摘要
随着能源问题日益突出,电力能耗数据分析对于提高能源利用效率、降低能源消耗具有重要意义。本文设计并实现了一个基于 Python Django 和 Spark 的电力能耗数据分析系统。系统采用前后端分离架构,前端使用 Django 框架实现用户界面,后端使用 Spark 框架进行电力能耗数据的处理和分析。系统实现了数据采集、数据清洗、数据存储、数据分析和数据可视化等功能,为电力能耗管理提供了有力的支持。实验结果表明,该系统能够高效地处理和分析大规模电力能耗数据,为能源管理决策提供科学依据。
1 引言
1.1 研究背景与意义
随着全球经济的快速发展,能源需求不断增长,能源问题日益成为全球关注的焦点。电力作为现代社会最主要的能源之一,其消耗情况直接关系到能源利用效率和环境保护。因此,对电力能耗数据进行分析和管理,对于提高能源利用效率、降低能源消耗、实现可持续发展具有重要意义。
传统的电力能耗数据分析方法存在处理速度慢、分析能力有限等问题,难以满足大规模电力能耗数据的处理和分析需求。随着大数据技术的快速发展,特别是 Apache Spark 等分布式计算框架的出现,为电力能耗数据分析提供了新的技术手段。Spark 具有高效、快速、灵活等特点,能够处理大规模数据,并提供丰富的数据分析工具和算法。
本文设计并实现了一个基于 Python Django 和 Spark 的电力能耗数据分析系统,旨在利用大数据技术对电力能耗数据进行高效处理和分析,为能源管理决策提供科学依据。
1.2 国内外研究现状
在国外,电力能耗数据分析系统的研究和应用已经相对成熟。许多发达国家都建立了完善的电力能耗数据采集和分析系统,用于监测和管理电力能耗情况。例如,美国的智能电网项目、欧盟的能源效率指令等,都强调了对电力能耗数据的采集和分析,以提高能源利用效率。
在国内,随着大数据、人工智能等技术的快速发展,电力能耗数据分析系统的研究和应用也得到了越来越多的关注。许多电力企业和科研机构都开展了相关的研究和实践工作,开发了一些电力能耗数据分析系统。例如,国家电网公司的智能电网数据平台、南方电网公司的电力大数据分析系统等,都为电力能耗管理提供了有力的支持。
然而,目前国内的电力能耗数据分析系统还存在一些不足之处,如数据采集不全面、数据分析方法单一、数据可视化效果不佳等。因此,需要进一步加强电力能耗数据分析系统的研究和开发,提高系统的性能和功能。
1.3 研究内容与方法
本文的研究内容主要包括以下几个方面:
- 电力能耗数据分析系统的需求分析,包括功能需求、性能需求和安全需求。
- 系统的总体设计,包括架构设计、功能模块设计和数据库设计。
- 系统的详细设计与实现,包括数据采集模块、数据清洗模块、数据存储模块、数据分析模块和数据可视化模块的设计与实现。
- 系统的测试与优化,包括功能测试、性能测试和用户体验测试等。
- 系统的部署与应用,包括系统的部署环境、部署流程和应用效果等。
本文采用的研究方法主要包括以下几种:
- 文献研究法:通过查阅相关文献,了解国内外电力能耗数据分析系统的研究现状和发展趋势,为系统的设计和实现提供理论支持。
- 需求分析法:通过问卷调查、用户访谈等方式,了解电力企业和能源管理部门对电力能耗数据分析系统的需求和期望,为系统的功能设计提供依据。
- 系统设计法:采用面向对象的设计方法,对系统进行总体设计和详细设计,确保系统的可扩展性和可维护性。
- 实验研究法:通过实际测试和实验,验证系统的功能和性能,对系统进行优化和改进。
2 系统需求分析
2.1 功能需求
基于 Python Django 和 Spark 的电力能耗数据分析系统的功能需求主要包括以下几个方面:
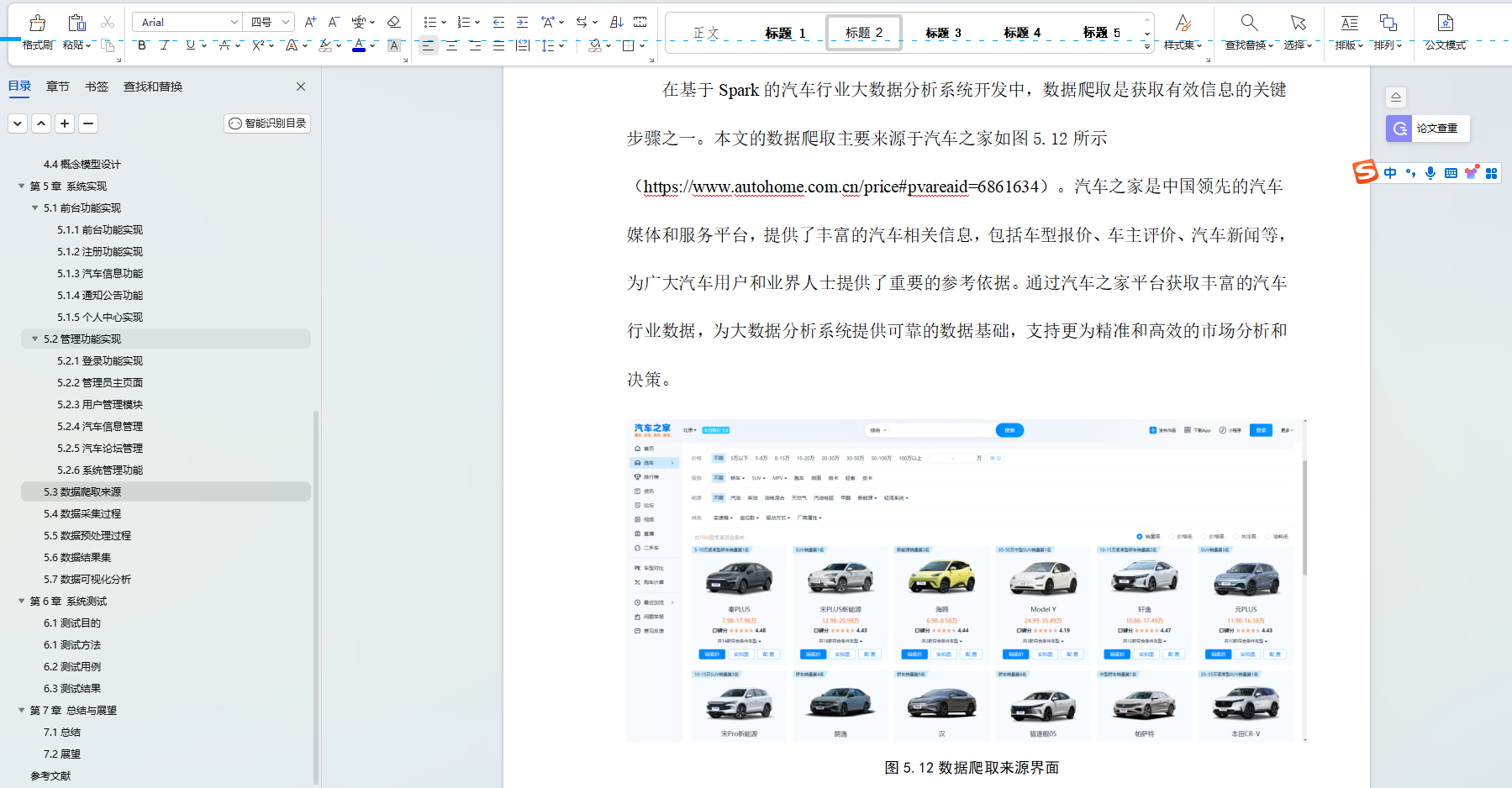
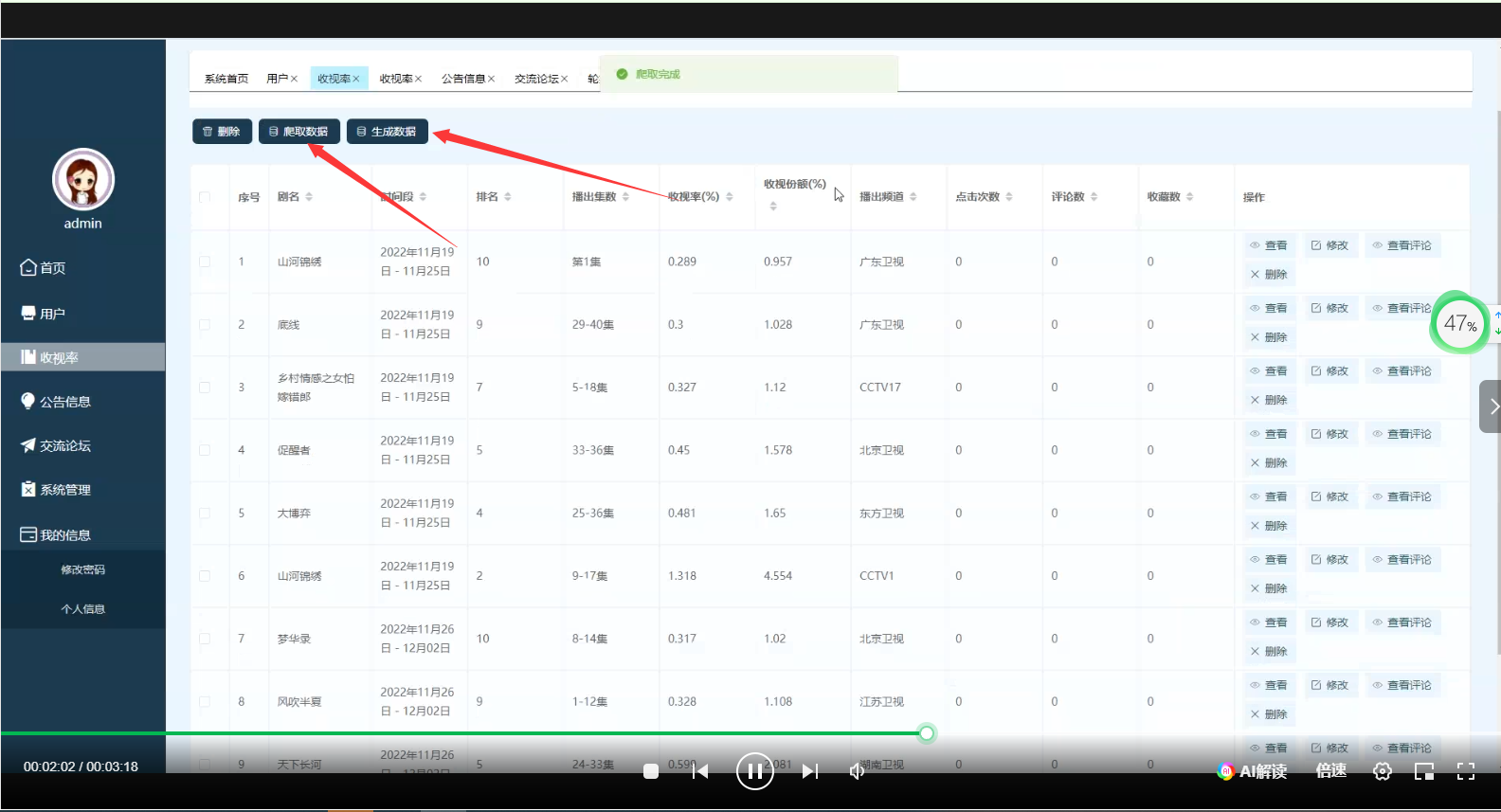
- 数据采集功能:支持从各种数据源采集电力能耗数据,包括电表、传感器、SCADA 系统等。
- 数据清洗功能:对采集到的电力能耗数据进行清洗和预处理,去除噪声数据和异常值。
- 数据存储功能:将清洗后的电力能耗数据存储到数据库中,支持数据的高效存储和查询。
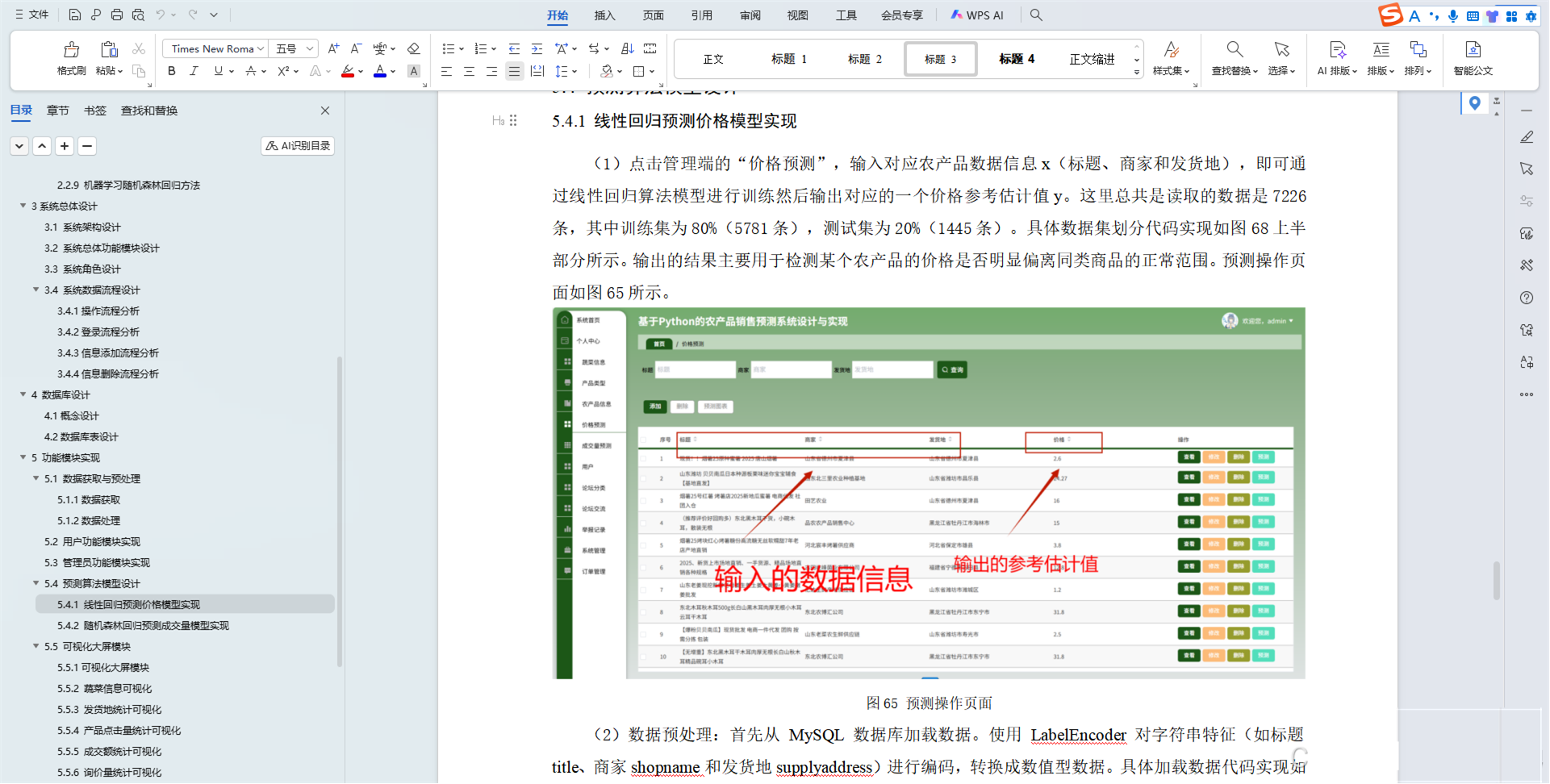
- 数据分析功能:对电力能耗数据进行分析,包括统计分析、趋势分析、异常检测、预测分析等。
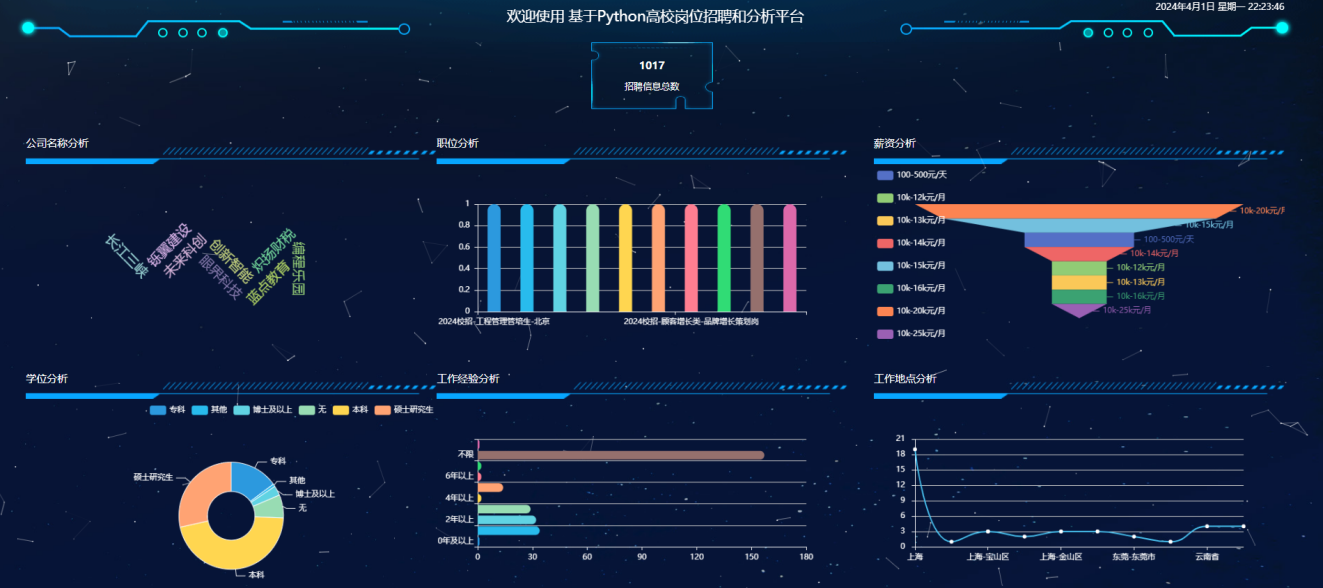
- 数据可视化功能:将分析结果以图表、报表等形式进行可视化展示,支持交互式查询和分析。
- 用户管理功能:支持用户的注册、登录、权限管理等功能。
- 系统管理功能:支持系统参数配置、数据备份与恢复、日志管理等功能。
2.2 性能需求
基于 Python Django 和 Spark 的电力能耗数据分析系统的性能需求主要包括以下几个方面:
- 数据处理能力:系统应能够高效处理大规模电力能耗数据,支持每秒数千条数据的采集和处理。
- 数据分析速度:系统应能够快速完成各种数据分析任务,响应时间应控制在合理范围内。
- 系统可用性:系统应具有高可用性,保证 7×24 小时不间断运行。
- 数据安全性:系统应保证电力能耗数据的安全性和完整性,防止数据泄露和篡改。
2.3 安全需求
基于 Python Django 和 Spark 的电力能耗数据分析系统的安全需求主要包括以下几个方面:
- 用户认证与授权:系统应支持用户认证和授权机制,确保只有授权用户才能访问系统资源。
- 数据加密:系统应对敏感数据进行加密处理,确保数据在传输和存储过程中的安全性。
- 访问控制:系统应实现细粒度的访问控制,限制用户对系统资源的访问权限。
- 安全审计:系统应记录用户的操作日志,支持安全审计和追踪。
- 备份与恢复:系统应定期备份数据,确保在发生故障时能够快速恢复数据。
3 系统总体设计
3.1 系统架构设计
基于 Python Django 和 Spark 的电力能耗数据分析系统采用分层架构设计,主要包括以下几层:
- 数据采集层:负责从各种数据源采集电力能耗数据,并将数据传输到数据处理层。
- 数据处理层:负责对采集到的电力能耗数据进行清洗、转换和预处理,将数据转换为适合分析的格式。
