文章目录
一、概述
二、实战
1.准备:
使用的虚拟机是roucky8,需要下载java,rqm四个包
可以在/etc下找到

使用rpm -ivh *.rpm 安装所有
实验开始前确保时间正确
如果时间不正确修改时间
vim /etc/chrony.conf
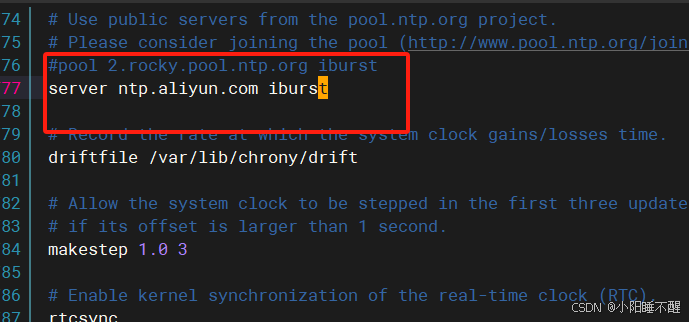
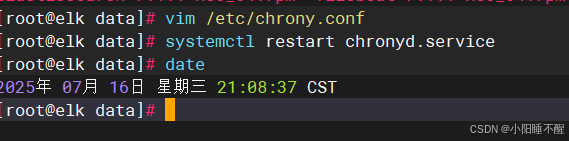
