文章内容较长,放宽心,带着疑问慢慢读,总能找到你想要的答案。
如何快速定位数据存储在内存地址的位置?
先提出一个问题:如何快速定位数据存储在内存地址的位置?
聪明的你会想到使用数组 :根据首地址+单个节点存储大小 x 数组下标,便可快速计算出目标的内存地址,从而做到时间复杂度为O(1)的查找速度。但这一切都建立在物理存储空间连续的情况。
如果物理存储空间不连续 ?如何实现y=f(x),根据x参数,通过f(x)函数,快速计算出y 目标地址呢?
在HashMap中,x参数就是key,这一切的计算都是围绕key进行展开的,这些计算可以简述为以下三行代码
java
int hashCode = key.hashCode();
int hash = hashCode ^ (hashCode >>> 16);
int index = (arrLen - 1) & hasharrLen变量为数组长度,你可以把这三行代码理解为f(x),而参数x=key,计算结果为y=index,计算结果的index便是映射数组的下标 。这个映射定位函数是多对一的函数,不同的key会得到相同的数组下标值。
在 HashMap 中,f(key) = hash(key) & (arrLen - 1) 就是一个哈希映射数组索引函数 ,不同的 key 可能映射到相同的数组索引,被称为映射冲突 或桶冲突 ,但是常常被称为哈希冲突,这称呼经常让人摸不着头脑,因为它的表述并不准确。
哈希冲突和映射冲突的关系
-
哈希函数
hash(key)内部产生相同值 → 叫「哈希冲突」 -
不同哈希值映射到同一个桶 → 叫「索引冲突 」或「映射冲突」
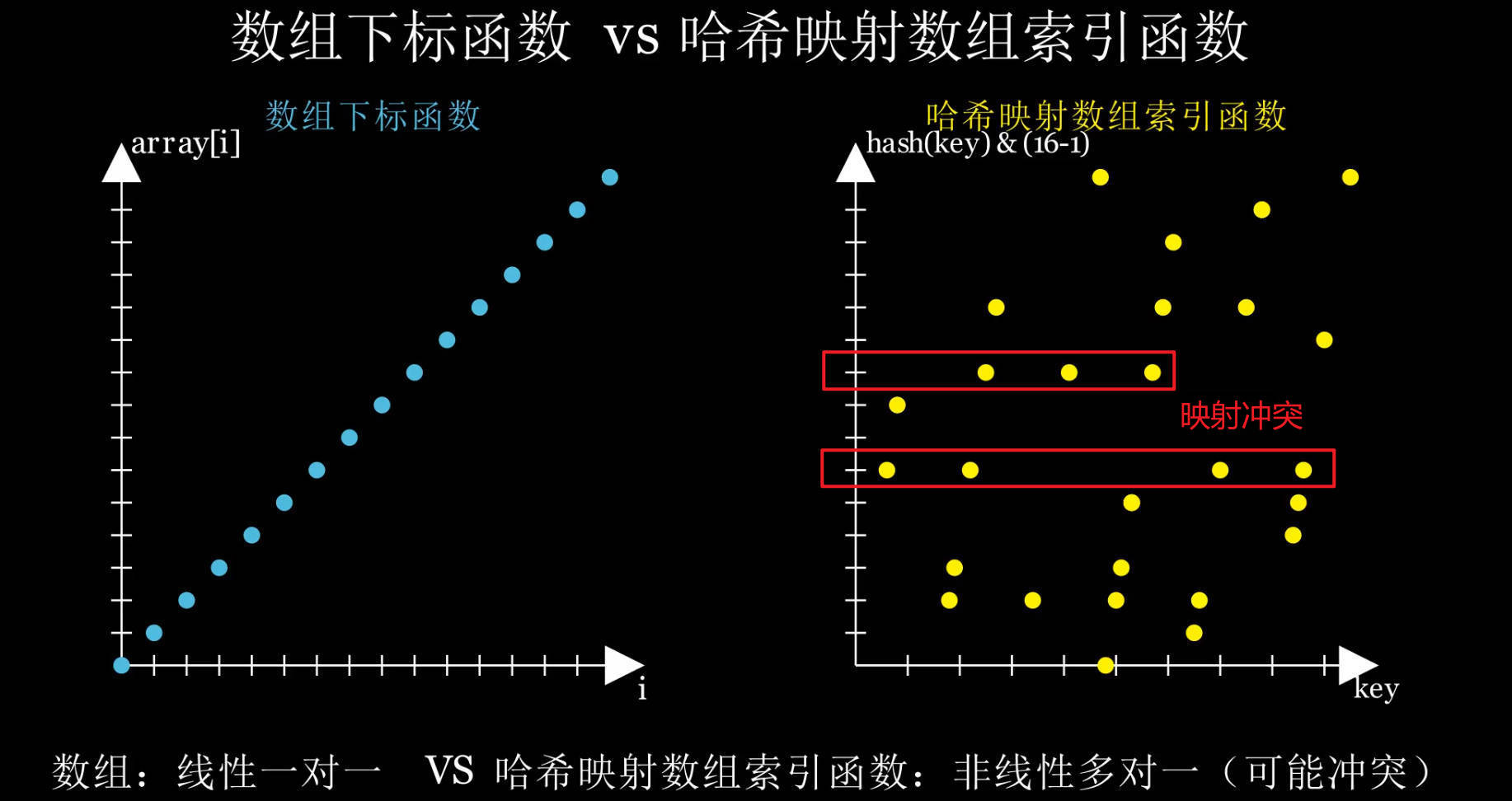
🔑 hash(key) & (arrLen - 1) 不会产生哈希值冲突,它是 哈希值到数组索引的映射 。真正冲突的是:不同 key 的哈希值,映射到相同数组索引 ------ 这才是 HashMap 要解决的冲突点。
即不同的key可能映射到相同的数组下标,这就是为什么 HashMap 需要链表或红黑树 来存储元素和处理冲突,而数组(桶)仅仅是用于存储链表头节点地址 或红黑树的根节点地址,然后再结合链表或红黑树进行检索。
对于HashMap的学习,其实主要就是学习Key值是如何解决的。
1. 前置知识
哈希(Hash),本质上就是把任意长度的输入(比如字符串、对象等)通过一个函数,映射成固定长度的"哈希值"或"哈希码"(通常是一个整数)。这个过程就像是给每个输入都贴上一个"标签",以便快速比较和查找。
1.1. 什么是哈希函数?
一种函数 H,接受任意长度的输入 x,并输出固定长度的整数(通常在 0 到 2^k-1之间)
-
映射性质
-
输入空间:可以是无限或非常大的(例如所有可能的字符串)。
