1. 写在最前面
最近的工作有一种,哪里需要顶哪里的感觉。最近一个月又被隔壁项目组借调过去,去搞优先级更高的服务了,不过好在笔者心态好,毕竟接触的越多学习的越多,学习的越多积累的就越多。本着学到就是赚到的想法,工作的时候态度积极了不少。
不过借调到隔壁组的坏处是本职工作 + 借调的双份任务都需要保质保量的完成,导致笔者没有更多的时间学习感兴趣的新知识,刚好周末寒潮来袭,宅在家里学习感兴趣的新知识就是一个很不错的选择了。
仔细思考了一下,除了使用 Cursor 好像没有拓展自己 AI 框架相关的知识,那今天就抽出点时间学习一下吧。
2. BeeAI 框架初印象
BeeAI Framework 是一个用于构建 AI Agent 应用的 Python 框架。从项目结构来看,它提供了多种 Agent 类型,包括 RequirementAgent、ReActAgent 和 ToolCallingAgent。框架支持工具集成、内存管理、中间件和工作流编排,看起来功能相当完善。
项目提供了快速上手的模板,包含了多个实用的示例,让笔者能够快速理解框架的核心概念和使用方式。
3. 核心概念学习
3.1 Agent 类型对比
从代码中可以看到,框架提供了多种 Agent 类型。笔者通过实际使用和代码分析,整理了一个对比表格,帮助理解不同 Agent 的特点和适用场景:
| 特性维度 | RequirementAgent | ReActAgent | ToolCallingAgent |
|---|---|---|---|
| 核心特点 | 支持条件需求(ConditionalRequirement)控制 | 经典的 ReAct(Reasoning + Acting)模式 | 专注于工具调用的 Agent |
| 工具调用控制 | 精确控制 - 强制在特定步骤调用 - 限制调用次数 - 设置工具依赖关系 | 自主决策 - Agent 根据推理自主决定何时调用工具 | 依赖 LLM 的工具调用能力 - 需要 LLM 支持 function calling |
| 适用场景 | 需要严格流程控制的任务 - 必须按顺序执行的步骤 - 需要限制工具调用次数 - 工具之间有明确依赖关系 | 需要灵活推理的任务 - 代码执行和计算 - 复杂问题求解 - 需要多轮推理的场景 | 简单的工具调用任务 - 单次或少量工具调用 - LLM 原生支持 function calling |
| 代码示例位置 | agent.py agent_requirement.py |
agent_code_interpreter.py |
agent_tool_calling.py |
| 典型使用 | 规划活动(先查天气,再搜索事件) | 代码解释器(执行 Python 代码) | 简单查询(天气、搜索) |
| 配置复杂度 | 较高(需要定义 requirements) | 中等(需要配置工具) | 较低(直接使用工具) |
| 灵活性 | 高度可控但配置复杂 | 最灵活,自主决策 | 简单直接但功能有限 |
选择建议:
- RequirementAgent:需要精确控制工具调用流程时使用,比如"必须先获取天气,然后才能搜索相关活动"
- ReActAgent:需要 Agent 自主推理和决策时使用,比如代码执行、复杂问题求解
- ToolCallingAgent:只需要简单的工具调用,且 LLM 原生支持 function calling 时使用
3.2 工具(Tools)
框架内置了多种实用工具:
ThinkTool:让 Agent 进行思考OpenMeteoTool:获取天气信息DuckDuckGoSearchTool:网络搜索PythonTool:执行 Python 代码SandboxTool:在沙箱环境中运行代码
3.3 需求(Requirements)
RequirementAgent 的核心特性是支持条件需求,可以精确控制 Agent 的行为:
ini
requirements=[
ConditionalRequirement(ThinkTool, force_at_step=1, max_invocations=3),
ConditionalRequirement(
DuckDuckGoSearchTool, only_after=[OpenMeteoTool], min_invocations=0, max_invocations=2
),
]这个设计非常巧妙,可以:
- 强制在特定步骤调用某个工具
- 限制工具的最大调用次数
- 设置工具之间的依赖关系
3.4 中间件(Middleware)
框架支持中间件机制,可以拦截和处理 Agent 的执行过程:
ini
middlewares=[GlobalTrajectoryMiddleware(included=[Tool])]这样可以记录工具调用的轨迹,方便调试和监控。
4. 实践案例
4.1 基础 Agent 示例(RequirementAgent)
第一个示例展示了如何创建一个简单的 Agent:
ini
agent = RequirementAgent(
llm=ChatModel.from_name(os.getenv("LLM_CHAT_MODEL_NAME")),
tools=[ThinkTool(), OpenMeteoTool(), DuckDuckGoSearchTool()],
instructions="Plan activities for a given destination based on current weather and events.",
