目录:
1.虚拟机设置1
2.虚拟机配置2
3.虚拟机配置3
1.虚拟机设置1
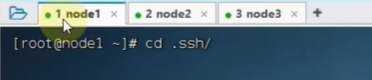
这里只是设置node1,其他两台都一样设置
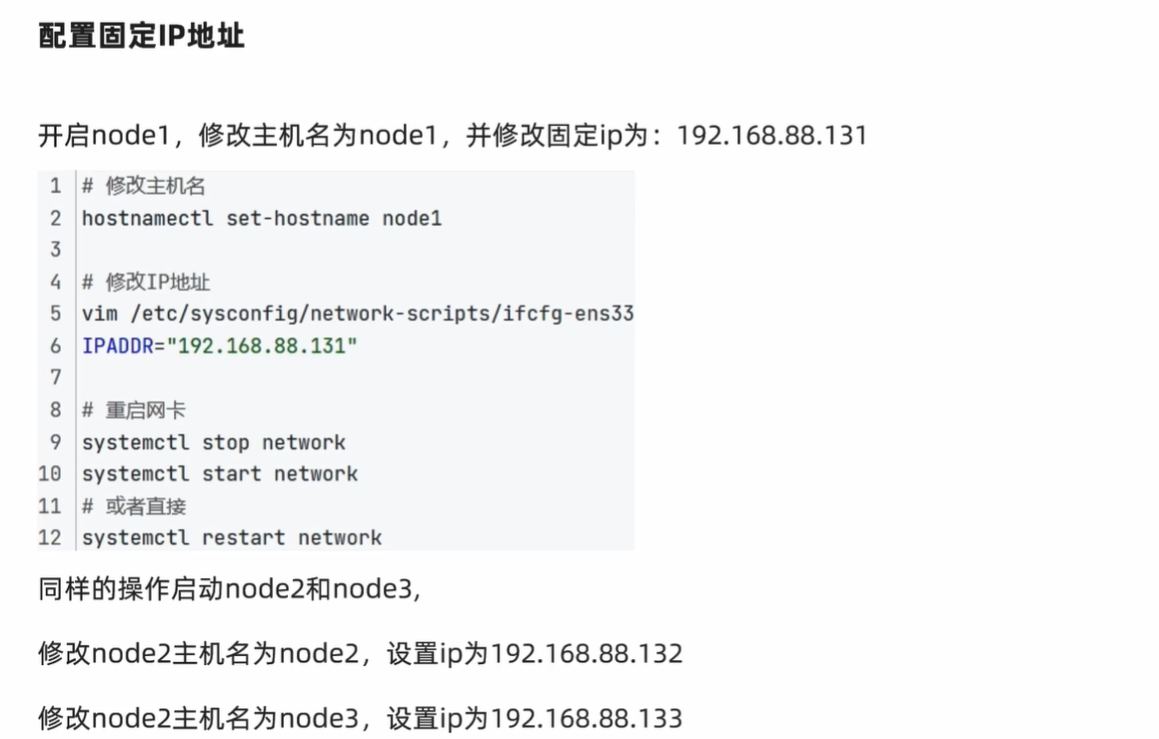
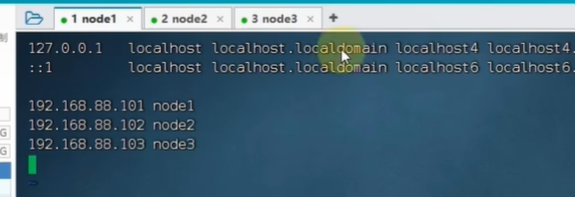
修改主机名
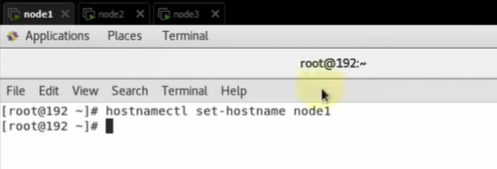
刷新
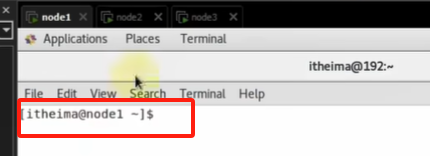
