在智能化机器人技术领域,兼具空中飞行与地面行驶能力的多模态机器人成为研究热点,而四旋翼无人机从空中到地面的形态转换因涉及复杂气动交互和执行器饱和控制难题,一直是技术瓶颈。加州理工学院团队研发了一款名为ATMO的新型地空两用机器人并被机器人顶会IROS 2025收录,其核心是完成极具挑战的"形态转换"机动------即在半空中变形并从飞行平滑过渡到地面行驶。这一过程因涉及复杂的空气动力学变化以及在临界倾斜角度时推进器接近饱和而异常困难 。该研究成果创新性地对比了基于模型预测控制(MPC)与端到端强化学习(RL)的两种控制策略,前者无需依赖执行器动态细节即可直接应用于硬件,后者通过仿真训练实现了 65° 大倾角的稳定着陆,二者在扰动恢复和故障容错等场景中展现出不同优势,为解决四旋翼形态转换控制难题提供了极具价值的技术路径参考。

动图1:ATMO机器人形态转换演示与方法介绍视频片段截取
原文链接:IROS 2025|RL vs MPC性能对比:加州理工无人机实测,谁在「变形控制」中更胜一筹?

为实现ATMO机器人高难度的形态转换机动,加州理工学院的团队设计并对比了两种技术路径截然不同的控制策略。这两种方法分别代表了机器人控制领域中"基于精确模型"与"基于AI学习"的两种主流哲学。
ATMO机器人硬件平台与动力学模型
ATMO机器人是一个能够飞行、地面驾驶,并在半空中完成形态转换的地空两用机器人。其硬件平台的关键设计包括:
1.变形机制:通过一个由单个直流电机驱动的闭环运动链,实现四个轮式推进器同步改变倾斜角度,从而在四旋翼飞行模式和地面行驶模式间切换。
2.硬件配置:机器人总重5.5kg ,搭载了用于传感器融合与状态估计的PX4飞控,以及用于运行复杂控制算法的NVIDIA Jetson Orin Nano机载计算机,ATMO机器人的图片如下。

图1: ATMO照片,该机器人借助轮式推进器执行器和用于在两种模式间切换的变形机构,能够实现驾驶和飞行功能。
为进行控制器设计与仿真,研究人员将ATMO建模为一个包含7个惯性部件(一个基座、两个臂和四个螺旋桨)的刚体系统。整个系统的动力学方程可以写成以下标准形式:
第一个式子描述了机器人主体运动的核心方程,遵循经典的多刚体系统动力学。其中,
是机器人质心位置,
是描述姿态的四元数,
是机身的倾斜角度,
,
是质心速度,
是角速度,
是质量矩阵,
是科里奥利项,
是重力项,
是电机每分钟转速,
是将电机实际产生的力映射到广义加速度的驱动矩阵。
第二个式子表示推进器电机的响应特性。它建立了一个一阶线性系统模型,用来反映一个物理现实:电机的转速无法瞬时改变,总是存在一定的延迟。是电机的时间常数,一个物理参数,决定了电机响应指令的快慢,
表示控制器发出的转速指令。第三个式子对机器人的变形结构进行了建模。描述了机器人身体的倾斜角度
