3)则会根据d1 > d2 > d3的层次结构生成4种分组集合,分别是:
sql
(d1, d2, d3)
(d1, d2)
(d1)
()ROLLUP的语法如下:
sql
SELECT
d1,
d2,
d3,
aggregate_function(c4)
FROM
table_name
GROUP BY
ROLLUP (d1, d2, d3);在上述语法中,d1、d2和d3是维度列,该语句将基于d1 > d2 > d3的层次结构计算c4列的聚合值。此外,你还可以通过以下语法进行部分汇总,以减少生成的小计数量:
sql
SELECT
d1,
d2,
d3,
aggregate_function(c4)
FROM
table_name
GROUP BY
d1,
ROLLUP (d2, d3);4.4.2 ROLLUP示例
还是以4.2.1 GROUPING SETS中创建的示例表sales.sales_summary为例,原始表为:

-
分层汇总,层级结构为
brand>category,即同一品牌(父级别)中包含不同的类别(子级别)sqlSELECT brand, category, SUM (sales) sales FROM sales.sales_summary GROUP BY ROLLUP(brand, category); -
设置层次结构为category > brand,结果将有所不同。
sqlSELECT category, brand, SUM (sales) sales FROM sales.sales_summary GROUP BY ROLLUP (category, brand); -
部分汇总(只有category小计,没有总计行):
sqlSELECT brand, category, SUM (sales) sales FROM sales.sales_summary GROUP BY brand, ROLLUP (category);