2.配置文件
第一个文件:vim /etc/hosts
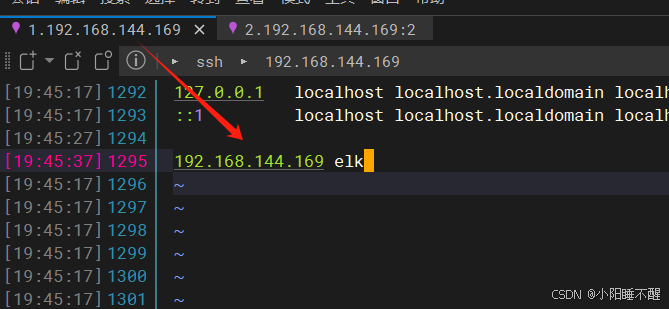
第二个文件 :cd etc/elasticsearch/
vim elasticsearch.yml
需要修改的地方:
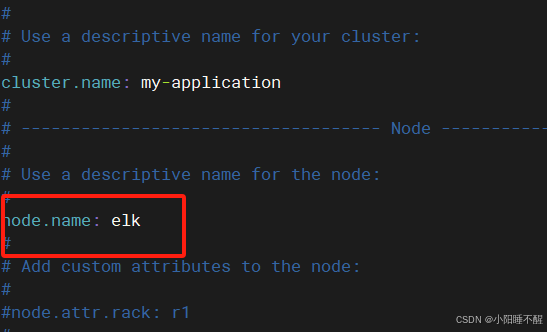
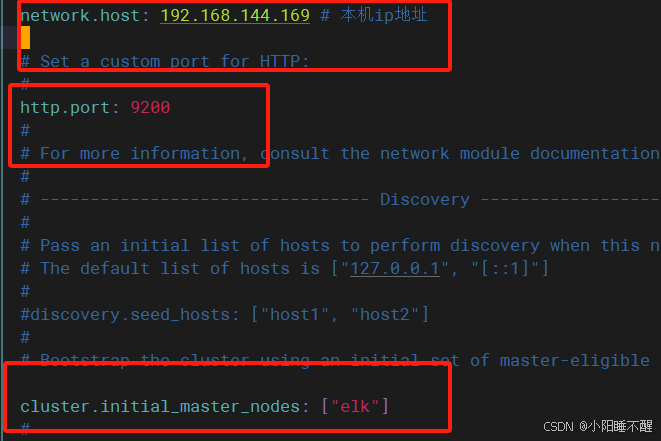