requirements=[
ConditionalRequirement(ThinkTool, force_at_step=1, max_invocations=3),
ConditionalRequirement(
DuckDuckGoSearchTool, only_after=[OpenMeteoTool], min_invocations=0, max_invocations=2
),
],
middlewares=[GlobalTrajectoryMiddleware(included=[Tool])],
)这个 Agent 可以根据天气和事件为目的地规划活动,展示了工具链式调用的能力。
效果如下:

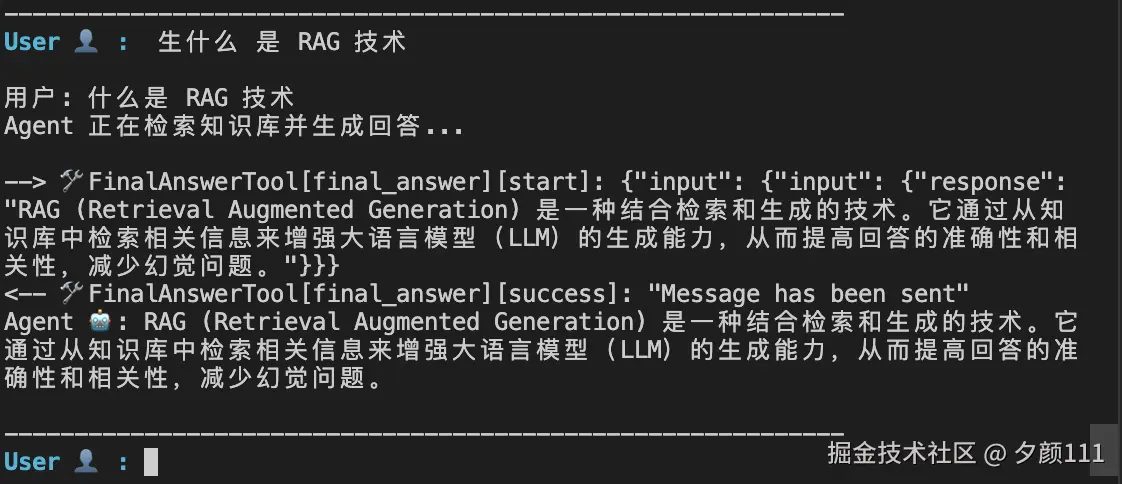
4.2 RAG 示例
RAG(Retrieval Augmented Generation)示例展示了如何构建一个基于知识库的问答系统:
python
class DocumentRetrievalTool(Tool):
"""文档检索工具,用于 RAG 演示"""
name = "document_retrieval"
description = "从知识库中检索与查询相关的文档片段。"
def __init__(self, documents: dict[str, str]) -> None:
super().__init__()
self.documents = documents
self._input_schema = DocumentRetrievalSchema这个示例展示了:
- 如何自定义工具
- 如何实现文档检索逻辑
- 如何将检索结果传递给 LLM
虽然示例中使用的是简单的关键词匹配,但在实际应用中可以使用向量数据库(如 Chroma、Pinecone)进行语义搜索。
效果如下:
4.3 Code Interpreter Agent(ReActAgent)
Code Interpreter 是 BeeAI Framework 中一个很有意思的功能,它让 Agent 能够安全地执行 Python 代码。笔者在实际使用中发现,这个功能的设计相当巧妙,值得深入分析一下。
4.3.1 架构设计
Code Interpreter 采用了容器化隔离的架构:
- K3s 容器集群:使用 K3s(由 Rancher 开发的轻量级 Kubernetes 发行版)作为容器编排平台。K3s 是 CNCF 的沙箱项目,相比标准 Kubernetes 更轻量(单个二进制文件小于 100MB),内存占用更少,非常适合边缘计算和开发环境。每个代码执行任务都在独立的 Pod 中运行
- 服务分离 :Code Interpreter 服务运行在
http://127.0.0.1:50081,通过 HTTP/gRPC 协议与 Agent 通信 - 存储隔离 :使用
LocalPythonStorage管理文件存储,区分本地工作目录和解释器工作目录
从 docker-compose.yml 可以看到使用了 rancher/k3s:v1.31.2-k3s1 镜像,而 code-interpreter.yaml 是标准的 Kubernetes 配置文件。整个系统通过 Kubernetes Pod 来执行代码,每个执行任务都是隔离的,执行完成后 Pod 会被销毁,确保了安全性。
4.3.2 PythonTool vs SandboxTool
Code Interpreter 提供了两种工具,它们的使用场景不同:
PythonTool:
- 用于执行简单的 Python 代码片段
- 适合数学计算、数据处理等一次性任务
- 代码直接提交给 Code Interpreter 服务执行
- 使用
LocalPythonStorage管理文件,支持文件的上传和下载
ini
python_tool = PythonTool(
code_interpreter_url=code_interpreter_url,
storage=LocalPythonStorage(
local_working_dir=os.path.abspath(os.path.join(dir_path, "../tmp/code_interpreter_source")),
interpreter_working_dir=os.path.abspath(os.path.join(dir_path, "../tmp/code_interpreter_target")),
),
)SandboxTool:
- 用于执行预定义的 Python 函数
- 可以设置环境变量,适合需要调用外部 API 的场景
- 从源代码创建,函数签名和文档字符串会被自动解析
- 更安全,因为只能执行预定义的函数,不能执行任意代码
ini
sandbox_tool = await SandboxTool.from_source_code(
url=code_interpreter_url,
env={"API_URL": "https://riddles-api.vercel.app/random"},
source_code="""
def get_riddle() -> Optional[Dict[str, str]]:
'''Fetches a random riddle from the Riddles API.'''