是如何根据控制指令变化的。
表示变形机构能达到的最大角速度。
是控制器发出的变形指令。
模型预测控制 (MPC) --- 基于精确模型的优化求解
**MPC是一种经典的、功能强大的模型驱动控制方法 。**其核心思想是利用一个精确描述机器人行为的数学物理模型,通过在线模型计算预测未来状态并滚动优化控制量。其核心优化问题可表示为:
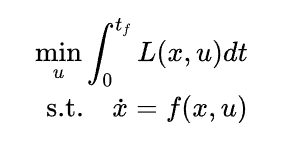
其中 是机器人的状态,
表示总的控制输入,
代表机器人的动力学模型,
是需要最小化的成本函数。
形态转换任务的难点在于机器人从空中飞行到地面接触,其控制目标和动态特性差异巨大。为了解决这一挑战,研究人员设计了一个巧妙的自适应成本函数。该函数是一个凸组合
,它融合了针对空中飞行的成本函数
和着陆转换的成本函数
。融合因子
会根据机器人当前的高度和身体倾斜角度在线调整。当机器人在高处时,成本函数侧重于飞行稳定性;当机器人接近地面并开始变形时,成本函数则平滑地过渡到侧重于安全着陆。这种设计成功解决了在高倾斜角下因执行器饱和而导致的优化问题无解的难题。
强化学习 (RL) --- 基于模拟训练的端到端策略
与依赖精确模型的MPC不同,RL是一种让AI在模拟中自主"试错"学习的控制方法 。该研究采用了一种端到端的RL策略,即训练单个神经网络,实现从传感器原始观测值直接到电机底层指令的映射,无需任何手动的控制器设计和调节。
RL策略的训练完全在Isaac Lab仿真框架中进行。为了确保模拟训练出的策略能在真实机器人上成功运行,研究人员在仿真中精确地加入真实世界的物理效应,这些都在仿真的物理步骤之前进行计算。
为模拟真实电机响应的延迟,推进器电机被建模为一阶线性系统 。其离散时间下的更新公式为:
其中 是机器人的状态,
表示总的控制输入,
代表机器人的动力学模型,
是需要最小化的成本函数。
形态转换任务的难点在于机器人从空中飞行到地面接触,其控制目标和动态特性差异巨大。为了解决这一挑战,研究人员设计了一个巧妙的自适应成本函数。该函数是一个凸组合
,它融合了针对空中飞行的成本函数
和着陆转换的成本函数
。融合因子
会根据机器人当前的高度和身体倾斜角度在线调整。当机器人在高处时,成本函数侧重于飞行稳定性;当机器人接近地面并开始变形时,成本函数则平滑地过渡到侧重于安全着陆。这种设计成功解决了在高倾斜角下因执行器饱和而导致的优化问题无解的难题。
其中 是由电机时间常数
和仿真步长
决定的滤波器系数,在训练中,名义上的电机时间常数为
。此外,另一个关键步骤是在训练时给策略网络的观测输入加入一个仿真步长 (20ms) 的延迟。若没有这个延迟,学习到的策略将无法在真实硬件上稳定运行。
在训练阶段,该研究使用了PPO算法,并采用了一种非对称的Actor-Critic架构,即在训练时给予Critic网络比Actor网络更多的信息,以帮助稳定训练过程。