启动服务并查看java状态

logstash安装在了 /usr/share/logstash/这里
ln -s
pwd/logstash /usr/local/bin/
第三个文件: vim /etc/kibana/kibana.yml
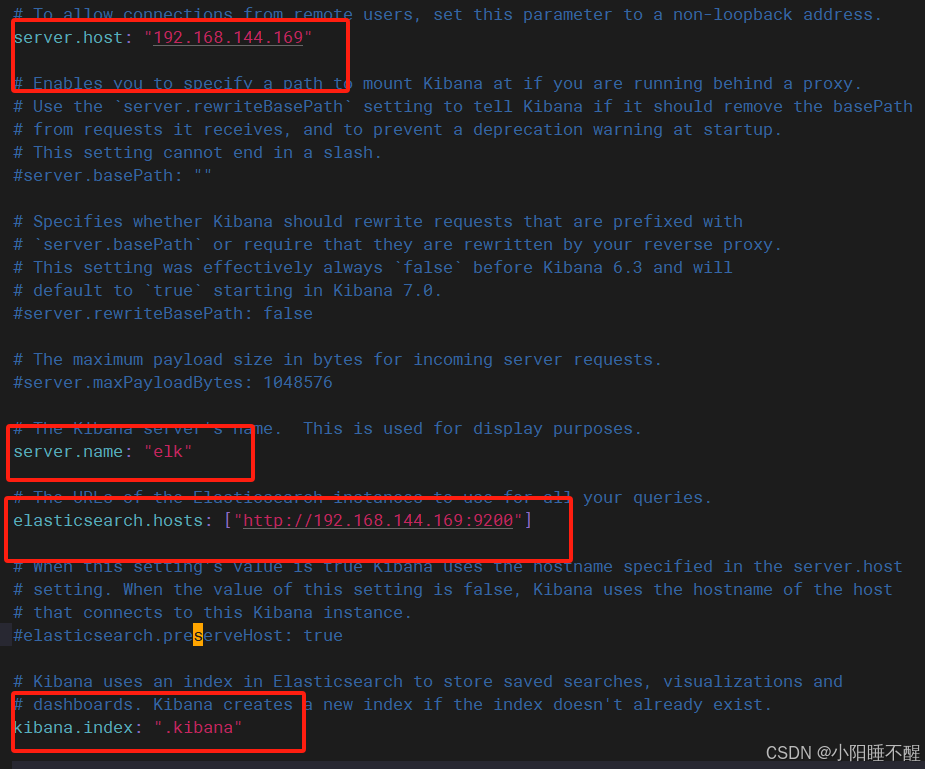
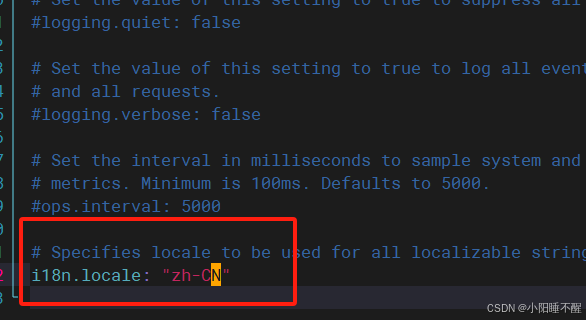