# ... 函数实现
""",
)4.3.3 安全机制
Code Interpreter 的安全设计体现在多个层面:
- 容器隔离:每个代码执行都在独立的 Pod 中,执行完成后 Pod 会被销毁,不会影响其他任务
- 资源限制:通过 Kubernetes 的资源限制,可以控制 CPU、内存等资源的使用
- 网络隔离:Pod 的网络是隔离的,可以控制网络访问权限
- 文件系统隔离:使用独立的存储卷,不会访问宿主机的文件系统
- 权限控制:通过 Kubernetes RBAC 控制 Pod 的创建和执行权限
4.3.4 存储机制
LocalPythonStorage 的设计很有意思,它区分了两个目录:
- local_working_dir:本地工作目录,用于存储 Agent 需要传递给 Code Interpreter 的文件
- interpreter_working_dir:解释器工作目录,Code Interpreter 服务实际访问的目录
这种设计的好处是:
- 文件传输是单向的,Agent 可以上传文件到解释器,但解释器不能直接访问 Agent 的文件系统
- 支持文件持久化,可以在多次调用之间共享文件
- 便于调试,可以在本地查看生成的文件
4.3.5 使用场景
在实际使用中,Code Interpreter 特别适合以下场景:
- 数学计算:执行复杂的数学运算,比如"计算 534*342"
- 数据分析:处理 CSV 文件、生成图表、统计分析
- API 调用:通过 SandboxTool 安全地调用外部 API,比如示例中的谜语 API
- 代码生成和执行:让 Agent 生成代码并执行,验证代码的正确性
4.3.6 为什么使用 ReActAgent
Code Interpreter Agent 使用 ReActAgent 而不是 RequirementAgent,原因在于:
- 灵活的工具选择:Agent 需要根据问题自主决定使用 PythonTool 还是 SandboxTool
- 多轮推理:复杂任务可能需要多次代码执行,Agent 需要根据前一次执行结果决定下一步操作
- 错误处理:如果代码执行失败,Agent 需要推理错误原因并尝试修复
这种自主决策的能力,让 Code Interpreter Agent 能够处理更复杂的任务,而不仅仅是简单的代码执行。
4.4 Multi-Agent Workflow
多 Agent 工作流示例展示了如何让多个 Agent 协作完成任务:
- Researcher:使用 Wikipedia 工具收集信息
- WeatherForecaster:使用 OpenMeteo API 获取天气信息
- DataSynthesizer:综合历史数据和天气数据生成最终总结
这种设计模式非常适合复杂的任务分解和并行处理。
5. 框架优势分析
5.1 设计理念
- 模块化设计:工具、Agent、中间件都是独立的模块,易于扩展
- 类型安全:使用 Pydantic 进行数据验证,减少运行时错误
- 异步支持:全面支持 async/await,适合高并发场景
- 可观测性:支持 OpenInference 集成,可以追踪 Agent 的执行轨迹
5.2 与其他框架的对比
相比 LangChain、LlamaIndex 等框架,BeeAI Framework 的特点:
- 更简洁的 API:代码更直观,学习曲线更平缓
- 更强的控制能力:通过 Requirements 可以精确控制 Agent 行为
- 更好的类型支持:充分利用 Python 的类型系统
6. 学习心得
6.1 收获
- 理解了 Agent 框架的核心概念:工具、Agent、中间件、工作流
- 学会了如何自定义工具 :通过继承
Tool类实现自定义功能 - 掌握了条件需求的使用:可以精确控制 Agent 的执行流程
- 了解了 RAG 的实现方式:检索 + 生成的组合模式
6.2 实际应用场景
基于这次学习,笔者认为 BeeAI Framework 适合以下场景:
- 智能客服系统:结合 RAG 和工具调用,提供准确的客户支持
- 数据分析助手:使用 Code Interpreter 进行数据分析和可视化
- 内容生成工具:利用多 Agent 工作流生成高质量内容
- 自动化任务:通过工具集成实现复杂的自动化流程
7. 碎碎念
啦啦啦,终于在周末的寒潮中宅在家里学习了 BeeAI Framework,今日份学习就先到这里结束吧。
- 人生最美好的一天,永远都是今天。
- 冬天就要靠近温暖的人和事,祝我们这个冬天爱与运气同在。
周末的学习时光总是过得很快,但收获满满。希望下次能继续探索更多有趣的技术!