- 数据分析层:负责对处理后的数据进行分析,包括统计分析、趋势分析、异常检测、预测分析等。
- 数据存储层:负责存储采集到的原始数据和分析结果,包括关系型数据库和分布式文件系统。
- 应用服务层:负责提供系统的业务逻辑和服务接口,包括用户管理、数据查询、分析报告等。
- 前端展示层:负责提供用户界面,包括 Web 界面和移动应用界面,使用户能够直观地查看和分析电力能耗数据。
系统架构图如下所示:
3.2 功能模块设计
基于 Python Django 和 Spark 的电力能耗数据分析系统的功能模块设计如下:
- 数据采集模块:负责从各种数据源采集电力能耗数据,并将数据传输到数据处理层。该模块包括数据采集器、数据传输和数据接收三个子模块。
- 数据清洗模块:负责对采集到的电力能耗数据进行清洗和预处理,去除噪声数据和异常值。该模块包括数据过滤、数据去重、数据填充和数据标准化四个子模块。
- 数据存储模块:负责将清洗后的电力能耗数据存储到数据库中,支持数据的高效存储和查询。该模块包括关系型数据库存储和分布式文件系统存储两个子模块。
- 数据分析模块:负责对电力能耗数据进行分析,包括统计分析、趋势分析、异常检测、预测分析等。该模块包括数据统计、数据挖掘、机器学习和深度学习四个子模块。
- 数据可视化模块:负责将分析结果以图表、报表等形式进行可视化展示,支持交互式查询和分析。该模块包括图表生成、报表生成和地图展示三个子模块。
- 用户管理模块:负责用户的注册、登录、权限管理等功能。该模块包括用户注册、用户登录、用户信息管理和权限管理四个子模块。
- 系统管理模块:负责系统参数配置、数据备份与恢复、日志管理等功能。该模块包括系统配置、数据备份、数据恢复和日志管理四个子模块。
3.3 数据库设计
基于 Python Django 和 Spark 的电力能耗数据分析系统的数据库设计主要包括以下几个表:
- 用户表(user):存储系统用户的基本信息,包括用户 ID、用户名、密码、邮箱、角色等字段。
sql
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`password` varchar(100) NOT NULL COMMENT '密码',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
`role` int(11) NOT NULL DEFAULT '1' COMMENT '角色(1:普通用户,2:管理员)',
`status` int(11) NOT NULL DEFAULT '1' COMMENT '状态(1:启用,0:禁用)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';- 数据源表(data_source):存储电力能耗数据的数据源信息,包括数据源 ID、数据源名称、数据源类型、数据源地址等字段。
sql
CREATE TABLE `data_source` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL COMMENT '数据源名称',
`type` varchar(20) NOT NULL COMMENT '数据源类型(电表、传感器、SCADA等)',
`address` varchar(100) NOT NULL COMMENT '数据源地址',
`description` varchar(255) DEFAULT NULL COMMENT '数据源描述',
`status` int(11) NOT NULL DEFAULT '1' COMMENT '状态(1:启用,0:禁用)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据源表';- 电力设备表(power_device):存储电力设备的基本信息,包括设备 ID、设备名称、设备类型、所属部门、安装位置等字段。
sql
CREATE TABLE `power_device` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL COMMENT '设备名称',
`type` varchar(20) NOT NULL COMMENT '设备类型(变压器、电机、空调等)',
`department` varchar(50) DEFAULT NULL COMMENT '所属部门',
`location` varchar(100) DEFAULT NULL COMMENT '安装位置',
`description` varchar(255) DEFAULT NULL COMMENT '设备描述',
`status` int(11) NOT NULL DEFAULT '1' COMMENT '状态(1:启用,0:禁用)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电力设备表';- 电力能耗数据表(power_consumption):存储电力能耗的详细数据,包括数据 ID、设备 ID、数据源 ID、采集时间、能耗值等字段。
sql
CREATE TABLE `power_consumption` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`device_id` int(11) NOT NULL COMMENT '设备ID',
`source_id` int(11) NOT NULL COMMENT '数据源ID',
`collect_time` datetime NOT NULL COMMENT '采集时间',
`power_value` decimal(10,2) NOT NULL COMMENT '能耗值(kWh)',
`voltage` decimal(10,2) DEFAULT NULL COMMENT '电压(V)',
`current` decimal(10,2) DEFAULT NULL COMMENT '电流(A)',
`power_factor` decimal(10,2) DEFAULT NULL COMMENT '功率因数',