Actor网络的输入包括位置、姿态、线速度、角速度、倾斜角以及过去10个时间步的历史动作,输出为4个轮式推进器电机的转速和1个倾斜角度指令。
Critic网络只在训练时使用,用于评估Actor所做决策的优劣。Critic网络的输入除了Actor的所有观测信息外,还有在真实世界中无法获得的特权信息,包括随机干扰力和力矩,干扰起止时间,当前时间与地面接触冲量。输出为对Actor的动作评估分数。
奖励函数是引导AI智能体学习的唯一信号,其设计目标是激励机器人在目标点附近安全地以大倾角着陆 。其完整形式为多个加权项的总和:
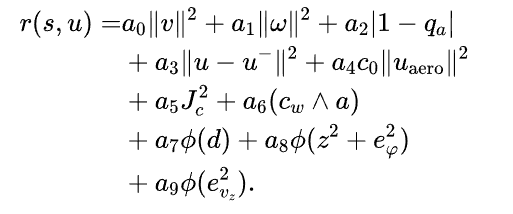
其中,是可调的奖励权重,
,
分别惩罚过大的线速度、角速度以及偏离水平的飞行姿态,
是控制消耗惩罚,鼓励平滑动作,
惩罚在首次接触地面后仍然使用推进器的行为,
是地面撞击惩罚,激励机器人学习软着陆,
是着陆成功奖励,
是一个指数函数,用于将误差转化为奖励,
是接近目标奖励,
是一个关键的塑形奖励。它激励机器人在接近地面时,执行最大程度的倾斜,
鼓励机器人以一个期望的恒定速率下降。

为验证和对比模型预测控制(MPC)与强化学习(RL)两种策略的性能,研究团队在真实世界的硬件平台和高保真的仿真环境中进行了一系列实验。实验结果清晰地揭示了两种方法在敏捷性、抗干扰能力和故障恢复方面的各自优势与不足。
硬件实验
研究人员在加州理工学院的CAST飞行场地,利用Optitrack动捕系统为ATMO机器人提供高精度定位,进行了真实的形态转换着陆实验,实验结果如下图所示。
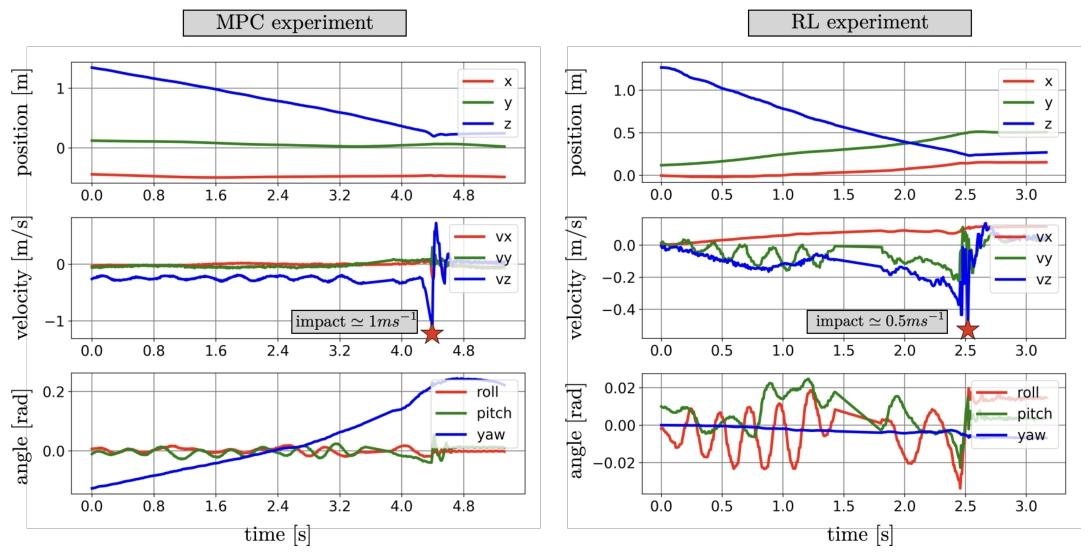
图2:使用两种控制器在硬件上执行形态转换操作。左侧显示了模型预测控制(MPC)控制器的性能,右侧为强化学习(RL)控制器的性能。
在着陆倾角与冲击速度方面,RL 控制器实现了最大 65° 的着陆倾角,冲击速度为 0.5 m/s,显著优于 MPC 控制器的 60° 倾角和 1.0 m/s 冲击速度。这表明 RL 通过自主学习能更接近执行器饱和边界(临界倾角 60°),实现更激进的形态转换。
在动态稳定性方面,MPC的角动态更稳定,滚转振荡幅度较小,但存在偏航方向的显著漂移。RL在下降过程中滚转振荡略大,推测与系统延迟估计误差及电机动态建模不精确有关,通过在部署策略时减少通信延迟可优化。
仿真实验
为了系统性地评估两种控制器的鲁棒性,研究团队利用Isaac Lab的并行仿真环境,分别测试了抗干扰能力和部分执行器故障下的恢复能力。
在抗干扰能力测试中,对机器人施加了不同方向和大小的推力干扰,并记录了其恢复过程中的着陆冲击速度和最终与目标的距离,结果如下图所示。
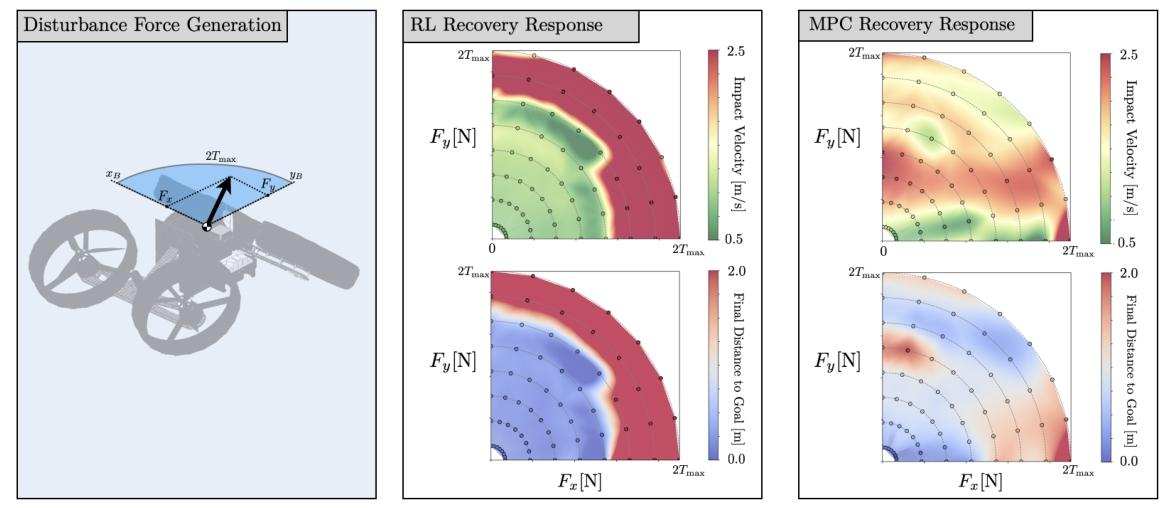
图3:强化学习(RL)与模型预测控制(MPC)方法的对比。针对每个控制器,记录了 64 种不同推力下的冲击速度和到目标的最终距离。推力方向在xy平面内变化,推力大小在 0.60到 8.0
之间变化。数据点以散点图形式呈现,并叠加了插值热图。
RL控制器表现出极强的抗干扰能力,在高达5-6(
为单个推进器的推力系数)的巨大干扰力下,依然能够完全恢复并安全着陆,其表现远超训练时所遇到的干扰强度。然而,一旦干扰超过某个阈值,其性能会急剧下降。
MPC控制器的表现更为平均,它能从更大的干扰中恢复位置,但通常伴随着无法接受的高冲击速度。它缺少RL控制器所展现出的那个表现优异的清晰恢复区域。
部分执行器故障下的恢复能力旨在模拟电机磨损或电池电量不足等导致的部分执行器失效场景。研究人员在仿真中不对称地降低了各个推进器的效率,这是一个控制器事先完全未知的、非均匀的故障模式,结果如下图所示。
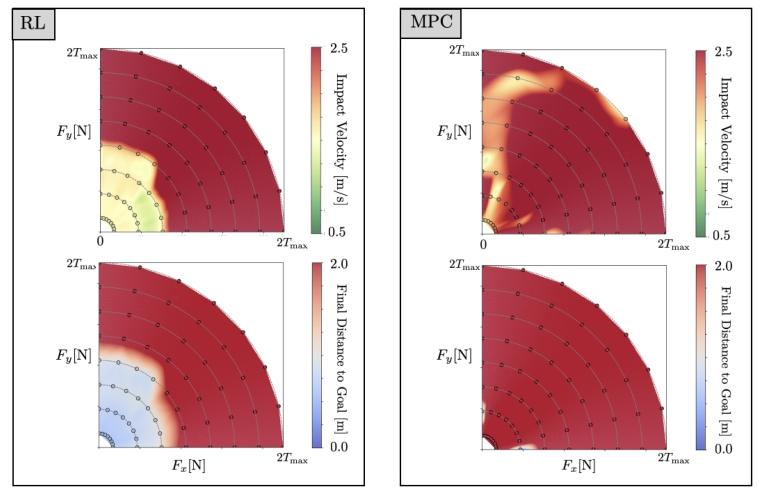
图4:部分执行器故障下的恢复特性。 推进器电机的推力和力矩系数按 0.8, 0.9, 0.85, 1.1 的比例相乘,顺序为右前、左后、左前、右后。
RL控制器在测试中展现了惊人的自适应能力。尽管推进器效率下降且不均衡,它依然能够在相当大的干扰力下成功恢复并着陆。这表明RL策略学习到了某种内在的鲁棒性,能够泛化到未曾明确训练过的故障场景。
MPC控制器在这种未建模的故障下,表现出完全的脆弱性,几乎在所有的干扰测试中都失败了。论文指出,虽然可以通过更复杂的故障诊断与自适应算法来扩展MPC以应对此类情况,但这将需要大量的额外工程工作,而RL策略则无需额外处理就获得了这种鲁棒性。

这篇论文针对一个名为ATMO的可变形机器人,旨在解决其从飞行到地面行驶的形态转换这一高难度控制问题 。研究者们设计并深入对比了两种核心控制策略:一种是基于精确物理模型的传统模型预测控制(MPC),另一种是无需精确模型、通过仿真训练的端到端强化学习(RL)。实验结果表明,RL控制器在真实硬件上实现了更敏捷、冲击更小的着陆,并展现出对部分执行器突发故障的惊人鲁棒性,而MPC控制器则完全失效 。研究最终得出结论:尽管RL策略的成功部署依赖于在仿真中对电机延迟等真实物理效应的精确建模,但它能够学习到一种更灵活且对未建模动态更具适应性的高级控制能力,为复杂变形机器人的发展开辟了新道路。
论文题目:Quadrotor Morpho-Transition: Learning vs Model-Based Control Strategies
论文作者:Ioannis Mandralis, Richard M. Murray, Morteza Gharib