-
输出空间:有限且固定(例如 32 位整数,共约 4 294 967 296 种可能)。
-
哈希函数:
h: 输入 → 输出,把大空间"压缩"到小空间。
-
-
理想特性
- 确定性:同样输入每次产生相同输出;
- 高效性:计算速度要快,适合大量数据处理;
- 均匀分布:对不同输入应尽量输出均匀分布,减少"碰撞"(不同输入映射到同一哈希值)的概率;
- 固定长度:不论输入大小,输出长度相同,便于存储和比较。
1.2. 哈希冲突(Collision)
由于输入空间远大于输出空间的原因,不同元素不可避免地"挤"到同一个标签上(鸽笼原理)。
鸽笼原理:如果有 n 个鸽子和 m 个鸽笼,且 n > m,那么至少有一个笼子要装下不止一只鸽子。
哈希冲突就是不同的输入被哈希函数映射到相同的哈希值。如果要想保存下这些冲突数据,必须要解决哈希函数必然带来的问题--哈希冲突。
解决哈希冲突常见策略
-
开放寻址:线性探测,二次探测,和双重哈希
-
闭散列:分离链接
HashMap解决哈希冲突采用的是分离链接策略。
1.3. 在Java中怎么计算哈希值
在Java中默认所有对象计算哈希值的方法都是identityHashCode(Object x)
常见的两种计算哈希值的方法:
hashCode()- 这是实例方法,且在
Object中声明为native,所有类都继承它。 - 大多数类都会重写(
override)它,以便根据类的内部状态(字段值)计算一个逻辑哈希码,比如String、List、用户自定义的实体类等。 - 这个哈希码用于
HashMap、HashSet、Hashtable等基于散列的集合,它要求:- 相等的对象(
equals返回true)必须具有相同的哈希码; - 不相等的对象哈希码越分散越好,减少冲突。
- 相等的对象(
- 这是实例方法,且在
identityHashCode(Object x)- 这是一个静态方法,不会被任何类覆盖,也不依赖于对象的
equals/hashCode重写。 - 返回"原生的"对象身份哈希------也就是
Object类刚开始提供的那个哈希值。 - 常用于调试或需要绕过用户重写的
hashCode实现,以便获得真正基于对象身份(通常是内存地址或 VM 内部标识)的哈希。
- 这是一个静态方法,不会被任何类覆盖,也不依赖于对象的
这两种计算哈希值的底层算法
在 HotSpot JVM 中, Object.hashCode()(即身份哈希)生成算法默认是基于 Marsaglia 的 Xor-Shift 伪随机数生成 ,并且使用的是线程本地 的一组 32 位状态变量。哈希算法本质就是散列算法 ,类似于MD5这种散列算法,根据内容生成固定长度的内容,对于相同的内容每次计算结果都是相同的,但是反过来是无法解码的算法。更多详细内容可以学习JVM底层。
2. 数据结构概览
数组+链表/红黑树
底层维护一个类型为 Node<K,V>[] table 的数组,每个数组元素是链表或红黑树的根节点。
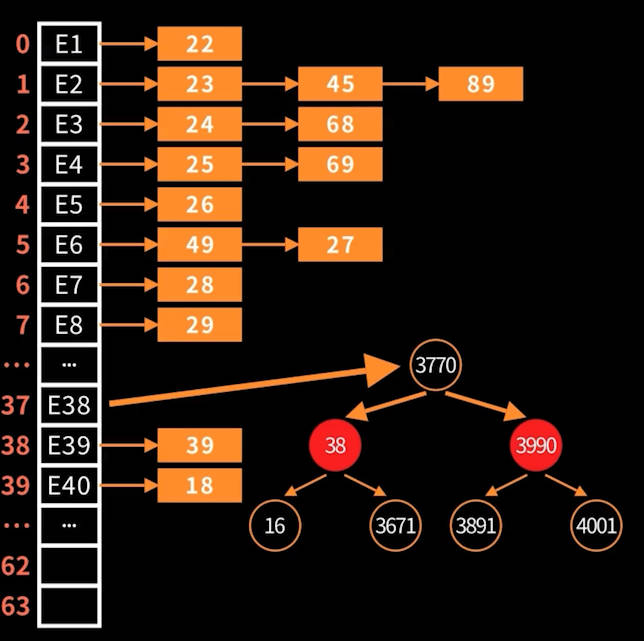
源码关键字段
java
transient Node<K,V>[] table; // 存放节点的数组
transient int size; // 当前 key-value 对数
int threshold; // 扩容阈值 = capacity × loadFactor
final float loadFactor; // 负载因子(默认 0.75)
transient int modCount; // 结构性修改次数,用于 fail-fast
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 节点数组默认初始容量16
static final int MAXIMUM_CAPACITY = 1 << 30; // 节点数组最大容量 2的30次方
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子
static final int TREEIFY_THRESHOLD = 8; // 树化阈值 8
static final int MIN_TREEIFY_CAPACITY = 64; // 树化的节点数组最小容量 64
static final int UNTREEIFY_THRESHOLD = 6; // 退树阈值 6初始容量与加载因子:
-
默认初始容量:16
-
默认加载因子:0.75
-
当
size > threshold时,触发扩容并重新分配位置。
3. 如果计算Key的存放位置?
哈希值+扰动函数+下标取模 => (h=key.hashCode())^(h>>>16) & (length-1);
扰动函数的目的是降低哈希碰撞的概率!!哈希值h的高16位和低16位做异或计算,再与数组下标做与运算。
-
异或运算:相同为0,不同为1;
-
与运算:不同为0,相同为0或1。
我们拆分开来,一点一点来掌握。
3.1. 定位数组槽位
HashMap 底层维护一个节点数组 Node<K,V>[] table,长度为 n(总是 2 的幂)。
java
int idx = (table.length - 1) & hash;n - 1的二进制形式是:例如当n = 16,n-1 = 0b1111。- 与运算
&相当于取低log₂n位,因此新扰动后的哈希hash的低位会决定落到哪个桶,比如n=16时,只会取到低位的4位。
计算例子如图 :

那么hash值是怎么计算出来的呢?