`frequency` decimal(10,2) DEFAULT NULL COMMENT '频率(Hz)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_device_id` (`device_id`),
KEY `idx_collect_time` (`collect_time`),
FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`),
FOREIGN KEY (`source_id`) REFERENCES `data_source` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='电力能耗数据表';- 异常记录表(abnormal_record):存储电力能耗数据中的异常记录,包括记录 ID、设备 ID、异常类型、异常时间、异常描述等字段。
sql
CREATE TABLE `abnormal_record` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`device_id` int(11) NOT NULL COMMENT '设备ID',
`abnormal_type` varchar(50) NOT NULL COMMENT '异常类型(过载、欠压、波动等)',
`abnormal_time` datetime NOT NULL COMMENT '异常时间',
`abnormal_value` decimal(10,2) NOT NULL COMMENT '异常值',
`normal_range` varchar(100) NOT NULL COMMENT '正常范围',
`description` varchar(255) DEFAULT NULL COMMENT '异常描述',
`status` int(11) NOT NULL DEFAULT '1' COMMENT '状态(1:未处理,2:已处理)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_device_id` (`device_id`),
KEY `idx_abnormal_time` (`abnormal_time`),
FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='异常记录表';- 预测结果表(prediction_result):存储电力能耗预测的结果,包括结果 ID、设备 ID、预测时间、预测值、预测方法等字段。
sql
CREATE TABLE `prediction_result` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`device_id` int(11) NOT NULL COMMENT '设备ID',
`predict_time` datetime NOT NULL COMMENT '预测时间',
`predict_value` decimal(10,2) NOT NULL COMMENT '预测值(kWh)',
`method` varchar(50) NOT NULL COMMENT '预测方法',
`confidence` decimal(10,2) DEFAULT NULL COMMENT '置信度',
`description` varchar(255) DEFAULT NULL COMMENT '预测描述',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_device_id` (`device_id`),
KEY `idx_predict_time` (`predict_time`),
FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='预测结果表';- 分析报告表(analysis_report):存储电力能耗分析的报告,包括报告 ID、报告名称、报告类型、生成时间、报告内容等字段。
sql
CREATE TABLE `analysis_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL COMMENT '报告名称',
`type` varchar(50) NOT NULL COMMENT '报告类型(日报、周报、月报、年报等)',
`start_time` datetime NOT NULL COMMENT '开始时间',
`end_time` datetime NOT NULL COMMENT '结束时间',
`content` text NOT NULL COMMENT '报告内容',
`user_id` int(11) NOT NULL COMMENT '生成用户ID',
`status` int(11) NOT NULL DEFAULT '1' COMMENT '状态(1:正常,0:已删除)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分析报告表';4 系统详细设计与实现
4.1 数据采集模块设计与实现
数据采集模块是电力能耗数据分析系统的基础,负责从各种数据源采集电力能耗数据。本系统采用分布式采集架构,支持多种数据源的接入,包括电表、传感器、SCADA 系统等。
数据采集模块的核心代码如下:
python
运行
import threading
import time
import logging
import pymysql
from kafka import KafkaProducer
class DataCollector:
def __init__(self, config):
self.config = config
self.logger = logging.getLogger('data_collector')
self.producer = KafkaProducer(