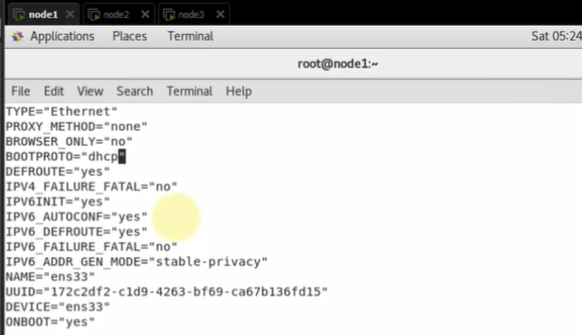
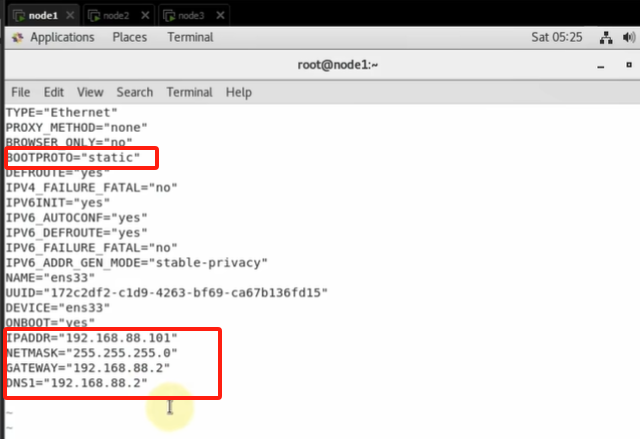
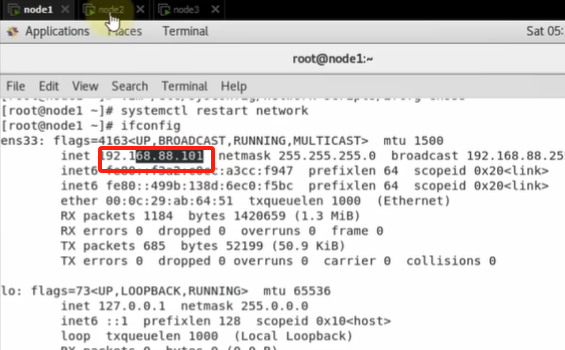
修改ip:

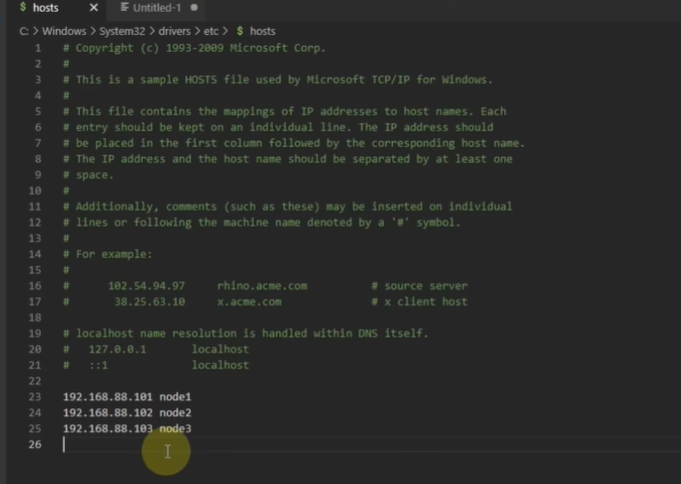
Windows:
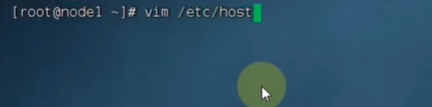
linux:

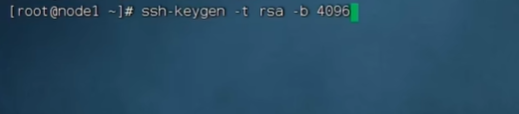
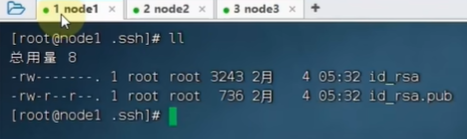
就生成了公钥私钥
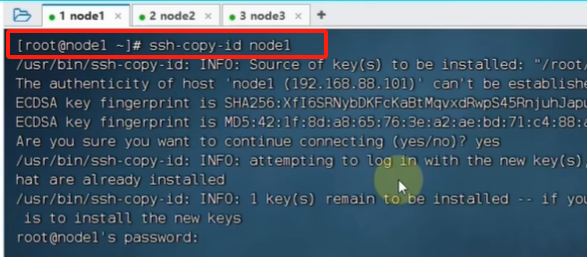
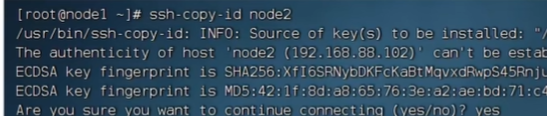
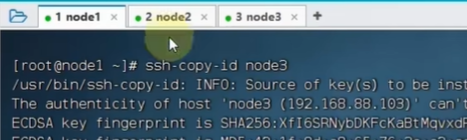
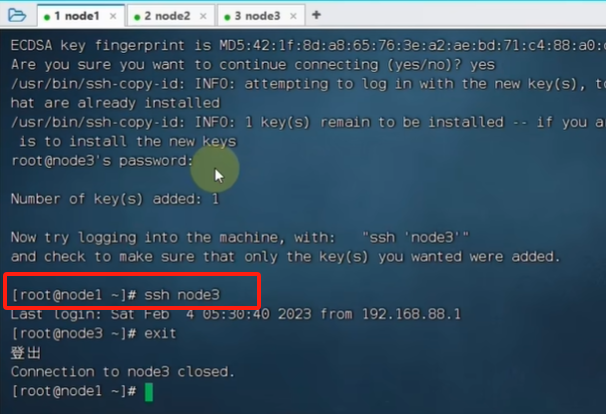