3.2. 哈希值计算
通过HashMap中的hash 函数 来实现哈希值计算,本质是使用hashCode函数计算,再对结果进行哈希值扰动,又称为哈希扰动函数 。
对象插入时,首先调用 key.hashCode(),得到一个 32 位的整型哈希值 h。为了减少高位数据丢失,HashMap 会对用户的 key.hashCode() 进一步扰动,将高 16 位与低 16 位异或,增加低位随机性,减少高位差异带来的冲突。
java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}h >>> 16:将高 16 位无符号右移到低位。h ^ (h >>> 16):将高位信息与低位异或,混合到低 16 位,降低不同hashCode()但高位相同的对象冲突概率。- 为什么右移16位?:因为hash的数据类型为
int,长度为32位的数据类型。
等价判断 如果哈希槽中已有节点(hashCode 相同或不同都可能落到同一槽),会遍历链表/树,对每个节点调用 equals 判断真正相等与否,从而保证集合中不出现重复Key。
3.3. 什么情况要重写hashCode和equals方法
在 Java 的 HashMap 中,键(key)对象并 不 是"必须"重写 hashCode() 和 equals(),但如果你希望基于对象内容而非内存地址来判断键的等价性,就 一定要 同时重写这两个方法。下面分几个方面来说明:
-
默认实现的行为
Object类中默认的equals()比较的是对象引用是否相同(==)。默认的
hashCode()通常基于对象在内存中的地址(或编译器/虚拟机内部生成的唯一标识)。因此,如果你不重写这两个方法,
HashMap会把两个内容相同但引用不同的对象当作不同的 key 来存储。 -
正确使用
HashMap的关键:hashCode/equals 协议根据 Java 规范,重写
equals()必须同时重写hashCode(),以满足以下契约:如果两个对象通过
equals()被认为是相等的,那么这两个对象的hashCode()必须相同。违反这一契约会导致在
HashMap(或其他基于哈希的集合,如HashSet)中出现查找失败、存储重复等诡异问题。 -
什么时候可以不重写?
你 故意 要基于"身份"(identity)来做 key 比较,也就是只有同一个对象引用才能对应同一个键。键对象本身就是不可变且唯一的,比如你直接使用某些单例对象或枚举类型作为 key。这时,使用默认的
equals/hashCode也是可行的。
最佳实践--推荐做法
自定义Key值对象 ,例如 Person等,需要根据内部字段来判断"逻辑相等",就应当同时重写 hashCode() 和 equals() ,可以借助 IDE 自动生成(如 IntelliJ IDEA、Eclipse)或使用 Lombok 注解(@EqualsAndHashCode)来生成相应的代码。
并且Key值对象最好是不可变的 ,比如:String类是个final类,内部数组也是被final修饰。
示例 :Person类字段被final修饰,但类不是final,还是会被继承重写,但如果有人在继承后重写了 equals/hashCode,就可能引入「不对称」或「不一致」的比较逻辑,导致在同一个 HashMap 中,基类实例和子类实例的对比出现异常。
java
public class Person {
private final String name;
private final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 重写 equals:基于 name 和 age 判断相等
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person other = (Person) o;
return age == other.age