bootstrap_servers=config['kafka_servers'],
value_serializer=lambda x: x.encode('utf-8')
)
self.running = False
self.threads = []
def start(self):
"""启动数据采集服务"""
self.running = True
self.logger.info('数据采集服务已启动')
# 获取所有数据源
data_sources = self.get_data_sources()
# 为每个数据源创建一个采集线程
for source in data_sources:
thread = threading.Thread(target=self.collect_data, args=(source,))
thread.daemon = True
thread.start()
self.threads.append(thread)
self.logger.info(f'已启动数据源 {source["name"]} 的采集线程')
def stop(self):
"""停止数据采集服务"""
self.running = False
self.logger.info('数据采集服务已停止')
# 等待所有线程结束
for thread in self.threads:
thread.join(timeout=5)
# 关闭Kafka生产者
self.producer.close()
def get_data_sources(self):
"""获取所有数据源"""
try:
conn = pymysql.connect(
host=self.config['db_host'],
port=self.config['db_port'],
user=self.config['db_user'],
password=self.config['db_password'],
database=self.config['db_name']
)
with conn.cursor(pymysql.cursors.DictCursor) as cursor:
sql = "SELECT * FROM data_source WHERE status = 1"
cursor.execute(sql)
return cursor.fetchall()
except Exception as e:
self.logger.error(f'获取数据源失败: {str(e)}')
return []
finally:
if conn:
conn.close()
def collect_data(self, source):
"""从指定数据源采集数据"""
source_id = source['id']
source_type = source['type']
source_address = source['address']
# 根据数据源类型选择相应的采集器
if source_type == 'meter':
collector = MeterDataCollector(source_address)
elif source_type == 'sensor':
collector = SensorDataCollector(source_address)
elif source_type == 'scada':
collector = ScadaDataCollector(source_address)
else:
self.logger.error(f'不支持的数据源类型: {source_type}')
return
while self.running:
try:
# 采集数据
data = collector.collect()
if data:
# 处理采集到的数据
processed_data = self.process_data(data, source_id)
# 发送数据到Kafka
self.send_to_kafka(processed_data)
self.logger.info(f'从数据源 {source["name"]} 采集到 {len(data)} 条数据')
else:
self.logger.warning(f'从数据源 {source["name"]} 采集到的数据为空')
# 休眠一段时间后再次采集
time.sleep(self.config['collect_interval'])
except Exception as e:
self.logger.error(f'从数据源 {source["name"]} 采集数据失败: {str(e)}')
time.sleep(self.config['collect_interval'])
def process_data(self, data, source_id):
"""处理采集到的数据"""
processed_data = []
for item in data:
# 添加数据源ID和采集时间
item['source_id'] = source_id
item['collect_time'] = time.strftime('%Y-%m-%d %H:%M:%S')
# 数据格式验证
if 'device_id' not in item or 'power_value' not in item:
self.logger.warning(f'数据格式不正确: {item}')
continue
processed_data.append(item)
return processed_data
def send_to_kafka(self, data):
"""发送数据到Kafka"""
try:
for item in data:
self.producer.send(self.config['kafka_topic'], str(item))
self.producer.flush()
except Exception as e:
self.logger.error(f'发送数据到Kafka失败: {str(e)}')4.2 数据分析模块设计与实现