第四个文件:vim /etc/logstash/conf.d/pipline.conf
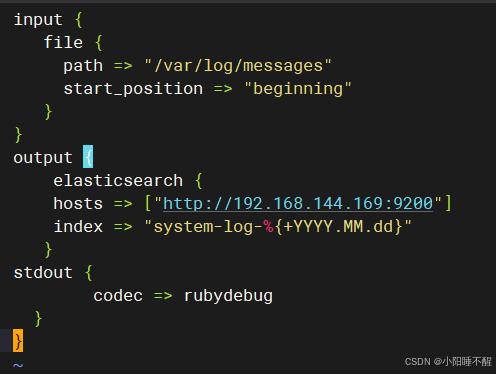
配置好后启动服务
systemctl start kibana.service
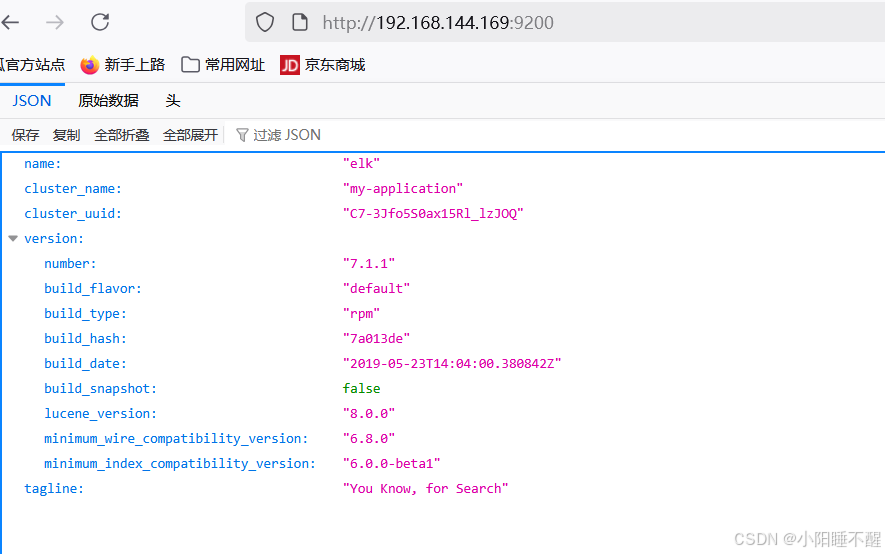
查看节点信息:
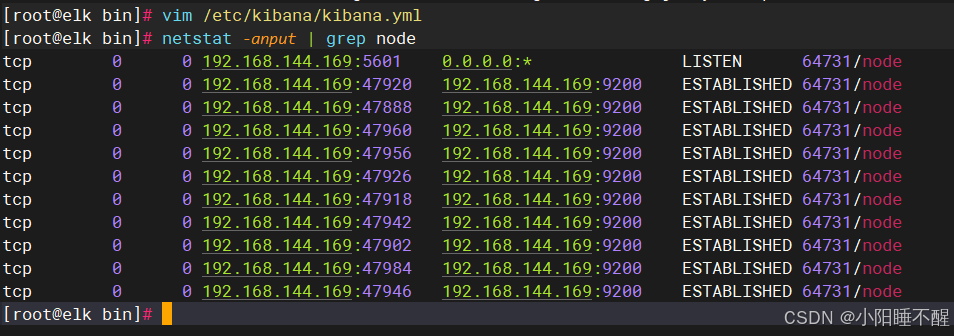
3.测试logstash服务的数据传输
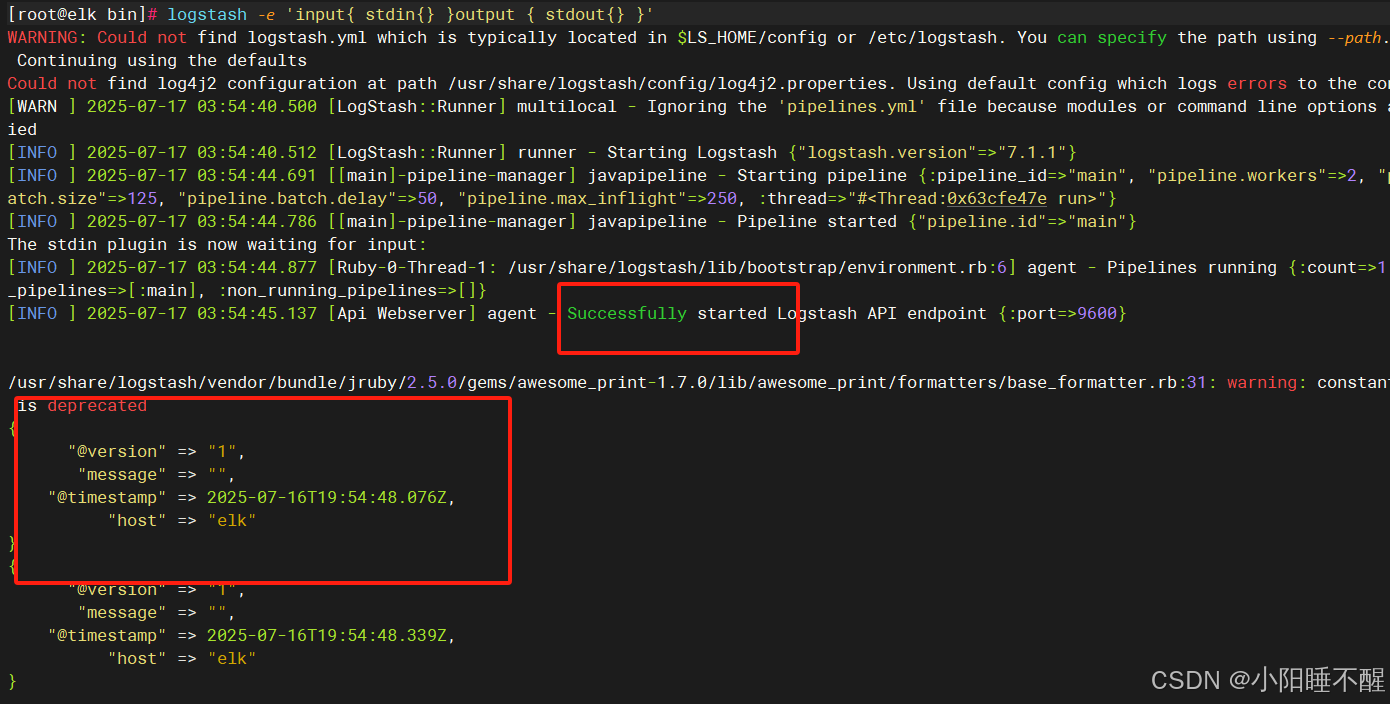
##标准输入与输出
root@logstash \~# logstash -e 'input{ stdin{} }output { stdout{} }'
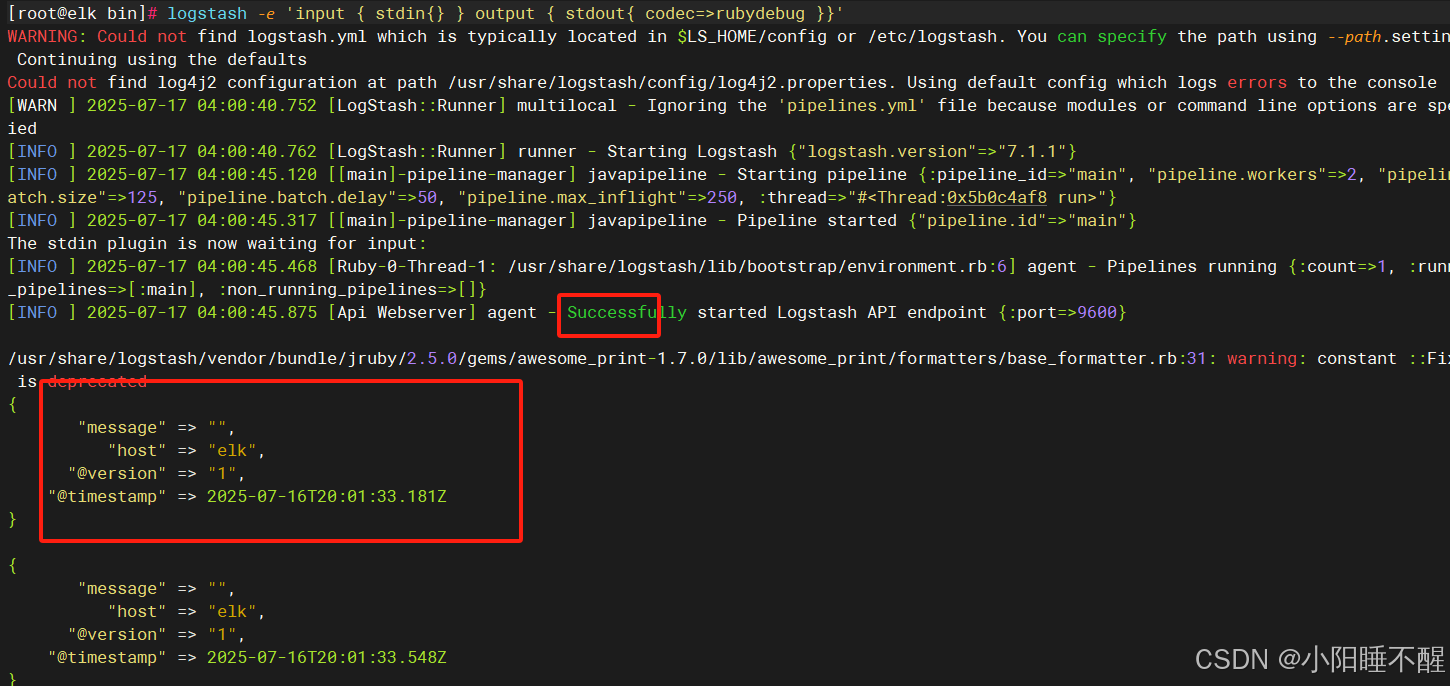
##使用rubydebug解码
root@logstash \~# logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'
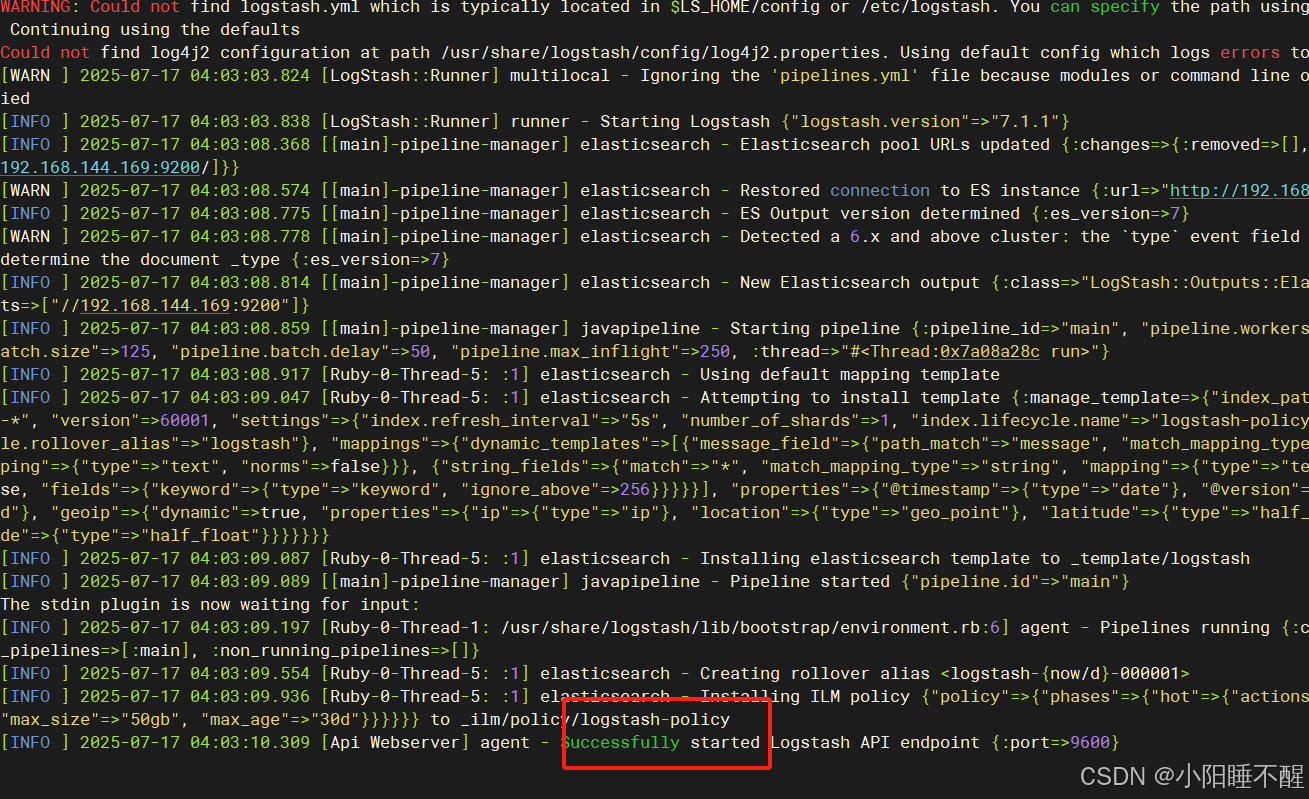
##输出到elasticsearch
root@logstash \~# logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>"192.168.144.169:9200"} }'
4.验证
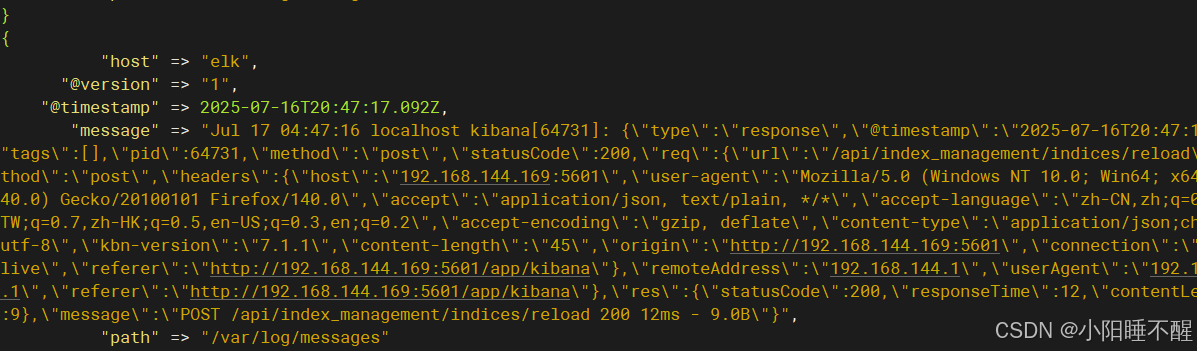
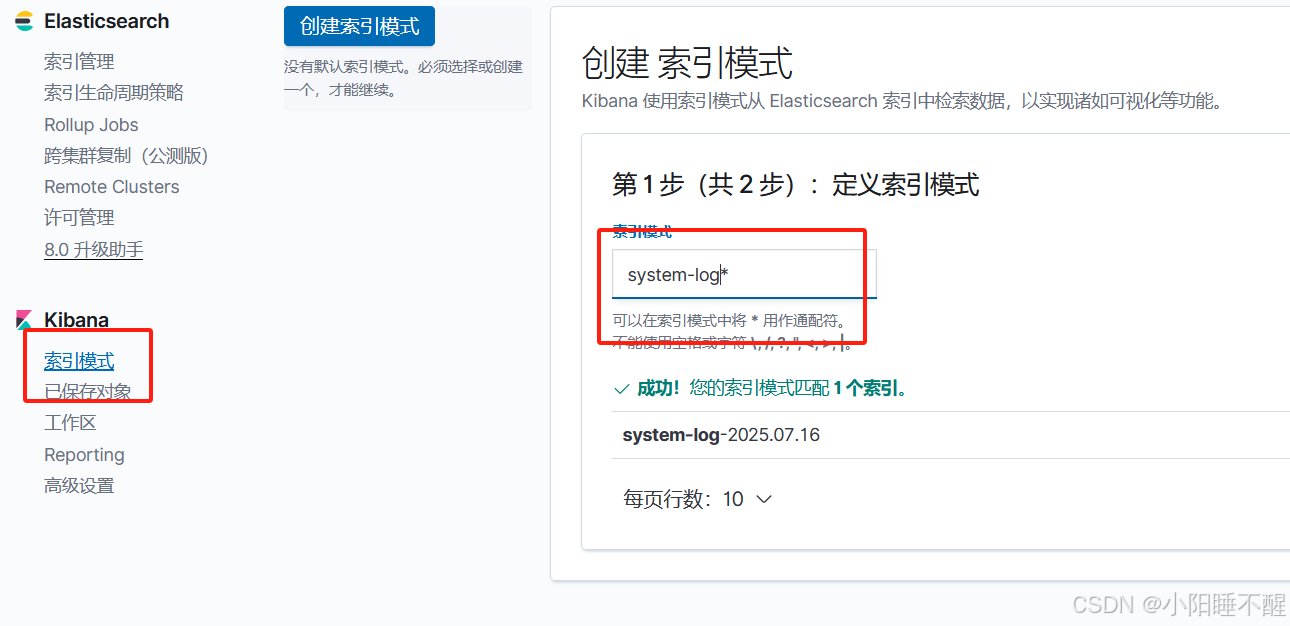
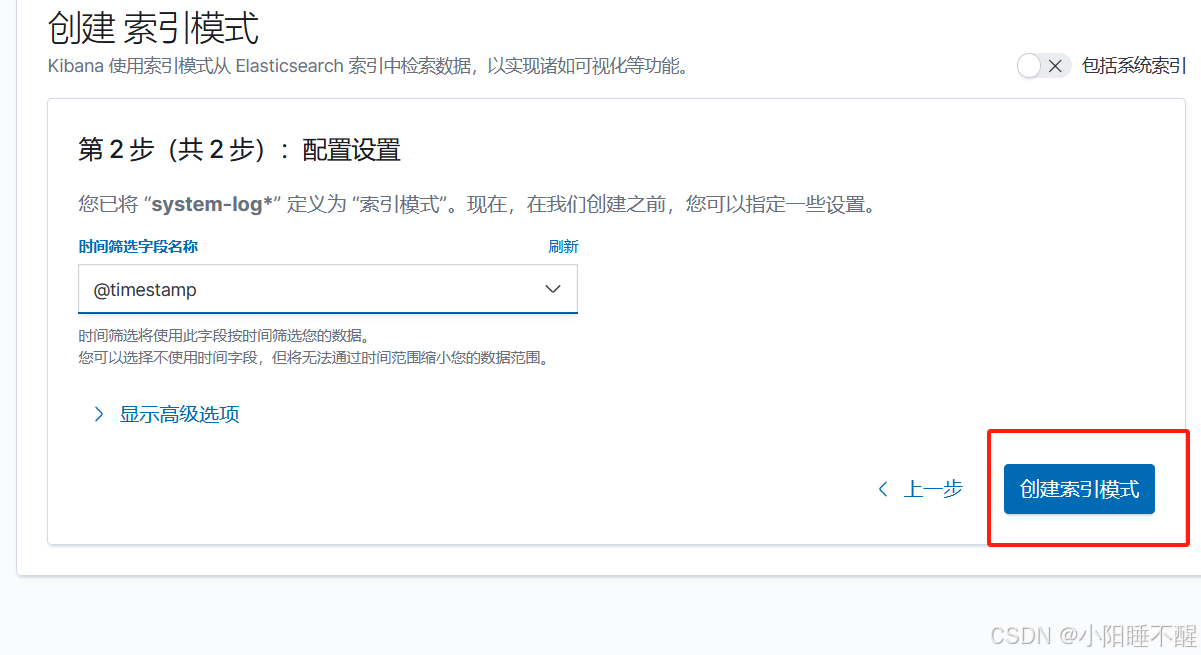
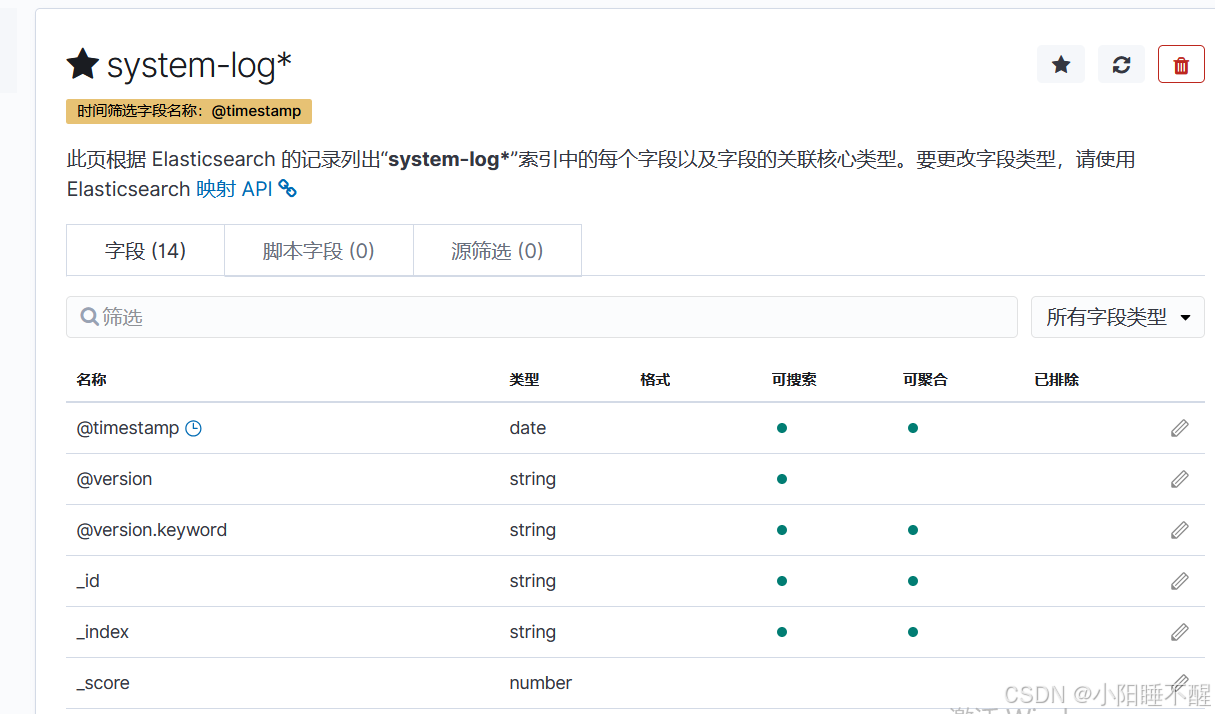
添加索引:
logstash -f /etc/logstash/conf.d/pipline.conf
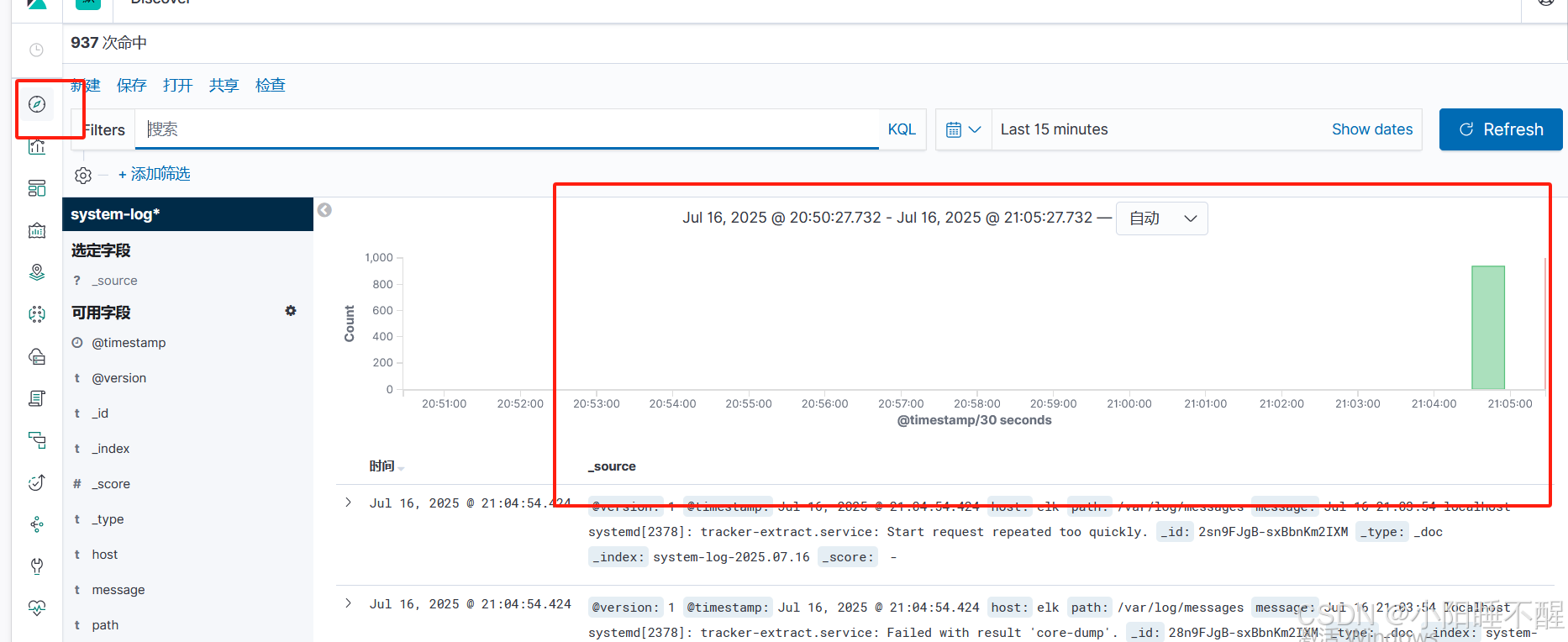
访问kibana
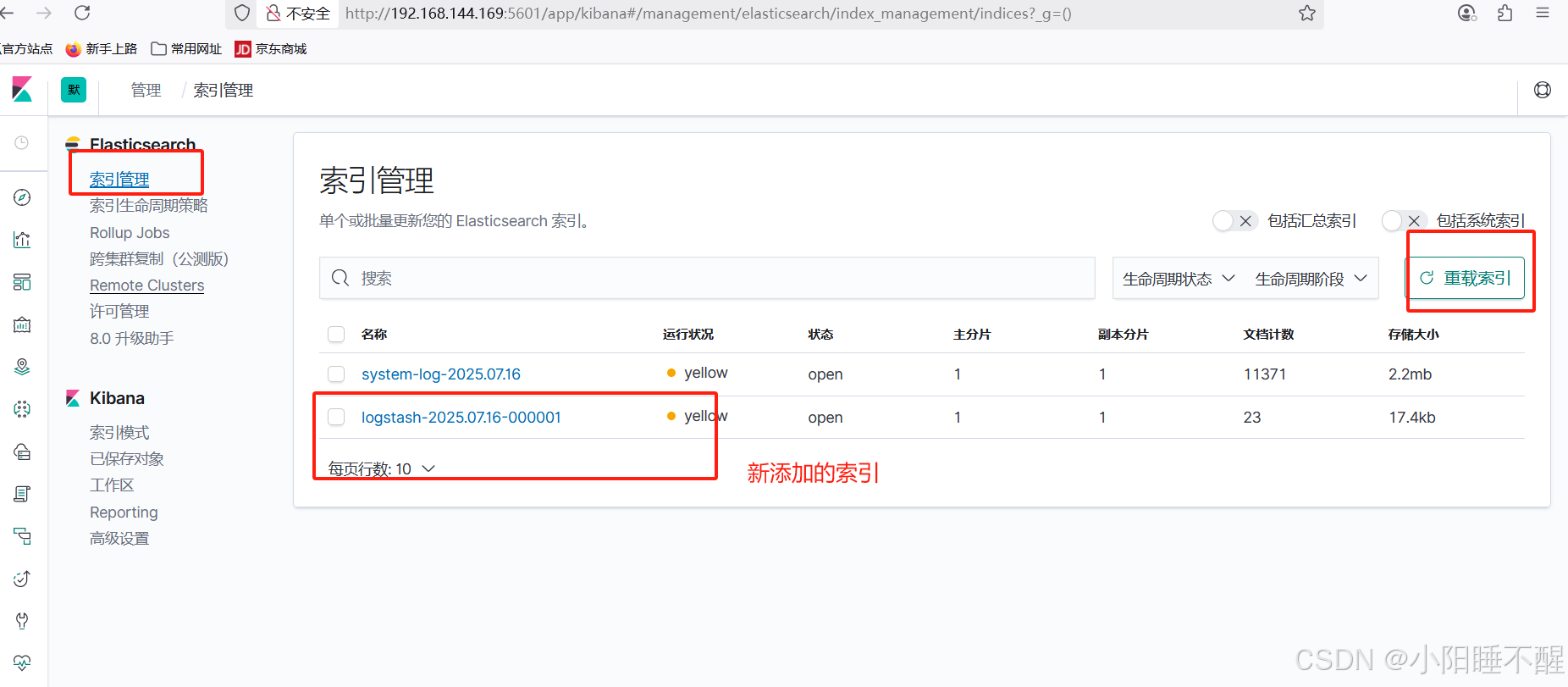
生成图表:
总结
提示:理论部分比较杂,后续会整理好
实战部分希望可以帮助到其他小伙伴们