&& Objects.equals(name, other.name);
}
// 重写 hashCode:确保相等的对象有相同哈希值
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}3.4. 哈希扰动(hash = h ^ (h >>> 16))为什么能减少冲突
-
底层定位数组槽位只用低位
javaindex = (table.length -- 1) & hash;因为
table.length是 2 的幂,length--1在二进制下像0b00...0111,所以算出来的index只看hash的低几位。 -
原始
hashCode()的低位往往不够随机比如某些类型(
String、自定义对象)算出的hashCode(),高位变化很丰富,低位却常常相似。直接取低位就会把这批看似不同的对象都落到同几个桶里,冲突多。所以在开发中,常常会重写Object的hashcode方法。 -
扰动函数把高位的信息混到低位
javastatic final int hash(Object key) { int h = key.hashCode(); return h ^ (h >>> 16); }h >>> 16:把高 16 位"搬"到低 16 位,^(异或):将这两部分交叉叠加。结果是:原来只在高位有差异的两个
hashCode()值,经过扰动后,差异也会反映到低位上。低位更多变化 使得对象更可能被分散到不同桶,冲突自然就少了。
看完这个例子就明白了
例子计算过程如图:
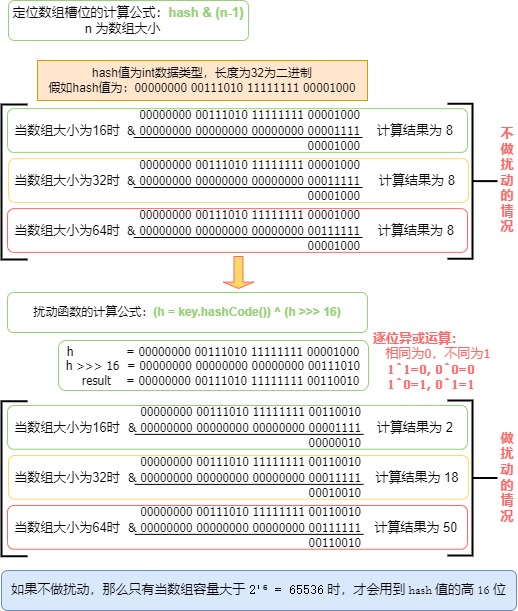
扰动函数结论如下
-
如果不做扰动,那么只有当数组容量大于
2¹⁶ = 65536时,才会用到 hash 值的高 16 位; -
数组小于65536前做的扩容,可能并不会使得节点分散到不同的数组槽位;
-
不管何种情况,都让高16位和低16位哈希值都参与计算,使得计算结果尽可能分散,从而减少冲突。
3.4. 小结
通过hash(Object key)获取尽可能分散的哈希值 ,避免在哈希值计算层面的哈希冲突 ;再将哈希值通过hash & (n-1) 映射(压缩)到数组范围内。
4. 为什么"哈希码越分散,冲突就越少"?
-
均匀分布减少集中
如果所有哈希值都集中在输出空间的某一小段区间,那这些标签对应的"桶"就会非常拥挤,冲突自然多。理想情况下,每个可能的哈希值被使用的概率都相等,输入均匀落在输出的各个位置上,任何两个不同元素映射到同一位置的概率才是最低的。
-
碰撞概率分析
假设有 N 个不同元素,要放到 M 个桶里(M 即哈希码空间大小),若哈希值均匀分布,那么任意两元素落在同一桶的概率约为 1/M。
总冲突概率与「元素对数」×「单对碰撞概率」成正比,约为
N(N−1)/2×1/M可以看到,当 M 越大/输出值越分散时, 越小,整体冲突概率就越低。
-
对哈希表性能的影响
低冲突 :每个桶的平均链长(或树深)接近 1,查找和插入都是
O(1)。高冲突 :部分桶链长变长,最坏可能退化到
O(n),性能急剧下降;Java 8 用树化把过长链表变成红黑树,最坏也能保证O(log n),但开销更大。
用开篇时提到的问题:如何快速定位数据存储在内存地址的位置?
函数y=f(x) ,f(x)为哈希映射数组索引函数 ,一个x(key)对应多个y(数组的索引index)。如果哈希码足够分散,分散到一个x对应一个y的这种理想情况,那么就可以根据函数直接计算出唯一的y,也就是说可以直接计算出目标内存地址,但这是一种接近数组查找速度的理想情况。为了尽可能提高计算目标内存地址的速度,就得让哈希码尽可能的分散。剩下影响哈希表性能的问题,便是哈希冲突问题如何高效解决?
将在下一篇HashMap文章展开,结合HashMap的四次扩容来剖析HashMap对哈希冲突问题的高效解决办法。


查看往期设计模式文章的:设计模式
原创不易,觉得还不错的,三连支持:点赞、分享、推荐↓