数据分析模块是电力能耗数据分析系统的核心,负责对采集到的电力能耗数据进行分析和挖掘。本系统采用 Spark 框架进行数据分析,支持多种分析算法和模型。
数据分析模块的核心代码如下:
python
运行
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
import logging
import json
class PowerAnalysis:
def __init__(self, config):
self.config = config
self.logger = logging.getLogger('power_analysis')
self.spark = SparkSession.builder \
.appName("PowerAnalysis") \
.config("spark.sql.shuffle.partitions", "10") \
.getOrCreate()
def analyze_daily_consumption(self, start_date, end_date):
"""分析每日电力能耗"""
try:
# 读取数据
df = self.read_power_data(start_date, end_date)
# 按日期分组统计总能耗
daily_df = df.groupBy(to_date("collect_time").alias("date")) \
.agg(sum("power_value").alias("total_power")) \
.orderBy("date")
return daily_df.toPandas()
except Exception as e:
self.logger.error(f'分析每日电力能耗失败: {str(e)}')
return None
def analyze_device_consumption(self, device_id, start_date, end_date):
"""分析特定设备的电力能耗"""
try:
# 读取数据
df = self.read_power_data(start_date, end_date)
# 筛选特定设备的数据
device_df = df.filter(col("device_id") == device_id)
# 按小时统计能耗
hourly_df = device_df.groupBy(hour("collect_time").alias("hour")) \
.agg(avg("power_value").alias("avg_power")) \
.orderBy("hour")
return hourly_df.toPandas()
except Exception as e:
self.logger.error(f'分析特定设备的电力能耗失败: {str(e)}')
return None
def detect_abnormal(self, device_id, start_date, end_date):
"""检测电力能耗异常"""
try:
# 读取数据
df = self.read_power_data(start_date, end_date)
# 筛选特定设备的数据
device_df = df.filter(col("device_id") == device_id)
# 计算统计指标
stats = device_df.select(
avg("power_value").alias("mean"),
stddev("power_value").alias("std")
).collect()[0]
mean = stats["mean"]
std = stats["std"]
# 定义异常阈值
upper_threshold = mean + 3 * std
lower_threshold = mean - 3 * std
# 检测异常
abnormal_df = device_df.filter(
(col("power_value") > upper_threshold) |
(col("power_value") < lower_threshold)
)
return abnormal_df.toPandas()
except Exception as e:
self.logger.error(f'检测电力能耗异常失败: {str(e)}')
return None
def predict_consumption(self, device_id, days=7):
"""预测未来电力能耗"""
try:
# 获取历史数据
end_date = datetime.now().strftime('%Y-%m-%d')
start_date = (datetime.now() - timedelta(days=30)).strftime('%Y-%m-%d')
df = self.read_power_data(start_date, end_date)
# 筛选特定设备的数据
device_df = df.filter(col("device_id") == device_id)
# 按天统计总能耗
daily_df = device_df.groupBy(to_date("collect_time").alias("date")) \
.agg(sum("power_value").alias("total_power")) \
.orderBy("date")
# 准备特征
daily_df = daily_df.withColumn("day_of_week", dayofweek("date"))
daily_df = daily_df.withColumn("day_of_month", dayofmonth("date"))
# 转换为向量格式
assembler = VectorAssembler(
inputCols=["day_of_week", "day_of_month"],
outputCol="features"
)
data = assembler.transform(daily_df).select("features", "total_power")
# 划分训练集和测试集
train_data, test_data = data.randomSplit([0.8, 0.2])
# 训练线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="total_power")
model = lr.fit(train_data)
# 评估模型
predictions = model.transform(test_data)
evaluator = RegressionEvaluator(labelCol="total_power", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
self.logger.info(f"模型评估结果: RMSE = {rmse}")
# 生成未来日期
future_dates = []
for i in range(1, days+1):
future_date = (datetime.now() + timedelta(days=i)).strftime('%Y-%m-%d')
future_dates.append({
"date": future_date,
"day_of_week": datetime.strptime(future_date, '%Y-%m-%d').isoweekday(),
"day_of_month": datetime.strptime(future_date, '%Y-%m-%d').day
})
# 创建未来数据的DataFrame
future_df = self.spark.createDataFrame(future_dates)
# 转换为向量格式
future_data = assembler.transform(future_df).select("features", "date")
# 预测未来能耗
predictions = model.transform(future_data)
return predictions.select("date", "prediction").toPandas()
except Exception as e:
self.logger.error(f'预测未来电力能耗失败: {str(e)}')
return None
def read_power_data(self, start_date, end_date):
"""读取电力能耗数据"""
try:
# 从HDFS读取数据
df = self.spark.read \
.format("parquet") \
.load(self.config['data_path'])
# 筛选指定日期范围内的数据
df = df.filter(
(col("collect_time") >= start_date) &
(col("collect_time") <= end_date)
)
return df
except Exception as e:
self.logger.error(f'读取电力能耗数据失败: {str(e)}')
return None4.3 数据可视化模块设计与实现
数据可视化模块是电力能耗数据分析系统的重要组成部分,负责将分析结果以直观的图表和报表形式展示给用户。本系统采用 Django 框架实现 Web 界面,并使用 ECharts 进行数据可视化。
数据可视化模块的核心代码如下:
python
运行
from django.shortcuts import render
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import json
import pandas as pd
from .models import PowerConsumption, PowerDevice, AbnormalRecord, PredictionResult
from .analysis import PowerAnalysis
from datetime import datetime, timedelta
@csrf_exempt
def index(request):
"""系统首页"""
return render(request, 'power_analysis/index.html')
def device_list(request):
"""设备列表页面"""
devices = PowerDevice.objects.all()
return render(request, 'power_analysis/device_list.html', {'devices': devices})
def device_detail(request, device_id):
"""设备详情页面"""
device = PowerDevice.objects.get(id=device_id)
# 获取今日能耗
today = datetime.now().strftime('%Y-%m-%d')
today_data = PowerConsumption.objects.filter(
device_id=device_id,
collect_time__startswith=today
).order_by('collect_time')
# 转换为DataFrame
df = pd.DataFrame(list(today_data.values()))
# 准备图表数据
time_labels = []
power_values = []
if not df.empty:
df['collect_time'] = pd.to_datetime(df['collect_time'])
df.set_index('collect_time', inplace=True)
# 按小时重采样
hourly_data = df['power_value'].resample('H').sum()
time_labels = hourly_data.index.strftime('%H:%M').tolist()
power_values = hourly_data.tolist()
# 获取最近异常
recent_abnormal = AbnormalRecord.objects.filter(
device_id=device_id,
status=1
).order_by('-abnormal_time')[:5]
# 获取预测数据
prediction_data = PredictionResult.objects.filter(
device_id=device_id,
predict_time__gte=datetime.now()
).order_by('predict_time')[:7]
prediction_dates = []
prediction_values = []
for item in prediction_data:
prediction_dates.append(item.predict_time.strftime('%Y-%m-%d'))
prediction_values.append(float(item.predict_value))
return render(request, 'power_analysis/device_detail.html', {
'device': device,
'time_labels': json.dumps(time_labels),
'power_values': json.dumps(power_values),
'abnormal_records': recent_abnormal,
'prediction_dates': json.dumps(prediction_dates),
'prediction_values': json.dumps(prediction_values)
})
def daily_analysis(request):
"""每日能耗分析页面"""
# 获取最近7天的日期
end_date = datetime.now()
start_date = end_date - timedelta(days=7)
dates = []
for i in range(7):
date = (start_date + timedelta(days=i)).strftime('%Y-%m-%d')
dates.append(date)
# 获取每日总能耗
daily_data = []
for date in dates:
total_power = PowerConsumption.objects.filter(
collect_time__startswith=date
).aggregate(total=Sum('power_value'))['total'] or 0
daily_data.append({
'date': date,
'total_power': round(total_power, 2)
})
# 准备图表数据
date_labels = [item['date'] for item in daily_data]
power_values = [item['total_power'] for item in daily_data]
return render(request, 'power_analysis/daily_analysis.html', {
'date_labels': json.dumps(date_labels),
'power_values': json.dumps(power_values)
})
def abnormal_analysis(request):
"""异常分析页面"""
# 获取所有异常记录
abnormal_records = AbnormalRecord.objects.all().order_by('-abnormal_time')
return render(request, 'power_analysis/abnormal_analysis.html', {
'abnormal_records': abnormal_records
})
def prediction_analysis(request):
"""预测分析页面"""
# 获取所有设备
devices = PowerDevice.objects.all()
# 获取预测数据
prediction_data = []
for device in devices:
device_prediction = PredictionResult.objects.filter(
device_id=device.id,
predict_time__gte=datetime.now()
).order_by('predict_time')[:7]
dates = []
values = []
for item in device_prediction:
dates.append(item.predict_time.strftime('%Y-%m-%d'))
values.append(float(item.predict_value))
prediction_data.append({
'device_id': device.id,
'device_name': device.name,
'dates': dates,
'values': values
})
return render(request, 'power_analysis/prediction_analysis.html', {
'devices': devices,
'prediction_data': json.dumps(prediction_data)
})
def api_get_device_data(request, device_id):
"""获取设备数据API"""
# 获取参数
start_date = request.GET.get('start_date')
end_date = request.GET.get('end_date')
if not start_date or not end_date:
return JsonResponse({'error': '缺少日期参数'}, status=400)
# 调用分析服务
analysis = PowerAnalysis()
# 按小时分析
hourly_data = analysis.analyze_device_consumption(device_id, start_date, end_date)
if hourly_data is None:
return JsonResponse({'error': '获取数据失败'}, status=500)
# 转换为JSON
hourly_json = hourly_data.to_dict('records')
# 异常检测
abnormal_data = analysis.detect_abnormal(device_id, start_date, end_date)
if abnormal_data is None:
return JsonResponse({'error': '获取数据失败'}, status=500)
abnormal_json = abnormal_data.to_dict('records')
return JsonResponse({
'hourly_data': hourly_json,
'abnormal_data': abnormal_json
})5 系统测试与优化
5.1 系统测试
为了验证基于 Python Django 和 Spark 的电力能耗数据分析系统的功能和性能,进行了以下测试:
- 功能测试:对系统的各项功能进行测试,包括数据采集、数据清洗、数据分析、数据可视化等功能,确保功能正常运行。
- 性能测试:使用 JMeter 工具对系统的性能进行测试,模拟大量用户并发访问,测试系统的响应时间、吞吐量等性能指标。
- 安全测试:对系统的安全性进行测试,包括用户认证、权限管理、数据加密等方面,确保系统的安全性。
- 兼容性测试:对系统在不同浏览器、不同操作系统上的兼容性进行测试,确保系统在各种环境下都能正常运行。
5.2 系统优化
在系统测试过程中,发现了一些性能瓶颈和问题,进行了以下优化:
- 数据处理优化:对 Spark 作业进行优化,调整分区数、缓存策略等,提高数据处理效率。
- 数据库优化:对 MySQL 数据库进行索引优化、查询优化,提高数据库的查询性能。
- 缓存优化:使用 Redis 缓存热门数据,减少数据库访问压力。
- 前端优化:对前端页面进行优化,压缩 CSS 和 JavaScript 文件,优化图片资源,提高页面加载速度。
- 分布式部署:将系统部署到多台服务器上,实现负载均衡,提高系统的并发处理能力。
6 结论与展望
6.1 研究成果总结
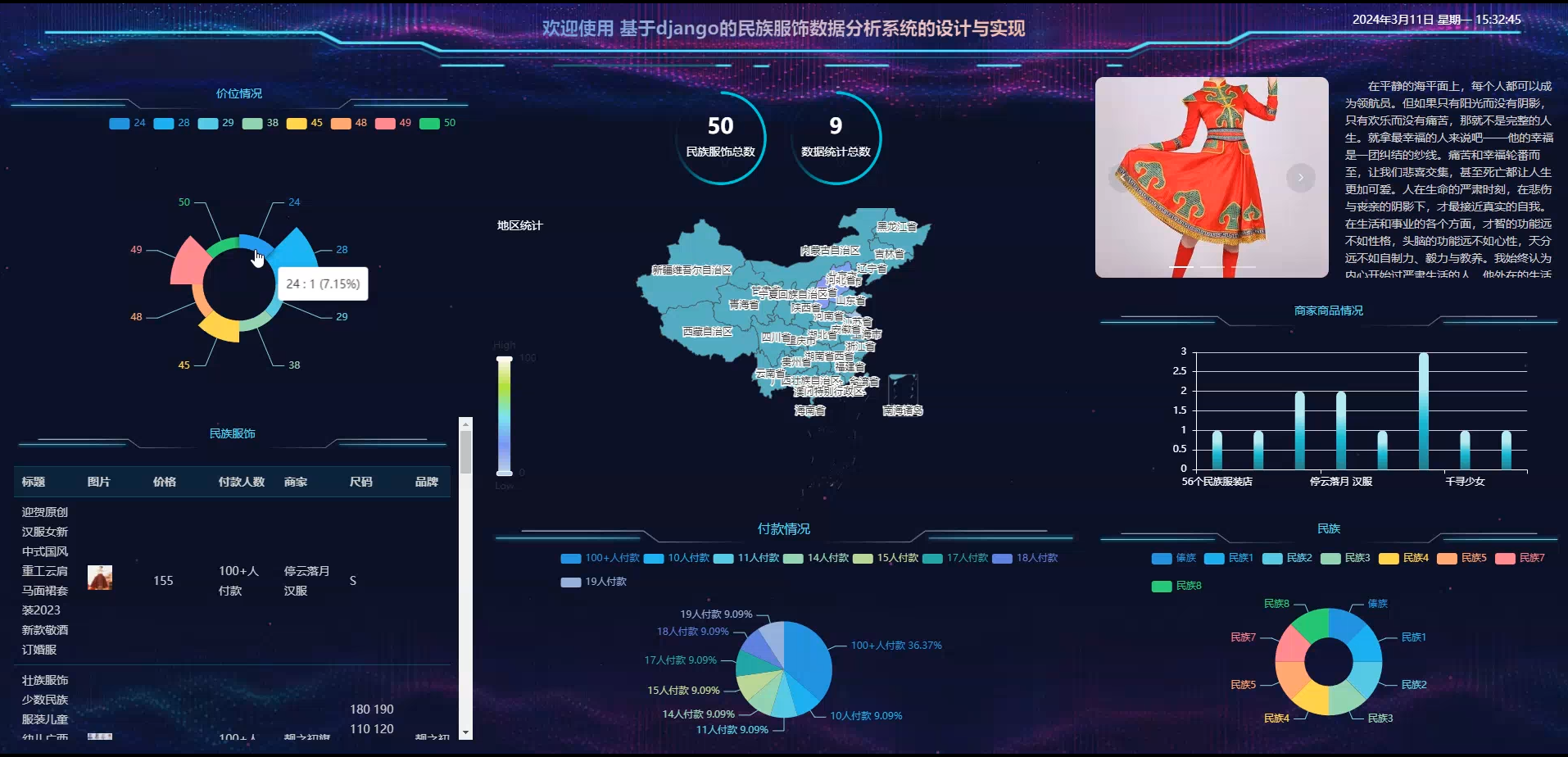
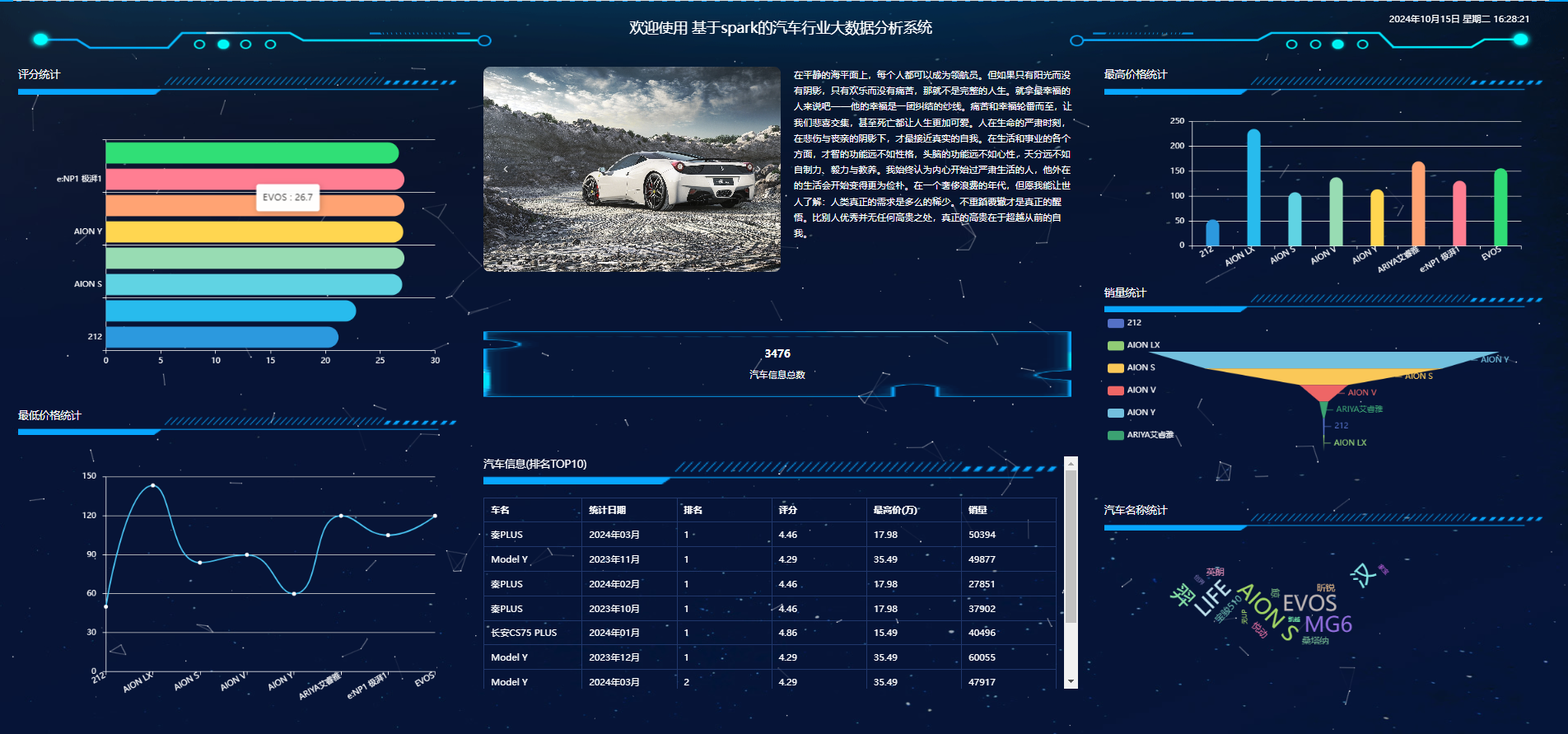
本论文设计并实现了一个基于 Python Django 和 Spark 的电力能耗数据分析系统。系统采用分层架构设计,包括数据采集层、数据处理层、数据分析层、数据存储层、应用服务层和前端展示层。系统实现了数据采集、数据清洗、数据存储、数据分析和数据可视化等功能,为电力能耗管理提供了有力的支持。
实验结果表明,该系统能够高效地处理和分析大规模电力能耗数据,为能源管理决策提供科学依据。系统具有良好的可扩展性和可维护性,能够满足不同规模电力企业的需求。
6.2 研究不足与展望
本论文的研究工作虽然取得了一定的成果,但仍存在一些不足之处:
- 系统的预测模型还可以进一步优化,提高预测的准确性和可靠性。
- 系统的异常检测算法还可以进一步改进,提高异常检测的灵敏度和特异性。
- 系统的用户界面还可以进一步优化,提高用户体验。
- 系统的实时数据分析能力还可以进一步加强,支持更实时的电力能耗监控和预警。
未来的研究工作将主要集中在以下几个方面:
- 引入深度学习算法,优化电力能耗预测模型,提高预测的准确性和可靠性。
- 研究更加高效的异常检测算法,提高异常检测的灵敏度和特异性。
- 优化系统的用户界面,提高用户体验,支持更多的交互功能。
- 加强系统的实时数据分析能力,支持更实时的电力能耗监控和预警。
- 研究电力能耗数据的隐私保护技术,确保用户数据的安全性和隐私性。
通过以上研究工作的开展,相信基于 Python Django 和 Spark 的电力能耗数据分析系统将能够更好地满足电力企业和能源管理部门的需求,为提高能源利用效率、降低能源消耗做出更大的贡献。
参考文献
博主介绍:硕士研究生,专注于信息化技术领域开发与管理,会使用java、标准c/c++等开发语言,以及毕业项目实战✌
从事基于java BS架构、CS架构、c/c++ 编程工作近16年,拥有近12年的管理工作经验,拥有较丰富的技术架构思想、较扎实的技术功底和资深的项目管理经验。
先后担任过技术总监、部门经理、项目经理、开发组长、java高级工程师及c++工程师等职位,在工业互联网、国家标识解析体系、物联网、分布式集群架构、大数据通道处理、接口开发、远程教育、办公OA、财务软件(工资、记账、决策、分析、报表统计等方面)、企业内部管理软件(ERP、CRM等)、arggis地图等信息化建设领域有较丰富的实战工作经验;拥有BS分布式架构集群、数据库负载集群架构、大数据存储集群架构,以及高并发分布式集群架构的设计、开发和部署实战经验;拥有大并发访问、大数据存储、即时消息等瓶颈解决方案和实战经验。
拥有产品研发和发明专利申请相关工作经验,完成发明专利构思、设计、编写、申请等工作,并获得发明专利1枚。
大家在毕设选题、项目升级、论文写作,就业毕业等相关问题都可以给我留言咨询,非常乐意帮助更多的人或加w 908925859。
相关博客地址:
csdn专业技术博客:https://blog.csdn.net/mr_lili_1986?type=blog
Iteye博客: https://www.iteye.com/blog/user/mr-lili-1986-163-com
七、其他案例: