SeaTunnel 是一个非常易用、超高性能的分布式数据集成平台,支持实时海量数据同步。 每天可稳定高效地同步数百亿数据,已被近百家企业应用于生产,在国内较为普及。
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的云原生湖仓。
SeaTunnel 架构
SeaTunnel 整体架构:
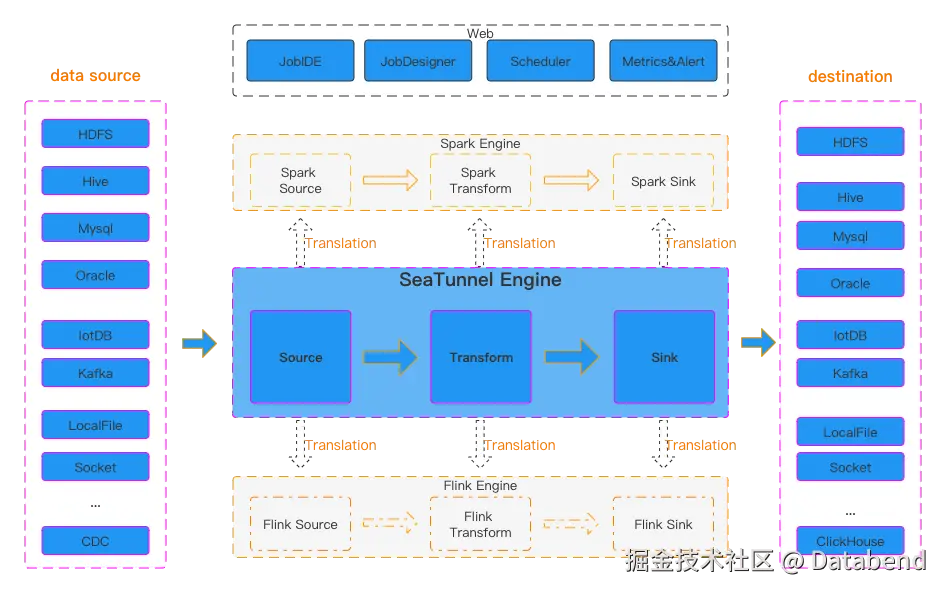
本文将使用 SeaTunnel 建立从 MySQL 到 Databend 的数据同步管道,实现从 MySQL 数据源同步数据到 Databend 目标表的目的。
SeaTunnel MySQL-CDC 和 Databend Sink Connector
SeaTunnel 的 MySQL CDC 连接器允许从 MySQL 数据库中读取快照数据和增量数据,其实现的原理是基于 debezium-mysql-connector 。
而 Databend 在 PR FeatureConnector-V2 Support databend source/sink connector 之后也同时在 SeaTunnel 中支持了 Databend 作为 Source 和 Sink Connector。这里我们使用 SeaTunnel 的 MySQL-CDC Source Connector 和 Databend Sink Connector 来搭建数据同步管道。
编译 SeaTunnel
由于上述 Databend Connector 的 PR 刚合并入 SeaTunnel 的 dev 分支,还没有正式 release,所以目前要使用 Databend Connector 的话,需要基于源码对 SeaTunnel 进行构建。
Clone 源码
首先我们需要从 GitHub 克隆 SeaTunnel 源代码。
bash
git clone git@github.com:apache/seatunnel.git本地安装子项目
在克隆源代码之后,需要运行 ./mvnw 命令将子项目安装到 maven 本地存储库。否则代码无法在 JetBrains IntelliJ IDEA 中正确启动。
bash
./mvnw install -Dmaven.test.skip构建 SeaTunnel
安装 maven 后,可以使用以下命令进行编译和打包。
ini
mvn clean package -pl seatunnel-dist -am -Dmaven.test.skip=true构建后的内容在 seatunnel/seatunnel-dist/target 中,我们需要解压 apache-seatunnel-2.3.12-SNAPSHOT-src.tar.gz,得到如下目录:

bin 下面是可以直接运行的 shell 脚本,能够一键启动 SeaTunnel;
config 中是 jvm options 相关的配置文件;
lib 中是运行 SeaTunnel 或者 connector 相关的 jar 包。
创建 connector 配置文件
我们的任务设定是通过 SeaTunnel 从 MySQL 中同步 mydb.t1 表。 配置文件 为 mysql-to-databend.conf:
ini
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://127.0.0.1:3306/mydb"
username="root"
password="123456"
table-names=["mydb.t1"]
startup.mode="initial"
}
}
sink {
Databend {
url = "jdbc:databend://127.0.0.1:8000?presigned_url_disabled=true"
database = "default"
table = "t1"
username = "databend"
password = "databend"
# 批量操作设置
batch_size = 2
# 如果目标表不存在,是否自动创建
auto_create = true
}
}相关的参数设定可以参考 seatunnel MySQL文档 和 seatunnel Databend Connector。
本地启动 MySQL 与 Databend
启动并初始化 MySQL 表数据
本地启动 MySQL 后,创建一个数据库 mydb,在 mydb 中新建一张表并插入 10 条数据:
sql
create database mydb;
use mydb;
create table t1 (a int, b varchar(100));
insert into t1 values(1,'aa')
...
insert into t1 values(10,'bb')本地启动 Databend
yaml
version: '3'
services:
databend:
image: datafuselabs/databend:v1.2.754-nightly
platform: linux/arm64
ports:
- "8000:8000"
environment:
- QUERY_DEFAULT_USER=databend
- QUERY_DEFAULT_PASSWORD=databend
- MINIO_ENABLED=true
volumes:
- ./data:/var/lib/minio
healthcheck:
test: "curl -f localhost:8080/v1/health || exit 1"
interval: 2s
retries: 10
start_period: 2s
timeout: 1s直接 docker-compose up 即可启动 Databend 服务。
启动 SeaTunnel
bash
./bin/seatunnel.sh --config ./bin/mysql-to-databend.conf -m local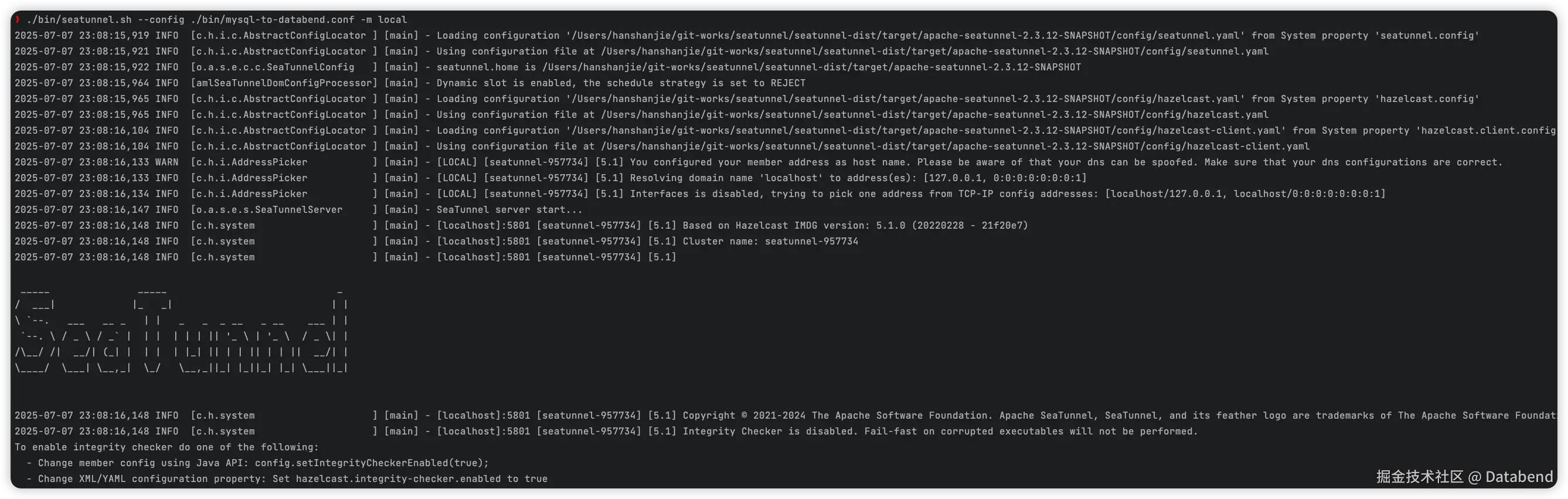
启动后 Databend Sink Connector 会首先将 MySQL 表中的全量数据同步过来:
接下来我们往 MySQL 中插入几条数据,就会同步 MySQL 中增量的数据:

可以看到 SeaTunnel 在终端输出的日志:
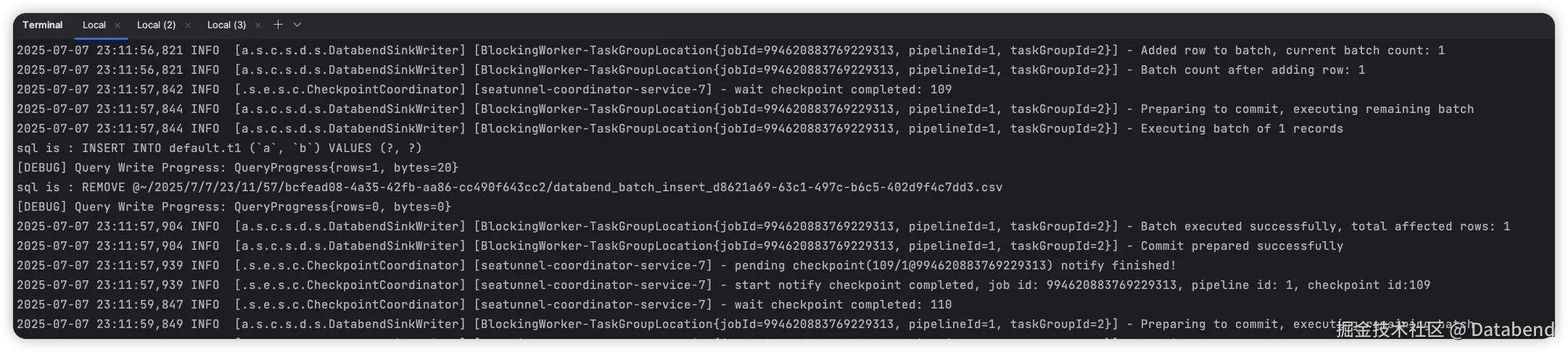
以及 Databend 中查询到数据:
说明数据已经及时同步过来了。
目前 Databend Sink Connector 还只支持 Append Only 模式,对于 update、delete 的数据没做处理,会在下一个 seatunnel 的 PR 中实现完整的 CDC 功能。
结论
通过本文我们成功实现了从 MySQL 到 Databend 的实时数据同步管道。这个解决方案具有以下优势:
- 简单易用:SeaTunnel 提供了简洁的配置方式,只需少量配置即可建立高效的数据同步管道。
- 实时性强:基于 CDC 技术,能够实时捕获 MySQL 的数据变更并同步到 Databend。
- 可扩展性好:SeaTunnel 的分布式架构使其能够处理海量数据同步需求。
- 低开发成本:无需编写复杂的 ETL 代码,通过配置文件即可完成数据集成任务。
需要注意的是,目前 Databend Sink Connector 还只支持 Append Only 模式,对于 update、delete 的数据没做处理,完整的 CDC 功能将在后续的 PR 中实现。这个方案特别适合需要将 MySQL 数据实时同步到 Databend 进行分析的场景,帮助企业构建实时数据湖仓架构。