文章目录
- [Week 15: 深度学习补遗:集成学习初步](#Week 15: 深度学习补遗:集成学习初步)
Week 15: 深度学习补遗:集成学习初步
摘要
本周主要继续跟随了李宏毅老师学习了集成学习有关的知识,围绕集成学习的思想、Bagging和Boosting重新组织数据集的基本思想等进行了基本的了解。
Abstract
This week, I primarily continued studying ensemble learning concepts under Professor Hung-yi Lee's guidance. I gained a foundational understanding of the core principles of ensemble learning, including the underlying philosophy, as well as the fundamental approaches to reorganizing datasets for Bagging and Boosting techniques.
1. Ensemble 集成学习
模型通常有两种评价标准:Bias 偏差 与 Variance 方差,Bias代表与目标之间的偏差程度,Variance代表偏差程度的稳定性。Bagging的基本思想是,利用预测结果Variance大但是Bias小的一组模型进行结果的平均,最后给出一个相对准确的结果,虽然每个模型单独拿出来看Variance较大,但在将其集合起来后,Variance会缩小、同时Bias仍然会保持较低的水平。
2. Bagging
Bagging的思想是,在总共的 N N N个训练数据中,每次取 N ′ N' N′笔数据组成一个新的数据集,通常来说使用有放回抽取的方法,因此通常情况下可以使 N = N ′ N=N' N=N′,因为在有放回的情况下,可能会反复抽到同一个数据,因此两个数据集并不会相同。
因此,通过 n n n个数据集,找出了 n n n个函数,在测试的时候,把测试数据输入这 n n n个数据集里,将得出来的结果做平均或者Voting,通常就会使结果更鲁棒、Variance更小,即性能更佳,更不容易过拟合。如果是运用在回归问题,通常采用平均的方法;如果运用在分类问题,则通常采用Voting的方法。
Bagging通常在模型非常复杂,担心模型过拟合时才采用(比如决策树),最终目的是降低Variance。
3. Decision Tree 决策树
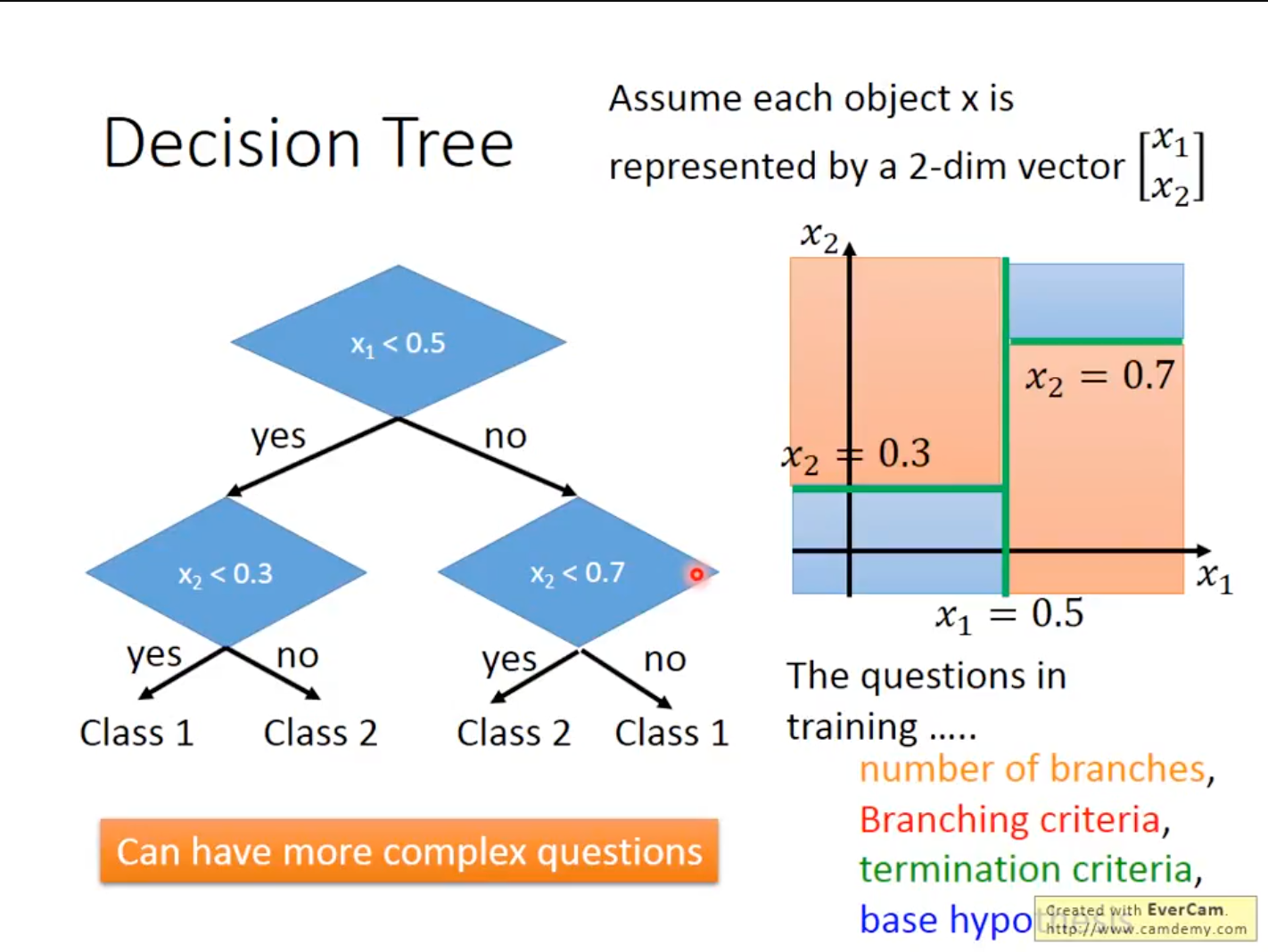
决策树简单来说就是一个用测试数据建成的树,在某个参数满足某个条件时进入其中分支。但决策树在训练中实际上有很多的问题,比如到底需要构建多少分支、分支产生的标准是什么、分支终止的标准是什么、决策树构建分支的基本假设都是什么等等。
在决策树上,永远可以构建出一个足够深的树将训练集的错误率降到0,相当于每一个点都在一个很深的树上面的一个节点。
因此提出了随机森林的方法,随机森林是决策树的Bagging方案。可以采用普通的Bagging方法对决策树进行Ensemble,但是会出现生成的树都差不多的问题,因此对某些特征或者问题进行随机限制,让每个树随机的不能使用某种特征/某个问题,最后将每个树的结果都结合起来,就组成了随机森林。
而使用Bagging时,可以不将数据集分割成验证集与训练集,而直接使用Out-of-bag Validation的方法,即是将当前树未使用的数据直接当做测试集来测试当前树,最后将所有树的Out-of-bag (OOB) Error平均,得到一个随机森林的OOB Error。
需要注意的是,随机森林本质上是Bagging,和Bagging一样,它并不能帮助模型拟合训练集,其作用主要是帮助提升模型鲁棒性。
4. Boosting
Boosting在如果你的机器学习算法可以产色会给你错误率小于50%的分类器时,利用Boosting后可以达到0%的错误率。
Boosting的基本步骤是:
- 找到第一个分类器 f 1 ( x ) f_1(x) f1(x)。
- 找到第二个分类器 f 2 ( x ) f_2(x) f2(x)用来辅助 f 1 ( x ) f_1(x) f1(x)。前提是, f 2 ( x ) f_2(x) f2(x)不能与 f 1 ( x ) f_1(x) f1(x)过于相似,需要让 f 2 ( x ) f_2(x) f2(x)辅助 f 1 ( x ) f_1(x) f1(x)降低Error Rate。
- ...
- 合并所有分类器的结果。
Bagging的分类器是没有顺序的,可以并行处理,但Boosting的分类器是Sequential的,必须按顺序进行训练和预测。训练不同的分类器需要不同的数据集,有一种新的数据集组织方式,就是给每一个数据分配一个权重,在不同的权重下,同一个数据集可以被组织为不同的两个,其损失函数就会经历如下变化。
L ( f ) = ∑ n l ( f ( x n ) , y n ^ ) → L ( f ) = ∑ n u n l ( f ( x n ) , y n ^ ) L(f)=\sum_n l(f(x^n),\hat{y^n})\to L(f)=\sum_n u^nl(f(x^n),\hat{y^n}) L(f)=n∑l(f(xn),yn^)→L(f)=n∑unl(f(xn),yn^)
即权重越高的数据就会被考虑的更多。
总结
本周主要学习了集成学习相关的初级知识,基本了解了Bagging和Boosting技巧的基本思想,同时对决策树以及随机森林的基本理论有了一定的了解。Bagging和Boosting是LLM训练中的重要技巧,下周准备对集成学习相关知识继续进行深入的学习。