使用chattts的兄弟都知道,它只支持30s的朗读,所以如果要使用篇的话,就需要想一些别的办法,我现在使用的办法是:
-
将长篇小说按章节进行分拆
使用用正则表达式从文件中取出每个章节
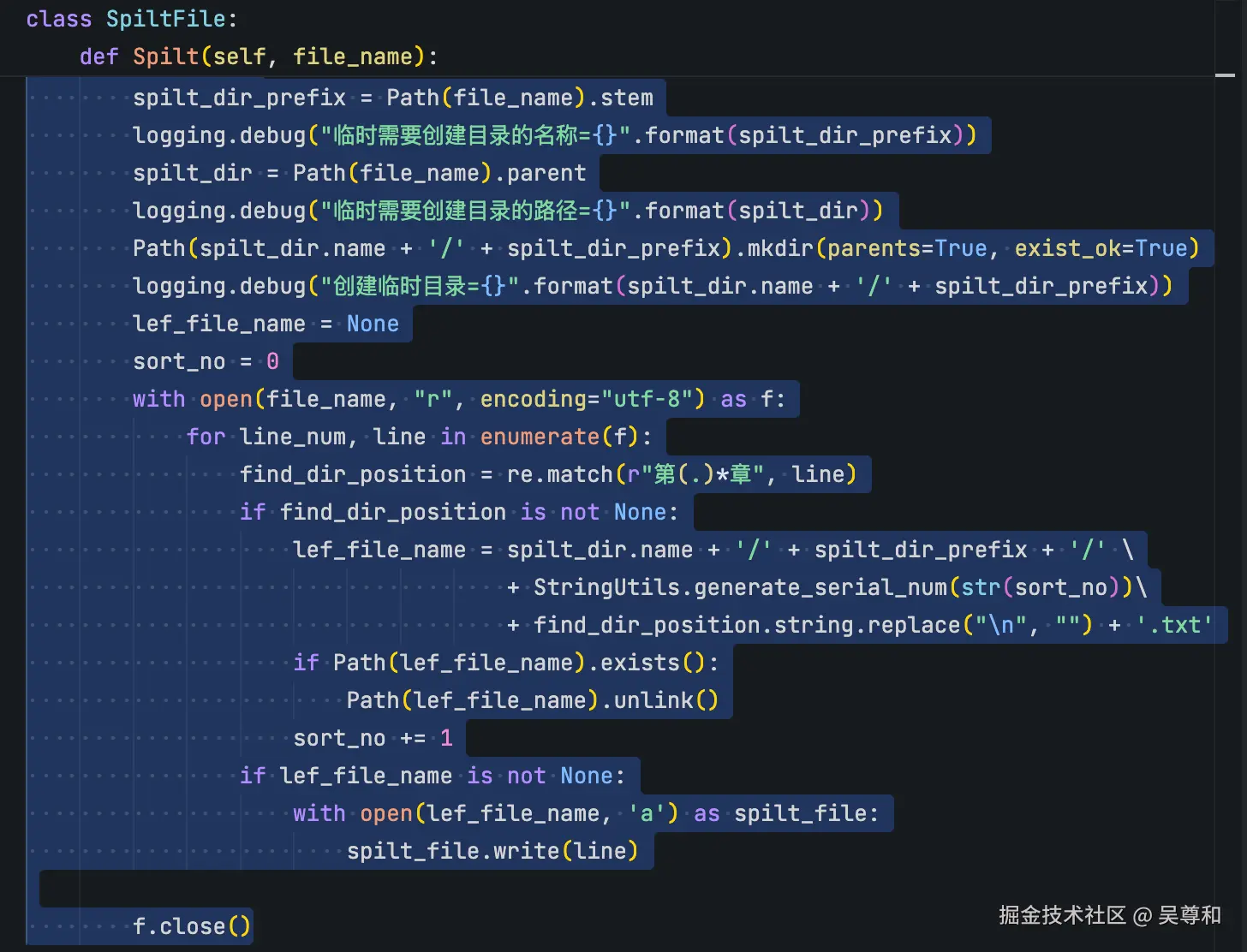
-
将每个章节按自然语言的语句来分折每一个语句 主要是由通过nlp,将章节进行分段处理生个语句,将每个语句中加入相应的语气词,保障每个语句是在30s以内。
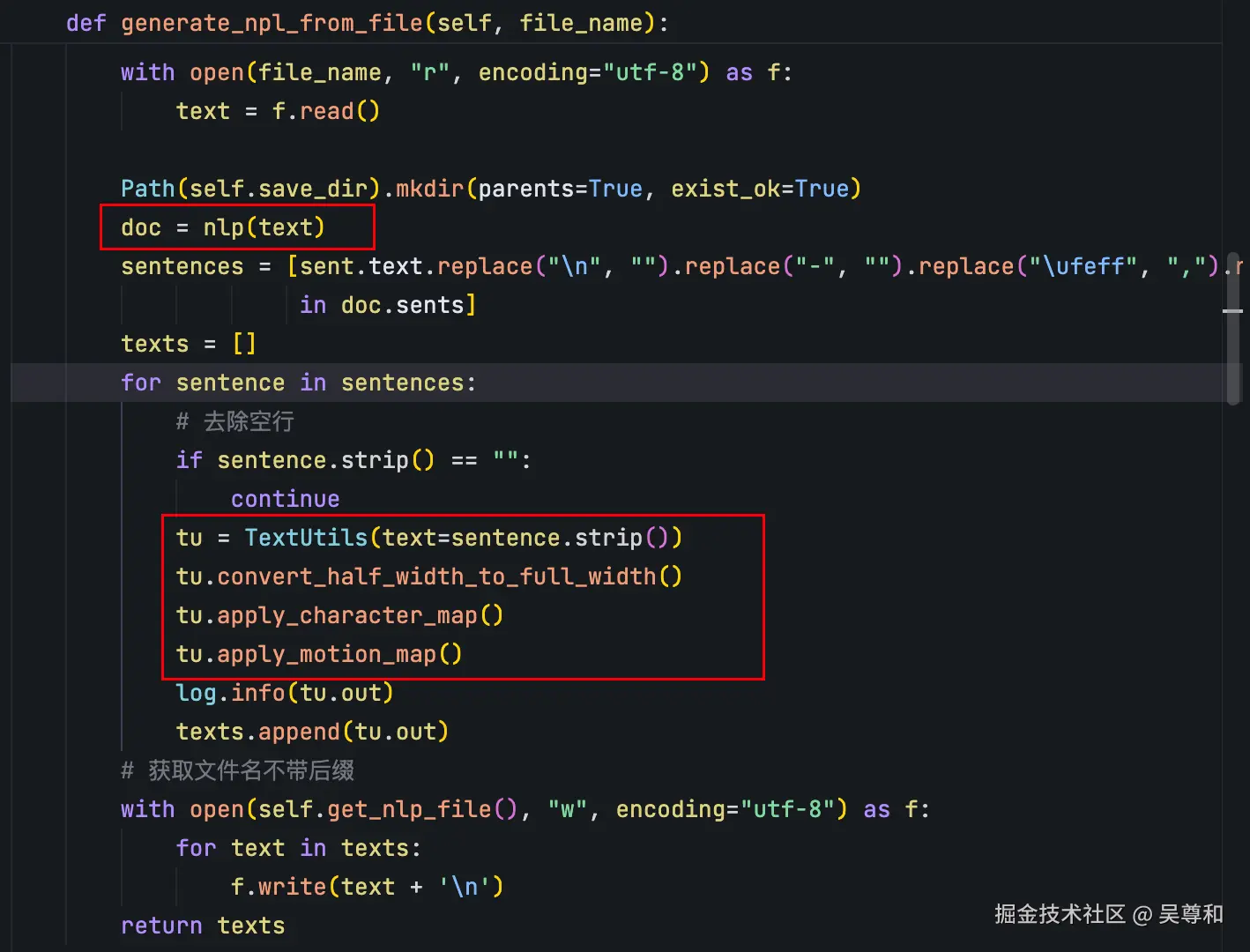
-
将每个语句生成一个文件,将每个章节的语音进行合并成一个mp3文件
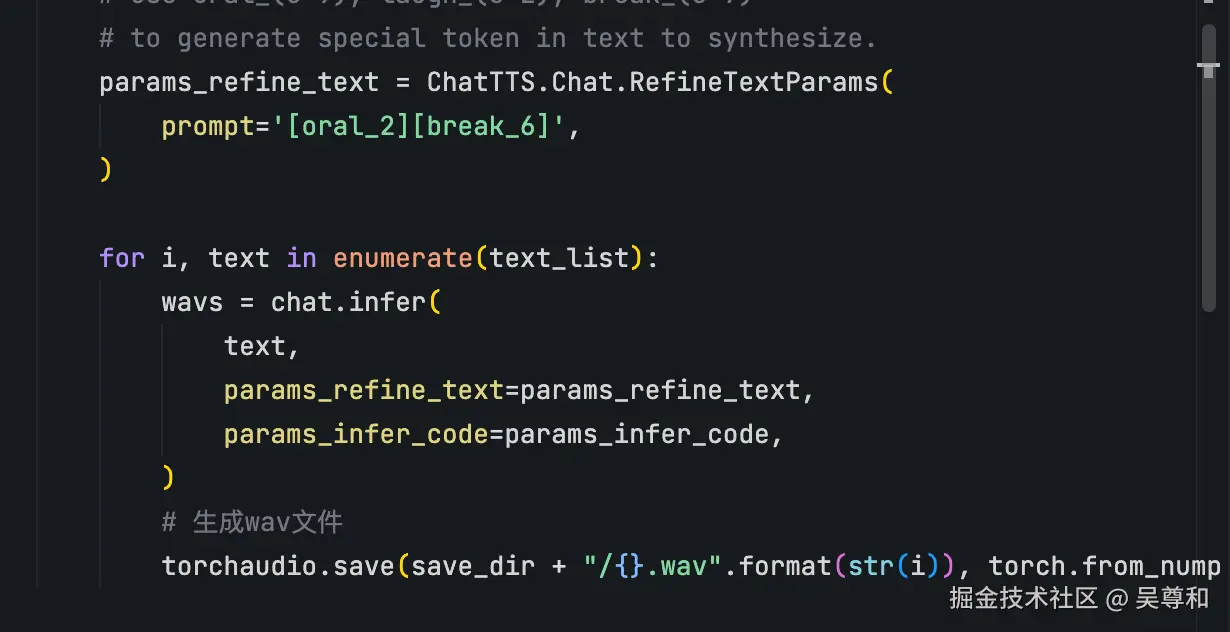 5. 通过视频生成工具将文件转成mp4
5. 通过视频生成工具将文件转成mp4
scss
Path(source_directory + Path(self.get_file_name()).stem).mkdir(parents=True, exist_ok=True)
output_file_wav = source_directory + Path(self.get_file_name()).stem + '/' + Path(self.get_nlp_file()).stem + '.wav'
cmd = ["ffmpeg","-safe", "0","-f", "concat","-i", self.save_dir + "input.txt","-c", "copy", "-y",f"{output_file_wav}"]
log.info(" ".join(cmd))
subprocess.run(cmd, check=True)
# 删除
Path(self.save_dir + "input.txt").unlink()
for wav in wav_list:
Path(wav).unlink()
# 将文件转换成mp3
output_file_mp3 = source_directory + Path(self.get_file_name()).stem + '/' + Path(self.get_nlp_file()).stem + '.mp3'
cmd_to_mp3 = [
"ffmpeg",
"-i", f"{output_file_wav}",
f"{output_file_mp3}"
]
log.info(" ".join(cmd_to_mp3))
subprocess.run(cmd_to_mp3, check=True)
# 删除wav文件
Path(output_file_wav).unlink()