嘿,各位未来的AI大神们,阿威又回来了!
经过前面几个章节的"浴血奋战",我们已经成功打造了基于RAG的知识库问答机器人和能帮你干活的AI智能体。它们在你的本地电脑上跑得风生水起,是不是感觉自己已经是个AI高手了?
打住!先别急着开香槟。
咱们现在手里的,说白了,还是个"玩具"或者"原型"。它很酷,很有趣,但离一个能稳定、可靠、高效地为真实用户提供服务的"产品",还差着十万八千里。这就好比你用乐高拼了一辆超跑,外形100分,但真要开上秋名山,分分钟散架。
这一章,我们就来干一件"煞风景"但至关重要的事情------应用的工程化。我们要把我们的AI"玩具",一步步锻造成能上战场的"兵器"。准备好了吗?系好安全带,咱们从Jupyter Notebook的"舒适区"一脚油门踩进真实世界的"赛道"!
7.1 从"我的代码能跑"到"服务稳定可靠"
在软件工程界有个经典名言:"在我电脑上是好的啊!"(It works on my machine!)。这通常是一切灾难的开始。我们的目标,就是彻底消灭这句话。
7.1.1 告别 app.py 的单文件闯天下时代
很多兄弟刚开始学的时候,喜欢把所有逻辑------加载模型、处理输入、调用API、打印结果------全都塞在一个Python脚本里。这在实验阶段没问题,一把梭哈,简单直接。
但要做成服务,这就行不通了:
- 职责混乱:一个文件干了所有事,想改其中一小块逻辑,就像在盘丝洞里找线头,牵一发而动全身。
- 无法并发:你的脚本一次只能处理一个请求。用户A在用,用户B就得干等着。这要放到线上,用户早就跑光了。
- 状态管理噩梦:用户的对话历史、身份信息存哪儿?用全局变量吗?那多用户同时访问时,岂不是乱成一锅粥?
所以,第一步,咱们得有个"总管",一个能接待用户、分发任务、管理秩序的角色。没错,就是Web框架。
Web服务 (产品) 单文件脚本 (原型) /chat 路由 /upload 路由 Web框架 (如FastAPI) 用户请求 调用聊天逻辑 调用文件上传逻辑 返回聊天结果 返回上传状态 app.py 用户请求 处理所有逻辑 返回结果
- 引入Web框架(FastAPI/Flask) : 我们需要用像FastAPI或Flask这样的工具,把我们的AI能力封装成一个个API端点(Endpoints)。比如,
/chat负责对话,/upload_doc负责上传知识库文档。 - API的艺术: 设计清晰、规范的API接口。请求应该长什么样?成功和失败的返回格式分别是什么?这都是我们需要提前定义好的"合同"。
7.1.2 你的AI应用也需要"记忆" - 状态管理
HTTP协议本身是无状态的,一次请求结束,服务器就把你忘了。但我们的AI应用,尤其是多轮对话机器人,必须有"记忆"。
- 问题在哪 :如果每个
/chat请求都是独立的,那机器人就记不住上一轮我们聊了啥。它会变成一个只会说"你好"的复读机。 - 解决方案 :
- 会话ID (Session ID):最常见的玩法。前端每次请求都带上一个独一无二的会话ID。后端根据这个ID,就能找到对应的历史聊天记录。
- 数据库/缓存: 聊天记录存哪儿?可以存Redis里(速度快),也可以存PostgreSQL里(更持久)。
- LangChain的记忆模块 : 幸运的是,LangChain已经为我们准备好了各种
Memory模块(比如ConversationBufferMemory),能方便地与后端存储集成。
7.2 前后端分离:让专业的干专业的事
在chapter6_agent_project里,我们已经实践了前后端分离的架构。这里我们再深入聊聊为什么这么做是现代Web开发的标配。
- 前端 (Frontend): 负责"颜值",也就是用户看到和交互的界面。用HTML/CSS/JavaScript(或者React/Vue这类框架)构建。它的核心任务是展示数据和收集用户输入。
- 后端 (Backend): 负责"内涵",也就是我们那些牛逼的AI逻辑。它只通过API与前端通信,不关心界面长啥样。
这种分离的好处是:
- 解耦:前端工程师和AI工程师可以并行开发,互不干扰。前端可以随便换UI库,后端也可以随时优化模型,只要API接口不变就行。
- 可扩展性:如果未来我们想开发一个移动App,或者小程序呢?只要它们调用相同的后端API就行了,我们不需要重写任何AI逻辑!
- 性能:后端可以部署在性能强劲的服务器上,而前端的静态文件可以放在CDN上全球加速。
7.2.1 流式响应 (Streaming):提升用户体验的"魔法"
你用ChatGPT时,会发现它的回答是一个字一个字"打"出来的,而不是等全部生成完了一次性给你。这就是流式响应。
- 为什么需要它? 大模型生成一个完整的回答可能需要几秒甚至几十秒。如果让用户干等,体验会非常糟糕。流式响应能立刻给出反馈,大大降低了用户的等待焦虑。
- 实现原理 :
用户 前端 后端 大语言模型 发送消息 "你好" POST /chat (stream=true) 请求生成回答 (以流式方式) "你" (第一个token) "你" 显示 "你" "好" (第二个token) "好" 显示 "你好" "!" (第三个token) "!" 显示 "你好!" DONE (结束标志) DONE 用户 前端 后端 大语言模型 - 技术选型 : FastAPI原生支持
StreamingResponse,实现起来非常方便。前端则需要使用Fetch API或EventSource来处理这种持续到来的数据流。
7.3 Docker:给你的应用一个"集装箱"
环境配置是程序员永恒的痛。在你机器上跑得好好的Python脚本,换到同事电脑或服务器上,可能就因为缺这个库、少那个依赖、版本不对而出错了。
Docker就是来解决这个问题的神兵利器。
- 它是什么? 简单来说,Docker能把你的应用程序,连同它所有的依赖(Python解释器、库、配置文件等),一起打包到一个标准化的"集装箱"(Image)里。
- 有什么用?
- 环境一致性: 这个"集装箱"在哪都能跑,无论是Windows、Mac还是Linux服务器,里面的环境都一模一样,彻底告别"在我电脑上是好的"。
- 快速部署 : 部署一个应用,不再是繁琐地一个个装依赖,而只是简单的一句
docker run。 - 隔离与安全: 每个集装箱都是一个独立的环境,不会和宿主机或其他集装箱互相干扰。
7.3.1 编写你的第一个 Dockerfile
Dockerfile就是一份"打包清单",告诉Docker如何构建你的应用镜像。
dockerfile
# Dockerfile for our AI Backend
# 1. 选择一个基础镜像 (包含Python)
FROM python:3.10-slim
# 2. 设置工作目录
WORKDIR /app
# 3. 复制依赖清单并安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 4. 复制所有应用代码
COPY . .
# 5. 暴露端口 (告诉Docker我们的应用在哪个端口监听)
EXPOSE 8000
# 6. 启动命令 (当容器启动时运行什么命令)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]- 解读: 这份文件就像一个菜谱,一步步指导Docker如何从一个纯净的Python环境,构建出我们完整的、可运行的应用。
7.4 部署:让世界看到你的作品
有了Docker镜像,部署就变得简单多了。虽然生产环境的部署是个大学问(涉及到Kubernetes、CI/CD等),但我们可以从简单的开始。
7.4.1 docker-compose: 本地编排你的服务
我们的应用有前端和后端两个部分,我们希望一键启动它们。docker-compose就是干这个的。