就可以免密登录了:在node1登录node3

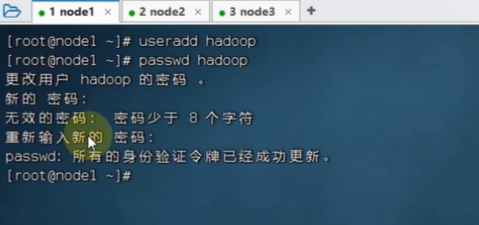

创建公私钥
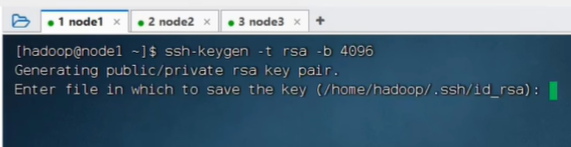
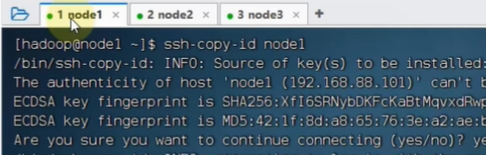
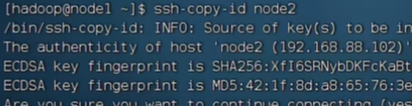
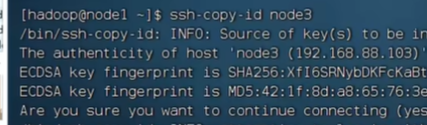
设置完之后,就可以从node1到node2
2.虚拟机配置2

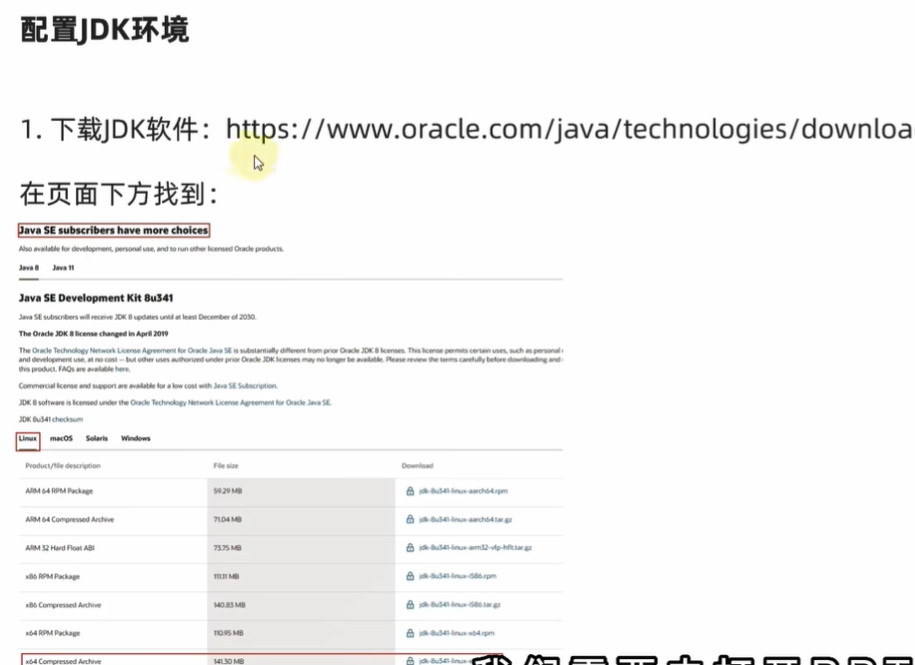



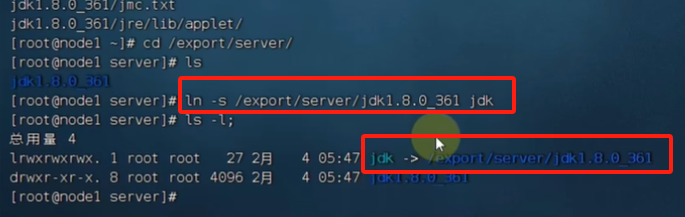
配置软连接
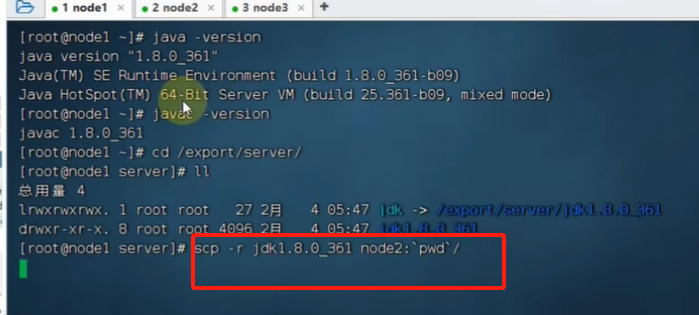
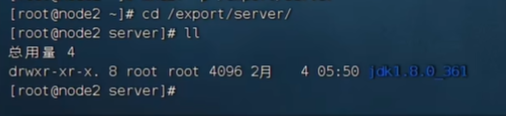
远程复制,从node1到node2:

3.虚拟机配置3
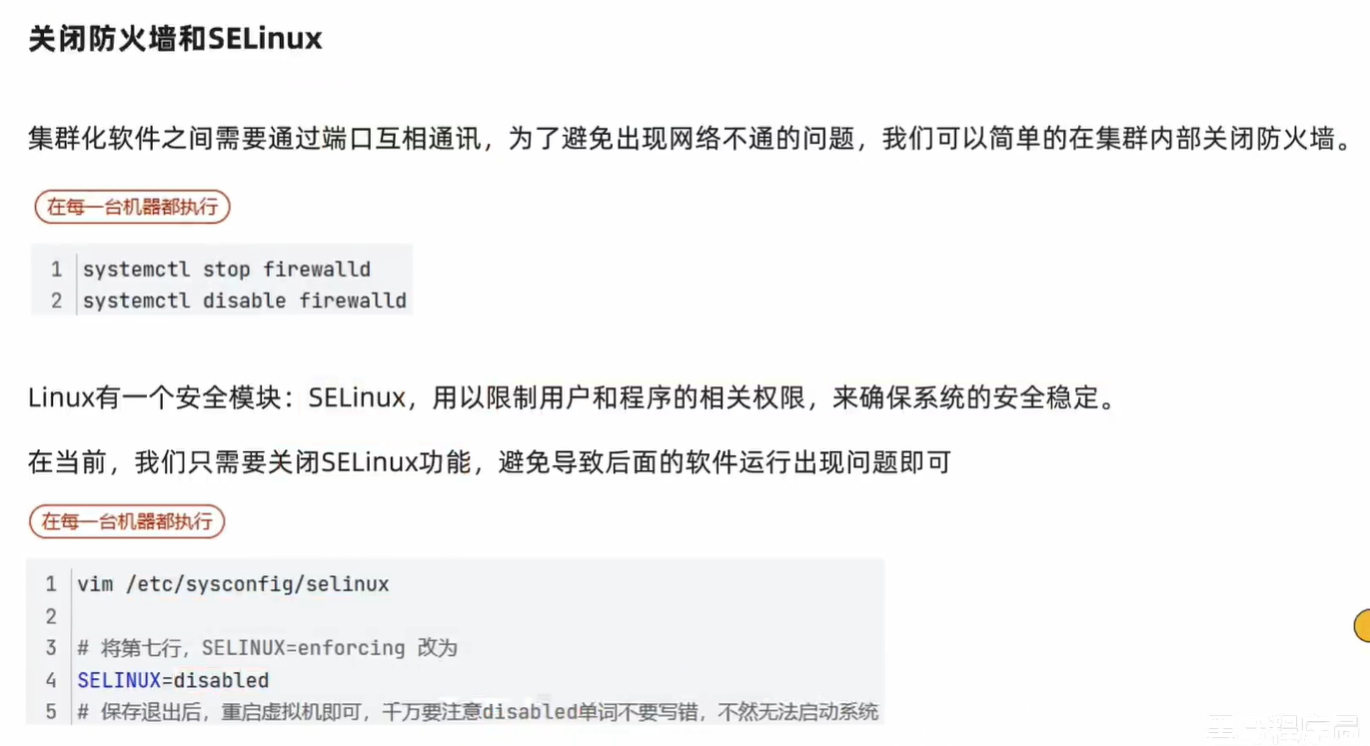
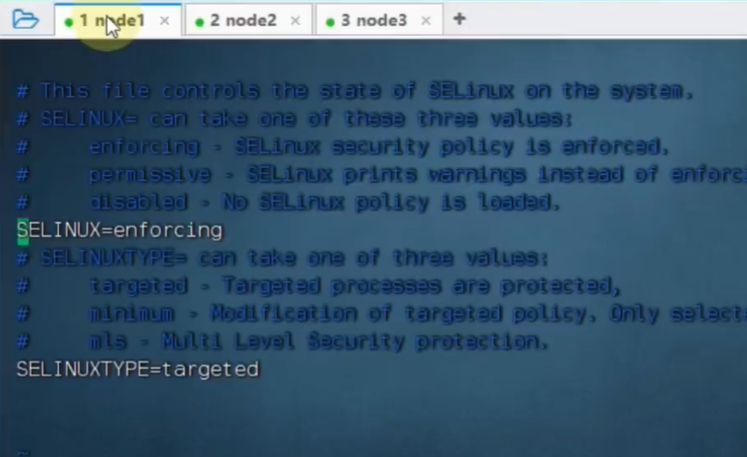
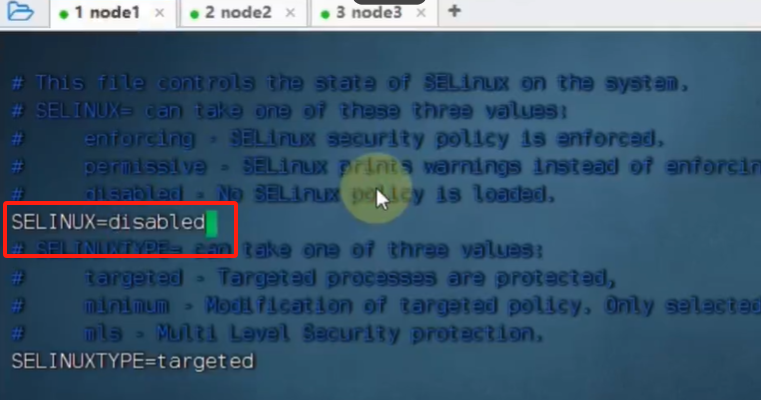
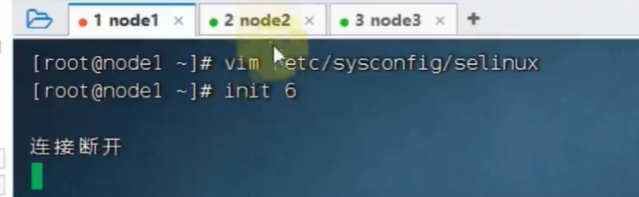
重启系统

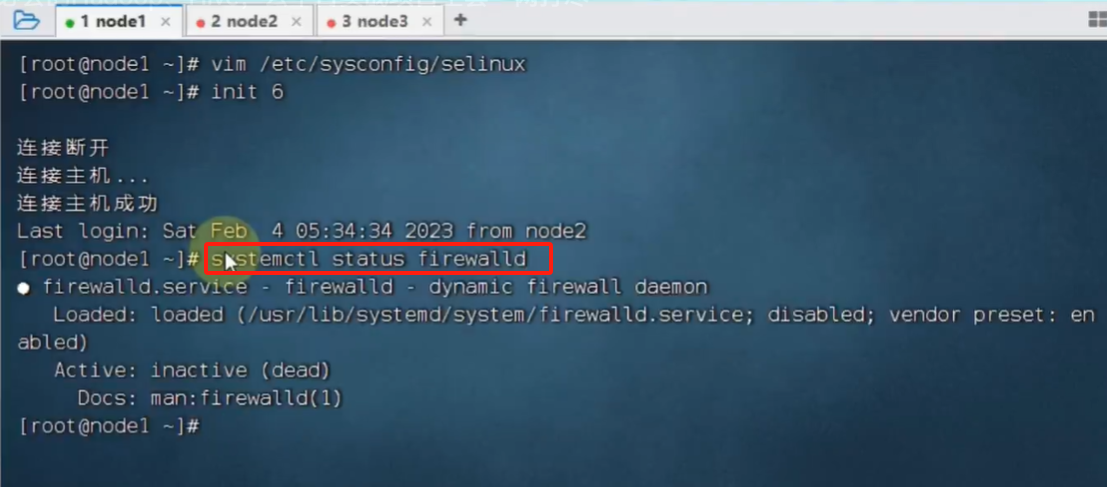
查看防火墙状态:

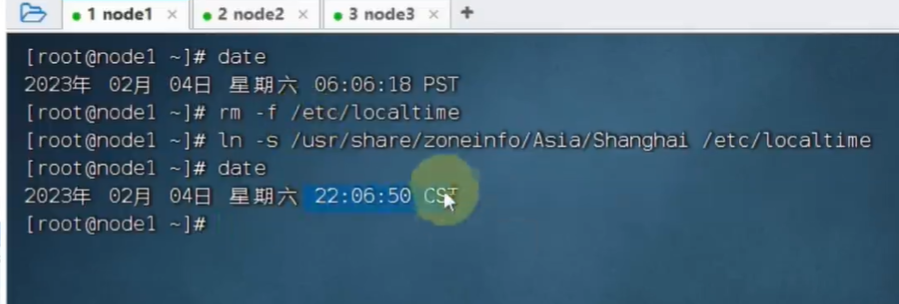
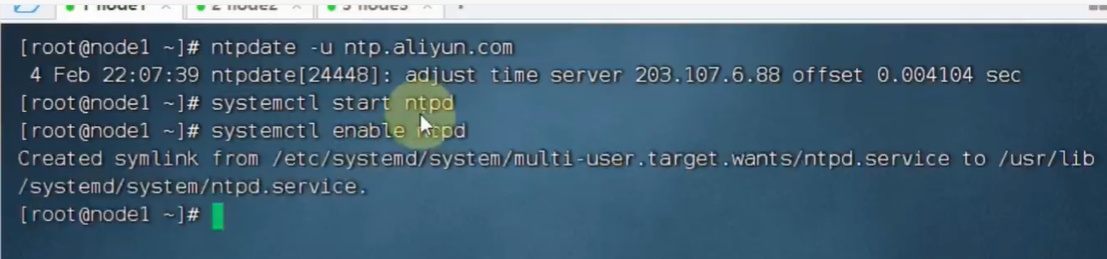

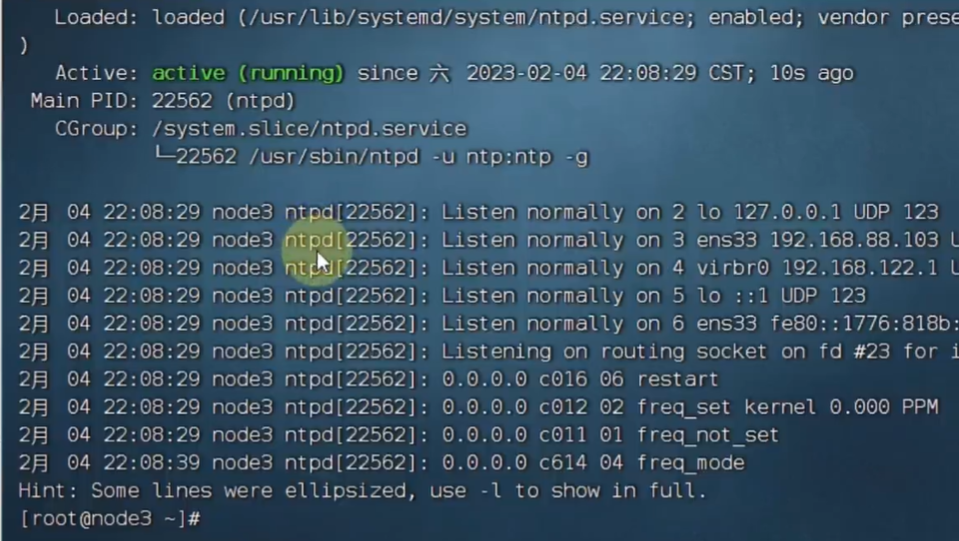
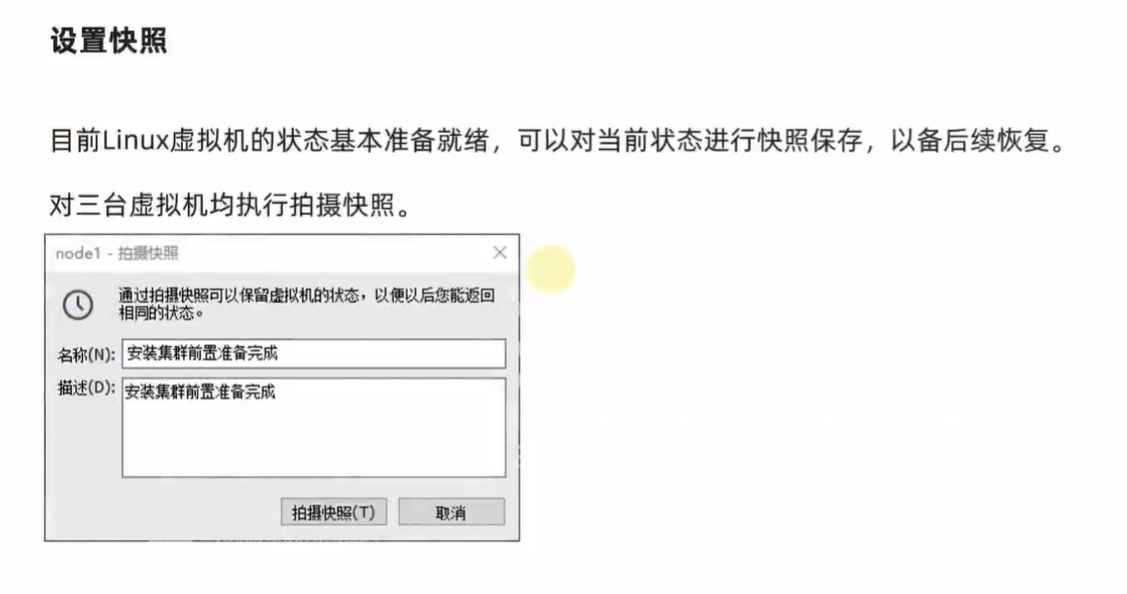

目录:
1.虚拟机设置1
2.虚拟机配置2
3.虚拟机配置3
这里只是设置node1,其他两台都一样设置
修改主机名
刷新
修改ip:
Windows:
linux:
就生成了公钥私钥
就可以免密登录了:在node1登录node3
创建公私钥
设置完之后,就可以从node1到node2
配置软连接
远程复制,从node1到node2:
重启系统
查看防火墙状态: