同事的设备玩两天,想试试看能不能复刻GLM-4.7-UD-IQ1-M量化模型部署,以下是实验过程:
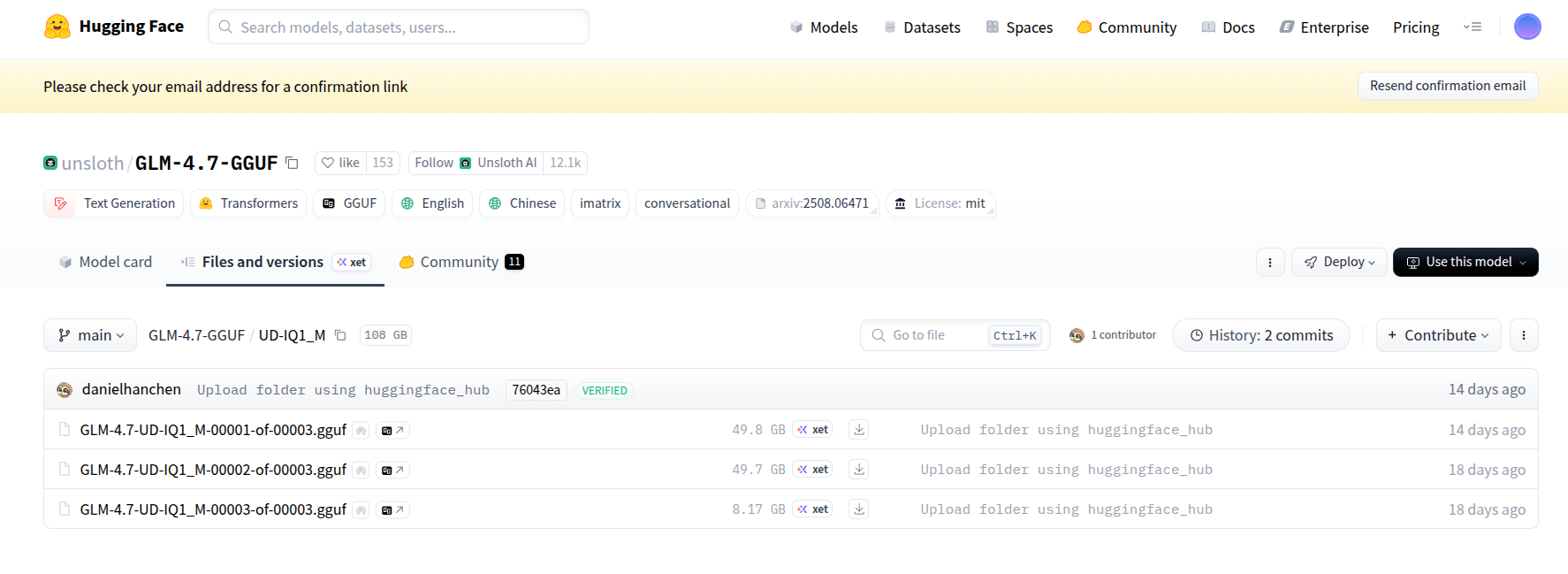
网址:https://huggingface.co/unsloth/GLM-4.7-GGUF/tree/main/UD-IQ1_M
先搞明白如下:
1.三个分卷GGUF(101GB)是超大模型文件的分卷拆分版本。
拆分的目的: GLM-4.7模型的UD-IQ1_M量化版总大小高达101GB,如果做成一个单独的 GGUF 文件,会带来两个严重问题,一是传输风险高,网络稍有波动就会下载失败,且无法精准断点续传(只能从头重新下);二是存储/操作不便,单个 101GB 文件对文件系统、传输工具要求更高,容易出现如文件损坏、无法复制等问题;将其拆分成 3 个大小均匀的分卷文件,方便下载、存储和分享。
分卷文件的核心性质:缺一不可 ,这 3 个文件是完整模型的分片,必须全部下载完成,且放在同一个目录下 ,才能被如Cherry Studio等工具识别和使用(单独一个或缺少一个,都无法启动模型);无需手动合并 ,你不用像解压分卷压缩包那样手动合并它们,Cherry Studio、Ollama 等支持 GGUF 格式的工具,会自动识别这是分卷文件,加载时自动整合为完整模型,无需你做额外操作;格式不变:它们依然是GGUF量化格式,只是拆分了存储,功能和单个GGUF 文件完全一致,只是体积更大,对应的回复质量、细节丰富度更高(但对硬件要求也更高)。
文件名含义:00001-of-00003就是"第1个,共3个"的意思,用于标记分卷序号,确保工具能正确识别整合顺序。
2.101GB的UD-IQ1_M量化版是高保真量化、近无损量化,体积大、内存占用高(约 80-90GB),但回复质量更接近原版未量化模型,细节更丰富,适合对回复质量要求高的场景,如写长文、复杂推理等。
3.git clone不能直接完整下载,其先天限制是无法直接克隆大文件,git clone是Git工具的默认命令,它的核心功能是克隆普通小文件组成的代码仓,对大文件而言,Git默认不支持直接克隆。hugging face的大文件托管方式依赖特殊工具(即Git LFS/Git Xet),这俩工具是Git的大文件扩展插件,专门用于处理超大文件。直接执行git clone命令时,因未安装并启用这俩插件,Git只会克隆到仓库的目录结构和小文件(如 README.md、分卷文件清单等),会自动跳过托管在Git LFS/Git Xet上的分卷GGUF文件,最终得到的只是一个空架子仓库,没有核心的模型权重文件。
4.这里通过浏览器直接下载并设置权限
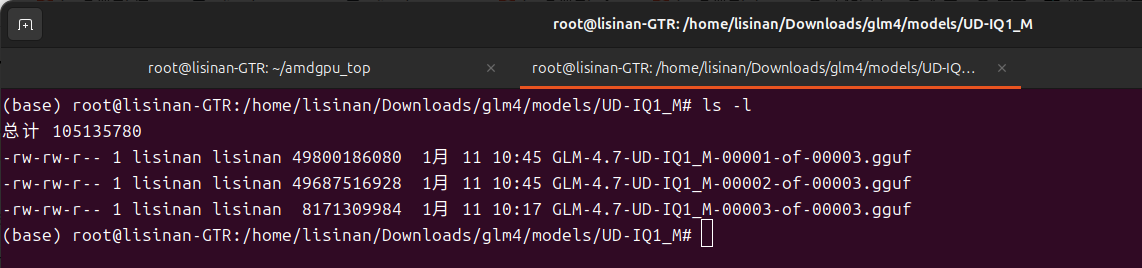
sudo chmod -R 755 /home/lisinan/Downloads/glm4/models/UD-IQ1_M
ls -ld /home/lisinan/Downloads/glm4/models/UD-IQ1_M

llama.cpp是一个轻量级、跨平台的开源项目,专门用于运行 GGUF 格式的大语言模型,无需复杂的深度学习框架(如 PyTorch/TensorFlow)
安装编译llama.cpp需要的工具
sudo apt update -y && sudo apt install -y git gcc g++ make pkg-config libopenblas-dev cmake cmake-curses-gui克隆 llama.cpp 官方仓库
# 进入用户主目录(方便查找,后续可移动)
cd ~/
# 克隆llama.cpp官方仓库(获取源码)
git clone https://github.com/ggerganov/llama.cpp.git
在root用户下配置 Rocm 环境变量
# 编辑环境变量配置文件
vim /etc/profile
# 在文件末尾添加以下两行
export PATH=/opt/rocm/bin:$PATH
export LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
# 保存并退出vim(按Esc,输入:wq,回车)
# 加载环境变量(立即生效,无需重启系统)
source /etc/profile验证Rocm 环境变量是否生效
# 查看Rocm版本(显示版本即生效)
rocm-smi
# 查看Rocm库路径(显示路径即生效)
echo $LD_LIBRARY_PATH编译 llama.cpp(生成可执行文件)
cd ~/llama.cpp
# 进入llama.cpp/build目录,清理旧编译文件
cd /root/llama.cpp/build
rm -rf *
# 重新执行CMake配置(开启ROCm加速,关闭CURL)
cmake .. -DLLAMA_HIPBLAS=ON -DLLAMA_CURL=OFF
# 并行编译(16核CPU,提升速度)
cmake --build . -j 16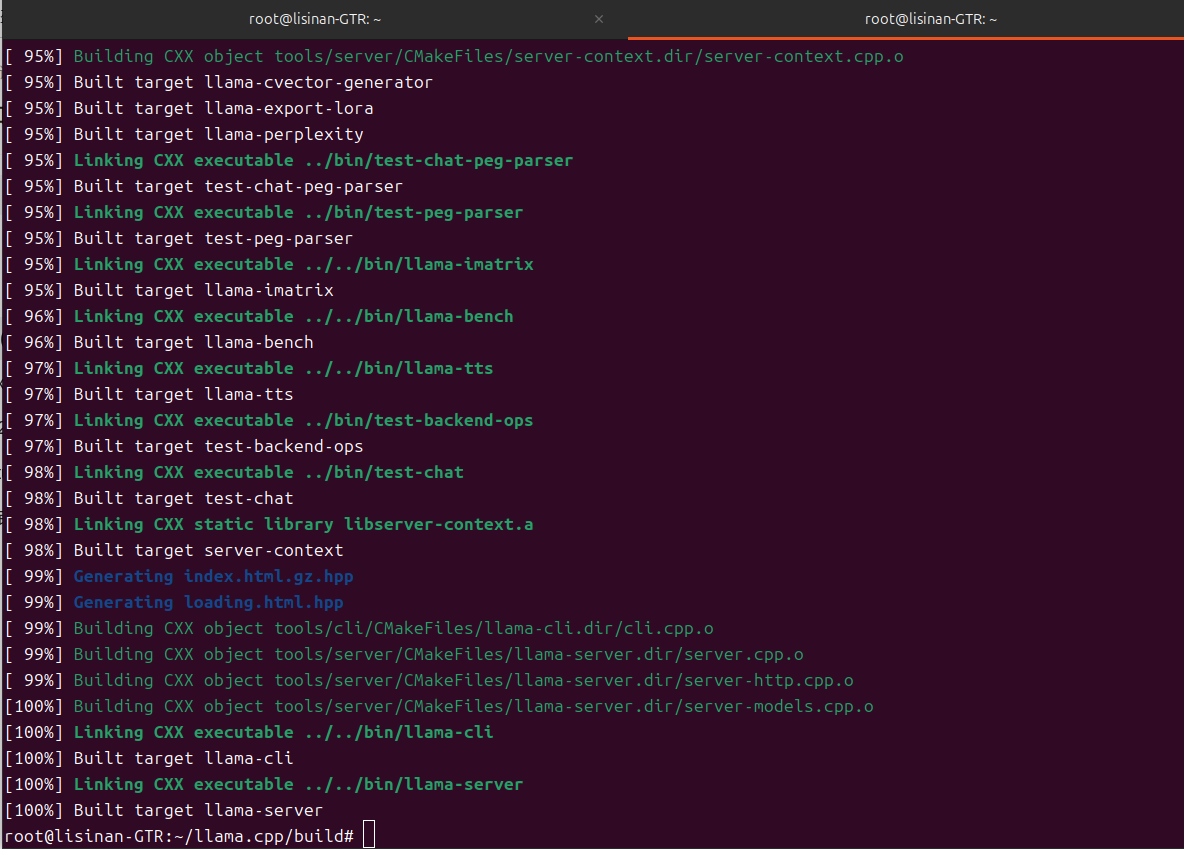
运行llama-server
# 进入bin目录
cd /root/llama.cpp/build/bin
# 复刻实验(更换8888端口)
./llama-server \
-m /home/lisinan/Downloads/glm4/models/UD-IQ1_M/GLM-4.7-UD-IQ1_M-00001-of-00003.gguf \
--host 0.0.0.0 \
--port 8888 \
--ctx-size 30720 \
--n-gpu-layers -1 \
--ubatch-size 2048 \
--flash-attn on \
--no-mmap \
--jinja \
--temp 1.0 \
--top-p 0.95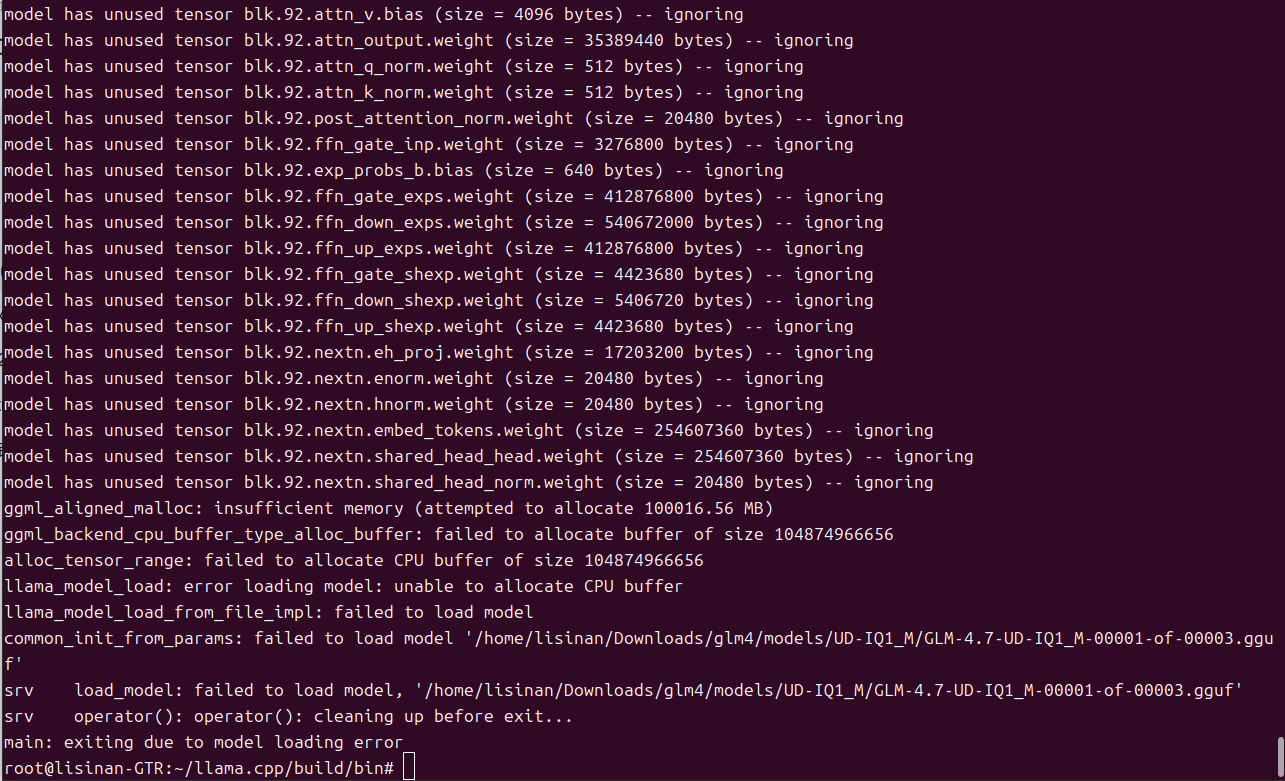
进入了模型核心加载流程,报错内存不足,硬件资源瓶颈。
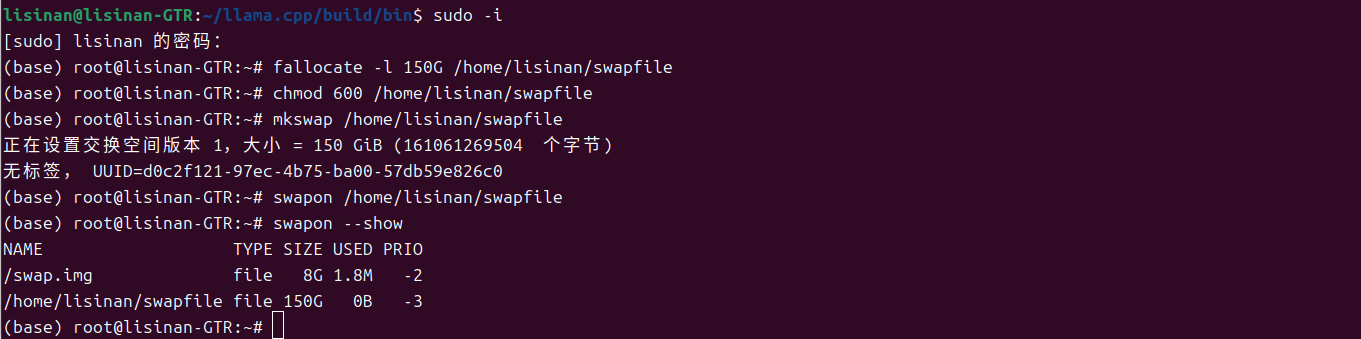
临时启用超大交换分区(虚拟内存)先跑起来, 通过创建超大交换分区(即:将硬盘空间虚拟为内存),补充物理内存不足。但不推荐
创建 150GB 交换文件(补充内存,适配101GB模型)
su - root #切换到 root 用户(创建交换文件需要 root 权限)
fallocate -l 150G /home/lisinan/swapfile #创建 150GB 交换文件
chmod 600 /home/lisinan/swapfile #设置交换文件权限(仅 root 可读写)
格式化交换文件,启用交换分区
mkswap /home/lisinan/swapfile
swapon /home/lisinan/swapfile
验证交换分区是否生效
swapon --show
2、普通用户下加载模型
su - lisinan # 切换到普通用户,我这里是lisinan
cd ~/llama.cpp/build/bin # 进入 bin 目录
加载大模型,利用交换分区补充内存
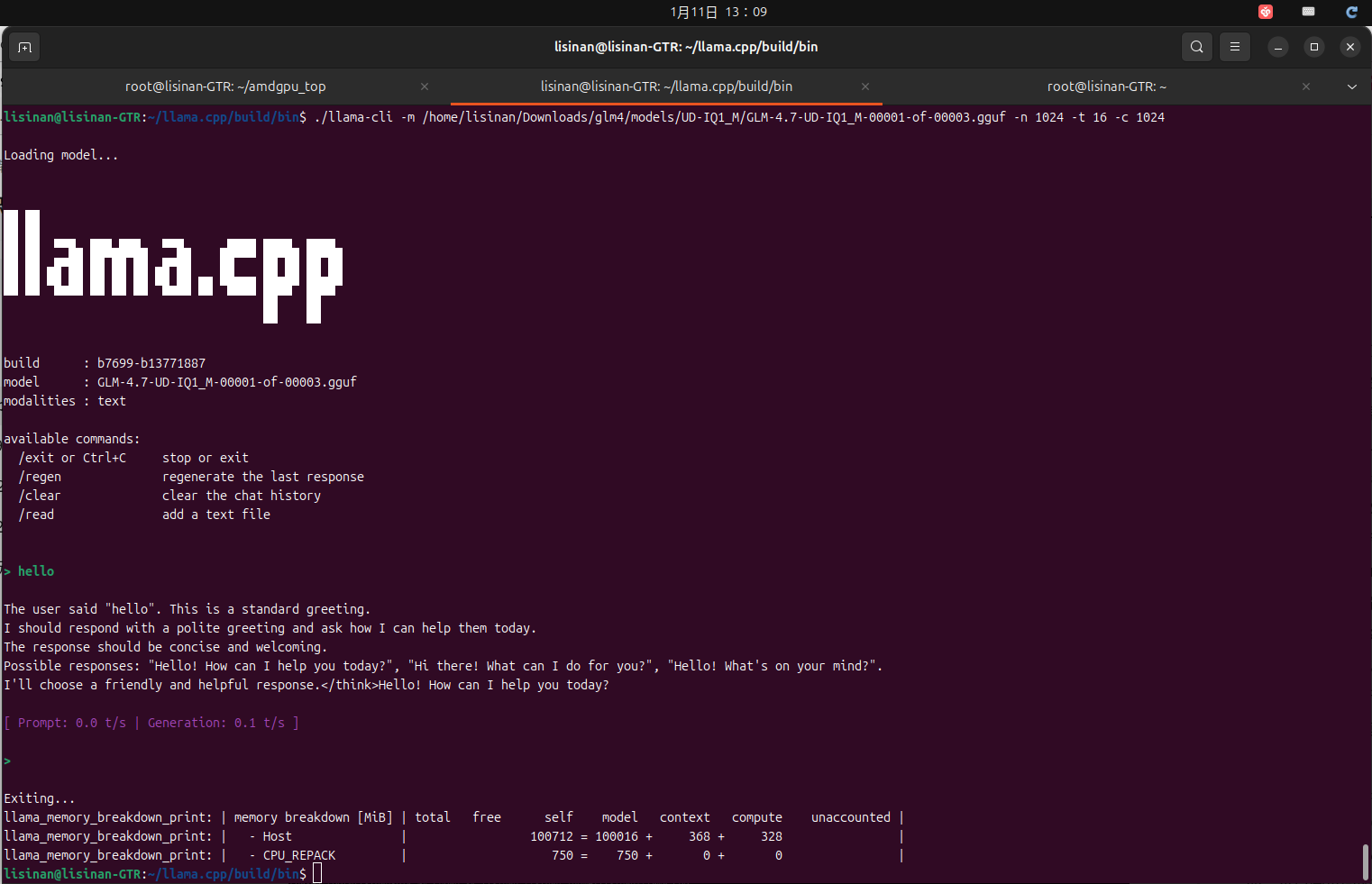
./llama-cli -m /home/lisinan/Downloads/glm4/models/UD-IQ1_M/GLM-4.7-UD-IQ1_M-00001-of-00003.gguf -n 1024 -t 16 -c 1024
注:
1.基于上述硬件情况部GLM-4.7-UD-IQ1-M,速度巨慢无比,加载少说有30分钟以上,推理也巨慢无比,漫长的等待,且耗损 SSD 寿命,临时可用,长期不建议。
2.使用完成后,执行以下命令关闭并删除交换文件
su - root
swapoff /home/lisinan/swapfile
rm -f /home/lisinan/swapfile
以上是基于Max395(ubuntu24.04)AMD显卡复刻GLM-4.7-UD-IQ1-M量化模型部署实验全过程。