docker-compose.yml 文件:
yaml
version: '3.8'
services:
backend:
build: ./backend # 从backend目录的Dockerfile构建
ports:
- "8000:8000" # 将主机的8000端口映射到容器的8000端口
volumes:
- ./backend:/app # 将本地代码挂载到容器,方便开发时热更新
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY} # 从.env文件读取环境变量
frontend:
build: ./frontend
ports:
- "8080:80" # 前端通常用Nginx在80端口提供服务
depends_on:
- backend # 确保后端先启动- 一键启动 : 在项目根目录运行
docker-compose up,Docker就会自动构建并启动你的前后端两个服务。简直不要太爽!
7.4.2 云端部署初探
当你想让公网用户访问时,就需要把应用部署到云服务器上。
- 选择1:云主机 (IaaS): 像阿里云ECS、腾讯云CVM。你需要自己登录服务器,安装Docker,然后把你的项目弄上去跑。自由度高,但需要一些运维知识。
- 选择2:平台即服务 (PaaS): 像Vercel(适合前端)、Render、Heroku。你只需要把代码(或Docker镜像)推上去,平台会自动帮你搞定部署、域名、扩缩容等一堆破事。对开发者极其友好,强烈推荐新手尝试。
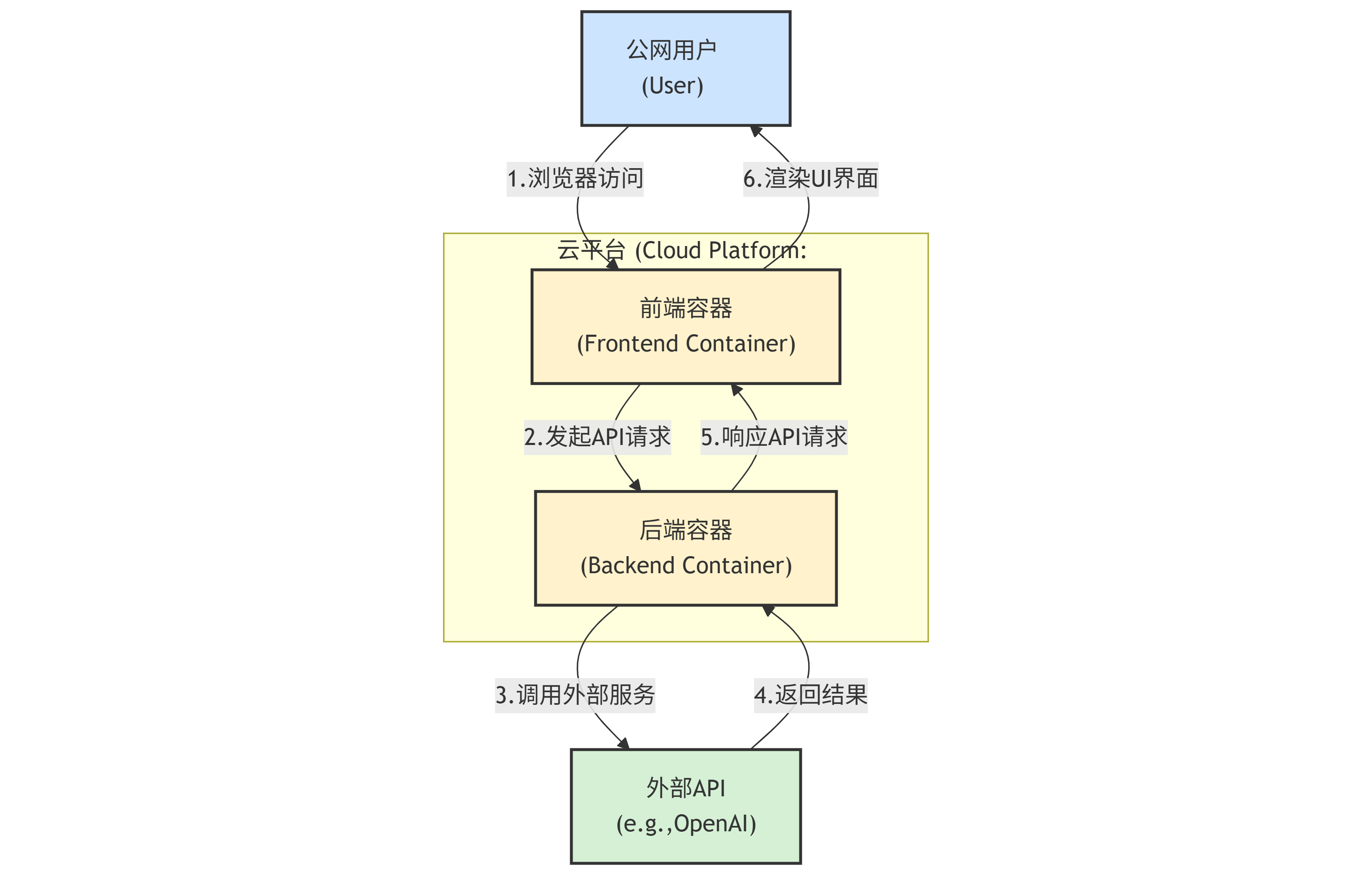
7.5 监控与日志:应用健康的"心电图"
应用上线后,就进入了"养娃"阶段。娃会不会生病?会不会哭闹?你得时刻盯着。
- 日志 (Logging) :
- 记什么? 关键操作(谁登录了)、API请求与响应、错误信息(Traceback)、AI模型的输入输出。
- 原则 : 日志不是
print(),要使用Python的logging模块,输出结构化的信息(比如JSON格式),方便后续的分析和检索。
- 监控 (Monitoring) :
- 监控什么? CPU/内存使用率、API响应时间、错误率、Token消耗量。
- 为什么重要? 监控能让你在用户发现问题前,就提前预警。比如API响应突然变慢,可能就是模型提供商那边出问题了。
- 神器推荐:LangSmith
- 对于开发AI应用,尤其是基于LangChain的应用,我必须强烈安利LangSmith。
- 它就像是专门为LLM应用打造的"Chrome开发者工具"。你能清楚地看到一个请求进来后,在你的Chain或Agent内部每一步的执行情况、耗时、输入输出。
- 哪个环节出错了?哪个Prompt效果不好?哪个Tool调用失败了?在LangSmith里一目了然。这在调试复杂的AI逻辑时,简直是救命稻草!
好了,这一章的内容有点硬核,但相信我,这些知识的价值,在你第一个线上应用遇到问题时,就会立刻体现出来。
我们从一个只能在自己电脑上孤芳自赏的脚本,一路走来,把它变成了一个拥有独立API、前后端分离、被Docker打包、可以部署到云端、并且有基本监控的"正规军"。
这,就是从开发者到工程师的蜕变。下一章,我们将探讨更高级的话题,比如如何持续集成/持续部署(CI/CD),以及如何对我们的AI应用进行评测和优化。
路漫漫其修远兮,但每一步都让我们离打造出真正牛逼的AI应用更近。我们下期见!